
基于改进Faster R-CNN算法的舰船目标检测与识别
2018-11-07 13:36赵春晖
沈阳大学学报(自然科学版) 2018年5期
赵春晖, 周 瑶
(哈尔滨工程大学 信息与通信工程学院, 黑龙江 哈尔滨 150001)
我国作为领土大国和军事强国, 海洋领土的安全不容忽视, 海面军事能力是我国作为军事强国的一种体现, 所以我国要对港口和海面进行监控. 本项目将通过对舰船图像识别, 达到作战力量评估、作战力量侦察、监控敌方战场动态、敌我海上态势的分析、监控敌方港口及舰船信息、战场力量分析、预估战斗结果等目的.
在图像检测与识别领域,传统的图像识别方法都是人为的设计目标的特征[1-2],这样工作量很大并且识别效果不好.随着科技的进步,通过深度学习方法对图像进行目标检测与识别[3],日益为人们所使用.深度学习框架能够通过卷积神经网络对训练图像学习,自动的从图像中提取出目标的特征,学习能力强且识别速度快、精度高[4].所以本文中应用了Faster R-CNN算法对舰船目标图像进行目标检测与识别,Faster R-CNN算法虽然创新性的使用了区域建议网络,但是算法的运行速度仍然不够快,这是由于区域建议网络在最后的特征图层的每一个元素的对应位置生成了9个不同大小和尺寸的区域框,这里的区域框的尺寸和比例都预先设定好,并没有根据数据集中目标的大小而改变,所以训练和检测的速度都会相对较慢.在本文中,引用了K-Means聚类算法[5],对训练集中的目标框的大小进行聚类分析,得出图像中的目标框的几种不同尺寸,用这几种尺寸代替原本算法中设定好的9个区域框,使得Faster R-CNN算法框架能够更快地收敛,并更快地检测出目标框.
1 Faster R-CNN算法介绍
Faster R-CNN算法的框架如图1所示,前段的几层为VGG16[6]的13个卷积层,13个relu层和4个池化层,通过这些层来获取图像的特征图[7](Feature Maps),然后Faster R-CNN算法创建了区域建议网络来生成候选区域框(即Proposals),随后再使用感兴趣区域池化[8](Region of Interest Pooling,即ROI Pooling)从经过VGG16得到的特征图中获得各个候选区域的特征表达,最后用Softmax分类器[9]进行分类,并且使用包围盒回归[10](B-Box Regression)及非极大值抑制[11](Non-maximum Suppression,即NMS)进行最后的处理,得到最终的前景目标框.

图1 Faster R-CNN算法结构框架Fig.1 Block diagram of Faster R-CNN algorithm
1.1 区域建议网络
传统的深度学习算法提取候选区域都是通过选择性搜索(Selective Search,即SS),这样产生候选区域较慢并且较多,而且有很多是相互重叠的,增加了算法的运算量,为了减少一些不必要的计算,Faster R-CNN算法创新性的提出了一种区域建议网络(Region Proposal Network,即RPN)来代替原本的选择性搜索网络.如图1中的RPN部分,首先,将整张图片输入算法框架, 得到经过一系列卷积和池化操作后的特征图,将这个特征图作为RPN网络的输入,将卷积后的特征图的点与原图片的位置进行对应,每一个特征图上的元素对应9个不同尺寸和大小的包围盒.RPN本身具有两个卷积网络,其中一个卷积结构通过1×1的卷积核进行18维的卷积运算,判定该包围盒(即anchor box)是否为前景图像;另一个卷积结构通过1×1的卷积核进行36维的卷积运算,得到该包围盒对于Ground Truth(即GT)的相对位置坐标dx(A),dy(A),dw(A),dh(A).
其中每个特征图元素对应的9个包围盒的设定方法为:将卷积后的特征图的点与原图片的位置进行对应,将特征图上的每一个点都映射到原图上(每一个像素点设定为一个“锚点”),每一个锚点上放若干个大小不同的“锚”(也就是后续所说的包围盒),一般使用的尺度为1282、2562和5122,并分别采用1∶1,1∶2,2∶1三种不同的宽高比,一共9种.
在RPN中的Proposal层, 输入分别为im_info、经过分类器后的分类结果、以及经过包围盒回归后的相对位置坐标dx(A),dy(A),dw(A),dh(A),通过这3个输入值,将前6 000个前景图像经过包围盒回归、非极大值抑制等筛选手段,得到300个回归到原图的候选区域,并且每个候选区域输出4个值(分别为得到的候选区域的左下角与右上角的横纵坐标).
1.2 感兴趣区域池化
Faster R-CNN算法通过进一步改进SPP-Net算法, 提出了感兴趣区域池化(Region of Interest Pooling, 即ROI Pooling), 感兴趣区域池化是空间金字塔池化的一个简化版本, 即只有一层金字塔, 也就是感兴趣区域池化只包含一种尺度. 经过多个实验证明, 通过ROI进行图像处理, 比原有的R-CNN算法运行速度加快数十倍.
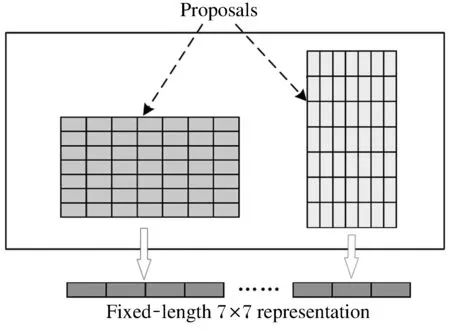
图2 感兴趣区域池化原理图Fig.2 Schematic diagram of ROI pooling
将候选区域映射到特征图上的位置,然后将每一块的水平方向和垂直方向都分成7份,然后对每一个分出来的块都进行最大值pooling,在这样的处理之后,输出结果都是7×7的大小,就可以实现固定大小的输出.
1.3 分 类
分类部分得到的特征向量,经过全连接和softmax进行计算和分类,看每一个区域属于哪一个种类,并且输出属于这个种类的概率为多少.然后再次通过包围盒回归,得到这个区域与真实的GT位置的偏移量,用于之后的回归,使得目标检测框更加接近真实位置.
分类的全连接层的计算公式如下:
(1)
可见分类的全连接层的输入向量的长度是固定的,这也验证了感兴趣区域池化的重要性.
1.4 非极大值抑制
非极大值抑制算法(Non Maximum Suppression,即NMS)在很多计算机视觉方向都有应用,比如边缘检测和目标检测.在分类器进行分类之后,会有很多被确定为正样本的候选区域框,会有大量的候选区域集中在目标的周围,他们之间有一定的重合,所以通过使用非极大值抑制方法来解决这个问题.非极大值抑制的本质就是将局部范围内的最大值挑选出来,对不是极大值的元素进行抑制.我们以舰船检测为例,如图3所示.
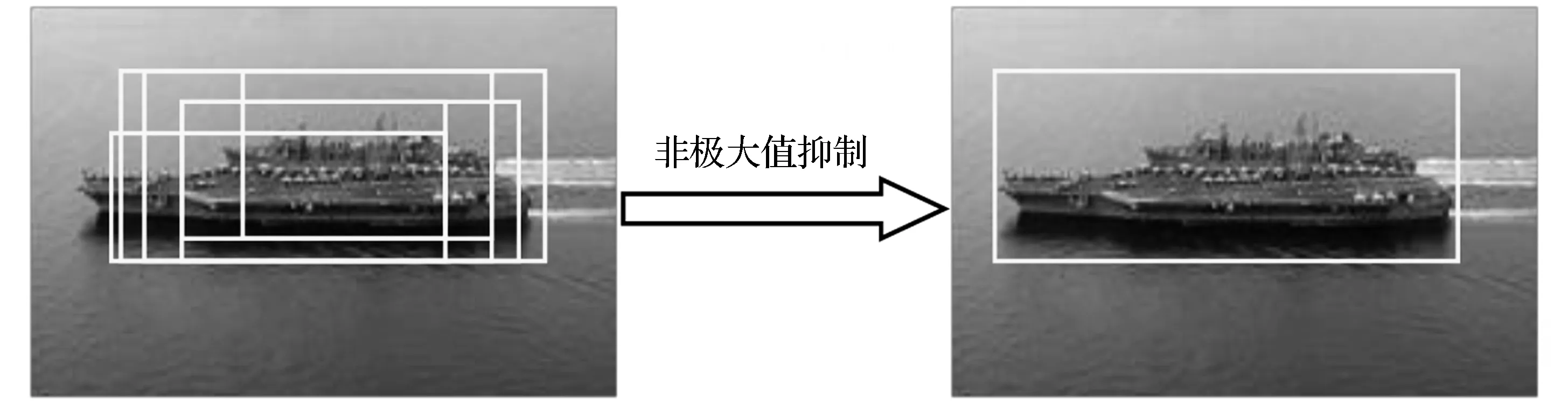
图3 检测窗口模型Fig.3 Detection window model
非极大值抑制算法的运算步骤如下:
(1) 将所有的框的得分进行排序,选出最高分的框.
(2) 再对剩余的框进行遍历,同时设定一个阈值,其他的框与这个最高分框的IOU值大于这个阈值时,就将这个框删除.
(3) 从未处理的所有框中,再选择一个得分最高的,然后重复前2个步骤.
经过上面所述的3个步骤,基本可以达到只留一个最优框的目标.
2 本文方法
2.1 数据集的采集与制作
K-Means聚类算法是一种典型的无监督学习算法,主要用于将样本(n个)通过运算归到k个类别中.其算法框架如图4所示.
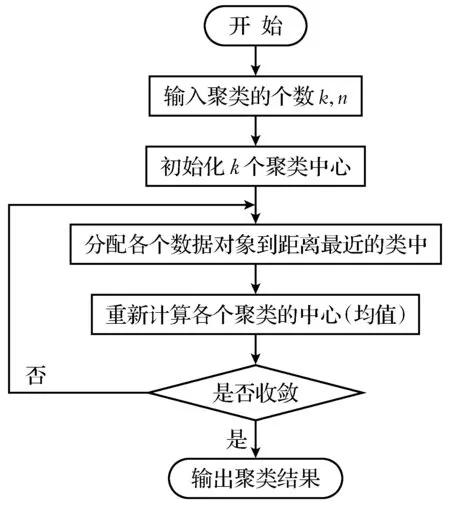
图4 K-Means算法原理框图Fig.4 Schematic diagram of K-Means algorithm
K-Means算法[12]的运算步骤为:
(1) 首先输入n个样本,并且设定分出的种类数k,随机的从n个样本中抽取k个点作为第一次聚类的中心点.
(2) 再将n个样本与k个聚类中心的距离计算出来,并将这n个样本进行分类(每个样本都属于与聚类中心距离最小的的那一类).
(3) 并将每一个类的所有样本计算出平均值,得到一个新的聚类中心,设定一个准则函数,并重复上述步骤,直到得出的结果符合这个准则函数,得到最终的聚类结果.
2.2 本文方法步骤
Faster R-CNN算法虽然相对于传统方法有很大程度上的检测速度提升和检测精度的提高,但是仍然有不足之处,传统的Faster R-CNN算法生成的包围盒个数较多,且对不同的数据集,本文提出通过K-Means聚类算法对包围盒的尺寸重新设定.本文中所提出的方法的具体运算步骤为:
(1) 对全部训练集进行标签[13]标定,并以.xml文件的形势进行保存.
(2) 读取.xml文件中所有目标(不分种类)的左下角与右上角目标,做差可以得到目标框的大小,以此作为K-Means聚类算法的输入,对数据集中的目标框大小进行,本文通过实验分析对应本文数据库,应取5类.
(3) 将5个聚类中心输入传统Faster R-CNN框架中,设定为包围盒初始大小,通过前文所属进行训练.
(4) 通过测试集图像对训练好的框架进行检测,使用传统的Faster R-CNN算法对相同的测试集图像进行检测,比较结果.
4)管材装运:装箱时不能采用钢丝绳吊装,不得抛、摔、滚、拖,装箱高度不宜超过2m,并且集装箱箱两端应该有填充物填充密实。
3 实验分析
3.1 数据集的采集与制作
本文在线采集了一定量的舰船数据图像制作数据集,采集图像分辨率为1 200×966,如图5所示的军舰和民船图像,其中80%的图像作为训练集图像,剩余的20%的图像作为测试集图像.

图5数据集图像
Fig.5 Data set image
图像中目标的标定,就是在含有目标的图像上人工将目标的外接矩形框标出并记录坐标位置和类别,这个目标的位置和类别以标签的形式保存下来,将在算法框架中被调用.如图6所示为通过labelImg对图像中的目标制作标签:
设定标签的保存位置,然后人工框出目标的位置框并将该框属于何种目标选择出来,最后点击Save键,则生成的标签将以.xml文件的形式保存在你预先设定的标签存储位置.注意此处的所有图像的命名方式都为6位数字名称(如000001.jpg),生成的标签在保存时也会保存为与图片名称相对应的.xml文件.在.xml文件中包含图片中标定的目标的所属种类〈object〉-〈name〉、目标的左下角〈xmin〉〈ymin〉及右上角坐标〈xmax〉〈ymax〉以及图片读取位置〈path〉等信息,这些信息都将会在本文方法中进行调用.
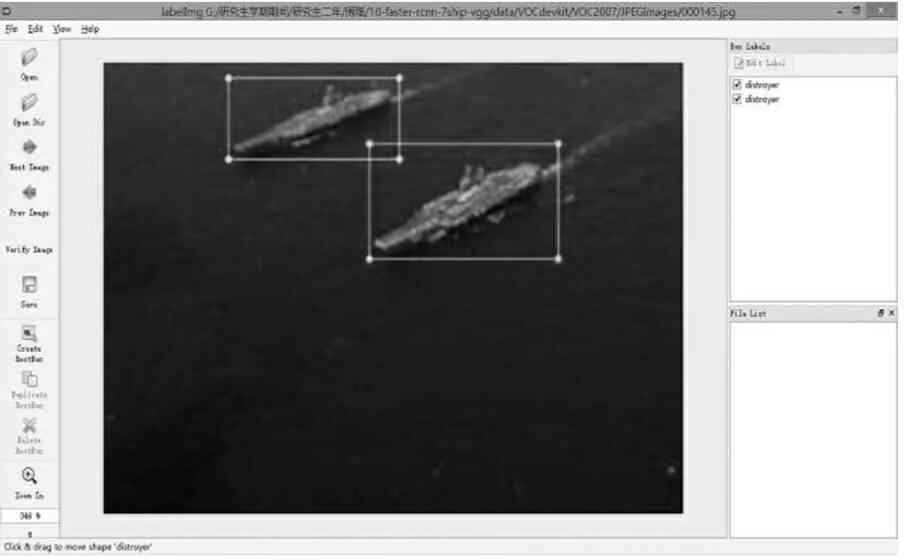
图6使用labelImg制作标签
Fig.6 Using labelImg to create labels
3.2 包围盒尺寸的选取实验
本文所用的方法首先将所有输入图像的目标进行标签的制作之后,得到了前景目标[14]的所有GT框的坐标,通过读取.xml文件中的目标的左下角〈xmin〉〈ymin〉及右上角坐标〈xmax〉〈ymax〉,通过计算可以得到GT框的大小,这就是本文应用K-Means聚类算法的n个样本,设定K-Means聚类算法的准则函数为:
(2)
在本方法中设定J=0.01,通过几次试验,分别令k=2,k=3,k=4,…,得到如下的结果图7.

图7 K-Means算法聚类结果图Fig.7 K-Means algorithm clustering result(a)—k=2; (b)—k=3; (c)—k=4; (d)—k=5.
从图7可以看出,相对于k=2,k=3,k=4这3种情况来说,认为k=5为最适合的种类数,能够将数据集更好几乎均匀的分为5种不同的尺寸.种类数过少或过多,都无法得到较好的训练结果,并且过多时训练时间较长.当选择分为5类时,可以得到如图7的结果,并将得到的5个聚类中心的坐标值输入Faster R-CNN算法,作为每个特征图元素对应的包围盒的大小.
3.3 Faster R-CNN算法框架的训练
为了验证算法的有效性及并行优化后的高效性,建立实验仿真环境:CPU处理器为i7四代处理器,固态硬盘250 G,内存为16 GB,GPU处理器为NVIDIA 1080 ti.实验平台为Ubuntu 14.04.
Faster R-CNN算法有2种训练方式,本文采取的是交替训练的方式,这种方法虽然更为繁琐,但是得到的结果可靠性更强.其中将原Faster R-CNN算法中每个特征图元素自动生成9个包围盒的大小更改为通过前文中的K-Means算法得到的5个聚类中心的坐标值,然后进行训练,训练的步骤如下.
(1) 使用迁移学习的方法,利用ImageNet数据集已经训练好的参数对网络进行初始化,然后独立训练RPN网络,设置训练次数为2 000次.
(2) 将第1步所产生的候选区域作为输入图片,训练一个Fast R-CNN网络,到此之前还没有任何一层的参数被公用,设置本步骤的训练次数为1 500次.
(3) 再通过使用上一步中所训练出来的Fast R-CNN网络的参数,重新训练一下RPN网络,但是保持RPN网络和Fast R-CNN网络所共享那些卷积层的参数,只令RPN网络所特有的卷积层重新训练设置训练次数为2 000次.
(4) 保持RPN网络和Fast R-NN网络所共享那些卷积层不变,只微调Fast R-NN网络所专门有的那几层的参数,最后达到快速准确的检测和识别图像的功能,设置训练次数为1 500次.
如图8为Faster R-CNN算法和本文算法对于相同的训练集图像的损失函数随着训练次数的增加数值的改变,其中蓝色折线为传统Faster R-CNN算法的训练结果,红色折线为本文算法的训练结果.其中每一种折线都有4个较高值,是如上文中所述的每一步训练的初始点.
可以从图8中, 明显的看出,本文算法在训练最一开始的时候的损失函数就较未改进的Faster R-CNN算法值低, 并且能够更快速的收敛到稳定的状态. 这是因为本文中的包围盒大小是对应本文中的数据集设置的, 所以在训练的过程中, 包围盒回归等步骤能够更快的将候选区域调整为与检测目标框相近的位置, 所以本文方法的框架能够有更低的损失函数值, 并且能够更加快速的收敛.
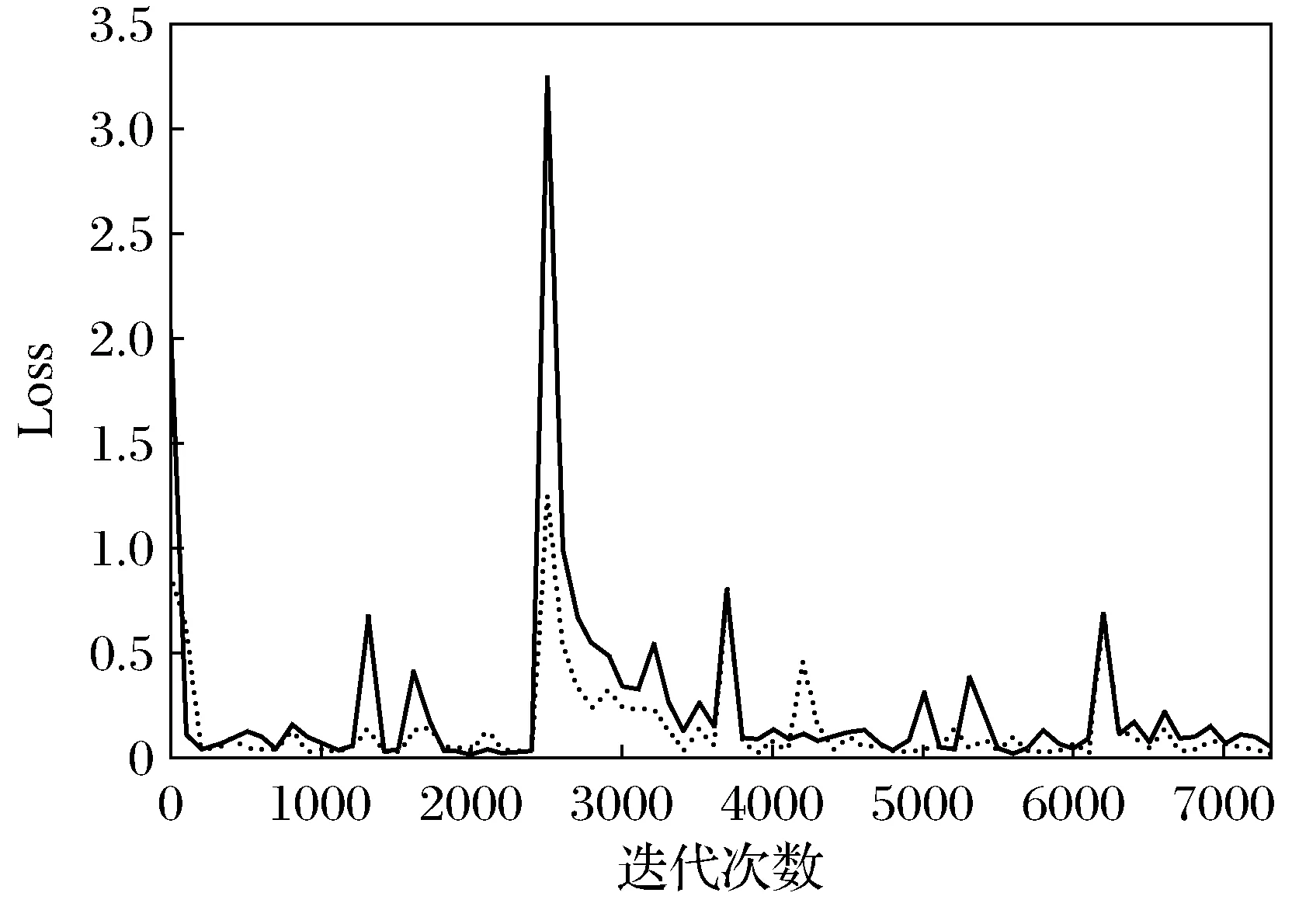
图8 训练的损失函数折线图Fig.8 Loss funtion line chart of training
3.4 检测结果与性能分析
通过前文中的训练方法对改进的Faster R-CNN算法框架进行训练,得到训练好的算法框架,对测试集图像进行舰船目标检测,得到了很好的效果,并输出了目标检测与识别的精度值mAP,以及图像的识别速度.舰船图像目标识别结果图如图9.从图9中明显的看出,前文训练好的框架可以很好的对图像中的目标特征进行提取,并快速的从图像中识别出目标.

图9 本文框架测试图Fig.9 The test result of the proposed method(a)—军舰检测结果; (b)—民船检测结果.
本文通过测试集图像对传统的Faster R-CNN算法框架和本文提出的改进Faster R-CNN算法框架进行了测试,记录了两种方法的检测精度(即mAP值)和两种算法的检测速度,如表1所示.
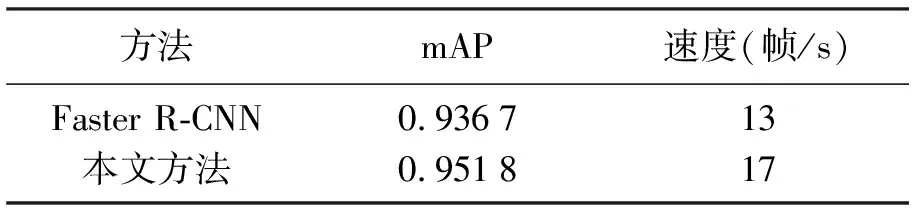
表1 本文框架测试图Table 1 The test result of the proposed method
从表1中的实验结果可以看出来,通过传统的Faster R-CNN算法可以很好的进行舰船图像的目标检测与识别,但是相对来说,目标检测速度较慢,每秒钟只能识别大约13张图片,
通过本文方法对Faster R-CNN算法的改进,可以使得该算法的训练和检测的时间变得更短,这是因为省去了每一个特征图元素对应原图生成9个包围盒的时间,并且通过K-Means聚类算法产生的包围盒大小对本数据集更具有实用性,使得算法中的后续的包围盒回归等步骤能够更快速的进行,从而能够在提升了图像识别速度的同时也提高识别的精度.
4 结 论
Faster R-CNN算法能够很好的通过大量训练数据,自动的提取不同种类舰船的特征,通过训练得到能够快速的进行舰船识别的Faster R-CNN算法框架.
本文通过K-Means聚类算法分别更改聚类种类的个数,综合分析,可以得到较为恰当的前景包围盒的尺寸,应用于Faster R-CNN算法的区域建议网络中,能够使得Faster R-CNN算法网络的学习速度和测试速度加快.并且通过K-Means聚类算法得到的包围盒尺寸与实际物体在图像中的尺寸大小更为相近,这使得深度学习网络学习得更加快速的同时,也对识别的精度有一定的提高.
但是本文的方法有一定的缺点,它不是对所有的数据集都能够自动的进行聚类分析,在本数据集中,K-Means聚类算法将数据集聚为5类,但是更改数据集后,可能聚为10类或20类更佳.并且本文的方法需要人工的将包围盒的尺寸进行更改和输入.综上两点,本方法提高了Faster R-CNN算法的检测速度和检测精度的同时,也需要大量提前的人工准备,这方面的不足之处有待改进.
猜你喜欢
黑龙江大学自然科学学报(2022年1期)2022-03-29
小资CHIC!ELEGANCE(2022年1期)2022-01-11
北京航空航天大学学报(2021年9期)2021-11-02
数学物理学报(2021年1期)2021-03-29
电子制作(2019年13期)2020-01-14
铁道通信信号(2019年6期)2019-10-08
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
