
基于GA-SELM算法的工厂化水产养殖水温预测方法研究*
2018-11-02 03:59袁永明张红燕李光辉
传感技术学报 2018年10期
施 珮,袁永明,匡 亮,张红燕,李光辉
(1.中国水产科学研究院淡水渔业研究中心,农业部淡水渔业和种质资源利用重点实验室,江苏 无锡 214081;2.江南大学物联网工程学院,江苏 无锡 214122;3.江苏信息职业技术学院物联网工程学院,江苏 无锡 214153)
在工厂化的水产养殖中,由于水产品的养殖密度较大,水温的突变会使鱼类的生存环境发生变化,不仅会引起氨氮、pH、溶解氧等水质因子的变化,还会降低鱼类的生长速度和鱼体对一些疾病的抵抗力[1]。
目前对水质环境的监测、预测方法主要包括传统数学方法和智能算法上。岑伯明[2]等依据池塘水温和气温实时的监测数据,在计量经济学方法的基础上构建自回归的池塘水温的预测预报模型,模型在预测效果上缺少检验,同时在预报的实时性上有所欠缺;张德林[3]等采用逐步回归法分季节的建立大棚水温和气温之间的统计关系,然而该方法的误差较大,适用性不强;曹美兰[4]等应用数理统计的方法建立以气象要素为主的水温预报多元回归模型,从而完成冬季养殖塘水下0.5 m和1.0 m的水温预报。在人工智能技术方面,徐大明[5]等利用粒子群算法优化的BP神经网络构建PSO-BPNN预测模型对水温和pH进行预测,算法的实时性缺少对比;陈英义[6]等提出了GA-BP神经网络的池塘养殖水温短期预测模型,而训练数据量较小,参照对比模型不全面;徐龙琴[7]等提出基于经验模态分解(EMD)、相空间重构和极限学习机(ELM)组合的鱼苗水温预测模型,模型缺乏对传感器采集过程中异常情况的处理。
在前人研究成果的基础上[7-8],本文提出基于GA优化改进激活函数的ELM工厂化池塘水温预测模型。首先利用因子分析法计算综合天气指数,参照该指数对传感器采集过程中丢失和异常的数据进行插补和校正,提高数据质量。改进传统的ELM的激活函数,将GA优化的ELM的初始化权值和偏置代入预测模型中,完成水温的最终预测。并将该模型应用到江苏省无锡市南泉罗非鱼工厂化养殖的水温预测中。
1 材料与方法
1.1 研究区域
本研究的所有试验均在江苏省无锡市南泉养殖基地(东经119.33°、北纬31.7°)完成。试验基地共有养殖池塘50亩,其中有3个室外高密度养殖水槽,每个水槽为27 m2,深1.5 m,投放5 000尾左右的罗非鱼水花(3 cm左右),平均每立方米水体投放130尾左右。水槽使用循环水技术,采用曝气推水增氧装置,推动不同水层的水体能够横向流动,从而提高水体溶解氧含量。
1.2 数据采集系统
本研究以江苏省无锡市罗非鱼养殖基地的高密度养殖水槽水质为研究对象,采用淡水渔业研究中心智能渔业物联服务中心开发设计的水产养殖物联服务系统完成养殖水槽的水质数据。数据采集系统由数据感知层、数据传输层和应用服务层组成。系统架构如图1所示,采集系统在水槽中放置了水质传感器,池塘岸边安装自动气象站获取数据,数据经传输层传递给应用服务层,经应用层分析处理后向用户提供分析结果和决策支持。

图1 系统架构图
1.3 研究方法
1.3.1 遗传算法
遗传算法GA(genetic algorithm)是由Holland教授于1962年首次提出的一种模拟自然界遗传机制和生物进化论而形成的并行随机搜索最优化方法[9-11]。遗传算法的主要思想是将生物进化原理引入编码串联群体中,通过遗传操作,以选择的适应度函数为依据完成个体的筛选,保留适应度较优的个体,从而使新群体获得上一代群体的信息,同时又优于上一代群体[12]。如此循环反复,直至满足终止条件。遗传算法的基本操作分为:选择、交叉和变异。
①选择操作
通过对适应度值进行计算,参照适应度值的大小从旧群体里选择个体到新的群体中。在群体中,个体适应度值越好,则个体被选择到的概率越大。
②交叉操作
在群体中分别选择两个个体,随机确定个体中的一个或多个交叉点,并对两个个体中的交叉点进行交换组合,从而产生新的个体。对新个体进行检验,当新个体不在参数选择范围内时,则继续进行交叉操作。
③变异操作
在群体中随机选择个体,对个体中的一点按照规则进行变异操作,即0变1、1变0的方法。对完成变异操作的个体进行检验,当该个体不在参数选择范围内,则重新进行交叉操作。
1.3.2 改进激活函数的极限学习机
极限学习机是一种新型的快速、有效的前馈神经网络学习算法[13-15]。其包含输入层、隐含层和输出层。在包含n个样本的集合(xi,yi)中,隐含层个数为L,激活函数为g(x),则该网络输出可表示为:

(1)
wj为第j个隐含节点与输入节点间权值;bj为第j个隐含节点的偏置;β为隐含节点与输出节点间权值;H为ELM网络隐含层的输出矩阵。则n个样本的等式可写成:
Hβ=Y
(2)
激活函数对ELM神经网络的网络训练有至关重要的作用,它的正确选择影响着网络的性能。传统的极限学习机隐含层激活函数为Sigmoid函数,然而激活函数的选择并不是唯一的。Sigmoid函数是一种基于双侧抑制的阈值函数,在诸如广义Hop-world的问题中,当值函数的逼近值为单调时,双侧抑制的判别方式会增加废运算[16]。近年来被广泛应用在深度学习领域的修正线性函数ReLU(rectified linear units)是一种不使用幂运算和除法运算的激活模型,具有一定的稀疏能力[17]。本文提出使用Softplus函数作为激活函数,它是ReLU的改进,不仅具有ReLU运算快、泛化性好的特点,更能避免ReLU强制性稀疏的缺点。这些性能使得该函数的网络平均性能更好,计算效率更高[18],Softplus的函数定义为:
g(x)=ln(1+ex)
(3)
1.3.3 遗传算法优化改进激活函数的ELM
在ELM模型的训练过程中,其隐含层输入权值和偏置向量是随机获取的,这也使得权值和偏置向量恰巧为某些特殊值时,会造成某些隐含层节点失效,降低模型训练和预测精度[19]。故而,隐含层节点数、隐含层输入权值和偏置向量的最优化选择对ELM模型有着重要的意义。遗传算法能够确定这些最优化的参数值,以期获得最优的ELM预测模型。
其主要步骤如下所示:
Step 1 新建ELM网络,种群初始化。在遗传算法中,初始化种群,对ELM神经网络的权值和偏置进行编码,确定ELM网络的拓扑结构,输入变量X=[X1,X2,…,Xm]T,输出变量Y=[Y1,Y2,…,Yk]T。
Step 2 确定适应度函数。在建立的ELM网络中,设置网络训练适应度函数、初始种规模size和最大进化代数maxgen,公式4为适应度函数。
(4)

Step 3 求解最优适应度函数。根据个体适应度值,随机对种群中个体进行选择、交叉和变异等遗传操作,获取全局最优适应度值Fitnessbest。
Step 4 获取最优权值、偏置。利用最优适应度值计算其对应的种群个体,最终得到ELM算法所需的最优输入权值矩阵abest和隐含层偏置bbest。
Step 5 确定激活函数和隐含层输出矩阵。在ELM神经网络中,确定Softplus作为网络的激活函数g(x),根据得到的最佳权值和偏置,计算隐含层的输出矩阵H。

(5)
Step 6 计算输出连接权值。通过确定的隐含层输出矩阵H,利用线性系统最小二乘解的求解方法,得到隐含层节点与输出节点之间的输出权值β,如公式6所示。其中,H+为输出矩阵H的广义逆。
(6)
2 GA-SELM的罗非鱼工厂化养殖水温预测模型
2.1 数据预处理
不同水质数据由于单位不同,在后期分析和处理时会产生一些影响。传感器数据在采集过程中也存在一些问题,例如,水中的污垢,会附着在传感器表层,在水体的腐蚀性下影响传感器的精准度和数据传输的效率。针对传感器目前出现的数据丢失和数据偏差情况,需要对这些异常情况进行数据校正。
2.1.1 数据校正
对传感器采集过程中短时间内丢失的数据,本文使用线性插值法[20],完成对时间段内缺失数据的插补。公式如式(7)所示:

(7)
式中:xk和xk+j分别为第k和第k+j时刻的采集的传感器数据,xk+i为第k+i时刻传感器丢失数据。
鉴于监测数据在时间上存在连续性,故传感器采集的水质数据若在任意时刻与前后相邻时刻间差值超过10%,则认定该数据为误差数据需要进行数据校正[21]。利用相似时段相似天气条件下,水体的水温值较为一致,将相似时段相似天气作为评价指标,评估天气指数。
确定气压、气温、湿度、风速、风向、CO2浓度、照度、光合有效辐射、辐射照度等天气因素,利用因子分析法计算天气指数,计算公式如下所示:
(8)
式中:WI为天气指数;Wj为因子分析过程中提取的公共因子的方差贡献率;Fij=∑Ximamj为各公共因子的得分;xim表示第i个公共因子在第m个天气指标上的值;amj表示第m个天气指标在第j个公共因子上的得分系数。
对误差数据,对照相似时间段,按照天气指数临近原则选择对应的水质数据替换误差数据,同时保证替换的数据在该时刻前后误差不超过10%。对较长时间段内丢的失数据,将天气指数作为插补依据,在相似时刻,按照天气指数临近原则选择对应的水质数据插补丢失数据,完成所有数据的插补和校正。
2.1.2 数据归一化
经过数据校正,在m个指标的数据集中,对n组数据使用Z-score数据标准化方法,消除数据量纲差异问题。

(9)
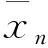
2.2 水温预测模型
2.2.1 水温预测指标体系构建
基于pH、CO2浓度、气压、气温、湿度、风速、风向、照度、光合有效辐射、辐射照度等水体因子和气象因子共计10个影响水温的指标因子。在诸多因素影响水温的情况下,本文采用皮尔森相关分析对这些影响水温变化的因素进行分析。将1 009个数据代入Person相关系数计算公式(10),获得水温与各影响因素之间的关联系数,结果如表1所示。

(10)
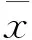
表1显示,水温与pH、CO2、气压、气温、湿度、风速、风向、照度、光合有效辐射、辐射照度等因子均具有一定的相关性,因此选择这些指标变量构建的水温预测模型。

表1 各影响因素与水温的person相关系数表
注:所有统计结果的Sig.值均在p<0.005水平
2.2.2 GA-SELM的水产养殖水温预测模型的设计
确定GA-SELM预测模型中的输入为上述10个变量,输出为待预测时刻的水温,建立基于遗传算法优化的极限学习机预测模型。在该预测模型中,要分别对所建立的遗传算法部分和ELM神经网络部分的参数进行设置。
①遗传算法部分。设置遗传算法的初始化种群规模为10,迭代次数为100。在多次运行且均方误差MSE(Mean Square Error)结果相近的条件下,设置遗传算法中的交叉概率为0.3。同时,在不断地试凑过程中确定变异概率为0.1。
②ELM神经网络部分。在ELM网络中,包含10个输入节点,和1个输出节点。而在隐含层节点数的确定上,为了避免出现“欠适配”、“过适配”的问题,在借鉴“试错法”试验思想下,通过不断试验和改变模型的拓扑结构,最终确定预测模型的隐含层节点数为28,从而确定预测模型拓扑结构完成ELM神经网络的训练和测试。
2.2.3 GA-SELM的水产养殖水温预测模型的评价
为了对GA-SELM算法的预测性能进行评估,选择均方根误差RMSE(Root Mean Square Error)、平均绝对百分比误差MAPE(Mean Absolute Percent Error)和平均绝对误差MAE(Mean Absolute Error)等指标作为模型预测性能判断的标准[22]。各评估指标的计算公式分别为:
(10)
(11)
(12)
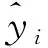
3 实验结果与分析
3.1 数据源
试验中的所有数据均来源于江苏省无锡市南泉罗非鱼养殖基地,在2016年7月1日至7月7日期间水产养殖监测系统采集的水质数据和自动气象站数据,数据采集频率为10 min/次,共计1 009组。其中,前6 d的864组数据组成训练集,最后1 d的145组数据组成预测模型的测试集。在试验过程中,确定pH、CO2浓度、气压、气温、空气湿度、照度、光合有效辐射、辐射照度、风速、风向为预测输入量,水温为预测输出量,经过多次试验,最终实现水温的预测。
3.2 预测结果分析
为了全面的分析和比较GA-SELM模型的预测性能,分别将BPNN、标准ELM模型作为对照模型对这些数据进行预测。在对照试验中,设置BPNN模型的隐含层节点数为6(根据隐含层节点数的经验公式l=sqrt(m+1)+c,m为输入指标数,c为1~10之间的常数)[23-24],训练次数为1 000,训练目标为0.1,激活函数为Sigmoid。在标准ELM模型中,设置其隐含层节点为28,激活函数为Sigmoid。各算法预测值与实际值对比结果如图2所示。

图2 各模型预测值与实际值对比图
图2显示,各神经网络模型的预测值与实际监测值均在不同程度上实现了水温的预测,虽然预测效果不同,除BPNN预测算法结果外,各算法的水温整体变化趋势与真实值变化趋势呈现较为一致的状态,可以证明各神经网络在模型构建和参数设置上较为合理。GA-SELM相较BPNN、标准ELM神经网络以及GA-ELM模型在预测值上更接近实际监测值,预测效果较为稳定,没有较大的波动点。图3为各算法水温预测绝对误差比较图,图9显示GA-SELM和GA-ELM算法在15:00点以前呈现较为一致的预测效果,预测值与真实值差值均在0上下波动,15:00以后预测差值出现较大的变化,说明两算法的预测效果出现了较大的差异。BPNN和ELM算法的预测误差波动明显,整体预测结果不理想,GA-SELM相较与这两种算法有明显的优势。

图3 各模型误差对比图
在所有测试集中,GA-SELM预测算法仅在两个时间段内(7:00am~11:00、17:00am~21:00)的预测误差较其他时间段误差偏大,这一时间段内分别为一日之内光合作用开始和结束的时间,水温变化幅度最大。
同时,由于水温随着气温存在一定的延时性,所以这两个时间段内水温预测难度很大。为了验证GA-SELM算法的准确性,在GA-SELM预测波动较大的时间段中选取7:00am和18:00am时间前后的预测结果列出,如表2所示。

表2 时间段内各神经网络预测效果表
从表2的预测效果对比表来看,在GA-SELM模型预测结果波动最大的两个时间段中,其预测相对误差仍优于标准ELM和GA-ELM预测模型,更接近实际监测数据。而在07:00的时间段内,GA-SELM的预测相对误差略高于BPNN神经网络模型,在17:00的时间段内,GA-SELM的预测相对误差明显低于BPNN模型。为了综合全面的评价这4个模型的预测性能,对3个模型的MAE、MAPE和RMSE进行对比,其对比结果如表3所示。
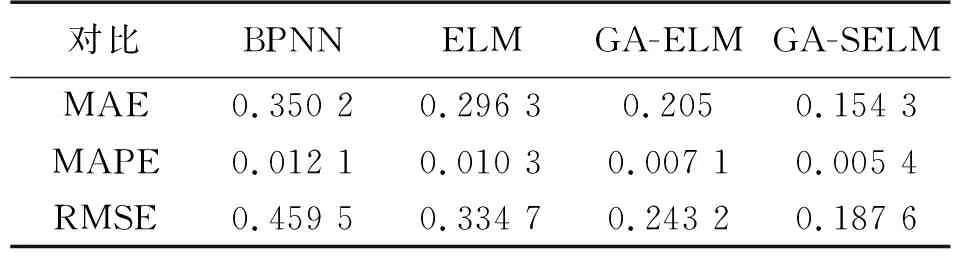
表3 3种水温预测模型的预测性能对比表
基于表3的3个模型的综合预测性能的所有数据可以发现,本文所提出的GA-SELM与BPNN神经网络的预测效果相比,其性能指标MAE、MAPE、RMSE分别降低了55.94%、55.37%和59.17%。同时,GA-SELM相较于标准ELM算法的预测性能,MAE、MAPE、RMSE则分别降低了49.92%、47.57和 43.95%。GA-SELM相较于GA-ELM算法的预测性能,MAE、MAPE、RMSE则分别降低了24.73%、23.94% 和22.86%,表明新的激活函数有更好的预测性能。GA-ELM算法较标准ELM算法在MAE、MAPE、RMSE值上降低了30.81%、31.06%和27.34%,表明GA算法的优化过程能提高水温的预测精度。
综合图2、图3、表2和表3的数据可以发现,本文提出的GA-SELM水温预测模型能够很好地预测工厂化水产养殖中的水温。改进激活函数的ELM算法能够对非线性系统中的数据特征进行提取和训练,快速有效的找到水温数据的变化规律,同时对水温的延时问题有一定的抗干扰性,保证ELM算法的稳定。而GA算法则是避免了ELM算法中初始权值和偏置的随机性问题,帮助改进激活函数的ELM算法快速获取最佳参数组合,为高性能的水温预测模型提供最优条件。
4 结束语
在应用遗传算法的基础上对改进激活函数的极限学习机的初始权值和偏置进行优化,解决极限学习机中参数的随机性问题,提出了基于GA-SELM的工厂化水产养殖水温预测模型,为解决传统水产养殖中水温预测的不稳定、强时滞性问题提供了新的方向,并应用在了江苏省无锡市罗非鱼工厂化养殖的水质监测中。经过与BPNN和标准ELM预测结果的对比分析,其仿真结果表明,GA算法和改进激活函数的ELM算法结合所建立的预测模型预测精度高、稳定性好、实时性强,能够为水产养殖中水温预测提供较为合理的依据,帮助渔民和从业者高效的管理和监控水质。
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
成都信息工程大学学报(2022年3期)2022-07-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
电子制作(2019年7期)2019-04-25
电子制作(2018年17期)2018-09-28
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
自动化学报(2017年7期)2017-04-18
统计与决策(2017年2期)2017-03-20
现代电子技术(2016年15期)2016-12-01
现代计算机(2016年34期)2016-02-28
