
一种改进的实体关系抽取算法
——OptMultiR
2018-10-19 03:03延浩然靳小龙贾岩涛程学旗
中文信息学报 2018年9期
延浩然,靳小龙,贾岩涛,程学旗
(1. 中国科学院 计算技术研究所 网络数据科学与技术重点实验室,北京 100190; 2. 中国科学院大学 计算机与控制学院,北京 100049)
0 引言
近年来,互联网技术和应用模式的快速发展在改变人们生活方式的同时也产生了巨大的数据资源[1]。如何从网络大数据中获得有价值的知识,并对其进行深入的计算和分析,已成为国内外工业界和学术界研究的热点。在此背景下,知识图谱这一概念于2012年5月17日被Google正式提出,其初衷是为了提高搜索引擎的能力,增强用户的搜索质量以及搜索体验[2]。目前,随着智能信息服务应用的不断发展,知识图谱已被广泛应用于智能搜索、智能问答、个性化推荐等领域。其中关系抽取(relation extraction)与实体抽取等技术作为知识图谱的构建技术,受到了越来越广泛的关注。
以往的关系抽取算法大多使用全监督学习来实现,虽然全监督学习可以达到极高的准确率和召回率,其缺点也显而易见: 对于每一条训练数据,都需要事先进行人工标记。受限于此,全监督的学习方式很难应用到互联网产生的海量文本中[3]。在此背景下,远程监督(distant supervision),也被称为弱监督(weak supervision),成为了一种更为高效的学习方式。通过与已有知识库(如Freebase,Wikipedia等)的链接,远程监督模型会自动寻找知识库中存在的实体,并将原有文本转换为以实体对(entity pair)为基本单位的训练样本,然后参考知识库中实体对之间已经存在的关系进行启发式的抽取。由于省去了人工标注这一费时费力的过程并具有较高的迁移性,能够启发式地处理语料文本的远程监督,目前已经成为了较受欢迎的关系抽取方法。
远程监督这一概念最早于1999年被Craven和Kumlien提出[4],当时他们的研究目标是使用酵母蛋白质数据库作为知识库,抽取蛋白质与细胞、疾病和药物之间的二元关系。近年来,远程监督受到了广泛的研究和使用。2009年Mintz等人使用Freebase和Wikipedia中的文本作为知识库,创建了一种新的远程监督学习框架[5]。他们的假设是: 所有符合一对指定实体对的句子,都表达了这一实体对在知识库中的对应关系(而这个关系是唯一的)。2010年Riedel等人认为这一假设过于严格,他们将其改进为“对于特定实体对的所有句子中,至少有一句表达了知识库中的对应关系”[6]。把其中每一个句子看作是一个实例,每一个关系的抽取看作是一个标记,以上的学习方式都属于多实例单标记的远程监督关系抽取,即每个实体有且只具有一种关系。这显然是与客观事实相违背的,例如,“姚明曾是CBA篮球队上海大鲨鱼队的前任队员”和“姚明现在是大鲨鱼队的老板”两句话中,“姚明”和“上海大鲨鱼队”就存在这两种关系。在此背景下Hoffmann等人于2011年提出了一种多实例多标记算法—MultiR[7],该模型使用Freebase作为知识库,纽约时报中的内容作为训练文本。MultiR假定一对实体对中可以存在多个关系,每一个关于该实体对的提及(一个句子)都有可能表达任意关系,并建立了概率图模型进行求解。在此以后的远程监督抽取大多都基于多实例多标记学习这一假设作为基本模型进行求解[8-10]。
然而,MultiR算法还存在着两个主要的问题。首先在抽取打分的过程中,算法没有利用待抽取的关系与实体对在知识库中的已知关系之间存在的联系,从而导致一些出现次数少的文本特征对抽取结果产生了噪声干扰,使得算法抽取出的是实体对根本不可能存在某种关系。其次,在概率图匹配的计算过程中,MultiR使用的贪心算法会受到枚举顺序的影响,且该方法只能求得较优解,无法达到全局最优。
本文针对上述问题,对MultiR算法主要进行了两点改进:
(1) 考虑到特定实体对存在的关系之间具有一定的联系,本文提出了关系权重矩阵模型,在模型进行抽取打分的过程中加入关系间的权重影响,通过权重向量去降低个别文本特征带来的噪声干扰。使得新的算法不再会抽取出实体对不可能存在的关系。
(2) 针对概率图匹配中存在的问题,本文采用了基于状态压缩的动态规划算法来代替原有的贪心算法进行求解,新算法可以求得原概率图匹配问题的最优解,且后续的实验也证明了该算法在实验复杂度上的增加仅为常数级。
1 MultiR模型
本节将对MultiR模型及其存在的问题进行简要阐述。
1.1 模型概述
基于多实例多标记抽取模型的思想,MultiR使用了条件概率模型来定义以上所有待抽取的随机变量的联合分布,其抽取模型平面图如图1所示。
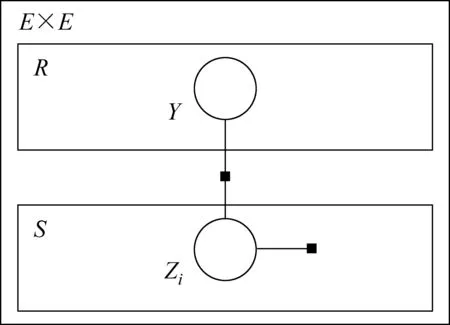
图1 MultiR模型示意图
本质上来说,它训练了一个从文本特征到关系的参数矩阵。在每一次训练迭代中,通过对每一个实体对(e1,e2)中的每个句子(提取成文本特征向量)xi抽取出一个隐含变量zi=r∈{r∪None},代表这个句子表达的关系,通过对所有的zi进行去重统计,得到一个布尔型数组Y′,其中Y′r表示关系r是否被实体对(e1,e2)表达。通过对关系库中该实体对已知的关系集合Y的对比,MultiR在每一次迭代中对该句子中的文本特征参数进行梯度修正,直至模型收敛。
具体算法实现如下:
initializeparameter verctor Θ←0
fort=1...Tdo
fori=1...ndo
(y′,z′)←arg maxy,zp(y,z|xi;θ)
ify′≠yithen
z*←arg maxzp(z|xi,yi;θ)
Θ←Θ+φ(xi,z*)-φ(xi,z′)
endif
endfor
endfor
ReturnΘ
对算法的进一步解释:
最外层循环T表示了迭代次数。内层循环变量i枚举了每一个实体对(e1,e2),首先计算使用维特比估计的z和y,此处的抽取不使用知识库中的关系作为先验知识而全靠特征和关系之间的参数θ进行抽取,将此次的抽取结果z′通过去重转换为关系向量y′,并与知识库中该实体对已知存在的关系向量yi进行对比,如果存在偏差就去计算第二种假设以进行修正。在第二种假设的计算中,yi将作为先验知识,求得的抽取结果记为z*。在本次迭代的最后,模型对θ进行更新,对于z*和z′中存在差异的句子,模型会更新该句子对应的特征向量,使其向z*抽取的关系靠近,并且远离z′抽取的关系。
1.2 模型存在的问题
1.2.1 抽取过程中产生的噪音
上文中提到,MultiR模型本身只考虑文本特征到关系的映射,并没有考虑实体对本身或者关系库本身带有的额外信息,这是对已知资源的一种浪费。此外,一些出现次数极少的文本特征会对抽取的结果产生比较严重的噪声影响。如果某个文本特征在整个训练集中仅出现过一次,那么它会被赋予一个特定的关系极大的权重,以至于以后该特征出现的句子会被以极大的概率抽取为这个特点关系。
另外,本文对测试集上抽取错误的句子进行了人工分析。通过对这些错误抽取的结果进行分析,可以得出如下结论: 有一定数量的句子被抽取出了该实体对几乎不可能存在的某种关系。例如,“中国政府将向南苏丹提供500万美元紧急援助”这个句子中由于存在“美元”“援助”等词汇,容易被抽取成某个子公司关系或者其他商业性的上下级关系,但实际上“中国”和“南苏丹”作为两个国家,不会存在这样的关系。
1.2.2 条件推论计算问题
条件推论的计算p(z|yi,xi;θ)要求在已知条件下,每一个先验关系yij都必须被xi中的某个句子抽取到。为了计算该抽取结果,MultiR构建了一个概率图模型,以寻找最符合yi的z的分布,这个问题也就被转换为了不同权重下图的边覆盖问题。
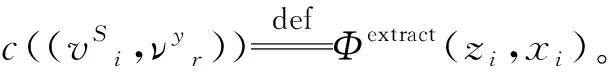
图2 条件推论匹配问题示例图
在求解该问题上,MultiR模型使用了一种求近似解的贪心算法,其策略如下: 首先枚举νyr∈νy,对于该关系点,选取未被其他关系点中与它边权最大的句子点,并将其标记为选取状态。在所有的关系点都有句子点对应后,对于还未选取的句子点,模型选择边权最大的关系点作为它的抽取结果。原模型贪心匹配策略计算的时间复杂度是o(|r||s|),其中|r|是该数据包在关系库中的关系数量,|S|是数据包在训练数据中的句子数。
在原模型中,该贪心算法取得了一定效果。但本文认为该方式存在比较明显的问题。首先,求解的匹配值仅仅是较优解,而非最优解;其次,这样的求解方式严重受枚举顺序的影响,如果更改枚举点的顺序,有极大的概率会导致完全不同的匹配结果。因此本文认为这样的求解方式还存在着比较大的改进空间。
2 改进模型OptMultiR
2.1 关系权重矩阵
针对1.2.1节中提到的问题,本文认为在远程监督中知识库本身就是一个丰富的高可信度的基础数据来源。举例来说,当A分别与B和C之间存在某种亲属关系时,B和C之间也更可能被抽取出亲属关系,而非同事关系。因此我们可以在模型训练开始之前利用实体对在知识库中已有的关系预先生成一个权重矩阵,当对某个实体对的某个句子进行关系抽取的时候,使其更倾向于抽取出其在知识库中存在的关系,或是与这些关系近似度比较大的关系。
2.1.1 相关定义
下面对权重矩阵W|R|*|R|进行定义,第i行表示了关系i与其他关系的权重向量,其中
(1)
表示了关系i和关系j之间的相关性(权重),数值越大相关性越强。其中决定关系Ri与Rj关系权重的是在训练数据中同时拥有它们两个的实体对Et的数量。这里模型引入了一个超参数δ∈[0..1),δ值越大,模型就认为关系之间的相关性越强(抽取的新关系越往已知关系上靠拢),δ越小表示模型越不重视关系之间的相关性(在抽取的时候也就可以更倾向于打分的结果,有更大的概率抽取出新关系)。
当对某个实体对(e1,e2)的某个句子s进行关系抽取的时候,首先像原模型一样通过维特比算法对每个关系进行打分,获得一个长度为|R|的打分向量Score。然后找到(e1,e2)在知识库中存在的关系集合Y,计算权重向量Weight,其中
(2)
最后句子s抽取出的关系r的编号sr的计算如式(3)所示。
sr=argimax(Weighti*Scoreii∈|R|)
(3)
2.1.2 对NA关系的特殊处理
现在重新考虑关系权重矩阵模型。在该模型下,所有的关系大致可以被分为三类: ①非独立关系。这个集合下的关系或多或少都曾与该集合中的其他关系在一个或多个实体对中共同出现过,在某个句子的抽取过程中,它们会有较大的概率获得更大的权重Weight,也就更容易被抽取出来,因此它们是关系权重矩阵中的“获益者”。②独立关系。这个集合中的关系从未与其他关系共同出现过,它们所出现的实体对在知识库中的关系集合只有一个元素——它们自己,因此这些关系的权重永远为1(归一化前)。③NA关系。NA关系并不会与任何关系共现,它是绝对孤立的一种关系。严格意义上来说,NA表示的不是一个关系,而是一个实体对真实存在的关系集合减去知识库中存在集合的子集。
基于上述情况,不难发现独立关系集合中的关系和NA会被判定为同等权重大小(值均为1)。然而知识库是不完备的,在现实情况下这些关系可能确实与其他关系共现过却并未被知识库记录,在此情况下模型依旧赋予了其与NA相同的权重,等同于降低了该关系被抽取出的概率,变相提高了NA关系被抽取出的概率,从而使得模型的召回率降低。
因此本文进行如下修改: 针对NA关系的Weight,将其乘以一个新的超参数α∈[0..1]以平衡知识库的不完备性带来的影响。从实验表现来看,该假设非常具有实际意义。
2.2 基于状态压缩的动态规划算法
为解决1.2.2节中提出的条件推论求解过程中存在的缺陷,本文使用基于状态压缩的动态规划算法来求解,以较小的时间代价求得该问题的最优解。
设x是一个自然数,它表示了所有的关系被选与否的状态,其中x的二进制表达如下: 第i-1位表示了第i个关系是否被选取,1表示已经被选了,0表示没有被选。设总关系数一共有m个,则x的取值范围是[0..2m-1],0为初始状态,表示没有关系被选择,2m-1是算法要达到的最终状态,表示所有关系都已经被选择。对于第i个关系来说,它只能从满足x&2i-1=0的x去转移(“&”表示位运算“与”操作),代表着x的第i-1位还是0,也就是说在这个x下第i个关系还没有被选择。
下面给出动态规划转移方程: 设f(x,y)表示x状态下选择到第y个句子,整个模型获得最大权重,转移方程如式(4)所示。
(4)
转移方程含义: 在x状态下仅考虑是否要把第y个句子匹配给第k个关系,如果匹配,总权重就要加上它们两者之间的边权。当然,这里转移的一个重要条件是x&2k-1=0,表示x状态下k关系还没有与句子点匹配过。如果不去匹配,那么加入与第y个句子点权重最大的边权即可。
有一种特殊情况是句子点的个数小于关系点,这种情况下显然无论如何难以满足上述的匹配条件。对于该情况,本文依旧使用枚举句子点,为每个句子点找到一个还未被匹配过的边权最大的关系点的贪心算法。事实上,出现这种情况的数据集并不多,对总体的影响不大。
新的匹配算法匹配一个实体对的时间复杂度是O(2|R-1||R||S|),乍看起来相比于原模型的复杂度O(|R||S|)来说增加了一个指数级参数2|R-1|。实际上通过对数据的观察发现,对于一个实体对来说,其知识库中可能拥有的关系一般在1到2个,最多不会超过5个,而句子数受训练文本规模的影响可能是成千上万条。因此2|R-1|可以被认为是一个小于等于30的常数,其大小只受选取知识库内容的影响,而当训练数据足够大的时候|S|会随之线性增长,相比起来2|R-1|的影响因素可以说是微不足道了。表1记录了不同数据量规模下两种算法模型训练过程的耗时对比。

表1 训练耗时对比表

续表
综合来看,使用状态压缩的动态规划算法去计算条件推论,时间上并未有太大增加,求解值却能从近似解优化到最优解,因此可以被认为是比较有效的优化。
3 实验
为比较本文改进的OptMultiR模型相对MultiR模型的性能提升程度,本文采用与验证MultiR相同的实验数据。这个数据集最初由Riedel等人在文献[6]中生成。其中训练语料选取的是纽约《时代周刊》自1987年1月1日至2007年6月19日的约18万篇新闻。观察发现,这些新闻中的实体和关系与Freebase知识库契合度较高,因此选用该知识库进行远程监督可以取得较好的效果。
关于评价指标,本文采用了聚集抽取和句子级抽取两种不同的评价体系。
3.1 参数选择
在我们的模型OptMultiR中,存在两个超参数,一个是关系权重矩阵中的影响因子δ,另一个是对NA关系赋予的α。首先本文进行相关实验分析其性质,并根据相关评价指标确定最优的参数取值。
通过比较几组不同参数组合的PR曲线,本文发现仅比较曲线的最大准确率、召回率或F1值都是不够精确的。在某些参数组合下,整个模型的置信度体系会失效,从而导致图像在召回率<0.05之前就产生了低于原MultiR的准确率,从而与原图像产生交叉,显然这样的参数是不可取的。因此本文决定选择PR曲线与坐标轴围成的面积大小作为性能优劣的评价指标,并且仅考虑在任意召回率下,准确率均优于原模型的PR曲线,即
通过对δ不同取值下模型性能的分析,本文发现当δ过大时,关系权重模型会导致已有关系的Weight过大,使得整个算法在抽取过程中很难抽出新的关系,因此本文对参数选取的取值范围如下:
通过实验,以上121种组合中仅19种符合要求,本文对剩余的参数组合及其曲线围成的面积进行了排序,结果如表2所示。通过排名我们最终选取面积最大的参数组合作为两个超参数最终的值(δ=0.008,α=0.3)。

表2 超参组合面积排名表

续表
3.2 聚集抽取
聚集抽取是远程监督方法下的关系抽取算法最常用的一种评价体系。在该评价方法下,考察的是对于每一个实体对(e1,e2)的所有句子s1,…,sn,其构成的整体的抽取结果集合Y′是否与实体对在知识库中已知的关系集合Y一致,不考虑具体句子抽取的准确性。
在整体抽取的评价中本文选用的对照算法有:
(1) Mintz: Mintz等人于2009年提出的单实例单标签抽取算法[5]。
(2) MultiR: Hoffmann等人于2011年提出的多实例多标签算法,本文用来改进的原型算法[7]。
(3) MIMLRE: Surdeanu等人于2012年提出的多实例多标签算法,相比于MultiR它进行了更少的假设,对每一个关系都有单独的分类器[8]。
聚焦抽取结果对比如图3所示。通过图3可以看到,在相等召回率的情况下,OptMultiR相比其他算法在准确率上都取得了更好的结果。各算法F1分数取得最大值时的准确率和召回率结果如表3所示,可以看到OptMultiR均取得了最好的结果。

图3 聚集抽取结果对比图

Precision/%Recall/%F1/%Mintz26.1722.6724.29MultiR32.0524.0527.48MIMLRE32.9220.5625.32OptMultiR34.0026.1029.53
3.3 句子级抽取
仅进行聚集抽取的评价是不精确的,本文还需要考量对于每一个句子来说关系抽取结果是否准确。Hoffman等人在MultiR的实验中选取了一部分句子并对其抽取关系进行了人工标注[7]。以下实验中均采用该人工数据集与MultiR进行句子级对比。图4即为在该数据集下针对每一条句子OptMultiR与MultiR的抽取效果对比。在召回率最高的点上,原MultiR达到了72.4%的准确率和51.9%的召回率,对应的F1分数是60.5%。而我们优化后的OptMultiR取得了79.57%的准确率以及59.55%的召回率,对应的F1分数是68.12%,各项指标均优于原模型。此外我们还对新模型中加入的两个超参进行了观察,图4中另外两条线对应的是OptMultiR模型仅使用超参δ=0.08或超参α=0.3时的PR曲线。从图像中我们可以观察到,仅仅使用关系权重矩阵(δ)的确带来了准确率的提升,同时由于先验知识的影响其召回率大幅下降,与此对应的是仅考虑NA关系的不完备性(α)而不使用关系权重矩阵的情况下,准确率产生了大幅下滑甚至会低于原模型,但带来了最大召回率的提升。因此将两者进行适当结合才能互相弥补,取得整体性能上的提升。

图4 MultiR与OptMultiR句子级抽取对比图
3.4 特定关系上的表现
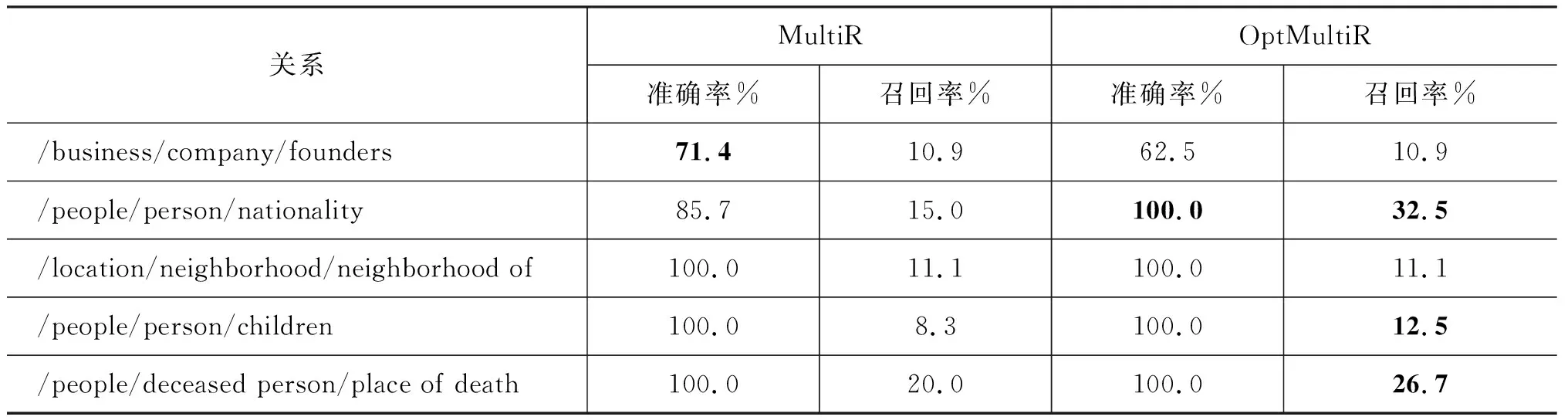
考虑到数据集中的句子关于不同关系的分布数量是不平衡的,本文额外对出现数量比较大的八种关系的抽取表现进行了对比。同样考虑到知识库的不完备性,本文选取了100条句子作为测试数据并进行了人工标注以保证其正确性。对这九个关系的抽取结果见表4。

表4 在特定关系下的抽取结果对比表
续表
可以看到除了关系founders的准确率以外,优化后的OptMultiR对本文选取的常见关系在准确率和召回率上都有了显著提升。关于关系founders,它的准确率由71.4%降为62.5%,通过观察实际样本得出的结论是,这些未被发现的样本标注为了NA。这也就意味着对于founders这个关系来说,模型要更加弱化NA关系以提升其准确率,这也反映了模型存在的一个不足,那就是对于所有的关系来说NA系数α是共用的,显然关系库中关系的不完备性是不尽相同的,如何改善这一缺陷也是本文未来工作的一项目标。
4 总结
关系抽取这一构建知识图谱的关键技术,已经经过了十几年的发展。从最初基于人工模式匹配的方式,到后来机器学习热潮的涌现,再到远程监督方法的流行[11-12]。在此过程中抽取模型也从单一标签进化为多实例多标签学习,本文选取了经典的多实例多标签算法MultiR并对其进行优化。对于模型本身,本文引入了独立的关系权重矩阵模型干预抽取的打分过程,使得抽取的关系更为精确。在从实现方式上,本文使用基于状态压缩的动态规划算法,求得了概率图计算问题的最优解。从实验结果来看,无论是整体的表现性还是对于高频出现的关系,优化后模型OptMultiR的抽取能力都远超过原模型,性能取得了显著的提升。在今后的工作中,我们会继续依据关系之间的相关性对模型进行优化,并且尝试减少模型中的超参带来的人为干扰,以增强系统的鲁棒性。
猜你喜欢
心理学报(2022年5期)2022-05-16
北京大学学报(自然科学版)(2022年1期)2022-02-21
当代陕西(2020年17期)2020-10-28
中国外汇(2019年18期)2019-11-25
制造技术与机床(2019年6期)2019-06-25
人大建设(2018年5期)2018-08-16
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
中国交通信息化(2016年9期)2016-06-06
