
个性化学习资源推荐算法研究
2018-09-29 02:42:22卫文婕付宇博
中国教育信息化 2018年18期
卫文婕,付宇博
(华中师范大学 国家数字化学习工程技术研究中心,湖北 武汉430079)
一、引言
近年来,基于互联网的在线学习平台越来越普及,依据中国互联网络信息中心颁布的报告,2017年在线学习用户的规模已达1.44个亿。随之而来的问题是,大多数在线教育平台为不同学习者提供的往往是相同的学习界面和学习资源,没有充分考虑到个体间的差异提供针对性的学习资源。另一方面,学习者面对海量的数据信息,也很难快速有效地找到满足自己需要的学习资源,甚至会出现认知过负、迷航等问题[1]。所以,个性化学习资源推荐系统日益受到教育领域专家的关注,并逐渐成为了教育技术领域的研究热点。个性化学习资源推荐系统就是在传统网络教育平台的基础上,加入个性化的思想理念,使得学习者在学习过程中可以拥有更大的针对性以及能动性,并且能够根据其背景知识水平、学习手段和风格、兴趣爱好以及学习需求,结合学习者当前的认知结构以及学习能力,有针对性地给学习者提供满足其偏好和需求的个性化学习资源,以此来激发他们的学习热情,提高其学习积极性,让学习者能够自主高效地学习,从而实现最好的学习效果[2]。
个性化学习资源推荐系统就是在传统的在线教育平台的基础之上,加入了个性化的思想理念,使得学习者在学习的过程中可以拥有更大的针对性与能动性,并且能够根据学习者的个性特征构建学习者模型,从而有针对性地向学习者推荐学习资源[2]。个性化学习资源推荐系统的建立需要有个性化学习资源推荐技术(算法)的支持,在现有的研究中,最常用的个性化学习资源推荐技术(算法)主要包括基于内容(Content-based,简称CB)的推荐、基于协同过滤(Collaborative Filtering,简称CF)的推荐以及混合推荐(Hybrid Recommendation,简称 HR)三种类型。
推荐技术的核心是算法,算法的使用能够让学习者快速高效地找到满足自己需求及偏好的学习资源,提高学习效率。在个性化学习推荐系统中,每一种推荐技术(算法)都有其优缺点,单独的一种技术很难实现最好的推荐效果,因此,在实际的应用当中,研究者通常会使用两种或多种推荐技术混合的方式来实现更好的推荐效果[3],即混合推荐。个性化学习资源推荐技术的核心是算法,由于混合推荐大多是建立在基于内容(CB)的推荐和基于协同过滤(CF)推荐的算法之上的混合策略,其基本的思想还是源于前两者,因此,本文将重点介绍CB推荐和CF推荐及其常用算法,并就算法的优缺点进行比较分析和总结,而对于混合推荐只做简要论述。
二、基于内容的推荐
基于内容的推荐(CB)是最早被应用的推荐方法,它是通过计算与学习者喜好程度较高的资源或项目(item)的相似度,来为其推荐与之喜好相同或相似的item[4]。由于CB推荐可以不依靠巨大的用户群体或者是评分记录来产生推荐列表,也即只有一个用户(学习者)也能够进行推荐,因此实时性较好[5]。基于内容(CB)的推荐流程一般可以分成三步:①项目表征(Item Representation):为每个学习资源抽取出一些特征来表示此项目(特征提取);②兴趣建模(Profile Learning):根据学习者过去喜欢(以及不喜欢)的资源的特征数据来学习训练出其喜好特征 (建立profile文件);③产生推荐(Recommendation Generation):通过比较上两步得到的学习者的profile文件和候选资源的特征,为该学习者推荐一组相关性最大的资源[6]。CB推荐的过程如图1所示。在基于内容的推荐技术中,最常用的算法是向量空间模型(Vector Space Model,简称VSM)算法。
向量空间模型是一种能够简单地把非结构化的学习资源变成结构化的内容的方法,也是一个可以把文本内容表示成数学向量的代数模型[7]。它能够把对文本内容的处理转化成数学空间中的向量运算,用数学空间上的相似度来表征语句含义的相似度,很直观并且容易理解。VSM多用于文本类资源的推荐。
如给学习者推荐一篇喜欢的文章。假设已知学习者喜欢一篇文章j,利用VSM方法首先把该文章表示成一个多维向量,即 aj=(W1,W2,…,Wn),其中 Wi表示第 i个词在文章j中的权重。如果向量维数很多,计算起来会比较麻烦,因此需要降维处理,也就是特征提取,可以采用开方拟和检验方法选出资源中较具代表性的特征词来表示该资源,从而降低向量维数[8]。然后,需要计算特征词的权重,最常用的计算权重的方法是信息检索中的词频-逆文档频率 (Term Frequency–Inverse Document Frequency,简称TF-IDF)[9]。计算完成后,我们得出学习者喜欢的文章 aj=(ω1j,ω2j,…,ωmj)。给出一篇文章 c,首先把文章 c向量化并降维处理,得到 c=(ω1c,ω2c,…,ωmc),判断它是否是学习者喜欢的文章,就要计算文章c和aj的相似度,如果相似度很高的话,则可以认为c也是学习者喜欢的文章。计算相似度可以用数学中的向量夹角余弦的计算公式[6]:
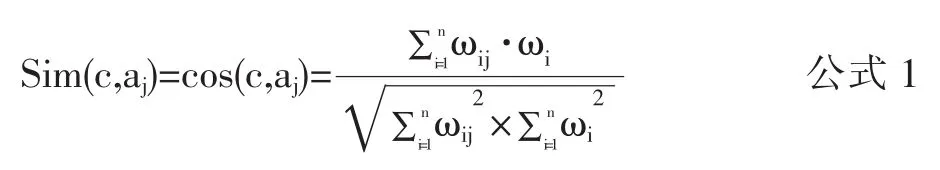
两篇文章的相似度可以通过两个多维空间向量的夹角余弦值来体现,余弦值越大,就表示向量之间的夹角越小,也就表示文章的相似度也越高。
向量空间模型(VSM)的优势在于:它是基于线性代数的简单模型,直观易懂;可以在文本类的学习资源集之间计算出连续的相似度和关联度,并按照关联度对文档集进行排序,从而依次推荐给学习者。它的不足之处在于相似度的计算量较大,当有新的文本加入文档集时,则需要重新计算全部词组的权重及文本相似度;并且对语言的识别敏感度不佳,检索的词组必须和文档中的词组完全相同,无法进行近义词之间的关联[7];另外,VSM算法是基于文本类的推荐,因此它的推荐结果的多样性不足。针对VSM语言识别敏感度不佳的缺点,相关专家对VSM进行了扩展和优化,研究出潜在语义学模型[10]、潜在语义索引模型[11]等,极大提高了语言识别的效果。但因为CB推荐多采用基于内容相似度检索以及基于概率的方法来产生推荐,所以它多用于文本类资源的推荐,对于视频音频等多媒体资源的推荐效果不是很好,即推荐的多样化不足[3],于是有研究者提出了基于协同过滤的推荐算法[12]。由于CF算法是基于学习者对资源的评分矩阵进行推荐的,与资源的形式和内容没有太大关系,因此CF算法能够给学习者提供满足其偏好及需求的更多样化(如文本类、视频音频类等)的个性化学习资源。
三、基于协同过滤的推荐
协同过滤(CF)技术是根据用户(学习者)对资源的评分矩阵,利用相似度算法找到待测(目标)资源或用户的最近“邻居”,根据邻居用户或邻居资源来预测未评分的目标资源,通过预测结果为学习者提供较准确的个性化推荐[13]。CF推荐技术根据算法运行期间需要用到的数据的差异可以分为基于内存的协同过滤(Memory-Based CF)和基于模型的协同过滤(Model-Based CF)。基于内存的协同过滤又可以细分为两类:基于用户的协同过滤(User-based CF)和基于项目的协同过滤 (Item-based CF)[14]。协同过滤技术(算法)是个性学习化推荐领域目前研究较多并且也是最成熟的推荐技术,它的应用广泛,推荐的效率及精确性也比较高。
1.基于内存的协同过滤
(1)基于用户的协同过滤
基于用户的协同过滤(UB-CF)算法的核心思想是:首先收集用户信息,包括用户注册信息(年龄、性别、兴趣爱好、知识水平等)和用户评分记录,算法根据用户(学习者)的注册信息可以生成用户模型,利用学习者对资源的评价记录来构建评分矩阵[4];再根据评分矩阵并使用相似度算法计算出学习者之间的相似度,形成最近“邻居”用户集合;最后利用最近邻居用户的评分记录来预测目标(待推荐)用户对学习资源的评分,并基于评分的高低来判断目标用户对学习资源的喜好程度,从而实现推荐[15]。UB-CF算法采用的是“相似的用户对学习资源的评分也是相似的”这样的一种思想,它的详细步骤为:
然后计算邻居用户。基于学习者-资源评分矩阵并使用相似度算法计算出学习者之间的相似度,进而找出最近邻居用户集合。其中计算学习者相似度的方法可以使用改进后的余弦相似度算法:[4]
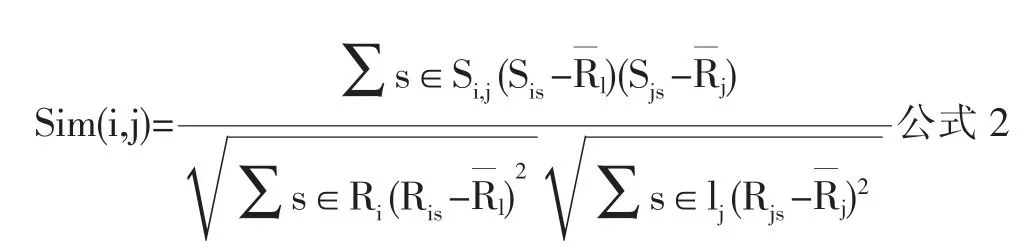
公式2中,Si、Sj分别表示的是学习者i和j的资源评分集合,Si,j=Si∩Sj表示的是学习者i和j共同评过分的学习资源集合,Ris、Rjs分别表示的是学习者i和j对学习资源 s 的评分,表示学习者 i和 j对学习资源评分的平均值。
上文的余弦相似度算法对于绝对的数值不是特别敏感,它更多的是从方向上来进行差异的比较和分析,因此不能较精确地衡量数值之间的差异[16]。而改进后的余弦相似度算法减去了用户对学习资源的平均评分,并且考虑到了用户共同评过分的资源集合,以此来改善因为不同学习者的评分标准而产生的结果的误差。
相似度计算完成之后,会得到一个和待推荐(目标)学习者相似度较高的学习者用户集合,选择合适的阈值m,确定待推荐学习者的最近邻学习者用户集合为Um={u1,u2,…ul…um}。
最后产生推荐。得到了目标用户的最近邻用户集合Um之后,可以通过对Um进行加权来预测目标(待推荐)学习者o对学习资源t的评分Rot:[15]
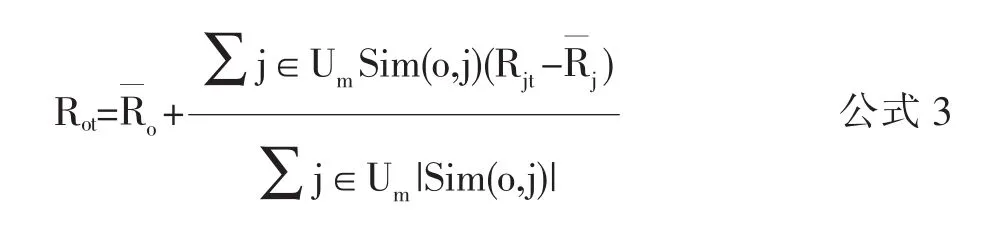
基于用户的协同过滤算法依据学习者(用户)对学习资源的评分矩阵得到学习者之间的相似度,其推荐结果相对准确且形式比较多样化,另外它还能够发现目标学习者潜在的新兴趣。但同时UB-CF也存在着一些不足之处,比如用户资源评分矩阵的数据稀疏性与系统的扩展性等问题[14]。
(2)基于项目的协同过滤
基于项目的协同过滤(IB-CF)和基于用户的协同过滤的算法思想基本相同,核心都是计算最近邻居集合及生成推荐列表。区别是IB-CF算法中最近邻居集合的确定依据是项目(学习资源)之间的相似度。IB-CF技术基于的是“学习者对于相似的资源(项目),评分也是相似的”这样的一种思想,详细步骤为:
首先,收集用户(学习者)信息以及对每个资源项目有过评分的学习者,构建项目—学习者的二维评分矩阵。
第二,通过评分矩阵计算目标资源t和用户已经评价过的资源之间的相似度,计算公式可以利用公式2,不过i和j表示的应是资源(项目),S表示的是用户集合。然后根据相似度计算的结果和用户模型 (知识水平、兴趣以及历史行为数据)来选择k个与已被评价过的资源最相似的item组成目标项目t的最近邻项目集合 Tk={t1,t2,…,tk}。
第三,产生推荐。最后将用户u对Tk的评分及相似度Sim的加权平均值作为对目标学习资源t的预测评分Put[15]。根据计算得出的预测评分值的高低来判断是否推荐给学习者。

公式4中,S(t,n)代表的是项目t和项目n的相似度,Run代表的是用户u对邻居集合中学习资源的评分值,Tk代表的是待推荐项目t的邻居集合。
在基于项目的协同过滤推荐中,因为各个学习资源之间的相似度比较固定,因此可以把各个项目之间的相似度放在线下计算,这样就能够节省计算时间,进而可以在一定程度上保证推荐的实时性。IB-CF的局限性在于冷启动问题较严重[17],即它只能对系统中已经有信息或者评分的用户和资源进行推荐或是被推荐,而对于新用户或资源则无法进行。
2.基于模型的协同过滤
基于模型的协同过滤推荐技术是依据学习者的兴趣爱好、学习需求、背景知识、历史行为等,利用数据挖掘或者是机器学习的算法从获取到的数据中训练出一个学习者模型,然后根据这个模型对学习资源的评分进行预测,进而产生推荐[18]。一般模型的建立速度会比较慢,但是一旦模型训练成功,进行预测的速度会很快[14]。在模型建立的过程中,当出现维数较多的信息矩阵时,计算起来会很麻烦,因此降维算法是基于模型的协同过滤中最重要的算法之一。所以,接下来详细介绍一种Model-based CF中常用的降维算法:奇异值分解(Singular Value Decomposition,简称 SVD)算法。
2000年,Sarwar为了改善用户评分矩阵中的数据稀疏问题提出了SVD算法[19]。SVD是一种降低维度的协同过滤算法,是一种有效的特征提取方法,它利用学习者(用户)与资源之间的潜在关系,通过去除一些没有代表性的或者不重要的用户或者学习资源来对初始的评分矩阵进行奇异值分解,并提取一些本质特征,从而实现对初始矩阵的降维处理。
SVD是线性代数中的一种矩阵分解技术,它揭示的是矩阵的内部结构。SVD可以将一个m×n的矩阵R分解为U、S、V[20],U是 m×n的正交矩阵 (UUT=1),V 是 n×n的正交矩阵 (VVT=1),S是 m×n 的矩阵,且 R=U×S×VT[21],其中 U、S、V 的计算步骤为:①计算S。首先,计算RT和RTR(RT是R的转置矩阵,即把R的行换成相应的列),然后计算RTR的特征值,再把特征值进行排序然后开方,由此就得到了S。②计算V和VT。利用RTR的特征值来计算特征向量,而V就是特征向量的组合集合。③计算U。R=USVT,RV=USVTV=US,RVS-1=USS-1=U,U=RVS-1。
用SVD将矩阵R分解成U、S、V以后,如果只保留前 k 个最大的奇异值, 也就是把 U、S、V 变成 Uk、Sk、Vk,那么就实现了对矩阵降维的目的。
SVD算法的优势是通过对矩阵的降维,极大地减少了运算量,在一定程度上提高了推荐系统的扩展性,而且较好地改善了协同过滤推荐中用户—学习资源 (项目)评分矩阵中的数据稀疏问题[22]。它的不足之处是在降低维度时,k值的选取较困难:如果k值过大,降维的意义就不大了,而如果k值过小,则可能会丢失原矩阵中比较重要的有用信息[23]。
综上所述,对基于内存的协同过滤和基于模型的协同过滤的总结对比如表1所示。
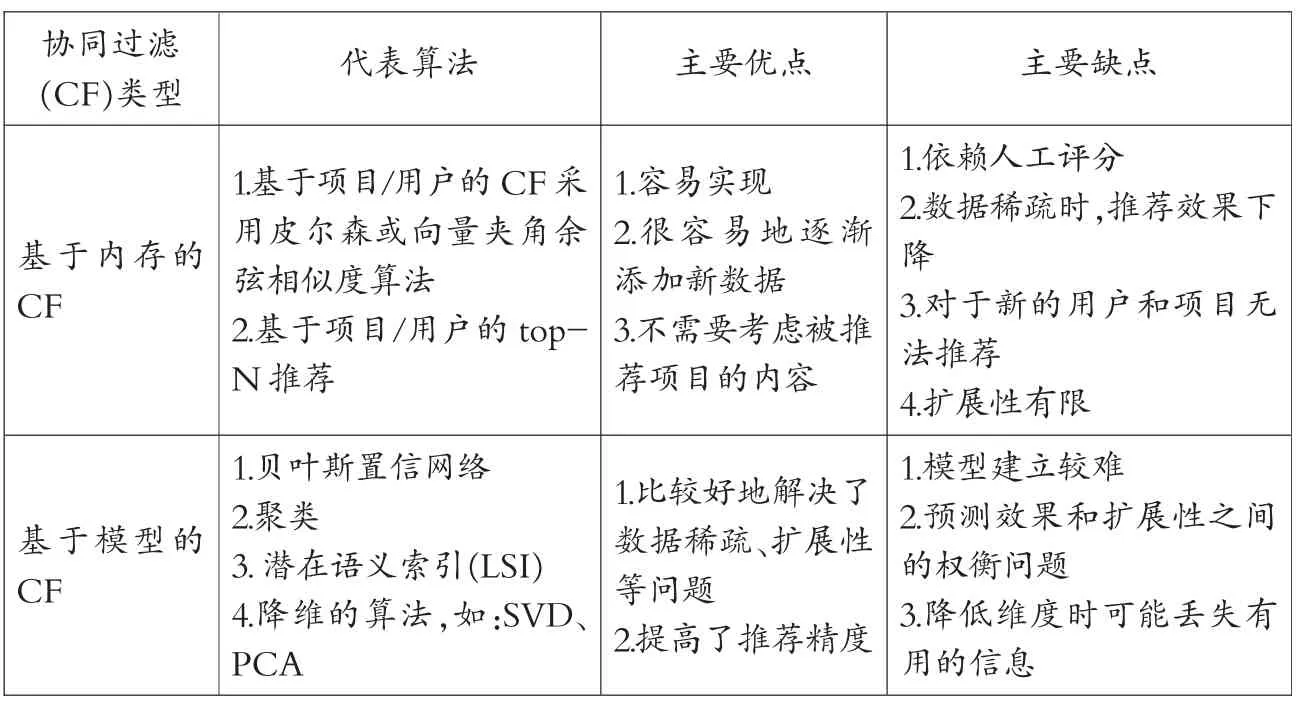
表1 基于内存的CF和基于模型的CF的对比表
四、基于内容的推荐和基于协同过滤推荐的比较
综上所述,无论是基于内容的推荐算法,还是基于协同过滤的推荐算法,都存在一定的优势和不足,这两类算法的优缺点对比总结如表2所示。
CB推荐和基于内存的CF推荐的相同点是都采用统计学的方法,通过计算用户之间或资源之间的相似度来进行推荐,核心任务都是相似度的计算。不同的是CB推荐的相似度计算是根据资源的属性向量来计算的,而基于内存的CF推荐是利用用户对资源的评分矩阵计算的。另外,基于内容推荐的优势在于它的推荐结果直观易懂,而且覆盖率较高,实时性好;缺点是推荐形式多限于文本类资源,多样性不足,且相似度计算量太大,当有新的文本加入学习资源文档集时,相似度就需要重新进行计算。基于内存的CF推荐是基于用户对资源的评分矩阵来计算相似度并进行推荐的,与资源的形式无关,因此推荐结果的形式更多样化;基于模型的协同过滤推荐可以使用机器学习和数据挖掘的算法基于学习者的个性化特征为其构建专属的用户模型,然后根据用户模型为学习者进行资源推荐,因此,CF推荐的资源个性化和自动化程度相对较高,但用户模型建立的难度比较大,并且存在冷启动问题,即当有新的学习者或资源加入系统时,没有足够的数据来对其进行推荐或被推荐。
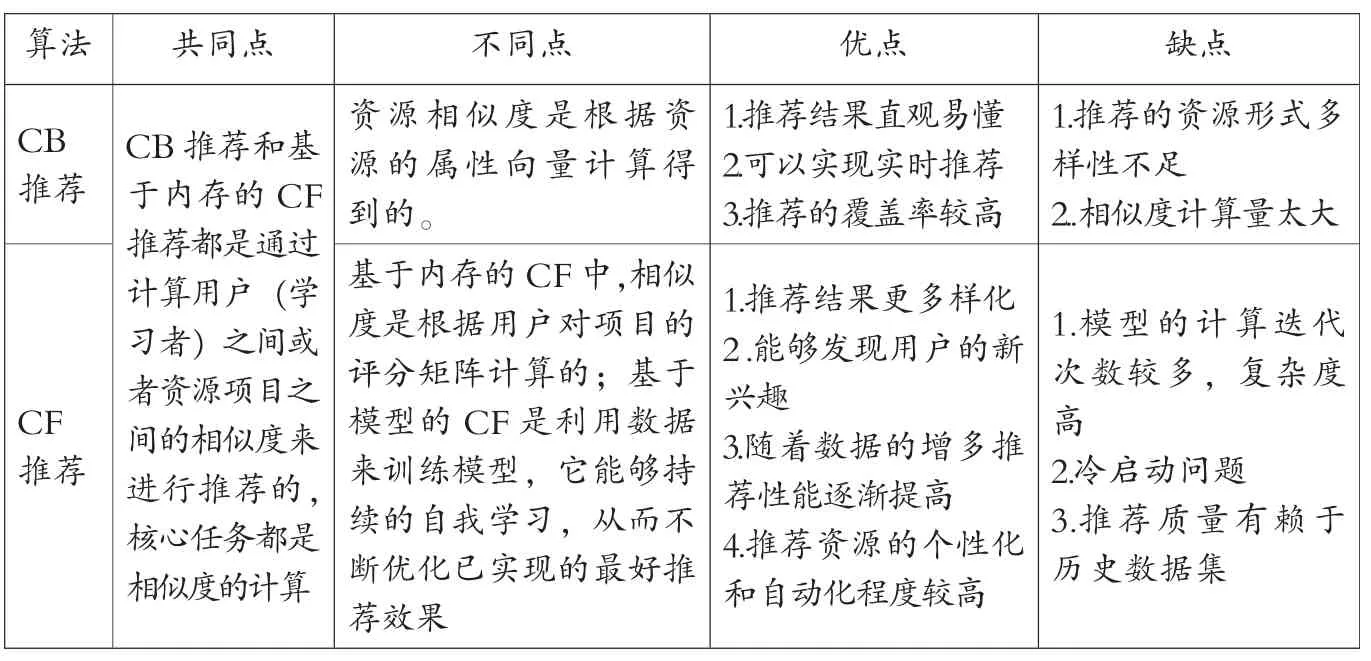
表2 CB推荐及CF推荐的对比表
五、混合推荐策略
在个性化学习推荐系统中,各种推荐技术中的算法都有其优缺点,单独的一种技术很难实现最好的推荐效果,因此在实际应用中,研究者通常会采用两种或两种以上推荐技术混合的方式来综合各种推荐技术的长处,为用户提供更加快速精确的学习资源推荐,从而实现更好的推荐效果。Burke在论述了几种混合推荐的方法,包括加权、切换、级联、特征增强以及元级。[24]
1.加权(Weighted)
系统综合采用多种推荐算法对同一资源进行评分,并把这些评分按照一定的规则加权处理,得到一个总分数,根据这个总分来判断是否进行推荐。最简单的加权混合推荐策略就是把由多种推荐技术(算法)得到的几个评分进行有权重的线性组合。加权混合推荐的好处是系统的推荐能力可以用一个直观的方式呈现,并且可以根据学习者对推荐资源的反馈评价来调整权重的分配,从而不断改善混合策略的推荐效果。
2.切换(Switching)
资源推荐系统同时提供多种推荐技术,在推荐过程中,根据不同学习者的需求,采用一些特定的标准来变换不同的推荐方法以达到最好的推荐结果。该策略的优势是系统对各个推荐技术的优缺点很敏感,可以根据不同情况及时切换推荐技术,但不足是切换标准的制定为推荐过程带来了额外的复杂性,增加了系统的负担。
3.级联(Cascade)
在级联混合策略中,系统会根据推荐技术的优先级先采用某一种推荐技术(优先级较高)给出一个粗略的推荐结果,然后再使用另外一种推荐技术(算法)在这个推荐结果的基础上进行更细致准确的处理,进而产生更精确的推荐结果。由于级联是分阶段的推荐,第二步的推荐技术是在第一步的基础上进行的,因此只需要应用于部分资源即可,所以它比将所有技术应用于所有项目的加权混合更高效。
4.特征增强(Feature Augmentation)
首先使用一种推荐技术(算法)将源资源数据经过处理输出特征结果,然后将该结果作为下一个推荐技术的输入。特征增强技术提供了一种在不修改核心系统的条件下改进系统性能的的方法。
5.元级(Meta-level)
组合两种推荐技术,将一种推荐技术产生的模型作为另一种推荐技术的输入。元级和特征增强有些类似,都是把一种技术的输出作为另一种技术的输入,但不同的是,在特征增强混合中,输入第二种技术的是特征结果;而在元级混合中,输入第二种技术的是整个模型。元级方法的优势在于推荐技术作用于数据信息密集的模型上要比作用于原始评分数据更容易,且推荐结果也会相对更个性化更准确。
在个性化学习资源推荐系统中,最常用也是最基本的推荐技术就是基于内容的推荐和基于协同过滤的推荐,因此,大多数的混合推荐策略都是基于这两种技术来实现更好的推荐效果。需要注意的是,为了最优化推荐效果,混合推荐中的算法都需要调整到最优化状态。
六、结束语
本文围绕个性化学习资源推荐这一主题,重点阐述了两大类学习资源推荐技术的代表算法,并对比分析了各类算法的优缺点。此外还简要论述了混合推荐中常用的组合策略,并对各类混合策略的优缺点进行了简单的分析和总结。虽然个性化学习资源的推荐已经成为教育领域的研究热点,但仍然存在一些问题有待进一步的研究和优化。比如,如何保证推荐的实时性和准确性的平衡,混合推荐中如何有效地分配各类算法的权重;以及模型建立问题、冷启动问题等。随着机器学习和数据挖掘研究越来越成熟,未来预计将会有更多的机器学习算法被运用到学习资源推荐中来,从而进一步提高推荐结果的精确性以及个性化程度,并使学习者可以快速高效地获取所需知识,提高学习效率。
猜你喜欢
科学大众(2020年23期)2021-01-18 03:09:08
学生天地(2020年15期)2020-08-25 09:22:02
文苑(2020年4期)2020-05-30 12:35:12
意林·少年版(2020年2期)2020-02-18 11:14:52
汽车观察(2019年2期)2019-03-15 06:00:50
新闻传播(2018年12期)2018-09-19 06:27:10
海外华文教育(2016年4期)2017-01-20 08:22:24
汽车与新动力(2016年6期)2017-01-04 10:50:48
中国卫生(2016年5期)2016-11-12 13:25:26
中国卫生(2015年1期)2015-01-22 17:20:15
