
基于机器学习的5G系统智能公平调度算法研究
2018-10-25 10:27王辉静李坤颖
深圳信息职业技术学院学报 2018年5期
吴 舟,王辉静,李坤颖
(1. 深圳信息职业技术学院 中德学院,广东 深圳 518172;2. 深圳信息职业技术学院 计算机学院,广东 深圳 518172)
引言
针对未来宽带无线接入的需求,目前欧盟、中国、日本、美国等都启动了第五代移动通信系统的需求与关键技术研究[1-7]。5G已成为国内外移动通信领域的研究热点。
未来的5G网络可以通过对过去的行为模式、输出成果以及统一网络或者其它网络上的类似实体的行为进行学习,网络的决策质量将会持续提高。而机器学习和人工智能则是最佳的候选技术,可以为未来的5G无线系统提供更强大的复杂决策能力。在5G系统中,将会存在使用多种标准,多种制式的用户设备存在,比如4G、5G、wifi或者卫星通信等。同时不同标准和制式的用户设备的业务类型也不同,比如视频业务、直播业务、游戏业务等,那么采用什么样的机器学习算法能够在具有不同延时的用户设备当中智能选择用户设备进行调度,既能保证每个用户设备业务的服务质量,又能兼顾到公平性,这正是本文的研究目标。本文针对5G通信系统中由于每个用户设备的业务数据包长度、传输延时及信道环境不同导致的用户无法公平获得传输机会,提出了改进的k-means机器学习算法,能够在不同条件的用户设备当中智能选择用户设备进行调度,在保证每个用户设备业务的服务质量的同时,又能兼顾到公平性。
1 系统模型
5G系统高空平台端使用Massive MIMO多天线系统。本文假设高空平台端配有m根天线,地面小区中共有A个多用户设备,每个用户端配有n根天线,这A个用户均匀分布在小区中。同时假设发射机已知用户的信道信息。系统模型图如图1所示。
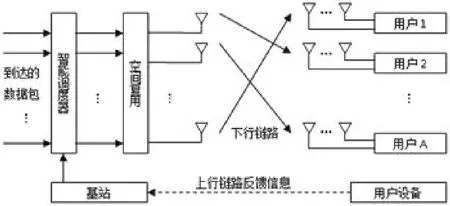
图1 基于机器学习的智能公平调度系统模型图Fig.1 System model of intelligent fair scheduling based on machine learning


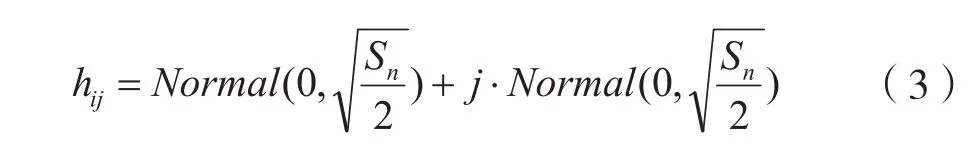
其中nS的均值等于路径损失,方差为nσ。
如前所述,在5G系统中,将会存在使用多种标准,多种制式的用户设备存在,每种用户设备的业务数据包传输延时都会有差异,这会给用户调度带来公平性的问题。本文提出了一种适合5G通信系统的多用户的智能公平调度算法,采用机器学习算法中的k-means非监督学习算法。因为传统的k-means算法对初始质心的选取是很敏感的,有可能造成局部最优解,为了克服这个问题,我们对传统的k-means进行了改进,提出了预处理k-means方法,k值的选取并不是随机选择的,而是在调度开始阶段先进行预处理训练,在一段调度时间中,按照系统所有待调度的用户设备的信道环境、业务数据长度以及平均传输延时(平均传输延时在训练阶段会动态更新),计算用户设备的调度优先级,按照优先级进行排序,从中选出前k个用户设备作为初始聚类点,预处理训练阶段结束,然后按照正常的k-means算法对后面新的待调度用户设备进行聚类,直到收敛为止。
2 基于机器学习的智能公平调度算法
2.1 预处理
为了克服传统的k-means算法对初始质心的选取是很敏感的,有可能造成局部最优解的问题,采用预处理方法,k-means算法的k值的选取并不是随机选择的,而是在调度开始阶段先进行预处理训练,在一段调度时间中,按照系统所有待调度的用户设备的信道环境、业务数据长度以及平均传输延时(平均传输延时在训练阶段会动态更新),计算用户设备的调度优先级,按照优先级进行排序,从中选出前k个用户设备作为初始聚类点,预处理训练阶段结束。
首先定义均衡矩阵G用于估计发射信号:
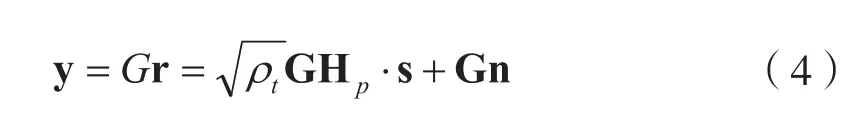
根据式(4)可以估计出用户的SNR:


由式(5)就可以得到用户设备a在该SNR下可以达到的传输速率,如下式所示:
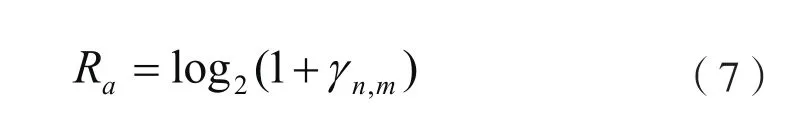
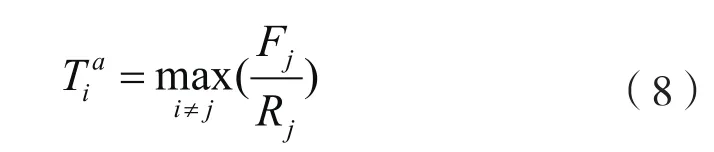
那么待调度用户设备的优先级按照下式计算:

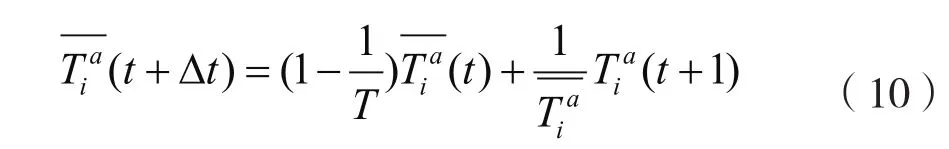
其中T是时间常数,为滑动时间窗口的长度。它反映了一个用户对接收不到数据传输的忍受能力,较长的T将允许等待较长的时间直到用户的信道质量变好,这有利于系统容量的提高,但是可能带来延时的增加。
按照公式(9)得到每个用户的调度优先级,按照优先级进行排序,从中选出前k个用户设备作为初始聚类点,预处理训练阶段结束。
通过预处理之后选择的k个初始聚类点是按照公平性准则得到的,保证了k-means算法的聚类结果是根据公平性来划分的,避免了因为随机选择初始聚类点造成的局部最优解问题。
2.2 k-means算法
采用预处理得到k个初始聚类点之后,下面按照正常的k-means算法对后面新的待调度用户设备进行聚类,直到收敛为止。算法步骤如下:

(3)重新计算聚类点坐标:

M为每个簇的用户设备数目,每个簇的数目不一样。
(4)重复第(2)和第(3)步,直到簇不发生变化或者达到最大迭代次数。
(5)按照分好的簇对用户设备完成调度。
本文提出的基于改进k-means算法的多用户智能公平调度算法流程图如图2所示。基于改进k-means机器学习算法能够在具有不同延时的用户设备当中智能选择用户设备进行调度,在保证每个用户设备业务的服务质量,又能兼顾到公平性。同时为了克服传统的k-means算法对初始质心的选取是很敏感的,有可能造成局部最优解的问题,采用预处理方法,k-means算法的k值的选取并不是随机选择的,而是在调度开始阶段先进行预处理训练,保证了能够得到全局最优解,使得机器学习算法收敛。

图2 基于机器学习的智能公平调度算法流程图Fig.2 Algorithm flow of intelligent fair scheduling based on machine learning
3 性能比较与分析
下面将对本文算法进行仿真实验,验证算法性能。我们采用文献[8]中的参数设置,信道的路径损失为0dB,阴影衰落为10dB。
我们假设每个用户的队列始终有数据包传送。为了分析本文智能公平调度算法性能,我们选择了两种经典的调度算法进行比较,一种是轮询算法(Round Robin,RR),另外一种是最大SNR算法(Max SNR)。

图3 三种算法系统容量比较Fig.3 System capacity comparison of three algorithms
图3 为三种算法在不同用户数下的系统容量比较。从图中可以看出,轮询算法的系统容量不随用户数目的增加而提高。而最大信噪比算法和本文的智能公平调度两种算法则随着用户数目的增加而增加,系统性能得到改善。
图4所示为三种算法在不同用户数下系统平均延时比较。从图中可以看出,本文的智能公平调度算法的系统平均延时最小,这是因为本文算法首先在预处理阶段按照不同延时对用户进行了初始聚类,然后采用k-means机器学习算法进行训练,使系统根据实际环境情况按照公平性原则对具有不同延时的用户进行选择调度,保证了每个用户的业务需求得到满足。

图4 三种算法系统平均延时比较Fig.4 Comparison of average delay of three algorithms
4 结论
针对5G系统多用户场景中由于每个用户设备的业务数据包长度、传输延时及信道环境不同导致的用户无法公平获得传输机会,本文提出了基于改进k-means机器学习算法,能够在不同条件的用户设备当中智能选择用户设备进行调度,在保证每个用户设备业务服务质量的同时,又能兼顾到公平性。在仿真分析中,采用了经典的RR和Max SNR两种算法进行比较。从仿真结果可以看出,三种算法中,本文的基于机器学习的智能公平调度算法具有最小的系统平均延时,并取得较大的系统容量。
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
自动化仪表(2020年10期)2020-11-13
电子制作(2019年14期)2019-08-20
电影(2018年8期)2018-09-21
制导与引信(2017年3期)2017-11-02
工业设计(2016年11期)2016-04-16
船舶力学(2015年6期)2015-12-12
环境科技(2015年6期)2015-11-08
电网与清洁能源(2015年2期)2015-02-28
