
一种支持大页的层次化DRAM/NVM混合内存系统
2018-09-21 03:26刘海坤王孝远廖小飞
计算机研究与发展 2018年9期
陈 吉 刘海坤 王孝远 张 宇 廖小飞 金 海
(华中科技大学计算机科学与技术学院 武汉 430074) (服务计算技术与系统教育部重点实验室(华中科技大学) 武汉 430074) (集群与网格计算湖北省重点实验室(华中科技大学) 武汉 430074) (湖北省大数据技术与系统工程实验室(华中科技大学) 武汉 430074) (hkliu@hust.edu.cn)
随着计算机软硬件技术的飞速发展,传统的动态随机访问存储器(dynamic random access memory, DRAM)因其存储密度小、可扩展性有限、刷新和闲置功耗大等缺点已经无法满足应用越来越大的内存需求.诸如相变存储器(phase change memory, PCM)、磁性随机存储器(magnetic random access memory, MRAM)等非易失性存储器(non-volatile memory, NVM)具有可随机访问、存储密度大、无静态功耗等优点,但也存在着访问时延较高、写次数有限、写功耗大等缺点,因此直接使用NVM替代DRAM目前尚不可行.学术界提出使用DRAM/NVM混合内存架构,通过混合使用小容量DRAM和大容量NVM,将DRAM作为NVM内存的缓存或者将DRAM和NVM统一编址并通过页迁移将频繁访问的数据放置于DRAM中来克服NVM高访问时延缺陷的方式,提升系统性能.DRAM/NVM混合内存系统的设计与优化成为了学术界的研究热点.
随着非易失性内存的引入,计算机系统的内存容量固然得到显著提升,但是也给系统设计带来了新的问题:内存地址空间增大、虚实地址转化的开销随之增大、虚实地址转换将成为新的系统瓶颈[1].当下主流的处理器都设计有加速虚实地址转换的特殊硬件-旁路转换缓冲(translation lookaside buffer, TLB).TLB的发展受到了其尺寸、查询延迟及能耗开销等因素的限制,因此近年来TLB的容量增加相当缓慢.TLB的查找位于访存的关键路径上,对系统性能有着至关重要的影响.当操作系统运行大内存占用的应用程序并采用默认大小为4 KB的页面时,操作系统不仅需要较大的内存空间来管理那些页表项,而且应用程序运行过程中还会产生较多的TLB 缺失和页表查询操作,从而大大影响系统的性能.TLB硬件的容量与快速增长的内存地址空间之间出现了不可调和的矛盾[2-5].
操作系统中内存分配的单元是一个个的物理页框,通常是4 KB大小.大页是由2n个物理地址对齐且连续的4 KB页面构成,可以容纳更多的数据.在使用2 MB大页的系统中,一个TLB表项可以映射的快速地址转换范围是2 MB,在TLB表项数一样的情况下,TLB映射的地址范围是使用4 KB页面时的512倍.大页技术可以使一个TLB表项映射一个很大的物理内存页,从而在不增加TLB硬件容量的情况下显著调提高TLB的地址覆盖范围,降低查找TLB的缺失率.当操作系统以 2 MB 甚至更大作为分页的单位时,将会大大减少 TLB 缺失数,显著提高应用程序的性能,对于存储容量越来越大的混合内存系统更是如此.
在混合内存系统中,使用大页存在着新的挑战.譬如,在平行架构的混合内存中,NVM大页内部的数据的访问往往是不均匀的,部分数据会被频繁访问,而另一部分数据则很少被访问[6].对于热的那部分数据,应该迁移到DRAM中来提高访问性能.但如果以大页为粒度进行页面迁移,在迁移了热数据的同时,也将大量的冷数据迁移到了DRAM中,这就占用了DRAM空间,还产生了不必要的迁移开销和带宽占用.但是细粒度的迁移需要复杂的硬件设计或者更改操作系统的页表、TLB设计等.在层次结构的混合内存中,DRAM和NVM之间通常采用细粒度的数据交换方式,层次结构的混合内存系统可以将NVM大页中的热数据以细粒度的方式加载到DRAM中,更适合在层次结构的混合内存上使用大页,因此本文将着重于层次化混合内存上的大页支持.在层次结构的混合内存中,查找DRAM缓存的元数据查找和存储开销成为了新的挑战性问题,使得支持较大容量DRAM缓存比较困难.
针对上述问题,我们设计了一个在层次化混合内存上支持大页和大容量DRAM缓存的系统(supporting both superpage and large-capacity DRAM cache, SSLDC).SSLDC系统在DRAM和NVM之间使用直接映射的方式,同时在DRAM缓存中使用4 KB的粗粒度数据块进行管理,从而将元数据大小降低到能放入片上高速缓存中.为降低DRAM/NVM之间的粗粒度数据交换对内存带宽造成的压力,提出了DRAM缓存数据过滤机制,只将访问频繁的热数据缓存到DRAM中,避免将缓存收益不高的冷数据拷贝到DRAM中,减少了混合内存间的数据交换,从而减轻了内存带宽的占用.还提出了一个基于内存实时信息的动态热度阈值调整策略,周期性的动态调整热度阈值,以灵活适应应用访存特征的变化.实验结果表明,SSLDC系统与使用大页的纯NVM内存系统和CHOP缓存策略系统相比分别平均有69.9%和15.2%的性能提升,并且与使用大页的纯DRAM内存系统相比平均只有8.8%的性能差距.
1 背景介绍
本节首先介绍2种主流的混合内存架构,并分析其各自的特点;然后介绍地址转换过程中存在的TLB性能瓶颈,进而介绍大页在降低TLB缺失率方面的有效性以及在混合内存中支持大页使用的必要性.
1.1 DRAMNVM混合内存技术
由于PCM等NVM介质具有低延迟、低能耗、非易失性、高密度的特点,被认为是DRAM内存的有效补充或者替代品.但NVM的读延迟是DRAM读延迟的几倍,NVM写延迟更是超出DRAM一个数量级,且NVM写操作的能耗是DRAM的几倍.NVM内存单元写次数有限,大概只能承受108~1012次的写操作,而DRAM可以承受大于1015次写操作[7],NVM写耐受力不足DRAM的1/1 000,NVM存储单元非常容易因为频繁的写操作而被写坏,因此NVM不能完全取代DRAM的位置.为了充分利用NVM容量大和DRAM读写性能好的优势,并且最大限度地避免2种存储介质的缺陷,一般把NVM和DRAM结合起来构造混合内存系统.目前主要有平行和层次2种混合内存架构.
1) 层次化混合内存架构(层次结构).如图1(a)所示,层次结构的混合内存系统中,DRAM等快速存储器作为NVM的缓存[8-9],由于缓存操作时间开销较小,因此相较于统一编址结构的平行架构混合内存系统,层次结构的混合内存系统能获取更多的性能提升.传统的层次化混合内存系统用硬件管理DRAM缓存,DRAM的组织形式类似于传统的片上高速缓存,DRAM缓存对操作系统透明.最后一级片上缓存(last level cache, LLC)缺失后,首先通过DRAM内存控制器中的硬件电路查找访问地址对应的标识(tag),判断访问是否在DRAM缓存中命中,然后再进行数据访问,由此可看出,层次化混合内存系统在DRAM缓存缺失的情况下的访存时延比较长.此外,硬件管理的DRAM缓存一般采用Demand-Based数据预取机制[10],即DRAM缓存中数据缺失后,必须将其对应的NVM数据块取到DRAM中,该数据块才能被访问,在大数据环境下,很多应用局部性很差,这种数据预取机制会加剧缓存污染问题.
2) 统一编址混合内存架构(平行结构).如图1(b)所示,DRAM与NVM统一编址,2种内存都作为主存使用,并由操作系统进行统一的管理和分配[11-13].为了充分发挥NVM与DRAM的优势,并且尽可能地避免NVM的缺陷给系统带来的性能影响,现有研究普遍使用热页迁移这种优化策略,即将频繁访问和频繁写的NVM页面迁移到DRAM中.为了保证数据迁移的正确性,迁移操作一般分为2个步骤串行执行:①读取源和目标页框的内容到缓冲区中;②将缓冲区数据写入到目标地址中.因此一次页迁移操作会产生4次页拷贝,由于读取和写入2个阶段是串行执行的,迁移操作的时间开销比较大.

Fig.1 Hybrid memory architectures图1 混合内存架构
由以上分析可以发现层次结构和平行结构适合不同的应用特征.层次化结构更适合局部性良好的应用,由于大部分访存都在DRAM中命中,可以极大地提高访存性能.对于访存局部性一般的应用,由于所有的访存必须经过DRAM,将导致大量的缓存换入换出,甚至可能导致性能差于纯NVM主存.在平行结构中,由软件及硬件监测应用的访存特征、页面的访问信息,并据此进行页面的分配、回收与迁移,可以实现更大的灵活性,但由于监测和页面迁移的原因,会带来一定的系统开销,尤其是在页面粒度较大的情况下,迁移一个页面将带来较为严重的性能开销.
1.2 大页技术
当处理器要访问某个内存地址时,不是直接在页表中查找.虚拟地址首先被送到TLB中查找,若TLB命中,则得到物理地址;否则,称为TLB缺失,将通过操作系统的TLB缺失处理程序查找页表来获取物理地址,并进行TLB的更新.在X86架构中,共有4级页表,意味着一次TLB缺失,会增加4次对内存的访问.而内存的访问速度相比于处理器慢了几个数量级,TLB缺失处理会增加地址转换的开销,使系统性能下降.尤其是当运行科学计算、大数据等内存占用量巨大的应用时,TLB缺失的情况会变得更加严峻.一些相关研究指出,地址转换开销占整个系统开销的10%~15%[14-15],Muck等人指出,在某些场景下TLB的缺失处理时间占应用总执行时间的40%以上[16],在虚拟化场景下地址转换开销占整体开销甚至高达89%[17],大内存工作集应用中地址转换开销占整体开销高达50%[18].由此可见,TLB缺失会严重影响系统的整体性能.因此,必须采取适当的手段降低TLB缺失率,降低地址转换的开销,从而提高系统性能.
降低TLB缺失率的办法主要有2种:1)增大TLB的表项数目.由于TLB在系统访存的关键路径上,增加TLB表项数目会增加系统的访问时延以及造成更高的能耗开销,并且少量地增加TLB表项不能解决TLB的性能瓶颈问题.2)使用大页.大页是由2n个基本页(比如4 KB页面)组成连续且自然对齐的页面.通过使用较大的页面粒度,增加每个TLB表项所能寻址的地址范围,从而显著的降低TLB缺失率.比如相较于使用4 KB页面粒度,2 MB的页面粒度的系统中,一个TLB表项可以覆盖2 MB页面的地址范围,从而使得一个TLB表项可映射的地址范围提升(2 048 KB)/(4 KB)=512倍,进而显著增加TLB命中率,同时实现在未增加TLB硬件开销的情况下,显著地降低了虚实地址转化开销.
Korn等人通过运行SPEC CPU2006基准得出,使用64 KB和16 MB的大页,分别提高系统性能高达46.9%和50.9%[18].Zhang等人指出,对于Linpack测试基准中的矩阵乘法,使用16 MB的大页相比于使用16 KB的页面,TLB缺失数量可减少99%以上[19].使用大页被认为是降低TLB缺失率最好的办法.
对于大内存应用,如果使用传统的4 KB细粒度页面,会使TLB缺失率剧增,导致系统性能严重下降.因此在混合内存系统中解决TLB 性能瓶颈问题显得尤为迫切,提供大页支持十分必要.
2 在混合内存中使用大页的挑战
下面将分2部分介绍在平行结构和层次结构混合内存中使用大页所面临的挑战.
2.1 平行结构混合内存系统中使用大页的挑战
在平行结构的混合内存架构中,操作系统需要提供一定的策略来将NVM中访问热度高的页面迁移到DRAM中,将DRAM中热度低的页面交换到NVM中,页面迁移涉及到4次页拷贝,开销很大.为了防止过多的数据迁移,文献[11]和文献[20]中提到了使用硬件方法的细粒度热数据迁移策略,但对硬件的改动较多,硬件复杂度高,实施难度大.硬件都是针对DRAM/NVM容量比例设计的,可扩展性差.大页内部数据读写热度往往不均,在DRAM和NVM间以大页为粒度进行热数据迁移,会在迁移了热数据的同时也迁移了大量的冷数据,造成极大地带宽浪费.软件支持的细粒度热数据迁移,又需要操作系统支持多粒度页面,迁移时需要更改页表、TLB表项,进行clflush, tlb shootdown等操作,系统开销非常大,DRAM和NVM的内存管理也会变得很复杂.
2.2 层次结构混合内存系统中使用大页的挑战
而在层次化的混合内存架构中,硬件管理的DRAM缓存支持以较小的粒度加载NVM主存中的数据.比如在纯DRAM内存的架构上,LLC中的cache line的粒度是64 B,而DRAM主存的页面粒度是4 KB, 当LLC缺失时,以相对于DRAM页面较小的cache line粒度来加载数据.层次化混合内存结构中NVM和DRAM之间的数据交换不需要对页表、TLB等进行操作,相较于平行结构开销更小.层次化的混合内存可以很好地支持大页的使用,便于实现热度感知的细粒度数据交换,不会存在平行结构混合内存架构中的困难.因此在更适合在层次结构的混合内存上提供大页支持.
然而,层次结构的混合内存中存在着元数据查找和存储开销大的挑战.图2中展示的是DRAM查找元数据命中时的访存开销.如图2(a)所示,当访问DRAM缓存时,首先查找元数据,确定所访问的数据是不是在DRAM中.这个串行化的查找过程,在访存的关键路径上.如果将元数据存放在DRAM中,相当于每次访存都增加了一次对DRAM内存的访问,这将严重影响系统的性能.
为了加速元数据的查找过程,如图2(b)所示,一般将元数据存储在一块高速的静态随机存储器(static random access memory, SRAM)中,以减少元数据查找对系统性能的不良影响.对于片上cache,因其容量小、所需元数据很少,不存在元数据空间开销大的问题.但当前计算机中DRAM一般有着较大的容量,对于4 GB的DRAM缓存,若使用64 B粒度的数据块,元数据的存储开销将达到384 MB,远远超过当前的LLC大小,放置在SRAM中是不现实的.
对于上述问题,Loh和Hill在组相联的DRAM缓存中采用64 B细粒度cacheline[21], 如图3所示,他们修改了硬件结构,将元数据和数据放置在同一个bank行中,每一个bank行里存放着一组cache line和对应的元数据.每次访存请求到来时,根据请求中的地址得到组相联映射的组号,查找元数据时会把组号对应的bank行加载到bank行缓冲区(bankrow buffer)中.如图2(c)所示,如果DRAM命中,则数据此时已经在bank行缓冲区中了,能快速地访问数据.
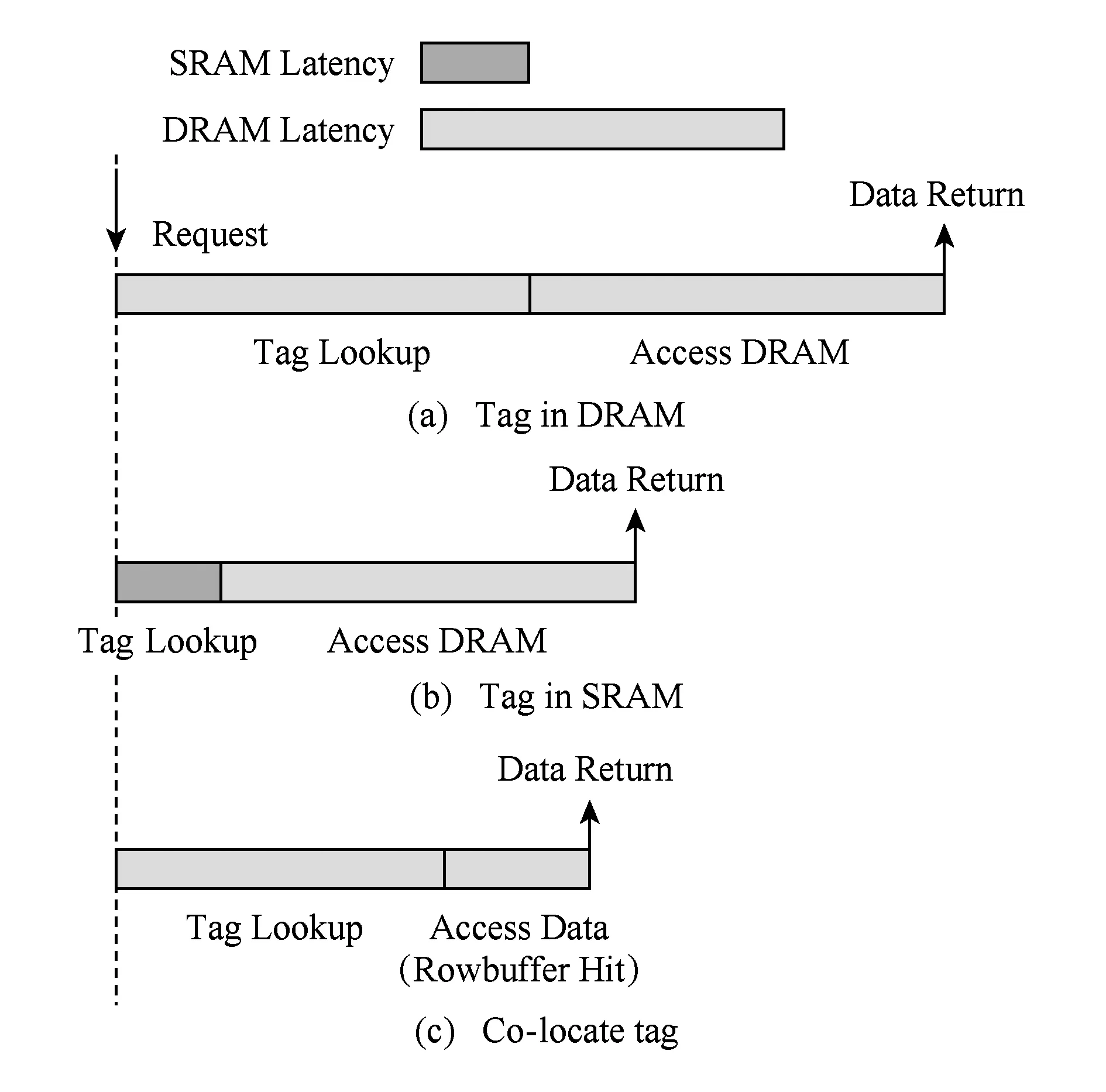
Fig.2 Access cost when DRAM hit图2 DRAM缓存命中时的访问开销

Fig.3 Metadata and data in the same bank row图3 元数据和数据放置在同一bank row示意图
图3中的策略充分利用了内存的行缓冲区(row buffer)命中,有效地缩短了DRAM命中时的串行查找开销,甚至优于将元数据放置在SRAM中的情况.但是在DRAM缓存缺失时会产生4次访存:1)访问存放在DRAM中的元数据,判断所访问数据是否在DRAM缓存中;2)DRAM缺失后,需要访问NVM读取数据;3)将NVM上的数据写到DRAM缓存中;4)访问DRAM缓存,进行相应的访存操作.当应用的局部性不佳导致DRAM命中率很低时,该策略由于DRAM缺失时开销较大,将导致严重的性能下降.同时对内存硬件结构有修改,可扩展性差,大约有9%的DRAM用来存放元数据,减少了DRAM实际可用的容量,会加剧DRAM的缺失问题.
Jiang等人提出了缓存热页(caching hot page, CHOP)的策略[22].在DRAM缓存中采用4 KB的粗粒度管理方式,有效地减小了元数据存储开销,将元数据放置在SRAM中加速元数据的查找过程.使用4 KB的DRAM 缓存粒度,每次DRAM缓存缺失时,都会从下层存储器中加载一个4 KB的页面.根据局部性原理,DRAM缓存采用更大的页面管理粒度,可以有效地提高DRAM命中率,但是粗粒度的数据交换会增加对内存带宽的压力.Jiang等人通过DRAM管理粒度敏感性实验得到,当DRAM缓存行(DRAM cache line)增加到2 KB时,内存带宽占用接近100%,这是严重的性能瓶颈.因此提出了cache过滤机制,加入一个硬件的过滤缓存(filter cache)结构动态的监测主存中页面的热度.当DRAM缺失时,只有访问频度超过一定阈值的热页,才能被加载到DRAM缓存中.避免了将热度低的页面加载到DRAM缓存中造成的页面拷贝开销和带宽占用,也防止了冷数据加载到DRAM中浪费DRAM的空间.
但CHOP缓存机制中的DRAM缓存只有128 MB,因此需要198 KB的空间存储元数据.当今计算机里内存大小一般远大于128 MB.对于4 GB的DRAM缓存,需要6 MB的SRAM空间存储元数据,会造成较大的硬件开销.因此,CHOP缓存机制不能支持较大的DRAM缓存,系统的可扩展性差.同时,该策略中的热页阈值是通过离线的分析访存轨迹(trace)得到的,找出贡献80%访问次数的页面,认为这些页面热页,并将这些页面中访问最少的次数设置为阈值.针对不同应用都需要离线运行一遍,然后通过分析获得静态阈值.由于不同应用程序的访存特性差异,他们的阈值都不相同.这种静态的阈值设置可能过高,会增加对NVM的访存操作;而且这种静态阈值的设置只考虑到了热度信息,没有考虑到实时带宽占用的影响,阈值设置方法可操作性差,不适用于多进程等多种应用场景,自适应性较差,灵活性低.
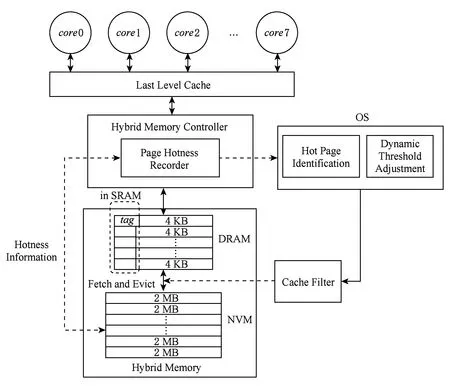
Fig.4 Architecture and function modules图4 系统架构与功能模块
3 支持大页和大容量缓存的混合内存系统
针对第2节提到的挑战,本文设计了一个支持大页和大容量缓存的层次化混合内存系统SSLDC.下面首先介绍系统的几个模块是如何工作的;然后介绍DRAM缓存的管理,包括使用粗粒度的DRAM数据块、DRAM缓存与NVM主存间使用直接映射相联;最后介绍缓存数据操作的过滤机制,包括轻量级的热度信息监测、动态的热度阈值调整.
3.1 系统架构与功能模块
针对在混合内存中使用大页时存在的诸多挑战,我们设计了一个在层次化结构的混合内存上支持大页和大容量缓存的系统,针对DRAM缓存的元数据存储和查询延迟的问题,采用4 KB粗粒度的DRAM管理方式,在DRAM缓存和NVM主存之间采用直接映射,从而进一步精简了DRAM缓存标志的结构,减小了元数据的存储压力,解决了文献[22]中的CHOP策略无法支持大容量DRAM、可扩展性差的问题.
图4所示的是SSLDC系统的架构和功能模块整体设计图.DRAM作为NVM主存的缓存使用,可以看作是L4C (level 4 cache),被硬件直接管理,对操作系统透明.在DRAM中采用4 KB的粗粒度管理方式,与NVM主存之间采用直接映射的方式相联.在NVM主存中使用2 MB的大页,以减少TLB缺失率,加快地址转换的速度.提出一个对DRAM缓存数据操作的过滤机制,只有访问热度高的4 KB NVM数据块才能在DRAM缺失时被加载到DRAM中.热度监测机制周期性的监测NVM上的访问信息,包括以4 KB为粒度的数据块的读写热度、每个监测周期内DRAM命中率、DRAM和NVM之间交换数据对内存带宽的占用情况等.在内存控制器中开辟一小块高速SRAM来记录NVM中最近最频繁访问的4 KB数据块的热度信息,并综合实时的DRAM命中率、带宽占用情况、DRAM缓存使用情况,周期性地对热度阈值进行调整.
3.2 DRAM缓存的管理
在整个访存流程中,首先查找DRAM缓存的元数据来确定所访问的数据是否在DRAM缓存中.为了加速元数据的查找过程,本文选择将元数据存储在高速的SRAM中.在层次化结构中,显然DRAM缓存越大,就能存放更多的数据,DRAM命中率也会更高,从而有更好的性能.DRAM容量对DRAM命中率的影响将在后续的实验部分讨论.一般每一个DRAM数据块需要6 B的元数据来维护DRAM到NVM的映射关系[21-22].如果DRAM缓存管理采用64 B数据块、组相联映射的方式,对于一块4 GB的DRAM缓存,需要384 MB的空间存储元数据,如此巨大的元数据无法放置在SRAM中.当采用4 KB大小的DRAM 数据块时,存储元数据的空间开销减少到6 MB.但将这么多的元数据放在SRAM中还是存在一定困难.
图5(a)展示的是DRAM缓存和NVM主存之间的组相联映射.在组相联映射中,NVM主存数据块映射到哪一组是固定的,而映射到组内的哪一路是不固定的.硬件比较器并行的将访存地址中的tag和所在组中每一行的tag进行比较.tag需要维护DRAM缓存中数据块在NVM中的具体的地址,因此每个元数据表项需要占用较多的位存储地址信息.
为了减少元数据存储的开销,如图5(b)展示的是直接映射的示意图.在直接映射中,每一个NVM内存数据块都映射在固定的DRAM缓存块上,图5(b)中所示的DRAM与NVM的容量比是1∶4.直接映射的元数据tag不需要记录数据块对应的NVM主存的地址,只需要记录所对应数据在NVM主存上的区号.在图5(b)中,元数据中的tag只需要2 b保存DRAM缓存数据块在NVM主存中的区号,就足以维护混合内存间的映射.这极大地精简了元数据的结构,对于图5(b)中DRAM与NVM容量比例 1∶4 的配置,每一个DRAM数据块只需要4 b来存储元数据,相较于组相联映射的6 B开销,明显减少.为了提高系统的可扩展能力和内存配置灵活性,我们使用6 b来记录主存上的区号,因此DRAM和NVM的比例可以根据需要灵活配置.使用4 KB粗粒度管理的4 GB DRAM,只需要1 MB的元数据存储开销.精简后的元数据存放在SRAM中,而不造成较大的硬件开销.

Fig.5 Set-associative mapped and direct mapped hybrid memory图5 组相联映射和直接映射的层次化混合内存
使用直接映射,硬件电路简单,容易实现,但存在着命中率低的问题.在LLC和主存的直接映射中,每一块主存数据只能映射在固定的cache空间上,如果两块映射在同一cache空间的主存数据在某时间段内都被频繁访问时会成数据频繁的换入换出,DRAM命中率严重下降.但考虑到,本架构中使用4 GB的大容量DRAM,2个可能发生冲突的主存数据块在物理地址上相隔4 GB的距离,因此在这样的大容量DRAM缓存和NVM主存间使用直接映射的方式,产生缓存数据块替换的概率会下降很多,而且后续提到的DRAM缓存过滤机制也能在一定程度上减少这种频繁的数据交换.在后续实验部分进行的混合内存上映射方式敏感性测试也佐证了这一点.
3.3 DRAM缓存的过滤机制
在访存流程中,查找DRAM发生缺失时,会先从NVM中取数据到DRAM中,然后在DRAM中访问数据.每次DRAM缺失都会造成一次数据的预取,由于本系统中使用4 KB的粗粒度DRAM数据块,因此频繁的取数据操作产生的数据拷贝量会造成严重的带宽压力.文献[22]中指出,如果每一次DRAM缺失,都从NVM主存中加载数据,当DRAM缓存数据粒度是2 KB时,在某些场景下就可能造成100%的带宽占用.因此需要在层次化混合内存系统中加入过滤机制,避免向DRAM缓存中加载热度低的数据块,以降低对内存带宽的占用.
图6展示的是采用DRAM预取过滤机制后的访存流程.CPU发出的访求请求通过地址转换得到物理地址,再到cache中查找.如果cache命中,则直接访问cache上的数据;否则,首先查找DRAM缓存中的元数据.若DRAM命中,则直接访问DRAM上的数据;若DRAM缺失,则查找存放在SRAM上的数据块热度记录表.数据块热度记录表有1 024个表项,存储着当前监测周期内最近最频繁访问的NVM中的4 KB数据块的热度信息.如果所访问的数据块信息不在数据块热度记录表中,则直接访问NVM内存并插入一条新的表项到数据块热度记录表中,这样过滤掉取一个NVM数据块到DRAM中的操作.若所访问的数据块热度信息在数据块热度记录表中,则需要判断其热度是否大于阈值.如果大于阈值,该数据块被鉴定为热数据,被缓存到DRAM中;否则,直接访问NVM,并更新数据块热度信息,该数据块暂时不会被缓存到DRAM中.
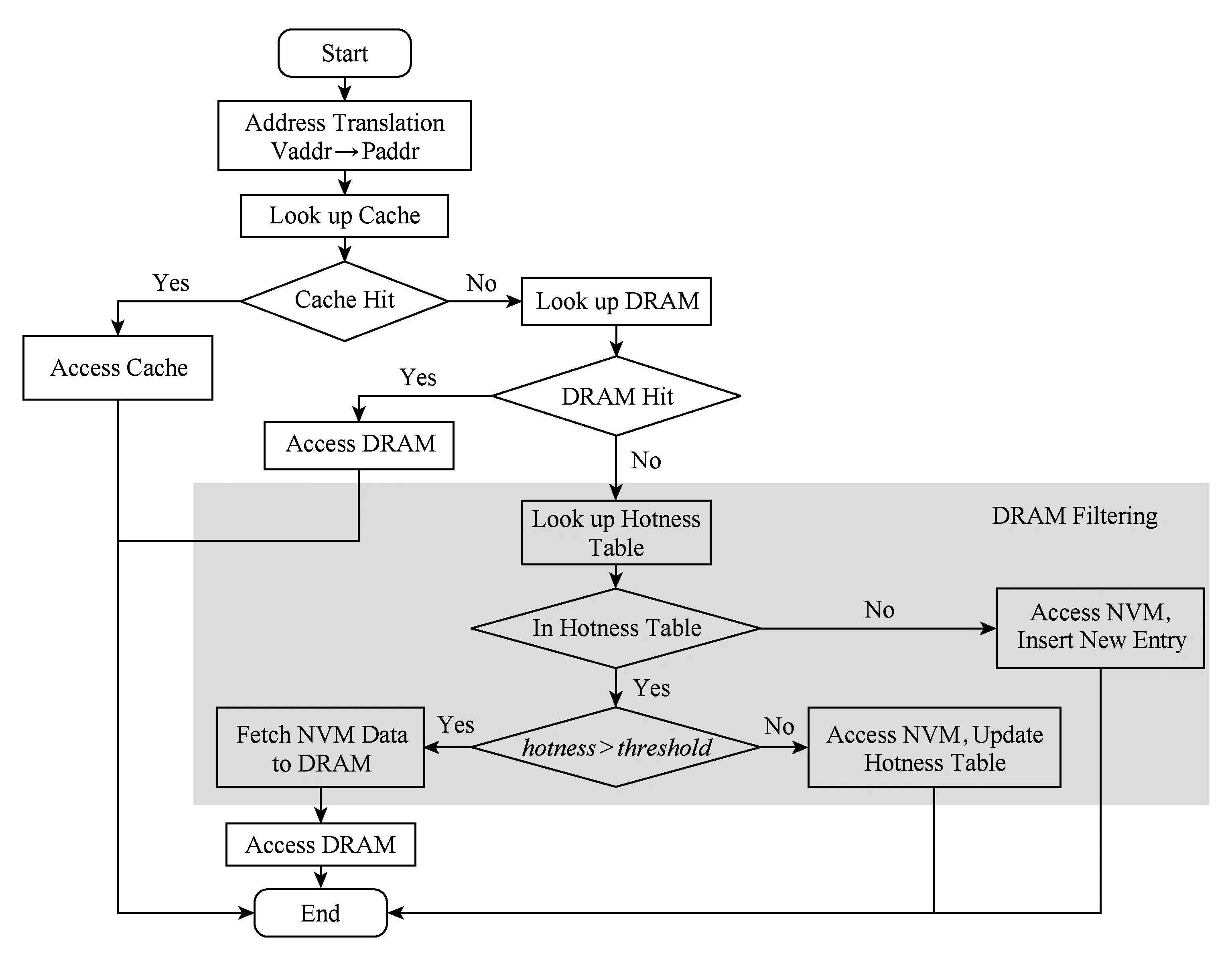
Fig.6 Memory access process while using cache filter图6 使用缓存过滤时的访存流程
通过上述的过滤机制,只有热度足够的NVM数据块才会被缓存到DRAM中,避免了将大量冷数据块缓存到DRAM中,从而降低了混合内存间数据交换对内存带宽造成的压力.
如图7所示,以108个CPU时钟周期为时间片记录每个周期内混合内存间数据交换对带宽的占用情况,分别画出了不使用过滤机制和使用过滤机制运行Linpack[23]应用时,数据交换对内存带宽占用百分比随时间变化的曲线图.未使用过滤机制的Linpack在起始阶段对带宽的占用在20%,随着时间推移,访存特征发生变化,对带宽的占用迅速提高到100%,这个时候系统甚至会发生瘫痪.而使用了过滤机制后,由于根据应用的实时访存特征,动态的调整热度阈值,只把满足热度阈值的热数据缓存到DRAM中,带宽占用始终被控制在较低的水平.

Fig.7 Bandwidth occupancy with cache filter and without filter图7 使用缓存过滤和不使用过滤时的带宽占用
3.4 轻量级的数据块热度监测
要在DRAM上使用过滤机制,需要知道NVM上数据块的热度信息.本系统中NVM上热度信息监测的粒度和DRAM缓存管理粒度一致,都是4 KB数据块.在NVM上以4 KB为粒度监测数据块的访存信息,每个4 KB数据块需要使用2 B的计数器来存储热度值,以保证数据块在周期时间内的热度值不会超过计数器最大计数范围.对于本架构中32 GB的NVM,监测所有的NVM数据块需要16 MB空间存储热度信息,数据量太大,存储在SRAM中不现实.而每次DRAM缺失时,都需要查找一次访存请求所访问数据块的热度值,为了缩短查找时延,需要将热度信息存储在高速的SRAM中.这就是当前面临着的矛盾.
文献[24]中通过实验分析大量应用的访存特征,得出虽然大部分应用总的内存占用很大,但是在一定的时间周期内(108cycle)所访问到的工作集只是其中很小的一部分.在本系统中由于DRAM缓存读缓存请求的过滤作用,大部分访存请求都直接访问DRAM中的数据,实际上访问NVM内存的部分工作集就更少了.根据这一特性,我们增加了一小块SRAM,用来存放数据块热度信息记录表.每个热度信息表项需要8 B的存储空间,包括3部分组成:1)28 b的NVM数据块的块号,用来记录NVM中数据块的块号信息,最大可支持1TB大小的主存,有很强的可扩展性.2)22 b的最近最少使用(least recently used, LRU)值,用来记录当前热度信息记录表中表项的LRU信息.3)14 b的热度值,记录当前数据块的热度.本系统中的热度记录表包括1 024个表项,只需要8 KB的硬件存储开销.
在DRAM缓存过滤机制中,每次DRAM缺失都需要查找数据块热度记录表以确定是否要将访存请求访问的数据块缓存到DRAM中.如果热度信息记录表的表项数太少,会造成大量的表项替换,一些旧的数据块的热度信息就会丢失,对热度监测的准确性造成影响.为了验证使用1 024个表项来维护热度信息是否足够,我们统计了查找热度信息记录表的命中率.经过实验得出查找热度信息表的平均命中率高达99.1%,只有极少的旧表项会被换出,证明了本系统中使用1 024个表项是足够的.由于NVM读写不对称,读延迟是DRAM的几倍,而写延迟比DRAM高一个数量级.同时NVM写耐受力差,频繁的写操作容易破坏NVM的存储单元.因此更倾向于将写热度高的数据鉴定为热页加载到DRAM中.在统计NVM数据块访问热度时,对于读写操作分别给予不同的热度权重.每对NVM内存进行一次读操作,增加Tnvm_read_cycle-Tdram_read_cycle的热度值,其中Tnvm_read_cycle和Tdram_read_cycle分别代表NVM和DRAM进行一次读操作平均所需的时钟周期数.每对NVM内存进行一次写操作,增加Tnvm_write_cycle-Tdram_write_cycle的热度值,其中Tnvm_write_cycle和Tdram_write_cycle分别代表NVM和DRAM进行一次读操作平均所需的时钟周期数.由于写操作密集的数据放置在DRAM中带来的收益更大,因此写操作在数据块热度计算过程中被赋予了更大的权重,写操作频繁的数据块就更容易达到阈值从而被缓存到DRAM中.
除了记录NVM数据块的热度信息,也用一个计数器记录每个周期内混合内存间数据交换的数据量,用来估算数据交换对内存带宽的压力.同时也记录DRAM缓存的访问次数和命中次数,用来计算每个周期内实时的DRAM命中率,用于指导阈值的动态调整策略.
3.5 动态热度阈值调整
阈值的选取,决定了在DRAM缺失时是否从NVM主存中将请求的数据块加载到DRAM中.阈值选取过低,会减弱了过滤机制的作用,将大量访问热度不高的数据也加载到DRAM中.阈值选取过高,热数据很晚才能被加载到DRAM中,NVM会承受大量的读写操作,会降低系统的性能和使用寿命.由于应用的访存特征在运行过程中会动态地发生变化,不同的应用访存特征差异性也较大.为了保证系统的灵活性和可用性,需要使用动态的热度阈值调整策略.
在本系统中,对于阈值的动态调整,为了尽可能优化系统的性能,有3点因素需要考虑:1)DRAM实时的命中率.DRAM的命中率越高,从NVM中取数据的次数就越少,性能、带宽上的表现也会好.因此在带宽条件允许的情况下适当地降低阈值,将更多的数据加载到DARM缓存中,有助于提高DRAM缓存的命中率,从而提升系统整体性能.2)大多数应用的工作集小于DRAM缓存大小,对于这类应用,设置较低的阈值,将其全部工作集尽早的调入到DRAM缓存中有利于提高系统的性能.3)要考虑带宽的占用情况,避免出现带宽100%占用的情形.在带宽占用严重时,应快速大步长的提高热度阈值,减少数据交换量,防止数据交换对内存带宽造成巨大压力.根据上述的3点因素,在SSLDC中提出了基于应用运行过程中实时信息的动态阈值调整算法.
阈值动态调整的过程如下:
1) 考虑DRAM的命中率.当DRAM命中率小于10%时,此时的阈值可能设置得太大了,导致最近访问的数据热度很难达到将其缓存到DRAM中所需的阈值.此时需要快速地以大步长来减小阈值;当DRAM命中率在10%~50%时,混合内存的性能不是很好,此时适当地减小阈值,以提升DRAM命中率;当DRAM命中率在50%~80%之间时,在不对内存带宽产生压力的情况下,以小步长减小阈值以进一步提高DRAM命中率.
2) 考虑实时的DRAM缓存使用情况.在DRAM空间比较富余时,将阈值设为0,尽可能地利用空闲的DRAM缓存.
3) 考虑带宽的实时占用情况.前面2点都是尽可能地在带宽允许的条件下减小阈值,以达到更高的DRAM命中率.在本策略中,每个周期都会统计DRAM和NVM间数据交换所产生的带宽占用量,根据这个占用情况来最终决定阈值的设置.当数据交换产生的带宽占用小于10%时,不会对内存带宽产生压力,因此不进一步对阈值进行调整.当数据交换的带宽占用超过20%时,此时会较严重的对内存带宽产生压力,大步长的增加阈值,从而过滤掉更多数据交换的操作.当数据交换的带宽占用在15%~20%之间时,存在一定的带宽压力,此时适当的增加阈值,降低数据交换所产生的内存占用;当这部分带宽占用在10%~15%之间时,小步长的增加阈值,将数据交换产生的带宽占用控制到10%左右.
使用了动态阈值调整技术后,DRAM和NVM间数据交换产生的带宽占用维持在10%左右,在不对带宽产生明显压力的情况下,尽可能地降低阈值以提高DRAM命中率,从而提高系统整体性能.
4 实验评测
本系统是基于zsim[25]和 NVMain[26]两个广泛使用的模拟器实现的.其中,zsim是一个快速的x86-64架构的多核模拟器,它使用Intel Pin[27]工具收集处理器的访存信息,并且在zsim中进行重放.我们借鉴了文献[24]对zsim做的修改,同样在zsim源码中加入了对操作系统功能的模拟模块(比如伙伴分配器、页表及TLB管理等).CPU访存前,首先调用伙伴分配器为虚拟页分配对应的物理页,并在页表中建立虚拟页到物理页的映射;CPU访存时,通过TLB获取虚拟地址对应的物理地址.另一个模拟器—NVMain,是一个时钟精确性的内存模拟器,它可以同时模拟DRAM以及NVM内存的访存行为.在实验中,我们使用NVMain来模拟DRAM与NVM组成的混合内存系统.
4.1 实验配置
本系统详细配置信息如表1所示.因为PCM是研究领域中主流的NVM介质.我们选择PCM作为NVM的代表,其中具体的时序和能耗参数主要参考文献[24]和文献[28].

Table 1 System Detailed Configuration 表1 系统详细配置

Table 1 (Continued)
我们测试了不同访存特征的测试集,如表2所示,这些测试用例选自SPEC CPU 2006[29],Parsec[30],Problem Based Benchmarks Suit (PBBS)[31]以及大内存应用Graph500[32],Linpack[23]和NPB-CG[33].其中mcf,soplex,freqmine,BFS,setCover等应用的内存占用小于4 GB大小.MST,Graph500,Linpack,NPB-CG的内存占用均超过4 GB.

Table 2 Benchmarks表2 应用程序测试集
为了衡量本系统在系统性能、能耗、带宽占用等方面的表现,共设置了5组系统进行对比:
1) NVM-2 MB.主存由单一的32 GB NVM存储器构成的系统,在所有对比系统中,性能最差.
2) DRAM-2 MB.主存由单一的32 GB DRAM存储器构成的系统,在所有对比系统中,能耗较高,价格最贵,但性能最好.
3) CHOP.文献[4]中提到的层次化结构混合内存系统,采用4 GB的DRAM缓存、32 GB的NVM主存,操作系统中使用2 MB的大页.DRAM缓存的管理粒度是4 KB,并使用固定阈值的过滤机制对DRAM上的缓存数据的操作进行过滤.
4) SSLDC.本文中设计的支持大页和大容量缓存的层次化混合内存的SSLDC系统,使用层次化的混合内存架构,4 GB DRAM使用4 KB的粗粒度管理方式,与32 GB的NVM以直接映射的方式相联,操作系统中使用2 MB大页.在DRAM缓存上使用本文描述的过滤机制,判断数据块热度的阈值根据实时访存情况进行动态的调整.
5) SSLDC_no_filter.和SSLDC大致相同,只是不对DRAM上缓存数据的操作进行过滤.
4.2 性能测试
本文将平均每个时钟周期执行的指令条数(instructions per cycle, IPC)作为系统性能的指标.在测试中把NVM-2 MB系统作为参照组;DRAM-2 MB因为没有页面迁移开销并且开启了大页,所以DRAM-2 MB的性能是所有测试系统的上限.图8显示了5组对比系统的性能结果图.
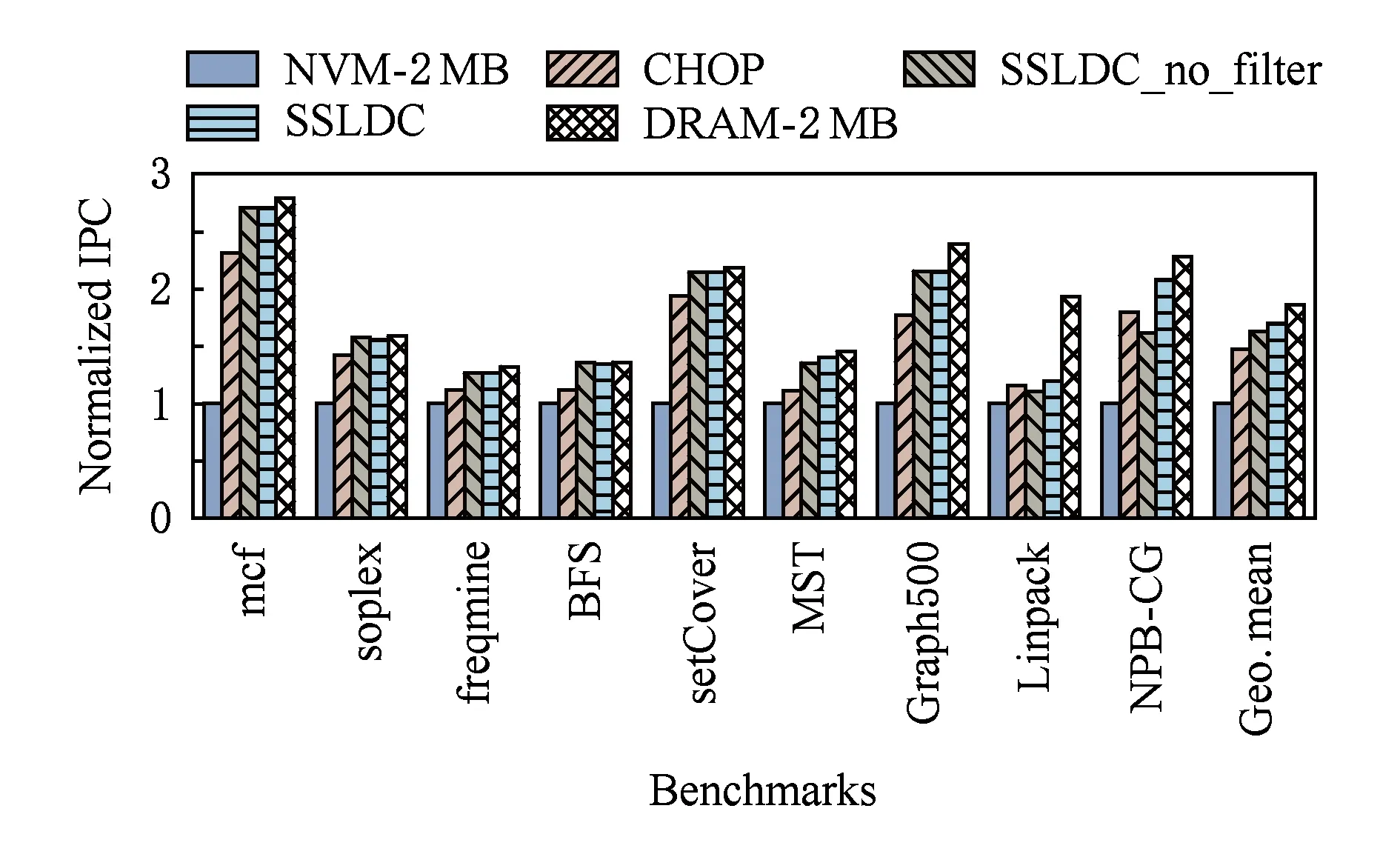
Fig.8 Systems IPC result图8 系统IPC结果
从图8可以看出,SSLDC相对于NVM-2 MB和CHOP分别平均有69.9%和15.2%的性能提升,并且距离上限(DRAM-2 MB)平均只有8.8%的性能差距.对于内存占用小于DRAM缓存大小的应用,SSLDC和SSLDC_no_filter的性能接近,增加了过滤机制对于性能的影响不大.这是因为SSLDC中的动态热度阈值调整策略,会在DRAM使用量小于70%时将阈值设置为0,相当于停止了过滤,因此对于内存占用小于DRAM缓存大小的应用,两者性能十分接近.Graph500虽然内存占用达到几十GB,但本次测试只运行了4×1010条指令,产生的工作集大概是2865 MB,小于DRAM缓存的大小,因此SSLDC和SSLDC_no_filter的性能也是接近的.MST,Linpack,NPB-CG产生的工作集均大于DRAM缓存的容量,SSLDC的性能都仅次于DRAM-2 MB的性能上限.对于内存占用小于DRAM缓存的应用,CHOP的性能普遍比SSLDC和SSLDC_no_filter要差.这因为CHOP中静态阈值设置得有些高,数据块需要达到很热才会被缓存到DRAM中,在此之间都在NVM中访问,因此性能较差.而SSLDC和SSLDC_no_filter很早就把所有数据缓存到DRAM中,因此性能较好.而对于Linpack,MST,NPB-CG等内存占用大的应用,CHOP的性能都要好于SSLDC_no_filter.因为这类应用的数据不能全部缓存到DRAM中,SSLDC_no_filter没有过滤机制,在DRAM和NVM之间会频繁的交换数据,占用大量带宽同时产生巨大的数据拷贝开销,性能会比较差.
4.3 能耗测试
图9显示了各个系统的能耗对比.其中,NVM-2 MB系统作为对照系统.

Fig.9 Power consumption result图9 能耗结果
从图9中可以看出DRAM-2 MB系统能耗最高,这是因为DRAM产生了较多的静态能耗.类似地,CHOP,SSLDC_no_filter和SSLDC能耗高于对照系统(NVM-2 MB)的原因也有部分是因为增加了DRAM刷新能耗,此外还有页面拷贝到DRAM以及写回到NVM中的能耗.从图9中我们可以看到,与DRAM-2 MB,CHOP相比,SSLDC平均降低67.6%和20.1%的能耗.NVM有着较低的静态功耗,但注意到mcf,setCover,Graph500,NPB-CG这几个应用的NVM-2 MB能耗并不是最低的,尤其是mcf和setCover,NVM-2 MB的能耗仅次于DRAM-2 MB,虽然比DRAM-2 MB的能耗低很多.这是因为mcf和setCover等应用有频繁的访存操作,NVM读写的动态功耗较大,因此NVM-2 MB运行这些应用时功耗较高.SSLDC在能耗方面表现优秀,对于大多数应用都有着较低的能耗.
4.4 带宽占用情况测试
图10显示了CHOP,SSLDC_no_filter和SSLDC三种策略的带宽使用对比.在本实验中以CHOP作为对照系统.
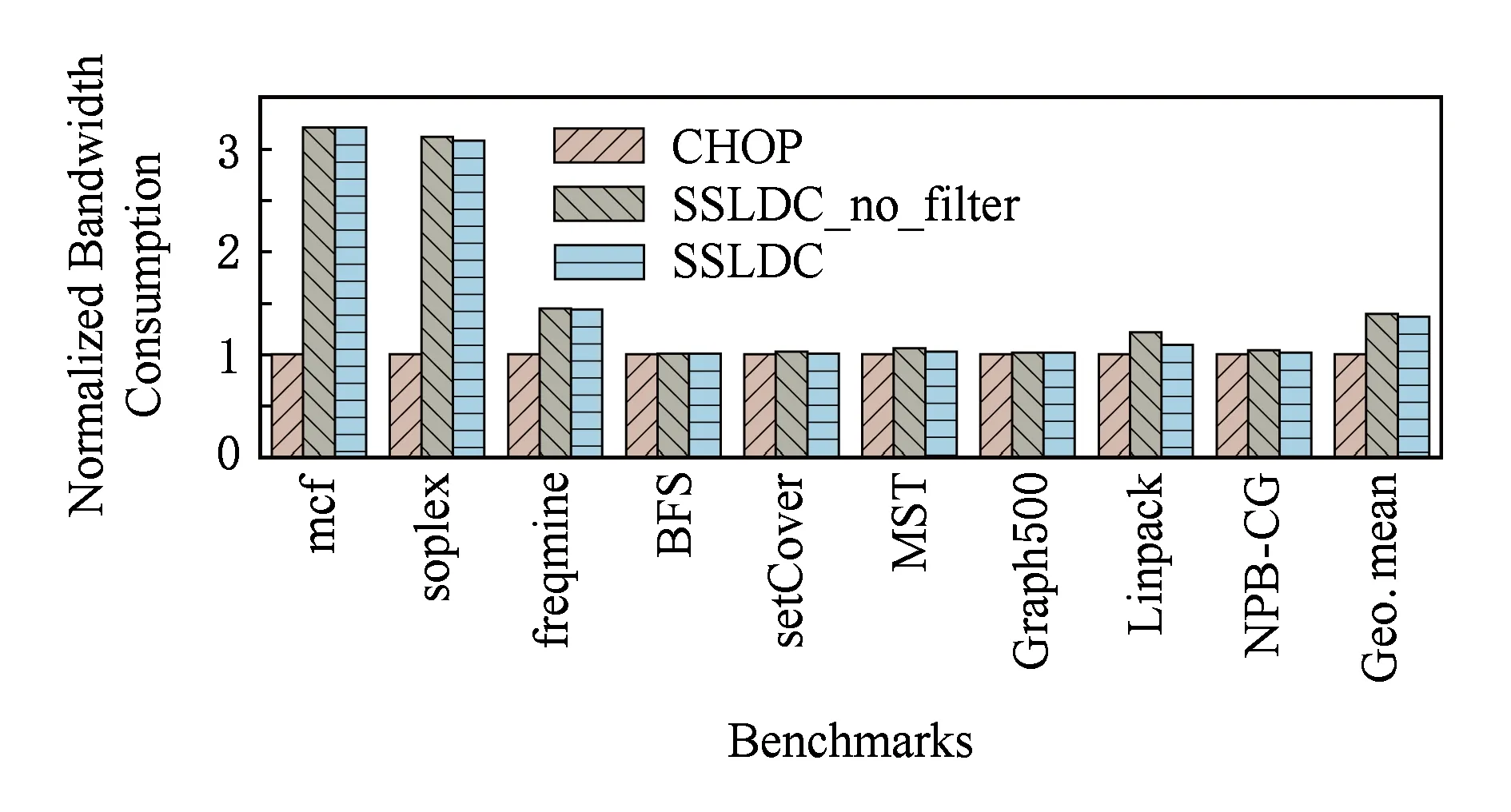
Fig.10 Bandwidth occupancy result图10 带宽占用结果
从图10可以看出,相比于CHOP,SSLDC_no_filter和SSLDC增加了39.9%和36.9%的带宽占用.这是因为CHOP中的静态阈值设置得较高,所以有很强的过滤能力.如4.2节性能测试中提到的,CHOP阈值设置过高导致只有热度很高的数据才能被缓存到DRAM中,NVM因此承受了大量的读写,导致系统性能较差.对于mcf,soplex,freqmine等应用完全可以将全部工作集尽早地缓存到DRAM中,以提高系统性能.但过高的阈值阻碍了将数据缓存到DRAM的操作.图10中这3个应用的带宽占用量明显低于其他2组的原因,正是由于阈值设置的不合理.图10中显示的是运行全部测试集的平均带宽占用情况,所以大多数应用的带宽占用在3组策略下区别不大.
4.5 大页的优化效果
图11显示了SSLDC中大页优化的效果图.其中纵坐标显示的是每运行一千条指令所产生的TLB 缺失次数(TLB misses per kilo instructions,MPKI).通过图11可以看出开启大页后显著地降低了TLB缺失次数,对于Linpack等内存占用较大的应用,可以降低99.96%的TLB缺失率.平均来说SSLDC开启大页可以降低99.8%的TLB缺失率.
图12显示的是,在操作系统中使用2 MB大页和使用4 KB时系统IPC的对比情况,对于mcf,soplex,setCover,Graph500,NPB-CG等应用,使用大页后性能提升明显,其中Graph500应用的性能提升超过220%.使用大页后,相对于使用4 KB基本页的平均性能提升高达37.3%.
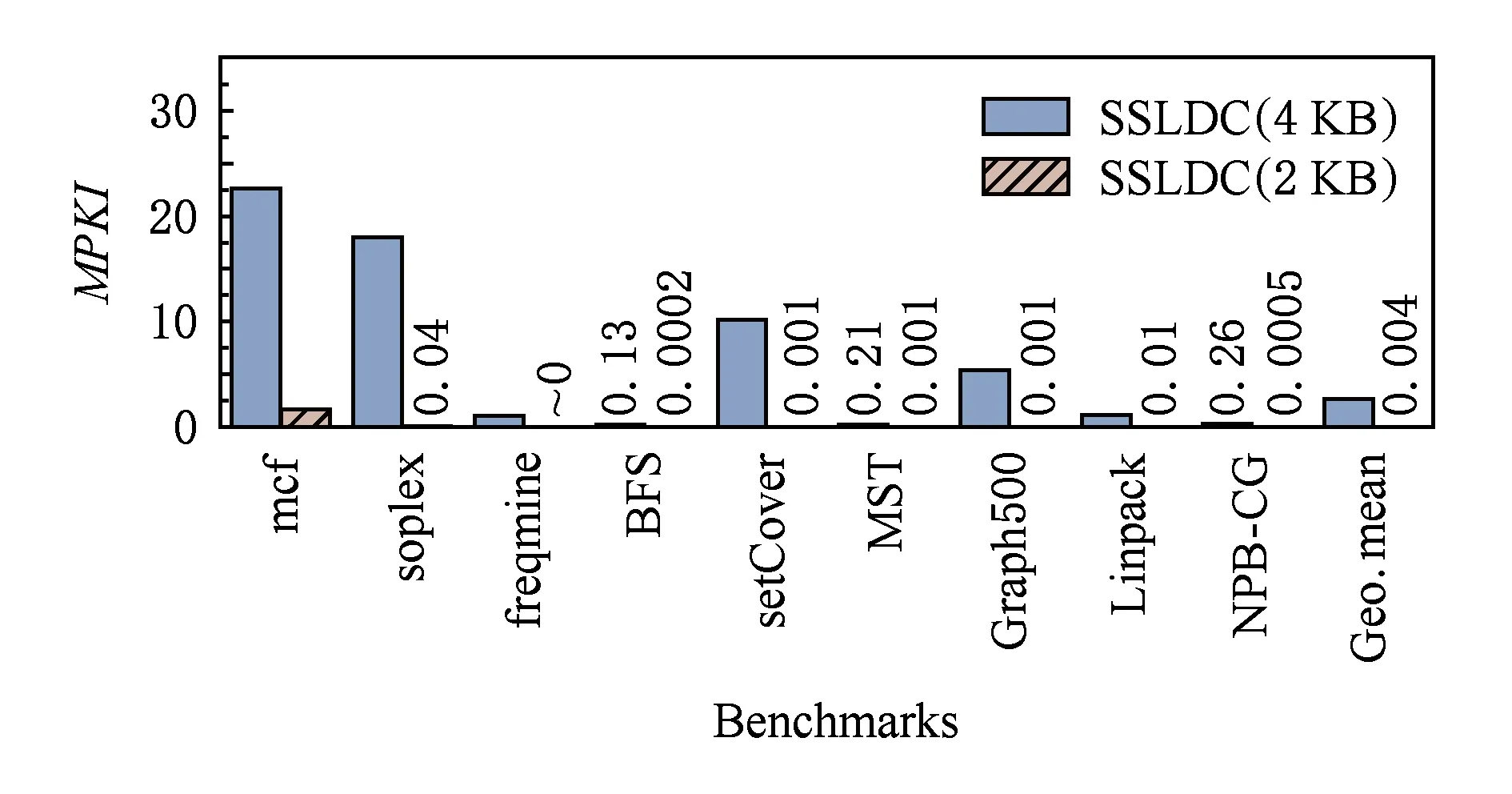
Fig.11 MPKI result图11 MPKI结果

Fig.12 IPC result图12 IPC结果
4.6 混合内存间映射方式的敏感性实验
为了验证混合内存间映射方式对DRAM命中率以及性能的影响,选取了3个代表性的应用来进行映射方式的敏感性实验.
如图13展示了3个应用在使用直接映射、4路组相联映射、8路组相联映射、16路组相联映射这4组不同映射策略时的DRAM命中率.从图13中可以看出采用不同的映射方式,DRAM命中率变化不大.

Fig.13 Effect of mapping mode on DRAM hit rate图13 映射方式对DRAM命中率的影响
图14中也同样显示出,混合内存间的映射关系对系统IPC的影响不大.因此在本架构中使用直接映射的方式不会对DRAM命中率和系统性能产生显著影响.

Fig.14 Effect of mapping mode on IPC图14 映射方式对IPC的影响
4.7 DRAM缓存容量的敏感性实验
为了研究DRAM容量对DRAM命中率和系统性能的影响,分别进行了1 GB,2 GB,4 GB,8 GB不同DRAM缓存容量配置的实验.
DRAM容量对DRAM命中率的影响如图15所示,DRAM缓存容量越大,命中率也越高.

Fig.15 Effect of DRAM capacity on DRAM hit rate图15 DRAM容量对DRAM命中率的影响
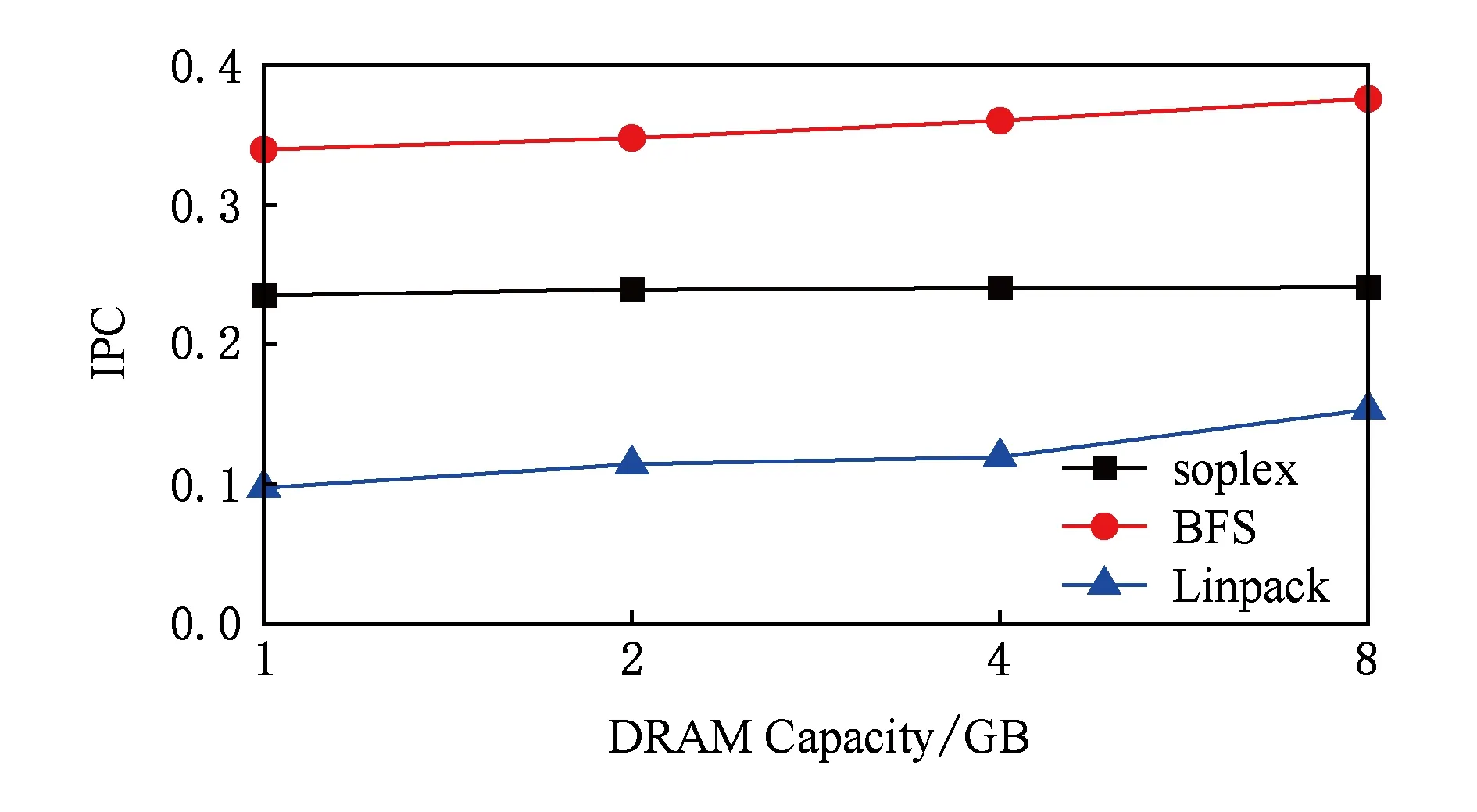
Fig.16 Effect of DRAM capacity on IPC图16 DRAM容量对IPC的影响
如图16所示,使用更大容量的DRAM缓存可以有效地提高系统性能和DRAM命中率.Linpack的8 GB DRAM这一组实验的IPC比使用1 GB DRAM时提高了50%,DRAM缓存命中率也提高了大约5倍.soplex和BFS的IPC与DRAM命中率都随着DRAM缓存容量的增大有所提升.因此在层次化混合内存中支持大容量的DRAM有显著优势.
4.8 过滤机制的时间开销
在DRAM缓存过滤机制中,每次DRAM缺失都需要查找数据块热度记录表以确定是否要将访存请求访问的数据块缓存到DRAM中.查找数据块热度记录表在访存的关键路径上,虽然数据块热度记录表存储在高速访问的SRAM中,但仍需要分析一下这部分开销对整体性能的影响.
图17展示的是查找数据块热度记录表的开销在整个程序执行时间中的占比.对于大多数应用,使用过滤机制产生的额外开销只有不到1%,几乎可以忽略不计.对于Linpack和NPB-CG,这部分开销超过了3%,这是因为Linpack和NPB-CG的内存占用非常大,且访存的局部性比较差,所以DRAM的命中率较低,造成了较多次数的数据块热度信息表查找.
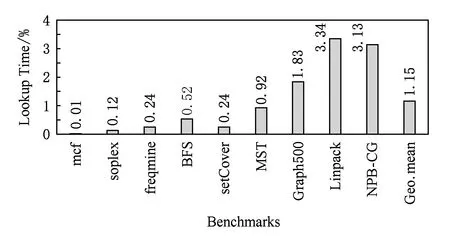
Fig.17 Time spent in hotness table lookup图17 查找热度信息记录表的时间开销
4.9 硬件存储开销
在本系统中,有2部分数据需要存储在SRAM中:
1) DRAM缓存的元数据.因为在DRAM缓存中使用4 KB的粗粒度管理方式,且在DRAM缓存和NVM主存之间使用直接映射的方式,进一步简化了元数据的结构,降低了硬件存储开销.对于本系统中4 GB的DRAM缓存,仅需要1 MB的SRAM硬件存储开销.
2) 数据块热度信息记录表.在周期性的监测NVM数据块热度信息时,用一块SRAM存放当前最近最频繁访问的NVM数据块的热度信息.每一个表项需要8 B,1 024个表项一共需要8 KB的SRAM存储开销.
总体来看,本系统的硬件存储开销在可以接受的范围内是可实现的.
5 总 结
本文设计了一个能同时支持大页和大容量DRAM缓存的层次化混合内存系统.为了优化元数据结构,以尽可能地减小元数据存储开销,在DRAM中使用4 KB数据块粒度,并在DRAM缓存和NVM主存之间使用直接映射的方式维护地址映射信息,精简了元数据结构,所以大容量DRAM缓存的元数据都可以放置在SRAM中.考虑到DRAM每次缺失时都需要从NVM中读取数据,这将带来严重的带宽占用.为了减小带宽压力,增加了一个过滤机制,只有NVM中访问热度达到阈值的热数据块才能被缓存到NVM中,避免了不必要的冷数据读取产生的带宽占用.提出了一个动态热度阈值调整方法,根据应用实时的内存信息周期性的动态调整热度阈值,保证在不造成内存带宽压力的情况下,尽可能地迁移热数据提高DRAM命中率,从而提高系统整体性能.与使用大页的纯NVM内存和现有的CHOP策略相比分别平均有69.9%和15.2%的性能提升,并且与使用大页的纯DRAM内存系统相比也平均只有8.8%的性能差距.

[1]Alam H, Zhang Tianhao, Erez M, et al.Do-It-Yourself virtual memory translation [C]//Proc of the 44th Annual Int Symp on Computer Architecture.Los Alamitos, CA: IEEE Computer Society, 2017: 457468
[2]Mccurdy C, Coxa A L, Vetter J.Investigating the TLB behavior of high-end scientific applications on commodity microprocessors [C]//Proc of the IEEE Int Symp on Performance Analysis of Systems and Software (ISPASS 2008).Los Alamitos, CA: IEEE Computer Society, 2008: 95104
[3]Basu A, Gandhi J, Chang Jichuan, et al.Efficient virtual memory for big memory servers [J].ACM SIGARCH Computer Architecture News, 2013, 41(3): 237248
[4]Barr T W, Cox A L, Rixner S.Translation caching: Skip, don’t walk (the page table) [J].ACM SIGARCH Computer Architecture News, 2010, 38(3): 4859
[5]Bhattacharjee A.Large-reach memory management unit caches [C]//Proc of the 46th Annual IEEE/ACM Int Symp on Microarchitecture.New York: ACM, 2013: 383394
[6]Chen Yujie.Hardware/software cooperative caching for hybrid DRAM/NVM memory architectures [D].Wuhan: College of Computer Science and Technology, Huazhong University of Science and Technology, 2017 (in Chinese)(陈宇杰.软硬件协同管理的异构内存缓存机制[D].武汉: 华中科技大学计算机科学与技术学院, 2017)
[7]Mao Wei, Liu Jingning, Tong Wei, et al.A review of storage technology research based on phase change memory [J].Chinese Journal of Computers, 2015, 38(5): 944960 (in Chinese)(冒伟, 刘景宁, 童薇, 等.基于相变存储器的存储技术研究综述[J].计算机学报, 2015, 38(5): 944960)
[8]Meza J, Chang Jichuan, Yoon H B, et al.Enabling efficient and scalable hybrid memories using fine-granularity DRAM cache management [J].IEEE Computer Architecture Letters, 2012, 11(2): 6164
[9]Qureshi M K, Loh G H.Fundamental latency trade-off in architecting DRAM caches: Outperforming impractical SRAM-Tags with a simple and practical design [C]//Proc of the 45th Annual IEEE/ACM Int Symp on Microarchitecture.Piscataway, NJ: IEEE, 2012: 235246
[10]Qureshi M K, Srinivasan V, Rivers J A.Scalable high performance main memory system using phase-change memory technology [C]//Proc of the 36th Annual Int Symp on Computer Architecture.New York: ACM, 2009: 2433
[11]Ryoo J H, Meswani M R, Panda R, et al.SILC-FM: Subblocked interleaved cache-like flat memory organization [C]//Proc of the 2016 Int Conf on Parallel Architectures and Compilation.Piscataway, NJ: IEEE, 2017: 435437
[12]Bock S, Childers B R, Melhem R, et al.Concurrent migration of multiple pages in software-managed hybrid main memory [C]//Proc of ICCD2016.Piscataway, NJ: IEEE, 2016: 420423
[13]Salkhordeh R, Asadi H.An operating system level data migration scheme in hybrid DRAM-NVM memory architecture [C]//Proc of the 2016 Conf on Design, Automation & Test in Europe.Piscataway, NJ: IEEE, 2016: 936941
[14]Barr T W, Cox A L, Rixner S.SpecTLB: A mechanism for speculative address translation [C]//Proc of the 38th Annual Int Symp on Computer Architecture.Piscataway, NJ: IEEE, 2011: 307317
[15]Talluri M, Hill M D.Surpassing the TLB performance of superpages with less operating system support [J].ACM SIGPLAN Notices, 1994, 29(11): 171182
[16]Muck J, Hays J.Architectural support for translation table management in large address space machines [C]//Proc of the 20th Annual Int Symp on Computer Architecture.Piscataway, NJ: IEEE, 1993: 3950
[17]Bhargava R, Serebrin B, Spadini F, et al.Accelerating two-dimensional page walks for virtualized systems [C]//Proc of the 13th Int Conf on Architectural Support for Programming Languages and Operating Systems.New York: ACM, 2008: 2635
[18]Korn W, Chang M S.SPEC CPU2006 sensitivity to memory page sizes [J].ACM SIGARCH Computer Architecture News, 2007, 35(1): 97101
[19]Zhang Xiaohui, Jiang Yifei, Cong Ming.Performance improvement for multicore processors using variable page technologies [C]//Proc of the 6th 2011 IEEE Int Conf on Networking, Architecture, and Storage.Piscataway, NJ: IEEE, 2011: 230235
[20]Chou C C, Jaleel A, Qureshi M K.CAMEO: A two-level memory organization with capacity of main memory and flexibility of hardware-managed cache [C]//Proc of the 47th Annual IEEE/ACM Int Symp on Microarchitecture.Piscataway, NJ: IEEE, 2014: 112
[21]Loh G H, Hill M D.Efficiently enabling conventional block sizes for very large die-stacked DRAM caches [C]//Proc of the 44th Annual IEEE/ACM Int Symp on Microarchitecture.New York: ACM, 2011: 454464
[22]Jiang Xiaowei, Madan N, Zhao Li, et al.CHOP: Adaptive filter-based DRAM caching for CMP server platforms [C]//Proc of the 16th Int Symp on High Performance Computer Architecture(HPCA).Piscataway, NJ: IEEE, 2010: 112
[23]Linpack.Benchmark programs and reports[EB/OL].[2018-04-05].http://www.netlib.org/benchmark/
[24]Liu Haikun, Chen Yujie, Liao Xiaofei, et al.Hardware/software cooperative caching for hybrid DRAM/NVM memory architectures [C]//Proc of the Int Conf on Supercomputing (ICS’17).New York: ACM, 2017: Article Number 26
[25]Sanchez D, Kozyrakis C.ZSim: Fast and accurate microarchitectural simulation of thousand-core systems [J].ACM SIGARCH Computer Architecture News, 2013, 41(3): 475486
[26]Poremba M, Zhang Tao, Xie Yuan.NVMain 2.0: A user-friendly memory simulator to model (non-) volatile memory systems [J].IEEE Computer Architecture Letters, 2015, 14(2): 140143
[27]Luk C K, Cohn R, Muth R, et al.Pin: Building customized program analysis tools with dynamic instrumentation [J].ACM SIGPLAN Notices, 2005, 40(6): 190200
[28]Lee B C, Ipek E, Mutlu O, et al.Architecting phase change memory as a scalable dram alternative [J].ACM SIGARCH Computer Architecture News, 2009, 37(3): 213
[29]Henning J L.SPEC CPU2006 benchmark descriptions [J].ACM SIGARCH Computer Architecture News, 2006, 34(4): 117
[30]Bienia C, Kumar S, Singh J P, et al.The PARSEC benchmark suite: Characterization and architectural implications [C]//Proc of the 17th Int Conf on Parallel Architectures and Compilation Techniques.New York: ACM, 2008: 7281
[31]Carnegie Mellon University.PBBS: Problem based benchmarks suit[EB/OL].[2018-04-05].http://www.cs.cmu.edu/pbbs/
[32]Standard Performance Evaluation Corporation.Graph500[EB/OL].[2018-04-05].http://graph500.org/
[33]NASA Advanced Supercomputing Division.NAS parallel benchmarks: NPB-CG[EB/OL].[2018-04-05].https://www.nas.nasa.gov/publications/npb.htmlChenJi, born in 1992.Master candidate.His main research interests include in-memory computing and operation system.
猜你喜欢
保健医苑(2022年1期)2022-08-30
体育科技文献通报(2022年5期)2022-06-05
动漫界·幼教365(中班)(2021年4期)2021-05-23
电脑爱好者(2020年17期)2020-09-14
文体用品与科技(2019年24期)2020-01-09
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
长江丛刊(2018年31期)2018-12-05
NBA特刊(2017年8期)2017-06-05
电脑爱好者(2015年21期)2015-09-10
