
基于Matlab2014编写多样性指数算法研究
2018-10-10 06:33:30卢志宏
农业与技术 2018年17期
卢志宏
(铜仁学院,贵州 铜仁 554300)
生物多样性和人类社会经济的可持续发展存在着千丝万缕的关系,生态学对物种多样性的研究主要是通过生物的种类、个体数量来揭示生物种类数量和人类之间的关系;随着人类活动的增加,对环境的破坏越来越强烈,人们对生物多样性关注越来越普遍。物种多样性指数是研究生物多样性的方法之一, 其计算方法多种多样,定义也存差异,本文根据张金屯关于多样性指数的比较研究[1],在matlab2014a平台上编写了11种多样性指数计算方法,旨在为繁复的计算提供快速准确的方法。
1 样方数据准备
植物调查数据一般在野外记录植物种类名称、数量、株高、盖度、地上生物量(鲜重、干重2项),还有一些调查会采集枯落物的重量,以及记录采集样方时的时间、地点、天气状况等信息。本文的原始记录如图1,外业完成后原样输入到excel表格中。
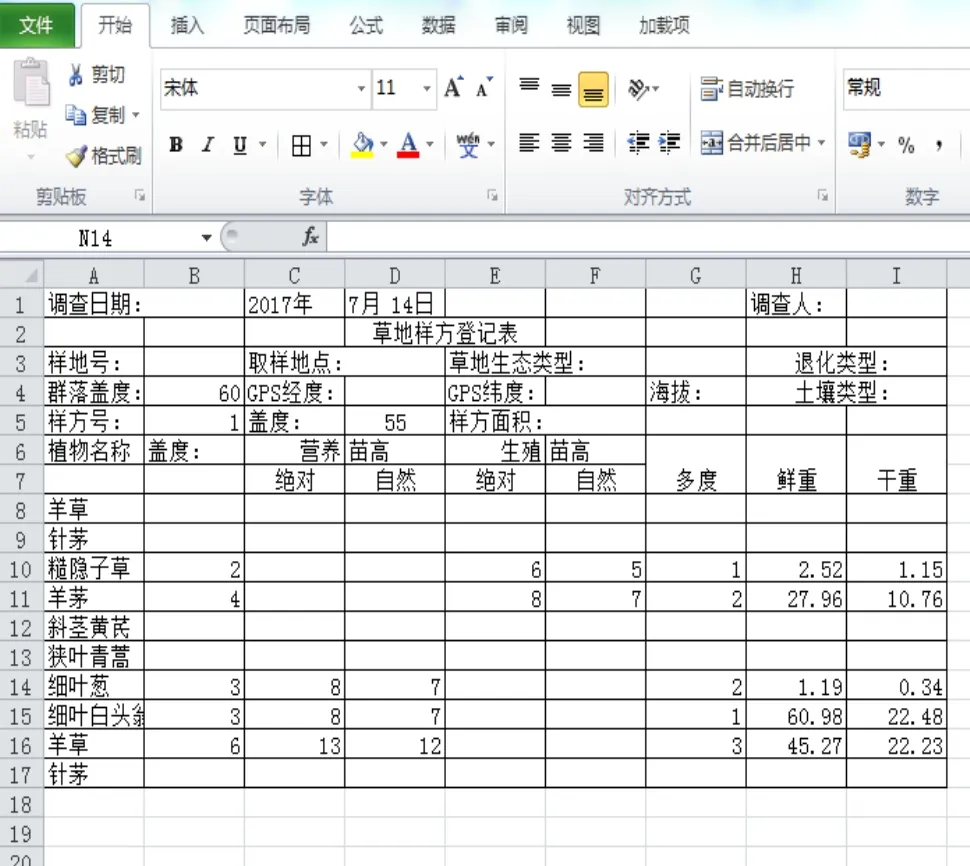
图 1 样方记录示意图
2 数据样方的整理
野外样方数据采集存在随机性,每个样方出现的植物种类不一样,而设计记录表格的时候,为了提高工作效率,一般在预实验的基础上将出现频率较高的植物名称输入表格,作为模版印出来;而在野外实验的时候就会出现表格中没有的植物,或表格中的植物没有出现的现象,记录的时候就补上或跳过;这样最终的记录和模版存在一些差异,在数据录入的时候为了提高效率,同时为了便于检查录入的正确率,一般不会打乱excel模版中的顺序。大量样方数据表格就难以一致,在计算多样性指数的时候,就要求剔除无效数据,这个过程一般是人为操作,费时又低效,本文采用了程序语言来实现,提高了效率。
2.1 整理的思路
从图1可知,表格的横行由A到I,是9列内容,由文本和数字组成,按照matlab语言的规定,用矩阵分别读取文本和数字,同时删除B到I单元格空白的部分及所对应行的文字,即实现了样方数据的整理。
2.2 数字和文本的读取
实现语言如下:
[...,...,...] = xlsread([...,’...’],’...’,[‘.’.,.,’.’,.])
中括号中逗号隔开的3部分内容分别表示xlsread读取f i lename中的数据,并返回数值数据到double型数组、非数值的文本到字符串单元数组和未处理的单元数据到字符串单元数组,即表示分别读取了图1 中文字和数字部分。
2.3 空白数据的删除
实现语言如下:
if ...==0 && ...==0 && ...==0 && ...==0 ...=...;...=[...,...]; end
if...end表示按照一定的条件进行选择,可以设置一定的并列条件,删除图1中数字部分空缺的行,即实现了有效数据的整理。
2.4 整理后数据的保存
通过exlwrite命令将整理好的数据保存在新建excel文件中,用于后续的多样性指数计算。
2.5 批量数据的读取
在实现了数据自动整理的基础上,需要考虑批量读取数据,虽然这一步十分简单,但必不可少,否则无法实现不同小区、梯度等处理间物种多样性的分别计算,也将会影响到后续的统计学分析。
在植物多样性调查中,一般设置若干个小区或梯度,如放牧小区、载畜率梯度、海拔梯度等,每个小区或梯度设置3~5个重复样地,每个重复样地内调查3~5个样方。每个样方记录在一张表格里,便于以后的数据整理。将整理后的所有数据按照相等行数记录在同一个excel表格中,matlab将按照一定的规则读取数据。读取数据的规律如表1,本文中每个样方占用20行。

表 1 不同梯度、重复和样方所在的行数
通过统计梯度、小区和样方所对应的数,可以发现存在如下的数列关系:
每个样方的第一行:
R1=20×G×P×(R-1)+20×G×(P-1)+20×(R-1)+1;
每个样方的最后一行:
R20=20×G×P×(R-1)+20×G×(P-1)+20×(R-1)+20;
找到样方起始行数后,通过xlsread命令即可实现批量读取所有的样方数据。
3 多样性指数的计算
3.1 多样性指数的计算公式
Shannon-Wiener 信息指数(1949):

3.2 多样性指数的实现
分别统计每个样方中出现的物种数、每个物种出现的数量,面积默认为1m2,并统计3个样方内出现物种数、每个物种个体数量。然后根据多样性公式进行编辑。
3.3 matlab完整的程序语言
完整程序如图2,运行后可获得结果,极大提高了工作效率。

图 2 多样性指数计算程序
3.4 多样性指数计算结果
由表2可知,3个梯度,每个梯度3个重复,共计9个小区11种 多样性指数输出到表中,提高了计算效率。
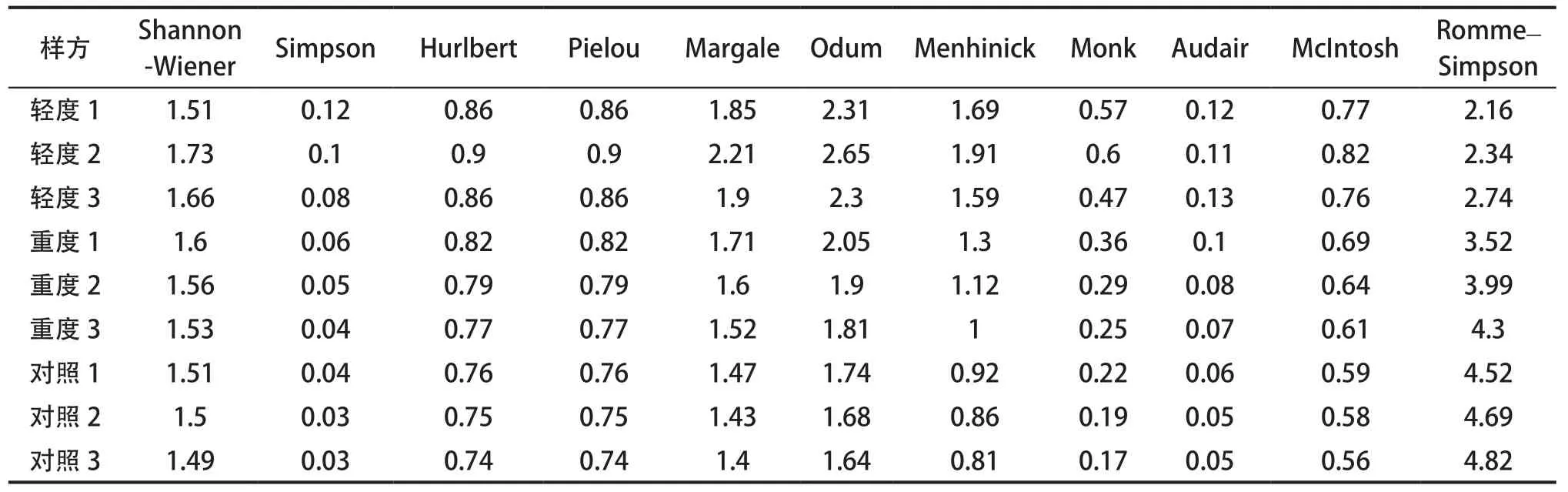
表 2 多样性计算结果
4 结论
通过该程序可以极大地降低多样性指数的计算时间,提高了准确性;同时在本程序的基础上,可以很方便地增加其他多样性指数计算公式,满足不同研究工作的需要。
猜你喜欢
林业勘查设计(2022年1期)2022-02-15 05:35:12
现代临床医学(2022年1期)2022-02-12 02:04:26
数学物理学报(2021年6期)2021-12-21 06:24:38
乡村科技(2021年17期)2021-10-20 08:50:56
安顺学院学报(2021年4期)2021-09-16 08:11:08
应用数学(2020年2期)2020-06-24 06:02:50
林业调查规划(2020年3期)2020-06-03 07:02:36
文化创新比较研究(2020年14期)2020-01-02 19:25:56
文化创新比较研究(2020年10期)2020-01-02 02:10:07
文化创新比较研究(2020年13期)2020-01-01 06:17:02
