
基于深度学习算法的坦克装甲目标自动检测与跟踪系统
2018-09-27 12:00:44王全东常天庆戴文君
系统工程与电子技术 2018年9期
王全东, 常天庆, 张 雷, 戴文君
(陆军装甲兵学院兵器与控制系, 北京 100072)
0 引 言
图像处理技术在军事领域的典型应用是目标自动检测和自动跟踪系统。目前,坦克火控系统的目标自动跟踪技术已达到实用化水平,中、俄、以、日等国的部分3代坦克已安装了具备目标自动跟踪功能的稳相式火控系统,能够在坦克乘员发现和锁定目标后对其进行自动跟踪[1]。但由于战场环境的复杂性,坦克火控系统的目标自动检测技术尚处于研究和试验阶段,距离实战应用尚有差距。导致现有坦克火控系统的目标检测和选取,全部需要依靠乘员人工进行搜索和选择,系统的自动化、智能化水平和对战场图像信息的综合处理能力有待进一步提高。迫切需要发展一种同时具备目标自动检测与跟踪功能的坦克火控系统,实现对目标搜索、检测、跟踪和火力打击的一体化,从而使火控系统能够从日益复杂的战场环境中更迅速、准确地发现、识别和跟踪各类目标,更快地对各类战场目标做出反应。
目标检测算法通常包含:建议区域提取、目标特征建模和区域分类与回归3部分[2],其中特征建模属于算法的核心部分,其对目标特征的表达能力直接影响分类器精度和算法整体性能。目前主流特征建模方法按照特征提取方式的不同,主要分为:基于人工设计的特征模型和基于自学习的特征模型(以下简称人工模型和自学习模型)。常用的人工模型,如尺度不变特征变换(scale invariant feature transform, SIFT)[3-4]、方向梯度直方图(histogram of oriented gradient, HOG)[5-6]、Haar-like[7-8]等,具有结构简单、直观的优点,并且具有良好的可扩展性。采用多种特征组合的可变部件模型[9-11](deformable part-based model, DPM)算法,能够弥补利用单一特征进行目标表示的不足,是近年来人工模型常用的检测框架,被大量应用于人脸及行人等目标检测任务并取得了较好的效果。然而由于人工模型只包含图像原始的像素特征和纹理梯度等信息,并不具备高层语义上的抽象能力,对目标的刻画仍不够本质,使得这种方法在处理复杂场景下目标检测任务时的效果并不理想。
2006年,文献[12-13]首次提出了深度学习的概念和方法,指出包含多隐层的卷积神经网络(convolution neural network,CNN)具有极佳的特征学习和提取能力,与传统人工模型相比,其通过逐层提取方式学习到的抽象特征对数据本质的刻画能力更强,更适合于对数据的分类与识别,并且首次提出以“逐层初始化”的方式克服深度神经网络在参数训练上容易陷入局部最优的问题,解决了困扰深度神经网络多年的参数训练难题,掀起了深度学习的热潮,已成为目前最为有效的自学习模型方法。2012年,文献[14]提出的R-CNN算法最早将CNN理论引入目标检测领域,并获得了当年PASCAL视觉目标图像库(visual object classes, VOC)国际目标检测竞赛的冠军,相比于之前采用传统人工模型检测算法的最佳结果,平均精度(mean average precision,MAP)提高了显著提升。其后的SPP-Net[15]、Fast R-CNN[16]、Faster R-CNN[17-18]等改进算法在检测速度和精度上逐步提升,代表了目前该领域的最高水平。
当前,深度学习模型已逐渐代替传统人工模型算法成为处理图像检测问题的主流算法[19-23],为解决复杂战场背景环境下的目标检测提供了新的技术途径。本文采用深度学习的方法对复杂战场环境下的目标检测与跟踪问题进行了研究,选取坦克装甲车辆这种典型的战场目标进行识别,相关技术也适用于其他类型目标。
1 基于Faster R-CNN算法的坦克装甲目标检测
常用的深度学习网络模型包括自动编码器、受限波尔兹曼机、深度置信网络和CNN等,其中CNN及其改进型网络是目前深度学习领域采用的主流网络模型。
1.1 R-CNN系列算法的演化与对比分析
R-CNN算法的原理框架如图1所示,以对坦克装甲目标的检测为例,实现流程是:首先采用选择性搜索(selective search,SS)方法在整个输入图像中提取1 000~2 000个可能包含有目标的矩形建议区域,并通过缩放操作将得到的矩形建议区域统一缩放到相同大小(227像素×227像素)后,用深度CNN提取其特征向量。然后用训练好的分类器,如Softmax、支持向量机(support vector machine,SVM)等,对各候选区域进行分类。最后采用非极大值抑制的方法,在一个或多个临近的判定为相同目标的建议区域中,使用边界回归算法精细修正建议框位置,得到最终的目标检测、识别结果。
R-CNN算法的缺点在于:一是需要采用CNN提取近2 000个目标建议区域的特征向量,计算量巨大,算法无法满足实时性要求;二是由于网络的全链接层需要固定大小的输入,为固定输入CNN前的建议区域大小而对所有目标建议区域强制进行的缩放操作,会导致部分建议区域图像比例的失真和图像信息的流失。SPP-Net[15]和Fast R-CNN[16]算法针对R-CNN算法存在的问题进行了改进,只需对整幅待检测图像进行1次CNN计算后,直接在整幅图像的特征图上找到与建议区域相应的特征区域,并采用空间金字塔池化(spatial pyramid pooling,SPP)的方法,对不同大小的特征区域提取出相同固定大小的特征向量用于分类,不再限制输入神经网络的建议区域的大小。与R-CNN算法相比,SPP-Net和Fast R-CNN算法既显著减小了卷积运算的计算量又有效避免了缩放操作带来的图像失真和信息流失,使得算法的检测速度和MAP得到大幅提升。
通过对Fast R-CNN图像检测过程中各处理流程时间损耗的分析发现,建议区域的提取占据了整个检测流程的大部分时间,成为制约该算法速度继续提高的主要瓶颈。为解决建议区域提取的速度问题,2015年,文献[17]提出了Faster R-CNN算法,该算法通过采用和检测网络共享全图卷积特征的区域建议网络(region proposal network, RPN)的方式,产生高质量建议区域,使得建议区域的提取时间显著减小,显著提高了算法的检测速度。R-CNN及其改进算法在VGG-16网络模型下的MAP及训练、检测时间(GPU模式)对比如表1所示[14-18]。

表1 R-CNN及其改进算法的MAP及速度对比
1.2 迁移学习与模型训练
由表1可知,Fsater-RCNN算法的检测速度和精度较之前的算法有了明显提高。因此,本文首先采用迁移学习的方法将Faster R-CNN算法应用解决复杂背景下的坦克装甲目标检测问题。
(1) Faster R-CNN算法基本原理
Faster R-CNN算法的基本原理如图2所示。

图2 Faster R-CNN算法原理图Fig.2 Schematic diagram of Faster R-CNN algorithm
其首先使用一组交替出现的Conv+Relu+Pooling网络结构,在Conv5-3层(对于VGG网络而言)得到输入图像的卷积特征图。其次,通过RPN网络在特征图上以滑动窗口的方式产生许多个初始建议区域(anchor),并通过softmax分类器判断该anchor属于前景或背景的概率,再利用bounding box回归对初始建议区域的位置进行修正,得到精确的建议区域。最后,通过感兴趣区域(region of interest, ROI)池化将PRN网络产生的建议区域对应的卷积特征池化为统一大小的特征矢量,并通过分类与回归网络对建议区域内的目标进行分类和边界回归,得到最终的检测结果。
(2) 迁移学习与模型训练
多层级的深度CNN通常具有海量(千万级)的模型参数需要进行训练和学习,对训练样本的数量和计算机的内存、计算速度等硬件条件都有非常高的要求。而且现有大规模图像数据库,如ImageNet、VOC、CIFAR等,只包含行人、汽车、飞机等常见目标,通过此类型数据库训练的深度网络模型,只能检测数据库中所含有的特定类型的目标(20类)。但经大型数据库训练完成的模型参数已具备较强的目标提取能力,可作为迁移学习的初始化参数,显著提高迁移学习的训练效率。
迁移学习主要采用小规模的针对某新型目标的数据集对在大规模的图像数据集上预训练好的网络模型的模型参数进行监督训练和微调[24-26],使新训练得到的神经网络模型具备对该新型目标的检测能力。本文主要针对坦克装甲目标的检测,由于本文数据集的样本数量远小于ImageNet等图像数据库(百万级),因此采用迁移学习的方法对模型进行训练。常用的深度卷积网络模型包括LeNet(5层)、ZF-Net(7层)、Alex-Net(8层)、VGG-Net(19层)和Google-Net(22层)等,较深的网络层数通常意味着更高的检测精度,但算法卷积计算量也越大,检测速度也越慢。在综合考虑检测精度和算法速度的情况下,选择层数适中的ZF-Net模型,本文迁移学习的模型训练流程如图3所示。
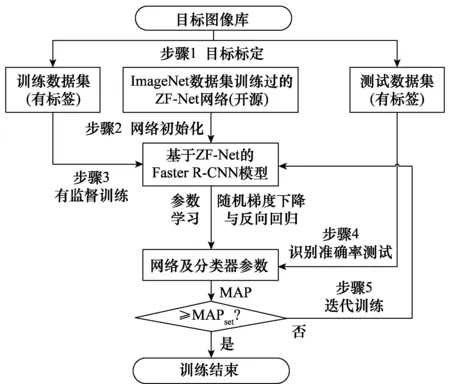
图3 基于迁移学习的目标检测模型训练过程Fig.3 Training process of target detection model based ontransfer learning
步骤1构建训练与测试数据集。深度学习网络模型的训练和测试需要大量的样本数据,本文建立了由6 000张彩色图像构成的满足PASCAL VOC标准数据集格式的坦克装甲车辆图像库(训练集5 000张,测试集1 000张)。对训练集和测试集图像中所有坦克装甲目标均进行了标注,分别包含12 476和2 317个目标。
步骤2选用经ImageNet数据集上训练好的ZF-Net作为初始化网络模型(开源),对模型参数进行有效初始化(区别于传统训练模式下的随机初始化)。
步骤3采用Fsater R-CNN算法框架,以有监督训练的方式,采用由5 000张图像构成的训练数据集对网络进行训练,根据损失函数采用随机梯度下降和反向回归算法对网络的模型参数进行微调和更新,得到新的模型参数。
步骤4采用由1 000张图像构成的测试数据集,对新训练网络模型的识别效果进行测试,计算得到MAP。
步骤5根据测试结果,循环步骤3~步骤5,进行多次的迭代训练,直至模型的MAP达到预期的检测精度。
1.3 检测结果及分析
坦克装甲目标在相机视场中的成像尺度与其和相机之间的距离成反比。实际应用中,目标可能出现在距离坦克几十米至数公里的范围内,目标成像尺度变化跨度很大。对于坦克图像库图像中的任意目标,假设其高度和宽度的较大者为maxw&h像素,按照maxw&h的大小将目标分为以下4种尺度类型的目标,具体的分类标准为
(1)
基于人工模型的典型传统算法:可变部件模型(deformable part models,DPM)算法以及分别采用ZF和VGG网络的Faster R-CNN算法对坦克装甲车辆图像库的测试集中各种尺度装甲目标的检测精度和速度如表2所示,各项指标的最佳效果采用粗体进行标志。所有的测试均在CPU为E5-2650Lv3,GPU(显卡)为GTX-TITIAN-X配置的图像工作站上进行。

表2 不同检测算法在坦克装甲车辆图像库测试集上的检测精度和速度
由表2可知:
(1) Faster R-CNN算法的检测精度明显优于传统DPM算法。虽然Faster R-CNN算法的模型参数和计算量明显大于DPM算法,但由于Faster R-CNN算法的绝大部分计算均在GPU上进行,使其平均检测速度可以达到甚至超过传统算法(受网络深度影响)。
(2) Faster R-CNN算法在采用VGG网络时的平均检测精度比ZF网络提高大约7%,但由于VGG网络的模型深度增加,导致卷积运算量增大,算法检测速度明显降低。
(3) 对微型目标的检测精度明显低于中型和大型目标,这是传统DPM算法和Faster R-CNN算法均存在的问题。Faster R-CNN算法对微型目标检测精度不及大目标的原因在于:算法采用的网络结构(ZF或VGG)中,相邻两个卷积网络层之间存在一个池化层(作用近似于降采样),导致深层卷基层输出特征图的尺度与原始输入图像相比会缩小很多,而算法的RPN和分类与回归网络均采用最后一个卷积层(Conv5-3)的输出特征作为输入,其尺度比原始输入图像缩小了16倍,对于微型目标而言容易造成建议区域的提取不够精确,同时也无法保留足够的信息用于后续的分类和回归。提高Faster R-CNN算法对微型目标的检测精度是一个值得继续深入研究的问题。
本文训练的基于ZF网络的Faster R-CNN算法对坦克装甲目标图像的部分检测效果如图4所示,模型输出目标概率大于0.8即认为是目标。由检测结果可知,本文经过迁移学习和训练得到的深度网络模型在复杂背景下对各种姿态和多种类型的坦克装甲目标均具备良好的检测能力。这是由于深度学习算法通过大量的样本训练使模型具备了较强的目标提取能力,并且通过CNN的逐层提取方式得到了坦克装甲目标的深层次结构性特征,与传统人工规则构造特征的方法相比,该特征更能够刻画目标图像数据的丰富内在信息,对各型坦克均具有较强的泛化能力,而且对目标姿态、颜色、大小和环境的变化具有很高的容忍度,可以较好的适应各种战场环境,在有限的烟雾及局部遮挡(此类情况在战场环境中较为常见)情况下,仍能识别坦克目标,显示出了良好的目标检测识别能力,实现了对复杂背景环境下坦克装甲目标的自动检测。

图4 复杂背景下的坦克装甲目标检测结果Fig.4 Detection results of tank armored targets under complex background
部分错误检测结果如图5所示,主要表现在算法存在一定的过检、误检、漏检和检测失败的问题。图5(a)过检测的原因在于边界回归算法存在局限,检测出的两个相邻目标框的重叠度未能满足将其归于同一目标的回归规则。图5(b)误检的原因在于CNN学习到的是目标的深层次结构特征,对于部分局部类似坦克的建议区域存在被误检为坦克目标的可能。漏检(见图5(c))和检测失败(见图5(d))的原因在于目标较小或者遮挡、伪装严重,CNN难以提取到有用的目标特征用于分类,导致的检测失败。上述几种失败的检测识别情形,说明深度学习算法仍有其不足之处。但其与传统基于人工特征的检测算法相比还是表现出了极大的优越性,对一般难度的目标图像具有很高的检测精度。另外本文算法的模型深度和训练样本数量有限,对算法的目标检测精度也会有一定影响。

图5 各种检测失败情形Fig.5 Various dection failures
2 坦克火控系统现有跟踪算法的不足与改进
2.1 “相关跟踪”算法的原理与不足
某典型三代坦克目标自动跟踪火控系统采用的“相关跟踪”[1]算法原理,如图6所示。为保证跟踪算法的实时性,图像传感器一般选用黑白相机。假设瞄准镜图像大小为M×N像素,用F(x,y)代表瞄准镜图像中某点(x,y)处的灰度值。在t0时刻,炮长采用大小为K×L的跟踪框锁定目标,产生一个K×L像素大小的目标样板图像Q,用Q(i,j)代表目标样本图像点(i,j)处的灰度值。

图6 目标样板图像与瞄准镜子图像Fig.6 Target template image and sub-images of sight
用Suv代表左上角坐标为(u,v)大小为K×L的一个瞄准镜图像的子图像,Suv(i,j)代表该子图像中点(i,j)处的灰度值,则
Suv(i,j)=F(u+i,v+j)
(2)
相关跟踪算法就是从当前瞄准镜图像中,找到与目标样板最相似的子图像位置,作为跟踪结果。这需要对瞄准镜子图像和目标样板图像的相似度进行衡量,引入相似性测度的概念:
(i,j)-Q(i,j))2
(3)
Ruv越小,说明该子图像与样本图像的相似度越高。为了减小Ruv对光线等环境因素导致的图像灰度值变化的敏感程度,通常采用式(4)所示的归一化后的Ruv作为瞄准镜子图像和目标样板图像相似度的评价指标。
(4)
由式(4)可知,每次相关匹配操作均需要对样板图像和子图像的K×L个像素灰度值进行乘积求和开方运算,计算量较大,影响算法实时性。对于上述问题,序贯相似性检测算法(sequential similarity detection algorithm,SSDA)[27]方法是一种常用的改进算法,其对于失配位置不需要计算所有点对应的相关性,可以迅速得到该位置不是匹配点的结论。如图7所示,设定一个阈值T0,对每一搜索位置,按照一定的对比顺序比较该子图像和目标样板图像的差值,并累计其误差Er,当Er超过阈值T0则停止匹配计算。

图7 SSDA算法示意图Fig.7 Diagram of SSDA algorithm
SSDA算法的匹配精度随阈值T0的增加而增加,但计算速度随之降低,因此可以采用单调增加阈值Tn(或阈值自适应算法)代替固定阈值T0,达到速度和匹配精度的最优。
坦克火炮属于直瞄型武器,从炮长发现目标到火力打击的过程,可在数秒内完成,在目标姿态和环境变化不大的情况下,“相关跟踪”算法的跟踪效果还是不错的。但现有坦克火控系统的目标跟踪技术在实际运用中也存在如下问题:
(1) 无法从大范围战场环境中快速实现目标的自动检测与识别,而且目标的选取仍需炮长人工进行选择。
(2) 现有跟踪算法对环境变化敏感,难以适应目标姿态和光照的剧烈变化,尤其是目标的快速旋转和遮挡。
为了弥补采用“相关跟踪”算法的火控系统在面对环境或目标姿态剧烈变化时的不稳定性,现有坦克火控系统在跟踪失败时,允许炮长随时退出自动跟踪工况,切换为手动跟踪工况,但并未从根本上解决上述问题。
2.2 基于TLD框架的复合式目标跟踪算法
为了弥补“相关跟踪”算法在面对环境和目标姿态变化时的不稳定性,将基于深度学习的检测算法与现有“相关跟踪”算法相结合,提出了如图8所示的基于跟踪-学习-检测(tracking-learning-detection,TLD)框架[28]的复合式目标跟踪算法,其中检测器采用基于深度学习模型的Faster R-CNN算法,跟踪器采用SSDA算法。视频流首先输入检测器模块,当检测出目标后,再将目标模板送入跟踪器进行跟踪。之后检测器模块和跟踪器模块同时工作,并将检测器与跟踪器输出的目标位置框Dr和Tr的综合结果,作为最终的目标跟踪结果,以此提高火控系统跟踪的稳定性。同时为保证跟踪器也能够适应一定程度目标的状态变化,以检测器的最新检测结果对跟踪器的跟踪模板进行在线持续更新。

图8 基于TLD框架的复合式跟踪算法结构Fig.8 Composite tracking algorithm based on TLD framework
检测器输和跟踪器输出的目标位置框Dr和Tr的融合规则如下:
(1) 若检测器检测失败,跟踪器跟踪成功,则以Tr作为最终跟踪结果;
(2) 若跟踪器跟踪失败,检测器检测成功,则以Dr为最终跟踪结果,并对跟踪器模板进行更新和初始化;
(3) 若检测器、跟踪器均成功,则计算Dr与Tr的重合度r。若r≥0.8,可认为检测器和跟踪器的位置输出结果基本一致,以Dr为准。若r<0.8,则分别计算Dr、Tr内图像与上一帧目标位置框内图像的相似度,以相似度大的作为最终跟踪结果,相似度的计算参照式(4)。
Dr与Tr的重合度(intersection over union, IoU)定义为
(5)
式中,area( )代表求面积。
(4)如果跟踪器和检测器均失败(目标丢失),则采用检测器持续对目标进行检测,待检测出目标后立即对跟踪器模板进行更新和初始化,并重启跟踪器。
2.3 跟踪测试结果与分析
选取了如图9所示的4段典型的坦克运动视频,对本文复合式跟踪算法与SSDA算法以及TLD算法的跟踪效果进行了对比测试。4段测试视频的特点为:1号视频中目标进行直线运动,没有遮挡且目标姿态和成像大小几乎不变;2号视频中目标进行快速S型机动,姿态持续变化,用于测试模型对目标姿态变化的适应能力;3号视频目标运动过程中连续出现树木遮挡,用于测试算法对目标遮挡的适应能力;4号视频为目标长时间运动的视频,运动过程中目标姿态和目标成像大小均存在变化,部分帧中的目标存在树木遮挡,且目标颜色与背景较为相似,用于测试跟踪算法的持续稳定跟踪能力。测试前对所有测试视频的目标真实位置都进行了标注,以用于对算法的跟踪效果进行评估,实验中设定跟踪框与标注框的重合度大于0.5即视为跟踪成功。

图9 跟踪算法测试视频Fig.9 Videos for the test of tracking algorithm
采用目标跟踪测试基准(object tracker benchmark,OTB)跟踪算法测试基准[29]中的成功率和精确率曲线评估本文算法的实际跟踪效果,结果如图10所示,图10(a)~图10(d)分别为1~4号视频的成功率曲线,图10(e)~图10(h)分别为1~4号视频的精度曲线。其中,A为SSDA跟踪算法,B为TLD跟踪算法,C、D均为本文提出的复合式跟踪算法。区别在于:C算法的检测模块仅在第一帧及跟踪器跟踪失败时才进行检测,其目的在于提升算法速度;D算法的检测模块采用逐帧检测(检测器始终处于工作状态)。各算法的目标选取方式、成功跟踪帧数以及平均跟踪速度如表3所示,各项指标的最佳效果均采用粗体进行标志。

图10 不同跟踪算法的成功率与精度曲线对比图Fig.10 Comparison of success rate and accuracy curves of different tracking algorithms

测试视频总帧数成功跟踪帧数ABCD目标选取(手动:×,自动:√)ABCD平均跟踪速度/(帧/s)ABCD1297297297297297××√√21835286154183××√√33623562276349××√√41 8653821 1521 5341 865××√√40122711
成功率曲线主要反映算法的持续跟踪能力即跟踪算法的稳定性,精确率曲线主要反映算法的跟踪精度。由图10及表3的测试结果可得如下结论。
(1) 跟踪稳定性
在处理目标姿态无明显变化的简单跟踪任务时(1号视频),4种算法均能实现对目标的连续稳定跟踪,但当目标姿态发生快速变化和被部分遮挡时(2、3、4号视频),A、B算法均出现了不同程度的跟踪失败现象,C、D算法的成功跟踪帧数明显高于A、B。原因在于C、D算法的检测器可以在跟踪器跟踪失败时重新检测出目标,并对跟踪器模板进行更新和初始化,使得算法在处理目标姿态变化和遮挡等情况下的跟踪效果更稳定。B算法虽然也有检测模块,但其检测模块采用在线PN学习的方式,检测效果严重依赖目标样版图像,对目标姿态变化和遮挡的容忍度有限。C算法的成功跟踪帧数少于D算法的原因在于跟踪失败后检测器重新检测出目标需要一定的时间,在此期间存在短暂的目标丢失。
(2) 目标选取
A、B算法需要手动选取跟踪目标,C、D算法可以实现对跟踪目标的自动选取,自动化程度更高。
(3) 跟踪精度
当4种算法的成功跟踪帧数大致相同时(1号视频),采用跟踪器和检测器融合输出目标位置的方式(B、D)比只采用跟踪器(A、C)的方法,对目标的跟踪精度更高。但当目标姿态发生快速变化和被部分遮挡导致跟踪失败时(2、3、4号视频),跟踪成功率较高算法(C、D)的跟踪精度优于成功低较低算法(A、B)。
(4) 跟踪速度
复合式跟踪算法(D)的跟踪速度与现有SSDA(A)相比算法仍存在较大差距,比TLD算法(B)更快是因为检测模块采用了GPU加速。与D算法相比,C算法是一种折衷的方式,在提高跟踪速度的同时牺牲了部分跟踪精度。
3 目标自动检测与跟踪实验系统设计
要从大范围战场环境中快速检测和跟踪目标,首先要求实验系统能够快速、稳定地获得宽视场、高分辨率的战场图像。为使图像具有足够的像素点用于对目标的描述,便于后期的目标检测与跟踪,相机视场一般很小(坦克瞄准镜的视场为8°左右)。本文采用动态扫描凝视成像技术,实现小视场探测器对大范围战场的快速成像。具体而言:将相机固定在转台上,通过转台的连续转动对战场区域进行连续扫描,以弥补相机视场的不足。但相机随着转台的旋转会导致曝光时刻景物与探测器间存在相对运动,从而产生像移问题,造成成像的模糊及拖尾效应。本文通过在相机的光学系统前增加快速反射镜,以控制快速反射镜旋转的方式实现对像移的补偿。
3.1 动态扫描凝视成像的工作时序
为了在曝光时间保持景物与探测器之间的相对静止,使探测器在运动状态下仍能保持对景物的凝视(达到静止成像的效果),必须通过对快速反射镜的反扫控制,实现对探测器(随动于转台)转动速度的补偿。
系统连续成像的过程与反扫工作时序如图11所示,其中,θM为探测器位置,θS为瞄准线(视轴)位置,θFSM为反射镜位置。当探测器处于位置M,瞄准线处于位置a时,瞄准线处于视场#a的中心,此时要求反射镜的转动速度ωFSM和探测器的转动速度ωM相匹配,使得瞄准线在惯性空间“凝视”;同时必须保证“凝视”时间(反扫时间)大于探测器的积分时间,完成对视场#a的清晰成像。当探测器完成积分成像后,反扫补偿镜快速回到反扫起始位置。当系统判断探测器位置位于M+1时,瞄准线处于位置a+1,此时两幅图像刚好满足设计的重叠角度,快速反射镜再次进行反扫,再次使瞄准线在惯性空间“凝视”,完成对视场#a+1的清晰成像,随后重复本过程(#a+2,…,#a+n),直至完成整个区域循扫或周视成像。

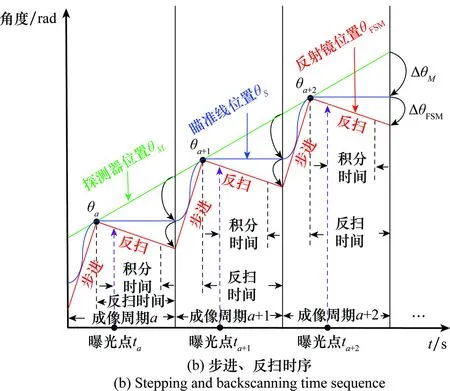
图11 系统连续成像过程与反扫工作时序Fig.11 Continuous imaging process of the system
在图11(b)所示的工作时序下,整个光学系统和探测器随着转台进行“匀速转动”,反扫补偿镜以固定周期进行“步进”和“反扫”,2个运动机构(转台和反射镜)共同运动、精确配合,使瞄准线周期性的“步进”和“凝视”。在“凝视”期间,探测器位置随转台的转动不断变化,但瞄准线角度稳定不变,从而实现探测器对战场侦查区域的高效凝视成像。
3.2 控制系统设计
目标检测与跟踪实验系统的总体控制结构如图12所示。系统采用复合轴控制,主要包括转台位置控制回路和快速反射镜位置控制回路。2个控制回路均采用由位置环和速度环构成的双环控制结构,其中转台位置控制回路以惯性角速率测量元件(陀螺)为反馈,隔离外界的力矩扰动,确保转台以给定的速度扫描成像。
实验系统主要有区域侦查、全景侦查和目标跟踪(手动/自动)3种工作模式。区域侦查模式下:首先通过调转指令将转台旋转至扫描起始位置,然后向扫描方向匀速旋转,同时通过反扫指令对反射镜的速度进行控制,实现对指定区域的扫描凝视成像,并通过目标检测算法快速发现其中的可疑目标及其所处方位。全景侦查模式下:控制系统可无视转台实际位置,从转台现有位置为扫描起点,在反扫指令的配合下,完成360°扫描凝视成像,并通过目标检测算法快速发现360°视场中的可疑目标及其所处方位。目标跟踪模式下:系统在区域侦查或全景侦查发现可疑目标后,将转台快速调转至目标所在区域,并采用复合式跟踪算法实现对目标的持续跟踪。
3.3 电气结构设计
实验系统的电气关联图如图13所示。其中,管理计算机接收来自信息处理计算机的各种操控指令,并传输给可见光相机、红外相机、激光测距机、伺服控制计算机等组成单元,控制组成单元的功能和运动,同时将光电系统的视频图像信息、瞄准线角度信息等回馈给信息处理计算机。相机获得的图像数据通过两路千兆网分别传输,首先由上位光纤收发器将两路千兆网转换为光信号,并通过光滑环传输到下位光纤收发器,下位光纤收发器将接收到的光信号重新转化为两路千兆网信号并最终传入信息处理计算机进行目标检测和跟踪的处理。

图12 目标检测与跟踪实验系统总体控制结构Fig.12 Overall control structure of the target detection and tracking experiment system

图13 实验系统电气关联图Fig.13 Electrical connection diagram of experimental system
光相机与红外相机的分辨率分别为:1 600×1 200和640×480,二者的视场一致且为同轴设计,水平向均为5.4°,垂直向均为7.2°,光轴一致性小于0.3 mrad。设计了如图14(a)所示的光路结构,经快速反射镜反射的入射光线通过一个分光镜,将入射光线分为可见光和红外光两部分,分别送入可见光与红外相机进行成像。由同一个快速反射镜弥补转台运动导致的像移问题,实现了可见光和红外相机对快速反射镜的共用。如图14(b)所示,可见光相机由于分光镜的遮挡,未能在实际结构中显示。

图14 光路结构设计Fig.14 Design of optical structure
3.4 软件设计
最终设计的实验系统及系统终端界面如图15所示,主要包含:伺服控制、目标调转、激光测距、轴角解算和目标检测与跟踪等功能。通过对转台轴角的解算,可以实时获得扫描图像的方位信息。当检测到目标后,通过调转指令,可将相机视场快速移动到目标所在区域。
系统主要存在区域侦查、全景侦查和目标跟踪(手动/自动)3种工作模式,为保证可见光相机和红外相机曝光的一致性,二者均采用统一的外部曝光触发脉冲。在GPU加速的情况下,本文采用ZF网络的Faster R-CNN算法的检测速度可以达到17帧/s。由于算法目前的检测速度有限,在此我们设计全景侦查的周期为5 s:曝光脉冲频率15 Hz,由75张扫描图像构成360°周视成像,相邻两帧图像重叠0.6°。区域侦查的周期为2 s:曝光脉冲频率12 Hz,由24张扫描图像构成120°区域成像,相邻两帧图像重叠0.4°。对全景或区域侦查采集的战场图像进行目标检测,根据检测算法输出的目标概率大小,只显示概率最高(≥0.8)的3幅可疑目标图像及其方位信息。操作人员可通过调转指令将,将相机视场快速调转至目标所在区域,并对其进行监视和跟踪。

图15 目标检测与跟踪实验系统Fig.15 Target detection and tracking experiment system
4 实验测试
系统目前的目标检测和跟踪功能只针对可见光图像。由于红外图像的训练样本十分有限,本文尚未进行对红外图像目标检测和跟踪的研究,目前红外相机仅作为一种辅助成像方式,用来人工发现隐蔽目标。对实验系统的成像以及本文目标检测和跟踪算法的实际效果进行了测试。
4.1 动态扫描凝视成像效果测试
保证相机在快速扫描情况下的清晰成像是开展目标检测和跟踪的基础,图像清晰度对后续目标检测和跟踪的结果具有重要影响。对实验系统在静止成像、移动成像和移动反扫成像3种成像方式下可见光相机的成像效果进行了测试,其中静止成像指转台和反射镜均静止情况下的成像,移动成像指转台转动而反射静止情况下的成像,移动反扫成像指转台和反射镜均转动,即动态扫描凝视成像方式下的成像。测试结果如图16所示,可以发现相机在移动成像方式下的成像结果存在严重的像移模糊现象,而移动反扫成像通过对反射镜的控制,在“动平衡”中实现了对转台运动造成的像移补偿,使曝光时刻景物与探测器之间保持相对静止,实现了对景物的稳定清晰成像,成像效果与静止曝光无明显差异。
点锐度法是一种改进的边缘锐度算法,主要根据图像边缘灰度变化情况来判别图像的清晰度,该方法易于实现,适用于细节丰富、有纹理特征的图像清晰度评价。为了对不同成像方式下的成像效果进行定量分析,本文采用点锐度的方法对系统成像质量进行评价。

图16 不同成像方式下可见光相机的成像序列对比Fig.16 Comparison of imaging sequences of visible light camera in different imaging modes
对于一幅m×n大小的彩色图像,首先分别提取图像三通道的RGB分量:Rm×n,Gm×n,Bm×n。则该彩色图像最终的点锐度评价值为
PRGBm×n=0.30PRm×n+0.59PGm×n+0.11PBm×n
(6)
对图16所示的3组不同成像方式下成像序列的点锐度进行了计算,其结果如表4所示。

表4 可见光相机各种成像方式下的点锐度及归一化点锐度值
表4中,PRGB(a)、PRGB(b)、PRGB(c)分别为静止成像、移动成像和移动反扫成像方式下可见光相机成像序列的点锐度评价值。由于图像的点锐度会受图像内容影响,为了弥补图像内容对点锐度的影响,以静止成像时图像的点锐度为参考,对移动成像和移动反扫成像时图像的点锐度进行归了一化处理,其中

(7)
由表4可知,采用移动反扫成像方式下相机成像序列的相对点锐度值明显高于移动成像方式,说明移动反扫成像方式下相机成像的清晰度明显高于移动成像。而且移动反扫成像方式下相机成像序列的点锐度值均在静止成像方式相机成像序列点锐度值的90%以上,说明两者清晰度差别不大,系统动态扫描凝视成像效果良好。
4.2 大范围目标检测功能测试
120°区域侦查模式下的目标检测结果如图17所示。转台扫描起点的轴角位置为(60°, 0°),以下均按照(方位角,俯仰角)的方式对轴角进行表示。采用顺时针扫描,整个120°扫描区域由24张图像构成,其中在第7帧和第16帧中发现可疑坦克装甲目标,输出的目标概率分别为0.983和0.992,图像所在轴角位置分别为(92.79°, 0.10°)和(137.58°, 0.08°),与目标实际位置相符。2幅图像的俯仰方向轴角不为零,是因为转台转动时系统存在轻微抖动,对陀螺仪输出的角度值存在一定影响,但影响较小,基本可以忽略。操作人员可根据轴角解算得到的图像方位信息,将相机视场快速调转至目标所在区域,在跟踪模式下对其进行后续监视和跟踪。

图17 120°区域侦查模式下的目标检测结果Fig.17 Target detection results in 120° regional detection mode
4.3 复合式目标跟踪算法测试
选取了一段包含遮挡及目标快速旋转机动的场景视频,对上述目标检测与跟踪一体化算法(C、D)与现有SSDA(A)及TLD(B)算法进行了对比测试,跟踪结果如图18所示。在第30帧附近,目标与背景颜色相近且出现树木遮挡,A算法由于跟踪误差的累积使跟踪出现漂移,并逐渐导致跟踪失败。B、D算法由于检测器的存在,其跟踪并未受遮挡的影响,C算法在跟踪器失败后,在第34帧通过目标检测器重新检测出了目标,并对跟踪器进行了初始化。目标在第90~150帧进行快速转弯机动,在此期间目标姿态发生持续快速变化。由于目标机动速度较快,在第125帧附近,B、C算法均出现了目标跟踪丢失的情况,C算法跟踪失败是由于其跟踪模块采用SSDA算法,由于目标姿态变化显著超出模型了容忍度,导致跟踪失败(但随后又通过检测器模块在130帧附近检测出目标)。B算法采用线上PN学习的方式,由于其跟踪模板更新速度跟不上目标姿态变化或者目标特征变化太大,超出模型容忍度,导致跟踪失败。本文复合式跟踪算法(D)的检测器模块,采用深度学习(线下学习)的方法,能够适应目标的各种姿态变化,在跟踪器跟踪失败的情况下,可以重新检测出目标,并对跟踪器模板进行在线跟新,从而实现了对目标的持续稳定跟踪,取得了较好的跟踪效果。但基于深度学习的目标检测器的计算量巨大、速度较慢,导致复合式跟踪算法的速度目前尚不能达到实时性的要求。

图18 坦克装甲目标的检测跟踪结果Fig.18 Detection and tracking results of tank armored target
5 结论与展望
信息化战争中,坦克乘员往往要在较短时间内处理大量的战场信息,对整车反应速度提出了更高要求,实现对目标的自动检测与跟踪是坦克火控系统未来发展的重要方向,本文设计了一套面向坦克火控系统的目标自动检测与跟踪实验系统。该系统采用动态扫描凝视成像技术实现了对大范围战场图像的快速、清晰获取,并采用迁移学习和基于深度学习模型的Faster R-CNN算法实现了对复杂背景下的坦克装甲目标的快速检测,与基于人工模型的传统算法相比达到了较高的检测精度。通过将Faster R-CNN算法与现有跟踪算法相结合,提出了复合式目标跟踪算法,实现了对坦克装甲目标的自动检测与稳定跟踪。
本文实验结果表明:基于深度学习的目标检测算法通过多层CNN学习和提取坦克的目标深层次结构模型,能够检测出各种姿态下的坦克装甲目标,对目标的烟雾或局部遮挡以及目标姿态、颜色、大小和环境、背景的变化具有较高的容忍度。同时,通过将其与传统跟踪算法相结合,可以实现目标的自动检测和持续稳定跟踪,为坦克火控系统实现对复杂背景条件下的目标自动检测与跟踪,提供了一种稳定、可行的技术方案。研究中发现目前深度学习算法在应用于坦克火控系统的目标检测、跟踪时仍然存在部分问题,主要表现在:
(1) 算法实时性有待提高
目前,Faster R-CNN等主流深度学习算法尚无法实现对连续视频的实时检测与跟踪,但深度学习算法的发展速度很快,从R-CNN模型到Faster R-CNN仅用了不到两年时间,检测速率已经提高了近百倍,最新的YOLO(you only look once)[30]、SSD(single shot detector)[31]等深度学习模型采用“单步检测”的方式省略建议区域提取过程,直接利用CNN的全局特征预测每个目标的可能位置,已经可以实现视频目标的实时检测,但模型精度有所降低。
(2) 模型复杂度高,计算量大,对系统软硬件需求较高
现有深度学习算法基本未考虑计算机资源的限制,其对计算机软硬件的需求远超目前火控计算机的资源配置,要实现此类技术在坦克火控系统中的工程应用,需要继续对模型进行适当简化和优化,降低对系统的软硬件要求和设备成本。
(3) 对于小微目标仍然存在部分漏检问题
对于一般场景下的显著目标,Faster R-CNN算法已经可以达到很高的检测精度(MAP>60)。但深度学习算法在在小微目标检测方面的精度与大尺度目标相比仍有较大的提高空间。这是由于算法采用的网络结构中,相邻2个卷积网络层之间存在一个池化层,导致深层卷基层输出特征图的尺度与原始输入图像相比会缩小很多,对于小微目标而言容易造成建议区域的提取不够精确,同时也无法保留足够的信息用于后续的分类和回归。通过合理利用多个卷基层特征而不仅仅是最后一个卷基层的特征的方式来弥补小微目标的特征在经过多个池化层后在深层卷积特征图上的信息损失,从而增强算法对小微目标的检测能力,是一种不错的改进思路。
未来要实现深度学习算法在坦克火控系统目标自动检测与跟踪中的工程化应用,后续应主要围绕上述3项问题开展相关研究工作。此外,目前尚未有标准的大规模战场目标图像数据库,导致模型训练样本数量偏少。如何利用小样本数据实现高效网络的训练也是一项值得深入研究的问题。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17 08:08:06
学与玩(2022年8期)2022-10-31 02:41:58
太阳能(2022年3期)2022-03-29 05:15:50
小学生学习指导(小军迷联盟)(2020年12期)2021-01-05 12:16:24
作文小学中年级(2020年6期)2020-07-24 08:33:10
太阳能(2020年3期)2020-04-08 03:27:10
当代工人·精品C(2019年2期)2019-05-10 00:13:22
计算机应用与软件(2017年7期)2017-08-12 15:45:55
科技知识动漫(2017年5期)2017-05-11 00:07:47
自然资源遥感(2014年3期)2014-02-27 11:56:38
