
基于机器学习的无参考图像质量评价综述
2018-10-16 05:49:48杨璐,王辉,魏敏
计算机工程与应用 2018年19期
杨 璐,王 辉,魏 敏
1.中国科学院 光电技术研究所,成都 610209
2.中国科学院大学,北京 100049
3.成都信息工程大学 计算机学院,成都 610225
1 引言
视觉质量是图像复杂且固有的特征,其复杂度在和人脑视觉处理机制相关[1],因此对图像质量准确建模一直是热点研究问题。通常方法是与理想的成像模型或者完美的参考图像对比得到失真度量[2]。根据是否存在可参考的图像,将图像质量评价方法分为全参考(Full Reference,FR)、半参考(Reduced Reference,RR)和无参考(No Reference,NR)质量评价三类,其中无参考图像质量评价(NRIQA)也叫盲图像质量评价(Blind Image Quality Assessment,BIQA)[3-4]。NRIQA方法在实际应用中,需求广泛但实现难度大于有参考图像或特征的方法。随机器学习发展尤其是深度学习对各个领域的影响一致[5],NRIQA技术也在不断革新。本文通过分析近十几年典型的NRIQA算法,归纳不同算法特点,研究其现状及发展趋势,为后续研究提供参考资料。文章结构如下:第1章介绍常用数据库和衡量NRIQA算法性能的指标,总结NRIQA算法面临的主要问题和解决方法概要;第2章介绍典型算法,这些算法在提出时都具有当时最先进的性能,甚至沿用至今,极具代表性;第3章统计在LIVE数据库[6-8]对比实验及算法鲁棒性测试实验,即在LIVE[7]数据库上重新训练,并在CSIQ数据库[9]上测试;第4章根据分析实验结果得出结论,总结盲图像质量评价现状及发展趋势。
2 无参考图像质量评价方法衡量
图像质量评价旨在拟合人眼,通常以算法的评价值与与人眼的主观评分值进行计算比较。在公共数据库上,图像的主观评分值用平均主观得分(Mean Opinion Score,MOS)表示或者使用平均主观得分差异(Differential Mean Opinion Score,DMOS)表示。其范围因不同数据库而异,常见有[0,1]、[0,5]、[0,9]和[0,100]。MOS值越大表示图像质量越好,DMOS值越大表示图像质量越差。近年来提出的NRIQA方法大都基于机器学习方法,每种算法都有自己的提出思想和特点。为了方便与其他方法对比,通常选择在公共数据库上训练并测试,使用公认的技术指标进行算法性能衡量。本章首先介绍常用的图像质量评价数据库和公认的算法性能衡量指标。
2.1 常用数据库和算法性能指标
仅介绍常见的几个公开数据库和常用性能指标。
(1)LIVE(Laboratory for Image&Video Engineering)数据库[7]是最为广泛应用的共享数据库,共982幅图像,包含JPEG2000、JPEG、白噪声、高斯模糊和快速瑞利衰减5种其他基准库共有失真类型,图像质量用范围为[0,100]的DMOS值表示。
(2)CSIQ(Categorical Subjective Image Quality)数据库[9]共866幅失真图像,6种失真,图像质量由范围为[0,1]的DMOS值表示。
(3)TID2008(Tampere Image Database)数据库[10]包括1 700失真幅图像,17种失真,范围[0,9]的MOS值表示质量。
(4)TID2013数据库[11]将TID2008扩充至3 000幅图像,包含24类失真,同时给出峰值信噪比、结构相似度SSIM 值[2,6]、MSSIM[12]值、像素域的 VIF[13]值等作参考。
NRIQA算法性能衡量指标最广泛采用的是视频质量专家组(VQEG)采用的评估标准——线性相关系数和秩相关系数。此外,还有评估方式[14-15]以解决没有MOS值的大规模图像数据库。
(1)线性相关系数(Linear Correlation Coefficient,LCC),也称皮尔逊线性相关系数(Pearson Linear Correlation Coefficient,PLCC),描述预测值与主观评分之间的相关性和算法的准确性。
(2)秩相关系数(Spearman’s Rank-Order Correlation Coefficient,SROCC)衡量算法的单调性。
2.2 难点及现有解决方案
基于学习的图像质量评价难点有二:第一,图像质量与视觉、心理等复杂因素有关,当前没有成熟的理论支撑模型;第二,如上述介绍基准库数据量太小,无法支撑大型深度网络,扩充数据库费时、昂贵、缓慢。典型的NRIQA方法几乎都是从以上两个问题着手解决。
2005年第一次将自然场景统计(Natural Scene Statistics,NSS)[16]用于图像质量评价后,大量实验表明NSS特征与图像质量存在密切关系。之后采用小波、DCT等提取不同子带特征,或在空域获取NSS特征,如:CORNIA[12]和BRISQUE[17]。在学习方法中,使用支持向量回归或神经网络提取特征并映射到MOS/DMOS,或使用码本结合特征。利用没有MOS/DMOS值的数据集,通过学习构造码本克服数据规模的缺陷如CORNIA,尽管其具有高维度但后来BIQA模型中经常采用,例如:BLISS[18]、dipIQ[19]和IQA-CNN[20](一个卷积和两个全连接层的CNN作为CORNIA端到端版本)。
对于深度学习,常见的(Opinion Free,OF)BIQA模型采用其他方式标记图像质量,利用其他非IQA数据库扩大训练集规模。如BLISS利用FRIQA测量得出的综合分数,先进的FR方法与主观意见分数高度相关,可用作人眼意见分数的近似值;dipIQ利用具有不同图像内容的大规模数据库获得大量质量可识别图像对,然后使用RankNet[21]从数百万的DIP中学习BIQA模型;RankIQA[22]使用相对质量排序已知的降质图像训练连体网络,再将网络参数迁移到传统CNN上训练更深层广泛的网络;DLIQA[23]保留了图像的语义信息,按设定规则标记图像质量等级,MEON[14]使用不同数据库对子任务进行分别训练。对于(Opinion Aware,OA)BIQA方法,直接在标注了质量分数的IQA库训练,但也采取不同措施增加数据量或扩展网络深度。IQA-CNN从图像中采样32×32图像块从而增加训练集规模;Deep-BIQ[24]利用迁移学习从预先训练好的分类模型微调。对BIQA建模根据需求通常归为回归问题,按处理思路也被归为分类问题或分类+回归的问题。通用BIQA模型依靠失真图像和相应意见分数来学习将图像特征并映射到质量分数的回归函数。可分为:
(1)单任务模型
失真类型已知的特定失真质量评价,如NSS[16]方法针对JPEG2000压缩;
失真未知的通用失真质量评价,这也是大多数方法目标。
(2)多任务模型:如失真类型识别和质量预测
两个子任务无关,如IQA-CNN++[25];
两个子任务相关如MEON[14]。
分类问题:模型探讨失真图像质量的区间,通过其他方法处理具体意见分数。如DLIQA将盲质量评估重新定义为5级分类问题,对应于5种明确的心理概念以促进学习人类定性描述;HOSA通过K-均值聚类,学习感知特征与主观意见分数之间的映射关系。该类方法通常在输出层添加回归模型实现质量分数的输出。
3 NRIQA学习模型
下文将NRIQA模型即BIQA模型分为基于机器学习和基于深度学习。尽管深度学习属于机器学习范畴,但由于近几年发展迅猛,一些特有的学习手段如残差网络相继被提出,因此越来越多的人将其单独看作一种学习方法。基于机器学习的BIQA模型利用能够表征自然场景特性的统计模型估计出参数并作为作为回归特征,学习回归模型获得图像的质量分数,自然场景统计NSS是最典型的特征。基于深度学习的BIQA模型面临的首要难题是现有训练集规模不够,最大的数据库也仅包含了千位的图像及注释。为扩展网络深度迁移学习是自然联想到的方法,继承预训练用于分类任务网络的结构和权重进行微调,但其性能和效率很大程度上取决于预训练任务的普遍性和相关性。为解决图像标注数据量不足,基于深度学习的BIQA算法分为两类:一类直接利用标注的MOS/DMOS标签训练浅层网络,这类方法称为OA-BIQA(Opinion Aware);另一类从结合其他非IQA数据库设计自动标签生成模型、任务分段实现等方式增加训练数据规模,称为OF-BIQA(Opinion Free)方式或OU-BIQA(Opinion Unaware)。以下选择典型的机器学习算法和深度学习算法详细介绍,以通用的全参考方法作对比。
3.1 典型全参考对比方法
FRIQA方法相比BIQA方法,已经形成了较为完善的理论体系和评价模型。在提出新的BIQA方法后,会与FRIQA方法比对。实验数据表明,典型BIQA方法其性能接近甚至优于FRIQA方法。最常用的FRIQA是基于像素统计的均方误差MSE、峰值信噪比PSRN,和基于结构信息的结构相似度SSIM[2],基于SSIM还有多种变形,如效果不错的 IW-SSIM[26]、MS-SSIM[2]。此外,2011年提出的特征相似性指数FSIM[27]强调人类视觉系统理解图像主要根据图像低级特征,使用相位一致性和梯度两种特征建立相似性指数,又加入颜色特征建立彩色图像特征相似度指数FSIMc[27]。2012提出的梯度相似度GSM[28]强调梯度能传达重要的视觉信息,梯度特征和像素值结合能达到不错的效果,实验测得性能比FSIM差,但算法计算速度快很多。2014提出的视觉显著性指数VSI[29]认为超阈值的失真很大程度上会影响图像的显著图,把FSIMc中的相位一致性特征换成了显著图。更多的全参考方法参见文献[30]。
3.2 机器学习中的典型模型
通用BIQA算法学习从图像特征到相应质量分数映射,或者在映射之前将图像分成不同的失真。这类型的算法均面临以下问题:(1)需要大量样本训练鲁棒性;(2)实验证明算法对不同数据集敏感;(3)使用新训练样本时必须再训练。而NSS特征反映了图像内容的自相似性和特定性,因此不存在对不同数据库敏感,使用新样本时也无需再训练。
2005年,Sheikh等提出NSS[16]学习模型,第一次尝试对JPEG2K压缩图像进行无参考质量评价。方法的成功表明人对图像质量的感知和失真的可感知性确实与图像的自然性有关。但模型精度无法提高很快被超越,其原因在于提取的先验信息并不能完全解释降质过程,第二表征JPEG2K压缩的NSS模型不完善。
2010年,Moorthy等提出BIQI[31],一个基于NSS的NRIQA框架。BIQI对5项失真预设5个质量评估算法实现失真未知的IQA任务。估计存在已定义失真的概率,再计算各个失真对应质量,最终质量表示为失真概率与对应质量加权求和。BIQI模型分成两步的思想对后续研究有重要影响,但局限性也很明显,对于未定义失真类型BIQI无计可施。
2010年,Saad等提出BLIINDS[32]以改善机器学习训练出的算法其性能受特征的限制。模型基于局部离散余弦变换系数的统计,以期到达满足实时系统需求的性能。但其准确率一般,究其原因未能如预想一样尽可能多地提取决定视觉质量的特征,提取的特征并不足以表示图像质量。
2011年,Moorthy等再提出DIVINE[33]基于失真识别的图像真实度和完整性评估指数。基于失真图像统计特性变化完成失真类型识别和质量预测,但DIIVINE计算量大,实时性不强。
2012年,Saad等提出BLINDS的后续研究模型BLIINDS-II[34]。依赖贝叶斯推理模型预测给定某些特征的图像质量。
BLIINDS-II和DIVINE、BLIINDS方法对比较。BLIINDS-II和DIIVINE间有明显的设计差异。BLIINDSII采用更简单的表示方式,使用更低维的特征空间和更简单的单级(贝叶斯预测)框架,在更稀疏的DCT域中运行。BLIINDS指数旨在实现在实时系统中运行的质量评估算法所需的速度和性能。
2012年,He等人基于NSS稀疏表示提出了SRNSS[35]。在小波域中提取NSS特征;通过稀疏编码表示特征。SRNSS模型采用更少的参数,多次实验显示具有强鲁棒性。
2012年,Peng等人提出无参考图像质量评估的码本表示CORNIA(Codebook Representation for Noreference Image Assessment)[12]。CORNIA提取图像块作为局部特征,表明可以直接从原始图像中学习特征。不考虑任何先验知识使其适应性更广,基于CORNIA的后续研究取得了很好的效果。
2012年,Mittal等提出另一种在空域提取NSS特征的模型:盲图像空间质量评估器BRISQUE(Blind/Referenceless Image Spatial Quality Evaluator)[17]。灵感来自Ruderman[36]关于空间自然场景建模以及SSIM的成功。模型使用局部标准化亮度系数来量化失真产生的“自然度”损失,具有非常低的计算复杂性适合实时应用。
CORNIA和BRISQUE对比,提取NSS特征传统方法是通过图像变换和滤波技术,如小波变换、余弦变换和Gabor滤波等,非常耗时不适用于实时系统。CORNIA和BRISQUE都是在空域提取NSS特征。不足的是这类模型一旦建立很难优化,不会像深度学习模型一样随训练数据增加,模型更加准确。
2015年,Zhang等提出集成的局部自然图像质量评价器 ILNIQE(Integrated Local Natural Image Quality Evaluator)[37]。通过整合多个NSS特征:归一化亮度统计、均值减法和对比归一化统计、梯度统计、Log-Gabor滤波器响应的统计和颜色统计学习多元高斯模型。但LINIQE并没有比CORNIA或者BRISQUE得到更好的结果,究其原因选择的特征并不能完全表征图像质量。
2015年,Zhang等提出了基于图像语义显著性方法SOM(Semantic Obviousness Metric)[38]。语义显著性特征来自目标检测方法BING[39]找到的图像中多个作为目标的概率排序的相似区域。虽然BING非常快,有很高的物体检测率和良好的泛化能力,但也决定了SOM与图像中目标息息相关,目标丰富质量差的图像获取的信息也能多于目标少质量好的图像,同时对于天空这类不具有明确边界的图像算法存在局限性。
2016年,Xu等人提出了高阶统计聚合算法HOSA(High Order Statistics Aggregation)[40]。图像块作为局部特征,通过K均值聚类构造包含100个码字的小码本。将每个局部特征软分配给几个最近的聚类,并且将局部特征与对应聚类之间的高阶统计量(均值、方差和偏度)的差异软聚合,以建立全局质量感知图像表示。
3.3 深度学习中的典型OA模型
在深度学习中质量预测是在输出层做回归,将图像多维特征转化为一个可以表示质量的数值。通常依赖失真图像和相应意见分数来学习将图像特征映射到质量分数的回归函数。这类型的模型被认为是具有“观察意识”(Opinion Aware,OA)的BIQA模型。以下介绍几种典型算法模型。
2014年,Kang等提出IQA-CNN[20]基于卷积神经网的BIQA模型。将特征提取和回归集成到CNN框架加深网络深度提高学习能力,同时可以使用反向传播等方法训练,方便结合改善学习的技术如dropout[41]和ReLU[42]。IQA-CNN相当于CORNIA的神经网络实现。IQA-CNN关注由图像降级引起的失真,例如模糊、压缩和加性噪声等,对于对比度或亮度引起的质量差异不作为失真。
2015年,Kang等继续提出基于IQA-CNN的后续研究,一个简洁的多任务CNN:IQA-CNN++[25]估计图像质量并识别失真,其参数比IQA-CNN减少了近90%。IQACNN++增加卷积层数量并减小滤波器的接受野,修改全连接层。在满足需求的前提下希望获得更多的信息,局限在于训练集规模太小限制了网络深度。
2017年,Bianco等提出DeepBIQ[24],基于分类任务预先训练的卷积神经网络(CNN)迁移学习实现BIQA任务。通过对图像子区域预测分数累加和求平均来估计整体图像质量。微调采用随机初始化值代替预先训练CNN的最后一个全连接层作为新的CNN。迁移学习使得网络深度增加,但其性能受到原始任务影响。
2018年,Boss等提出无参考图像质量评价之深度图像质量方法DIQaM-NF(Deep Image QuAlity Measure for NR IQA)[43],在作者提供的参考中方法命名为deepIQA,一些引用也采用此命名。基于端对端训练,包含10个卷积层和5个池化层,以及2个全连接层。可能数据量无法支撑这深度的网络,实验结果并未超越IQA-CNN这样的浅层网络。
3.4 深度学习中的典型OF/OU模型
训练可靠的OA-BIQA模型需要大量的人工评分训练样本,但通过主观测试获得意见分数通常昂贵且耗时,训练数据极其有限。同时OA-BIQA模型通常具有弱泛化能力,在实践中的可用性受限。相比之下OF-BIQA不需要主观评分来进行训练,具有更好的综合能力的潜力。因此有必要开发不依赖主观意见分数来进行训练“自主意识”(Opinion Free,OF)的BIQA模型。第一个OF-BIQA模型是2012年由Mittal等提出的TMIQ模型[44]。TMIQ将概率潜在语义分析pLSA应用于从大量原始和失真图像中提取的质量感知视觉词,以揭示对视觉质量至关重要的潜在特征或主题,但效果不是很理想。之后Mittal等提出了另一个OF-BIQA模型NIQE[45],优于TMIQ,而且不需要失真图像训练。但在所有类型的失真中无法普遍适用,并且当失败时,很难调整模型来提高性能。这些OF-BIQA模型都不如当时先进的OA-BIQA模型如BRISQUE、CORNIA,故不再赘述。BLISS用于将OA-BIQA模型扩展到OF-BIQA模型,并实现与CORNIA、BRISQUE可比较的性能。
2014年,Ye等提出基于使用合成分数盲学习图像质量方法BLISS(Blind Learning of Image Quality using Synthetic Scores)[18]。BLIS从全参考(FR)IQA测量得出的综合分数训练BIQA模型。先进的FR方法与主观意见分数高度相关,可用作人眼意见分数的近似值,结合不同的FR方法以生成综合评分代替人工评分。因此BLISS基于FFIQA的准确性,选择的FRIQA方法直接影响训练结果。
2015年,Hou等提出从语言描述学习规则进行定性评价的BIQA模型DLIQA[23]。可以保留语言描述到数值分数的这种不可逆转换中失去的信息,学习后算法时间复杂度非常低;模型对小样本问题具有强鲁棒性。但定性标签无法直接同其他算法作比较,且同一等级的图像无法按质量排序,需要在输出层按某一规则转成质量分数。
2017年,Ma等提出dipIQ[19]方法。生成质量可识别图像对DIP解决训练数据不足的问题,再使用RankNet[21]从DIP中学习OF-BIQA模型。自动DIP生成引擎是选择3个FRIQA模型 MS-SSIM[2]、VIF[13]和GSMD[46],采用文献[8]中提出的非线性逻辑函数将3种模型的预测映射到LIVE库DMOS规模。
2017年,Liu等提出RankIQA[22]。生成有序的降质图像训练连体网络进行质量相对排名,再将经过训练的网络迁移到传统CNN上,使该CNN可从单幅图像中估计出绝对图像质量。作者尝试了从浅到深的3种网络,最深的VGG-16取得了最好的结果,在有足够训练数据前提下,若尝试更深的网络可能获得更好的效果。
2017年,Kim等提出一种基于卷积网络的盲图像评估器 BIECON(Blind Image Evaluator based on a Convolutional Neural Network)[47]。模仿FR-IQA方法,先生成局部质量再汇总回归得到主观评分。不同于IQA-CNN,局部质量训练的图像块质量分数由全参考方法获得。
2018年,Ma等提出端到端优化的多任务深度神经网络MEON(Multi-task End-to-End Optimized deep Neural Network)[14]。灵感来自 BIQI[31]和IQA-CNN++[25],MEON先训练一个失真类型识别子网络,再从预训练的早期层和第一个子网络的输出训练质量预测子网络。选择生广义分裂归一化GDN[48]作为激活函数。
2018年,Kim继续提出深度图像质量评估器DIQA(Deep Image Quality Assessor)[49]。训练过程包括回归到客观误差图和回归到主观评分两部分。另外,采用两个简单的手工特征捕获由于规范化和特征映射无法检测到的特定失真统计数据。
2018年,Gao提出通过多级深度表示的盲图像质量预测BLINDER[50]。从有37层的DNN模型VGGnet中提取多级表示,分别在每个层上计算一个特征表示,然后估计每个特征向量的质量得分,最后平均这些预测分数来估计整体质量。
BIECON、MEON、DIQA和IQA-CNN对比,BIECON、DIQA和IQA-CNN++虽然都是基于CNN,且采用局部描述符增加数据量,但是它们从设计到实现都不同。IQA-CNN++仅仅将图像分成图像块,没有更多的处理,其多任务方式也只是共享一些早期层,子任务间没有直接联系。BIECON和DIQA、MEON结构及思想反而更接近,都是将训练过程分为两步,第一步作为预训练跟后续训练有直接关系;同时第一步训练能够使用大规模训练集。不同在于MEON作为多任务模型,第一步训练结果即为子任务,BIECON和DIQA的第一步训练仅作为代理回归目标,属于单任务模型,比较有意义的在于它们提出了可视化方法分析CNN模型所学到的内容,可视化学习过程对理解和研究深度学习至关重要。DIQA不同于BIECON增加了手工特征,但这类特征在不满足应用情况下不仅无效果甚至会产生负面影响。基于CNN或DNN的BIQA模型虽然可直接使用训练神经网络的最新方法,并可通过添加更多隐藏层升级网络,但是都存在以下局限性:它们的模型实际上并不深;通常使用模型中最后一层的输出作为质量预测的特征表示。除了RankIQA尝试16层的网络,BLINDER采用了37层的网络,使用更深的模型,探索更多级的特征,是基于神经网络的BIQA模型提高性能最直接的方法。
4 实验对比
整体流程:首先统计排序算法在LIVE数据库常见失真测试结果,均按照80%的训练数据,20%的测试数据,再选择准确性和相关性高的算法测试泛化能力。先在整个LIVE数据库训练,再CSIQ和TID2013数据库上测试。若提供相应数据直接采用,未提供数据提供了开源模型的自行测试,未开源且数据不全的模型给出已有且有参考性数据,不参与排序。
首先,统计多篇算法在LIVE库上计算的PSRN和SSIM在常见失真项JP2K、JPEG、WN和BLUR的SROCC和LCC值作为全参考方法参考。基于假设:单个失真数据记录正确,每项保留小数点后三位,考虑到数据有限且中位数差异不大,取值最后取平均数。
采用如表1同样的方法依次统计PSRN方法的LCC中位数均值,SSIM方法的SROCC和LCC中位数均值。最后,得到SROCC值和LCC值作为全参考方法代表。
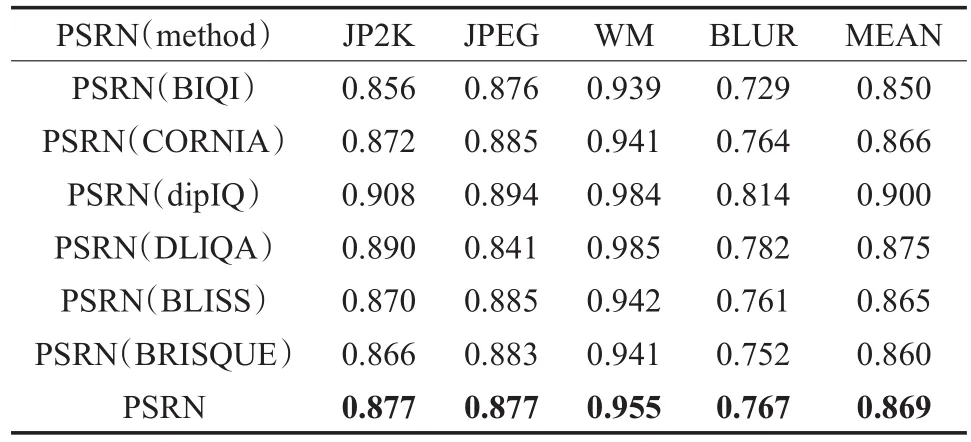
表1 LIVE库上PSRN方法SROCC中位数均值
表2列出了经过同样计算得出的各个算法综合SROCC和LCC值,前4种算法单项失真数据不全,仅提供原文数据参考。表3列出各算法最敏感失真类型及其测得的SROCC、LCC值和最不敏感的失真类型及其测得值(后为失真类型)。
以PSRN和SSIM方法作为参考,在LIVE数据库的测试排序可以看出选择的大部分典型方法优于PSRN,IQA-CNN、dipIQ、CORNIA等几种方法优于优于SSIM,因此在特征选择和方法思想上都值得进一步探讨,其中CORNIA实现在空域提取NSS特征,IQA-CNN可视为CORNIA的卷机网络实现;dipIQ训练数据标签源于全参考方法,且拥有大量训练数据。
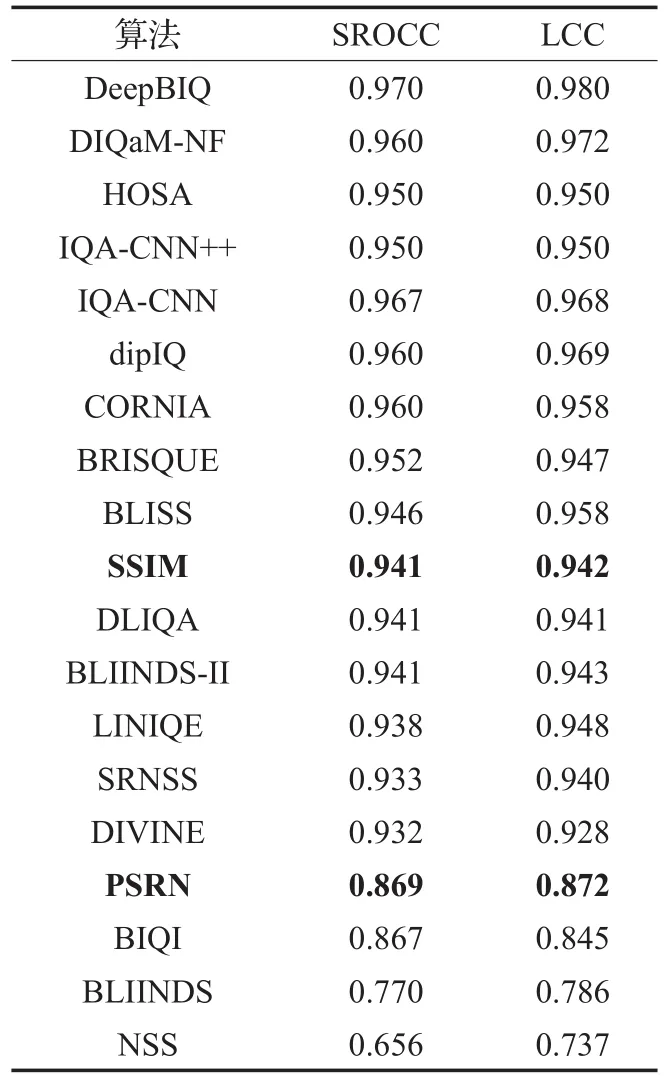
表2 典型模型在LIVE库排名
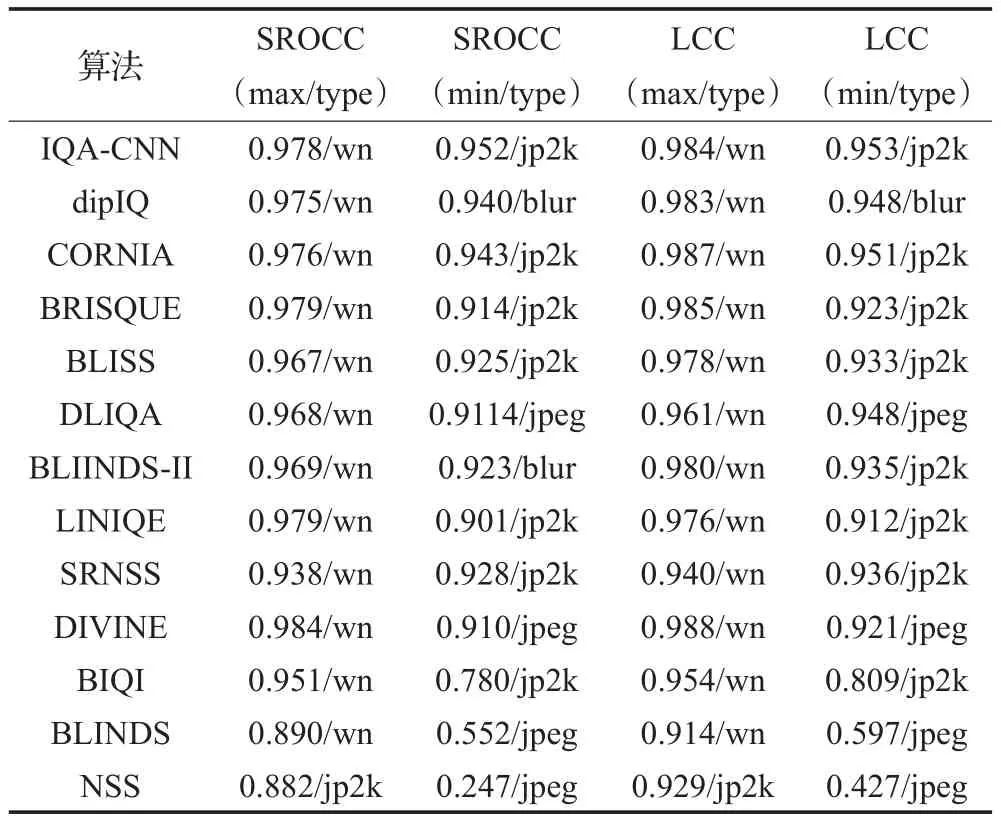
表3 LIVE基准库SROCC和LCC最值
统计显示除NSS专门为JP2K失真建模外,其余算法对白噪声失真WN预测表现高于其他项,在JP2K失真上表现很差的情况下也接近或高于NSS算法。除了第一次尝试对单项失真利用NSS特征建模的思想外,NSS算法不具有竞争力。BIQI、BLINDS方法最高/低的SROCC差异巨大,BIQI根据选择的失真类型预设对应的质量评价算法,jp2k失真特征和评价方法的选择均会影响最终结果。BLINDS也因最高的SROCC值低于0.9不再继续讨论。基于深度学习的方法如IQA-CNN、dipIQ等取得更高的分值。SROCC值与LCC值具有强一致性,高SROCC值对应高LCC值。接下来进行泛化能力测试。
对比表3可以看到算法对不同数据库敏感,在TID2013库中,算法准确率有不同程度下降且SROCC与LCC最值对应的失真类型不再高度一致(见表4)。对WN失真敏感度降低,对JP2K预测能力提高。
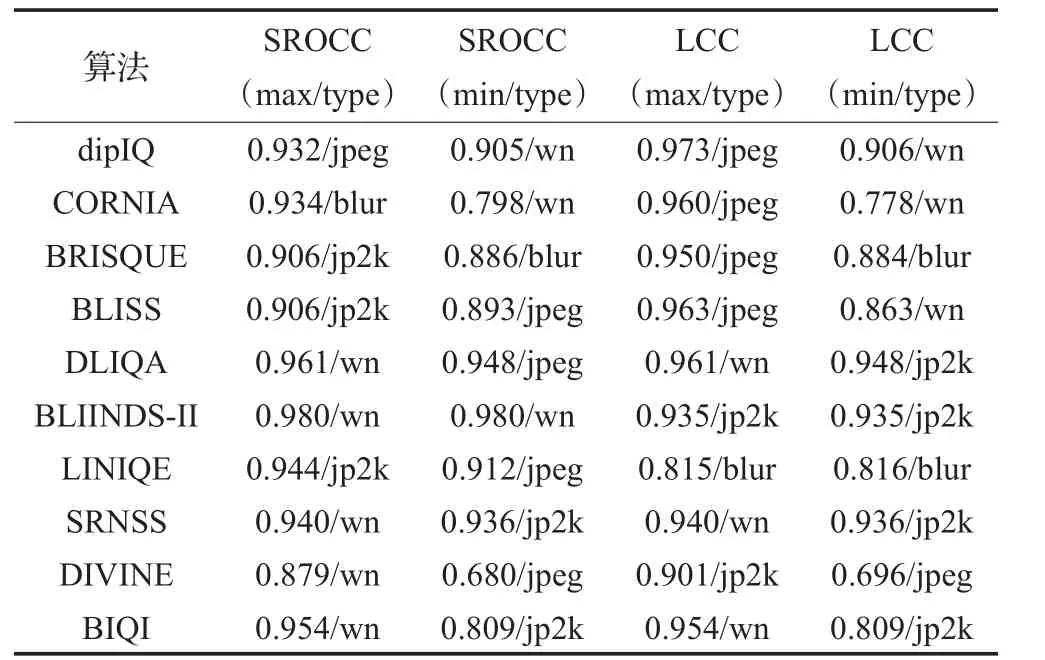
表4 TID2013基准库SROCC和LCC最值
在CSIQ数据库,算法实现比在TID2013上贴近预训练效果(见表5)。但原因可能在于CSIQ数据量小,与LIVE库差不多,相对而言TID2013库数据量大,更好的方法是从更多不同库选择同失真类型、同规模数据测试,并在多个库训练交叉检验,缺点在于耗时缓慢,难以一一实现。在这3个数据库上仅仅对比了常见的4种失真,而现实生活中则存在更多类型失真。排名结果如表6、表7。
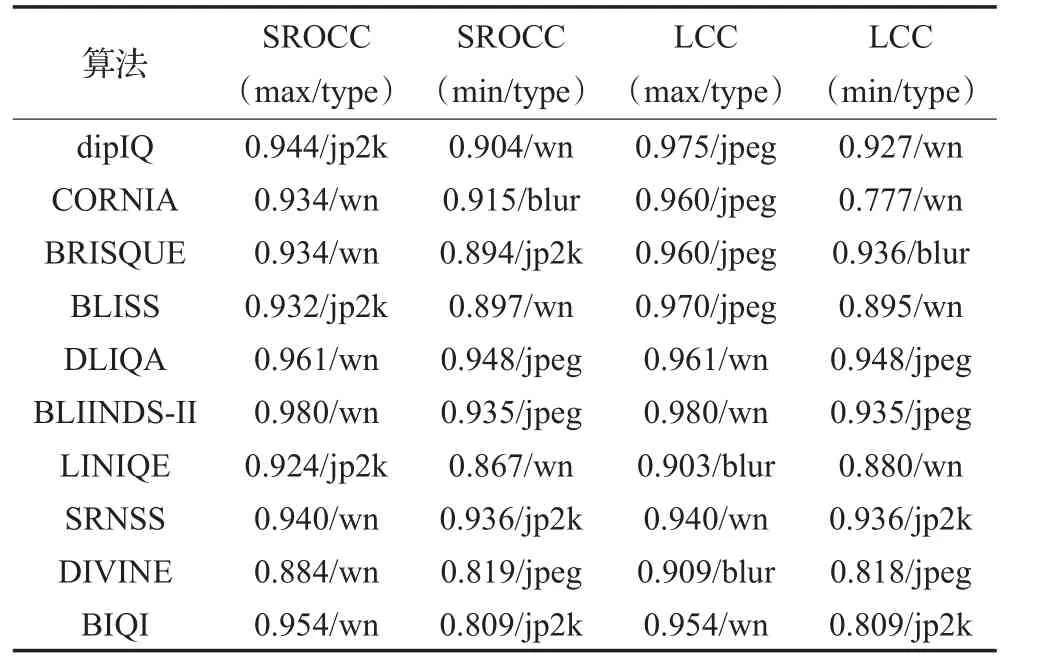
表5 CSIQ基准库SROCC和LCC最值
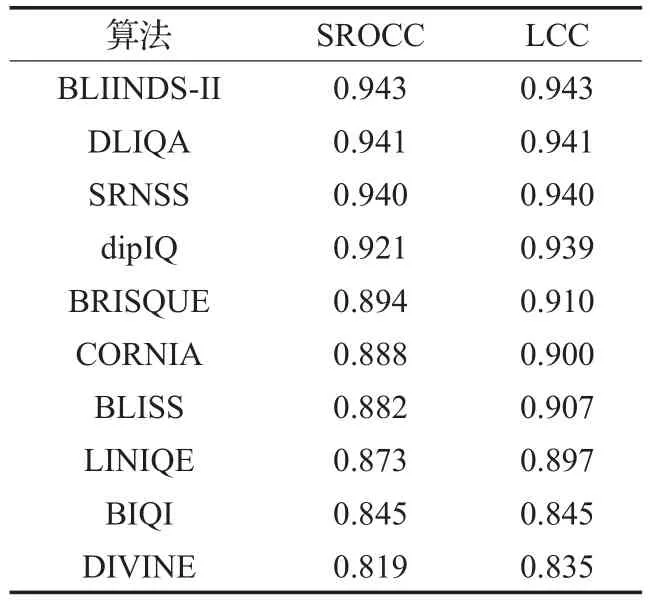
表6 TID2013库上算法性能排名
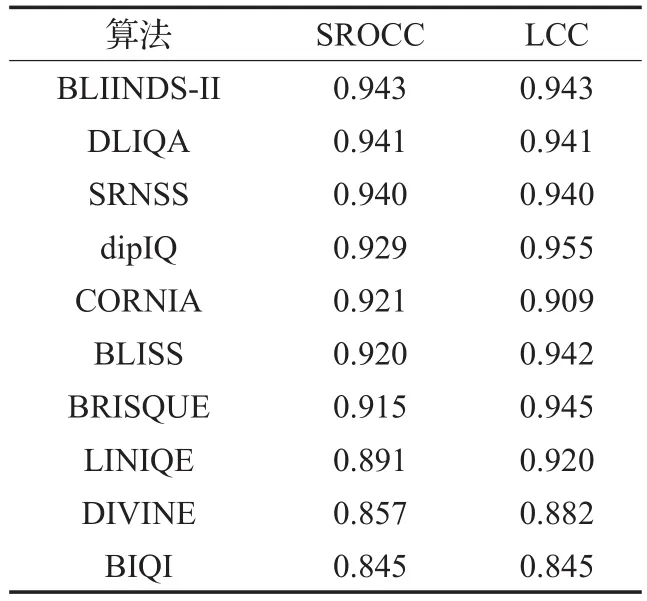
表7 CSIQ库上算法性能排名
除算法如IQA-CNN、HOSA等无法重新训练也没有参考数据对比外,在TID2013和CSIQ数据库上算法的综合排名基本一致。
如表8,TID即TID2013数据库。选择对应算法表现最优的失真SROCC比上表现最差的SROCC值MAX-srocc/MIN-srocc说明面对不同失真类型的稳定性,其值越接近1说明算法对不同失真类型的评价表现接近。表8按算法鲁棒性排序,BLIINDS-II、DLIQA、SRNSS其泛化能力都很强,处在前三,准确性也不错,dipIQ泛化能力不如这3个算法但也远好于后面的算法,同时dipIQ对于不同失真表现稳定。其中BLIINDS-II在DCT域中提取特征,SRNSS在小波域中提取特征。频域中可捕获到空域中无法察觉的信息,但同时也丢失了空域位置信息,稀疏编码使得鲁棒性强,但有限的特征使准确率难以提高;DLIQA提取语义信息与人眼相关性极大,学习后算法时间复杂度低,不过定性的质量评价到定量评价的映射直接决定最终结果,对算法影响极大;而dipIQ训练数据近百万。CORNIA成功的从空域中提出特征并对后续研究有深远影响,在图像处理中因像素周围的像素点关系密切有着天然优势。BLISS结合不同的FR方法生成可以代替MOS/DMOS值的分数,大大增加训练样本,也给其他的OF-BIQA模型提供了一种可行的方案。BRISQUE方法在确保准确度前提下具有非常低的复杂度,但相对于BIQA方法近几年获得的准确率,BRISQUE方法还有更大的优化空间。LINIQE、DIVINE、BIQI方法准确度次之,同时对于不同失真表现效果差异较大,算法不够稳定。BIQI方法设计理念比较简单,对于特定应用场景简单有效,在对失真类型的准确评价和不同失真的评价算法的选取等方面优化或许会取得更好的成绩。
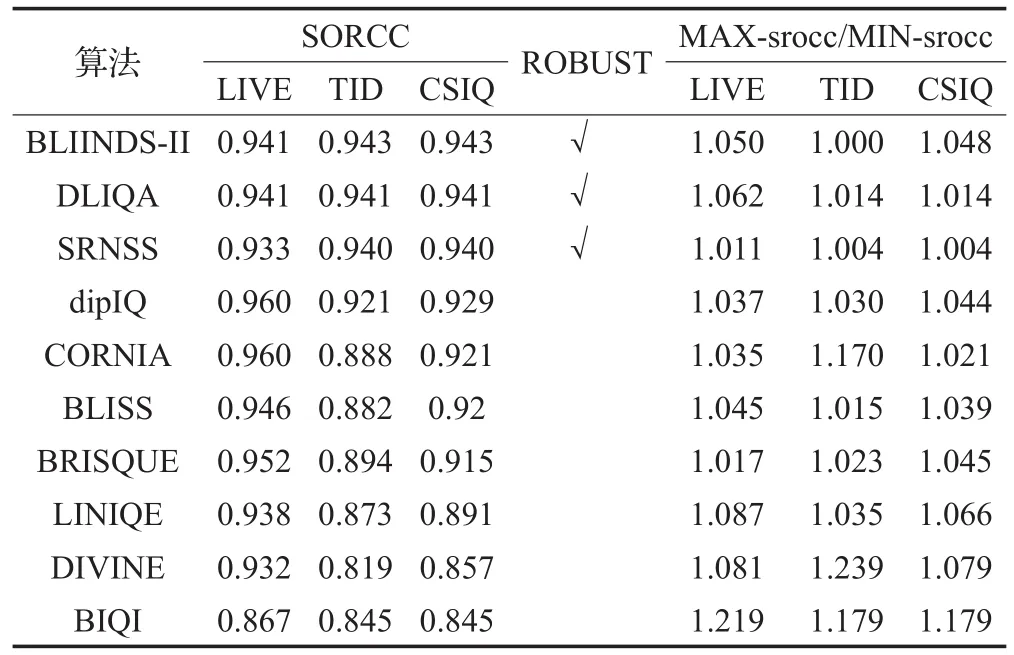
表8 算法性能特点总结
不足的是实验仅仅单向测试了算法的泛化能力,后续考虑在CSIQ、TID2013等数据库训练,在LIVE等数据测试,更多的交叉检验能更好地说明了算法鲁棒性。同时,可实现IQA-CNN、BIECON等方法参与测试,新的方法不断涌现,基于不同的设计优化理念、更深的网络层数都让无参考图像质量评价不断地取得新进展,让新方法也参与到众多的比较中有利于对比优化。
5 结束语
通过研究典型算法不难发现:第一,同一个研究团队持续跟进算法不断更新性能,如图像与视频工作实验室Laboratory for Image&Video Engineering先后提出了BRISQUE、DIVINE、BLIINDS-II等方法;第二,积极利用各个领域新技术如深度学习方法大胆尝试;第三,深度学习方法取得了更好的成果,但并非所有的深度学习方法都绝对优于其他机器学习方法。前两点保证了关于盲图像质量评价问题的研究从未间断,且发展过程有迹可循;第三点说明整理并分析不同方法优缺点,互相借鉴、优化创新便可能取得新进展。分析现有的方法不同特点,可以推断盲图像质量评估发展大约分为以下几个方向。
(1)复合失真图像质量评价:现有的BIQA方法通常只能处理仅包括一种失真类型的图像,但实际失真图像通常包括多项失真,如同时包含JPEG压缩、模糊和噪声等。
(2)增强型质量改变评价:当前方法测量的质量变化仅包含单项失真产生的降质,不考虑如对比度、亮度或其他图像增强引起的质量改变。
(3)扩充数据规模研究:想通过更深层的网络提升准确度就需要大规模的训练集。增加可用数据是持续研究的热点问题。一是逐步扩大现有公开库,二是创新优化OF-BIQA方法。
(4)HVS特征研究:图像质量评价旨在拟合模仿人眼功能,对视觉特征研究和准确建模是长远研究内容。
(5)理论结合应用需求:不仅关注算法的准确度、一致性、鲁棒性,还有实时性,不同需求针对性,将理论成功转化应用;利用应用效果反向优化算法,研究并完善理论体系,构建成熟的评价框架。
(6)深度学习方法研究:深度学习复兴至今,前馈网络的核心思想并没有发生重大变化,如上述方法依然使用相同的反向传播和梯度下降方法。但基于算法上的改变如使用交叉熵损失函数代替均方误差损失函数,使用ReLU替代Sigmod则显著改变了神经网络的性能。在对HVS特征研究有限的情况下,对工具进行改进,可能会对无参考图像质量评价提出更稳定、更强大的算法。
猜你喜欢
小学生学习指导(高年级)(2021年4期)2021-04-29 02:17:14
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
趣味(数学)(2019年12期)2019-04-13 00:29:08
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
小学生导刊(2017年16期)2017-06-15 20:29:38
财经(2017年2期)2017-03-10 14:35:35
财经(2016年15期)2016-06-03 07:38:02
财经(2016年3期)2016-03-07 07:44:46
