
聚类分析数据挖掘技术在成人招生中的应用
2018-11-17 07:10傅振南
福建教育学院学报 2018年10期
傅振南
(福建教育学院,福建 福州 350025)
大数据时代,数据挖掘被广泛应用于新零售、金融商业、科学研究、数据云服务、高校管理等领域。随着教育改革的进一步深化,成人高等教育面临着诸多挑战,在普通高等教育扩招的冲击下,生源萎缩相当严重,竞争日趋白热化,在招生高校数量不变而生源急剧减少的情况下,拿出更管用更精准的招生宣传方法是制胜的关键点。文章以F院校成人招生录取数据为例,通过聚类分析数据挖掘技术对相关数据进行挖掘分析,为招生宣传工作提供有力决策支持。
一、聚类分析数据挖掘技术概述
1.聚类分析数据挖掘技术
常用的数据挖掘技术包括:神经网络、决策树、聚类分析、统计分析、关联规则、粗糙集方法、支持向量机、遗传算法等。数据挖掘实际上是挖掘算法的选择、执行阶段。文章首先根据挖掘任务,从常用的技术中选择适合数据分析提取的聚类分析技术算法。聚类分析被广泛应用于模式识别、市场研究、数据分析等众多应用领域,是数据挖掘研究领域一个重要分支。它适合探讨样本数据的内部关系,因为每个样本数据的类别都是未知的,它是用一定的关联标准将所提供的样本数据划分成不同的族,同一族内的样本数据相似度较高,相似度用距离作为度量方式,根据对象的属性值来进行分析评估。K-Means是典型的基于划分的一种聚类算法。其中K表示类别数,Means表示均值,因此K-Means不难理解是一种通过均值对数据单元进行聚类的算法。下面利用K-means 聚类算法的特性,去分析招生宣传对象所在单位类型存在不同的特征,并加以分析应用。
2.使用聚类分析数据挖掘技术的主要流程
做任何工作首先都要确定它的目的任务,数据挖掘也不例外,确定任务后再细分选择数据,清洗一些属性缺失、错误数据值、违反完整约束规则的数据,并搜集遗漏数据,然后进行数据整合,整合完有重复记录须清洗去除。接着做数据预处理分析,进一步考证数据质量,为进一步分析做好准备,根据事先确定的分析任务,从准备好的数据中提取与任务相关的数据,并选择挖掘操作类型。最后将数据转换成针对挖掘算法建立的分析模型,这也是数据挖掘成功与否的关键。
二、聚类分析数据挖掘过程和分析——以F院校2017年录取数据为例
1.收集样本数据
从成人高校招生系统导出F院校2017年19张录取数据表,主要包括考生投档单表、专业代码表、职业类别表、性别代码表等。
2.数据预处理
(1)数据提取。根据原先确定的分析目标提取出样本数据字段,主要从主表——考生的投档单表(T_TDD.DBF)中提取分析目标相关的样本数据字段,主要是考生的毕业学校、所在单位、从业类别、性别等。由于数据库设计的原因,T_TDD.DBF表中有些字段是用代码表示,无法直接读取它的真正表达意思,如性别用“0”和“1”代码表示,民族、政治面貌、招生类别、招生层次、招生专业等字段也均用数字代码标记,因此需要先做好这些代码的转换工作,将其整理成一目了然的标识,表达出它的实际意思。转换好相关样本数据表的格式,将其用SQL Server 2000或ACCESS 2003以及更高版本的数据库操作软件进行表间的数据关联操作,然后通过菜单操作或SQL语句进行连接。
(2)数据清洗。连接整合处理后的考生投档单表(T_TDD.DBF)由68个字段组成,要进行有效的逻辑转换前需要根据分析目标所需的相关样本数据字段,可使用可视化分析技术工具如分布图、条形图、直方图去除对目标分析不存在任何意义的字段。比如招生类别字段,99.6%的字段值都为“统一考试”,对目标分析结果无任何意义,如图1,另如果一个表内的字段值超过97%都为“NULL”,该字段对目标分析结果也毫无意义,将这些字段及跟分析结果不相关的考生号、准考证号、政治面貌等字段去除,经前后对照考虑,选取考生投档单表(T_TDD.DBF)中的与任务挖掘高度关联的教学站点、毕业学校、录取专业、职业类别、性别、成绩等6个字段。

图1 招生类别字段分布图
(3)数据逻辑转换。通过这个步骤,将考生投档单表(T_TDD.DBF)的考生数据按归属教学站点进行聚合,根据以往录取直观经验考虑,不同教学站点分布的专业不同,增加专业录取人数、录取平均分等字段信息,整合转换后的探索性数据集字段如下:教学站点、录取人数、录取平均分、人力资源管理人数、行政管理人数、学前教育人数、会计人数、工商企业管理人数、小学教育人数、电子商务人数、市场营销人数、工程造价人数、机电一体化技术人数、建筑工程技术人数、计算机应用技术人数、电气自动化技术人数、电子信息工程技术人数、数控技术人数、各毕业学校人数、各职业类别人数。
(4)数据规范化。不同教学站点样本数据属性的度量单位不致相同,特别是职业类别、投档成绩和专业人数,采用Max-MAX规范化方式对此类样本数据集进行线性变换标准化操作,可防止初始值域的属性权重两极化。。
3.结果可视化
K-means聚类算法产生教学站点探索性数据集时,重点要将学生所在教学站点分成几个簇,因为它代表K-means算法中k的确定。本方案采用探索性方法,分别创建了包含4,5,6,7,8,9,10个簇的聚类模型,对结果进行分析比较,综合可用性、可解释性原则,发现6个簇聚类模型信息提供最多,也相对容易将结果进行展示。
为便于对聚类挖掘结果进行解释和分析,采用可视化技术工具条形图,找出各簇所表示的独特性质,比较各簇在不同字段上的分布情况,以便提取有用的信息,共生成10幅条形图,因为篇幅限制,文章只选取图2展示聚类1在学前教育和会计相对于其他聚类的显著特性,表1显示了各个聚类簇的特征。
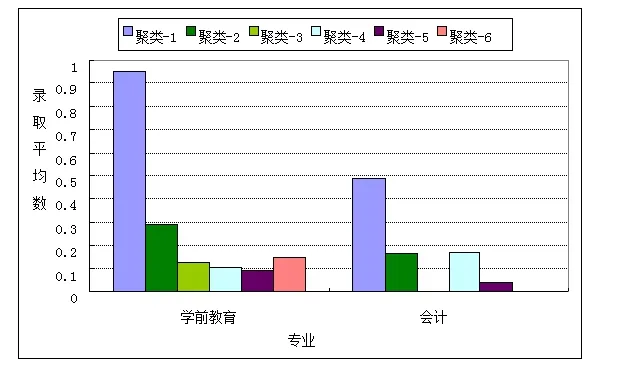
图2 聚类1在学前教育和会计相对于其他聚类的显著特性展示

表1 各簇的特征汇总
三、结果研究与应用
通过聚类结果分析得出1-6簇的特征汇总,结合笔者日常招生宣传的经验总结、实际情况,可在以下几方面进行精准招生宣传工作:1.族1可以看出职业中专学校对这两个专业提升学历有需求,此类专业重点宣传对象为职业中专学校学生。2.族2可以看出技工类学校对理工类专业提升学历有需求,此类专业重点宣传对象为技工类学校或工科类学校学生。3.族3可以看出这些教学站点生源主要是在城乡结合部或农村的男性打工或务农人员,文化水平不高,可重点在这些区域的地方媒介进行宣传,为这类人群进行考前辅导,避免想学没考上的问题出现。4.族4可以看出负责电子商务、工程造价的教学站点对这两个专业招生宣传不够,没针对性在行业里进行招生宣传,须加强。5.族5可以看出这个教学站点报考专业很集中,考生的职业类别大部分为“办事人员”,对专业要求不高,招生宣传时统一引导到一个专业,以便更好教学管理,节省人力物力。
综上,通过对成人招生录取数据的挖掘分析,为招生宣传决策提供了一定的参考。但未对分析结果适用高校的范围进行挖掘,通用性值得进一步研究。
猜你喜欢
江苏科技信息(2022年16期)2022-07-17
大众投资指南(2021年35期)2021-02-16
民族古籍研究(2018年1期)2018-05-21
电力与能源(2017年6期)2017-05-14
新校长(2016年8期)2016-01-10
信息通信技术(2015年6期)2015-12-26
浙江大学学报(工学版)(2015年1期)2015-03-01
图书馆建设(2015年10期)2015-02-13
新世纪图书馆(2014年7期)2014-09-19
中国中医药现代远程教育(2014年16期)2014-03-01
