
数值预报产品多源文件共享监控保障系统研制
2018-11-17 02:35:18夏正龙钟艳雯朱亮吕冠儒周超
现代计算机 2018年29期
夏正龙,钟艳雯,朱亮,吕冠儒,周超
(湖南省气象信息中心,长沙 410118)
0 引言
近年来我国大力开展并加快气象业务现代化建设,随着数值预报技术的发展,目前可用于业务的数值预报产品无论是种类,还是数据量都得到了大大的丰富和增加,中期预报模式、区域预报模式、台风路径预报模式、海浪预报模式、环境预报模式、集合预报等数值预报产品相继投入业务运行,各种分辨率的数值预报产品也越来越得到各级气象预测预报业务系统的重视和应用,数值预报业务正在发挥着越来越重要的基础作用,为各级气象台的日常公众预报服务,特别是为关键性、灾害性、转折性天气的预报服务等提供了有物理基础的指导产品和定量参考信息[1-2],变成不可缺少的重要数据支撑。同时随着气象预报业务服务的需求不断提高,对部门内提供CMACast广播文件共享[3-4]、CIMISS[5-6]、数值预报云[7]下载文件共享以及对部门外提供文件共享等,数据源和共享方式也越来越多样,保障能力要求也越来越高,能够实时掌握各类数值预报产品在多源文件共享服务的及时性和完整性,成为数值预报产品文件共享服务保障工作的迫切需求。
1 多源文件共享监控保障系统的架构设计
目前气象数值预报产品的收集主要通过CMACast广播接收、国家局主站下载、外省推送、数值预报云下载等多种方式,每天收集到的数值预报产品多达几十种类,收集后再通过通信系统分类推送到各文件共享数据源提供服务,从“气象数据传输命名(QX/T 129-2011)[8]”和“气象资料分类与编码(QX/T 102-2009)[9]”这两项气象行业标准并结合文件名定义规范和实际收集情况分析,数值预报产品文件一般具有:(1)文件名有固定结构,由强制字段、自由字段及字段分隔符组成,强制字段和自由字段都有定义;(2)文件名有时间定义,一般都有产品预报时次等定义;(3)一般都有固定时次,例如欧洲中心每天2次(00时,12时),产品生成时间也比较集中;(4)同类产品每个时次生成的文件数和大小等相对也比较固定等特点,为采用以文件名模板区分数值预报产品种类、以文件数和大小判断完整性和按资料时次进行监控等提供了方法策略。我省目前提供数值预报产品文件共享服务方式主要包括共享磁盘映射,FTP服务和CIMISS系统接口调用3种方式,共享磁盘映射和FTP服务采取开通协议,按照类别分目录提供固定天数的查询访问,共享磁盘映射主要针对省局内部直属单位,FTP服务针对全省气象部门及外部门,CIMISS系统以文件系统存储非结构化数据,并设计表结构记录文件索引信息及管理型元数据信息,提供接口调用方式供全省气象部门使用[10-11],这几种共享服务方式为信息采集提供了思路和方法,确认了建立多源文件共享监控保障系统的可行性。
本文结合数值预报产品收集特点和我省提供共享服务方式的分析,充分吸取前期气象监控系统[12-15]成功的设计思路,利用先进成熟的IT技术,设计了多源文件共享监控保障系统,系统整体架构主要由数据共享源、存储管理、功能应用3部分组成,见图1。
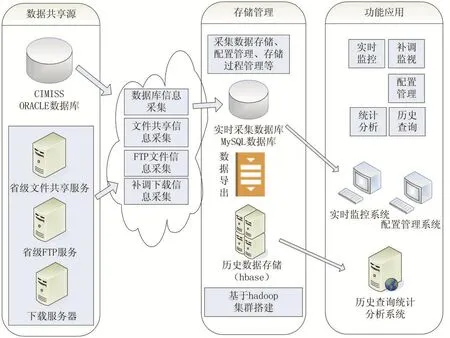
图1 系统框图
1.1 数据共享源
数据共享源主要包括我省目前用于提供共享磁盘映射、FTP服务的各种服务器和接口调用的CIMISS系统,这些数据共享源实时接收着从CMACast、省际共享、下载平台等各处收集到的数值预报产品,按照既定的存储管理和共享服务规则,提供给气象部门各业务单位和业务系统使用。
本文设计以资料代码为每类数值预报产品的唯一标识实时采集不同类型数据共享源的文件信息和统计结果,集中统一存储到实时采集数据库中供监控查询统计使用,具体包括3个方面:(1)对接CIMISS系统的共享服务情况,实时同步采集CIMISS数据库中相关文件信息记录;(2)实时扫描各数据共享源共享目录,采集文件信息,并实时统计逐类别逐资料时次的文件数、百分率等结果;(3)缺失文件及时从可下载数据源处下载,并分发到缺失文件共享数据源提供共享是保障服务完整性的一个重要手段,及时主动扫描每个下载数据源对比从共享数据源采集到的信息记录,获取到缺失文件后下载推送到缺失文件的共享数据源,并存储相关补调下载信息。
1.2 存储管理
综合对气象数值预报产品文件属性、共享服务方式的分析,主要包括各类数值预报产品的基本信息、监控统计信息、下载和存储定义等,从存储信息的使用需求考虑设计为满足较短时间查询的实时采集数据库和较长时间统计分析的历史数据存储2部分组成,存储内容基本一致,为整个系统提供数据支撑。
(1)实时采集数据库采用MySQL数据库管理,存储实时从多源文件共享数据源采集的文件信息和文件数、完整率等统计结果,在整个存储表结构设计中,资料代码为每类数值预报产品的唯一标识,关联所有的存储信息,保存时间较短,一般为1-2月,保存内容主要包括监控信息、文件存储信息、下载补调信息、统计结果以及数值预报产品相关配置定义(基础定义、下载定义、存储目录、监控时次定义等),见图2具体表结构设计E-R图。
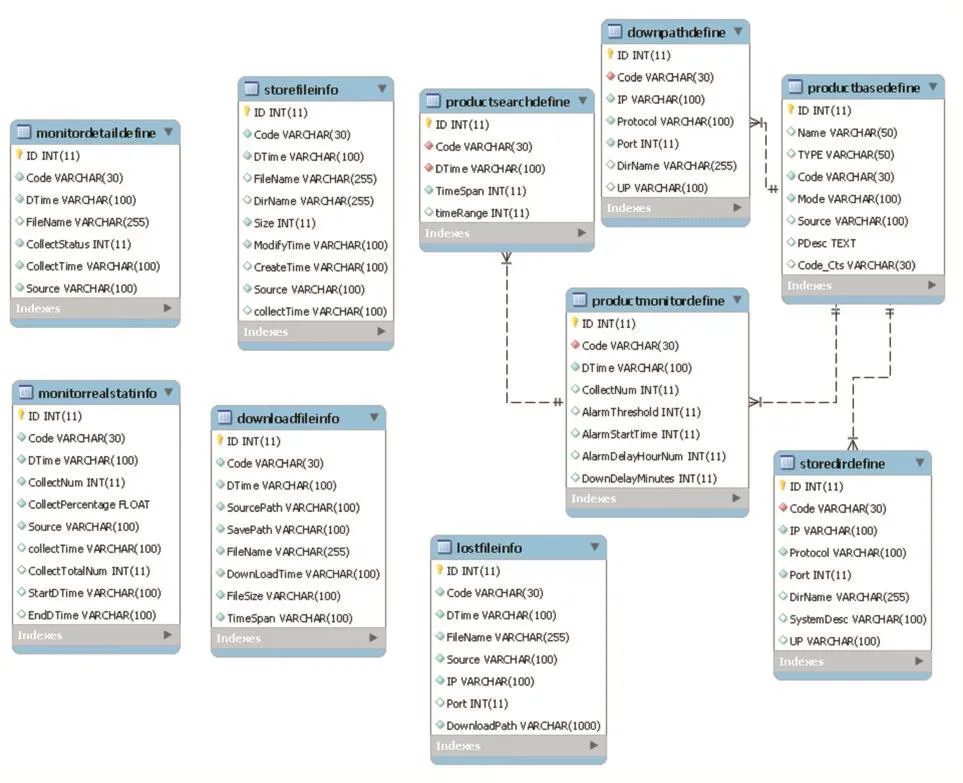
图2 具体表结构设计E-R图
(2)历史数据存储:本文采用基于Hadoop集群搭建HBase分布式数据库,用于存储管理较长时间的采集信息,为较长时间的统计分析功能服务。HBase是一个面向列的分布式数据库,表中的所有行根据行的键值(也就是表的主键)排列,行中的列被分成“列族”,同一个列族的所有成员具有相同的前缀,所有对表的访问都要通过表的主键,所以主键的设计将直接影响查询检索,数值预报产品一般总是依照资料时次、产品代码、数据源等顺序进行查询统计分析,因此本文结合实时采集数据库的表结构设计,主存储信息表采用资料时次、产品代码、数据源及ID构成的组合键作为主键,列字段和实时采集数据库对应表的列字段相同,其他辅助表结构则和实时采集数据库相同,这样极大地方便了对历史存储信息的数据导入(出)和统计分析,例如查询一段时间的某类数值产品在某台数据共享源上的文件情况,只需要将起始时间、结束时间、产品代码、数据源作为行键过滤条件加到HBase的Scan的Filter列表中即可,同时可设置起始时间和结束时间为Scan的起始行和终止行来提高查询速度,但需注意将时间格式转换为行键中资料时次对应格式,查询条件代码示例和结果(转换输出格式)如下:
monitorrealstatdao mrsd=new monitorrealstatdao();/*监控统计结果查询类*/
mrsd.getDataByTimeRange("20180123 15∶26∶50".getBytes()/*起始时间*/,"20180127 15∶26∶50".getBytes()/*结束时间*/,"F.0011.0002.S001".getBytes()/*资料编码*/,"省级文件共享服务器".getBytes()/*数据源*/);
图3
(3)为了导出实时采集信息到历史数据存储HBase库中,本文配合使用了Hadoop生态圈的软件Oozie和Sqoop[16],通过“数据增量导入”方式实现从实时采集数据库定时同步信息到历史数据存储中管理。Apache Sqoop是一个开源工具,允许用户将结构化数据抽取到Hadoop中用于进一步处理,Sqoop拥有一个可扩展的框架,能够从(向)任何支持批量数据传输的外部存储系统导入(导出)数据,本文通过使用Sqoop job工具,结合MySQL表结构和HBase存储表行键和列的设计,建立了从MySQL数据库到HBase库的增量导入job,完成实时采集数据库和历史数据存储的数据同步功能,创建Sqoop job数据导入语句创建示例(监控统计信息)如下:
sqoop job-- meta- connect jdbc∶hsqldb∶hsql∶//10.110.172.41∶16001/sqoop--create monitorrealstatinfo-syncjob-- import--connectjdbc∶mysql∶//10.110.172.181∶3306/modelmonitordb--table monitorrealstatinfo--username sa--password-file/user/hadoop/works/sqoop/sqoop-monitorrealstatinfo-sync-job/.password--hbase-table monitorrealstatinfo--column-family monitorstatinfo--columns"ID,Code,DTime,CollectNum,CollectPercentage,Source,collectTime,CollectTotalNum,StartDTime,EndDTime,rowtime"--hbase-row-key DTime,Code,Source,ID--incremental lastmodified--check-column rowtime--last-value"1970-01-01 00∶00∶00"-m 1
本文创建的Sqoop job具体任务有①下载补调文件信息导入②监控信息详情导入③监控统计信息导入④文件存储信息导入⑤产品基础定义导入等。

图4
Apache Oozie是一个运行工作流的系统,工作流由相互依赖的作业组成,Oozie由两部分组成:一个工作流引擎,负责存储和运行由不同类型的Hadoop作业组成的工作流;一个coordinator引擎,负责基于预定义的调度策略及数据可用性运行工作流作业。在Oozie中,工作流由一个由动作节点和控制流节点组成的DAG(有向无环图),本文通过定义Oozie工作流,定时执行每一个Sqoop导入job任务,实现数据同步作业的及时运行和管理。Oozie工作流创建和成功执行DAG图示例(监控统计信息)见图5-图6:

图5 Oozie工作流创建
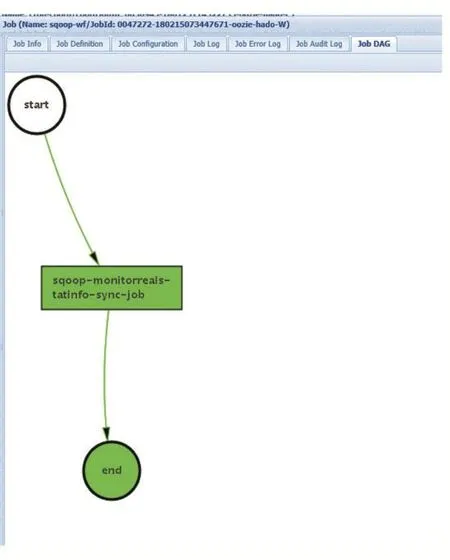
图6 成功执行DAG图示例
1.3 功能应用
本文基于集中存储的实时采集数据库和历史数据存储,将同一共享数据源的各类数值预报产品进行集中统一监控,实现接收数、接收百分率、接收详情以及缺失补调情况等实时监控、历史查询和统计功能,为我省业务值班和数据服务管理人员提供及时掌握情况的重要工具,设计了具有实时监控、补调监视、配置管理、历史查询和统计分析等功能的3个子系统:
(1)配置管理子系统:根据数值预报产品相关文件特点,实现产品定义、存储目录、下载定义等配置的灵活添加、修改等功能。
(2)实时监控子系统:建立针对不同种类数值预报产品收集情况的实时监控,以图表两种形式展示产品类型、产品名称、文件接收数和完整率等信息,并支持文件收集详情、历史信息、补调下载记录等任意时间段的查询统计功能,见图7。

图7 程序运行界面
(3)历史查询统计分析子系统:基于HBase历史数据存储可支持长时段的统计查询分析,本文基于B/S架构通过对HBase表数据查询统计功能模块的开发,目前已实现了各类数值预报产品逐30天收集情况查询统计功能,为其他长时段统计查询分析功能开发提供了经验如图8所示。

图8 历史查询图形显示
2 结语
本文通过对我省数值预报产品收集情况的分析,设计建立了以实时采集数据库(MySQL数据库)和历史数据存储(HBase库)为核心,实时采集各数据共享源相关文件信息,建立了具有实时监控、历史查询、统计分析等功能的数值预报产品多源文件共享监控保障系统,本文重点阐述了系统的整体结构、关键技术和应用功能等内容,系统的建立在我省气象资料的数据保障业务中具有重要意义。(1)改变了我省目前没有集中统一的平台实时监控和有效掌握数值预报产品每天接收下载及文件共享服务的情况,为保障我省气象预报预测与服务人员应用数值预报产品资料的需求和管理人员实时掌握各类数值预报产品在多源文件共享服务的及时性和完整性等方面提供了重要的保障工具。(2)通过在Hadoop集群下建立HBase分布式数据库存储长时间序列的历史数据,开发统计分析功能,实现了我省在大数据方面研究工作的突破,为以后相似工作提供了方法经验。
下一步研究将以在大数据平台下针对数值预报产品多源文件共享监控保障的长时间序列统计分析工作为重点推进,为我省进一步制定数值预报产品的数据存储管理服务策略等工作提供分析方法和依据,同时本文的设计思路与方法可以为气象部门进行其他气象资料的统计分析提供参考与借鉴。
猜你喜欢
小学生学习指导(低年级)(2023年4期)2023-05-09 11:52:52
中学生数理化·高一版(2021年11期)2021-09-05 14:27:13
计算机与生活(2018年3期)2018-03-12 08:38:11
中国科技期刊研究(2017年2期)2017-05-14 06:16:26
焊接(2016年2期)2016-02-27 13:01:02
江西通信科技(2015年3期)2015-12-05 05:52:09
浙江大学学报(工学版)(2015年2期)2015-05-30 07:05:04
无线互联科技(2014年11期)2014-12-09 08:55:20
土木建筑工程信息技术(2013年4期)2013-10-17 02:27:54
燃气涡轮试验与研究(2010年4期)2010-04-16 03:54:23
