
实时云办公系统下文件管理的一致性维护研究
2018-10-26 02:23高丽萍
小型微型计算机系统 2018年9期
高丽萍,张 强
1(上海理工大学 光电信息与计算机工程学院, 上海 200093)2(复旦大学 上海市数据科学重点实验室, 上海 200093)
1 引 言
传统的单服务器环境中,在用户网络良好且电脑配置良好的情况下,当用户量过大时用户操作界面很容易变得反应缓慢甚至卡死,这种情况随着云时代的到来,得到大大的缓解,云利用一切在线的资源进行合理的分配分布式的处理,将区域分离的资源通过网络连接起来,利用一切优势进行处理复杂或者庞杂的问题.云以其高可靠性和高可扩展性和按需付费的原则[1],使得大多企业都选择将公司的资源存放在云环境下,文件管理是其中办公系统中的重要组成部分.一直以来,企业的文件管理都是在单机环境下进行的,针对大型企业的数量极大和庞杂的文件,一个人的管理显得效率低下,多人实时协同管理文件将大大提高业务效率,利用云的强大处理数据能力和高效性,在云环境下的多人实时协同文件管理将显得高效便捷.
协同工作允许地理位置不同的用户借助网络进行工作交互,实时协同编辑的效果要求在进行交互的过程中即时可见,最终在各地的文档状态一致,同时满足各用户的意图,在实时协同编辑领域有几种比较常见的实现一致性的技术:操作转换技术(OT)[2],地址空间转化算法(AST)[3]和版本控制技术,因文件系统是典型的树形结构,使用AST技术,回溯过程需要大量的操作来维持结构的变化,效率较低,OT 的基本思想是根据已被执行的并发操作的效果来调整当前操作的相关信息,使得转换后的操作被执行后能够最终得到正确的结果,从而维持一致性.在OT技术中所有已执行的操作存储在历史序列( History Buffer,HB)[4].OT能较好的解决非线性文档一致性问题.如Palmer和Cormack在文献[5]中提出了基于OT的分布式协同电子协同表格系统;Sun等人在文献[6]中提出基于OT技术采用多版本技术解决2D文档模型下垂直交叉的冲突,维护了文档一致性;Agustina等在文献[7]中提出基于OT技术利用多版本解决了3D系统中依赖图文档模型中依赖冲突的问题.
实时协同发展过程中,基于OT思想提出了一些较好的控制算法,如dOPT[8],GOT,GOTO[9],COT[10]等.GOT,GOTO只在线性文档的状态下适用,COT是基于上下文的操作转换控制算法,COT算法可以很好的适应树形文档的数据模型,并根据上下文的状态来判断节点操作的可执行状态.但传统的COT算法是在P2P的环境下工作的,P2P工作环境有2大局限性:协同站点数在协同工作开始前就已经确定,且站点不能中途退出;P2P环境下的COT每次传输都要附带一个C(O)的文档状态文本,当协同工作时间过长或操作过多时,这个C(O)就会变得很庞大,降低了实时性影响用户体验.在新的云环境C/S架构下,用户的流动性和大量性会对实时协同工作造成很大的干扰,这需要设计新的控制算法支持大量用户的动态加入和退出,并保证高可靠的实时性.本文改进原有COT来满足新的架构新的环境,在服务器和客户端各维持两个HB(DS,DS′),DS是全局总的历史操作序列,而DS′是一个动态变换的局部历史序列,也是C/S传输过程中的C(O),在服务端设置一个定时器Timer,每隔时间t,在服务器与客户端的交流过程中,服务器从每个客户端获取最新的DS′,并进行处理得到最大子集,返回给各客户端,这样,各客户端DS′每隔时间t将会动态的减小,并且每次传输的C(O)都会保证在很小的范围,对于提高实时办公有很大的改进,同时在系统设计上,我们采用WebSocket协议技术,相比于HTTP协议,通信能力大大增强.
传统的COT算法是针对P2P线性文档模型,文件管理模型是在具有强大处理能力的集中式架构云环境下进行的,本文针对架构的变化和实时性的需求,提出改进的Improved _COT算法来适应新的环境,接着将改进的算法应用到云办公系统的文件管理之中,解决文件管理中的三个典型操作create,rename,delete的冲突,维护系统的一致性.此外,为了更好的体现实时性,本文将基于WebSocket实现一个文件管理系统CloudFileSystem来验证算法的可行性.
2 相关工作
一致性维护是保证协同系统办公的正确性的关键,合理且高效的算法能够大大提高用户的体验,操作转换(OT)是最早出现的实时协同系统一致性维护的技术,自从1989年Ellis提出OT来,实时协同编辑经过多年的发展陆续出现了GOT,GOTO,AST,ABT[11]等一系列的优秀算法,但是这些算法基本上应用的场景都是在线性文档的编辑,图形编辑和图像编辑中,且都是针对P2P的分布式系统中,在云时代复杂的网络环境中,实现用户实时的交互是一项巨大的挑战.
云环境下的协同工作是目前协同研究的主流趋势[15-18]目前研究协同文件管理的文章比较少,SUN在2016年提出了在云存储下的文件储存的 CSOT算法[12],该算法是基于文件的节点和路径特性来分析协同文件存储中的冲突.文献[12] 局限在单服务器上讨论了文件的在云储存中的一些情况,如图1所示,在用户量过大时,单服务器的状态将无法承载过大的数据量,在云环境下通过负载均衡技术将数据的转发到多台服务器上同时处理不同的数据,这样大大缓解了的单台服务器的压力,从而强化了用户的体验.同时,本文将已文献[12]文件模型为模板设计实时集中式架构下的文件管理系统,结合该应用场景给出实例论证验证一致性,针对文件节点的三个操作(create,delete,rename) 做了不同转换策略,在此基础上结合云环境的特性和高用户体验性设计改进的Improved_ COT算法来适应新的环境.
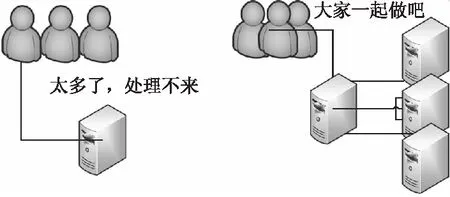
图1 单服务器环境和云环境Fig.1 Single server and cloud environment
本文针对C/S架构下文件管理系统中实时性在算法上做出了改进,同时在系统设计上我们采用的工具协议等都要保证能尽量达到更好的实时性.
web应用是具有天然跨平台优势,利用网页来实现工作方便快捷,在基于OT技术的控制算法中,目前只有Google Wave所采用的Jupiter[13]算法和Bin Shao等人提出的TIPS[14]协议是完整支持集中式架构的,Jupiter 算法并不是完美的,在一些特定的情景下算法并不能得到正确的结果.TIPS算法是基于HTTP协议设计实现的,并不能严格的达到实时性,传统的HTTP协议每次请求都会建立新的连接,虽然后面发展出了如AJAX技术,轮询,comet技术来向实时性方向靠拢,但是由于HTTP每次发送信息都带有完整的头信息,对于应用需求很低的延时下,这本身是一个棘手的问题,基于此,HTML5规范的WebSocket协议被提出了,它可以实现实时的全双工通信,尽管WebSocket存在一些安全问题,但它仍有巨大的优势,建立连接就不会断掉,一旦服务器和客户端完成握手,信息可以畅通无阻地随意来往两端,而不用附加无用的HTTP头信息,这大大的降低了带宽的占用,提高了性能.所以在本文中并没有采用上述协议,而是在WebSocket协议的基础设计并实现系统原型CloudFile -System.针对文件管理过程中最常见的几个操作rename,delete,create来说明文件管理中的常见操作冲突处理方法并验证算法的可行性.
本文的后期工作如下.在第三章将介绍COT算法及其改进算法.第四章介绍办公系统文件的模型结构及相关的转换函数;第五章设计实时云办公系统来验证算法的有效性;最后给出总结和展望.
3 Improved_COT算法的设计与分析
本文在设计改进的算法过程中,假设在网络环境良好的情况下,并不会发生丢包等情况.在COT算法中,C(O)是COT中的各站点维护的文档状态,站点交互过程中需要传递C(O),操作转换也需要与C(O)中的元素进行比较转换操作,与传统的P2P协同工作环境相比,云环境下的协同工作提出了新的挑战,在P2P端,站点的数量和操作的数量有限,传输信息的大小对协同工作的影响较小,携带的C(O)大小变化不会很大,在云环境下动态的协同关系中用户量和数据量较大,那么C(O)将随着时间增加而急剧的变大,信息传输过程中和操作处理执行过程,都会浪费大量时间来做无用的工作,合理的改进COT是保证实时协同的重要前提,同时云环境相对于P2P网络环境,架构发生了变化,COT又必须适应新的架构体系,本文针对云环境下架构的变化和实时性的要求提出了改进的COT算法来实现C/S端的一致性维护.
3.1 Improved_COT算法设计
随着原来越多的操作堆积在C(O)中,在传输操作的过程中,必然造成传输的流量越来越大,大量的臃肿的操作势必会造成传输的拥塞,这种情况会导致实时性的大大减弱,维护好C(O)的大小变得非常重要.
在COT中,每次操作传输都带有C(O),随着协同工作的时间越来越长,C(O)中操作的数量也会越来越多,每次传输到服务器的操作的体积也越来越大,为了更好地做到实时性,设计合理有效的算法来减小C(O)的大小,又不影响COT的本质工作是保证实时性的重要前提.
COT的工作核心是每次传到其他站点的操作执行COT(O,DS),如下
1.可执行形式EO=transform(O,DS -C(O))
2.执行EO
3.DS=DS+{org(EO)}
DS是该站点的文档状态,C(O)是O的上下文状态,随着累积的操作越来越多,C(O)的体积越来越大,维护好一个合理体积的C(O)是实时性保障的前提,在1中,O的执行条件是将DS与C(O)中的操作对比,在C(O)中没有的操作将与O进行操作转换,那么在一次次操作操作传输过程中,DS和C(O)靠前的操作将会进行一次次无用的比对,这浪费了时间和传输开销,删除前面的操作变得非常重要,保证了C(O)中的操作不会过多而拥塞传输造成实时性降低.在服务器端和客户端维护两个文档DS,DS′,DS与COT中DS一致,DS′是一个动态变化的文档状态.算法设计如下:
Algorithm1.Improved_COT(O,DS)onServer
C(O)={} ;DS={};TDS={};MDS={};
DS′={} //一个动态的DS来实现减少DS-C(O)的判断操作
t=Timer(T); //定时器
If(t){ //每隔时间t从各客户端获取一次DS′
Send request DS′to all sites;
MDS=[DS1,DS2,DS3….]
If(MDS.length>Limit){
PDS[ ]=Split(MDS,N);
send to Other Server to handler;
get the COi= Handler(PDSi) from Other Server;
TDS={CO1,CO2…};
}else TDS=MDS;
FlagCO=handler(TDS);
send FLAGCO to all sites;
}
//end~
在Algorithm 1中协同工作开始后,在服务器端设置一个定时器Timer,TDS为在中心服务器上进行处理的操作序列,MDS为从各站点接受过来的操作序列集合,服务器每隔时间t向各站点发出接受DS′的请求.初始化MDS为DS′的集合,在云环境下高效处理大量数据用到了负载均衡算法.首先,当协同人数很少,一台服务器也能够很快的处理完成,直接服务器处理完成即可,当协同人数过多达到设定的临界值,此时需要利用云服务的特性,对数据进行分流,多台服务器同时工作,快速处理完成并将部分处理结果反馈到一台服务器上,进行最终处理,这里设置一个临界值Limit表示当MDS的长度大于这个临界值的时候,在单台服务器上处理这些操作的时间大于数据在服务器之间传输的往返时间和处理时间的总和,因往返时间一般是固定的,且分发到其他服务器的数据是较短的,所以Limit的值可以经过实验固定下来.处理过程使用handler(TDS)函数进行,最终将标记的序列FLAGCO发送到每个客户端.
Algorithm2.Improved_FCOT(O,DS)onClientj
C(O)={} ;DS={};
DS′={};
GET FLAGCO= Handler(TDS) from server;
DS′=DS′-FLAGCO;
FLAG(DS,FLAGCO);
C(O)=DS′;
//end~
在Algorithm 2中客户端接受到FLAGCO后,DS′副本进行标记,将生成新的DS′置为DS′- FLAGCO,这样每隔一个时间段服务器向每个站点发送一次请求,进行处理,当协同时间过长也不会影响用户的响应速度和处理速度,保证很好的实时性.
在服务器端进行处理时最重要的就是如何对数据的处理,服务器端的hanlder(TDS)是本文的重点 算法如下:
Algorithm3.Handler(TDS)
FLAGCO = TDS[0];
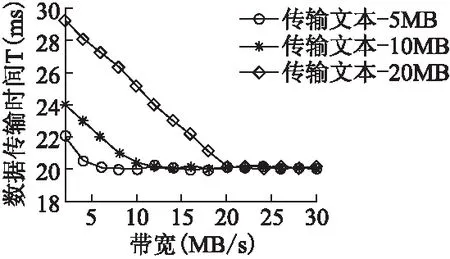
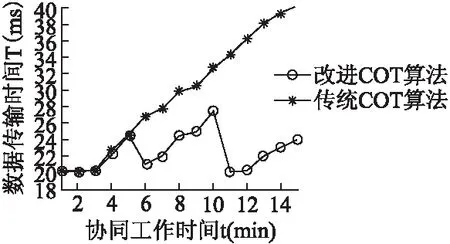
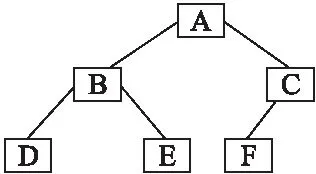
For(int i=1;i FLAGCO = Handler(FLAGCO,DSi); } Return FLAGCO; 初始化CO0为TDS的第一个元素,依次与队列中的其他元素进行handler(DS1,DS2)处理,最终返回一个FLAGCO的序列,函数Handler(S1,S2)如下: Algorithm4.handler(DS1,DS2) Init:CO1[]={},CO2[]={}; If(DS1.length==DS2.length){ DS1′=sort(DS1); DS2′=sort(DS2); If(DS1′.equals(DS2′)) Return DS1′; } DS′=getAllSameEl(DS1,DS2); For(int i=0;i If(DS1[i].contains(DS′)) CO1[i]=DS1[i]; Else break; } For(int i=0;i If(DS1[i].contains(DS′)) CO2[i]=DS2[i]; Else break; } Return handler(CO1,CO2); //end~ 对来自两个站点的序列DS1和DS2处理如下,首先初始化两个为空的CO1和CO2,判断DS1和DS2是否有相同的队列长度,是,对DS1和DS2进行复制操作,产生DS1′和DS2′,对DS1′和DS2′中的操作按标记的序号进行排序操作,若DS1′和DS2′是相同的,则返回DS1,若不同维护一个DS′是找到DS1和DS2中的所有相同的元素,分别将DS1和DS2中的元素与DS′中的元素对比,存在DS′中的元素按在DS1和DS2中的顺序分别记录到CO1和CO2中,然后递归处理Handler(CO1,CO2),直到找出满足条件的CO. 时间t的设置要看网络的状态,本文设计的是在云平台的环境下,即PC端上能够提供较好的网络状态,所以,服务器和客户端的传输不会出现掉包等情况,时间t,可以设置在2分钟左右,协同办公的人数不会太大,上限设置为50人,那么在5分钟左右的时间,假设每分钟每个站点有100个操作,C(O)中的操作数量也是10000个,这个数量不会影响传输的操作,当然在网络状态不稳定的情况,我们暂时没做考虑. 服务器端主要接受来自各站点的操作,同时将负责操作转发到其他服务器,并且每个服务器都负责不同的功能,能大大的提高操作处理的速度,服务器端算法设计如下: Algorithm5.ControlProcedureonServer Thread1: If(get the new connected request) { open a new connected ; Send the latest documnet to it; }//监听连接,一旦发现,向其发送最新副本 Thread2: Get O from all site Improved_COT(O,DS′) on Server; Thread3: Send O to Other site; 在Algorithm 5中线程1是为了监听用户的动态变化,每次有新的用户加入进来就给用户发送最新的文档副本.线程2接受各站点的操作进行Improved_COT算法处理.线程3将接收到的操作直接转发到其他站点.客户端主要接受来自服务器转发不同客户端的操作然后直接执行COT就可以了,算法如下: Algorithm6.ControlProcedureonClientj Thread1: Get latest document from server; Thread2: Improved_COT(O,DS′) on Client; thread3: send O to server; 在Algorithm 6中线程1是在初次连接时接受来自服务器端的文档副本.线程2进行改进的COT控制算法,详细的COT算法就不在这里介绍了,可以在文献[12]中看到.线程3是将产生的操作立即传到服务器端. 传统的COT算法中C(O)大小并没有改进,将传统的COT在云环境下的应用和改进的COT在云环境下的应用进行对比,本文针对协同工作的时间产生的操作的数量和网络带宽做了相关方面的测试,仿真信息传输通信实验,在网络带宽一定的情况下,当协同工作时间越长,操作数量越来越大,C(O)变大时,信息传输耗时越久;在操作数量一定的情况,带宽越宽,操作的传输效率越高. 在网络通信中,客户端与服务器之间的信息传递是需要时间的,简单的说,数据从一端发送开始到另一端接受处理完成要消耗时间,这个时间往往是影响实时协同工作的重要内容.所以减少时延是必要地研究,数据在网络中经历的时延有四种:发送时延,传播时延,处理时延和排队时延,处理时延和排队时延本文不予讨论,时延仿真过程中,我们设定网络吞吐量就是达到网络带宽的100%,给定网络带宽为100kb/s,每个操作大小一致为10Kb,同时在硬件,距离等条件一致情况下,传输时间最低时间为20ms,操作随时间产生的利用随机数random函数来在范围(40,100)之间产生.下面给出图2和图3分别随着带宽变化和协同工作时间变化,传输时间的变化. 图2 带宽变化对比图Fig.2 Contrast chart of bandwidth variation 图2中给出三种不同大小的传输文本大小,随着带宽的变化越来越大,最终传输的时间趋近稳定,而文本越大,趋近稳定所需的带宽越大. 图3 FCOT与COT对比图Fig.3 Contrast chart of FCOT and COT 图3中给出传统的COT算法中DS与改进的Improved_ COT算法中的DS′随着时间的变化,传输时间的变化图,试验中选取了上个试验中的临界带宽为10MB/s,改进COT中的定时时间t设为5min,当操作随着时间累积,DS和DS′的大小达到图一中临界带宽对应的文本大小时,传输时间开始增加,传统的COT算法中,达到临界时,传输时间与工作时间几乎成正比,而在改进的COT算法中,随着时间增加,传输时间是波浪状的,不会拥塞传输通道.同时可以看到若设置定时时间t越小,越可能达到最小传输时间值. 分析在图3的情况,我们知道了Improved_COT与传统的COT在传输文本时间上的差异,设每秒在每台机器上产生的操作数量为N,一起协同工作的站点数为S,在平均情况下,协同工作时间为T,服务器设定时间为t,传统的COT算法在C(O)的大小为N×S×T,而Improved_COT的C(O)大小是N×S×T-FLAGCO×(⎣T/t」),由上述算法可知,FLAGCO是服务器每隔时间t进行的一次标记操作,在本文设定无丢包环境下,所有操作可以被正确接受和处理,即FLAGCO是在时间t的范围内的一个值为N×S×t,综上得知Improved_COT的C(O)大小近似为N×S×t.一般情况下N和S是在一个变化不大的区间变化的可看作固定值,所以COT与工作时间T成一个线性关系,即传统的COT的空间复杂度为O(T),Improverd_COT是与t也是一个线性的关系,即空间复杂度为O(t),在进行OT转换操作并没有改变,进行OT的时间复杂度是跟C(O)有关的,所以传统的COT和Improved_COT在时间复杂度的一个考量上是跟空间复杂度一致的,随着时间的增大,传统的COT的性能将急剧下降,而Improved_COT的性能将是非常稳定的. 相比于在P2P环境下传统的COT算法,在云环境下Improved_COT算法有以下几点优势: 1.云环境下采用的集中式架构支持大量用户动态的在线协同工作. 2.随着协同时间的增加,Improved_COT算法可以有效的减少C(O)的长度,在云环境下,利用云的优势,将大量分析计算的工作集中在服务器端,各站点用户只需要处理长度很小的C(O)进行COT操作,这对整个实时的环境性能有巨大的提升. 实时文件管理系统允许多个用户同时操作同一文件夹节点进行操作,是典型的树形文档结构,针对基于操作转换的协同树形文档下的研究主要有:实时评论系统,协同办公系统等,实时协同评论系统最新的研究是复旦大学夏欢欢的移动云环境下的研究,文章主要针对移动性对多人评论保证数据的一致性做研究,同时提出了文献[15]在树形文档下的局部复制方案,协同办公系统下研究最新的技术是C.SUN的提出的文献[12],文中提出了在服务器端的文件和文件夹节点的四个操作,针对文件夹的新建,删除,改名和针对文件节点的更新操作,设计了操作转换算法来实现文件的一致性维护.由于文献[12]中已经对文件与文件间,文件与文件夹间,文件的编辑状态等冲突情况做过详细的论证和处理,本文主要是针对文献[12]中的文件夹节点及其三个操作将云存储下的模型转换到办公系统下的文件管理中来,在用户端和服务器端都实现文件的一致性维护,同时验证Improved_COT算法的可行性.本文的操作场景是基于文献[12]的文档模型下,下面本文将不再赘述具体的内容,只针对实例的改进和验证做出详细描述. 定义1. 树形文档复制空间 树形结构中各节点都是层次结构,节点之间够关联关系,T=(N),N是树中的节点,节点N={N0,N1,N2,N3…..}表示树形文档中各节点的集合,N.param= {name,PN,Depth}:表示节点N的属性集,name是节点名称,下面定义将对属性PN和Depth进行定义. 定义2. 层级(Depth) Depth是节点所处树形结构中的层级,根节点层级默认为0.层级是用来判断操作节点的位置关系的直接属性.先通过判断层级的大小来确定PN的关系,会大大提高检索效率. 定义3. 路径(PathName,简称PN)PN是节点Ni从根节点N0到Ni路径 路径是树形结构下的所有节点都具备的信息,本文定义的路径由根节点到上层父亲节点的路径加上该节点的名字命名组成,如图5中B节点的路径是A/B,B节点是D节点的父亲节点,D节点路径PN=B.PN+"/"+D.Name,路径是判断节点信息的唯一标识,假设有两个路径Ni.PN和Nj.PN有以下关系: rn1:Ni.PN= Nj.PN:表示指向相同的节点. rn2:Ni.PN∈Nj.PN:表示节点Nj是节点Ni的上层节点,如A/B/D 属于A/B,B是D的上层节点 rn3:Nj.PN∈Ni.PN:表示节点Ni是节点Nj的上层节点,如A/B/D 属于A/B,B是D的上层节点 rn4:Ni.PN≠Nj.PN&Ni.PN¢Nj.PN&Nj.PN¢Ni.PN:表示节点N1和N2直接没有直接关系,对节点操作没有影响,如B节点和F节点.对两个节点分别操作不会产生冲突. 图4 文件结构图Fig.4 File structure diagram 路径的确定是根据从根节点到当前节点的name加上“/”来确定的,路径的关系确定是根据字符串匹配策略来实现的,当两个字符串之间是包含关系,即一个字符串是另一个字符串的子字符串的时候,由上述定义2,3,算法如下: Algorithm7.PathRealtion(Ni,Nj) init(); if(Ni.Depth>Nj.Depth)//先确定层级大小关系 if(subString(Ni.PN,Nj.PN)==true) return rn2; else return rn4; else if(Ni.Depth=Nj.Depth) if(Ni.PN ==Nj.PN) return rn1; else return rn4; else if(subString(Nj.PN,Ni.PN)==true) return rn3; else return rn4; 根据文献[12]中提到的操作模型,依赖关系及冲突兼容操作,给定并发操作Oa和Ob分别操作于节点i和节点j.Oa在Ob后执行,在Ob的基础上对Oa进行操作转换,如此针对三种操作模型有9种转换函数,见表1. 表1中(表示兼容操作,(表示冲突操作.本文针对三大操作可能产生的几种冲突做出转换函数算法.上述各种情况是针对文件管理过程中的三个常见操作创建(create),改名(rename)和删除(delete)操作做出的符合文件管理系统策略的几种转换函数,不同于C.SUN的云存储下操作转换函数,本文没有针对文件节点作讨论,针对CSOT的转换函数,本文设计了一个新的属性depth来加快操作转换的速率,在一些特殊的场合比如depth相等,那么直接比较depth,可以直接判断出是非冲突操作,另外由于云的特性,在一些操作并发冲突时,解决策略是每个操作附加一个时间标量属性来进行判断. 表1 文件模型下create,rename,delete操作之间的冲突和兼容性表Table 1 Conflict and compatibility among create,rename and delete operations under file model 由于篇幅限制,这里给出两个操作转换函数的算法: Algorithm8.TR(dl,dl)(Oa=delete(Ni),Ob=delete(Nj)) if(i=j&&Ni.PN∈Nj.PN){ return null; }else return Oa; Algorithm 8中,若节点i是节点j的下层节点或者是同一节点,那么对操作Oa执行的效果就为空,其他情况为非冲突操作,执行效果不变. Algorithm9.TR(dl,rn)(Oa=delete(Ni),Ob=rename(Nj.nameold,Nj.namenew)) if(i=j) { return null; }else if(Ni.PN∈Nj.PN){ Ni.PN=**/Nj.PN/**; return delete(Ni) }else{return Oa;} Algorithm 9中,是在rename操作之上对delete操作做操作转换,当i和j是同一节点时,保留rename操作的效果,delete操作执行效果为空;当i是j的下层包含节点时,对Ni的路径进行修改,再返回正确的执行效果;其他情况,保留原始的执行效果. 本节针对上述在文件管理中的转换函数给出实例论证,如图5所示,给出两个客户端站点S1,S2和服务器端站点 S0,3个站点初始文档状态一致为如上图(1)所示,S1上给定操作O1= rename(N2.B,N2.K),将第三个节点的名字由B改为K,S2上给定操作O2和O3,O2= delete(N5),删除节点E,O3= create(N2,J),在节点B上创建进的子节点J.操作效果如图5所示. 站点1上先立即执行执行O1,此时文档状态DS={O1},在发送给服务器,接受来自服务的操作O2,O3,C(O2)={},根据COT的六条性质C(O2)包含DS但C(O2)≠DS,O2要与DS- C(O2)中的操作做操作转换,由上述算法 图5 C/S架构站点工作图Fig.5 Site work diagram under C/S architecture TR(dl,rn)判断O2′为先改变节点E的路径,在执行删除操作,当O3到来,C(O3)={O2},如上情况,DS- C(O3)=O1,由上述算法TR(cr,rn)对O3进行操作转化得到O3′为改变节点路径,再执行创建子节点操作,执行效果如图6. 图6 站点1 OT转换过程图Fig.6 Process chart of OT on site1 站点2上立即执行本地操作O2,O3,此时文档状态DS={O2,O3},在接收到来自服务器端转发S1的操作O1,C(O1)={},满足性质C(O1)DS但C(O1)≠DS,此时O1要与DS- C(O1)中的操作依次进行操作转换,由上述TR(rn,dl)和TR(rn,cr)得到O1′=O1,执行效果如图7.服务器端的操作执行顺序跟站点1的一致,这里不再说明. 图7 站点2 OT转换过程图Fig.7 Process chart of OT on site2 由上述可知,最后两个站点的文档结构一致,数据在不同站点的维护了一致性,由此可见算法是正确可行的. 本文是对文件管理中的三个基本操作create,rename,delete,利用Improved_COT算法来实现文件管理中的一致性维护研究的,为了验证算法的正确性,本文开发了基于webSocket协议的实时文件管理系统--CloudFileSystem来验证算法的有效性和正确性,CloudFileSystem是一个web环境的应用,本系统采用的SSM(SpringMVC+Spring+Mybatis)框架来搭建的一个web系统,通过部署到到tomcat上来实现访问,同时为了体现云特性,采用 Docker 技术在一台物理计算机上运行3个服务端程序. 服务器端设计:采用 Docker 技术在一台物理计算机上运行3个服务端程序,模拟云环境的分布式服务,利用eclipse IDE J2EE来作为开发环境,将项目部署到tomcat8.0上,通过网页来访问. 客户端设计:基于webSocket 协议设计的好处,传输效率高,速度快,CloudFileSystem利用SSM搭建框架,通过Jquery Ajax 来实现信息的传输,Ajax通过局部异步请求,大大降低了传输的代价,同时在文件的存放上利用datatable的设计来设计文件的存放,使得开发过程简介高效,CloudFileSystem的所示,输入正确的信息登录进入云系统后,点击协同文件管理进入到协同工作的环境,如图8所示.左边显示的协同在线的人,右边是协同工作的区域. 图8 系统设计图Fig.8 System design drawing 在系统设计中,针对转换函数中设计了两个接口,一个是路径的判断关系接口StringPathReation(FileNi,FileNj),获取两个文件节点,返回一个字符串,由该字符串判断两节点的路径关系;一个是操作转换的接口Operation TR(Operation c1,Operation c2),Operation类是操作的定义,根据操作c1和c2的操作类型调取相应的实现函数来实现操作转换. 本文在系统设计应用层协议采用的是WebSocket协议替代HTTP协议,在相关工作中提到实时协同工作要最好的达到实时性,在硬件条件一致的情况下,传输的文本要尽可能的小,由此提出了改进的Improved_COT算法,同时在发送消息过程中,HTTP协议带有一个相对重量级的表头,在实现实时传输是极不合适的,同时每次都会建立和释放连接也会浪费资源和时间,本文就WebSocket协议和HTTP协议的在传输操作的过程中进行了测试.实验效果如图9,图10. 图9 富裕带宽下HTTP与WebSocket协议对比图Fig.9 Comparison diagram of HTTP and WebSocket protocols under rich bandwidth 图9是在带宽为30MB/s的情况下进行的测试,HTTP协议中,在初始状态到一段时间,数据传输时间稳定在30ms左右,经过一定的协同工作时间,传输时间开始增大到了5分钟,10分钟时,数据又开始急剧减小到30左右;在WebSocket协议中图线中,就是上面的纵向平移下来,可知,由于HTTP协议每次传输都要建立和释放连接所消耗的时间. 图10 临界带宽下HTTP与WebSocket协议对比图Fig.10 Comparison diagram of HTTP and WebSocket protocols under critical bandwidth 在图10中,测试的是在临界带宽的情况下进行的,此时因为HTTP协议带有表头,协同工作开始后,数据的传输时间立马增加,没有平稳期,而在WebSocket协议的基础上,还是如图8所示,只是传输时间增大的临界点时间变长.数据量在协同工作中不总是那么稳定,因此数据会有波动. 因本文是改进的COT在两种协议之间的实验,服务器负载在服务器间隔时间t正常的情况下是比较充足的,为了验证在机器负载有限的情况下,WebSocket协议和HTTP协议之间的关系,本文适当的扩大了服务器时间t为原有的3倍. 图11 相同负载下下HTTP与WebSocket协议对比图Fig.11 Comparison diagram of HTTP and WebSocket under same server load 在图11中,可以看到两种协议都是协同工作时间的增加经过一段时间的线性增长后变成几何增长,但是HTTP协议则是比WebSocket协议更快的达到转折点,由此,相同负载下,WebSocket协议更有优势. 在第三章的测试中可以看到随着带宽的增大,传输的时间会趋近一个定值,在HTTP协议中,每次传输由都会建立和释放连接,浪费了时间和开销,同时服务器每次都会浪费时间和资源来进行头信息的解析,占用服务器资源,并且在传输文本大小上也越来越大.因此在应用层协议选择上我们选用了最新的WebSocket的协议来实现实时协同工作的交互. 本文针对云环境,实时性的特点在文件管理的基础上提出了改进的COT算法来实现文件管理三个基本操作rename,create,delete的一致性的维护研究,在云环境下,架构需要变化,由针对实时性的特点,使用了WebSocket全双工的通信协议,同时对COT中的C(O)进行了改进,使得一切都向实时性的方向靠拢,同时,在文件系统的树形结构模型下,为提高查找速率,对原有基于C.SUN的云存储的算法进行了改进,最后设计了一个CloudFileSystem来验证算法的正确性和有效性. 文件管理系统在云环境下的应用,实时性的保证都是研究的热点,然而在现实中很多情况是无法保证网络良好的情况,比如在移动环境下的研究,算法又需要重新设计来适应移动环境,同时在文件的存储上是否可以改用其他方式,比如利用哈希表来存放节点,这样可以快速定位到节点的位置进行操作,大大节约了时间,这样就需要重新设计数据结构来适应新的变化,这些都是以后研究的方向.3.2 Improved_COT算法分析
4 云环境下文件管理的一致性维护
4.1 数据模型
4.2 转换函数

4.3 实例论证
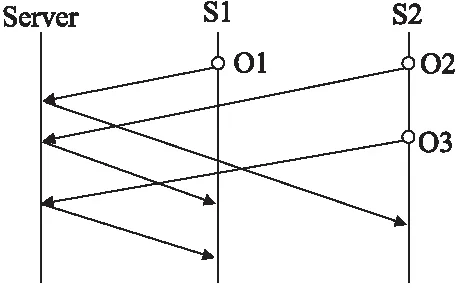

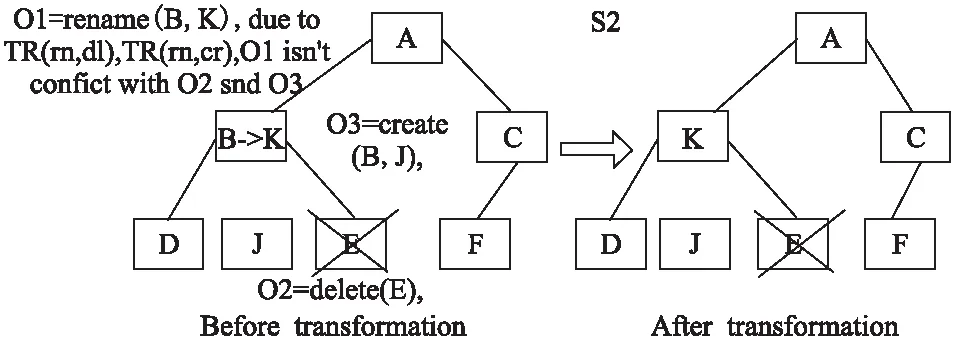
5 CloudFileSystem系统验证
5.1 基于WebSocket的系统设计
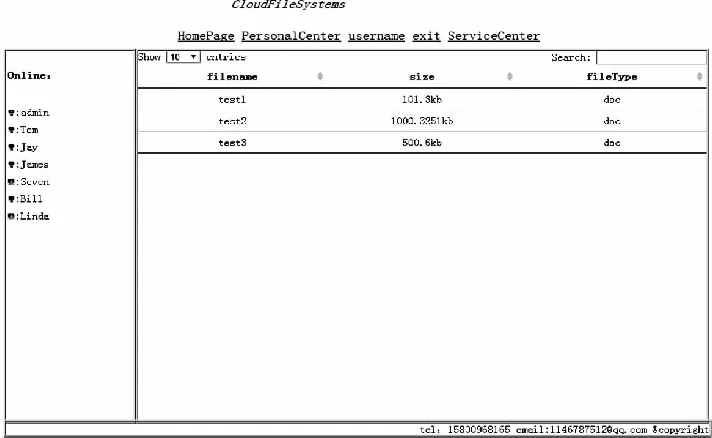
5.2 WebSocket与HTTP协议实验对比分析

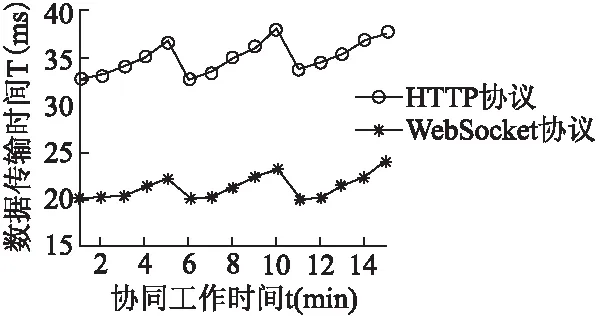

6 总结及展望
猜你喜欢
客联(2022年3期)2022-05-31中国新闻周刊(2021年26期)2021-07-27电子制作(2019年14期)2019-08-20党的生活·党员电教与远程教育(2017年9期)2017-10-17电脑爱好者(2017年7期)2017-05-06价值工程(2017年4期)2017-02-16东方教育(2016年15期)2017-01-16故事会(2016年21期)2016-11-10共产党员(辽宁)(2012年21期)2012-09-20
