
基于数字信号处理器的婴儿声音识别系统的设计与实现*
2018-10-18 02:54:14顾国良许鹏沈晓燕
生物医学工程研究 2018年3期
顾国良,许鹏,沈晓燕
(南通大学 电子信息学院,江苏 南通 226019)
1 引 言
在复杂多变的世界中,婴儿显得十分弱小,他们只有在成年人的精心呵护下,才能健康地成长。哭是婴儿出生后生命的象征,也是他们与外界交流的工具,通过啼哭表达自己的诉求,因此,一种可以实时准确监测婴儿哭声的系统是非常有必要的。在上世纪六七十年代,国外己经有对婴儿哭声进行研究,危地马拉的儿科医生莱斯用计算机对儿童哭声的疾病信息进行研究[1]。2003年,西班牙的一位工程师发明了一款可以分析婴儿哭声的仪器,不过被证实检测效果并不好[2]。国内主要是在一部分研究机构和高等院校对声音信号进行研究,设计了婴儿哭声信号识别的一些测试系统[3],目前,很多医院对婴儿监护仍需人工来完成,市面上也有很多类似育婴箱的智能监护产品,但具有婴儿哭声识别功能的较少且识别精度不高[4]。为了解决该问题,本研究采用动态时间规整识别算法与线性预测系数结合,实现对婴儿哭声的准确识别。本系统以DSP为硬件平台,其强大的浮点运算功能,大大提高了系统的时效性和准确性。
2 婴儿啼哭声特点及识别方法
婴儿啼哭声与成年人的语音比较,既有相似又有不同,实验所用语音为一段婴儿啼哭声,图1为婴儿啼哭声的时域波形和对应的语谱图。分析得婴儿哭声具有以下不同于语音信号的特点:基频较高,婴儿的声带短而且薄,因此得到的基音频率较高;婴儿啼哭的某些声音单元,其包络部分呈现规律性。本研究使用动态时间规整算法对婴儿哭声进行识别,语音识别系统原理框图见图2。

图1 语谱图
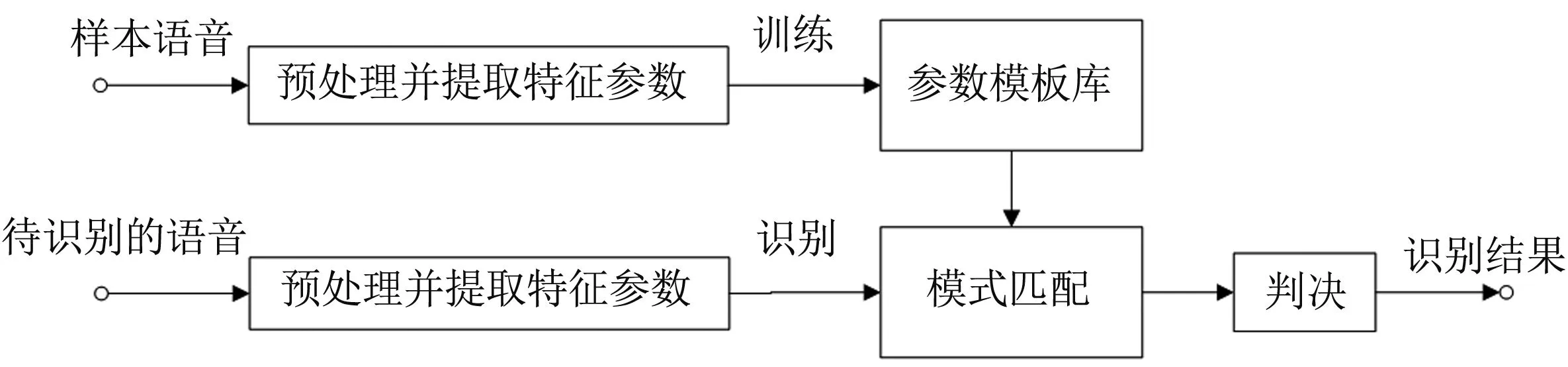
图2 语音识别系统原理框图
样本语音经过端点检测等预处理之后,对得到的语音信号进行特征参数提取,然后存入模板库中,待识别的语音经过预处理和参数提取后,将采集到的语音的特征参数与模板库中的每个模板进行模式匹配,将相似度最高的模板对应的语音判决为识别结果输出[5-6]。
2.1 线性预测系数特征提取优化算法
线性预测分析的基本思想为:一个语音样本当前的值可以用样本中若干过去的值通过某种线性组合来无限逼近。实际语音和线性预测的采样值通过最小均方误差(MSE)准则来确定唯一的一组线性预测系数(LPC)。
根据模型化表示法,图3为婴儿哭声信号模型,其中增益为G的信号t(n)在经过H(z)产生输出信号,即婴儿哭声信号x(n),声道参数即是线性预测系数。
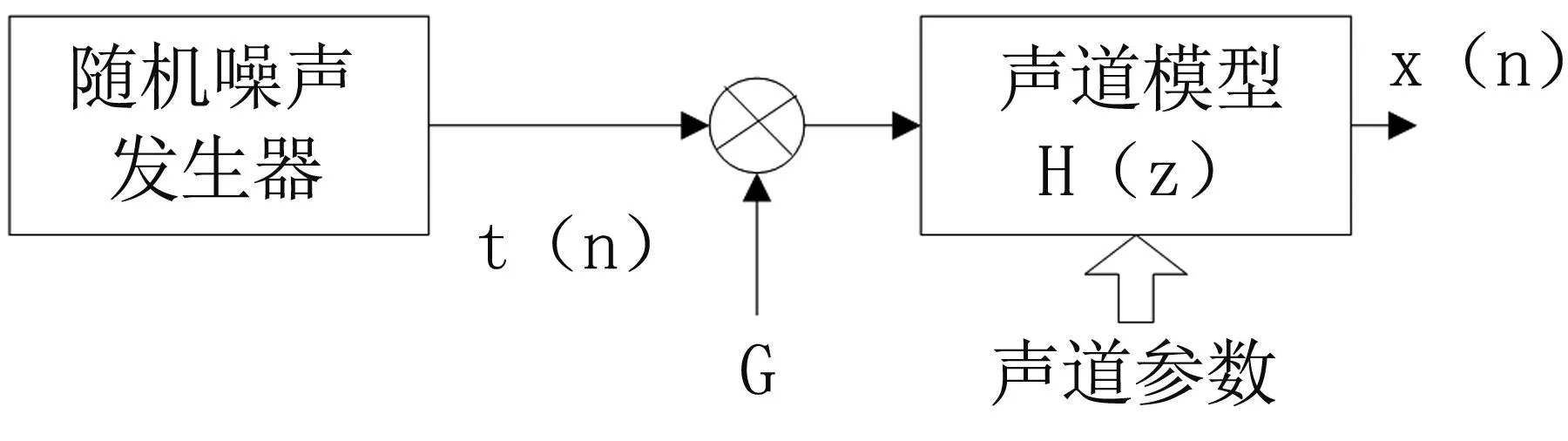
图3 婴儿啼哭声信号的模型化
其中,H(z)为全极点模型的表达式见式(1):
(1)
在式(1)中,模型参数分别为:系数ai、增益常数G、以及模型阶数p。
(2)
由式(2)得,F(z)由ai决定,采用最小均方误差准则,可求得ai。
短时预测均方误差为En,其表达式见式(3):
(3)
在实际研究中,En在每一帧声音信号的范围内进行,当∂En/∂ak=0时,En可取到最小值,其中,k=1,2,…,p,即:
(4)
因此,可以得到线性方程组:
(5)
其中,k=1,2,…,p。如果定义
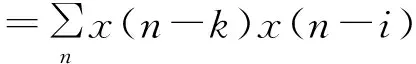
其中,k=1,2,…,p;i=0,1,2,…,p,则式(5)可用式(6)表示:

(6)

对于线性预测方程组,自相关法稳定性较好,具有高效递推算法的优势,因此优先考虑自相关法,自相关函数经过加窗处理后可以得到式(7):

(7)
自相关函数法需要加窗进行过滤,但误差较大,计算精度较差。
为提高识别精度,本研究采用优化过的布莱克曼窗进行滤波,相对于其它窗函数,其主瓣宽,旁瓣比较低,且波动较小,幅值识别精度高。首先进行预加重处理,在经过端点检测之后,将语音信号进行分帧,然后对每一帧信号使用优化的布莱克曼窗处理,使得滤波之后的信号噪声明显减少,求得哭声信号的线性预测系数精度大大提高。
2.2 动态时间规整算法
动态时间规整(dynamic time wraping, DTW)算法,用满足一定条件的时间规整函数W(n)描述测试模板和参考模板的时间对应关系,该规整函数使得两模板匹配时累加距离最小[7],原理图见图4。
有两个时间序列A和B,分别为参考模板和测试模板,他们的长度分别是n和m(m,n为任意值)A=a1,a2,…,ai,…,an;B=b1,b2,…,bi,…,bn;
若n=m,直接计算两个序列的距离,若n不等于m,需要将两个时间序列对齐,采用动态规划(dynamic programming, DP)的方法,进行线性缩放。构造一个n×m的矩阵网格,矩阵元素(i,j)表示ai和bj两个点的欧式距离d(ai,bj),d(ai,bj)=(ai,bj)2。
从(0,0)点开始匹配这两个序列A和B,每到一个点,将之前所有的点计算的距离累加,到达终点(n,m)后,这个累加距离就是序列A和B的相似度。
累加距离γ(i,j)可以按下面的方式表示,累积距离γ(i,j)为当前格点距离d(i,j),也就是点ai和bj的欧式距离与可以到达该点的最小的邻近元素的累加距离之和,即:
r(i,j)=d(ai,bj)+min{γ(i-1,j-1),γ(i-1,j),γ(i,j-1)}

图4 动态时间规整算法原理图
3 系统整体结构设计
系统整体结构见图5,拾音器采集音频信号传输给音频解码芯片,音频解码芯片通过多通道音频串行接口(multichannel audio serial port,McASP)将处理过的音频信号传输给DSP芯片,使用优化的自相关函数算法提取后,然后将处理后的音频与存储器模块中的音频数据库进行比对,确定是否为婴儿哭声,DSP将得到的结果通过串口在控制端的PC上显示。
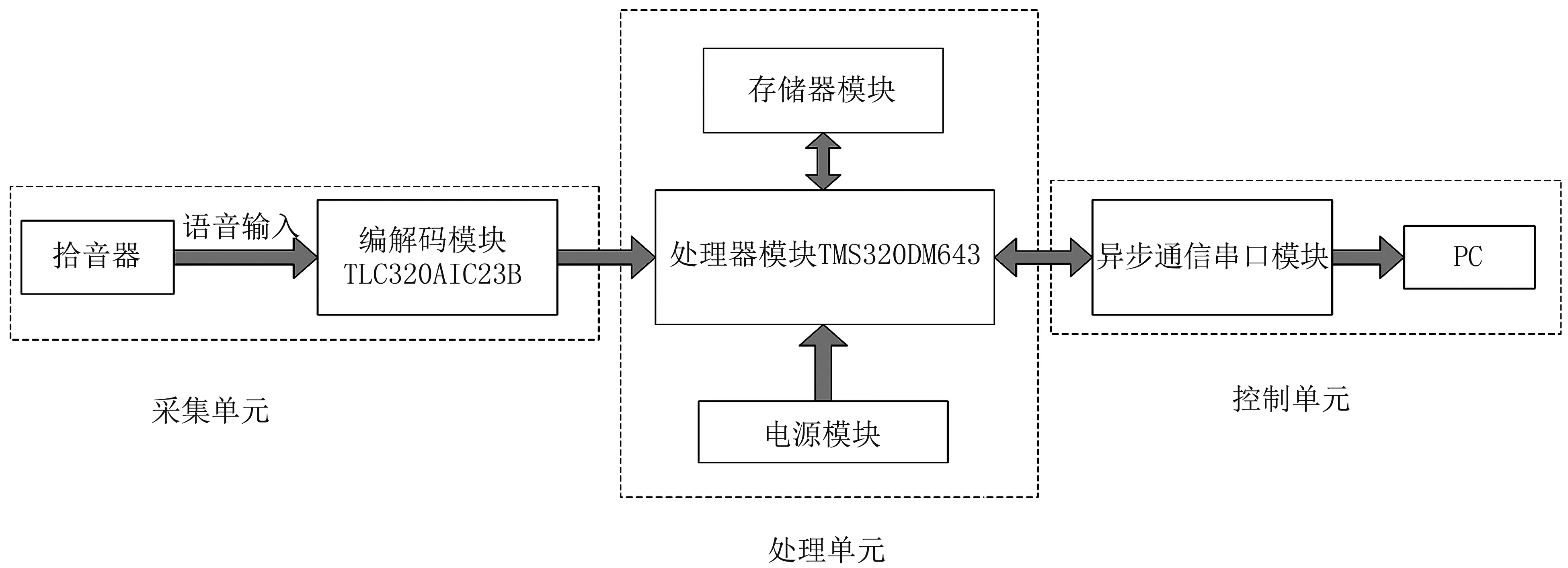
图5系统整体框图
Fig5Theoverallsystemdiagram
3.1 硬件设计
采集单元,拾音器是用来采集现场环境声音再传送到后端设备的一个器件,它是由麦克风和音频放大电路构成。TLV320AIC23B是一款性能极高的音频编解码器芯片,内置放大滤波电路,其数模转换和模数转换功能采用集成过采样数字插值滤波器的sigma-delta技术,支持16位、20位、24位、32位采样,采样率为8~96 kHz。该芯片还集成了一个可调且可编程的麦克风放大器。
处理单元,TMS320DM643芯片是定点DSP中性能最优的数字信号处理平台,非常适合数字媒体的应用。TMS320DM643主频高达5760 (million instructions per second,MIPS),时钟周期最高为720 MHz,为高性能DSP编程技术提供高效的解决方案。TMS320DM643采用两级缓存技术且具有许多功能强大的外设,集成有1个McASP片上外设和一个I2C( Inter-integrated Circuit)总线模块。McASP是一种多通道音频同步串行接口,TLV320AIC23B通过McASP实现与TMS320DM643的数据通信。McASP 同样具有很强的可编程能力,可以配置为多种同步串口标准,直接与各种器件高速接口。另外,我们增加了一个4 M×64-位的SDRAM 存储器,用于存储程序与数据。
控制单元,TL16C752B是具有64字节(first input first output,FIFO)通用异步收发器,它可以完成DSP数据的传送以及串行传输的波特率的设定。TL16C752B是一块串行协议转换芯片,它可以将DSP发送的数据以通用的串行协议传输,实现DSP与其它硬件的数据传输。TL16C752B通过MAX3232实现与计算机的通信,MAX3232完成电平转换,TL16C752B完成数据传送的并/串转换以及串行传输的波特率设定等功能。
3.2 软件设计
软件设计流程图见图6。
根据模块化的程序设计思想,实现程序的简洁明了,方便调用和调试,将所用到的算法程序封装到子程序模块中,对于被调用频率高的子程序,可采用汇编语言实现[8-9]。
完成硬件模块的初始化后,设置McASP以中断的方式接收TLV320AIC23B传过来的数据,使McASP的接收中断,DSP会把接收到的数据存放在某块缓冲区中,此缓冲区为循环缓冲区,以便用一个有限容量的数据区来存储数量极大的语音数据,然后对数据进行采样,将McASP接收到的语音信号利用短时能量和过零率相结合的方法进行端点检测,采用优化的自相关函数算法进行特征提取,使用动态时间规整算法识别,确定结果,然后通过串口显示在计算机上。
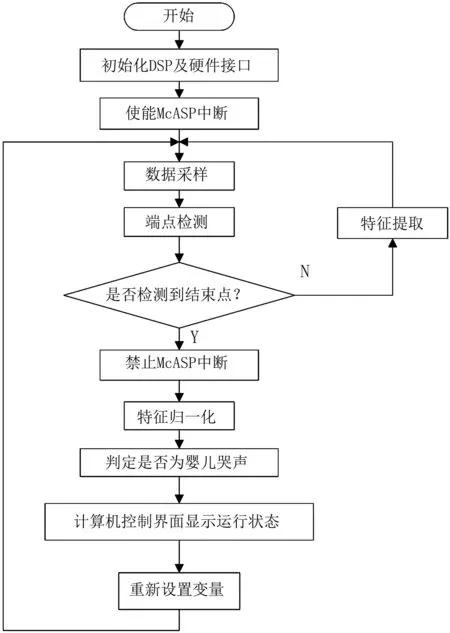
图6 系统主程序流程图
4 实验设计与分析
为测试系统对婴儿哭声的识别率,选取婴儿哭声、笑声、开关门声、狗叫声、非儿童人声进行实验。本研究中分别录制60段婴儿哭声,婴儿声音样本来自5名1周岁以下的婴儿各12段;录制50段婴儿笑声,婴儿声音样本来自5名1周岁以下的婴儿各10段;录制非儿童人声,来自于25名男性,25名女性,分别对阿拉伯数字1,2,3,4,5的发音50段;录制50段狗叫声,来自于5种犬类各10段;录制50段开关门声。
本研究AD转换器的采样率设置为8 kHz,LPC阶数为12,帧长为240。首先,取10段婴儿哭声样本进行训练,样本来自5名婴儿,提取特征参数,组成参考模板库。
实验一:使用汉明窗提取线性预测系数和动态时间规整识别算法,将所有样本从系统的输入端输入,查看输出端显示的结果,实验结果见表1。
表1一般的线性系数提取算法识别率
Table1Generallinearcoefficientextractionalgorithmrecognitionrate

样本数告警数告警率(%)识别率(%)婴儿哭声50418282婴儿笑声50122476开关门声5024狗叫声50816语音 ”1”5048语音 ”2”501293.4语音 ”3”5036语音 ”4”5024语音 ”5”5036
研究表明,当信号为婴儿哭声时,识别率为82%,当信号为婴儿笑声时,识别率为76%,这两项关于婴儿声音的识别率并不理想。而当信号为非婴儿声音时,各种声音的识别结果有一些差异,狗叫声的误报次数最高,经计算得出所有非婴儿声音样本正确识别率为93.4%。可以明显看出,该系统婴儿声音正确识别率偏低,非婴儿声音比婴儿声音的正确识别率略高。
实验二:使用布莱克曼窗提取线性预测系数和动态时间规整识别算法,将所有样本从系统的输入端输入,查看输出端显示的结果,实验结果见表2。
表2改进的线性系数提取算法识别率
Table2Improvedlinearcoefficientextractionalgorithmrecognitionrate

样本数告警数告警率(%)识别率(%)婴儿哭声50489696婴儿笑声503694开关门声5012狗叫声5024语音 ”1”5012语音 ”2”500097.7语音 ”3”5012语音 ”4”5024语音 ”5”5012
研究表明,当信号为婴儿哭声时,识别率为96%,当信号为婴儿笑声时,识别率为94%,这两项识别率达到理想的效果。而当信号为非婴儿声音时,各种声音的误报次数普遍较低,非婴儿声音样本正确识别率可达97.7%。总体来说,该系统婴儿声音和非婴儿声音的正确识别率差距相差不大,都达到较高的水平。
综上,将布莱克曼窗提取线性预测系数和动态时间规整识别算法相结合,婴儿声音和非婴儿声音的识别率均得到了提高,其中,婴儿哭声和笑声识别率得到了明显的提高,系统性能整体得到提升且运行良好,系统识别时间为大约500 ms左右,完全满足育婴箱的要求。
5 结论
本研究设计了一套针对婴儿哭声的监护系统,通过改进的自相关函数算法提取音频线性预测系数特征参数,使用动态规整算法进行识别,提高了对婴儿哭声识别的精确度;另外,本研究介绍了系统的硬件构成和软件设计架构,验证了平台的性能有效性。该系统实时性好,分辨率高,操作简单,想法新颖,在实际生活中有广阔的应用前景。
猜你喜欢
延河·绿色文学(2020年6期)2020-09-10 01:20:01
儿童时代·快乐苗苗(2020年6期)2020-06-29 12:36:03
计算机工程(2020年3期)2020-03-19 12:24:50
中国化工贸易·下旬刊(2019年5期)2019-10-21 03:13:08
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
幸福家庭(2019年14期)2019-01-06 09:15:36
中国交通信息化(2018年3期)2018-06-13 03:27:58
佛山陶瓷(2016年11期)2016-12-23 08:50:27
大观(2016年9期)2016-11-16 10:31:30
中国交通信息化(2016年2期)2016-06-06 07:28:02
