
基于词注意力卷积神经网络模型的情感分析研究
2018-10-19 03:03王盛玉曾碧卿韩旭丽
中文信息学报 2018年9期
王盛玉,曾碧卿,2,商 齐,韩旭丽
(1. 华南师范大学 计算机学院,广东 广州 510631;2. 华南师范大学 软件学院,广东 佛山 528225)
0 引言
情感分类任务面向用户生成的文本,分析文本的情感信息,最终得到文本的情感倾向: 正向、中性或负向。目前,情感分析已经广泛应用于诸多领域,如电子商务平台、电影推荐、舆情分析等。
当前,情感分类主要有基于规则、机器学习和深度学习这三类方法。基于规则的方法主要借助于情感词或专家构建的特征,但特征构建的代价非常高。基于机器学习的方法将情感分类视为与文档分类或主题分类相似的任务,采用unigram、bigram或one-hot等语言模型构建篇章特征,使用机器学习算法作为分类器对篇章进行情感倾向性分析。该方法面临篇章特征向量稀疏、维度爆炸、特征提取困难等问题。基于深度学习的方法把神经网络模型参数训练与特征学习的过程并行化,篇章映射成矩阵作为模型的输入,模型学习到篇章的特征表示后,将其输入到分类器,完成情感分类任务。
近年来,随着深度学习在情感分析领域的研究,越来越多的研究者使用深度学习、神经网络模型对文本进行情感分析。卷积神经网络在情感分析任务中的有效性已被证明。篇章通过word embedding映射后作为CNN的输入,经过卷积层和池化层得到篇章的特征表示。Kim[1]利用提前训练的词向量,成功地将CNN应用于句子分类任务。Kalchbrenner[2]提出一种动态k-max pooling的CNN用于句子特征学习,取得较好效果。
注意力机制(attention mechanism)目前已经成功应用于自然语言处理与图像处理等多个领域。在情感分析领域,注意力机制的应用,有利于模型更有效地发现和构建特征,使模型在训练时有选择地进行特征提取。Xu K[3]将注意力机制应用于解决图片描述生成问题;在机器翻译领域[4-5],注意力机制改进了原有的encoder-decoder翻译模型。Yin[6]等提出一种基于注意力机制的卷积神经网络,将其用于句子对建模任务中;Wang[7]等人利用基于多层注意力机制的卷积神经网络进行句子关系分类;这些方法的成功说明注意力机制与CNN结合的有效性。
CNN虽然拥有强大的学习能力,但在文本特征提取时,数据集未进行预处理,导致输入文本中存在大量非关键词;其次,CNN无法自动判别输入文本中哪些局部特征词较为重要,而这对情感分析至关重要;再者,CNN在情感分析中往往采用不同大小的卷积核,但忽略对单一词特征的提取;最后,CNN在情感分析领域的应用缺乏理论解释,同时卷积操作容易忽略篇章首尾词的上下文信息。因此,本文结合卷积神经网络和注意力机制,以词特征提取为目标,提出词注意力卷积神经网络模型(word attention-based CNN,WACNN)。该模型针对情感分析任务,做出如下三方面工作: ①词注意力机制。模型首先在词嵌入层后构造词注意力层,注意力机制作用在词嵌入层输出的文本特征表示上,以局部窗口的方式,获取窗口中心词的上下文信息,得到每个词的情感权重。②卷积核。卷积层的卷积操作可以视为获取文本的n-grams特征,在该层加入大小为1的卷积核,获取单一词的特征。③输入填充。借鉴n-grams思想,对卷积层的输入进行适当的0填充(Padding),使卷积操作可以根据每个词的上下文提取特征。最后在MR5K和CR数据集上进行实验验证,取得了比普通卷积神经网络和传统机器学习方法更好的效果。
本文的主要贡献如下:
(1) 本文首次结合注意力机制和CNN来解决情感分类问题。
(2) 基于词注意力的卷积神经网络模型既能在词嵌入层自动地获取关键特征词,还能在卷积层分别提取词特征和整体的语义特征。
(3) 本文给出卷积在情感分析上的n-grams解释,并利用Padding方法模拟该特征提取,实验证明了Padding方法在文本特征提取上的有效性。
1 相关工作
1.1 情感分析
情感分析任务针对用户生成的文本,判断用户的观点、情感或态度[8]。情感分类作为情感分析的一项基础任务,通过对文本的情感分析获取其情感倾向性。传统的情感分析方法主要借助于机器学习算法和人工特征构建。Pang B[9]利用机器学习方法,借助一元词、二元词、词性标注等特征进行电影评论情感分析。Wang和Manning[10]将支持向量机与朴素贝叶斯方法相结合,在多个数据集上取得较好效果。
在语言模型上,传统方法多使用词袋模型,但该模型无法有效地获取文本的深层次语义特征。词嵌入(word embedding)[11]将词或短语映射到一个低维向量空间中,用以表征它的语法和语义特征。大量基于word embedding的神经网络模型应用于情感分类任务。Kim[1]将CNN应用于文本分类;Johnson等[12]提出一种类似于Kim的方法,但将高维度的one-hot向量作为模型的输入;Socher[13]提出递归神经网络对电影评论进行分析;Tang[14]使用CNN与带有门机制的RNN构建层次化的情感分类模型。
注意力机制方面,Bahdanau[4]提出注意力机制,并首次应用于翻译领域,Luong[5]则提出了两种注意力方式global attention和local attention。两者将注意力机制在翻译领域的成功应用,使其迅速成为研究的热点。Zhou[15]结合LSTM和注意力机制,用于特定目标的情感分类,将特定目标作为模型的关注点,训练中获取与特定目标关联性强的信息,分配高权重,从而有效识别目标的情感倾向。
1.2 卷积神经网络模型
本文以Kim的卷积神经网络为基础,卷积神经网络主要包括输入层、词嵌入层、卷积层、池化层和全连接层。假设输入的情感篇章为S={w1,w2,…,wn-1,wn},篇章长度为n,通过词嵌入层的词嵌入矩阵可得到篇章的Word2Vec特征表示X,如式(1)所示。
X={x1,x2,…,xn}
(1)
d代表词向量的维度,其中xi∈Rd。卷积层使用大小不同、数量不等的卷积核对输入矩阵进行卷积操作,获取每个局部的特征,生成输入篇章的特征图,如式(2)所示。
C=f(ω·X+b)
(2)
其中ω∈Rh×d代表卷积核权重矩阵,h代表卷积核大小,b代表偏置量,f(·)代表卷积核函数。得到特征图后,池化层进行下采样操作,提取重要的特征。最后,将经过池化后的卷积层输出串联作为全连接层的输入,得到最终的分类结果。
2 词注意力卷积神经网络模型
如图1所示,本文提出的词注意力卷积神经网络模型WACNN(word attention-based CNN)主要分为五个步骤:
(1) 词嵌入层: 将序列化后的输入文本进行词嵌入,得到文本的特征表示。
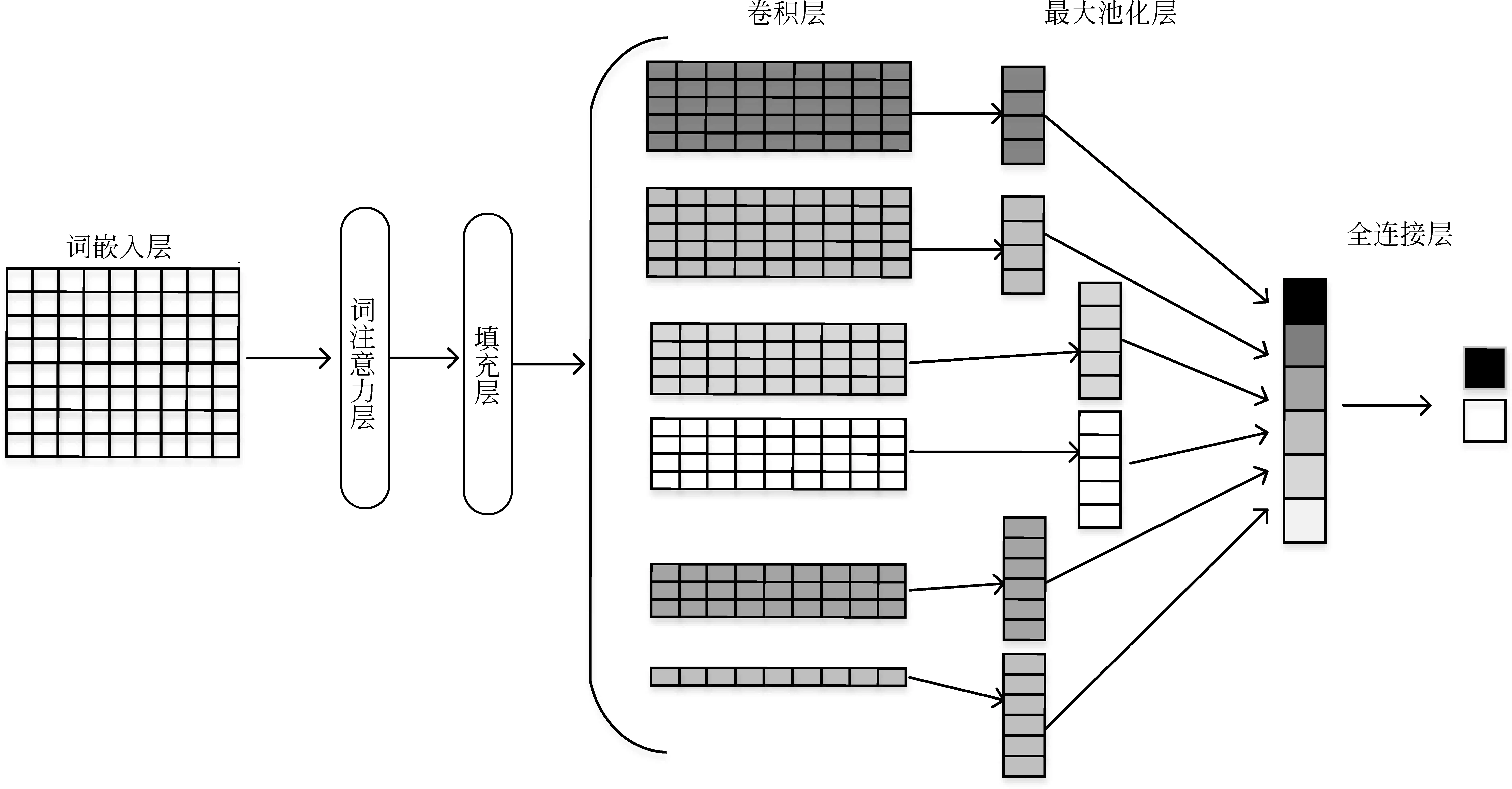
图1 词注意力机制卷积神经网络
(2) 词注意力层: 在词嵌入层后添加注意力层,使模型在训练的过程中有选择地进行词特征提取,降低噪声对情感分析的影响。
(3) 填充层: 本文以每个词的上下文含义作为词特征表示,根据卷积核大小对卷积层的输入进行填充,保证每个词都存在上下文。
(4) 卷积层: 卷积层除了使用多个大小为[3,4,5]的卷积核,还增加大小为1的卷积核。卷积层对填充后的注意力层输出进行特征提取,获取局部特征。
(5) 后两部分与CNN相似,包括池化层和全连接层。
通过步骤(2)~(4),使卷积神经网络在情感分析时,具备鉴别特征词的能力;卷积层既能获取每个词的特征,也能基于每个词的上下文得到局部特征。
2.1 词注意力机制
词嵌入层: 篇章经过序列化处理后得到S={w1,w2,…,wn-1,wn},wi代表词在整个数据集词汇表中的下标,篇章的特征表示采用one-hot模型。在词嵌入层采用词映射的方式将每个词映射为d维的向量,如式(3)所示。
(3)
e代表词向量矩阵e∈R|ν|×d,|ν|表示整个数据集中词汇的数量。
词注意力层: 注意力层的作用是对输入文本进行筛选,决定哪些词汇较为重要,使模型在训练过程中重点关注。如图2所示,我们采取n-grams语言模型,取该词和其上下文的含义作为该词的语义表达。设置词的上下文范围为D,pi表示词在文本中的位置,则词wi的语义可表示为: 大小为L=[pi-D,pi+D]=1+2D的窗口内上下文的含义。设置滑动窗口矩阵参数Watt∈RL×d,计算每个词xi的特征值权重αi,用以表示其对情感分析的重要程度。

(6)
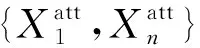
对于词嵌入层的输出X,注意力层采用滑动的方式,对每个局部提取词的权重αi,得到权重向量α,如图2所示。
α={α1,…,αn}
α∈Rn
(7)
n代表输入句子的长度。
图2 词注意力层
通过α可以标识每个词的重要程度,将其与对应位置的词向量相乘得到新的文本特征表示Xatt:
(8)
2.2 填充(Padding)方法
在情感分析领域,传统自然语言处理常采用unigram、bigrams或trigrams作为语言特征。
Pang B[9]曾使用该方法进行情感分析,此方法基于马尔科夫链,考虑每个词的上下文信息,研究结果表明该方法非常有效。卷积层提取局部特征,可以将卷积操作近似地视为提取文本的n-grams特征。每次卷积操作,卷积核参数ω∈Rh×d以xi为中心,考虑词的上下文,依次提取每个词的n-grams特征。以大小为3的卷积核为例,每次考虑中心词的上下文范围为1,即遵循隐马尔可夫原则,而大小为5时,上下文范围就扩大到2。
但在卷积层中,处于篇章首尾的词无法被卷积操作覆盖到,且无上下文信息,即首尾各存在h/2个词无法提取到n-grams特征,产生信息丢失。如图3所示,我们使用两种方式对卷积层的输入进行适当的填充,以使卷积操作可以提取到每个词的上下文信息。
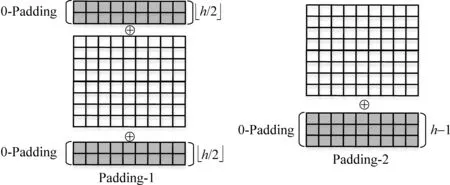
图3 两种Padding方式
(1) Padding-1: 对卷积层的输入在首尾位置进行0向量补全,补全大小为h/2,以保证开始词存在上文,结尾词存在下文,如式(9)所示。
(9)
(2) Padding-2: 在卷积层的输入末尾进行大小为h-1的0向量补全,如式(10)所示。
(10)
式(10)中,⊕表示串联操作。
2.3 卷积层和池化层
卷积层负责提取单一词特征和词的上下文信息。经过填充后的文本特征表示Xatt,将其作为卷积层的输入。卷积层使用大小为h的卷积核ω∈Rh×d对输入进行局部特征提取,如式(11)所示。
ci=f(ω·Xatt: (i: i+h-1)+b)
(11)
其中Xatt: (i: i+h-1)代表文本特征矩阵从第i行到第i+h-1 行的局部特征,f(·)代表卷积核函数,b代表偏置量。卷积层对特征矩阵X的不同位置进行卷积操作,得到特征图(feature map)c,如式(12)所示。
c={c1,c2,…cn-h,cn-h+1}
(12)

(13)
2.4 全连接层
上述为单一大小的卷积核,本文使用多个大小的卷积核,数量为z,将池化层的输出串联作为全连接层的输入,全连接层负责情感分类,得到结果,如式(14)所示。
(14)
式(14)中,⊕表示串联操作,O代表模型在多个不同大小的卷积核下生成的结果串联,z表示选取了几种大小的卷积核,m表示每个卷积核的数量,Wfc为全连接层的权重,bfc为偏置量,y∈{+1,-1},代表情感类别,此处为二分类。
3 实验数据与实验设置
3.1 数据集
实验部分在以下两个公开数据集上进行:
(1) CR: 用户在不同商品上的评论数据集,用于对评论进行情感倾向性分析[16]。
(2) MR5K: 用户对电影的评论数据。每一条评论数据包含正向和负向的情感倾向[17]。
上述的这些数据集已经人工对每条评论设置了情感标签,实验中暂不考虑标签与文本是否相符的情况。数据集详细信息如表1所示。

表1 实验数据集
表1中|V|代表数据集词汇数量;N代表数据集篇章数量;average代表篇章词数量的平均值;max代表篇章词数量的最大值。
3.2 实验参数与数据处理
本实验按照8∶1∶1将数据集划分为训练集、验证集和测试集。数据集的预处理采用keras自带的tokenizer接口进行分词。文本使用预训练的词向量进行映射,词向量采用Mikolov[11]提前训练好的公开结果集,向量维度300维[注]https://code.google.com/archive/p/word2vec/。为了降低数据分配对实验结果的影响,每组实验结果都取十折交叉验证的平均值。
实验中卷积神经网络的参数同Kim[1]构建的单层卷积神经网络参数相似,激活函数使用rectified linear units(RELU),卷积核大小分别为[1,3,4,5],每个卷积核数量为100个,Dropout层接收比例为0.5,batch_size为64,池化层采用最大池化,训练时对词向量进行微调,采用 Adadelta[18]算法优化模型参数,词注意力层取上下文范围大小D=2,即L=5,滑动窗口数量为1。全连接层隐藏单元200个。
3.3 对比方法
本文提出的方法与多种不同的方法进行对比,包括支持向量机(support vector machine,SVM)、卷积神经网络等。对比实验数据来自Kim[1]。
对比方法如下:
NBSVM,MNB: 使用朴素贝叶斯和支持向量机进行情感和主题分类[10]。
CNN-K: Kim[1]将卷积神经网络应用于篇章分类。
CNN-Z: Zhang Y[19]实验观察了卷积神经网络对各参数的敏感性。
CNN: 在本实验环境下,使用CNN在各数据集上的实验结果。
WACNN1: 词注意力卷积神经网络模型,填充层使用Padding-1方法。
WACNN2: 词注意力卷积神经网络模型,填充层使用Padding-2方法。
WACNN-N: 模型在填充层不使用Padding方法。
3.4 实验结果与分析
本文在MR5K和CR数据集上进行多组实验,得到目标的情感倾向。表2给出了实验在不同数据集上得到的分类结果。

表2 不同模型在特定目标的情感分类结果
从表2可以看出,本文提出的方法在两个领域的数据集上都取得更好的效果。WACNN1/WACNN2/WACNN-N都取得了比原始CNN和传统机器学习方法更好的效果。CNN模型将所有词都同等对待,提取每一处的局部特征,没有识别关键词汇的能力,基于注意力机制的WACNN模型相比CNN情感分类正确率有明显提升。在CR数据集上提升了2%,这说明注意力机制能使CNN在训练过程中有选择地关注特定目标词汇,降低噪声影响,从而更好地识别目标情感倾向性。本组实验验证了注意力机制同卷积神经网络结合有助于特定目标的情感分类。
从表2还可以看出,在多个数据集上,WACNN-N模型的表现要比WACNN1和WACNN2略差。从图4可以更显著地看出,WACNN-N效果优于原始CNN,但较WACNN1和WACNN2要差一些。卷积层在获取文本开始和结尾处的局部特征时,缺乏词的上下文信息,造成信息丢失,填充层的加入可有效提升模型效果,保证卷积层可提取到每个词的n-grams特征。实验验证了本文提出的两种填充方法在WACNN模型上的有效性。
从图4可以看出,两种填充方法的优劣并无绝对差别,在不同的目标数据中表现不一。两种方法哪种更优需要根据特定目标而定。
3.5 填充(PADDING)方法
卷积神经网络在卷积层的卷积操作,我们将其理解为依据中心词提取词的n-grams特征,并给出了两种填充方法保证卷积操作可以提取到每个词的上下文信息。
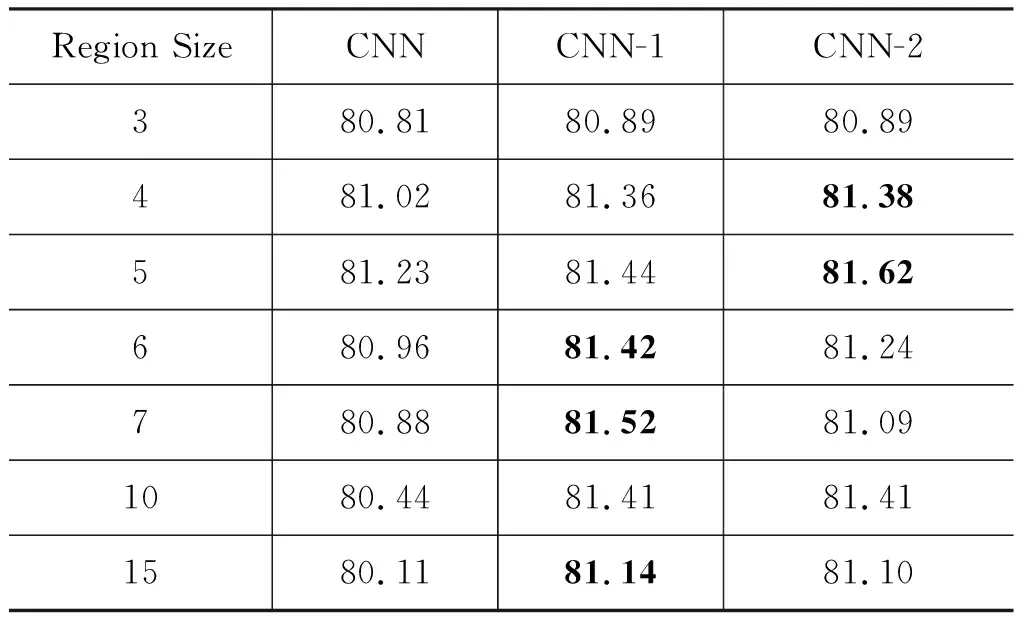
表2和图4验证了填充方法在WACNN模型上的有效性,本节在MR5K数据集上设计两组实验来验证理论猜想的正确性、填充方法在CNN上的有效性。分别考虑多卷积核大小和单一卷积核的CNN,形成表3和表4的实验结果。CNN-1代表使用Padding-1方法,CNN-2代表使用Padding-2方法。
从表3的实验结果可以看出,伴随着卷积核的变大,卷积层在文本开始和结尾处丢失的信息更多,取得的效果也越差。填充层的加入使输入根据卷积核的大小进行填充,卷积层提取到每一个词的上下文信息,能更好地表达文本的情感信息。CNN-1和CNN-2取得了比原始CNN更好的效果。实验验证了填充方法在多卷积核卷积神经网络上的有效性。

表3 Padding对多卷积核模型的影响
表4的实验结果表明,在不同大小的卷积核下,填充方法可取得0.3%~1%的模型提升效果。填充方法在单卷积核的情况下同样有效,但是两种方法的优劣并没有绝对差别,效果取决于目标数据。

图4 MR数据集上模型10折交叉验证的实验结果
Region SizeCNNCNN-1CNN-2380.8180.8980.89481.0281.3681.38581.2381.4481.62680.9681.4281.24780.8881.5281.091080.4481.4181.411580.1181.1481.10
3.4节和3.5节的实验表明: ①理论的正确性。情感分析任务中,卷积层以每个词为中心,依据词的上下文提取词的n-grams特征。②填充方法的有效性。两种填充方法有效地保证了每个词具有上下文信息,使卷积层可提取到每个词的特征。
3.6 词注意力可视化
情感分析任务中,卷积神经网络取得了不错的效果,但是模型在特征提取、特征选择等环节都缺乏可解释性和可视性。本文在词嵌入层之后卷积层之前添加词注意力层,使得模型在训练过程中有选择地进行特征提取。因此,我们可以对模型的特征提取和选择进行可视化,并给予解释。
本组实验从MR5K和CR数据集中随机各选出两条文本,模型的词注意力层得到每个词的权重,根据权重大小加深词的颜色,深色阴影代表最高权重级别,浅色阴影代表较高权重级别。表5和表6中只标识出权重较高的词,其余不做标注。
表5CR数据集文本注意力机制可视化

表6 MR5K数据集文本注意力机制可视化

从表5和表6中可以看出,模型训练时会将形容词短语(形容词+名词)和形容词视为较重要的词。例如在CR数据中“very sleek”“good front panel”“thinly sketched”,MR5K数据中“thinly sketched”“integrated”等。除此之外,否定词转折词、名词短语和比较短语也有很高的权重值。如“much better”“more like”“i’m not”“but”等。
本组实验证明: 词注意力层确实可以使模型在训练过程中发现关键词并有选择地提取数据特征。在情感分类任务中,情感词、形容词短语、比较词、否定词和转折词都对情感倾向性判断具有较大影响。
4 结论
本文提出一种基于词注意力的卷积神经网络模型,并将其用于情感分析领域,实验取得了较好效果。模型借鉴传统自然语言处理中的n-grams特征,在词嵌入层之后加入注意力层,提升了模型训练时的特征选择能力,并使模型具备特征选择可视化和可解释性;填充层的填充方法保证每个词都具备上下文信息;卷积层以词为中心,根据词的上下文提取特征。最后,模型在MR5K和CR数据集上验证了效果。
然而,本文将注意力机制应用在词特征的选择上,并未在语义层面进行特征筛选。所以接下来将对注意力机制进行改进,使其对语义的特征选择更加有效。
猜你喜欢
现代电力(2022年2期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
