
异质信息网络中基于元路径的社团发现算法研究
2018-10-19 03:03郑玉艳王明省
中文信息学报 2018年9期
郑玉艳,王明省,石 川,王 锐
(1. 北京邮电大学 计算机学院,北京 100876;2. 广州市城市规划勘测设计院 地理信息中心,广东 广州 510060)
0 引言
互联网技术的迅猛发展使得社会网络分析得到了广泛的研究。当前的社会网络分析主要基于同质信息网络,即关系网络中节点或边具有相同的类型。例如,图1(a)的作者合作网,节点类型都是作者,边的类型都是合作关系。然而,随着在线社会媒体、信息物理系统的大量出现,对象相互关联形成的复杂网络很难用同质信息网络建模,而是需要建模成异质信息网络。这种网络包含不同类型的对象,对象之间的关系表示了不同的交互语义。例如,图1(b)表示了科技文献数据中包含的对象和它们之间的关联。通过抽象对象和它们之间的关系可以构建如图1(c)所示的网络模式。该数据的对象类型包括作者、论文、会议和术语,这些对象之间存在不同语义的关系: 作者和论文之间的撰写关系,论文和会议之间的发表关系,论文和术语之间的包含关系。元路径可以捕捉这些丰富的语义信息[1-2],从而产生更有意义的知识发现。自从数据挖掘领域专家Jiawei Han和Philip S.Yu等于2009年开始倡导异质信息网络分析的研究[3],指出异质信息网络无处不在,对这类网络进行分析是数据挖掘领域重要的研究方向[4],异质信息网络分析就吸引了越来越多的研究者的关注,成为逐渐兴起的研究热点。在数据挖掘、数据库、信息检索等相关领域的一流的国际会议上出现了越来越多的关于异质信息网络分析的文章,例如文献[1,5-6]。目前,异质信息网络中的很多数据挖掘任务(如相似性度量、聚类、分类等)都已被研究。

图1 由科技文献数据构建的同质和异质信息网络。
社团发现是根据已经观察到的网络的结构信息及对象的属性信息来预测网络的社团结构,它是社会网络分析的一个重要任务[7]。通过社团发现可以将一个大的网络划分为多个小的节点的集合,使得同一个集合中的节点之间的关联相对紧密,而不同集合中的节点之间的关联相对稀疏。我们称这些小的节点的集合为社团。社团发现可以帮助我们更好地理解网络的拓扑结构及社团的进化过程。社团发现已有很多应用,例如,在文献网络中,可以探测作者的社团结构,进而预测作者之间未来的合作关系;在推荐系统中,可以探测出用户的社团结构,将属于同一个社团的其他用户购买过的商品推荐给当前用户。
目前,同质信息网络中的社团发现已经被深入研究,其中最常用的社团发现算法有基于标签传递的算法[8-11]和基于模块度优化的算法[12]。基于标签传递的算法简单、易于实现,并且拥有线性的时间复杂度,但是由于节点更新顺序的随机性等原因,使得该算法的结果随机性较大;而基于模块度优化的算法通过不断优化模块度,能够保证得到较稳定的社团探测结果。这些方法都是针对同质信息网络进行的,针对异质信息网络进行的社团发现研究相对较少,而实际的网络化数据往往包含多种类型的对象和关系,建模成异质信息网络可以更全面地包含这些丰富的信息,进行更准确的社团发现。
本文主要研究异质信息网络中的社团发现问题,关键在于如何充分利用异质信息网络包含的丰富的结构信息和语义信息来进行更准确的社团发现。例如,在文献网络中,要充分利用网络中包含的论文作者关系、论文会议关系等来提高社团发现的准确率。因此,本文提出了在异质信息网络中进行社团发现的方法HCD,通过使用异质信息网络的独特属性——元路径,来捕捉异质信息网络中丰富的语义信息。HCD主要包括基于单条元路径的社团发现算法HCD_sgl和融合多条元路径的社团发现算法HCD_all两部分。首先,将异质信息网络基于给定的元路径映射为同质信息网络。然后,根据设定的规则找出在网络中有较大影响力的种子节点,构建种子节点网络,并选择有较高准确性和稳定性的社团发现算法确定种子节点的社团标签。之后再根据网络结构及节点间的相似性,确定非种子节点的社团标签。最后在各条元路径对应的同质信息网络中执行改进后的标签传递算法,得到基于每条元路径的社团发现结果,将基于各条元路径的社团发现结果进行整合,得到异质信息网络中的社团发现结果,并在真实数据集和人工数据集上验证了所提方法的有效性。
本文其他章节安排如下: 第一节介绍了与本文相关的工作;第二节详细地阐述了本文提出的基于元路径的社团发现方法HCD;第三节对实验及结果进行了详细描述;第四节总结全文并对下一步工作进行了展望。
1 相关工作
社团发现作为社会网络分析的一个重要任务,得到了广泛的研究。目前,已经有大量的社团发现算法被提出。这些算法主要分为如下四种类型: 基于图划分的社团发现算法,基于模块度优化的社团发现算法,基于遗传算法的社团发现算法和基于标签传递的社团发现算法。
(1) 基于图划分的社团发现算法是将图划分为多个组成部分,使得各个组成部分内部之间的连接尽可能的多,各个部分之间的连接尽可能的少。例如,Kernighan-Lin算法[13]通过将图划分成多个子集来最小化图划分过程中边权值的损失,其中每个子集的大小等于预先设置好的一个值。Newman[14]通过将随机分块模型映射到最小割图划分问题来进行社团发现。
(2) 基于模块度优化的社团发现算法主要是将Newman等[12]提出的用于衡量社团发现质量的评价指标模块度作为优化目标,采取不同的优化方法使模块度不断增大,从而得到最终的社团发现结果。它主要有聚合和分裂两种类型,Newman提出的快速社团聚类算法[15]是经典的聚合算法,该算法通过沿着模块度增长最多的方向合并社团来优化模块度。Newman和Girvan提出的GN算法[16]属于分裂算法。该算法不断地移除边介数最大的边,直到每个节点都成为独立的社团。在移除边的过程中,对应模块度最大时的社团结构即为最终的社团发现结果。Blondel等[17]提出了一种新的算法BGLL,它通过两个阶段不断迭代进而获得最终的社团发现结果。第一阶段不断将节点移入能使模块度增长最大的那个社团来获得社团探测的结果,第二阶段将探测出的社团当作一个新的节点,重新构造网络。
(3) 遗传算法是模拟生物进化规律而演化来的一类启发式搜索算法。遗传算法在开始时有一组候选解,通过计算各个候选解的适应度函数,淘汰掉适应度低的那些候选解,并通过交叉变异操作生成新的候选解,直到找到问题的近似最优解。近年来,遗传算法被应用到社团发现和社团分析的研究当中。Pizzuti提出了GA-Net算法[18],该算法提出了community score的概念并将其作为适应度函数进行优化得到社团发现的结果。Liu等[19]使用遗传算法和聚类来探测网络中潜在的社团结构,该算法最初将网络分为两部分,之后再不断地分割子图,并在子图中应用嵌套的遗传算法进行社团发现。Tasgin等[20]通过遗传算法来优化模块度函数,从而进行社团发现。
(4) 基于标签传递的社团发现算法的基本思想是: 一个节点的社团标签是由它的所有邻居节点的标签所决定的。标签传递算法LPA是由Raghavan等[8]提出,开始时,每个节点都拥有一个独一无二的标签。之后每个节点都参考它的邻居节点拥有的标签来更新自身的标签,经过多轮的标签传播直至每个节点的标签都是它的邻居节点中拥有最多的那个标签,这时拥有相同标签的节点形成一个社团。Xie等[9]通过考虑节点的历史标签对标签传递算法进行了扩展,使其可以用于探测重叠社团。Hu[10]对标签传递算法进行了改进,提出了一个带权重的标签传递算法,在标签传递的过程中使用节点间的相似性为标签加权。Gregory[11]通过设置节点和社团之间的归属系数使得每个节点可以属于多个社团,并且提出了一个判断标签传递是否收敛的终止条件,使得标签传递能够在有限的步骤中收敛。
以上这些方法都是针对同质信息网络的。近些年,出现了一些在异质信息网络中进行聚类的相关工作。Sun等[21]提出了一种带有用户引导的聚类算法 PathSelClus,其聚类结果根据用户选择的元路径的不同而不同,而且PathSelClus需要事先指定簇的个数。Luo等[22]首次提出关系路径的概念来评价同种类型节点之间的相似性,通过利用标记信息来学习不同关系路径的权重,提出了一种半监督的聚类算法SemiRPClus。
2 基于元路径的社团发现方法
2.1 基本思想
相比于同质信息网络,异质信息网络具有很多新的特性,这些新的特性为数据挖掘任务带来很多新的挑战。异质信息网络中不同类型的对象和关系包含有丰富的语义信息,元路径可以捕捉这些信息。元路径是定义在网络模式上的一条路径[1]。以图1(c)为例,连接作者的两条元路径: “作者—论文—作者”表示作者的合作关系,“作者—论文—会议—论文—作者”表示作者在相同会议上发表论文的关系。基于第一条元路径,则经常合作出版论文的作者更可能在一个社团;基于第二条元路径,则那些经常在同一个会议上发表论文的作者更可能在一个社团。可见,选择不同的元路径,作者之间的相似性是不同的,进而会导致不同的社团发现结果。因而,基于异质信息网络的社团发现应该充分考虑各条元路径所包含的不同的语义信息。另外,劳逆等[23]指出,对于一个给定的网络,可能存在的元路径数目与路径长度成指数增长,而且,Sun等[1]指出很长的元路径并不是很有意义。因此,在社团发现任务中,我们需要选定合适长度的元路径。
基于这个想法,本文提出了异质信息网络中基于元路径的社团发现方法HCD,它包括两部分,第一部分是基于单条元路径的社团发现算法HCD_sgl,第二部分HCD_all是将基于各条元路径的社团发现结果进行融合,得到异质信息网络中的最终的社团发现结果。下面我们详细阐述这两部分。
2.2 基于单条元路径的社团发现算法HCD_sgl
基于单条元路径的社团发现算法主要包括两个阶段。第一阶段是基于单条元路径的初始社团划分,即根据预先设计的方法确定在该条元路径下所有节点的初始标签;第二阶段是基于单条元路径的最终社团划分,即采用改进的标签传递算法得到所有节点的最后标签,进而得到最终的社团发现结果。下面详细介绍这两个阶段。
2.2.1 基于单条元路径的初始社团划分
基于单条元路径的初始社团划分方法主要包括以下三步。①确定满足一定数目的重要种子的节点集合。②根据模块度优化算法获取较为准确的种子节点标签。③根据网络结构和种子节点的社团标签确定非种子节点的社团标签。
第一步选择种子节点的具体方法如下。首先,根据给定的元路径,通过矩阵相乘将异质信息网络映射为相应的同质信息网络。然后,求出在该同质信息网络中所有节点的节点度,并将所有节点按照节点度由大到小排序。对于节点度相同的节点,再按照节点的本地向心性由大到小排序。最后,选取节点序列中前seedNum个节点构成种子节点集合,并构建种子节点网络。这里,seedNum为控制种子节点个数的参数,可以通过实验确定最合适的种子节点个数。选择度大的节点是因为其在社团中有很多节点与其关联,拥有较大的影响力。节点的本地向心性是指相对于它的邻居节点,其在本地的小社团中地位的重要性,用节点的所有邻居节点度的累加和来表示,如式(1)所示。
(1)
其中,N(i)为节点i的邻居节点的集合。ki为节点i的度。kn(i)表示节点i的本地向心性,较小的值代表了较大的本地向心性,较大的值代表了较小的本地向心性。
第二步确定种子节点的标签采用的是文献[17]中的基于模块度优化的算法,主要包括社团探测和网络重构两个阶段,这两个阶段相互迭代,直到网络的模块度不再发生变化,此时就确定了种子节点的标签。其中,在社团探测阶段,我们先假设每个种子节点都属于不同的社团,然后对节点i,遍历它的所有邻居节点,分别计算将节点i移入它的第j个邻居节点所在的社团所产生的模块度的增量,这样,对节点i的所有邻居节点就得到了一个模块度增量的向量。然后选取这个向量的最大值。若为正,则将节点i移入对应邻居所在的社团;若为负,则节点i仍留在其原来的社团。循环遍历网络中的所有节点并执行上述节点移动过程,直到任何节点的移动都无法使得整个网络的模块度增加。这时,得到了本地最优的社团结构,社团探测阶段结束。在网络重构阶段,将社团探测阶段获得的社团作为下一层社团发现的新的节点,重新构造网络,新网络中节点之间边的权重为该节点在原来网络中对应社团之间所有有边相连的节点对之间的边的权重之和。节点到自身的边的权重为原来网络中社团内部节点之间边的权重之和。
第三步确定非种子节点的标签,过程如下: 首先,遍历全部的非种子节点,判断其邻居节点中是否存在种子节点。若该非种子节点的邻居中存在种子节点,则先获取它的全部种子节点邻居所属的社团集合,再计算非种子节点属于各个社团的可能性,最后将可能性最大的那个社团标签作为非种子节点的社团标签。非种子节点属于某个社团的可能性是指非种子节点与邻居中属于这个社团的种子节点的相似度之和;若该非种子节点的邻居中不存在种子节点,则查找所有种子节点,找到与该节点相似性最大的节点,并把其标签作为该非种子节点的标签。非种子节点i的社团标签按照式(2)的方法确定。
(2)
其中,Seed表示种子节点的集合,S表示节点相似性矩阵,Sij表示节点i和节点j之间的相似性。社团标签的集合为L,节点i的社团标签为Ci,节点i的邻居集合为N(i)。
通过以上三个步骤,网络中的全部节点都拥有了一个初始标签,其伪代码如算法1所示。

算法1 基于单条元路径的初始社团划分
2.2.2 基于单条元路径的最终社团划分
基于单条元路径对社团进行最终划分时,我们采用了改进的标签传递算法,它主要是对传统的标签传递算法进行修改,使得在每一轮标签更新时,能同时考虑该节点可能拥有的多个社团标签,以便可以进行重叠社团发现。在更新时,每个节点属于各个社团的归属度按式(3)计算。
(3)

为了避免保留的社团标签数目过多,我们删去归属度小于1/v的标签,若都小于1/v,则保留最大的那个,同时需对归属度进行标准化,v是每个节点最多拥有的标签数。为了确保算法能收敛到一个稳定状态,受文献[11]的启发,我们将mt=mt-1作为标签传递算法的终止条件,mt表示第t轮标签更新后属于各个社团的最小节点数,确定方法如式(4)所示。
(4)
其中,ct为第t轮标签更新后属于各个社团的节点个数,确定方法如式(5)所示。it为第t轮标签更新后剩下的社团标签集合,如式(6)所示。(c,i)表示属于社团c的节点数为i。
(5)
其中,L是社团标签集合,Vt是全部目标类型节点的集合。

(6)
经过上面两个阶段,我们得到了基于单条元路径的社团发现结果,其伪代码如算法2所示。

算法2 基于单条元路径的社团发现算法HCD_sgl
2.3 融合多条元路径的社团发现算法HCD_all
异质信息网络中不同的元路径具有不同的语义信息,因此基于单条元路径进行的社团发现可能并不能完整地描述整个网络的社团结构。鉴于此,我们融合多条元路径的社团发现结果,从而使得基于单条元路径不能发现的社团特征可以在基于其他元路径的社团发现结果中得到补充。
融合多条元路径的社团发现算法包括以下两个阶段。第一阶段首先遍历基于各条元路径的社团发现结果,针对每个节点形成一个标签序列,用来显示该节点在各个社团发现结果中的社团标签。如果一些节点在基于各条元路径的社团发现结果中都拥有相同的社团标签,即它们拥有相同的标签序列,则认为它们一定属于同一个社团,形成了一个相同社团的约束。
第二阶段为网络重构阶段。找到这些相同社团的约束后,将这些一定属于同一个社团的节点集合看作下一层社团发现的一个新节点,重新构造网络。然后在新构造的网络中进行模块度的优化,当网络的模块度不再变化时,算法终止,得到最终的社团发现结果。算法3是融合多条元路径的社团发现算法HCD_all的伪代码。

算法3 融合多条元路径的社团发现算法HCD_all
3 实验与结果
我们在DBLP数据集上验证了算法HCD_sgl和HCD_all的有效性,在人工数据集的非重叠社团数据上验证了算法HCD_sgl的有效性,在重叠社团数据上又进一步验证了HCD_sgl可以用于重叠社团发现,并对算法HCD_sgl中的参数seedNum进行了相关讨论。
3.1 数据集
(1) DBLP数据集: 本实验使用文献[24]中的DBLP数据集的子网络,该数据集包含数据库、数据挖掘、信息检索、人工智能四个研究领域(社团类型)的20个会议、14 376篇论文、14 475位作者和8 920个术语。其中含有标签的数据有4 057位作者、100篇论文和全部20个会议,标明了它们所属的社团类型(研究领域)。对数据进行预处理得到全部具有标签的数据集包含2 052位作者、3 100篇论文、20个会议和3 925个术语。
(2) 人工数据集: 该数据集分为两部分,一部分是规模较大的非重叠社团数据,用于比较HCD_sgl与其他算法在非重叠社团发现中的效果。另一部分是规模较小的重叠社团数据,用来验证HCD_sgl进行重叠社团发现的效果。
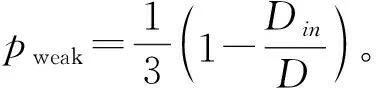

图2 非重叠社团网络示意图[25]
重叠社团数据集的网络中也包含A和B两种节点,A类和B类节点也都有四个社团,分别为A1、A2、A3、A4和B1、B2、B3、B4。每个A类节点的社团含有64个节点,每个B类节点的社团含有128个节点。A 类节点共有256个,B类节点共有512个。除了以上生成规则外,从社团A1中随机选择八个节点,使其到社团B2的边的生成概率为pstrong,因此这八个节点是社团A1和A2的共同节点。同样地,找到社团A2和A3,A3和A4,A1和A4的八个共同节点。
3.2 评价标准
实验中我们使用标准化互信息(NMI)[26]和模块度(modularity)[12,27]作为评价社团发现好坏的标准。计算分别如式(7)、式(8)所示。
(7)
其中,H(A)和H(B)分别是A和B的熵,I(A,B)是A和B的互信息,NMI用来衡量两个聚类结果的相近程度,取值范围是[0,1],值越大,表示社团发现的结果越好。
(8)

3.3 对比方法
因为算法开始基于给定的元路径将异质信息网络映射成同质信息网络,所以本文中我们选取了同质信息网络中三个经典的社团发现算法进行对比,谱聚类算法(spectral clustering,SC)[28]、基于模块度优化的BGLL算法[17]和标签传递算法LPA[8]。分别介绍如下。
(1)谱聚类算法(spectralclustering,SC)[28]: 该算法是一种基于图论的聚类方法,它先利用相似性矩阵的特征值把数据降维,再进行聚类。本文通过使用基于元路径的相似性算法使得谱聚类算法可以应用在异质信息网络中进行社团发现。
(2)BGLL算法[17]: 该算法是一个基于模块度最优化的启发式算法,包括社团探测和网络重构两个阶段。第一阶段通过节点交换进行社团划分,获取本地最优的模块度;第二阶段把第一阶段探测出的社团结构当作新节点重新构造更高层次的网络。两个阶段的不断迭代,直至不会产生更高层次的社团结构。
(3)标签传递算法(LPA)[8]: 该算法通过多轮的标签传递和更新,直至各个节点的社团标签都不再变化,最终使得每个节点的社团标签都是其邻居节点中包含最多的那个社团标签。
本文基于指定的元路径将异质信息网络映射成为同质信息网络,再将BGLL算法和LPA算法应用其中。
3.4 有效性实验
3.4.1 基于单条元路径的社团发现有效性实验
我们分别在DBLP数据集和人工数据集上进行非重叠社团发现实验,验证算法HCD_sgl的有效性,参数v设为1,seedNum设为700,谱聚类算法和标签传递算法均重复100次取平均值。
在DBLP数据集上,我们采用元路径APCPA对作者进行社团发现。谱聚类算法和HCD_sgl算法均使用PathSim[1]和HeteSim[29-30]作为相似性计算方法,PathSim和HeteSim都是异质信息网络中比较重要的两种相似性度量方法。实验结果如表1和表2所示。
在人工数据集的非重叠社团数据上,我们通过改变Din的值,来生成不同的网络,并且选择元路径ABA对A类节点进行社团发现。对于每个Din随机生成10个网络,对于每一个网络,运行算法10次求均值,结果如图3所示。其中,Din代表了社团的模糊程度,较大的Din对应的社团结构更明显,而较小的Din对应的社团结构更模糊,由于LPA算法的效果很差,因此这里只比较了HCD_sgl算法与BGLL算法、SC算法的效果。

表1 相似性计算方法为PathSim时各社团发现算法的聚类结果

表2 相似性计算方法为HeteSim时各社团发现算法的聚类结果
从表1和表2中,我们可以看出,基于两种不同的相似性计算方法,HCD_sgl的聚类效果比其他三个算法好。LPA算法效果是最差的,这是因为其初始标签过多,造成最终的社团发现结果中的标签数也较多,从而影响了社团发现效果。并且由于LPA算法在进行标签选择时存在随机性,导致每一轮最终的社团标签都较为不同,而HCD_sgl通过引入种子节点控制了社团标签个数,通过本文提出的确定种子节点和非种子节点初始标签的方法以及对传统标签传递过程的改进,消除了算法的随机性,使得算法可以获得较稳定的结果。BGLL的表现较HCD_sgl略差一点,原因可能在于使用模块度作为优化目标,这种方法偏向于找到较大的社团结构,因此会忽略一些较小的社团。谱聚类算法需要预先设定簇的个数k,而簇的个数直接影响了社团发现的结果。
从图3可以看出,随着社团结构越来越明显,不同算法进行社团发现的模块度都在增加,即算法的效果都在提升。SC算法的效果是最差的,HCD_sgl算法在不同模糊度的网络中进行社团发现的准确性都是最好的,可以取得比BGLL算法更好的效果。

图3 人工数据集中社团发现效果随社团模糊度变化图
3.4.2 融合多条元路径的社团发现有效性实验
为了验证HCD_all算法的有效性,我们分别选取APA、APCPA和APTPA三条元路径来运行HCD_sgl算法,融合这三条元路径运行HCD_all算法,算法中使用 PathSim来计算相似性,seedNum的值设为700。实验结果如表3所示。

表3 基于单条元路径的社团发现与融合多条元路径的社团发现效果比较
从表3可以看出,算法HCD_sgl基于不同的元路径的社团发现效果是不同的,说明不同的元路径能捕捉不同的语义信息。并且基于元路径APCPA的社团发现效果是最好的,较其他两条元路径有明显的优势,这说明元路径APCPA能够更好地捕捉当前网络的语义信息。融合了三条元路径的HCD_all算法在两个评价指标上都比HCD_sgl效果好,说明不同的元路径捕捉到的语义信息可以相互补充,从而达到更好的社团发现效果。算法HCD_all的效果相比APCPA的效果提升并不明显,原因是元路径APCPA捕捉了主要的语义信息,而其他两条元路径捕捉的语义信息相对较少。另外,这些捕捉到的相对较少的语义信息对整体的社团发现效果提升是有帮助的,表明其捕捉到了必要的信息,也进一步说明融合多条元路径的必要性。
3.4.3 重叠社团发现有效性实验
为了验证HCD_sgl算法进行重叠社团发现的效果,我们在重叠社团数据集中进行实验。HCD_sgl的参数v设为2,元路径选取APA,相似性计算方法采用PathSim,seedNum的值设为700。
表4显示了社团实际重叠部分的规模与HCD_sgl探测出的重叠规模。由表4可以看出,大多数社团的重叠部分都可以被HCD_sgl算法探测出来,证明了HCD_sgl的确可以用于重叠社团发现。

表4 重叠社团发现结果
3.5 效率实验
为了更加综合地说明提出方法的性能,我们在人工数据集不同的Din值对应的不同网络上,分别执行BGLL和HCD_sgl算法 25次,记录平均结果如表5所示。这里我们只与对比算法中有效性最好的BGLL算法进行了比较。由表5可以看出,在Din取不同值的情况下,HCD_sgl算法的效率总是比BGLL算法高,进一步说明提出方法相比其他基本方法的综合的性能优势。

表5 不同社团模糊度下算法的效率比较
3.6 参数讨论
算法HCD_sgl中的参数seedNum对探测出的社团数目和最终的效果都具有一定的影响,为了更好地研究这种影响,我们在DBLP数据集中使用元路径APCPA、相似性计算方法PathSim来进行参数实验,实验结果如图4和图5所示。

图4 种子节点数取不同值时算法执行效果

图5 种子节点数取不同值探测出的社团数目
从图4可以看出,随着seedNum的增加,评价标准模块度和NMI表现出相似的变化趋势。当seedNum的值小于5时,指标呈现出增长的趋势,当seedNum的值接近于5时,效果就比较接近社团发现的最终结果了,这说明度较大且本地向心性高的种子节点在网络中处于较为重要的地位,对社团发现起着关键性作用。当seedNum处于200~400之间时两个指标都出现下降,可能是因为新引入的种子节点产生了干扰,当把该种子节点的标签进一步传递给非种子节点时,将这种干扰扩大到了整个网络当中。当seedNum处于700~800附近后,效果达到了最好并且趋于稳定,可能是因为新添加的种子节点使得网络结构更加完整,从而使探测出的社团结构达到最优。
图5显示了seedNum取不同值时HCD_sgl探测出的社团数目的变化趋势。可以看出,随着seedNum的增加,社团数目不断增加,直至稳定,当seedNum为700时HCD_sgl可以探测出DBLP数据集中所有的四个社团。因此在其他实验中将seedNum的值设为700。
4 总结与展望
本文研究了异质信息网络中的社团发现问题,提出了一个利用丰富的结构信息和语义信息进行社团发现的方法HCD,它包括两部分: 第一部分是基于单条元路径的社团发现算法HCD_sgl,第二部分是融合多条元路径的社团发现算法HCD_all。 HCD_sgl基于给定的元路径将异质信息网络映射为同质信息网络,设计相应方法获得节点的初始社团标签,再利用改进的标签传递算法,得到最终的社团发现结果。HCD_all融合基于不同的元路径的HCD_sgl的社团发现结果,重新构造新的网络,再利用模块度优化算法获得最终的社团发现结果。HCD方法在真实和人工数据集上均取得了较好的实验效果。HCD_sgl能够取得比传统的标签传递算法更好的社团发现结果。HCD_all融合了异质信息网络中基于多条元路径的结果,可以取得比基于单一元路径的HCD_sgl算法更好的社团发现效果。本文提出的异质信息网络中的社团发现方法HCD只是基于静态网络的,可以进一步考虑时间因素,进行动态的社团发现。
猜你喜欢
阅读(中年级)(2022年9期)2022-10-08
家庭教育报·教师论坛(2021年42期)2021-12-23
北方论丛(2021年2期)2021-05-22
电子制作(2018年10期)2018-08-04
军事文摘(2017年16期)2018-01-19
中国交通信息化(2017年12期)2017-06-06
中央社会主义学院学报(2017年1期)2017-04-16
学苑创造·A版(2017年1期)2017-01-19
中央民族大学学报(自然科学版)(2015年2期)2015-06-09
中国民间疗法(2014年2期)2014-01-25
