
一种基于字符组合的复杂环境车牌检测方法
2018-10-15 05:58孙庭强
计算机技术与发展 2018年10期
孙庭强,郑 彦
(南京邮电大学 计算机学院,江苏 南京 210003)
0 引 言
车牌识别技术是智能交通系统的重要组成部分,其在超速检测、高速公路收费管理、车流量检测、小区车辆管理、电子警察等方面应用广泛[1]。现有的车牌检测方法大致可以分为两个类别:第一类方法基于图像分割,其一般检测过程分为分割图像、抽取特征以及目标匹配三个部分;另一类方法则基于滑动窗口,其检测过程是用特定尺寸的窗口以一定步长在待测图像中滑动并进行目标匹配。其中,基于图像分割的车牌检测方法是一种自底向上的方法,分割与检测依赖于图像的底层特征,包括颜色、边缘、纹理、形状、几何等等。检测对分割的依赖性以及特征选取的盲目性是图像检测中的经典难题,特别是在复杂环境下,大量不确定的噪声将严重影响分割与检测的准确性。关于如何增加车牌分割的准确性以及字符的识别率,国内外学者进行了大量研究。而基于滑动窗口的车牌检测方法则是一种自上向下的方法,依赖于各种先验知识,其中较为经典的算法包括模板匹配算法[2]以及形态学检测算法[3]等。该算法更加适合特定环境下以及平稳环境下的车牌检测,而复杂环境下,这类算法所依赖的先验知识适应性不强,容易导致漏检和误检。
在实际应用中,由于场景和需求的变化产生了两种基于图像分割的车牌检测与识别方法:基于车牌定位的方法[4]以及基于字符组合的方法[5]。其中,基于车牌定位的检测与识别方法需要经过图像分割、车牌定位、字符分割以及字符识别四个步骤,而基于字符组合的检测与识别方法只需要经过图像分割、字符定位、字符识别三个步骤,省略了分割定位车牌的过程。受复杂背景、光照强度等因素影响,基于车牌定位的检测与识别方法车牌定位困难,定位的准确性决定了车牌识别率,定位失败必然导致识别失败[6]。基于字符组合的检测与识别方法直接定位字符,规避了车牌定位困难的问题,因此具有较好的鲁棒性。然而该方法同时也存在着字符分割的可靠性不高,对于字符颜色变化和形状变化的鲁棒性差等问题。
在基于字符组合的车牌检测与识别方法的基础上,文中综合考虑复杂环境下的光照、天气、角度、距离、背景等变化因素,提出了一种基于多粒度区域生长的字符分割算法和一种基于多特征聚类的字符组合检测算法。在基于区域生长的分割算法中,根据灰度值对目标图像采用多个粒度进行生长分割,借鉴MSER稳定极致的思想,将区域生长分割与聚类分析进行交互,通过不断学习最终得到一个稳定的字符组合及其分割粒度区间,从而有效应对光照强度变化以及天气等原因导致的分割不准确等问题。在基于多特征聚类的字符组合检测方法中,相似性度量的计算包含颜色、几何以及位置关系这三种特征,无监督学习的聚类算法可以应对复杂背景下检测多个车牌的场景,而字符位置关系特征的引入可有效适应对拍摄角度和距离变化的情况,同时采用特征子集以应对部分字符遮挡、字符颜色变化等问题,增强鲁棒性。
1 多粒度区域生长
图像分割是提取图像中感兴趣目标的过程,常用的图像分割方法包括基于阈值的分割方法、基于区域的分割方法、基于边缘的分割方法、基于直方图的分割方法,以及基于特定理论的分割方法,如基于聚类分析的分割方法[7]、基于SVM的分割方法[8]、基于模糊熵的分割方法[9]、基于小波分析的分割方法[10]、MSER方法[11]等等。复杂环境下,车牌图像分割受环境因素和场景因素影响较大。固定的单一阈值或多阈值分割,单一粒度的区域或边缘分割在光照强度和天气变化较大的情况下都无法保证分割的准确性,因为在较强和较低光照环境下,区域间界限相对模糊,难以确定分割阈值。
1.1 MSER方法
MSER(最稳定极值区域)方法使用不同的灰度阈值对图像进行二值化,得到一个最稳定的区域,对于图像灰度的仿射变化具有不变性,且区域的支持集相对灰度变化稳定,可以检测不同精细程度的图像区域。然而,对复杂图像进行分割时,MSER方法却容易导致过分割,从而导致目标提取失败。
1.2 稳定字符组合
借鉴MSER方法求稳定极值区域的思想,同时为了防止过分割,文中提出了一种基于多粒度区域生长的车牌字符分割方法,从求解单个字符区域的稳定性转为求解目标字符组合的稳定性。区域生长图像分割方法是直接根据底层像素的相似性与连通性进行聚类的方法[12],生长的粒度即像素间的相似性度量,多粒度的区域生长方法,以多个不同的粒度分别进行生长分割,得到同一幅图像在不同粒度下的分割区域。对于目标区域集合,存在一个粒度区间,在该区间内目标区域稳定满足字符判别条件,这一粒度区间即为该区域集合的稳定分割粒度区间。区间最小值为最细分割粒度,区间最大值为最粗分割粒度。
1.3 多粒度区域生长过程
对于原始输入的车牌图像P,初始以较小的生长粒度g0进行生长分割,输出初次分割后的区域集合E(A0,A1,…,An),将区域集合E作为聚类算法的输入,输出候选区域子集{D1(A0,A1),D2(A2,A3),…,Dm(Ai,Aj,…,An)}。若{D1,D2,…,Dm}中不存在目标子集,则增大粒度继续分割;若{D1,D2,…,Dm}中存在目标子集Dk(目标子集可以有多个),即Dk中包含疑似车牌字符,则增大生长粒度g1=g0+△g重复分割,得到目标车牌字符组合R及其稳定分割粒度区间{g1,g2,…,gk}。
2 字符组合检测
图像分割得到了大量候选区域,在对候选区域进行字符组合检测时,常用的方法有马尔可夫链[13]和条件随机场[14]等,但其算法时间复杂度较高。因此,文中采用AGNES聚类算法以及字符位置关系判别进行字符组合检测,通过聚类分析算法和位置关系判别对候选区进行分析、选择合并策略、剔除假车牌,实现准确、快速的多车牌区域分割,在一定限度内自适应车牌的类型、大小、数量和方向[15]。同时为了增强字符组合检测对于字符形变的鲁棒性,采用特征子集优化聚类效果。为了降低算法的复杂度,加快检测速率,采用主成分分析方法,在聚类分析时选取最主要的灰度值、长度以及宽度三个特征进行相似性度量,为了弥补特征维数不足容易导致车牌字符误检的情况,对聚类结果进行基于字符位置关系的判别。
2.1 AGNES聚类
聚类是将数据分类到不同的类或者簇的一个过程,最大化类内对象的相似性以及类间对象的相异性。聚类大致上可分为划分聚类、层次聚类、模糊聚类以及基于密度的聚类,常见的聚类算法包括K-MEANS算法[16]、K-MEDOIDS算法[17]、AGNES算法[18]、DIANA算法、EM算法、OPTICS算法等。
AGNES(agglomerative nesting)是凝聚的层次聚类算法,一个簇中的对象和另一个簇中的对象之间的距离是所有属于不同簇的对象间欧氏距离中最小的。这是一种单连接方法,其每个簇可以被簇中的所有对象代表,两个簇之间的相似度由这两个簇中距离最近的数据点对的相似度来确定。该算法实现简单,适合小规模的数据运算,与K-MEANS、K-MEDOIDS相比,具有对噪声不敏感且不需要预先选择聚类质心点等优点。
AGNES算法描述如下:
输入:包含n个对象的数据集合,终止条件簇的数目k
输出:k个簇
(1)将每个对象当成一个初始簇
(2)Repeat
(3)根据两个簇中最近的对象找到最近的两个簇
(4)合并两个簇,生成新的簇的集合
(5)Until簇的数目等于k
其中,两个簇相似度的计算公式为:
D1={A1,A2},D2={A3,A4};
Distance(D1,D2)=min{Distance(A1,A3),
Distance(A1,A4),Distance(A2,A3),Distance(A2,A4)}
2.2 特征子集
相似性的度量方法是聚类分析的关键,以不同特征进行聚类得到的结果往往不同。在实际监控场景中,存在部分车牌字符被遮挡和车牌字符具有多种颜色导致漏检等情况,从特征的角度看,即某个特征的突变影响了聚类分析的结果。在聚类分析过程中,为了削弱某个特征的影响力,通常采用降低特征权重的方式实现。特征子集是改变特征权重的特殊形式,将某个特征的权值设置为0,即完全忽略该特征。
文中在对图像分割区域用AGNES算法进行聚类分析的过程中,采用原特征集、特征子集分别进行区域间相似性计算,以适应复杂环境下字符产生颜色、长度、宽度等形变的情况。原特征集F(gValue,xLength,yLength),其中gValue为区域平均灰度值,xLength为区域水平方向长度,yLength为区域垂直方向长度。F-1(gValue,xLength),F-2(gValue,yLength),F-3(xLength,yLength)分别为缺省区域垂直方向长度、区域水平方向长度、区域平均灰度值后的特征子集。
采用原特征集与特征子集分别进行聚类,两个对象的相似度计算公式分别为:
F:Distance(A1,A2)=sqrt(Wg*(A1.gValue-A2.gValue)2+Wx*(A1.xLength-A2.xLength)2+Wy*(A1.yLength-A2.yLength)2)
F-1:Distance(A1,A2)=sqrt(Wg*(A1.gValue-
A2.gValue)2+Wx*(A1.xLength-A2.xLength)2)
F-2:Distance(A1,A2)=sqrt(Wg*(A1.gValue-
A2.gValue)2+Wy*(A1.yLength-A2.yLength)2)
F-3:Distance(A1,A2)=sqrt(Wx*(A1.xLength-A2.xLength)2+Wy*(A1.yLength-A2.yLength)2)
初始以原特征集F(gValue,xLength,yLength)对分割区域E(A0,A1,…,An)进行聚类分析,经过车牌字符判别与多粒度的重复分割过程,得到目标区域集合及其稳定粒度区间。若目标区域集合的数量为0,即不存在任何区域集合符合车牌字符判别条件,则以特征子集F-1、F-2、F-3分别对分割区域进行再次聚类与判别。
2.3 位置关系判别
在复杂场景下,监控拍摄的角度与距离具有多样性,文中采用基于字符区域间位置关系的字符判别算法,在任意角度和距离上,各字符区域始终近似保持在同一条直线上。
算法描述如下:
输入:具有n个对象的聚类簇,目标对象个数k
输出:k个目标对象
Repeat
选取两个对象为一个候选集合
依次判断剩余对象是否与集合中对象的中心点在同一直线上,是则加入候选集合,否则丢弃
Until候选集合中对象个数为k
其中,判断三个点是否在同一直线的公式为:
A(x1,y1),B(x2,y2),C(x3,y3);
|cosA|=|(x1-x3)2+(y1-y3)2+(x1-x2)2+(y1-y2)2-(x2-x3)2+(y2-y3)2|/2*sqrt((x1-x3)2+(y1-y3)2)*sqrt((x1-x2)2+(y1-y2)2)≥t,t为夹角余弦阈值。
3 实验结果分析
为了验证文中多粒度区域生长算法的有效性,首先从图像库中挑选包含较低光照、较强光照、正常光照下已标记的训练图像进行分割检测,输出结果包括稳定分割粒度区间和对应粒度下的分割区域集合。实验结果表明,在不同粒度下进行分割,得到的字符区域细节有所改变。
如图1~3所示,图1为车牌字符经过多粒度生长分割以及聚类分析后得到的稳定目标字符组合,图2的分割粒度为稳定粒度区间中的较小值,图3的分割粒度为稳定粒度区间中的较大值,两个粒度下得到的字符形状具有较大差别。

图1 原始车牌字符图像
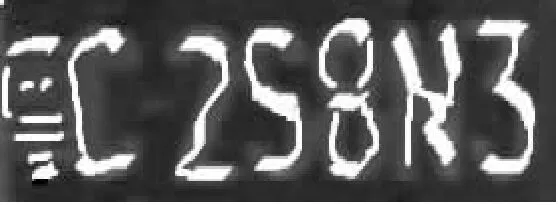
图2 细粒度分割结果

图3 粗粒度分割结果
将不同粒度下的分割字符区域输入到基于模板匹配的识别算法中,位于稳定区间低位和高位粒度的识别率较低,中间粒度识别率较高。融合三个粒度下的识别结果,识别率比单一粒度有所提高,如表1所示。
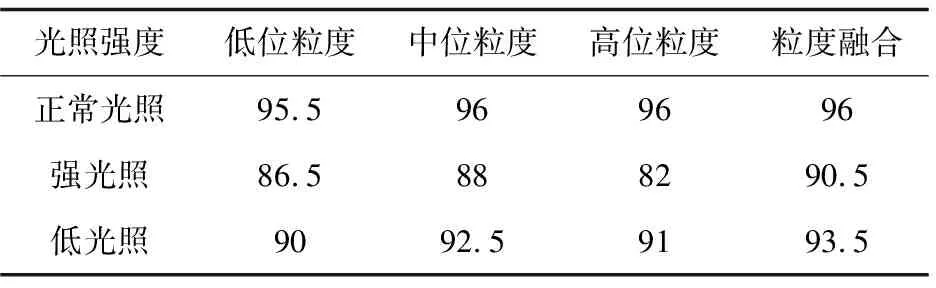
表1 稳定粒度区间三种粒度下的识别率比较 %
为了验证文中多特征聚类算法的有效性,从图像库中挑选车牌字符具有两种颜色的训练图像进行实验。对于图4中左边的车牌,初始以完整特征集合F(gValue,xLength,yLength)进行聚类,提取目标字符失败。再以特征子集F-1(gValue,xLength),F-2(gValue,yLength),F-3(xLength,yLength)分别重新聚类,子集F-3成功提取目标字符。

图4 原特征集合与特征子集聚类结果对比
最后,通过实验将基于梯度算子的边缘检测算法以及MSER方法与文中算法进行比较,采用三种算法分别进行车牌字符分割与检测,分析车牌字符的检测准确率以及检测速率,以及最终车牌字符的识别率。从表2可以看出,从检测准确率以及识别率上看,文中算法比边缘检测算法更有优势,从检测速率上看,文中算法的平均检测时间远小于MSER方法。
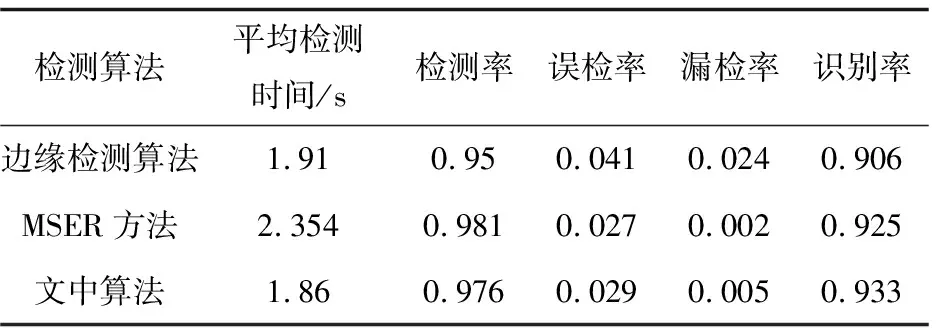
表2 三种字符检测算法对比
4 结束语
在基于字符定位的车牌检测与识别方法的基础上,结合区域生长、MSER方法、决策融合和聚类分析,提出了一种基于多粒度区域生长和多特征聚类的复杂环境车牌字符分割与检测方法。用稳定分割粒度区间代替单一分割粒度,融合多个粒度下的识别结果,提高了字符识别率。聚类分析中以多个特征子集代替单一特征集合进行字符组合检测,增强了算法鲁棒性,有效降低了漏检率。
猜你喜欢
粉末冶金技术(2021年3期)2021-07-28
动漫界·幼教365(中班)(2021年4期)2021-05-23
小型微型计算机系统(2020年10期)2020-10-21
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
电子制作(2019年12期)2019-07-16
计算机研究与发展(2018年6期)2018-06-08
新作文·高中版(2017年6期)2017-07-06
