
基于LIBSVM的融合傅里叶幅值与相位的示功图识别方法
2018-10-18 10:11:18,,
计算机测量与控制 2018年10期
, ,
(中国石油大学(北京)地球物理与信息工程学院,北京 102249)
0 引言
石油在能源结构中占据至关重要的地位,采油是石油生产过程中最基础和重要的环节。目前常用的采油方法中,有杆泵采油法是应用最为广泛的[1]。因此,有效地监测抽油机井的工作状态,快速准确地识别油井故障并采取合理有效的措施,对提高采油效率,增进油田效益有着举足轻重的作用。
油井实时示功图是油井工况的一个重要表征,它能够直观地反映出抽油机在采油过程中发生的各种异常状况,同时联系地质情况及井下技术状况等因素,可以识别出井下泵发生的故障类型。根据示功图进行工况分析的主要方法有“五指式动力仪”分析法、地面示功图分析法和井下泵示功图诊断法。相比于其它方法,地面示功图分析法具有更直观便捷,简单易行的优点。因此,根据油井示功图判断油井的工况是目前被广泛应用的方法[2]。
在使用示功图进行工况诊断的过程中,如何准确地对示功图进行特征提取,直接关系到能否精确地对油井存在的故障做出判断,因此,必须要选取恰当的特征提取方法[3]。目前,用于油井工况分析的示功图特征提取的方法主要有基于几何不变矩的矩特征向量分析法、基于网格法的灰度矩阵统计量法和基于DFT的傅里叶描述子法[4-6]。相比于其它方法,傅里叶描述子法具有计算方法简洁高效、计算量小、冗余信息少的优势,可以比较准确地提取出示功图的图像特征。
在传统的傅里叶描述子法中,只提取了示功图数据经DFT得到的各次谐波的幅度谱,并没有对各次谐波的相位谱进行整合,相当于只提取了图像波动的幅度情况,并没有提取图像波动的位置信息,从而丢失了示功图曲线形状的凸起或凹陷这类代表位置的有用信息,对图像识别的准确性有较大的影响。本文提出了一种融合信号DFT的幅值与相位信息的特征提取方法,更加完整地提取了示功图的特征信息,并构造出能在极大程度上反映示功图图形特征的特征向量。此外,相对于现在被广泛应用的二分类支持向量机,本文采用一种基于多分类向量机的分类识别方法[7-8],并优选了核函数,进一步提高了示功图诊断的准确率。
1 示功图特征分析及特征向量的构造
1.1 示功图特征理论分析
示功图是指在一个采油冲程过程中,以抽油机相对下死点的位移S为横轴,以抽油机的悬点载荷P为纵轴,绘制出一条关于P-S的曲线,它是一个封闭曲线[1]。
理论示功图是指只考虑悬点所承受的静载荷及由其引起抽油机杆柱及有关柱的弹性变形,而不考虑其它因素影响时,所得到的示功图曲线。典型示功图是在理论示功图的基础上,只考虑某单一因素影响的载荷随位移的变化关系曲线。
图1为抽油机井常见工况的典型示功图图例[9]。由图可见,正常示功图近似于平行四边形(理论示功图),上下边出现轻微的震荡波浪线;各类典型故障的示功图图形均存在一定的凸起或凹陷,且凸起或凹陷的位置不同。
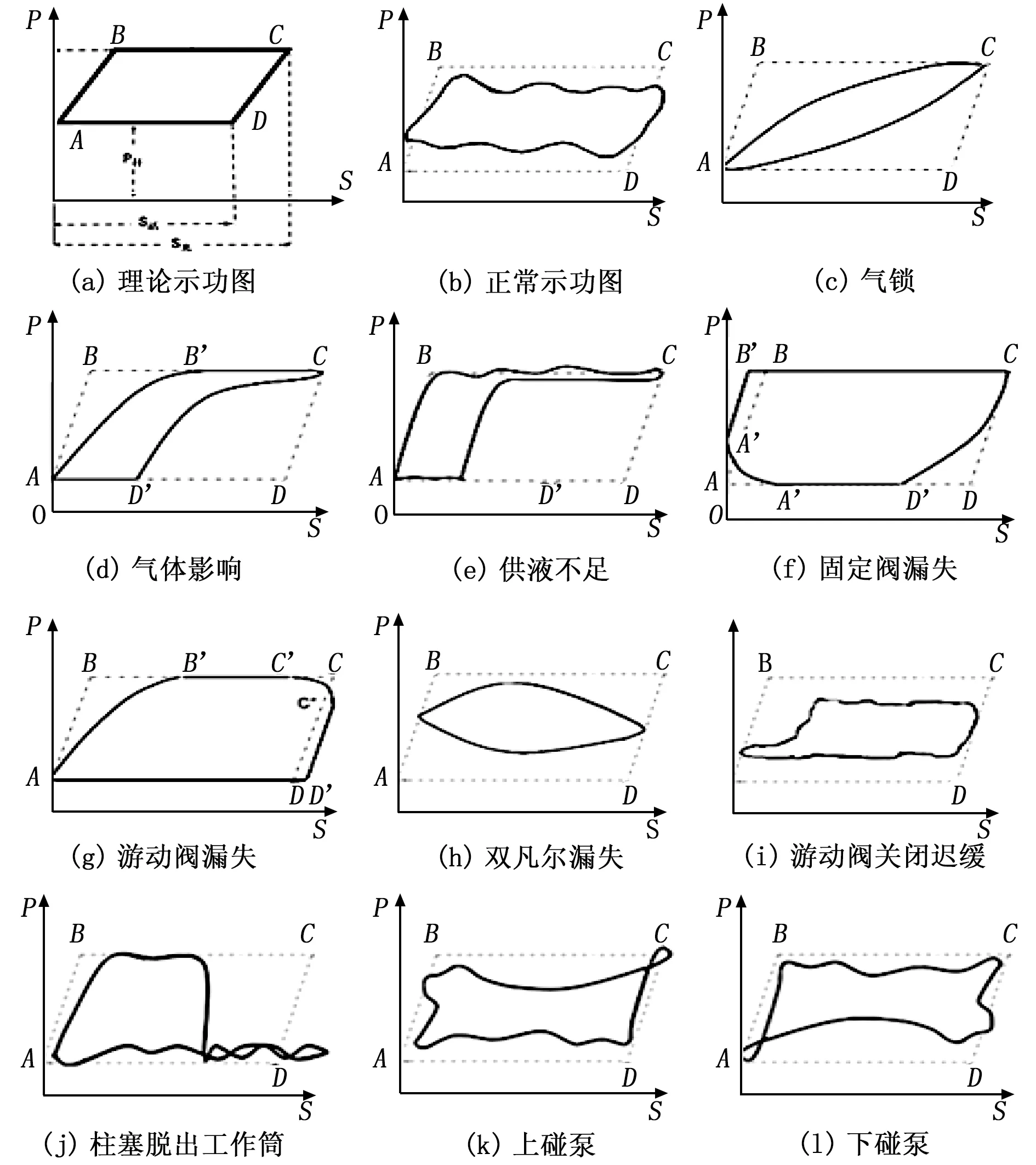
图1 典型示功图图例
在油田现场,由示功仪所采集的示功图一般是由下死点(图1(a)中A点)开始,经过一段时间达到加载终止点(图1(a)中B点),该过程中得到的曲线称为增载线(图1(a)中AB段);保持一定时间后又由上死点(图1(a)中C点)开始,经过一段时间达到卸载终止点(图1(a)中D点),该过程中得到的曲线称为卸载线(图1(a)中CD段)。
结合各类故障示功图的形成因素,对图1中各图进行分析可知,各类典型故障的示功图图形的特征主要表现为:
1)气锁:增载线和卸载线均有一定弧度。
2)气体影响:增载线、卸载线均都比较平缓,但增载线相对于卸载线更陡一些。
3)供液不足:增载线和卸载线相互平行,且均比较陡直。
4)固定阀漏失:卸载线比增载线平缓,示功图的左下角为圆弧。
5)游动阀漏失:增载线比卸载线平缓,示功图的右上角为圆弧。
6)双凡尔漏失:增载线和卸载线都比较平缓,形状呈水平椭圆形。
7)游动阀关闭迟缓:加载线延长且形状较陡直,示功图的左上方有缺失。
8)柱塞脱出工作筒:增载线正常,卸载线不太明显,图形右下角有波浪曲线。
9)上碰泵:图形右上角有一个环状凸出。
10)下碰泵:图形左下角有一个环状凸出。
1.2 示功图特征DFT分析
在油田现场,在一个冲程内,由示功仪所采集的实测示功图数据通常为200或250个点的位移与载荷数据,从而可以得到一组序列值(sn,pn),n=0,1,…,N-1,其中sn为位移,pn为载荷。将位移sn和载荷pn组合成如下一维复数序列:
zn=sn+jpn
n=(0,1,…,N-1)
(1)
对于封闭的曲线,该序列是以点数N为周期的周期序列。对其做DFT,得到:
k=0,1,…,N-1;n=0,1,…,N-1
(2)
Zk的模|Zk|称为DFT的幅值,反映的是示功图序列波动的各次谐波的大小,其相角h(k)称为DFT的相位,包含着其波动的位置信息。
图2为对各个典型示功图曲线作250点DFT得到的幅值谱|Zk|的曲线。由于幅度谱反映的是示功图波动的大小情况,因此幅度谱分析结果与前文所述的各类典型故障的示功图图形均存在一定的凸起或凹陷相对应。
根据图2可知,某些图形特征相似的故障类型的示功图,如“气体影响”与“供液量不足”、“游动阀关闭迟缓”与“柱塞脱出工作筒”均存在较大的面积缺失现象;再如“上碰泵””与“下碰泵”均存在环状凸出现象等,它们两两之间的DFT幅度谱差异并不大,因此,难以对这些故障种类的示功图进行准确地区分。
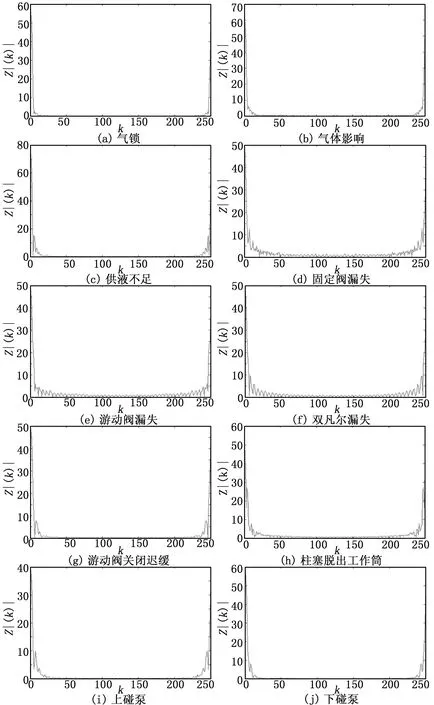
图2 典型故障示功图的DFT幅值信息
图3为分别对各个典型示功图的上行数据(增载线)和下行数据(卸载线)作250点DFT得到的相位谱h(k)的曲线。由于相位谱反映的是示功图波动的位置情况,因此相位谱分析结果与前文所述的各类典型故障的示功图图形的凸起或凹陷位置不同相对应。
根据图3可知,对于前文所述的DFT幅度谱差异不大的故障类型的示功图,如“气体影响”与“供液量不足”、“游动阀关闭迟缓”与“柱塞脱出工作筒”、“上碰泵”与“下碰泵”,它们两两之间的相位谱则有明显的差异,可以较好地分析出示功图特征的位置,从而较好地对这些故障种类的示功图进行准确地区分。
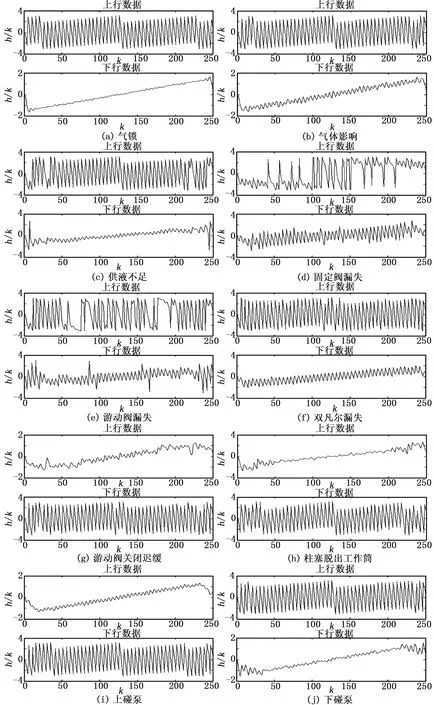
图3 典型故障示功图的DFT相位信息
1.3 特征向量构造
为了克服传统傅里叶描述子方法在用于示功图识别的缺陷,本文将示功图序列的DFT幅度谱与相位谱进行融合,构造了能够充分反映出示功图图形的形状轮廓特征、细节波动与凹凸位置信息的特征向量。同时,根据DFT的定义可知,此特征向量的各个分量之间均线性无关并且相互正交,从而最大程度地获取了示功图在其特征空间的信息,因而有效地提高示功图类型识别的准确率。由欧拉变换可知,
Zk=|Zk|ejh(k)=|Zk|cos(h(k))+j|Zk|sin(h(k))
(3)
公式(3)中的实部和虚部均同时包含了DFT的幅度信息和相位信息,因此,为了简化计算,仅选取实部来构造特征向量。又由于信号的主要能量集中在其低次谐波分量上,因此,在兼顾精度及计算量的前提下,选取DFT的直流项及前9次谐波来构造特征向量,则最终构造的融合了幅度与相位信息的示功图特征向量如(4)式所示:
(4)
这样,对每一个示功图都可以构造出一个线性无关的特征向量,以此特征向量作为该示功图的特征,输入到由训练样本训练得到的分类判别器中,进行人工智能判别,从而对示功图进行正确的分类识别,得到油井的实际工况。
2 支持向量机算法
2.1 经典支持向量机算法
支持向量机(SVM)是Corinna Cortes和Vapnik等人于20世纪90年代提出的一种机器学习方法,它主要应用于模式识别领域,是一种结合了统计学理论的VC维理论以及结构风险最小化原则的模式识别方法,在有限的训练样本中寻求学习能力与模型复杂度融合后的最佳折中结果,从而得到最小误差分类器。
支持向量机的基本思想是:首先,判断样本数据是否线性可分:1)若样本为线性可分,则直接寻找最优分类面进行分类;2)若样本为线性不可分,则引入两个变量(松弛系数和惩罚分量)进行辅助分析,通过非线性映射将样本映射到高维特征空间中,在高维空间中寻找最优分类面对样本进行分类[10];同时,它通过使用结构风险最小化原理,也在一定程度上对分类器实现全局的最优效果进行了保障。
SVM只用于两类问题的分类,解决多分类问题时通常是利用若干个两分类决策器解决多分类问题,具体实现方法大致可分为以下几种:
1)一对一分类方法(one-versus-one):该方法将多分类问题转化为若干个子分类问题,任意两类构造一个两分类分类器,对所有的两分类分类器都进行判断,最终的结果为所占比重最大的类,如图4所示。当子分类的数量过多时,计算量很大,会大幅度的降低训练与测试的速度。分类结果可能会出现分类重叠现象。
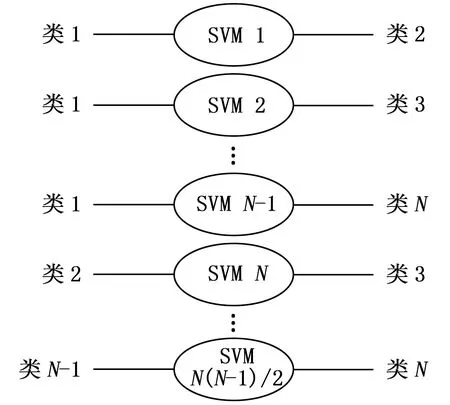
图4 一对一分类方式示意图
2)一对多分类方法(one-versus-rest):该方法将问题转化为多个两分类问题,将某类看作两分类问题中的一类,将其余的所有类看作另一类进行判别分类,依次循环,最终结果为分类函数值最大的类,如图5所示。若训练样本数目过大,会导致训练过程耗时很长。分类结果可能会出现分类重叠现象或不可分类现象。
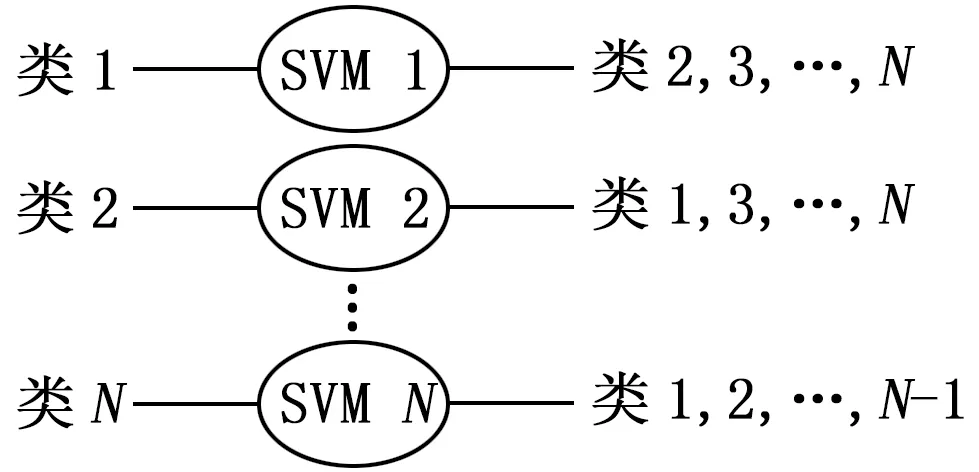
图5 一对多分类方法示意图
3)二叉树分类方法(Binary Tree):该方法是将样本数据分为两大类,然后继续划分每个大类为两个类,直至所有类不能再划分为止,如图6所示(图中示例n=4)。在训练学习的过程中,存在错误向下累积现象。
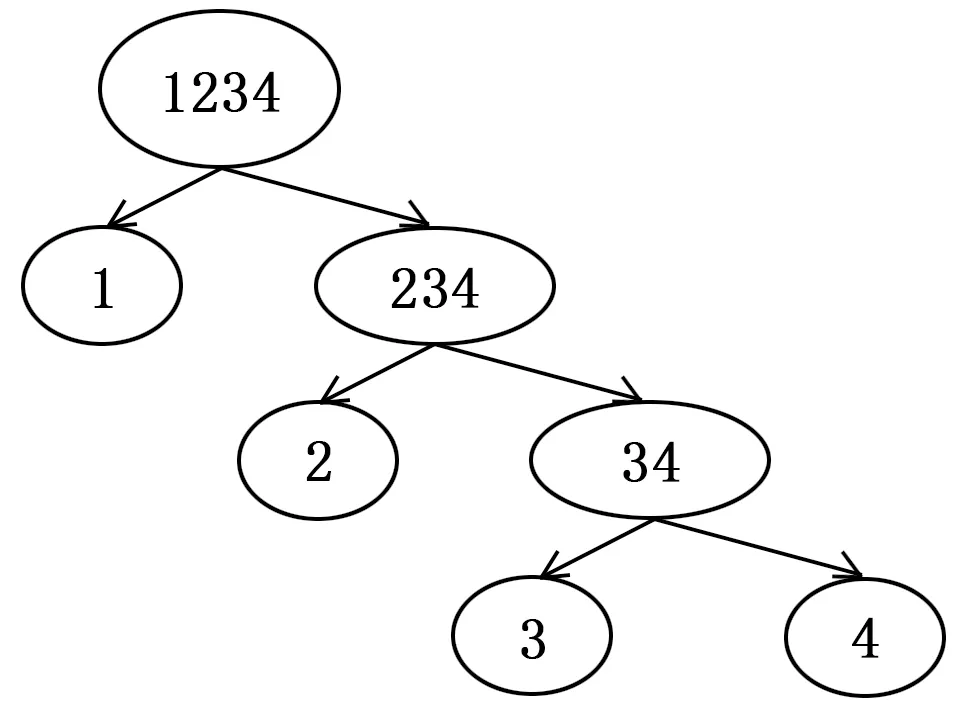
图6 二叉树方法示意图
4)DDAG算法(Decision Directed Acyclic Graph):该算法以有向无环图为理论基础,将所有分类器构成有向无环图,每次参与分类的两个类别可无重复的任意选取,如图7所示(图中示例n=4)。在训练的过程中,同样存在错误向下累积现象,而且训练过程的时间通常较长。
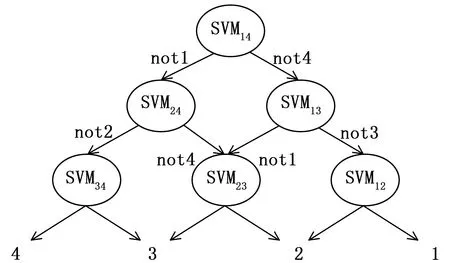
图7 有向无环方法示意图
2.2 LIBSVM算法
针对经典SVM的不足之处,许多研究人员对SVM进行了更为深入地研究,他们在将公式变形后研究出应用范围更具体且具有某些特定优势的变形算法。其中,由台湾大学林智仁博士等[11-12]于2001年开发设计的LIBSVM算法融合了收缩和缓存技术,
具有程序小,运用灵活;输入参数少,操作简单;是开源的,方便改进、易于扩展等特点,同时,具有较好性能又适用于Windows、Unix等多种操作系统,因此,目前被许多国际著名研究机构所采用作为训练算法。
LIBSVM作为通用的SVM软件包,该软件对SVM所涉及的参数调节相对比较少,提供了很多默认的参数设置,利用这些默认参数可以有效地解决包括分类问题在内的多种类型的问题。同时,它还有了交互检验的功能,利用所提供的多种常用核函数可以将交叉验证的参数选择变得更为精准。该软件可以解决C-SVM、ν-SVM、ε-SVR和ν-SVR等问题,包括基于一对一算法的多类模式识别问题。
所以,本文选用了LIBSVM支持向量机分类器,它能够将支持向量机、分布估计与回归完整结合在一起,从而对不同类型的示功图进行判别与诊断。LIBSVM分类器的设计与应用步骤如图8所示。
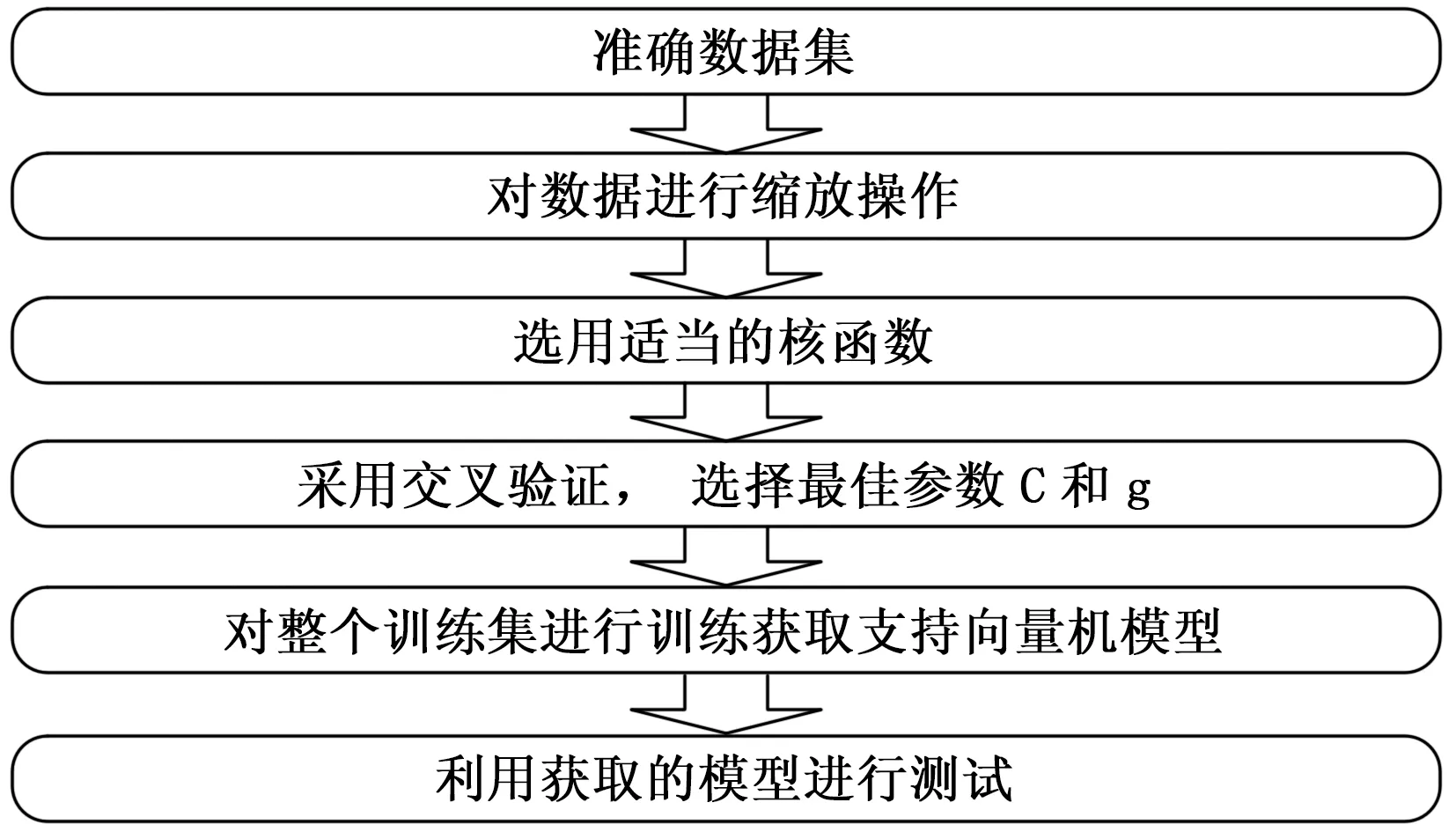
图8 LIBSVM分类器的设计与应用步骤
3 应用实例
3.1 实验过程
本论文研究的是一种对油井实测示功图进行分类识别的方法,该方法的实验过程分为图像预处理、训练和测试3个阶段。整体实验过程的流程如图9所示。

图9 实验过程流程图
图像预处理阶段主要是消除图像中的无关信息,增强有用信息的可检测性,同时最大限度地简化数据,从而提高特征提取及匹配识别的准确性。主要包括归一化处理、形态学处理和坐标数字化处理。
训练阶段是根据已知故障类型的示功图的面积特征,将故障示功图粗略分为若干个集合,然后分别在各集合中对由训练样本构造的特征向量进行训练,最终得到多分类判别器。
测试阶段是根据待识别故障类型的示功图的面积特征来确定其所属集合,然后将由其构造的特征向量输入到相应的多分类判别器中,从而实现示功图的分类判别。
训练阶段和测试阶段在构造特征向量时均采用利用前文介绍的方法,在得到融合DFT幅度谱与相位谱各特征成分的特征向量后,均采用匹配高斯径向基核函数的支持向量机对示功图进行训练和测试。
3.2 实验参数选择
本实验在Matlab仿真平台上进行仿真验证。由于LIBSVM算法的准确率主要与训练和测试时所选取的核函数种类有关,而核函数的正确选取依赖于产生分类问题的实际问题的特点,不同的实际问题对相似程度有着不同的度量,因此,选择正确的核函数有助于提高分类准确率。
核函数的种类由参数t决定。t=0时为线性核;t=1为多项式核;t=2时为高斯径向基函数;t=3时为Sigmod核函数;t=4为自己定制的任意一种的核函数。表1为采用不同核函数时识别准确率的对比。对表1中数据进行对比分析可知:
1)对于相同的数据,不同核函数的识别准确率不同;
2)当样本数据量较少时,高斯径向基核函数识别准确率更高。

表1 不同核函数时识别准确率对比 %
因此,考虑到实际采集到的示功图样本数量较少的情况,本实验在训练阶段和测试阶段支持向量机的核函数均选取高斯径向基核函数。
3.3 实验结果及分析
本实验选取了气锁、气体影响、供液不足、固定阀漏失、游动阀漏失、双尔凡漏失游动阀关闭迟缓、柱塞脱出工作筒、上碰泵和下碰泵,共10 种油田实际生产中易出现的故障类型的共275组示功图数据进行分析研究。利用现场采集的实测示功图建立样本库,并根据面积特征划分为若干个集合,在各集合中根据每类典型故障示功图样本的数量情况,适当选取其中一部分作为训练样本,其余部分划归为测试样本。在构造特征向量时,分别采取仅使用幅值信息和融合幅值信息与相位信息两种方法,对相同的样本分别进行训练和测试,测试结果如表2所示。

表2 不同特征向量构造方法的识别准确率对比
其中,方法一为仅利用DFT幅度谱构造特征向量;方法二为融合DFT幅度谱与相位谱构造特征向量。
结合前文对各类典型故障的示功图图形的理论分析和DFT分析结果,对表2中数据进行对比分析可知:
1)本文提出的方法二的识别准确率的平均值较方法一的识别准确率的平均值有明显提高;
2)方法一识别准确率较高的均为示功图图形特征明显且与其他故障类型的图形相似度较低的故障类型,如气锁、双凡尔漏失等,对于这些故障类型的示功图,本文提出的方法二可将方法一的识别准确率继续保持;
3)方法一识别准确率较低的故障类型多为图形特征不明显或与其他故障类型的图形相似度较高的故障类型,如气体影响、供液不足、固定阀漏失、游动阀关闭迟缓、柱塞脱出工作筒、下碰泵等,对于这些故障类型的示功图,本文提出的方法二的识别准确率相较于方法一的识别准确率则有大幅提高。
4 结论
1)提出了一种融合DFT幅值与相位信息的示功图特征提取方法,相较于传统的傅里叶方法,本文方法不仅可以反映示功图曲线的波动特征,而且可以反映示功图曲线凹凸的位置特征,能够更加全面和准确地表达出示功图所包含的特征信息。
2)相对于现在被广泛应用的二分类支持向量机,本文采用一种基于多分类向量机的分类识别方法,并选取高斯径向基核函数,进一步提高了示功图诊断的准确率。
3)实测表明,本文提出的示功图识别方法对油井示功图故障类型的诊断更加准确有效,可为油井生产的实时分析与优化控制提供技术支撑。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
许昌学院学报(2018年4期)2018-05-02 12:27:37
电子测试(2018年1期)2018-04-18 11:52:35
中华建设(2017年1期)2017-06-07 02:56:14
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
石油化工自动化(2015年6期)2015-02-26 05:47:47
电测与仪表(2014年15期)2014-04-04 12:05:20
压缩机技术(2014年4期)2014-03-20 15:55:45
