
基于FPGA实现千兆以太网二层交换*
2018-11-07 02:22:16贾婷,胡斌,刘台
通信技术 2018年11期
贾 婷,胡 斌,刘 台
(武汉中原电子集团有限公司,湖北 武汉 430205)
0 引 言
千兆以太网技术是目前局域网的主流解决方案。千兆以太网交换芯片是该技术得以实现的关键芯片。
本文介绍的FPGA实现的千兆以太网二层交换芯片,按照IEEE802.3标准实现了4个独立千兆端口之间的MAC帧交换。以太网二层交换是基于MAC地址工作的,基本工作原理可以概括为“学习查找”和“存储转发”。
设计支持以下功能项:
(1)支持4个10/100/1 000 Mb/s自适应,全双工RGMII端口间的MAC帧线速转发;
(2)每个出端口支持4种优先级队列;
(3)支持基于IEEE802.3xPause帧的全双工流量控制;
(4)支持简单生成树协议;
(5)支持4 096个MAC地址表项和基于Hash算法的自学习和查找。
(6)提供128 kB的MAC帧共享缓冲空间。
本文首先给出FPGA实现千兆以太网二层交换芯片的结构框图;其次,详细介绍设计中关键模块的实现原理;最后,给出设计的功能仿真,验证该设计的可行性。
1 功能概述
1.1 功能框图
FPGA实现千兆二层交换芯片的功能框图,如图1所示。芯片内部核心部分工作时钟为125 MHz,端口可工作在1 000/100/10 Mb/s速率,端口时钟可为125/25/2.5 MHz,因此需要端口帧收发缓存单元来缓存MAC帧。各端口接收到MAC帧后,向共享缓存控制单元发出请求。共享缓存单元公平轮询各端口的请求,为MAC帧分配存储空间,并将MAC帧从端口缓存单元分片存储到共享缓冲区,同时提取帧头信息,进行MAC地址的查找和自学习。将帧存储的起始地址、优先级信息、帧转发类型和目的端口号生成描述符信息,写入目的端口相应优先级的发送描述符队列中。描述符调度单元从各端口发送描述符队列中的调度描述符,按其携带的起始地址,从共享缓冲区读取MAC帧,写入目的端口的帧发送缓存单元,并释放空闲地址;最后,由MAC发送控制器完成802.3 MAC帧的封装和发送。交换芯片结构框图中还包括寄存器单元。用户通过SPI接口访问寄存器单元,可以通过读取寄存器的值了解芯片的工作状态,并通过配置寄存器改变芯片的工作模式。
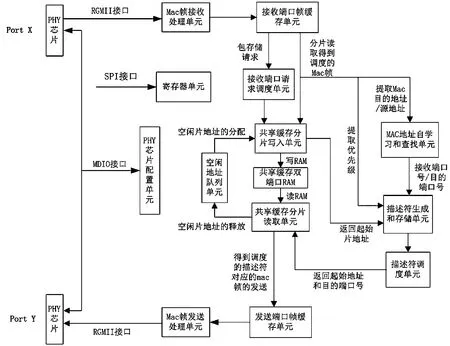
图1 FPGA实现千兆交换芯片功能
1.2 模块划分
模块化设计是FPGA设计中的一个重要技巧。它可以将大规模复杂系统按照一定规则划分成若干模块,然后对每个模块进行设计输入与综合,并将实现结果约束在预先设置好的区域内,最后将所有模块的实现结果有机组织起来,完成整个系统的设计。每个模块本身又可以通过多个子模块来实现,因此模块化设计不仅层次清晰,还有利于模块的复用、移植,更有利于日后的代码升级、维护以及设计的综合优化。根据FPGA设计中的模块化设计思想,结合FPGA软件的功能需求特点,基于以功能为主的原则,对FPGA程序进行如图2所示的模块划分。

图2 模块划分
2 FPGA关键模块实现
2.1 MAC帧收发控制器
图3是IEEE802.3规定的MAC帧格式。前两个字段分别是目的MAC地址和源MAC地址,第三个字段是长度/类型字段。

图3 IEEE802.3 MAC帧格式
数据字段是对上层IP数据报的直接封装,IP头部包含优先级信息。IEEE802.3规定有效的MAC帧长为64~1 518 Byte,因此数据字段长度应为46~1 500 Byte。MAC帧尾部是4 Byte的FCS,即帧检验序列。它采用CRC-32校验码,用以检验收到的帧是否存在差错。
802.3 标准规定,凡出现下列情况之一的即为无效的MAC帧:
(1)第三字段表示长度时,MAC数据字段的长度与长度字段的值不一致;
(2)帧长度不是整数个字节;
(3)用收到的帧检验序列FCS查出有差错;
(4)收到的MAC帧长度不在64~1 518 Byte范围内。
当目的MAC地址为x“FFFFFFFFFFFF”时,是广播包;当目的MAC地址为x“0180C2000000”时,是BPDU报文,用于实现生成树协议;当目的MAC地址为x“0180C2000001”时,是Pause帧,用于实现流量控制。
MAC帧收发控制器主要依赖MAC帧接收状态机和MAC帧发送状态机。根据IEEE802.3 MAC帧格式,MAC帧收发状态机如图4所示。
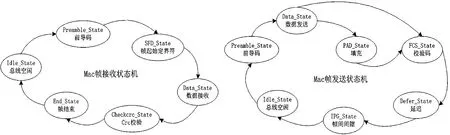
图4 MAC帧收发状态机
FPGA软件对接收到的MAC帧进行CRC校验判断,校验错误的帧直接丢弃,只对校验通过的帧进行存储转发。
2.2 存储转发控制单元
存储转发控制单元主要包括端口帧缓存单元、地址表查找单元、共享缓存管理单元和描述符调度单元。
2.2.1 端口帧缓存单元
FPGA软件为每个端口设置MAC帧收发FIFO各1个。FIFO宽36 bit,深4 096。MAC帧在端口收发FIFO中的存储格式,如图5所示。

图5 MAC帧数据存储格式
端口完成数据帧的缓存后,会向共享缓存交换单元发出请求,请求为包分配存储空间[1]。
2.2.2 地址表查找单元
本设计中,MAC地址表共支持4 096个MAC地址表项,地址表由1 000个Bucket组成,每个Bucket包含4个地址,组织结构如图6所示。地址表中,MAC地址的存储位置是由48 bit MAC地址计算出来的Hash值的低10位决定的。Hash算法采用CRC-CCITT多项式(X16+X12+X5+1)实现,根据MAC地址生成16位的Hash值,取其低10位,索引1 000个bucket。因Hash算法不是完美的,为防止出现碰撞,一个Hash值定位1个Bucket,每个Bucket包含4个MAC地址,第一个周期内读出bin0和bin1与DA比较;第二个周期内读出bin2和bin3。

图6 基于hash算法的MAC地址表查找
2.2.3 共享缓存交换单元
FPGA软件提供128 kB的共享缓存空间,并采用基于链表的控制机制对MAC帧分片存储,每片128 Byte,共支持1 024片。实质上,共享缓存式交换机是时分复用的,缓存在一个时钟周期内,只能允许一个端口读写。本设计以轮循方式为各端口分配空闲地址。共享缓存管理单元负责完成MAC帧的分片处理,也就是以128 Byte为一个单位从端口缓存FIFO中读取数据,然后为每个分片分配存储空间,并把第一个分片的存储地址记录在描述符中。每个分片除了记录数据外,还记录下一个分片的存储地址。当分片转发出去后,共享缓存管理单元完成片地址的释放。采用分片存储数据包,一个数据包的所有分片形成一个链表。这种结构使得发送描述符队列相对简单。每个描述符代表一个数据包,但只需要存储第一个分片的地址。这种结构可以自然实现数据包之间的分界,不需要设专门的定界符。空闲的片地址存储在空闲地址队列中,先进先出,有效实现了空闲地址的分配和释放。共享缓存管理单元的实现逻辑框,如图7所示。

图7 共享缓存管理单元实现逻辑框
2.2.4 描述符调度单元
RFC1349中定义的IP报文头部ToS字段高3 bit标识优先级,可使数据包具有8种优先级,其中0为最低优先级,7为最高优先级。FPGA软件为每个端口设置4个优先级队列,根据数据携带的ToS信息将其描述符映射到相应的优先级队列中排队[2],映射关系和调度示意图如图8所示。它的优先级关系为Cos0>Cos1>Cos2>Cos3。
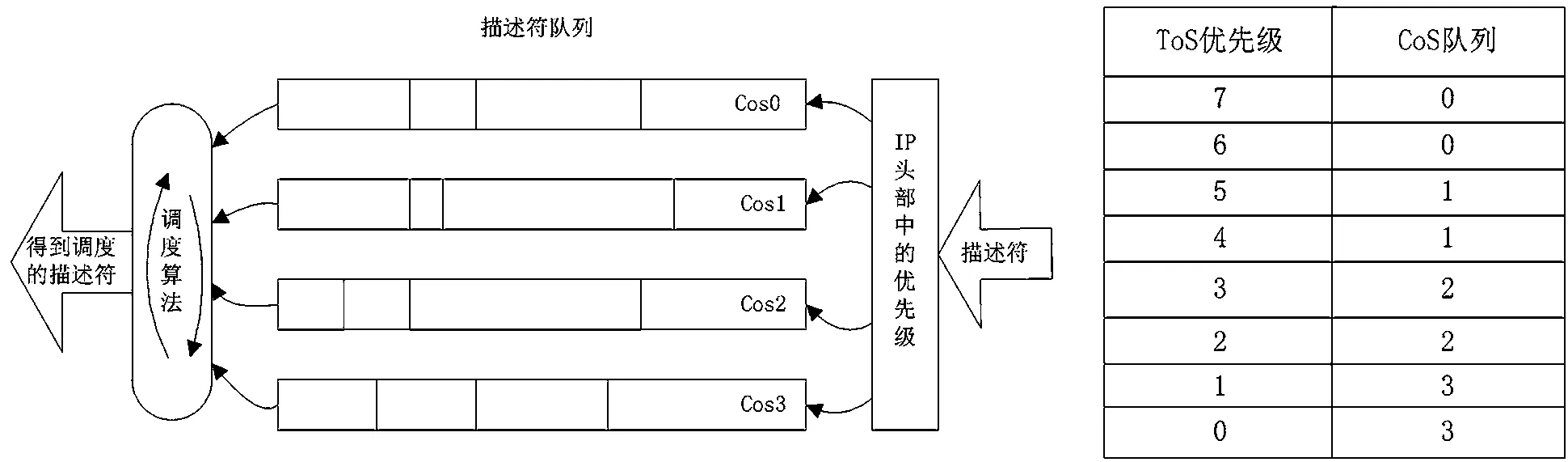
图8 描述符调度
每个端口4个描述符队列之间的调度算法采用严格优先级的方式进行调度。只有当高优先级队列为空时,才调度低优先级队列中的描述符。4个端口之间采用公平的轮询机制进行调度。描述符32 bit,具体格式如图9所示。

图9 描述符格式
2.3 STP生成树
当很多个交换机形成一个网络时,极有可能产生环路。此时若网络上有广播报文时,因为交换机对广播报文的处理是所有端口复制转发,而环路的形成就会导致广播报文永远无法消除,且被复制的越来越多而形成广播风暴,最终导致网络崩溃。生成树的作用是对网络进行自动拓扑,防止环路的产生[3]。
FPGA实现的二层交换芯片具备以下功能,可以支持生成树的运行:
(1)可以通过寄存器配置交换模式,选择是否使能生成树协议;
(2)可以识别以01.80.c2.00.00.00为目标地址的MAC层网桥协议数据单元BPDU报文,并通过IMP口将其转发且只转发给CPU;
(3)可以处理生成树标签,对于转发给CPU的报文,在标签中添加接收端口;从CPU接收的报文可以按照CPU在标签中指定的端口转发;
(4)CPU可以通过寄存器配置各端口的生成树状态,交换芯片能在下面5种状态里控制转发:
①Disabled(禁止态),不能接收和发送任何MAC帧;
②Blocking(阻塞态),只能接收BPDU,不能传输数据,也不能发送BPDU;
③Listening(监听态),不能接收或者发送数据,但可以接收和发送BPDU;
④Learning(学习态),不能传输数据,可以发送和接收BPDU,可以学习MAC地址。
⑤Forwarding(转发态),能够发送和接收数据和BPDU。
2.4 流量控制单元
IEEE802.3x中定义了全双工链路上流量控制的PAUSE机制,使用MAC Control帧携带PAUSE命令。PAUSE命令的MAC Control帧格式如图10所示,帧长度为64 Byte。多播地址01-80-C2-00-00-01保留给PAUSE帧专用。

图10 PAUSE帧格式
PAUSE帧中包含了PAUSE操作码和要求的暂停时间间隙。这些信息以两个字节整数形式表示,其中包含请求接收站点停止发送数据的时间长度。暂停时间以暂停“quanta”为单位,每个“quanta”等于512位时间。暂停时间的范围为0~65 535个单位。通过利用MAC Control帧传送PAUSE请求,全双工链路一端的站点能够请求另一端的站点在一段时间内停止发送数据。当暂停发送的端口收到时间因子为0的pause帧时,则停止等待,恢复发送。
本设计实现的千兆二层交换芯片,首先各端口是否使能pause帧机制的流量控制,是CPU通过寄存器配置的。若是端口未使能pause帧的流控,则共享缓存剩余空间不足时,直接丢弃数据包,避免缓存溢出,包处理出错。若端口使能了pause帧的流控机制,则在共享缓存剩余空间低于下限时,发送时间因子为x“FFFF”的pause帧,让对端等待,停止发送;当共享缓存剩余空间高于上限时,发送时间因子为x“0000”的pause帧时,让对方停止等待,恢复发送。这种方式又称为Xon/Xoff唤醒机制的流控方式。
仅仅采用基于Pause帧的流量控制,并不能保证高优先级数据的实时转发。假如某端口同时有多种优先级的数据需要发送,为了避免低优先级的数据积压占用共享缓存而引发pause帧的流控,造成高优先级的数据也暂停传输,FPGA程序中还加入了低优先级数据包的丢弃机制,即当共享缓存剩余空间低于下限时,若当前端口只有一种优先级的数据,则启动pause帧的流控;若当前端口有两种及以上优先级的数据时,则首先丢弃最低优先级的数据,释放缓存空间。
3 仿真结果
本设计的软件开发平台是Xilinx ISE 13.3,利用其自带仿真工具进行功能仿真。图11给出了MAC帧从端口2接收,然后交换至端口1发送的仿真结果。
从仿真图11可以看出,从端口2接收到的MAC帧,先写入端口接收FIFO中,完成帧的存储后产生rxfifo_req请求信号。然后,共享缓存单元响应请求,先从freecellfifo空闲片地址FIFO中读取一个空闲片地址x“38”,把数据从接收FIFO中写入共享缓存,并产生一个描述符,将描述符写入信号descriptor_valid。当描述符写入目的端口相应优先级的描述符队列后,共享缓存调度描述符,按照描述符中携带的起始地址从共享缓存中读取数据,并释放了x“38”的片地址。端口1的发送FIFO中有数据后,便开始通过发送控制器往链路上发送数据。
4 结 语
本文的设计对象是千兆以太网二层交换芯片。通过上述分析和仿真验证,可以证明FPGA体系结构和功能的正确性。目前,设计的可管理性主要包括链路配置、生成树配置以及流控配置。相比于市场上成熟的交换芯片,该设计可以满足千兆自适应二层交换的基本功能,但是尚存在需要完善和丰富的地方,也是后期继续研究的方向。
猜你喜欢
词学(2022年1期)2022-10-27 08:06:12
测绘学报(2022年12期)2022-02-13 09:13:01
数学物理学报(2020年5期)2020-11-26 06:06:48
广东通信技术(2020年10期)2020-10-26 06:36:52
小学生学习指导(低年级)(2020年4期)2020-06-02 09:09:26
软件(2020年3期)2020-04-20 00:58:44
火控雷达技术(2018年4期)2019-01-15 05:07:22
军营文化天地(2018年2期)2018-12-15 17:39:08
数字通信世界(2018年1期)2018-04-18 11:05:22
产品可靠性报告(2017年7期)2017-09-05 09:49:12
