
基于自适应Lasso变量选择方法的指数跟踪
2018-09-21 05:43秦晔玲朱建平
统计与决策 2018年16期
秦晔玲,朱建平
(1.太原理工大学 数学学院,山西 晋中 030600;2.厦门大学a.管理学院;b.数据挖掘研究中心,福建 厦门 361005)
0 引言
计算机科学的快速发展使得当代科学研究能够很容易地收集到海量数据集,特别是在金融领域。金融证券可以说是当代经济学的焦点之一,金融范畴中受到关注的一个重要问题就是投资组合管理。近年来关于指数化方面的投资发展迅速,指数跟踪技术的目的是使投资者在精准复制标的指数市场表现的基础上,获得较高利益。
完全复制和非完全复制为指数跟踪中最具代表性的两种方法。跟踪股票组合的最终目的为取得与标的指数大体相一致的收益;在评定实际的指数跟踪效果中,跟踪股票组合收益和标的指数收益之间的偏离程度可以设定为跟踪股票组合优劣的重要指标之一。该偏离程度可以用跟踪误差来衡量。
Markowitz(1952)[1]提出的均值-方差理论,在一定意义上可以看做是近代金融学的开端。但基于金融市场的股票收益率之间强共线性的原因,该理论构建的组合并不稳定;且在构建股票组合时没有全面地考虑到交易成本的影响,使得在数据的实际研究中很容易产生空头头寸,这一缺点使得该方法并不适用于我国的实际金融市场。针对上述问题,本文找到一种有效的解决方法,即选择股票构建组合进行投资,应用高维变量选择方法进行股票选择。
高维变量选择不仅广泛应用于生物医学,而且在指数跟踪的研究领域也被大量引入。传统的子集选择法是较为经典的高维变量选择方法,但该方法受实际数据的局限,且不稳定。较子集选择法更稳定的方法是岭回归,但岭回归只能压缩系数,不能将变量系数收缩到零达到完全剔除变量的目的,即达不到变量挑选的效果。高维变量选择的流行方法为Lasso算法,它不仅克服了上述子集选择和岭回归的各种缺点,而且实现了变量选择和参数估计同时进行,所以被优先使用在指数跟踪领域的变量选择中。
针对数量庞大的金融资产的有效选择,本文将统计中自适应Lasso选元方法应用到股票选择中,并且从实际情况出发,针对股票的特征加入非负约束,应用非负自适应Lasso变量选择方法,选取一定数量的股票进行组合构建最终达到良好的指数跟踪效果,更好地平衡因数量过多产生的高交易成本和因数量较少出现的大跟踪误差。
在指数跟踪问题的相关研究中,Larsen等(1998)[2]考虑股票数量及变更组合时机对于股票组合的影响,Bamberg等(2000)[3]考虑线性回归方法在最优组合选择方面的应用,Zorin等(2002)[4]考虑指数跟踪的神经网络方法。李俭富等(2006)[5]在证券价格时间序列基础上提出协整优化的指数跟踪算法。但这些方法存在模拟复杂,计算耗时长,没有充分利用历史数和据信息等不足。在前人研究的基础上,刘睿智等(2012)[6]将Lasso变量选择方法应用到投资组合研究中,并取得很好的效果。
本文主要基于自适应Lasso的变量选择视角选取适当的模拟算法进行具体的股票选择,并将深沪300两年的历史数据作为实证进行具体分析。研究内容包括自适应Lasso方法在股票选择中的理论依据和实际效果两个方面,关于股票选择的跟踪效果也进行了具体分析和实证对比。结果表明,自适应Lasso在股票选择中有很好的效果。
1 基于自适应Lasso变量选择方法的资产选择
1.1 指数跟踪与变量选择方法
在传统的投资组合领域中,资产池固定,无需重新选择资产直接进行配置;而在现代金融投资组合领域,市场中资产数目众多,数据量庞大,上述均值-方差模型在使用传统最小二乘回归方法进行股票选择时还存在着一些缺陷:(1)资产收益之间的共线性问题,协变量之间的共线性问题是股票的相互关联性在具体模型中的反映;(2)欠缺对交易费用的考虑,交易费用直接影响投资收益率,它是股票投资的重要因素;(3)各项资产的收益率或波动率对于权重结果的影响较大,造成结果不稳定;(4)协方差矩阵估计困难,甚至出现因选取样本量较少而导致矩阵X不可逆的情况,估计累计误差巨大等一系列问题使得普通最小二乘法有误。
针对普通最小二乘回归选股方法产生的一系列问题,一个较为直接的解决办法就是投资者需要对市场内的资产进行初步筛选。股票市场的股票非常丰富,需要合理地选择成分股的子集,即部分复制,然后进行指数跟踪,使得跟踪误差最小化,以期望取得较好效果。以变量选择方法为基本思想的股票选择可以有效地解决上述问题。关于从大样本数据中筛选有效信息的问题,Breiman(1995)[7]指出,传统的最优子集变量选择方法计算量庞大且结果不稳定,即变量选择结果对于实际操作中数据集的变动十分敏感。所以本文采用现代研究中较为流行的基于系数收缩的最优子集变量选择方法。
关于系数收缩的最优子集变量选择的具体方法,Tibshirani(1996)[8]提出Lasso回归算法,该方法的本质是在回归系数的绝对值之和小于一个常数的约束条件下,最小化残差平方和。Lasso方法不但能够有效地解决高维数据问题,而且能够得到完全的稀疏模型,它解决了之前最小二乘法的不稳定性和方差大的问题。Lasso方法优于古典的变量选择方法的一个具体表现为它是一个连续的过程,从而产生稳定的结果;同时,它的计算量小,易于实现。所以该方法在筛选变量方面得到广泛应用,Wu等(2014)[9]将该方法应用于经济领域的指数跟踪并且在实证分析中取得较好的效果。
然而Lasso方法本身存在着一些缺陷:当处理共线性问题时,Lasso的选择效果减弱;它的系数估计为有偏估计;只有在一定正则条件下才满足变量选择一致。针对上述问题,Zou(2006)[10]对其进行改进,在l1的惩罚系数前加自适应权重,使改进后的方法具有了“神谕”性质。自适应Lasso为凸优化问题,权重与数据相关,选取明确,它既保持了Lasso变量选择方法的诸多优点,又能够有效地减少具体操作是在使投资组合的变动趋势与标的指数大体相一致的基础上,达到减小跟踪误差,取得与标的指数收益率相同的目的。指数跟踪是指数基金的核心,对于指数跟踪模型,设 X=(x1,...,xp)是 p只股票多头头寸,y为1单位指数的多头头寸,则-y为1单位指数的空头头寸。由Markowitz均值-方差理论,所建立的模型是在保持组合收益率一定的情况下选择系数使得组合方差极小化,且该组合头寸的期望收益率为零,则实质上是回归模型[6],表示为模型参数估计的有偏性,所以该优化方法受到广泛关注且应用到实际变量选择的诸多方面。
本文基于Lasso变量选择方法将改进后的自适应Lasso方法应用到股票投资组合的初选中,并且考虑到股票的以下两个特点,给系数估计加上非负约束条件:(1)股票中成分股的份额总是为正;(2)国家对于股市的卖空现象加强监督,以稳定股票市场。将其称为非负自适应Lasso变量选择方法。
本文使用部分吸收来进行指数跟踪,即选择成分股的一个小子集,仅选择30只成分股,使跟踪误差最小化。不同的股票选择方法会产生不同的选取结果,从而产生不同的跟踪效果。本文发现,选择权重最大的30只股票和Lasso方法选择30只股票产生的跟踪误差均大于本文中统计方法选择的结果。
1.2 基于自适应Lasso方法的资产选择
非负自适应Lasso的系数估计为:
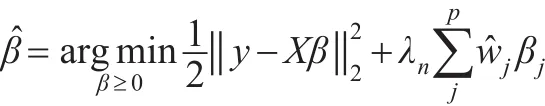
自适应Lasso模型是在Lasso算法的基础上改进而成,其系数估计由回归拟合的优良性和惩罚两部分构成。其中,惩罚项通过把较小的系数向0完全收缩达到剔除对应协变量的效果。自适应Lasso方法的一个突出优点是,通过调节权重系数,使得不同参数相应的惩罚不同,初始估计取倒数使得初始参数估计值较大的变量对应较小的权重系数和较小的惩罚,初始估计值较小的变量对应较大的权重系数和较大的惩罚。当某个自变量的初始估计值较大时,该自变量在自适应Lasso中权重系数就较小,即对应的惩罚就小,这样就保证了其以较高概率进入模型,即更容易被选择。
1.3 自适应Lasso估计算法
许多为Lasso设计的成熟算法,如最小角回归算法lars和glmnet,适当修改之后可以用来解决自适应Lasso的问题,但其算法并不简单。考虑到自适应Lasso实质是二次规划问题,且在本文的实际情况中有非负约束条件,为了计算的快速与简单,本文运用类似梯度下降法的迭代算法——乘性更新。该方法主要用来解决具有非负约束条件的二次规划问题[11]:
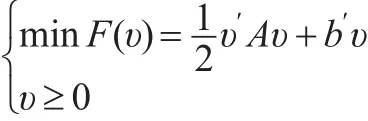
其中,υ=(υ1,...,υn)′为 n 维列向量,υ′是 υ的转置,A∈Rn×n是对称正定矩阵。乘性更新是一种特殊的迭代算法,设:
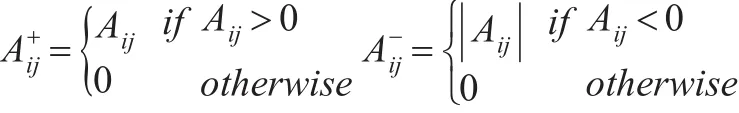
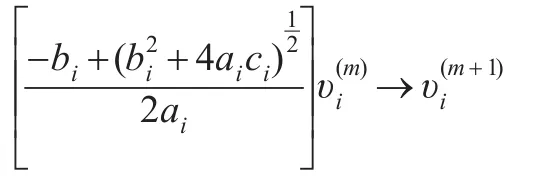
当给定一个非负调节参数λn时,非负自适应Lasso是以下二次规划问题的解:

迭代算法中相应参数改变为:ai=((X′X)+β)i,ci=((X′X)-β)i,bi=(λnW-X′y)i,然后就可以用非负自适应Lasso估计出β。迭代过程中涉及一个调节参数λn,利用类似对分法的方式选择λn:分别选取较大的λn和较小的λn估计参数;然后调节λn使得选出的成分股恰好为30只[12]。
2 实证分析
2.1 数据选取和模型说明
本文使用的数据集包括深沪300指数的股票价格和深沪300指数的300只成分股的股票价格。样本的时间区间分为两部分:2011年1月1日至2012年12月31日和2015年1月1日至2015年12月31日。其中,2015年数据用于第一部分模型拟合与预测,2011—2012年数据用于指数跟踪效果分析。深沪300成份股每年调整两次,但成分的变化基本不大,所以本文以收集数据截止日期的成份股为准,进入成份股之前的收益率视为零,被剔除的成份股将不再计入数据。
对于股票价格Pt,定义日收益率为t=1,...,T。协变量 xi,t=ri,t,i=1,...,300 表示第 i支成分股的收益率,yt=r0,t表示深沪300指数收益率,则模型表示为:

其中,βi是第i个成分股的权重,εt是随机误差项。本文的目的就是应用非负自适应Lasso统计模型来估计系数β。
指数跟踪效果分析中,部分吸收的偏差用跟踪误差(TE)来度量,定义为:
其中,mean(err)是 errt的均值,t=1,...,T ,errt=yt-是 yt的拟合值或者预测值。
2.2 模型拟合和预测结果分析
选择2015年的数据进行拟合和预测。1月至10月的数据进行模型拟合及系数估计,11月和12月数据进行预测。通过R程序,自适应Lasso方法选择出的30只成份股,估计出的股票权重系数如表1所示,拟合及预测曲线如图1和图2所示。
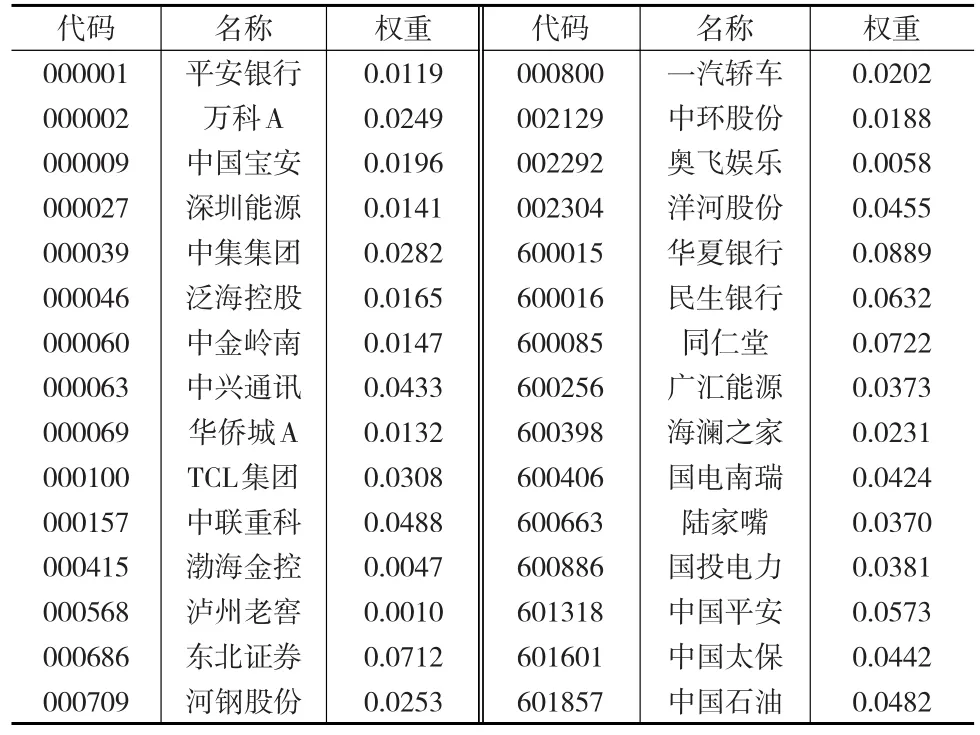
表1 自适应Lasso方法选股权重
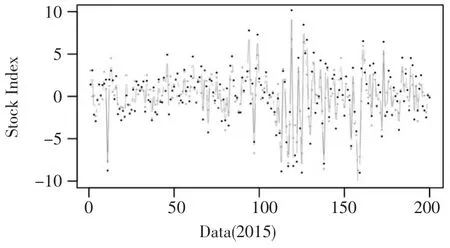
图1 1月至10月数据拟合曲线
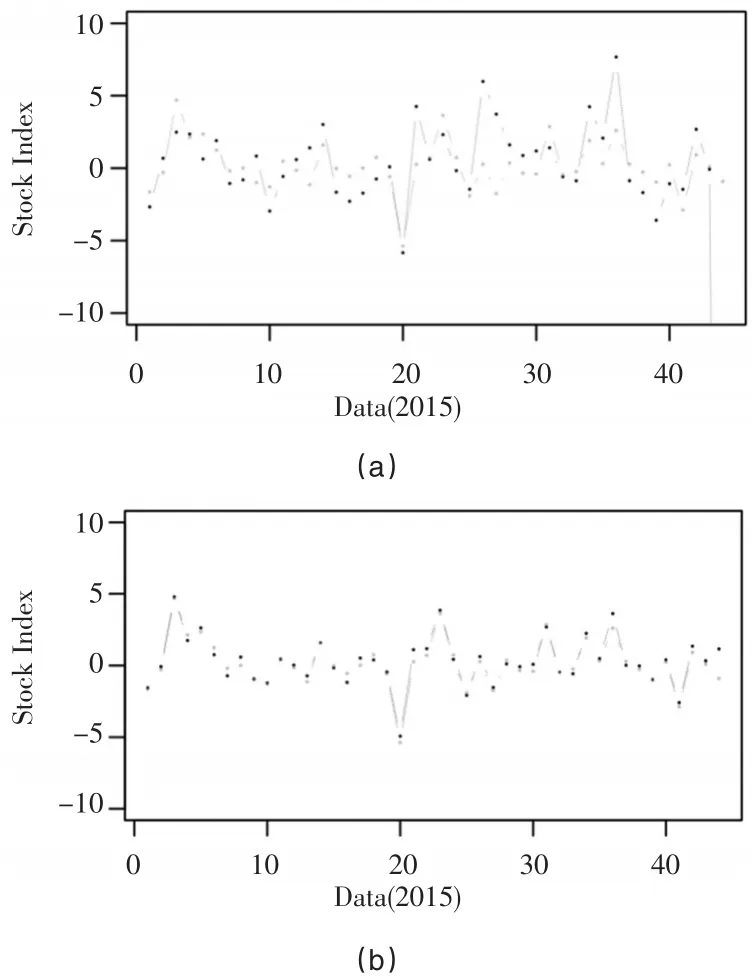
图2 11月和12月数据预测曲线
表1结果显示,本文提出的自适应Lasso算法选择出的30只股票跟踪组合中,有3只股票的权重占到6%以上,有3只股票的权重达不到1%,有24只股票的权重均在1%~6%之间,与Lasso选择方法的结果相比较,该方法的权重分布更为均匀[6]。权重系数分布的趋势越集中,越不利于指数跟踪,受大权重股的影响跟踪效果变差,从这个角度分析,自适应Lasso方法较优。
表1中选择出的30只成分股拟合曲线如图1所示,图中空心圆形为深沪300股票的日收益率实际值,实心圆形为预测值。虚线和实线曲线的走势相同,偏离程度较小,除拐点外,两条曲线在一定程度上几乎重合,说明该时间段内目标指数的跟踪效果良好。
图2(a)中,曲线为自适应Lasso选择变量并同时预测参数的拟合结果;图2(b)中,右边曲线为自适应Lasso选择变量之后进行非负线性回归的拟合结果,两条曲线几乎重合。图2中结果对比显示,第二种方法的性能明显优化。在今后的其他模拟实验中,不妨用二阶段方法来进行系数估计,即变量选择和系数估计分两部分进行,其模型性能会有所提高。
2.3 跟踪效果分析
选取2011—2012年的数据对自适应Lasso的变量选择方法在指数跟踪方面的应用效果进行详细分析。本文用一个时间窗口划分数据集:前六个月的数据用于建模,随后一个月的数据进行预测,则共有18个拟合样本,18个预测样本。由表1中选股结果可以看出,基于自适应Lasso方法选出的股票并不是对指数具有很大贡献的超大盘股,这并不符合传统认识。以Lasso选股方法,自适应Lasso选股结果与具有代表性的大权重股票组合基于跟踪误差进行对比分析,分别计算拟合跟踪误差和预测跟踪误差,其中前6个样本(2011年)的指数跟踪结果如表2所示。
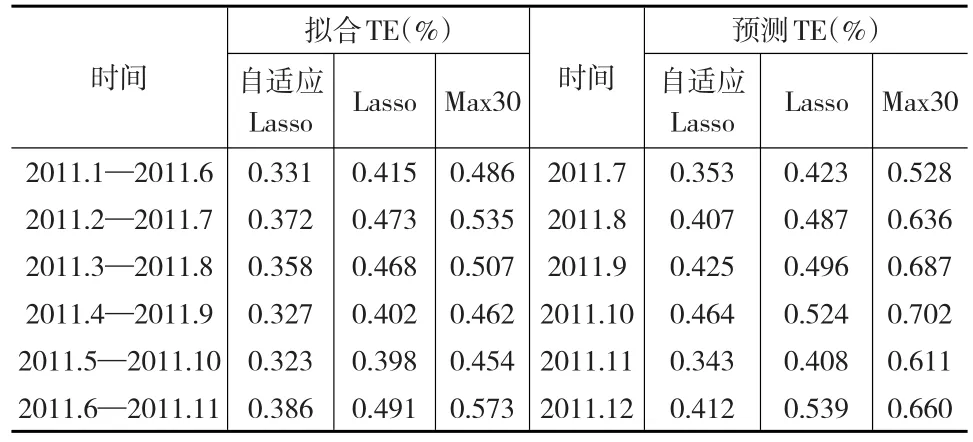
表2 2011年数据跟踪效果分析,拟合和预测跟踪误差(TE)
通过表2可以看出,三种方法选择出的30只股票组合跟踪误差均未超过2%,则意味着指数跟踪差异并不显著,指数跟踪风险小。综合考虑上述三种方法,自适应Lasso方法在指数跟踪应用中具有明显优势。首先在权重系数方面,自适应Lasso方法得到的权重系数分布均匀,并没有明显的集中趋势,这使得在实际操作中可以有效规避非系统性风险。其次在跟踪误差方面,其数值都在0.6%以内,跟踪效果较好。
3 结论
本文通过变量选择的基本观点对股票选择进行了一些探讨,介绍了非负自适应Lasso选股方法在指数跟踪实际应用中的优点,即保留Lasso算法的稀疏性从而达到选择股票的目的,同时使组合中产生非空头寸,减小模型的不稳定性和跟误差,对交易费用的惩罚更加合理。实证结果表明:(1)自适应Lasso方法在股票选择应用方面具有很好的效果。(2)自适应Lasso方法得出的权重分布相对均匀。(3)金融角度的观点认为,小规模证券由于数据相对缺乏,不能有效地跟踪模拟指数的走势。但本文自适应Lasso算法构建的30只股票中,系数的权重分布相对均匀,且考虑到交易费用低。所以对于小型投资者来说,在证券市场稳定的基础上,该选股方法值得一试。
本文关于指数跟踪问题的些研究还存在以下不足:(1)自适应Lasso方法得出的成分股权重系数之和不为1,不满足指数跟踪问题的实际要求。可以应用归一化方法(各股权重除以成分股权重之和)来进行调整,但这种方法并没有金融角度的理论支持。(2)指数跟踪的最终目的是将研究的方法应用到金融方向的实际问题中,但本文只做了初步的理论研究,并没有展开实际操作。后续工作可以将其选股方法应用于更现实的实际问题中。
对于金融系统的其他应用,可以试着将本文中的变量选择方法应用于金融风控的信用评估阶段,构建评分卡模型,改变传统方法中的变量选择过程,尽量解决平台间数据稀疏的问题。自适应Lasso不仅在实践上具有较好的实用性,在理论上也具有优良的性质,相信它会在未来的金融领域中发挥更大的作用。
猜你喜欢
心理学报(2022年5期)2022-05-16
小学生学习指导(高年级)(2021年4期)2021-04-29
当代陕西(2020年17期)2020-10-28
河北理科教学研究(2020年2期)2020-09-11
人大建设(2018年5期)2018-08-16
股市动态分析(2016年23期)2016-12-27
股市动态分析(2016年22期)2016-12-27
股市动态分析(2016年7期)2016-09-29
股市动态分析(2016年4期)2016-09-29
新高考·高二数学(2014年7期)2014-09-18
