
中国贫困县划分精度商榷①
——基于夜间灯光数据的检验
2018-11-15 01:35:24叶宸辰唐斌斌刘林平
中国农业大学学报(社会科学版) 2018年5期
叶宸辰 唐斌斌 刘林平
扶贫开发是中国改革开放以来的伟大事业,精准识别贫困对象是客观、科学扶贫的重要基础。精准扶贫,在微观层次上要落实到户,在中观与宏观层次上则要精准划分贫困县②政府文件中使用的全称是“国家扶贫开发重点县”。为了直观简明,本文将其简称为“国家级贫困县”或“贫困县”。。回顾中国农村扶贫开发的发展进程,可以把扶贫工作的主要特点概括为区域瞄准[1]。20世纪80年代中期以国家或省确定的贫困县为主要扶贫对象,2001年转为15万个贫困村,2011年又确立14个连片特困地区[2]。可见,区域扶贫是我国长期以来扶贫开发的主要手段。本文将围绕区域扶贫——精准识别贫困县展开分析。
相比于微观贫困识别,宏观识别能够解决诸多问题,如减少人力、物力、财力的损耗,减少精准识别到户的地理障碍,提高宏观扶贫政策的实施质量,减少政策制定时无法预测的实施风险等[3-5]。在宏观层次上识别,在区域中解决问题,不仅是微观精准识别的良好基础,而且能够为扶贫开发带来新的突破口。
那么,从我国开始实施扶贫开发政策以来,贫困县识别是否精准?贫困县评定过程是否受到政治、历史、区位等非经济因素的影响?这都是需要正视的问题。本文将使用DMSP/OLS夜间灯光数据,对国家级贫困县划分的准确度进行检验,并深入分析。
一、夜间灯光数据的客观性与可用性
美国国防气象卫星计划(Defense Meteorological Satellite Program,DMSP)在低空极轨道上运行四颗搭载线性扫描系统(Operational Linescan System,OLS)的卫星,其中三颗卫星记载夜间数据,即DMSP/OLS夜间灯光数据,其独特之处在于可以探测地表夜间在“可见光—近红外波段”的发射辐射,利用搭载线性扫描系统可以监测月光照射的云层,以及来自城市、乡镇、工厂、油气光线和短暂的(如火灾和闪电)电磁波,形成“VIS”波段数据③NOAA.Night-time Lights Posters.https://ngdc.noaa.gov/eog/night_light_posters.html.(accessed April 28,2018)。。目前,美国国家地球物理数据中心(National Geophysical Data Center,NGDC)每天从四个卫星接收数据,数据处理量大约在8.5 GB。可见,DMSP/OLS夜间灯光数据也是一种大数据。目前,对原始数据的处理包括重新设置卫星导航系统,按时间顺序整理数据,通过传感器解析数据,处理在传输过程中由于翻转引起的数据问题,将数据整合到卫星轨道中并将数据写入机器人磁带库系统①NOAA.DMSP Archive Description.https://ngdc.noaa.gov/eog/archive.html.(accessed April 28,2018)。。
(一)DMSP/OLS夜间灯光数据的优势
DMSP/OLS传感器具有良好的物理特征优势,增强了DMSP/OLS夜间灯光数据的客观性,有效克服了传统调查数据的诸多限制。
就其物理特征而言,在成像、传感器、数据处理等三方面有其特殊性②NOAA.OLS-Operational Linescan System.https://ngdc.noaa.gov/eog/sensors/ols.html.(accessed April 28,2018)。。第一成像方面,DMSP/OLS传感器具有低光成像功能,每天两次检测全球范围内的云分布和云顶温度,同时形成红外图像。目前数据包括:全球范围内的低分辨率图像数据,三千米扫描记录的高分辨率图像数据,以及根据监测记录的卫星星历、太阳和月球的资料所形成的高分辨率图像数据。其中,可见光图像的像素是相对值,范围在0到63之间。低分辨率扫描线的信息由1 465个可见像素、1 465个红外像素、卫星星历、质量评估结果以及其他卫星和天文参数组成。高分辨率扫描线的信息包含7 325个像素和相关支持信息。第二传感器方面,在太阳和月亮不同的光照情况下,可调整传感器的增益水平以保持恒定的云参考值。传感器回摆式扫描,以恒定的速率连续采集模拟信号。第三数据处理方面,通过压缩、重新排序、重构和解交织技术处理OLS数据。使用四体轨道力学程序计算卫星星历,所得数据均为观测值,而不是预测值,并且轨道数也纳入其内。另外,缺失的扫描线会被重新正确定位。依据每个像素和每条完整的扫描线对数据进行质量评估。
得益于DMSP/OLS传感器的物理特征优势,DMSP/OLS夜间灯光数据具备监测数据的良好属性。长此以来,传统的社会经济统计数据属于调查数据,主要是通过普查或抽样调查等方式收集获得。调查数据的收集需要花费高昂的人力、物力、财力成本,更新数据的周期较长,还可能受到政治或权力干扰,或者存在收集、录入、汇总与统计过程中的人为误差。而夜间灯光数据是一种监测数据,能够实时采集大到国家,小到县域或村落的各个层次的全球数据,不受地理空间、人为等因素干扰,数据的客观性增强。因此,在量的方面,DMSP/OLS夜间灯光数据扩大了数据采集量;在质的方面,提高了数据的时效性、客观性与准确性。
(二)灯光数据在社会经济领域的应用
在社会科学研究中,DMSP/OLS夜间灯光数据逐渐成为研究者青睐的研究工具。利用DMSP/OLS夜间灯光数据优势可以在城市空间、人口密度、经济发展等研究领域灵活应用。比如在城市发展研究领域,城市空间研究、城市化研究是应用灯光数据的主要研究方面。陈晋等人利用夜间灯光数据构建灯光指数,提出用遥感指标法评估中国城市化水平[6]。他们指出,遥感指标法可以克服统计指标法的主观性、滞后性、高成本等局限,弥补部分地区缺失的统计数据,构建综合全面、有可比性的城市化水平测量指标,应用前景广泛[7]。再如,在人口研究领域,主要利用DMSP/OLS夜间灯光数据进行人口密度分布的研究。卓莉等人运用夜间灯光数据、人口数据和植被覆盖指数来估算人口密度,发现其达到的人口密度网格化水平比行政单元化水平更接近人口实际分布特征,实现人口数据与社会经济统计数据的结合[8]。
此外,夜间灯光数据在经济发展领域的研究应用也不容忽视。国内外学者均已证明夜间灯光数据和国内生产总值之间的强相关性,可以作为良好的社会经济参数。国外学者偏向从国家层次展开研究,国内学者则在省级或某区域的应用居多。例如,1980年,韦尔奇(R.Welch)根据美国夜间灯光数据建立人口、城市面积与能源消耗量之间的关系模型(R2=0.89),证明夜间灯光数据可以监测国家层面的能源消耗量[9]。1997年,埃利维奇(Christopher D.Elvidge)等研究夜间灯光数据与各国国内生产总值的关系,发现二者具有强的对数-对数相关关系(R2=0.97)[10]。王琪等人的研究发现夜间灯光强度与中国各省的国内生产总值的拟合度约为94%,证明夜间灯光数据应用于省级经济分析的可行性[11]。徐康宁等以夜间灯光数据作为国内生产总值的替代变量,揭示出政府夸大GDP统计数据的可能性[12]。
综上可见,在社会科学研究中,DMSP/OLS夜间灯光数据的时效性、客观性、准确性、易获得性等优势使其具有广泛的应用价值。
(三)夜间灯光数据在贫困研究中的应用
1.代理变量:与多维贫困指数强相关
在贫困问题研究方面,近些年来国内外学者的相关研究证明了夜间灯光数据评估贫困问题的可行性。国外学者研究较早,2009年埃利维奇等人率先应用DMSP/OLS夜间灯光数据绘制世界贫困地图[13]。近年来,国内学者也开始应用夜间灯光数据研究中国的贫困问题。例如,王汶等人应用夜间灯光数据对省级贫困问题进行研究,其首先使用17个社会经济指标建构省级多维贫困指数,然后通过线性回归模型检验夜间平均灯光强度与该指数的拟合程度(R2=0.854)[14]1258-1261。延续这一思路,余柏蒗等人利用夜间灯光数据进一步验证夜间平均灯光强度与中国县级多维贫困指数的相关性,他们主要以重庆市为研究样本,用10个社会经济指标构建综合贫困指数,建立多维贫困指数与平均灯光强度的线性回归模型,结果显示决定系数R2高达0.855 4,二者高度相关[15]1219-1223。2016年,潘竟虎和胡艳兴以夜间灯光数据为基准,证明构建的多维贫困指数的正确性[16]126。虽然证明思路有所改变,但从线性回归模型中得知,平均夜间灯光指数依然是与多维贫困指数存在正向强相关关系,而且从平均夜间灯光指数得到的拟合度(R2=0.654)要比区域灯光总量指数的拟合度(R2=0.213)高得多[16]127。
由此可见,在以往的研究中,已多次证明平均夜间灯光强度与多维贫困指数之间具有较强相关性;另一方面也可以看到,研究者建构的多维贫困指数均纳入了经济维度和社会维度的指标。因此,平均灯光强度可以作为社会经济指标的代理变量,可以作为评估中国贫困的有效工具。本文将参考前人研究,不重复进行多维贫困指数的建构与相关证明工作,而把夜间灯光数据直接视为社会经济指标的代理变量,用以评估贫困问题,如中国贫困县的划分准确性。
2.研究局限:缺乏关注现实问题
从国内学者的研究中可以发现,以往关于中国贫困县的空间识别等技术层面的分析较丰富,但缺少联系某一具体问题展开研究,如国家级贫困县的精准识别、精准退出等。余文的思路是,根据平均灯光强度将2 856个县区从特困县到极富裕县分为七类,分别计算出每一类中属于国家级贫困县和非贫困县的个数,分析县域分布态势[15]1227。潘文将计算出的多维贫困指数进行分级,然后与国家级贫困县的空间分布进行对比[16]128。所以准确说来,这些研究主要证明了空间识别贫困的工具可行性与有效性,但没有围绕现实的贫困问题展开探讨。我们认为,贫困研究中,方法与工具的探索及优化是一个方面,现实问题的发现与探究也有其意义。因此,本文将围绕国家级贫困的划分问题,运用夜间灯光数据这一良好工具,进行深入探讨。
二、检验过程:国家级贫困县的夜间灯光值
(一)国家级贫困县的评估过程
从1986年国家确定有组织的开发式扶贫方式以来,中国农村扶贫工作具有典型的区域性特征,主要以县为单位开展工作,按省(自治区、直辖市)分配贫困县数量,以十年为一周期确定国家扶贫开发重点县名单。总体来看,自20世纪90年代以来,我国扶贫开发工作经历了三个主要阶段(参见表1)。
第一阶段是农村扶贫攻坚阶段,八七计划明确提出国家贫困县评定标准,确定国家级贫困县592个,分布在27个省、4个自治区和1个直辖市中。第二阶段是农村扶贫开发新阶段,主要把东部沿海发达地区的贫困县名额全部调整到中西部地区,增强区域聚焦;确定以国家扶贫办向各省规定贫困县总数量,各省自行评定上报具体县名单的方式开展工作。该阶段评定数量仍为592个,主要聚焦中西部的16个省、4个自治区和1个直辖市。第三阶段提出把连片特困地区作为扶贫开发的主战场。最新贫困县名单有所微调,分布区域没有改变,总数仍为592个⑦截止到2018年6月,官方未公示新的重点县名单。。

表1 国家级贫困县的评定情况
从三次扶贫阶段来看,评定国家贫困县主要参考经济指标,通过抽样调查、层层上报的方式获取统计数据。吴国宝曾指出,尽管每个县有100个农户入样,但是各省自行按照国家配额数量选报贫困县名单,所以抽样标准各省不一,而且仅仅依据省级层次的农民收支水平,由此估计的人均收入水平在统计上缺乏代表性[17]。此外,统计数据和抽样调查数据可能存在人为偏误,“一些县级政府故意压低人均收入,夸大贫困人口数,以争夺贫困县指标”[18]。如果上报数据有造假之嫌,就意味着选报的贫困县名单也有失真的可能性。那么,失真名单将扰乱评定机制,造成社会资源分配不公。综上所述,依据统计调查数据评定贫困县,有可能产生人为的评定偏误。因此,DMSP/OLS夜间灯光数据是一种优化的方法,本文将应用该数据进行贫困县划分准确度的研究。
(二)数据处理
1.夜间灯光数据提取
美国国家海洋和大气管理局(National Oceanic and Atmospheric Administration,NOAA)在官方网站上公开了1992年至2013年的DMSP/OLS夜间灯光数据。由于同一年份不同卫星、不同年份不同卫星的夜间灯光数据缺乏可比性。因此,下载的原始夜间灯光数据需要进一步处理。首先,利用GIS空间分析技术,采用埃利维奇等和刘志峰等提出的国内外通用处理方法进行数据提取[19-20],根据范子英等提出的方案进行校准,增加数据可比性[21]。然后从国家基础地理信息中心⑧下载来源:http://ngcc.sbsm.gov.cn/。获取全国县级行政边界矢量数据,提取县级行政区划单位(县级市、市辖区、自治县、旗、自治旗、林区、特区)的行政边界范围,进行掩膜处理[22],最终提取2261个县级行政区域的夜间灯光数据。
2.变量确定
关键自变量:夜间灯光总量(即灯光总强度)和平均夜间灯光强度(即夜间灯光密度)均可反映

式(1)中,A是平均夜间灯光强度(Average Night-time Light,ANL)。T是夜间灯光总强度(Total Night-time Light,TNL),指相应行政区域内的所有像素总值。N是相应行政区域内具有正辐射值的所有像素的个数和。
因变量:以“当年是否属于国家级贫困县”作为本研究的因变量。这是一个二分类变量,即该县当年属于国家级贫困县,记为1,反之记为0。根据研究需要,本文分别选取1994年、2002年、2007年、2012年的国家级贫困县名单①1994年、2002年、2007年、2012年贫困县名单分别来自:《2000年中国农村贫困监测报告》、《2002年中国农村贫困监测报告》、《2007年中国农村贫困监测报告》、国务院扶贫办网站《国家扶贫开发工作重点县名单》(来源:http://www.cpad.gov.cn/art/2012/3/19/art_343_42.html)。进行数据处理。有部分贫困县因行政区划调整而未能成功匹配。我们通过查阅行政区域的历史沿革情况,结合夜间灯光数据的光照面积,逐一认定,填补数据。
3.缺失数据处理
大数据也可能存在不完整的情况,如表2所示,缺失灯光数据的贫困县个数约占总贫困县数的6.4%(38个缺失值)或7.6%(45个缺失值)。缺失数据的存在会造成信息减损,因此在有条件的情况下都应尽量采用合理有效的方法进行处理。在本研究中,造成有些国家级贫困县缺失夜间灯光数据的原因是国家基础地理信息中心公布的县级行政边界矢量数据采用的是北京54坐标系(BJZ54),大比例尺地图反映地面的精度受到影响,在切割区域时存在一定误差。不过,这种数据缺失的概率与其本身的灯光值无关,属于随机误差。为了研究需要,我们尽可能保持数据的完整性。因此将采用插补方法对缺失数据进行处理。这种方法的基本原理是按照某一合理的猜测方式进行插补或替代缺失数据,然后在没有缺失数据的情况下进行分析[23]。区域的社会经济发展状况。本研究沿用王汶等人和余柏蒗等人的做法,采用县级行政区域的平均夜间灯光强度作为关键自变量[14]1256,[15]1222。平均夜间灯光强度的计算方式如下:

表2 夜间灯光数据与国家级贫困县匹配情况
本研究具体选择最近邻插补法进行缺失值填补。它是一种热卡插补法,其以不含缺失值的变量为辅助变量,寻找离填补数据最近的辅助变量的数据进行插补[24]。这一方法恰好可以结合贫困县所处的空间地理位置进行使用。即用所有与之相邻的行政区域的平均夜间灯光强度之和除以相邻行政区域的个数,求得插补的贫困县灯光数据。
(三)检验方法
根据我国各阶段扶贫开发的评定标准,本文对四个关键时点下的贫困县名单分别进行检验。如表1所示,选用1992年、2001年、2006年的平均夜间灯光强度,以及2007至2009年平均夜间灯光强度的三年均值,分别检验1994年、2002年、2007年、2012年国家级贫困县划分的准确度。主要采用两种方法进行检验:一是全国总体性检验,从总体角度了解各县级行政区的平均夜间灯光强度差异;二是针对各省贫困县配额,分省进行检验,目的在于了解省内各县级行政区的平均夜间灯光强度差异。
全国检验:将各县平均夜间灯光强度由低到高进行升序排列。以第592位为临界线②国家级贫困县总数为592个,因此以平均夜间灯光强度升序序列的第592位划设临界线。,划分出1至592位为弱夜间灯光密度区域,其余为非弱夜间灯光密度区域。如果贫困县落在弱灯光密度区域,则表示该县被划分为贫困县是准确的。如果贫困县落在非弱灯光密度区域,则表示从全国范围来看该县被划分为贫困县可能是不准确的。
分省检验:根据管理办法提出评定方式①《国家扶贫开发工作重点县管理办法》指出,国务院扶贫开发领导小组确定贫困县的原则、标准和各省(自治区、直辖市)可申报贫困县的数量,然后,各省(自治区、直辖市)确定省内具体贫困县数量和名单,最后,各省向国务院扶贫开发领导小组申报并审核备案。国务院扶贫办.国家扶贫开发工作重点县管理办法.中国政府网.2010- 02-23/2018- 02-09.http://www.cpad.gov.cn/art/2010/2/23/art_46_72441.html。,本文对有贫困县配额的省份分别进行检验。具体思路与总体检验相同,唯一的区别是分省检验的临界线是每个省的指标配额数。以其划分弱灯光密度区域和非弱灯光密度区域,检验省内贫困县划分的准确度。
三、夜间灯光数据检验结果
(一)总体检验结果
如表3所示,尽管国家级贫困县名单会有阶段性调整,但是各阶段贫困县落在非弱夜间灯光密度区域的比例超过四成。不过,自2001年颁布管理办法并陆续出台评定细则之后,该比例逐渐减少。综上所述,从全国检验结果来看,国家级贫困县名单的阶段性调整有一定效果,但仍存在一定偏误。

表3 灯光数据总体检验情况
(二)分省检验结果
鉴于省配额的评定方法出台于2001年,本文仅将2002年、2007年、2012年的检验结果进行比较②因篇幅所限,此处省略弱灯光密度区域贫困县数及占比。(参见表4)。
我们有以下几点发现:首先每个省的偏误比例不一。较严重的偏误(高于50%)发生在黑龙江、四川、内蒙古、河南、江西、吉林、青海、安徽等地,其落在非弱夜间灯光密度区域的贫困县比例近一半,甚至更高,如黑龙江省的比例保持在78.6%的高偏差水平。可见,在指定参评的21个省(自治区)中,超过四成的省(自治区)很有可能存在较严重的非精准扶贫情况,这一比例与总体检验的结果大体相同。进一步来看,这些地方分布在东北地区的大部(内蒙古、黑龙江、吉林),以及部分中部地区(河南、安徽、江西)和西部地区(青海、四川)。其次,纵观三年检验结果,每个省落在非弱夜间灯光密度区域的国家级贫困县数(比例)没有明显波动。这说明,每个省的评定结果相对固定,这与我国缺乏动态评估机制可能有关。由此,容易产生贫困县评定的“棘轮效应”[25]。
因此,夜间灯光数据反映了国家级贫困县划分偏误问题,即便贫困概念的意涵包罗万象,但就其最基本的社会经济维度而言,灯光数据检验结果反映出中国贫困县的识别精准度不足。这与我国缺乏指标明确的、信息公开的贫困县进退机制不无关系。那么,导致贫困县精准识别偏差的原因是什么?为什么有的国家级贫困县夜间灯光强度反而较强?这将是本文进一步研究的重点。
四、进一步检验:非弱夜间灯光密度的贫困县
自2001年起,国家明确把扶贫开发对象规定在中西部少数民族地区、革命老区、边疆地区和特困地区的县级行政区域①国务院扶贫办.国家扶贫开发工作重点县管理办法.中国政府网.2010-02- 23/2018- 02- 09.http://www.cpad.gov.cn/art/2010/2/。。“老少边”政策是划分贫困县的又一参考标准吗?还是说存在其他非社会经济性的、非政策性的因素影响评定?本节将以2012年国家级贫困县名单为例,检验影响贫困县划分的因素。
(一)变量说明
在进一步的检验中,我们纳入客观影响因素和主观影响因素两大类解释变量。客观影响因素中的解释变量将参照国家政策意涵[26]选取,将政治因素操作化为“是否属于革命老区县”变量,将民族因素操作化为“是否属于少数民族县”变量,将地理区位因素操作化为“是否属于边境县”变量。变量操作化过程依据国家官方网站的公开信息进行②中国革命老区资料库.中国共产党新闻网.2009-08-04/2018-03-29.http://dangshi.people.com.cn/GB/151935/164962/;国家民委.中国陆地边境县(旗)、市(市辖区)一览表.中国政府网.2006 - 12-31/2018-03-29.http://www.gov.cn/test/2006 07/14/con。,均设为二分变量,属于取1,不属于取0。
主观影响因素是指评定中可能存在的人为干扰因素。本节选择中国共产党第十七次全国代表大会产生的中央委员及候补委员的来源地(即出生地和籍贯地)及工作地进行操作化③中国共产党历次全国代表大会数据库.中国共产党新闻.2018- 03 -29.http://cpc.people.com.cn/GB/64162/64168/index.html。,将来源地或工作地曾是贫困县的取1,反之取0。该届产生中央委员204名,候补委员167名,其中来源地是国家级贫困县的委员有44人,曾在贫困县工作过的有32人①受到信息公开的限制,只收集到230人的工作地信息。。变量说明请见表5。
(二)提出假设
本文的检验分为两个层次,首先是对客观影响因素的检验,即探究“老少边”政策是否会影响贫困县评定。其次是加入主观影响因素进行检验。目前贫困县评定仍是以实地调查、上报统计数据等方式进行,容易存在上报数据失真、名单造假等人为偏误。这种人为偏误是否蕴藏着某种“关系上的照顾”,是值得探究的。据此,笔者提出以下研究假设:
假设1:存在非经济因素影响国家级贫困县的评定。

表5 变量操作化及描述统计
假设1a:相较于非革命老区,属于革命老区的县更有可能评上国家级贫困县。
假设1b:相较于非少数民族地区,少数民族县更有可能评上国家级贫困县。
假设1c:相较于非边疆地区,地处边疆地区更有可能评上国家级贫困县。
假设1d:中央委员和中央候补委员工作生活过的地方更有可能评上国家级贫困县。
另一方面,现实中存在某县具有“老少边”多种属性并存的情况,因此可能产生政策因素的交互影响;也会存在客观影响因素和主观影响因素交互作用影响贫困县评定的可能。所以进一步提出假设:
假设2:“老少边”政策上的照顾和“关系上的照顾”会两两交互作用,影响贫困县的评定。
假设2a:该县既属于革命老区,又是少数民族县,则更有可能评为国家级贫困县。
假设2b:该县既属于革命老区,又地处边疆地区,则更有可能评为国家级贫困县。
假设2c:该县既是少数民族县,又地处边疆地区,则更有可能评为国家级贫困县。
假设2d:该县既属于革命老区,又是中央委员和中央候补委员工作生活过的地方,则更有可能评为国家级贫困县。
假设2e:该县既是少数民族县,又是中央委员和中央候补委员工作生活过的地方,则更有可能评为国家级贫困县。
假设2f:该县地处边疆地区,又是中央委员和中央候补委员工作生活过的地方,则更有可能评为国家级贫困县。
在下文,我们将通过数据分析对这两大假设进行检验。
(三)模型选择
本文将通过两种方式进行模型检验:一是总体检验。这种方法下,样本数据包含参评贫困县的21个省(自治区、直辖市)的数据,即有省级和县级两个层次的资料,故使用多层次模型进行检验;二是区域检验,具体采用二分类Logistic回归模型检验我国四大经济区域的贫困县评定情况。
1.总体检验模型
鉴于以下原因,本研究采用多层非线性模型。第一,从实际评定方式来看,评定贫困县采用的方法是国家规定各省(自治区、直辖市)贫困县申报名额,省内评定具体贫困县名单,再向国家备案。可见,最终每个县是否能被认定为贫困县,无疑会受到省级行政单位的制约;换言之,省级行政单位可能是因变量变异的一个重要来源。第二,从使用的数据来看,处理出的数据包括省级和县级资料,同一个省在评定本省贫困县时,省内各县可能会有关联性,这将违背样本间必须独立的统计学原则。与此同时,本文通过建立一个只包含因变量和分层变量标识的空模型,检验群间差异对因变量变异的显著性,从模型上判定是否需要使用多层模型。结果显示,总体上是否能评定为贫困县因省和县而异。因变量在省的变异(o2的系数为0.552,标准误为0.102)十分显著,表明省内不同县的贫困县评定相互关联。采用多层模型技术,在模型中纳入省这一随机变量将改善模型的适合性,获得精确的参数估计。同时,省间的关联系数(ρ)为0.144①统计上规定,当ρ>0.059时,表示高层次因素对因变量的作用越大,需要使用多层模型。,表示14.4%的可变性来自群间变异即省,85.6%的变异来自群内变异即县。换言之,省和县因素对因变量都起到重要作用,但县本身的特征更重要。
因此,数据来源、数据性质以及初步模型诊断结果均表明需要采用多层非线性模型。其中,县级行政单位为第一层,省级行政单位为第二层,第一层寓于第二层中。另外此处采用随机截距模型,假定因变量变异均源于第一层,即各县对评定贫困县的影响不因省而异。
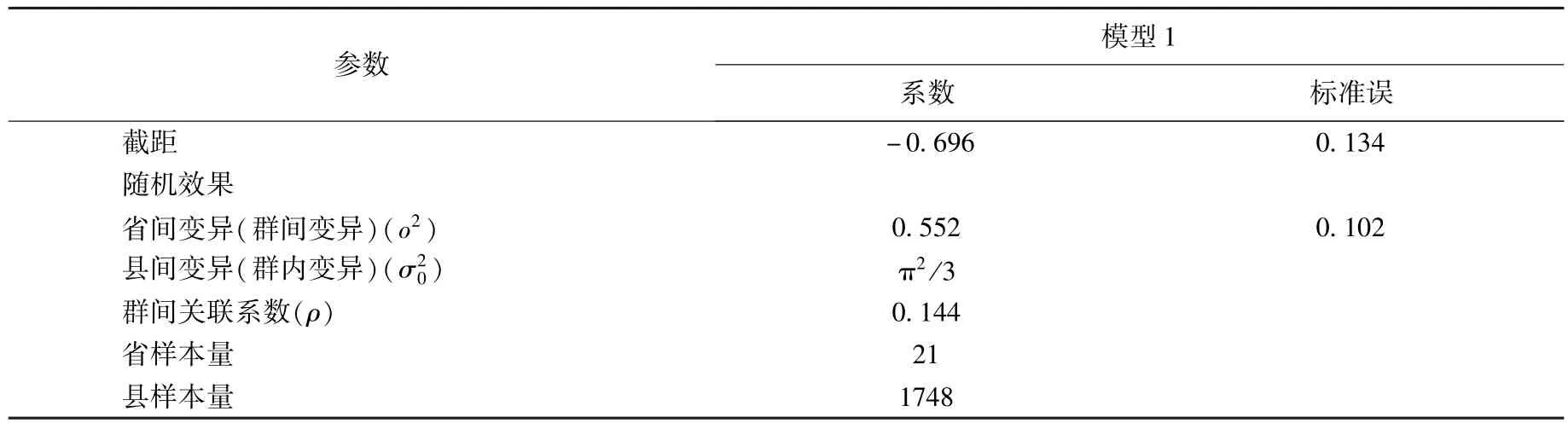
表6 总体检验评定省份无条件平均模型分析结果
2.分地区检验模型
夜间灯光数据检验中发现每个省的偏误比例不一,异常程度较严重的省(自治区)集中在东北地区和部分中西部地区。因此我们将按照地区特点来划分21个参评省,分别分析每个地区的贫困县评定的影响因素。通过多层模型的无条件平均模型检验发现,随机效应不显著,说明因变量不会随群而产生不同,因此分析中不宜选择多层模型。与此同时,本研究中的因变量“该县是否属于国家级贫困县”是一个二分变量,因此我们使用二分类Logistic回归模型进行分析。
(四)总体检验分析
总体来看,社会经济因素是重要的评定参考因素。从表7可以看出,在控制其他因素的前提下,均呈现显著负相关,说明平均夜间灯光强度越弱,越可能被评为国家级贫困县。这反映了两点意义:一方面这一检验结果与现实相符,平均夜间灯光强度较低意味着夜间亮灯少,可能是由当地经济水平较低、社会发展水平较弱造成的;另一方面说明夜间灯光数据具有一定现实意义,是社会经济指标的良好代理变量。
除此之外,从模型2可见,民族因素正向显著,即少数民族地区的县更有可能评上国家级贫困县。具体而言,在控制其他因素的前提下,少数民族县要比非少数民族县评上贫困县的几率高53%左右(e0.426-1≈0.531 1,p<0.05)。假设1b得到支持,而假设1的其他分假设均暂时没有得到充分的证据支持。
模型3至模型8呈现了影响因素两两作用的交互效果。只有交互模型6中交互项对因变量有显著正向影响(p<0.01),即加入政治因素和领导人因素的交互项(革命老区×有领导人)。假设2d得到数据支持。具体而言,在控制其他因素的前提下,评定国家级贫困县时,领导人的“关系上的照顾”作用在革命老区表现得更为明显;即与非革命老区且无领导人关联的地区相比,如果该县既是中央委员或候补委员曾经生活工作的地方,又是革命老区的话,评上国家级贫困县的几率更大。另外,模型6的拟合程度最优(Wald chi2=172.21,最大)。所以说,虽然革命老区在国家扶贫政策辐射范围内,但其可能存在非经济的、非政策性的主观因素干扰,影响国家级贫困县的准确划分。
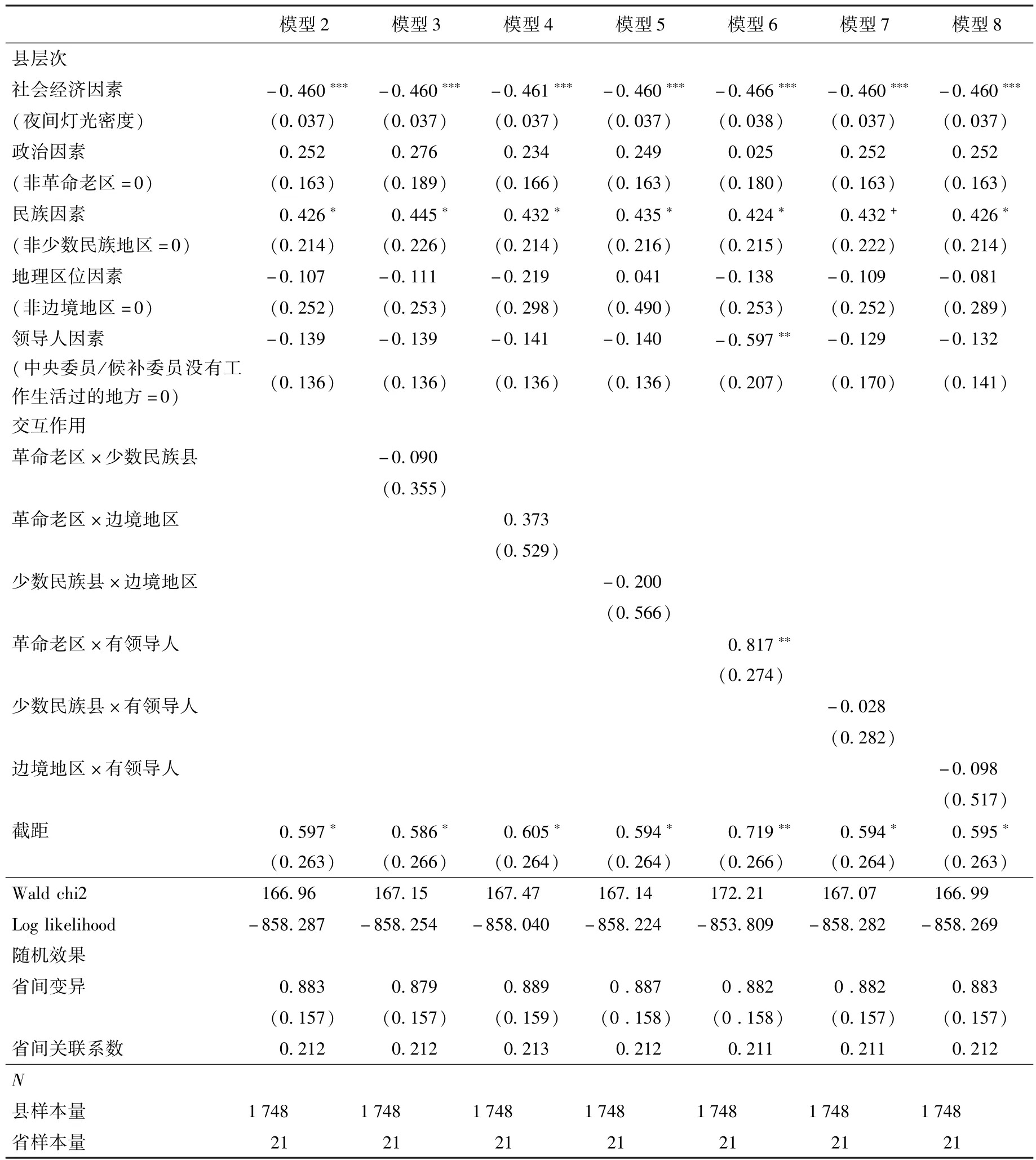
表7 总体检验:影响贫困县评定的因素
除假设2d外,假设2的其他分假设暂时没有找到有力的数据支持。但是,尽管其他交互模型的交互项没有显著性,模型中的民族因素均有显著正向影响。比如,在模型3中,在控制其他因素的前提下,在非革命老区,少数民族县要比非少数民族县评上贫困县的几率高56%(e0.445-1≈0.561,p<0.05)。在模型5中,在非边境地区,少数民族县评上贫困县的几率大约是非少数民族县的1.5倍(e0.435≈1.545,p<0.05)。在模型7中,在无领导人关联的地区,少数民族县要比非少数民族县评上贫困县的几率大约高54%(e0.432-1≈0.5403,p<0.10)。可以发现,民族因素是评定贫困县的重要参考因素之一。这与我国是一个历史悠久的、统一的多民族国家有着密切联系,长期以来我国注重民族平等、民族团结,以及各民族的共同发展,因此在政策上也会体现出对少数民族同胞的关怀。
综上所述,通过总体检验发现,国家级贫困县评定不但会考虑社会经济因素,还会纳入少数民族因素。另外,既是革命老区又是中央委员或候补委员曾经生活工作的地方,相较于非革命老区且无领导人关联的县,评上国家级贫困县的几率更大。这是一种非经济的、非政策性的人际干扰因素,可能是夜间灯光检验国家级贫困县的偏差来源。
(五)分地区检验分析
从夜间灯光检验结果得知,贫困县划分偏误存在地域特征。本节选取我国的经济区域特征为划分标准,将含有国家级贫困县的21个省(自治区、直辖市)分为西部地区、东北地区、东部地区、中部地区。
从表8可得,社会经济因素显著负向影响评定,即在控制其他因素的前提下,平均夜间灯光强度越低,越可能评为贫困县。不过,政策因素和“关系上的照顾”则在不同地区起到不同作用。首先看西部地区,从模型9可见,假设1均没有得到数据支持。模型10中,当放入交互项(革命老区×少数民族县)时,政治因素呈显著正相关,假设1a得到数据支持。表明在控制其他因素的情况下,对于非少数民族县,属于革命老区的县会比非革命老区县评上的几率高约78%(e0.578-1≈0.782,p<0.05)。模型11中,交互项(革命老区×有领导人)呈显著正相关,说明在控制其他因素前提下,评定国家级贫困县时,相比于非革命老区且无领导人关联的地区,既是中央委员或候补委员曾经生活工作的地方又是革命老区的县,评上国家级贫困县的几率更大。假设2d得到数据支持,即对革命老区的照顾和领导人“关系上的照顾”会交互作用,影响贫困县的评定。
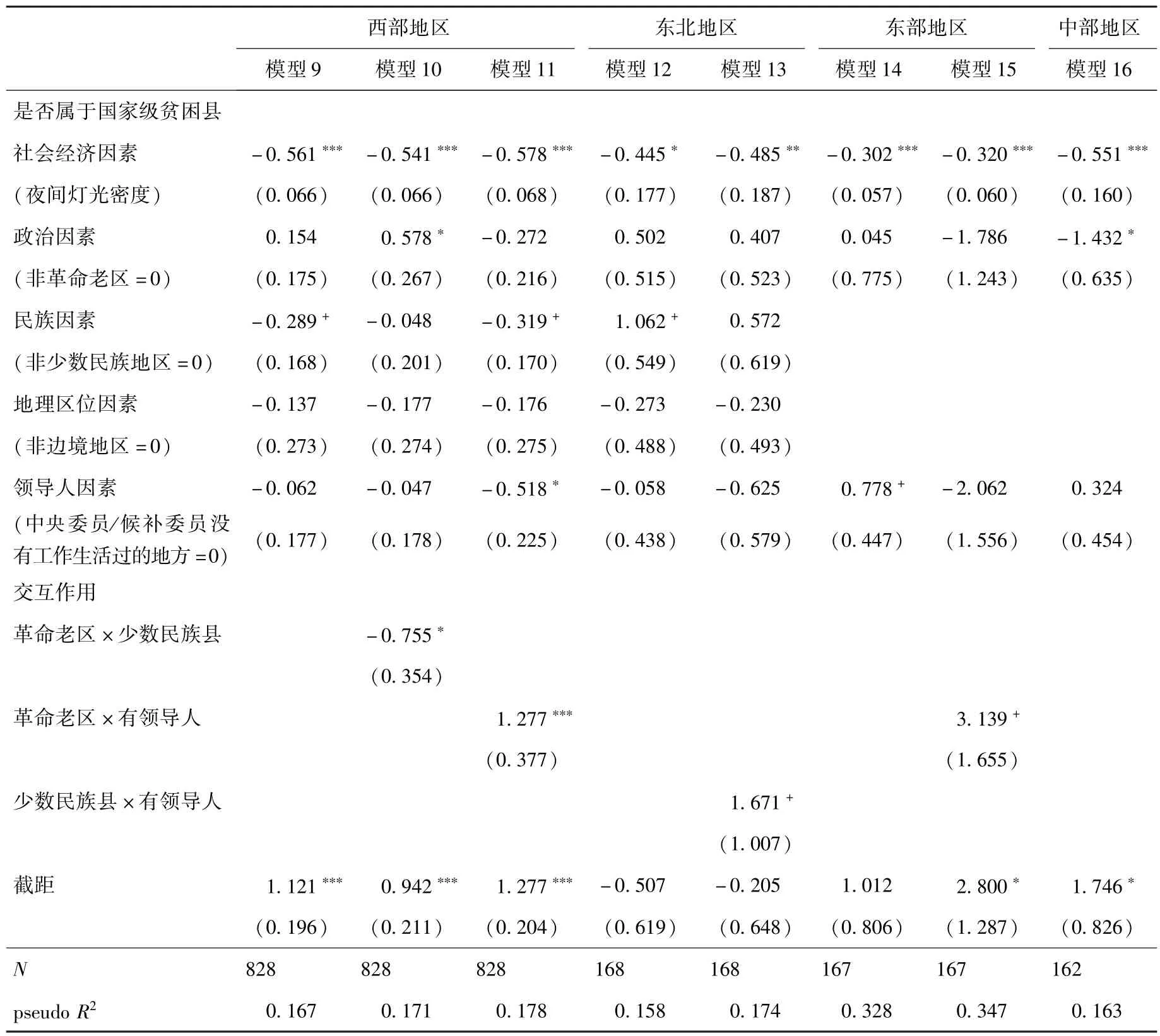
表8 地区检验:影响贫困县评定的因素
接下来看东北地区,模型12中少数民族因素呈显著正相关,假设1b得到支持。这说明在控制其他因素的情况下,少数民族县评上贫困县的几率是非少数民族县的3倍左右(e1.062≈2.892,p<0.10)。可见在东北地区,是否在少数民族地区会一定程度上影响贫困县的评定。当放入交互项(少数民族县×有领导人),其正向显著,表明在控制其他因素的情况下,既是中央委员或候补委员曾经生活工作的地方又是少数民族县相较于无领导人关联的地区且不是少数民族的县,评上贫困县的几率更大;也就是说,评定贫困县会受到民族因素和领导人因素的交互影响。
再来看东部地区,从模型14可见,控制其他因素的情况下,领导人因素对因变量的正向显著影响,即相较于无领导人关联的地区,在中央委员或候补委员曾经生活工作的地方越有可能被评上贫困县,几率大约是前者的2倍(e0.778≈2.18,p<0.10),假设1d得到数据支持。在模型15中,交互项(革命老区×有领导人)呈显著正相关,表明在控制其他因素前提下,评定国家级贫困县时,相比于非革命老区且无领导人关联的地区,既是中央委员或候补委员曾经生活工作的地方,又是革命老区的县,评上国家级贫困县的几率更大,假设2d得到支持。由此可见,无论是直接作用还是交互作用,领导人因素在东部地区的贫困县评定中起到重要的影响。最后看中部地区,交互检验均不显著,假设2均没有得到数据支持。
综上所述,无论在哪一地区,经济因素都是贫困县评定中最主要的影响因素。政策性因素呈现出地区特点,比如在少数民族较聚集的西部和东北地区,少数民族因素的作用较为凸显,而东、中部的作用基本不明显;西部和东部地区受到革命老区的政策影响较为突出,这与革命老区的分布存在一定联系。最后值得关注的是领导人因素,这一非经济的、非政策性的主观影响因素与政策因素产生交互作用,对贫困县的评定产生干扰。
五、结论与讨论
中国的贫困县划分准确吗?本文应用夜间灯光数据检验贫困县划分的准确性,并通过计量模型检验贫困县评定的影响因素,得到以下几点结论:
第一,夜间灯光数据可以科学、有效地评估中国贫困县划分的问题,以平均夜间灯光强度为代理指标的经济因素是影响贫困县评定的重要因素。
第二,应用夜间灯光数据检验出国家级贫困县划分存在缺乏精准度的问题。三个阶段的检验结果均显示出落在非弱夜间灯光密度区域的贫困县比例超过四成。其中,偏误较严重的县主要集中在东北地区和部分中、西部地区。
第三,国家级贫困县评定不仅会考虑社会经济因素,还会纳入少数民族和革命老区的政策性因素;同时也会存在领导人因素的干扰,即该县如果是中央委员和候补委员工作生活过的地方,评上的几率会有所增大。总体检验和分地区检验涉及到的影响因素大体相同,但影响因素的作用机制有所不同。具体而言,在总体检验中,经济因素、少数民族因素以及革命老区和领导人因素交互对贫困县划分产生影响;在地区检验中,除了以上三个因素之外,革命老区因素及其与少数民族因素的交互、领导人因素及其与少数民族因素交互也会对贫困县划分产生影响。不同地区影响方式不同,具体请参见表9。
我们认为,国家级贫困县的评定要尽可能客观、科学、合理。本文使用的夜间灯光数据是一种有效评估贫困的可用工具,它不仅可以检验贫困县划分的准确性,还可以成为检验扶贫效果的客观指标。夜间灯光数据作为一种通用的监测数据,可以便捷地从国际官方网站获得。这种公开透明的数据有助于增强评估的公开性、透明性,促进对扶贫开发项目的有效监督;有助于减少人力成本,精简繁琐的评审工作;有助于排除评定过程中的人为干扰,避免人际关系的强烈影响,杜绝统计数据等上报资料的弄虚作假;有助于建立动态的贫困县进退机制,及时有效地调整贫困县划分,提高国家治理能力。
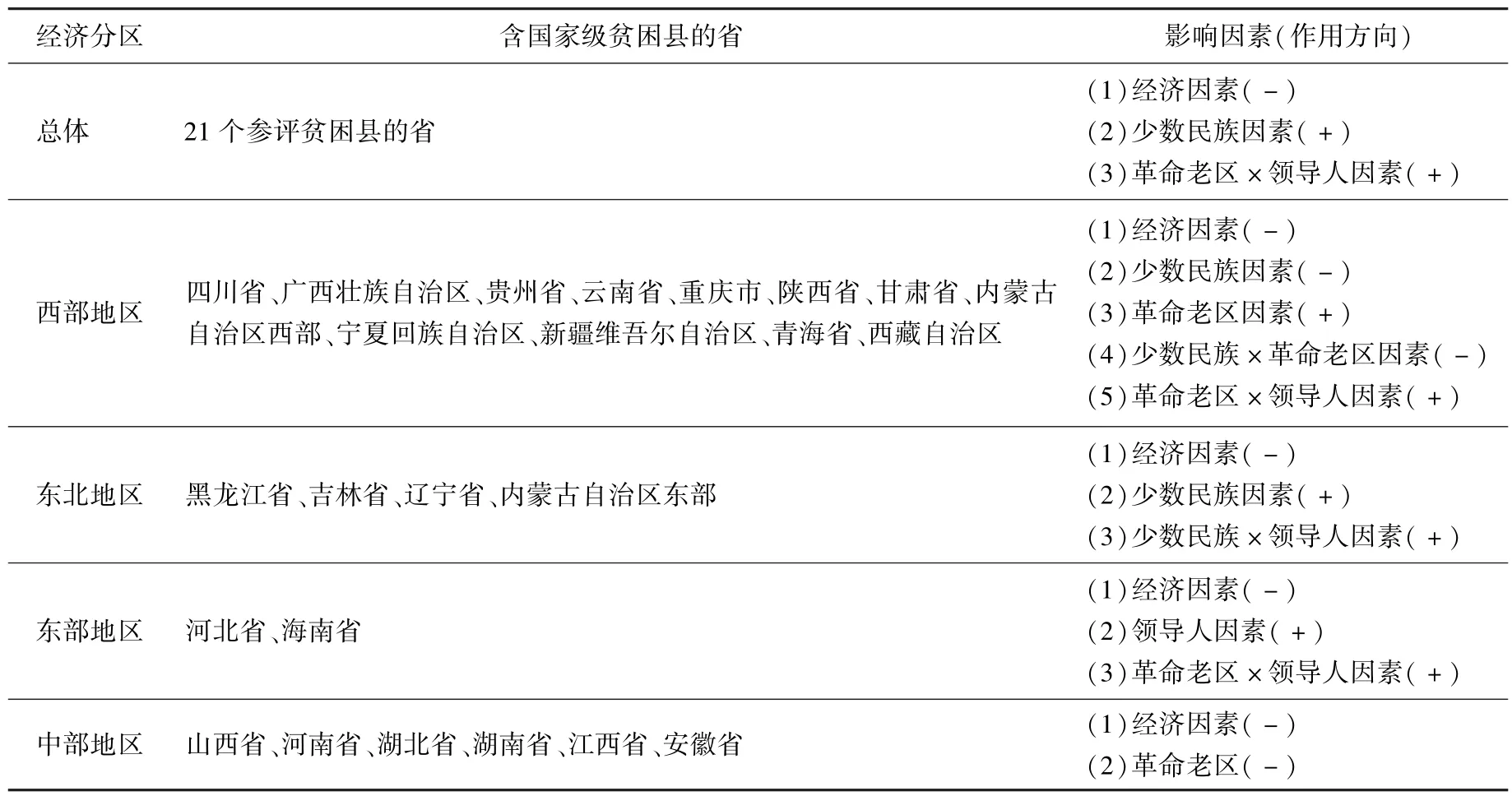
表9 影响贫困县评定的因素
猜你喜欢
娃娃乐园·综合智能(2023年1期)2023-02-18 03:14:54
心声歌刊(2021年4期)2021-10-13 08:31:38
小哥白尼(神奇星球)(2020年6期)2021-01-18 05:04:08
今日农业(2020年23期)2020-12-15 03:48:26
今日农业(2020年22期)2020-12-14 16:45:58
红土地(2019年10期)2019-10-30 03:35:10
今日农业(2019年10期)2019-01-04 04:28:15
中国报道(2018年11期)2018-12-22 07:04:22
红土地(2018年9期)2018-02-16 07:37:56
中国老区建设(2016年12期)2017-01-15 13:53:58
