
基于电量离群点挖掘的窃电辨识方法研究
2018-10-22 11:32王伟峰
中国计量大学学报 2018年3期
李 宁,王伟峰,蔡 慧,汪 伟,王 颖
(1.中国计量大学 机电工程学院,浙江 杭州 310018;2.国网浙江省电力有限公司,浙江 杭州 310007)
随着国民经济和电力生产力的快速发展,使得电力消费者用电需求量与日俱增,与此同时,供电质量与用电营销管理已经成为一个非常重要的话题[1].
然而由于高科技窃电手段层出不穷,导致窃电问题变得越来越突出.据不完全统计,全国每年因窃电造成的经济损失达几百亿元,国家为此蒙受了巨大的经济损失.窃电不仅会使电力部门蒙受巨大损失,而且会严重危及到社会经济秩序的正常运行[2-3].
目前,大多数的反窃电产品都属于装置或设备,这些设备大多数缺乏自身防护能力,无人值守时难免窃电者在反窃电产品本体上动手脚.而数据挖掘在防窃电方面的研究和应用俨然已经成为一个热点,数据挖掘用于预测分析以及统计分析和汇总商业智能等领域[4-5].目前虽然也出现了一些诸如聚类[6]、分类、离群点检测等数据挖掘算法,但这些算法都存在各自的缺陷,无法很好地完成疑似窃电判别的任务.在这些算法中,离群点挖掘目前主要应用于经济、金融、入侵检测等方面[7-9],因此将离群点挖掘应用于防窃电检测更是具有研究的价值.目前在这个方面的研究中,文献[10]应用基于距离的离群点算法,针对欠压法和欠流法提出一种新的窃电辨识方法.但是,这种方法仅仅只针对欠压法和欠流法,应用范围有限.而且,对于三相电压、三相电流等多维数据,数据处理的复杂度会随着检测样本数据量的增大而增大.文献[11]中提出了通过对电压、电流海量数据进行曲线拟合,建立数学模型并引入基于正态分布的离群点算法,依据拉依达准则对海量数据进行数据挖掘找出窃电嫌疑户.但是,实际上很难用某个分布模型描述或统计用户用电量以及电压电流值的分布情况.
针对这些方法存在的不足,本文提出基于电量波动率和离群点挖掘算法结合的电量波动模型.这不仅是一种更加新颖的疑似窃电辨识方法,而且由于分析对象是一维数据,模型处理复杂度低、准确度高.它通过分析用户的历史用电量数据,挖掘出用户用电的行为特征,从而区别异常用电数据和正常用电数据,找到窃电嫌疑点.
1 离群点挖掘算法
离群点挖掘就是从大量的数据中自动或半自动地获得有用信息的过程,即给定一个有n个数据点或对象的数据集和期望的离群点个数k,找出与数据集中其余数据显著不同的、异常的或不一致的前k个对象.离群点挖掘问题可以被看作两个子问题:
1)准确定义离群点;
2)找到离群点挖掘方法.
离群点挖掘方法主要分为基于分布(统计)的、基于深度的、基于聚类的、基于距离的和基于密度的五类.五种离群点检测方法在不同领域均有应用,但都存在不足.基于分布(统计)的方法要求数据集合服从某一种概率或分布模型,基于聚类的方法对离群点的挖掘效率较低且依赖于所有簇的个数,基于密度的方法多应用于在局部离群点检测中,基于深度的方法对高维数据处理效率低[12-14].因此,基于距离的离群点检测方法应用于窃电的判定和算法实现中比较合适.而定义基于距离的离群点的方法主要有以下两种[15-16].
定义1如果数据集中至少有p(p∈[0,1])部分对象与对象o的距离大于D,则对象o是一个基于距离的关于参数p和D的离群点.反过来说,就是不多于(1-p)部分对象与对象o的距离小于等于D.
定义2数据集中到其第k个最近邻居的距离dk最大的前n个对象就是离群点.
2 电量波动模型
2.1 电量波动描述
本模型分析的对象是用户的日用电量数据,从电量波动着手,找到电量波动率与用户异常用电特征之间的关系.以往描述数据波动情况,大多是用方差、标准差、极差等,采用最多的是样本标准差.但是,需要对同一样本不同时期的波动情况对比时,缺乏可比性.当样本平均水平不同,用标准差是无法实现两组数据离散程度大小对比的.由于在本算法的思路中,需要对一组电量数据按月(或一段时间内)分别计算波动率再进行比较,因此用标准差就不适合.因此,在本文电量波动模型的研究中提出一种新的电量波动描述,即采用变异系数(或离散系数)CV来描述用电量数据的波动和离散情况,就很好地解决了上述的问题.
定义3变异系数CV定义如下:

(1)
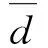
经过大量的研究分析得到:0≤CV<0.2时,为合理波动范围;0.2≤CV≤0.5时,为一般波动范围;0.5
变异系数一般是应用于金融、股票风险预测等方面,在电力行业几乎很少得到应用.本文是在大量的样本数据分析过程中,通过计算样本变异系数与算法窃电辨识结果进行综合分析设置波动范围,实际使用过程可以视具体情况作相应调整.
2.2 基于距离的离群点算法
基于距离的离群点算法是用距离来描述两个数据对象之间的相似程度,即两个数据对象的距离越大,说明两个数据对象相似度越小;反之,两个数据对象的距离越小,说明两个数据对象相似度越高.
由于算法分析的对象是用户电量,假设{x1,x2,…,xn}是由用电信息采集系统采集的一组用电量数组.描述两个数据对象之间的距离用欧氏距离来表示,对于两个一维空间样本g1(x1)和g2(x2),欧氏距离公式为
D(g1g2)=|x1-x2|.
(2)
对于n个样本,求两两样本之间的距离,可构成相似度矩阵来描述两两之间的相似度关系.本算法分析的用电量是一维数据,因此,本文采用的是一维欧氏距离.
描述n个样本两两之间的相似度关系可以用相似度矩阵(即欧氏距离矩阵)来表示,相似度矩阵如下:

(3)
其中,Dij表示对象i和j之间的相似度,满足正定性,即数据间的距离为非负,当且仅当i=j时,Dij=0;比较对象i和对象j,当它们相近或者是更加“接近”时,Dij→0;当它们的差异性越大,则该数值越大;并且满足对称性,即Dij=Dji.所以,相似度矩阵是一个以主对角线为轴的对称矩阵.
在完成了定义离群点的目标后,接下来更为重要的是如何进行离群点挖掘.以往算法中的离群点大多是作为负面的东西加以排除,而我们此处的离群点是用户是否存在窃电的有力判据,因此寻找一个有效且复杂度低的方法检测窃电嫌疑点就显得尤为重要了.本文提出的电量波动模型通过将电量波动率和改进的离群点算法相结合,很好地满足了上述要求.
首先,在计算和比较电量波动率的基础上,通过选取更加准确的质心来代表样本整体水平,然后比较单个样本与质心的相似度,以此来筛选离群点.基于电量波动的离群点算法框图如图1.
数据预处理一般包括数据清洗和归一化两个部分.数据清洗的规则如下:
规则一 各字段任一数据缺失即定义为数据缺失.如用户编码、总正向有功等;
规则二 在抄表数据中,将与终端电表采集的总正向有功数据进行清洗;
规则三 将标注不明确的数据视为无效并剔除,如未标明终端还是表计;
规则四 将样本数据中特别离谱的假数据(即异常偏高和值为负的数据)剔除.
总之,清洗后要保证用电量数据和相应的用电时间要一一对应.
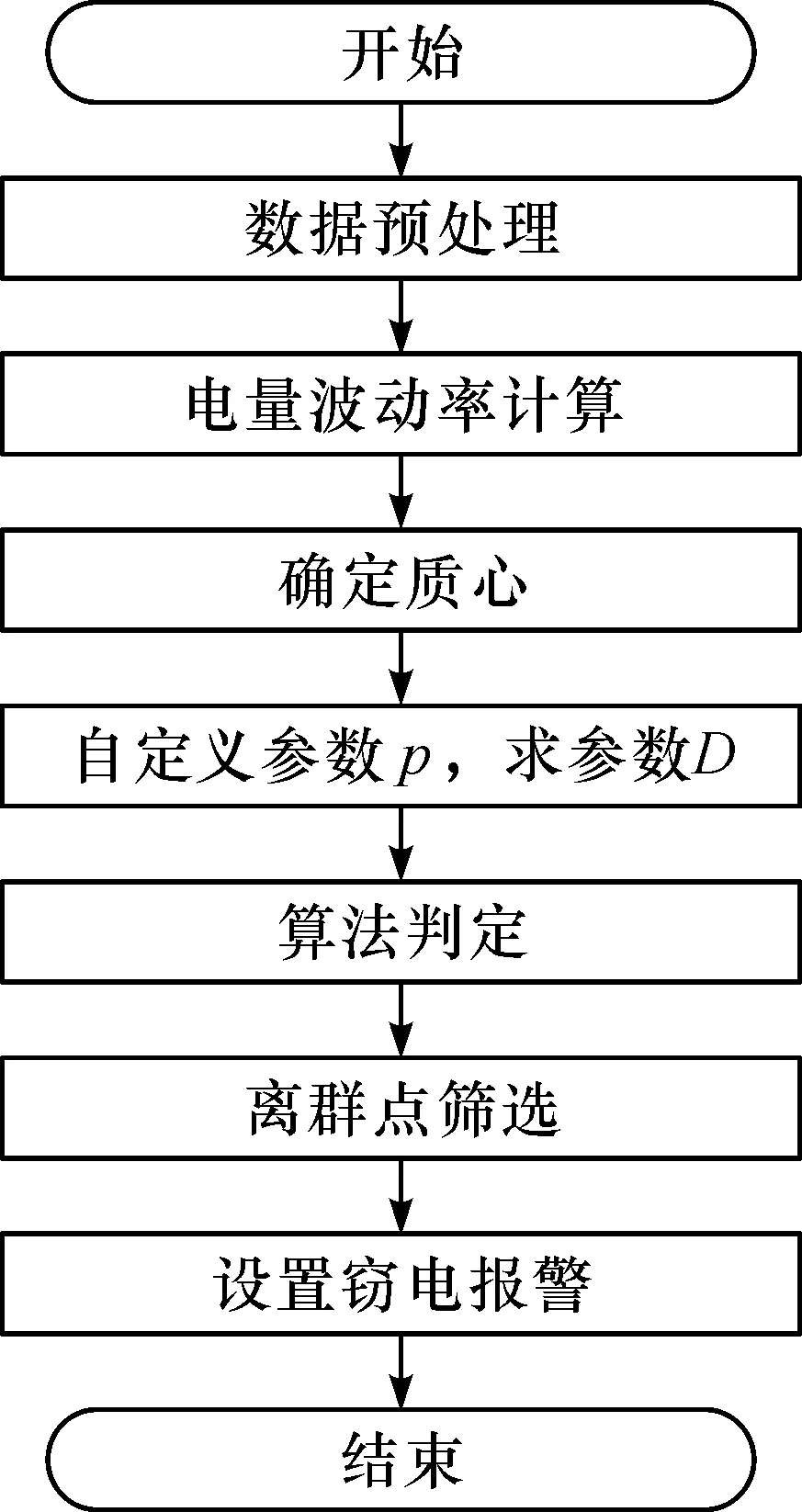
图1 基于电量波动的离群点检测算法流程图Figure 1 Flow chart of outlier detection algorithm based on electricity volatility
任意一天用电量的计算方法定义为
di=pi-pi-1.
(4)
式(4)中,pi代表第i天的表计总正向有功功率,pi-1代表第i-1天的表计总正向有功功率.
当样本数量庞大,需要对数据进行归一化处理,一般将所有样本化为介于0和1之间的数.一般的归一化方法如下:
.(5)
其中,x(i)代表任意一个样本值,min(x(n))代表样本最小值,max(x(n))代表样本最大值.
定义4基于电量波动率的样本质心avg2定义如下:
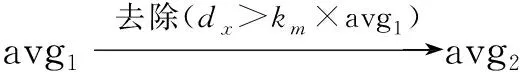
(6)
式(6)中,avg1为原始样本的平均值,avg2为去除所有dx>km×avg1的样本后的平均值.这样做的目的是排除异常偏高数据对窃电嫌疑点分析的影响.km为比例系数,根据定义3,按照单月(或一段时间内,具体时间长短可根据实际需求设定)计算CV,且将CVmin定义为所有CV≥0.2中最小的波动率.
变异系数越大,说明样本离散程度越大,一些不合理的数据距离合理的样本范围就越远,为了排除不合理的数据对整体样本的影响,需要根据定义5设置系数km.
定义5比例系数km定义如下:

(7)
需要注意的是,当CVmin≥0.8时,说明样本波动率过度严重,一般可直接进行窃电现场排查.这就是如前文所说,基于电量波动率可大大提高离群点检测和防窃电工作的效率.
在确定质心以后,下面就是进行离群点算法检测了,图2是离群点算法流程图.
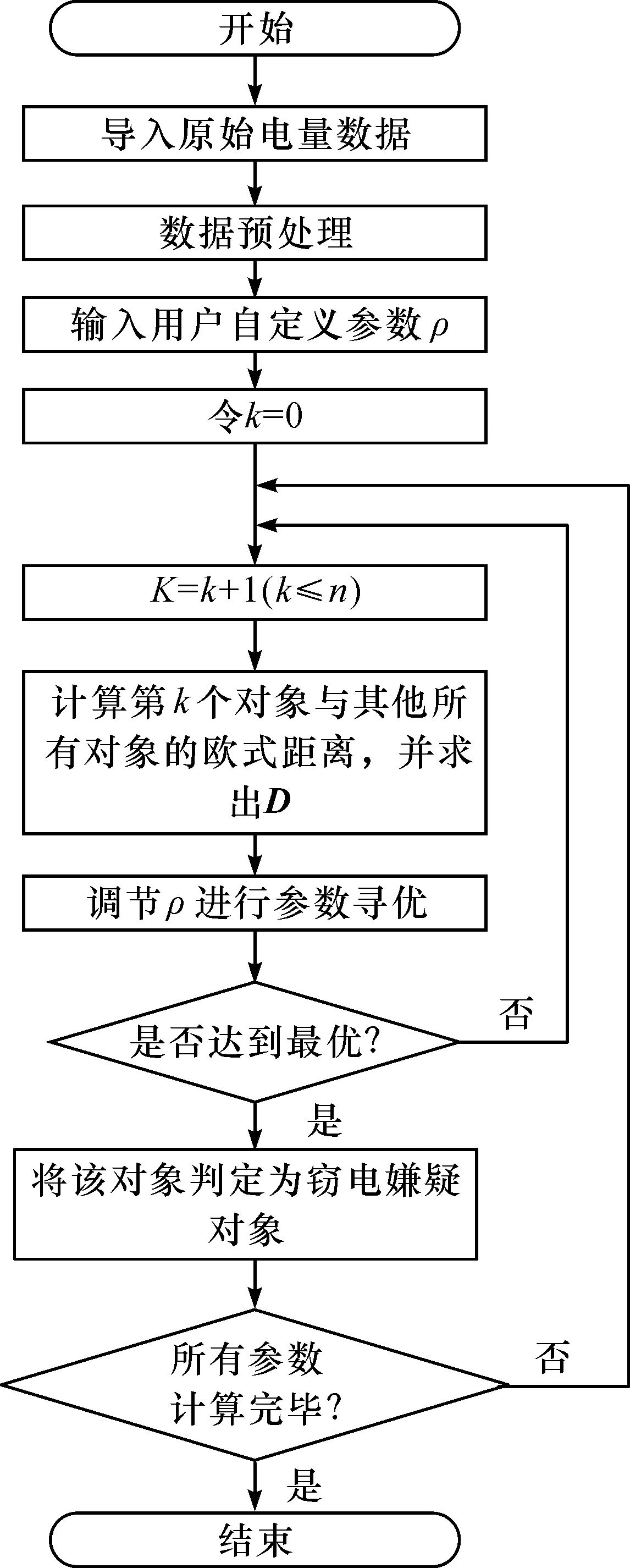
图2 基于距离的离群点算法流程图Figure 2 Flow chart of distance-based outlier algorithm
图2中,p参数一般会有一个可调的范围,即能够输出结果的参数范围.如可调范围为p∈[a,b],在可调范围内,设置p=b-0.01x,x为需要寻优的次数,利用循环实现寻优,观察离群点挖掘结果,最优挖掘结果对应的p就是最优的p.
3 算例分析
3.1 MATLAB计算分析
为了验证该算法在实际防窃电工作的准确性,选取由用电信息采集系统采集并经过清洗规则进行清洗之后的浙江省长兴县某化纤公司2016年5-7月共92 d实际用电数据如图3.该图显示的该公司总正向有功的真实数据.总正向有功是随着时间逐日进行累加的,当用户一直都是正常用电的话,总正向有功应该近似一条线性的直线,如果存在窃电导致表计功率减少,则这条近似直线的斜率会较小.显然,从原始的正向有功功率难以准确直观地判断出该公司在这三个月内是否存在窃电行为,以及在哪一天开始窃电.

图3 某化纤公司92 d的实际总正向有功数据Figure 3 The 92 days actual total positive active power data of a chemical fiber company
因此,下面运用本算法对该组数据进行处理和窃电分析.
首先,根据公式(4)计算出对应的日用电量数据.如图4,圆圈内有星状“*”填充的数据是检测出的离群点,很明显,离群点相对样本总体来说是小部分数据,这也正验证了“离群”的定义,它们与大多数样本的距离都很大.

图4 未考虑窃电实际的离群点检测结果Figure 4 Outlier detection results withoutconsidering the actual stealing situation
利用定义3的方法计算电量波动率可以得到:5月的电量波动率CV5=0.187 2,CV6=0.227 6,CV7=0.024 3说明7月电量波动极小,数据较平稳.
再根据上文所述的定义4以及定义5,CVmin=0.227 6,avg1=33.660 3,km=1.2,avg2=31.593 9,很显然,avg2更能代表样本总体的整体水平,说明质心选择的方法是可行的.
图4是单纯的离群点检测,并未考虑到窃电实际情况,因为窃电是不用电或少用电,所以用电量相较于正常情况应该是偏低的,故应该是将高于质心的离群点去掉.
如图5所示是考虑到窃电实际的离群点检测结果.由图可知,所检测出的离群点符合了窃电原理,而且在三个月的波动率中,6月的波动率最大,说明该月出现窃电的可能性也最大,而算法检测的窃电嫌疑点正是出现在6月,证明了算法检测离群点的准确性,也进一步佐证了基于电量波动的离群点检测算法相对于以往的窃电判别方法来说有一定的优势.

图5 考虑窃电实际的离群点检测Figure 5 Outlier detection results consideringthe actual stealing situation
在实际窃电判别中,仅仅出现一天或两天异常,其实并不能代表用户窃电,因为这种情况可能是由一些特殊的原因造成的.因此,此处我们设置了如果连续三天出现异常,第三天进行窃电报警的条件.如图6,第一次窃电报警的时间为“2016/06/08”,而实际查证的该用户开始窃电的时间为“2016/06/06”,与设置的窃电报警条件相符,进一步证明了该算法的可靠性.

图6 设置窃电报警条件下的结果Figure 6 The results of setting stealing alarm conditions
此外,需要说明的是,本次仿真实验中,离群点参数p设置为0.804 9,说明了所检测出的离群点具有很高的可信度,因为所有的离群点都满足至少有k=0.804 9×92≈74个样本与其本身之间的距离d>D=7.250 7.
3.2 算法分析结果与实际稽查结果比较
本算法的窃电分析结果是可以为一线员工的实际现场稽查提供理论依据的.依据算法分析结果,可以帮助稽查人员更有针对性地确定嫌疑用户的窃电时间,从而快速地实施窃电排查.
下面是利用本算法分析的一些案例结果与现场排查结果进行比较的情况,如表1所示.这一方面说明了本算法已经达到了比较理想的准确性.

表1 算法分析与实际排查情况对比
在实际分析中,共对若干个案例进行计算分析,这些案例包括纺织厂、丝绸厂和酒店管理有限公司在内的采用高供高计或高供低计的大型用电用户和一些低压用户.此处选取了10个案例分析结果如表1所示.结果表明,在10个分析案例中,当算法疑似度高于60%或是低于50%时,判断是否窃电与实际稽查结果相符合,而只有一组算法疑似度在50%~60%之间时,与稽查结果不符,准确度达到90%.当然,随着分析样本的增加,预计算法分析准确度还会增高,这说明了依据本算法,可以达到很好的窃电辨识效果,从而大大提高防窃电工作的效率.
4 结语
本文在深入分析窃电与防窃电现状以及了解窃电原理和常见窃电手段的基础上,提出了一种用于疑似窃电判别的电量波动模型.该模型结合了电量波动率和基于距离的离群点挖掘算法,是一种针对用户用电量分析的新的窃电辨识方法.首先,提出了一种新的描述电量波动的指标:变异系数,根据电量波动率选取样本质心,然后依据该质心和离群点原理筛选出离群点,并经过处理找到窃电嫌疑点,并设置窃电报警的条件.该算法不同于以往离群点算法仅仅依靠离群点定义来筛选离群点,更不同于传统防窃电算法仅仅依靠线损和电压、电流异常以及计量异常情况来判断是否窃电.应用本文这种模型进行疑似窃电判别,大大降低了数据处理的复杂度,提高了判别的准确性,进而提高了防窃电工作的效率.此外,将电量和电压、电流等负荷数据判别相结合,可进一步提高窃电判断的准确性.
当然,本算法仍旧存在一定的缺陷,即离群点参数寻优的过程是通过有限次调节p来完成的,当数据集为大规模数据集时,可能调节的p并不是最优.此外,样本质心除受到样本离散程度影响外,还需要考虑样本密度的影响,加上气候因素对用电量的影响也没有作充分考虑,因此模型还需要进一步地完善.
猜你喜欢
计算机与现代化(2022年10期)2022-10-18
军事文摘(2022年16期)2022-08-24
煤气与热力(2021年9期)2021-11-06
通信电源技术(2020年17期)2020-12-28
今日农业(2019年12期)2019-08-13
中国外汇(2019年23期)2019-05-25
文学少年(原创儿童文学)(2019年1期)2019-05-23
中国化肥信息(2019年3期)2019-04-25
小型微型计算机系统(2018年8期)2018-09-07
阅读(中年级)(2016年4期)2016-11-19
