
考虑连接性的路网划分算法
2018-10-29 05:05卢守峰陶黎明江勇东
交通运输系统工程与信息 2018年5期
卢守峰,陶黎明,江勇东
(长沙理工大学交通运输工程学院,长沙410114)
0 引言
随着汽车保有量的激增,城市交通拥堵呈现出了区域特性,使得区域交通的宏观建模得到关注.Daganzo等基于Godfrey对路网平均密度与平均流量相关性的发现,在2008年提出了反映区域交通网络状态特性的宏观基本图(Macroscopic Fundamental Diagram,MFD)概念[1].之后利用实测数据创建宏观交通基本图成为研究热点,卢守峰等[2]利用线圈检测器数据和出租车GPS数据对宏观交通基本图的创建进行了研究.Geroliminis等[3]利用实测数据创建宏观基本图,发现交通网络中车辆密度空间分布的均质性是影响MFD形状的关键因素.MFD的出现为交通控制策略提供了新思路,边界交通控制研究得到发展.国内学者张逊逊等提出基于MFD的多子区边界反馈控制策略[4],结果表明多子区控制策略可进一步减少拥堵,这也体现了子区划分的重要意义.
研究发现路网的均质性是得到准确MFD的重要前提,因此服务于MFD创建的非均质路网划分研究开始得到关注.Ji等[5]以路段为聚类对象,在2012年提出利用谱聚类中的归一化分割(Normalized cut,Ncut)方法进行路网划分.该方法以路段的车辆密度属性为对象,利用相似度函数计算权重矩阵,并通过求解矩阵特征系统,将交通网络划分为密度分布均质性较高的路段集合.谱聚类应用最早和最广泛的是图像分割领域,具有坚实的理论基础,但其存在两个主要缺点:①划分结果对参数值敏感;②需求解矩阵特征系统,对于聚类规模较大的应用,计算和存储压力大.继Ncut算法之后,Saeedmanesh等在2016年针对拥堵在路网中的传播特性,提出一种三步聚类算法[6].该方法在规模较大及存在数据缺失的路网划分中表现良好,但对于时间上的动态变化未考虑.因此,Saeedmanesh等在2017年又对该方法进行了改进[7],对归属稳定的路段进行确定性聚类,然后再基于最小化目标函数对稳定性低的路段进行合并或拆分.同年,Dimitriou等对K均值算法和METIS算法的路网划分效果进行了对比[8].研究表明,K均值算法在单纯的数值属性对象聚类上性能优于METIS算法,但其无法处理交通网络的空间连接性与交通流运行的组合特性.
本文通过考虑路网空间结构及其交通量分布在时间上的变化,对K均值算法在路网划分中的应用进行改进.然后利用车牌照自动识别实测数据对改进的方法进行测试,并利用子区的宏观基本图对划分结果进行分析.相比Saeedmanesh等在2016年提出的合并相似均匀路径方法,以及其他分层处理聚类对象连续性要求的方法[9],本文将路网连接性约束事先融入于聚类算法中,实现聚类与连接性约束同步,避免聚类子区内路段不连续,聚类后需再根据连接性调整结果的不足.
1 K均值聚类算法改进
K均值聚类作为一种经典的聚类算法,因具有简单高效的特点在各领域得到广泛应用[10].虽然传统的K均值聚类算法具有原理简单、运算快捷、易于实现、可扩展空间大等优势,但其在路网划分应用中的主要缺点有:①K值直接影响聚类结果,难以事先给出;②初始聚类中心的选择对聚类结果干扰大;③对不稳定的孤立点数据敏感;④聚类子区的路网连接性无法得到保障.这些问题使得传统K均值聚类算法难以实现路网的有效划分.
道路网络划分的目标是将具有强相似性和高关联度的路段聚类成簇,方便准确把握区域交通状态.基于此,路网划分结果要尽量满足3点:
(1)同一簇内路段之间的属性差异和不同簇之间的相似性尽可能小;
(2)簇的数量要少,以减小控制策略的设计压力和实施成本;
(3)在空间上确保子区路网的连通性和良好的紧凑性[11].
然而,在现实交通网络中,上述3点要求相互冲突.第1点的最优解要求簇数量尽可能大,每个路段本身单独为1个簇,这与第2点冲突.连接性和紧凑性属于空间要求,而第1点是数值上的要求,因此第1点对第3点具有限制.从可行性角度考虑,设计一个能够在这些要求之间实现良好平衡的聚类机制成为了主要研究目标.对于路网划分的结果评价,常用ANSK和TV值表示,其定义为[5]

式(4)可以转化为以方差和平均值来表示的形式,即

同时

式中:K代表划分得到的子区个数;A、B代表两个不同子区;Neighbor(A)为空间上与聚类A相邻的子区;Fi和Fj分别为A和B中的对象属性值;uA和uB分别为A和B中的对象属性平均值;C为子区集合;NA表示A中对象个数;d表示数据对象属性个数.
当不同子区的属性平均值差越大,评价子区内部方差越小,则NSk值越小,说明子区A的划分效果越好.由于一个具有较小方差和NSk值的集群可能伴随着一个具有较大方差和NSk值的相邻子区,所以用平均值ANSk对整区划分的效果评价.
K均值算法改进的思想是通过路网连接矩阵保证路段的连接性,先利用最大最小距离[12]公式确定初始聚类中心和路段差异,再捕捉差异性最小的路段.算法改进后具体步骤如下:
Step1 构建路网连接矩阵.
设路网中路段数为N,则先对其进行1~N的编号,然后建立N×N维的连接矩阵M,设连接道路i和j之间的权值M(i,j)为1;反之,为0.
Step2 选取初始聚类中心.
利用欧式公式计算路网中所有路段对车辆密度的距离集合U={D|D=,并取最大距离的路段对max{D}的路段i和j作为初始子区的聚类中心I和J.
Step3 路段捕捉.
先利用连接矩阵M,同步搜索分别与质心路段I和J相连的路段;然后计算这些连接路段与质心的欧式距离,并将距离值最小的路段捕捉至其对应质心所在的子区(当某一路段与I和J都相连且都是距离最小路段时,我们定义为“竞争路段”.则通过对比该路段与两个质心的距离,将其归属于值小的子区).
Step4 子区更新.
搜索与子区内已存在路段相连的路段,并按Step3的计算原则循环执行路段捕捉,直至路网中所有路段得到划分.
Step5 迭 代.
计算准则函数SSE值和子区的路段密度平均值,然后以子区内密度值与其平均值最接近的路段作为新质心,返回Step3直到SSE值不再减小.其中,p为数据对象,mj是簇Cj的平均值.
Step6 连续二分.
选取已分得子区中密度方差最大的一个子区作为再次划分的新路网,重复Step1~Step5,每次增加一个子区,当子区划分前后ANSK不再减小则终止划分,并确定子区数量为K.
Step7 补充划分.
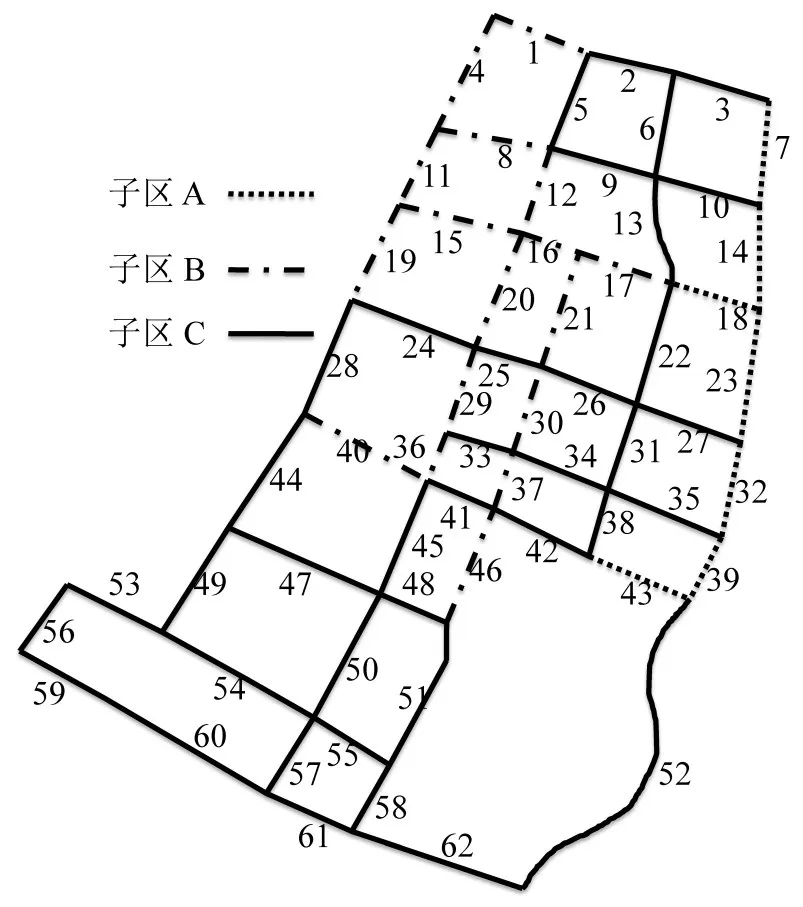
对于规模较大的路网,继续进行二分,对比ANSK和ANSK+n的大小,其中n为整数,且K+1 传统K均值聚类算法应用时,初始K值很难确定,Step6可以在路网划分中解决该问题.K值不提前给出,而是以划分前后ANSK的变化为依据,确定K值.但是,Step6通过比较连续二分后的ANSK大小,进行划分终止的判定,当路网内部交通荷载呈多区域均质分布时,可能出现非最佳划分状况.例如,Step6划分计算得到ANSK 考虑到子区的紧凑性和内部交通动态变化,利用聚类中处理“噪声”对象的常用思想,对连续时间间隔下的道路交通网络进行划分.通过统计路段在分区内的频数[9],对“噪声”路段(定义为相邻子区之间的‘连接路段’和与‘连接路段’相连的路段)进行拆分与合并调整,以减小不稳定路段对划分结果带来的干扰.假设有t个时间段,具体操作如下: (1)根据每个时间段的交通状态属性值划分路网,并统计每条路段在不同子区内出现的次数Fq,q代表子区编号. (2)进行“噪声”路段判定,找出各子区的“噪声”路段. (3)对比“噪声”路段在不同子区内出现的次数,若其在某个子区内出现次数Fq>t/K,且满足连接性条件,则将其进行拆分后合并至该子区. 为检测改进后的K均值聚类算法在路网划分中的效果,基于浙江绍兴柯桥城区道路的车牌照数据,进行路网划分试验.算法通过Matlab实现,路段密度由CUPRITE模型[13]计算得到.为与文献[5]的算法结果进行对比,密度单位,辆/m.初始路网如图1所示. 该路网由39个交叉口和62条路段构成,将某天6:10-21:50的时段取10 min为间隔,得到94个时间段.不同时段路段车辆密度变化如图2所示.路网密度方差变化如图3所示. 图1 初始路网Fig.1 Initial road network 图2 路段密度时间变化Fig.2 Time variation of links density 对于车辆密度均质性最低(方差最大)的第70个时段(17:40-17:50)路网密度进行分割,由于该路网规模较小,子区数量上限H设为3.划分结果如图4和图5所示,划分子区的评价指标如表1所示. 路网经过1次划分后,在K=2时方差和TV的值相比初始路网(K=1)明显变小.路网在经过2次划分后(K=3),其方差和TV值较第1次划分前后,减小幅度大大降低,且ANSK值变大.基于此,确定K的值为2,然后进行“噪声”路段的调整. 我们对94个时间间隔下的路网进行划分,“噪声”路段在两个子区中出现次数情况如图6所示. 图4 1次划分结果Fig.4 The first partition result 图5 次划分结果Fig.5 The second partition result 表1 子区评价指标值Table 1 Evaluation index values of sub regions 图6 “噪声”路段在不同子区内出现次数统计Fig.6 Statistics on the number of"noise"links in different sub regions 根据这些路段在不同子区的出现次数,若出现次数大于t K的子区与其现所在子区不同,且满足与新区连接性条件,则将其拆分后合并至出现次数大的子区.调整前后子区划分如图7所示.调整后的路网子区内,道路在空间上的紧凑性得到明显提高. 为分析该路网划分方法的优劣,我们将试验结果与传统K均值聚类和归一化分割的结果进行对比.其中,考虑到归一化分割算法的参数敏感性问题,对其相似度函数exp(-α(Fi-Fj))2中的α取103和104,F代表路段i和j的车辆密度.两个方法的子区划分结果如图8所示,对应评价指标如表2所示. 图7 “噪声”路段调整前和调整后子区图Fig.7 Subarea graphs before and after adjustment of"noise"links 图8 不同方法划分结果Fig.8 Partition result of different method 表2 各方法子区评价指标值Table 2 Sub-region evaluation index values of different method 通过划分结果的图像和相关指标对比,可以发现传统K均值聚类算法得到的子区方差、TV值和ANSK值最小,但同一个子区内的路段在空间位置上不相连,无法应用.归一化分割算法得到的子区,在空间连接性和紧凑性上优于另外两种方法,但其在不同数量级的参数下,对同一状态的路网划分结果不同.本文提出的考虑连接性的K均值算法,在评价指标上不及传统的K均值算法,但其很好地保证了子区路网的连接性,实现了其在路网划分中的有效应用.同时,其聚类结果不存在对参数尺度敏感的问题. 为进一步证明改进后算法在路网划分中的应用价值,我们绘制了划分前后的MFD,如图9所示. 在图9中,路网经划分后可清晰看出各子区的最大流量是不同的,这可以为分析交通路网运行状况和交通管控措施提供更准确的依据. 在传统K均值聚类算法中引入连接性约束,保证聚类子区内道路的连接性.通过最大最小距离算法确定初始聚类中心和路段差异性,利用聚类评价指标ANSK确定K值,避免初始聚类中心和子区数量选取所导致的划分结果不可靠现象.最后,从子区路网紧凑性角度出发,统计连续时间内多次划分的路段子区出现的频数,对噪声路段进行调整,进一步优化子区路网的空间结构.利用自动车牌识别实测数据,将该算法与传统K均值聚类和归一化分割算法进行对比.结果表明,该算法可以实现路段连续,划分结果不受参数尺度影响.通过路网划分前后的宏观基本图对比,证明该算法可使非均质路网得到有效划分,更准确地分析交通运行状况和实施交通管控措施.本文提出的路网划分算法不区分方向,进一步研究将从交通流的方向性和动态变化角度展开.2 划分试验
2.1 实 例





2.2 效果分析



3 结论
猜你喜欢
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09编辑之友(2021年12期)2021-01-05中学生数理化·七年级数学人教版(2019年6期)2019-06-25中学生数理化·七年级数学人教版(2019年6期)2019-06-25环球飞行(2018年7期)2018-06-27初中生世界·九年级(2017年10期)2017-11-08中国自行车(2017年7期)2017-08-16航海(2017年4期)2017-08-09中国公路(2017年11期)2017-07-31中国公路(2017年7期)2017-07-24
