
基于大数据的检察院新媒体平台稿件优化方法
2018-11-17 01:31陈立华刘盼盼
软件 2018年10期
季 芳,陈立华,孙 浩,刘盼盼
基于大数据的检察院新媒体平台稿件优化方法
季 芳1,陈立华2,孙 浩2,刘盼盼2
(1. 最高人民检察院检察技术信息研究中心,北京;2. 山东大众信息产业有限公司,山东 济南)
本文提出一种基于大数据与语义分析技术的稿件优化系统实现方法,该方法依据各级检察院以往文章的传播数据,对原创稿件和网络采集稿件进行评级和传播效果预测,筛选出符合检察机关官方新媒体账号属性的优秀稿件。以信息技术手段辅助创作,为提升检察院新媒体平台的内容质量和传播效果提供了技术支撑。统计数据表明,该方法可有效的提升检察机关新媒体平台的舆论影响力和宣传力度。
大数据;机器学习;自然语言处理;新媒体创作
0 引言
随着移动通讯网络环境的不断完善以及智能手机的进一步普及,移动互联网应用向用户各类生活场景深入渗透,促进手机上网使用率增长。互联网及移动化的普及,也使得新媒体以互联网为依托得到了迅速发展。国务院办公厅发布的《2017年政务公开工作要点》中对信息公开、政策解读、回应关切、制度机制建设、公众参与等方面提出了新思路,新要求。检察院积极贯彻党中央的重要战略部署,主动顺应“互联网+”的发展趋势,在职能范围内灵活运用互联网思维,充分利用大数据、云计算、物联网等现代信息技术,激发创新智慧与创造活力,推动检察工作创新发展,成为“互联网十检察工作”的主要内容。如何充分利用官方微博、微信等自媒体平台聚拢人气,扩大影响力,如何提高内容质量提出了更高的要求。
曹建明检察长在全国检察机关新闻宣传工作会议上要求统筹运用传统媒体和新兴媒体,着力提升新媒体时代社会沟通能力,弘扬检察“主旋律”,唱响检察“好声音”,传播检察“正能量”,为促进人民检察事业创新发展、全面推进依法治国作出更大贡献。
1 研究概述
本研究以检察院微信公众号历史文章的相关数据为基础,结合大数据与自然语言(NLP)分析技术,根据自媒体平台历史文章的传播情况为参照,采用机器学习的方式,建立文章传播预测模型,对网络上采集的内容及原创内容进行评级和预测,筛选出符合检察机关官方新媒体账号性质的文章,从而达到辅助运营人员进行文章创作的目的。本研究主要从数据抓取、自然语言处理、公众号画像和传播预测模型四个方面进行了探索。
数据抓取:对检察院微信公众号历史文章的相关数据进行抓取,包含文章标题、正文、发布时间、阅读量、点赞量等数据,考虑该研究的主要内容与数据获取方式的优缺点,本研究选用从数据公司购买数据进行研究,在本文中不再赘述。
自然语言处理:对检察院微信公众号历史文章进行处理,分析文章关键词及其词频。
公众号画像:公众号画像数据包括公众号粉丝数据,包括粉丝数、粉丝分布、性别、时长、来源等,还有公众号文章数据,包括推送频率、推送顺序、标题长度、主题情况等。本研究从已授权的微信公众号接口获取公众号画像数据,在本文中不再赘述。
传播预测模型:针对前面步骤获取的数据,利用机器学习算法,建立文章预测模型对准备发表文章的传播情况进行预测。
2 自然语言处理
自然语言处理是研究能实现人与计算机之间用自然语言进行有效通信的各种理论方法,目标是使用机器能够理解和产生自然语言,而自然语言理解和产生的前提是对语言能够做出全面的解析。
汉语词汇是语言中能够独立运用的最小的语言单位,是语言中的原子结构。汉语的研究可分为语法层面和语义层面的研究。语法层面包括中文分词、词性标注以及句法解析;语义层面包括命名实体识别、语义组块以及语义角色标注[9]。基于自然语言处理,可以进行关键词提取、情感分析以及自动问答等。
因此对中文进行分析就显得至关重要。
本文基于自然语言处理的基本技术,实现了对历史文章关的键词提取,首先采用分词技术处理文章,过滤停用词,保留有效的词;然后采用tf-idf(term frequency–inverse document frequency)算法计算出每个词语的权重;最后结合词语出现在标题中的重要性实现了关键词的提取[9]。在上述基础之上,根据每篇公众号文章的阅读数综合考虑得到公众号的关键词云。
串补技术最早应用在中国的输电线路中[10-12],该技术能显著提高大容量、远距离输电线路的利用效率,促进电网的稳定运行水平,降低输电损耗。将串补技术引用到配电线路中,同样可以解决配电网电压问题[11-12],不仅可以调节过电压或低电压至合格电压水平内,同时可以提高线路的功率因素降低线路损耗。
首先根据tf-idf(term frequency-inverse document frequency)计算公式并结合公众号文章标题的重要性,得到每篇文章中的关键词。然后根据每篇文章的阅读数综合考虑得到公众号的关键词云。
每篇文章中词语权重的计算公式如下:
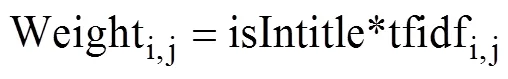
每篇文章中关键词最终权重的计算公式:
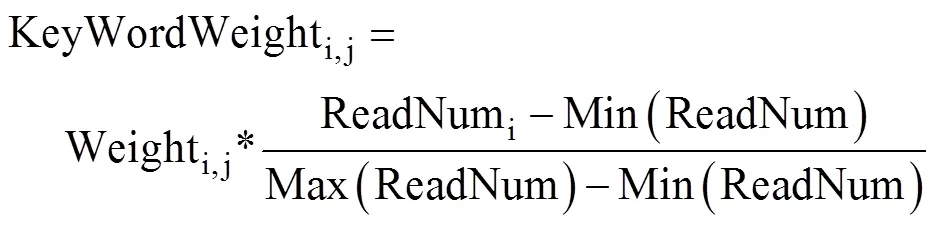
多篇文章中同时出现该关键词时,取权重最大的作为该关键词的最终权重。计算出权重后,排序,显示,得到最终的关键词云。
3 预测模型
3.1 数据划分
将微信号文章数据随机取三分之二作为训练语料,取三分之一作为测试语料。
3.2 算法选取
公众号下文章的传播效果可以用文章的阅读数或者点赞数表示,暂时以阅读数代表文章的传播效果。可以采用机器学习中的分类或者回归模型实现阅读数的预测。基于分类模型的方法通常是将文章按阅读数划分为几个等级,然后进行多元分类,目前没有统一的分类标准。基于回归模型的方法试图找到影响因素与阅读数之间的相关关系,进而使用线性回归或非线性回归模型进行[1]。研究目的是预测出文章阅读数的具体值,属于连续型数据的预测,因此应采用机器学习算法中的回归分析算法实现。具体可采用多元线性回归的方法实现。该方法通过已有的大量历史数据,找到一条最佳拟合直线,作为自变量和因变量的函数直线,最终实现预测。[7]
3.3 影响因素(自变量)的选取
公众号推送新文章时,该文章未来的阅读数,受多方因素影响,主要从两个角度考虑。一是从公众号特性的角度,包括公众号的粉丝数量、公众号男女粉丝比例、公众号推送文章的频率以及公众号粉丝的地域分布等;二是从文章的角度,包括文章推送的时间段、文章推送的顺序、文章标题的长度、文章的情感倾向以及文章的主题等。
3.4 线性回归算法
线性回归(Linear Regression),数理统计中回归分析,用来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,其表达形式为y = w'x+e,e为误差服从均值为0的正态分布,其中只有一个自变量的情况称为简单回归,多个自变量的情况叫多元回归[11]。

n组观测值时,

其矩阵形式为



最终计算出线性方程的所有参数的值。当有新的数据需要预测时,只需要将新数据的各个影响因素的值输入即可得到相应的预测阅读数。
按照该方法建立模型后输入文章标题、发布时间和正文内容后即可对文章的阅读量和传播效果进行预测,如下图所示。

图1 文章预测示例
4 结语
选取“最高人民检察院”微信公众号发布的历史文章,对预测模型的预测数据和实际的传播数据进行比对,结果如下。
由以上对比图可看出,该研究对文章的传播预测与实际情况相差不大,该项研究已经应用到最高人民检察院的微信管理系统中,有效提升了检察院新媒体文章的阅读量和传播,得到了检察院新媒体工作人员的一致肯定。
表1 文章阅读数预测值与实际值对比
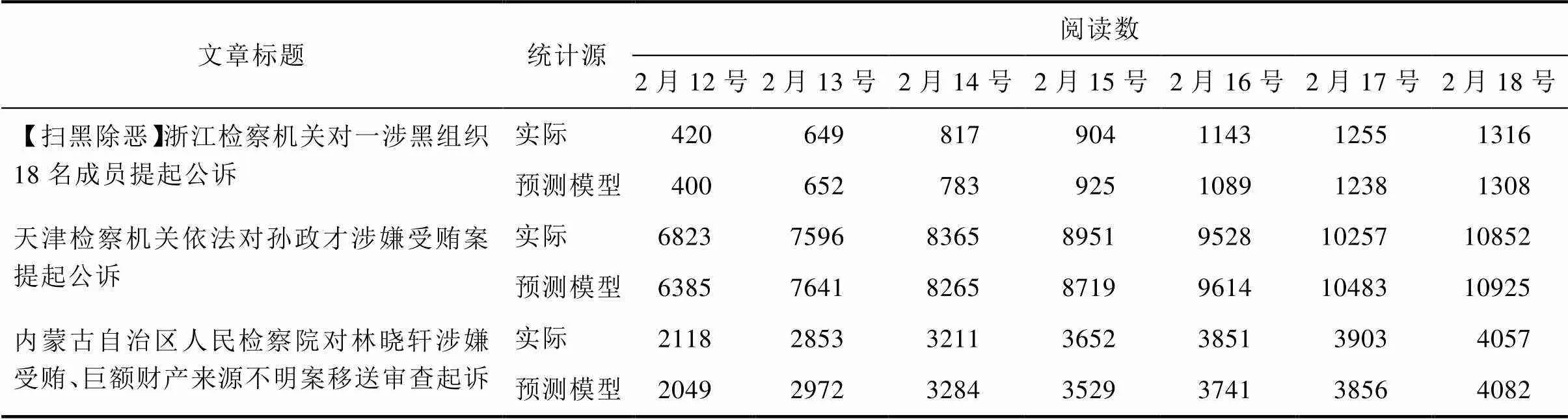
Tab.1 Comparison of predicted and actual values of article readings
表2 文章点赞数预测值与实际值对比

Tab.2 The article compares the predicted value with the actual value
[1] 范淼, 李超. Python 机器学习及实践-从零开始通往Kaggle竞赛之路. 清华大学出版社. 2016: 64-81.
[2] 周志华. 机器学习. 清华大学出版社. 2016.
[3] Pedro Domingos. The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World[M]. Basic Books, 2015.
[4] Daniel T. Larose, Chantal D. Larose. 王念滨, 宋敏, 裴大茗, 译. 数据挖掘与预测分析(第2版). 清华大学出版社. 2017.
[5] Maja R. Rudolph, Francisco J. R. Ruiz, Stephan Mandt, David M. Blei. Exponential Family Embeddings. 2016.
[6] Alexander Ratner, Christopher De Sa, Sen Wu, Daniel Selsam, Christopher Ré.Data Programming: Creating Large Training Sets, Quickly. 2017.
[7] Jake VanderPlas著陶俊杰, 陈小莉, 译Python. 人民邮电出版社. 2018.
[8] Lapedriza, À., Oliva, A., Torralba, A., Xiao, J., & Zhou, B. NIPS. Learning deep features for scene recognition using places database. 2014.
[9] 郑捷. NLP汉语自然语言处理原理与实践. 电子工业出版社. 2017: 16-21.
[10] Zhang, M., & Zhou, Z. A Review on Multi-Label Learning Algorithms. 2014.
[11] Styart J. Russell, Peter Norvig 著殷建平, 祝恩, 刘越, 陈跃新, 王挺, 译. 清华大学出版社. 2013.
[12] Chang Liu, Jun Zhu.Riemannian Stein Variational Gradient Descent for Bayesian Inference. 2017.
Research on Content Creation Optimization of New Media Platform of Procuratorate Based on Big Data
JI Fang1, CHEN Li-hua2, SUN Hao2, LIU Pan-pan2
(1. Supreme People's Procuratorate Inspection Technology Information Research Center, Beijing, China; 2. Shandong Dazhong Infomation Industry Co., Ltd, Jinan City, Shandong Province, China)
By big data and Chinese semantic analysis, according to the dissemination of previous articles of the procuratorate at all levels, the content and original manuscripts collected on the network are predicted and disseminated, and the characteristics of the official new media account of the procuratorate are selected. Excellent manuscripts were published, and information technology was used to assist in the creation. Data support was provided to improve the quality of content and communication effects, and the public opinion of the new media of the procuratorate was enhanced and the publicity was enhanced
Big data; Machine learning; Natural language processing; New eedia creation
TP391.1
A
10.3969/j.issn.1003-6970.2018.10.048
季芳(1981-),女,高级工程师,研究方向为检察信息化、电子政务;陈立华(1980-),男,高级工程师,研究方向为自然语言分析、大数据、人工智能;孙浩(1983-),男,开发工程师,舆情与大数据系统研究;刘盼盼(1990-),女,研究生,研究方向为自然语言处理。
季芳,陈立华,孙浩,等. 基于大数据的检察院新媒体平台稿件优化方法[J]. 软件,2018,39(10):250-253
猜你喜欢
党的生活(江苏)(2021年4期)2021-06-04
党的生活(江苏)(2020年10期)2020-11-26
党的生活(江苏)(2020年9期)2020-11-07
今日农业(2020年19期)2020-11-06
党的生活(江苏)(2020年6期)2020-08-27
山西省政法管理干部学院学报(2016年2期)2016-07-31
预防青少年犯罪研究(2015年5期)2015-12-30
纺织服装周刊(2015年35期)2015-01-07
纺织服装周刊(2015年24期)2015-01-07
纺织服装周刊(2015年15期)2015-01-07
