
一种基于社交事件关联的故事脉络生成方法
2018-09-21 03:25李莹莹蒋浩谊胡春明
计算机研究与发展 2018年9期
李莹莹 马 帅 蒋浩谊 刘 喆 胡春明 李 雄
1(软件开发环境国家重点实验室(北京航空航天大学) 北京 100191) 2(北京大数据科学与脑机智能高精尖创新中心(北京航空航天大学) 北京 100191) 3(国家计算机网络应急技术处理协调中心 北京 100029) (liyy@act.buaa.edu.cn)
社交网络已被政府、公司甚至总统(如奥巴马、特朗普等)等广泛用于发布新闻和报道事件.社交网络中信息的实时性和快速传播的能力使其成为获取信息的重要媒介.短文本的表述方式也能够有效地传递关键信息.社交网络的这些特性颠覆了传统媒体在信息传播上的统治力,这使其为监控事件及其演化提供了宝贵数据.然而,社交网络中文本的快速积累、口语化的表达方式以及文本内容中的错别字使得监控事件及事件间的演化具有极大挑战.从社交网络文本中对具有同一主题的的事件及其演化进行提取能够极大地帮助我们在全景上对某一事件进行了解.例如:我们期望获得关于平昌冬奥会所有项目(即事件)的信息和这些项目的进程(即事件演化).这需要我们首先检测事件,而后对这些事件进行聚类从而获得具有同一主题的事件(即故事),并最终以一种用户友好的方式(故事脉络)呈现出来.
目前针对该问题的方法按照是否需要用户提供关键词,大致可分为2类:1)关键词检索依赖型算法,将该问题形式化为信息检索问题,依据用户提供的关键词生成故事脉络,如MetroMap[1]首先依据用户提供的关键词匹配到相关的文档,然后用其构造用于表示故事脉络的多尺度地图.再如Wang等人[2]首先依据主题相关的包含文本描述的图像集合用图像的文本和时间相似度构造带权重的图,然后通过在该图上解决最小权重支配集(minimum-weighted connected dominating set)问题选择用于表示故事脉络的对象;再如GESM[3]首先依据用户提供的关键词得到相关的微博,然后依据Wang等人[2]的算法构造故事脉络.然而,这类方法严重依赖于用户所提供的关键词,而对于用户无法提供关键词的情况,这类算法无法提供相应的结果,这限制了该类方法的应用.2)为了解决这一问题,关键词检索独立型算法能够自动生成故事脉络,如CAST[4]首先从数据流中基于微博的文本相似度和时间相似度构造微博图,并将微博图中稠密子图做为事件,然后依据事件间的相似度构造事件间关系,依据事件间关系追踪事件的上下文.StoryGraph[5]则将每天的新闻文本分到不同主题集合中,然后通过新产生的主题与已经存在的主题的Pearson相关系数决定事件的演化.
然而,故事脉络生成仍然存在2个问题:1)事件由微博集合表示且有特定主题,如何从微博集合提取与事件对应的强相关的微博集合是一个关键问题.目前,针对该问题研究者们已经提出多种解决方式,然而如何选择最优的方法是一个具有挑战的问题.2)对有关联关系的事件如何进行有效组装,并以故事脉络的形式展示是另一个关键问题.
为此,我们将该问题形式化为3个连续的步骤,即事件检测、故事组装以及故事脉络生成.本文的主要贡献有3个方面:
1) 从微博检测事件.依据事件的隐式语义信息关联事件并组装故事,为故事生成故事脉络以可视化故事的发展过程;
2) 提出用包含摘要的有向无环图描述故事脉络.该故事脉络既可以使用户了解故事,也可使用户了解故事的发展过程;
3) 利用新浪微博数据集评价我们提出的故事脉络生成方法.基于用户体验的实验表明我们方法的性能优于现有方法.
1 研究问题和系统框架
在本节中,我们首先介绍术语的定义;然后,我们陈述所研究的问题;最后,我们描述系统框架.
1.1 术语定义
定义1.微博.一个微博m由二元组M,Tm表示,其中,1)M是微博的内容;2)Tm是微博的产生时间.
定义2.事件.一个事件e是在某时间和地点发生的事件[6],例如:“正确的中国国旗赶制完成预计11日运抵里约”是一个事件.其由六元组(式)Te,Microblog_set,Ce,Le,Pe,De表示.其中,1)Te表示检测到事件的时间;2)Microblog_set表示事件的微博集合;3)Ce表示记录事件主要信息的核心词集合;4)Le表示事件的地点;5)Pe表示事件的参与者集合;6)De表示事件的描述,该描述由一个短句子表示.我们基于微博集合Microblog_set识别Le,Pe和De特征.
定义3.故事.一个故事s定义为属于相同主题的事件集合,例如“2016里约奥运会”是一个故事,其由五元组(式)Event_set,Ts,Cs,Ls,Ps表示.其中,1)Event_set表示故事的事件集合;2)Ts表示故事的时间段;3)Cs表示故事的核心词集合;4)Ls表示故事的地点集合;5)Ps表示故事的参与者集合.我们基于故事的事件集合Event_set识别Ts,Cs,Ls和Ps特征.

Fig.1 The storyline in a story (“2016 Rio Olympic Games”)图1 “2016巴西奥运”故事的故事脉络
定义4.故事脉络(storyline).用于可视化故事的发展过程,其由二元组skeleton,summary表示,其中,1)skeleton是展示故事内事件间演化的有向无环图;2)summary是描述故事大意的短句子.
例1.图1中故事“2016巴西奥运”的故事脉络(部分)用于可视化该故事的发展过程.圆结点代表事件,事件的描述和检测时间(UTC+8)在该结点的右侧.事件结点的索引号表示该事件在时间轴上的顺序,索引号越大表示事件的时间越靠后.从事件结点ei到事件结点ej的有向边表示他们之间的时序演化关系.该故事脉络有3个分支:分支A、分支B和分支C.分支A与“巴西里约奥运俄罗斯部分运动员被禁赛”相关;分支B与“巴西里约奥运中国国旗有误”相关;分支C与“巴西里约奥运美国女子4×100接力掉棒”相关.故事脉络中的多个分支展示了故事“2016巴西奥运”的发展过程.故事摘要(summary)展示在上方的矩形框里.该摘要由各分支摘要合并而成,可帮助用户了解故事概述.
1.2 问题陈述
对于微博集({M1,M2,…,Mt}),其中Mt是时间片t的微博集合.我们的目标是:1)从微博集中检测事件({E1,E2,…,Et}),其中Et是时间片t检测的事件集合;2)依据事件的隐式语义信息有效的关联事件并组装故事(S={s1,s2,…,sNs}),其中si表示一个故事;3)为每个故事生成一个用于可视化故事发展过程的故事脉络.
1.3 系统框架描述
我们用包含3个组件的框架(如图2所示)解决故事脉络生成问题.首先,我们从微博集中检测事件;然后,我们通过关联事件组装故事;最后,我们为每个故事生成描述故事发展过程的故事脉络.
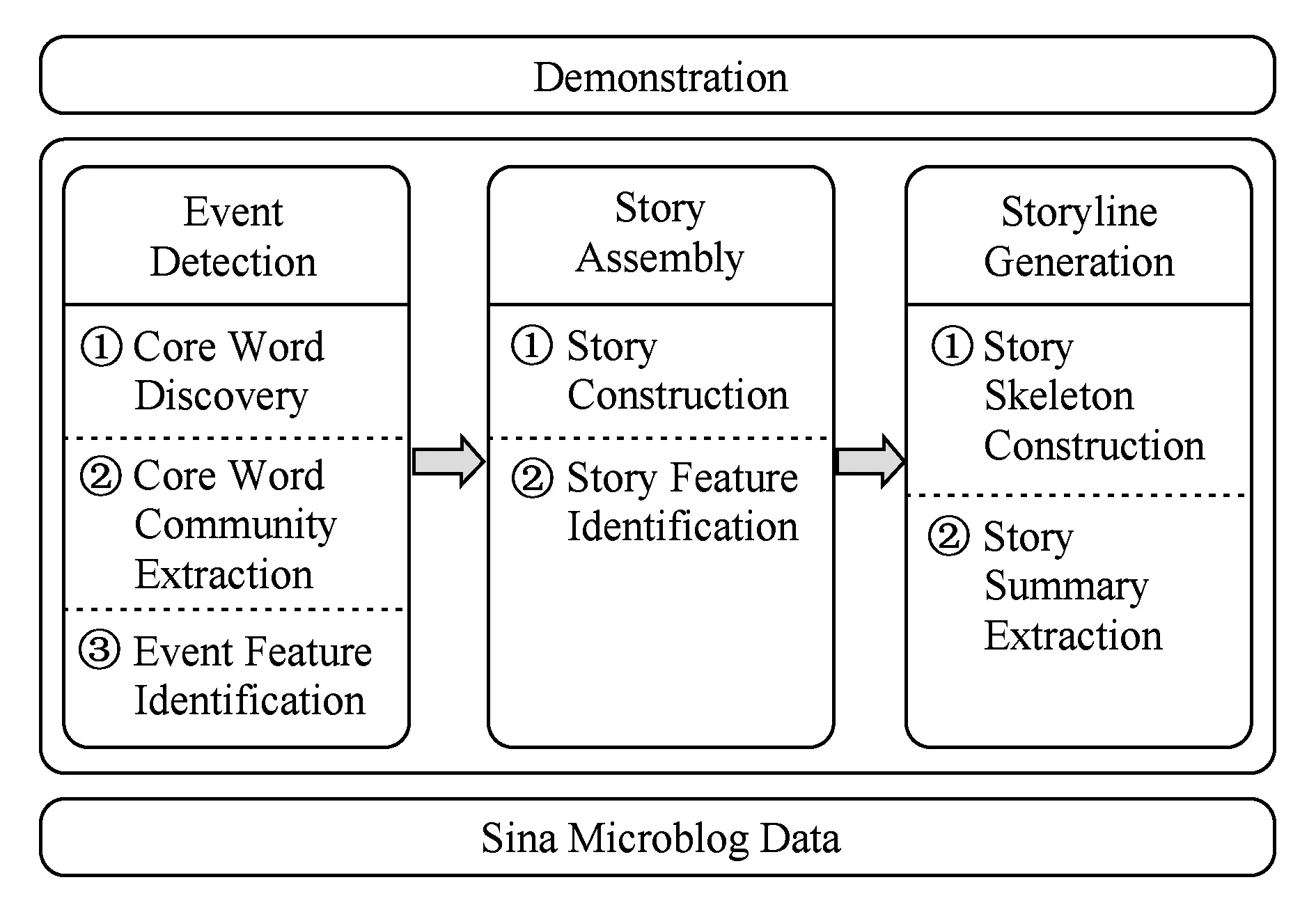
Fig.2 System framework图2 系统框架
1.3.1 事件检测
我们从微博集中检测事件.首先,从微博集得到由表示事件的核心词和核心词间共现关系构成的核心词图;然后,发现核心词图中紧密连接的子图并将子图做为事件的核心词集合;最后,为事件识别其他的特征Te,Le,Pe,De和Microblog_set.
1.3.2 故事组装
我们依据主题对事件分组,将事件组装成故事.首先,我们依据事件的隐式语义信息对事件聚类,将一个簇认为一个故事;然后,我们为每个故事识别其他的特征Ts,Ls,Ps和Cs.
1.3.3 故事脉络生成
我们为每个故事生成故事脉络,该故事脉络由包含摘要的事件有向无环图表示.首先,我们从故事的事件集基于弱连通分量和最大生成树构造有向无环图(skeleton);然后,我们基于故事的所有事件描述提取短文本作为故事的摘要.
2 系统组件
针对在第1节中形式化的3个步骤,即事件检测、故事组装和故事脉络生成,我们在本节具体介绍所对应的实现方法.
2.1 事件检测
在事件检测步骤,我们旨在从微博数据中检测事件.为帮助用户理解故事的发展过程,我们认为故事中的事件应该可以使用户剖析故事的细节,即事件应属于特定主题且具有细粒度性.
表示事件的词、核心词,在使用频率和与其他词的共现模式上较于该词的历史时刻有异常的变化[7].单个核心词表示的事件粒度较粗,不足以表达事件的全部信息.例如单个核心词、辅警,只能表示该事件与辅警有关.紧密连接的核心词集合可以详细地表达事件信息,增加事件内容覆盖率.例如,紧密连接的核心词集合,江苏省、沐阳、追授、牺牲和辅警,可详细表述“江苏省政府追授沭阳因公牺牲辅警孙孟涛见义勇为英雄称号”事件.用核心词集合表示的事件不利于用户理解讲述的内容,我们用事件的结构化表示帮助用户理解事件.
我们用3个连续的模块完成事件检测任务.首先,用热点发现算法[7]发现表示事件的具有异常出现频率的词(核心词);然后,用重叠的社区检测算法[8]提取紧密连接的核心词集合对事件进行详细描述;最后,从微博识别事件其余特征,方便用户理解事件.下面描述的3个连续的模块完成事件检测任务,我们采用Ring[9]实现的事件检测算法.
2.1.1 核心词发现
在核心词发现阶段,我们发现表示事件的核心词.表示事件的词在使用频率和与其他词的共现模式上较于该词的历史时刻有异常变化[7].我们用HOTSPOT[7]检测能描述事件的词.该算法首先依据微博数据构造词共现图;然后检测有异常变化的词,即核心词,并输出核心词及核心词间共现关系构成的图(核心词图).
2.1.2 核心词社区提取
在核心词社区提取阶段,我们提取表示事件的核心词集合.事件的核心词通常紧密连接.依据上一步输出的核心词图,我们用社区检测算法[8]检测紧密连接的核心词社区,即由词(点)和词间共现关系(边)构成的稠密子图.核心词社区对应事件的核心词集合,其能够有效地描述一个事件.我们依据图3(a)展示的核心词图检测出图3(b)的核心词社区,该核心词社区表示“江苏省政府追授沭阳因公牺牲辅警孙孟涛见义勇为英雄称号”事件.
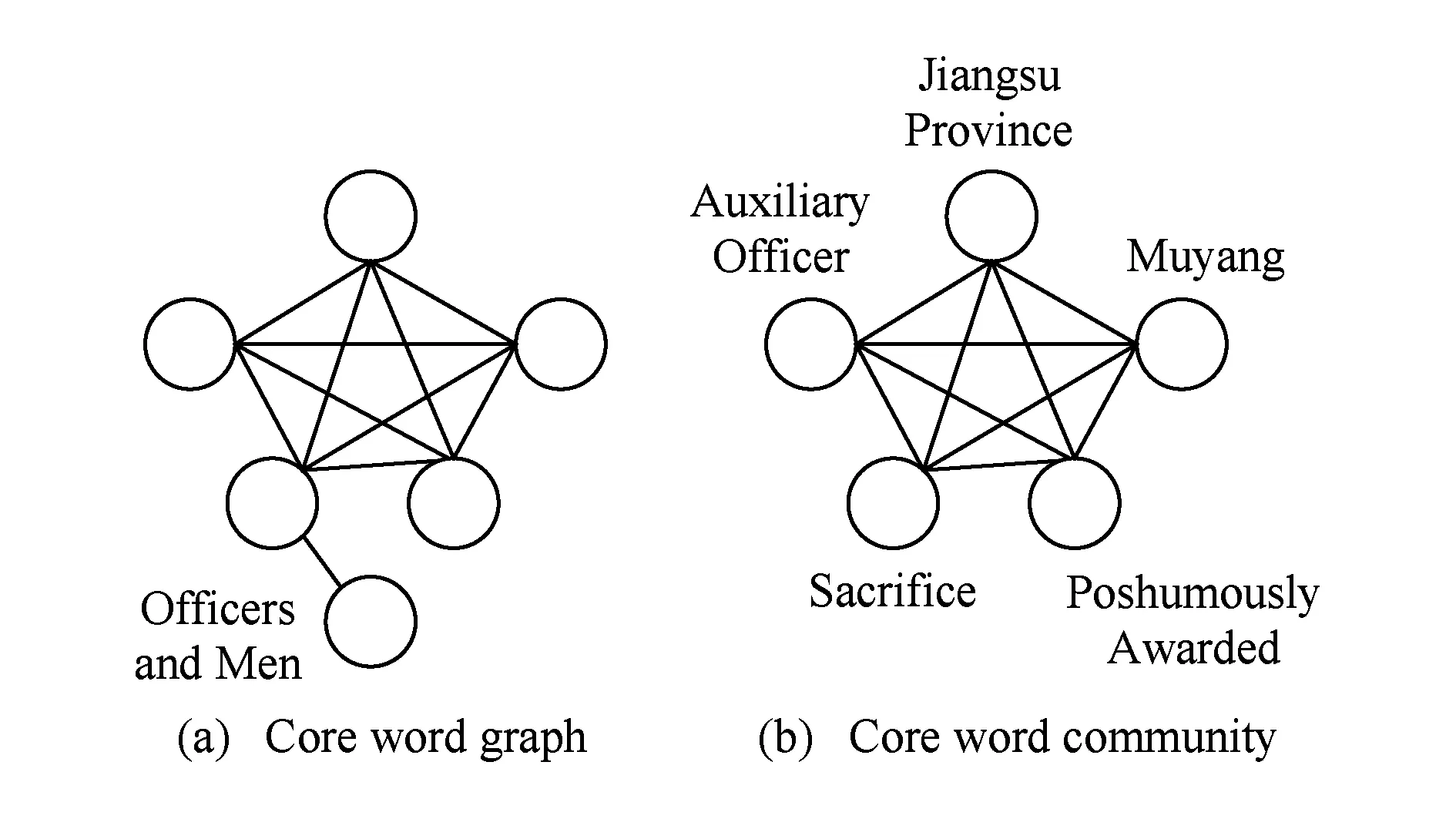
Fig.3 A core word community in the core word graph图3 核心词图的一个核心词社区
2.1.3 事件特征识别
在事件特征识别阶段,我们将事件的数据进行结构化以增加事件的描述信息.仅用核心词集合表示事件存在不足,如碎片化和易读性差.我们将用核心词集合表示的事件扩充为事件六元组,过程如下:
1) 我们将时间Te赋值为事件被检测的时间(每10 min);
2) 我们依据核心词集合寻找包含事件所有核心词的微博集合Microblog_set;
3) 我们将描述De赋值为事件的微博集合中包含核心词集合中的词最多的句子;
4) 我们从事件的微博集合中识别所有的命名实体(named entity),包括地名、人名和机构名等;
5) 我们将地点Le赋值为事件的微博集合中最频繁出现的地名;
6) 我们将参与者集合Pe赋值为事件的微博集合中出现的人名和机构名.
2.2 故事组装
在故事组装步骤,我们旨在通过关联事件组装故事.为帮助用户从全景了解故事,故事应囊括该主题下所有事件,即故事组装需有效组装有关联的事件.
依据事件词的相似度,即事件的显式语义信息,将有关联关系的事件聚成簇是简单直观的方式.但基于显式语义信息聚类得到的簇粒度较细,即只能将词相似度较高的事件聚到相同的簇.考虑到相同故事的事件可能包含较少的共有词,如表1所示,事件e10和事件e11仅包含“Rio”和“Olympic”两个共有词,基于显式语义信息的聚类不能有效组装有关联关系的事件.Latent Dirichelet Allocation(LDA)为数据集中的数据,例事件集合中的事件,生成有利于相似性和相关性判断的主题分布[10].我们通过用LDA生成事件的主题分布发现事件e10和事件e11的主题分布很相似.为方便说明,以下称事件的主题分布为隐式语义信息.我们基于LDA挖掘的隐式语义信息将相同主题的事件聚成簇.

Table 1 Two Eevents From the Story (“2016 Rio Olympic Games”)表1 故事“2016巴西奥运”中2个事件
我们用2个连续的模块完成故事组装任务.首先,我们依据事件的隐式语义信息关联事件,将事件分到不同的故事;然后,我们依据事件的特征,识别故事的特征,生成故事的结构化表示,以便用户查询.
2.2.1 故事构造
我们用预聚类和细聚类的方式组装故事.首先,我们用聚类算法DBSCAN[11]实现预聚类,即依据显式语义信息对事件分组;然后,我们用预聚类的结果初始化LDA中故事的词分布,并依据LDA生成的隐式语义信息构造故事.
1) 预聚类.预聚类依据事件的显式语义信息对事件分组.目前有很多成熟且应用广泛的聚类算法.我们从成熟聚类算法中选择适合我们任务的算法.基于密度的聚类算法DBSCAN有3个优势:①能处理带噪音的数据;②不需要指定类别;③容易适应单遍(single-pass)聚类,即只需遍历一遍数据集即可完成聚类.我们采用DBSCAN进行预聚类.
首先,我们为事件集合E中每个事件e构造词向量we.若第k个词在事件e中,we,k=1;否则we,k=0.然后,我们依据词向量用DBSCAN将事件聚到类成员P中,其中P={P1,P2,…,PI},Pi是包含一个事件集合的预簇.DBSCAN使用的距离函数:
dis(ei,ej)=1-cos(wei,wej),
(1)
其中,wei和wej分别是事件ei和事件ej的词向量.
最终,我们将事件集合E和基于DBSCAN的聚类结果作为细聚类的输入.
2) 细聚类.细聚类基于预聚类的结果挖掘事件的隐式语义信息,依据事件的隐式语义信息关联事件,并将事件赋值到故事.LDA生成的隐式语义信息有利于相关性判断.用预聚类的结果初始化LDA中故事的词分布可减少LDA的搜索空间.
首先,我们依据预聚类结果初始化LDA中故事的词分布,给定预聚类结果P,我们将相同的预簇中事件的词赋给相同的故事;然后,我们用Gibbs Sampling推断LDA的参数、事件的故事向量;最后,我们依据选择标准将事件赋给故事.
选择标准.我们假设每个事件属于且仅属于一个故事.我们将事件赋给概率最高的故事.
算法1.故事构造算法.
输入:事件集合E={e1,e2,…,en}、初始故事数Ns;
输出:故事集合S={s1,s2,…,sm}(m≤Ns).
Construct.Story (E,Ns);
①S←{s1,s2,…,sNs};
② {P1,P2,…,PI}←DBSCAN(E);
③ fori=1 toIdo
④ ifi≤Nsthen
⑤k←i;
⑥ else
⑦k←random(1,Ns);
⑧ end if
⑨ 将预簇Pi中所有事件的所有词赋给故事sk的词列表;
⑩ end for
故事构造的伪代码如算法1所示,给定事件集E,故事构造算法构造并返回故事集S.首先,我们用聚类算法DBSCAN预聚类(行②);然后,我们用DBSCAN的预聚类结果初始化LDA(行③~⑩);随之,我们用Gibbs Sampling推断LDA的参数,包括推断事件的故事向量(行~);而后,我们依据选择标准将事件分到故事中并去掉不包含事件的故事(行~);最后,我们返回非空的故事集S(行).

2.2.2 故事特征识别
在故事特征识别阶段,我们将故事的数据进行结构化以便于用户查询故事.事件检测组件为事件生成结构化表示,用事件的结构化表示生成故事的结构化表示既能充分利用相关微博的信息,也可以提高效率.我们基于事件六元组将用事件集合表示的故事扩充为故事五元组,过程如下:1)故事的时间段Ts的开始时间和结束时间分别被赋值为故事的事件集中事件的最早时间和最晚时间;2)故事内包含事件的特征越多,越能帮助用户查询故事,故事的地点集合Ls、参与者集合Ps和核心词集合Cs分别被设为故事的事件集中相应特征的并集.
算法2.故事特征识别算法.
输入:故事集合S={s1,s2,…,sm};
输出:故事集合S={s1,s2,…,sm}.
Identify.Story.Feature (S);
① for each storys∈Sdo
②Ts.start←min({Te|e∈Event_sets});
③Ts.stop←max({Te|e∈Event_sets});



⑦ end for
⑧ returnS.
故事特征识别的伪代码如算法2所示.给定故事集S,故事特征识别算法为故事集S中每个故事识别特征并返回故事集S.首先,故事的开始时间被设为事件集中的事件的最早时间(行②),故事的结束时间被设为事件集中事件的最晚时间(行③);然后,故事的地点集合、参与者集合和核心词集合分别被设为事件集中地点、参与者集合和核心词集合的并集(行④~⑥);最后,故事集S被返回(行⑧).
2.3 故事脉络生成
在故事脉络生成步骤,我们旨在为故事生成包含摘要的有向无环图以可视化故事的发展过程.为有更好的用户体验,故事脉络应兼顾准确性和理解性.准确性指故事脉络准确地展示事件的发展过程.理解性指故事脉络便于用户快速的了解故事.
故事可能包含多个相对独立的部分.例“2016巴西奥运”故事包含“巴西里约奥运俄罗斯部分运动员被禁赛”和“巴西里约奥运美国女子4×100接力掉棒”等多个相对独立的部分.我们用弱连通分量提取故事中多个相对独立的部分.为方便描述,下面称相对独立的部分为分支.
分支内的事件有较强的关联关系.复杂的图结构表示的分支不便于用户快速的理解[15].如图4(a)中图结构表示的分支,虽然其充分地表达了事件间的关联关系,但其也引入一些不必要连接,如事件e3到事件e7.为折中准确性和理解性,我们用最大生成树生成分支的树结构,如图4(b)所示.

Fig.4 A branch represented by a graph or tree structure图4 由图或树结构表示的分支
我们用2个连续的模块完成故事脉络生成任务.首先,我们从故事的事件集中基于弱连通分量和最大生成树构造故事骨架;然后,我们用基于图的方法提取短文本做为故事的摘要.
2.3.1 故事骨架构造
在故事骨架构造阶段,我们依据故事的事件集构造用于描述故事发展过程的有向无环图.首先,我们计算任意2事件间的权重,依此生成有向边,构造一个事件图;然后,我们依据事件图识别故事中的分支,即识别该图中所有的弱连通分量,并形成弱连通分量集合;最后,我们为弱连通分量集合中每个弱连通分量构造一个最大生成树,即用树结构表示的分支.这些用树结构表示的分支构成故事的骨架:
w(ei,ej)=I(Tei,Tej)siml(ei,ej)×
(cpsimp(ei,ej)+ccsimc(ei,ej)),
(2)
其中,ei和ej表示2个事件,I(Tei,Tej)表示事件间的时间关系;siml,simp和simc表示2事件地点、参与者集合和核心词集合的相似度;cp和cc是权重系数,该权重系数在满足cp+cc=1的条件下可以被调整.
演化关系包含着事件的时间关系.有向边只能从先发生的事件指向后发生的事件.若Tei 相同地点发生的事件更可能属于相同的分支.siml用于度量2事件地点间的相似度.siml(ei,ej)=1,若事件ei和事件ej的地点相同;siml(ei,ej)=0.5,若事件ei的地点地理位置上属于事件ej的地点,例如地点“中国北京”在地理位置上属于地点“中国”;siml(ei,ej)=0,在其他情况下. 事件间的参与者和核心词的相似度同样能反映事件间的演化关系.simp(ei,ej)度量2事件的参与者集合的Jaccard系数,simc(ei,ej)度量2事件的核心词集合的Jaccard系数. 事件的微博集合由包含事件所有核心词的微博构成.事件的地点和参与者由微博集合中的命名实体构成.因此事件的核心词、地点和参与者包含了微博集合的主要信息. 我们在3个组装的故事上调节权重系数cp和cc.首先,我们使用多组权重系数构造故事骨架.然后,我们依据骨架是否反应故事的发展过程对多个故事骨架排序,并依据排序结果设定cp=0.3和cc=0.7. 算法3.故事骨架构造算法. 输入:故事s的事件集Event_set={e1,e2,…,e|Event_set|}; 输出:故事的骨架skeleton. Construct.Story.Skeleton(Event_set); ① 基于Event_set创建一个按时间升序排列的事件列表event.list; ②skeleton←null; ③event2branch←null;*事件到分支映射* ④ fori=0 toevent.list.size-1 do ⑤event.parent←null;*父事件结点* ⑥edge.weight←0;*与父事件结点边的权重* ⑦ forj=0 toi-1 do ⑧j2i.weight←compute.weight(event.list,j,i);*依据式(2)计算事件j到i的有向边权重 * ⑨ ifj2i.weight>edge.weightthen ⑩event.parent←event.list.get(j); branch); branch); 故事骨架构造的伪代码如算法3所示.给定故事s的事件集Event_set,算法3为故事s构造并返回故事骨架skeleton.算法计算弱连通分量的同时构造弱连通分量的最大生成树.首先,我们依据事件的时间升序排列事件(行①).然后,我们遍历事件(行④~).我们计算事件event与任意时间在event之前的事件间的有向边权重,并寻找最大的权重和对应的父事件event.parent(行⑤~).若存在父事件,则事件event属于事件event.parent所在的分支,并在分支中添加从事件event.parent到事件event的边(行~),否则,构造新的只包含事件event的分支branch(行~).最后,我们返回故事骨架skeleton(行). 时间复杂度分析.升序排列事件花费的时间为O(|Event_set|lb(|Event_set|)).构造弱连通分量集和最大生成树需计算任意2事件间有向边权重,花费的时间为O(|Event_set|2).总花费时间为O(|Event_set|2). 2.3.2 故事摘要提取 在故事摘要阶段,我们依据故事的事件集为故事提取便于用户了解故事概述的摘要.为使用户从摘要了解各分支内容,故事摘要应包含各分支内容.事件描述便于用户理解事件,因此,我们基于故事的事件集提取几个事件描述作为故事摘要.首先,我们用TextRank[12]为各分支提取摘要;然后,我们将各分支的摘要合并为故事摘要. 算法4.故事摘要提取算法. 输入:故事骨架skeleton; 输出:故事摘要story_summary. Extract.Story.Summary (skeleton); ①story_summary←null; ② for eachbranch∈skeletondo ③branch_description←merge.description(branch);*将分支内所有的事件描述合为分支描述* ④branch_summary←TextRank(branch_description); ⑤story_summary.add(branch_summary); ⑥ end for ⑦ returnstory_summary. 故事摘要提取的伪代码如算法4所示.给定故事s的故事骨架skeleton,故事摘要提取算法为故事s提取并返回故事摘要story_summary.我们生成各分支摘要,并将各分支摘要合并成故事摘要(行②~⑥).首先,我们将分支branch中所有的事件描述合并为分支描述branch_description(行③),并用TextRank从文章branch_description中提取分支摘要branch_summary(行④);然后,我们将分支摘要branch_summary合并到故事的摘要story_summary中(行⑤),并将其返回(行⑦). 针对第2节中提出的方法,我们在本节进行实验验证.首先,我们介绍实验设置;然后,我们评价事件检测、故事组装和故事脉络生成3个组件的性能,并展示我们提出的方法较于已有方法的优势. 实验运行在2个Intel Xeon E5-2650 v3 CPUs,64 GB内存的机器(64 b Windows7旗舰版系统)上.新浪微博数据集包含从2016-06-01—2016-08-31的共2.16亿条微博.我们将时间片设为10 min,即每10 min检测一次事件.在该微博集我们共检测19.8万个事件. 本节主要评价事件检测的性能.首先,我们构造测试集;然后,我们评价2个事件检测算法Ring[9]和MetroMap[1]的性能. 算法MetroMap依据微博构造词共现图,基于词共现图用社区检测算法检测紧密连接的词社区,用词社区表示事件. 我们提出的框架(事件检测、故事组装和故事脉络生成)需要关联事件.框架是否合理依赖检测的事件间是否存在关联.事件核心词集合的重合度可以反映事件间的关联性.我们使用冗余度指数redundancy-ratio计算事件集E含有关联事件的事件所占的百分比: (3) 其中,E表示事件集;δ是0到1间的实数,表示阈值;ei表示事件;I(ei,E,δ)是示性函数,表示事件集E是否存在与事件ei相关联的事件.若事件集E存在事件ej(ei≠ej),且cos(corewordei,corewordej)>δ,则I(ei,E,δ)=1;否则I(ei,E,δ)=0. 事件检测使用的数据集包含2016-08-11—2016-08-13共3 d 780万条微博.我们用该数据集构造3个测试集.其中,测试集A由2016年8月13日的微博构成,测试集B由2016-08-11—2016-08-12的微博构成,测试集C由2016-08-11—2016-08-13的微博构成. Ring和MetroMap的冗余度指数如图5所示.在测试集C上,当阈值δ=0.1 时,Ring的冗余度指数大于82%,MetroMap的冗余度指数是100%.Ring和MetroMap检测的大部分事件至少有一个关联事件.这说明我们提出的自底向上的框架(事件检测、故事组装和故事脉络生成)的合理性. 在图5(b)中,MetroMap的冗余度指数随着阈值的增加轻微地减小,这说明MetroMap检测的事件存在大量重复事件.在图5(a)中,Ring的冗余度指数对阈值很敏感,这说明较于MetroMap,Ring检测到事件的多样性更好.同时,事件可能与另一天的事件相关联.因此,当数据集变大时,冗余度指数也变大. Fig.5 redundancy-ratio at different datasets and thresholds图5 不同数据集和阈值上的冗余度指数 本节主要评价故事组装的性能.首先,我们构造用于评价的故事集,即金标准;然后,我们利用金标准评价我们的故事组装算法、LDA[10]、BTM[13]、GSDMM[14]、DBSCAN[11]和Story Forest[15]的性能. 1) LDA.首先,该方法用主题模型LDA生成事件的主题分布;然后,该方法依据选择标准将事件赋给主题,一个主题对应一个故事. 2) BTM.首先,该方法用主题模型BTM生成事件的主题分布;然后,该方法依据选择标准将事件赋给主题,一个主题对应一个故事. 3) GSDMM.首先,该方法用主题模型GSDMM生成事件的主题分布;然后,该方法依据选择标准将事件赋给主题,一个主题对应一个故事. 4) DBSCAN.该方法用DBSCAN聚类,一个簇对应一个故事.事件间的距离用1减去事件间词的cosine值表示. 5) Story Forest.该方法依据事件核心词与故事核心词的Jaccard系数判定事件是否属于某故事. 构造金标准.我们请2个志愿者将事件检测算法检测的19.8万个事件分组,一个组对应一个故事.首先,一个志愿者对2016-06-01—2016-07-15的事件分组,另一个志愿者对2016-07-16—2016-08-31的事件分组.然后,一个志愿者查看另一个志愿者的分组结果,被2个志愿者认可的分组结果才会被保留.最后,为分析有演化过程的故事,我们移除包含4个及以下事件的故事.最终我们构造了共包含1 011个事件的41个故事. 我们使用已有的评价方法[16-17]评价故事组装的性能.我们将人工标注的故事称为金标准故事,将故事组装算法组装的故事称为组装故事.对任意一个金标准故事g,我们计算该金标准故事与任意组装故事a的相似度,并将有最高相似度的组装故事ag映射到金标准故事g: (4) 其中,sim(g,a)是金标准故事g和组装故事a的相似度;Event_setg是金标准故事g的事件集;Event_seta是组装故事a的事件集;|·|代表集合中元素的个数;∩代表集合的交集. 然后,我们计算F1值: (5) (6) (7) 其中,g是金标准故事,Event_setg是金标准故事g的事件集.ag是映射到金标准故事g的组装故事,Event_setag是组装故事ag的事件集,G是金标准. 3.3.1 参数调节 我们调节6种方法:我们的故事组装算法、LDA、BTM、GSDMM、DBSCAN和Story Forest,调整参数的方式为: 1) LDA,BTM和GSDMM.我们在标注故事集上调节3个方法的参数,alpha,beta和初始故事数Ns.首先,我们固定beta和Ns,从0.1~1之间,以0.1为步长调节alpha,并取得最优值;然后,我们选择取得最优值的alpha并固定Ns,从0.01~0.1之间,以0.01为步长调节beta,并取得最优值;最后,我们选择取得最优值的alpha和beta,从50~500之间,以50为步长调节Ns,并选择取得最优值的Ns.当2个参数设置取得相似结果时,我们参考文献报道的BTM和GSDMM中所使用的参数设置. 2) 本文方法.我们使用最优的LDA配置(alpha=0.1,beta=0.03),并用网格搜索调节初始故事数Ns、最小点数minpts和半径radius参数.其中Ns∈{50,100,150,200,250,300,350,400,450,500},minpts∈{2,3,4},radius∈{0.6,0.65,0.7,0.75,0.8}. 3) DBSCAN.我们用网络搜索调节最小点数minpts和半径radius参数.其中minpts∈{2,3,4},radius∈{0.6,0.65,0.7,0.75,0.8}. 4) Story Forest.我们从0.01~0.1以0.01为步长调节阈值.当阈值增加时,性能下降.因些,我们没有测试阈值大于0.1的性能. 3.3.2 性能评价 6种方法在不同初始故事数的性能(F1)如图6所示.因为空间限制,我们只展示在5个不同的故事数({50,150,250,350,450})的结果.使用显式语义信息组装故事的Story Forest和DBSCAN有较差的性能,这说明显式信息不能有效地组装故事.DBSCAN最优的结果准确率为0.706,召回率为0.459,这证明DBSCAN聚类得到的簇粒度较细,即只能将词相似度较高的事件聚到相同的簇.当初始故事数在[50,450]时,我们的方法和LDA的性能优于 BTM和GSDMM.我们的方法使用DBSCAN降低LDA初始化时的随机性,有比LDA更好的性能. Fig.6 Performances at different story number Ns图6 各算法在不同初始故事数Ns的性能 我们对比我们的方法和LDA在不同的参数(初始故事数Ns、最小点数minpts和半径radius)的性能.当minpts在[2,4]、radius在(0.65,0.75)和Ns在[100,500]时,我们的方法取得了比LDA更大的F1值,实验结果见附录A. (8) 不同的Gibbs Sampling迭代次数Ni ter的性能如图7所示.当Ni ter=1 000时,4个方法都达到最优性能;当Ni ter=200时,LDA没达到最优性能,而我们的方法达到最优性能.我们依据式(8)计算LDA和我们的方法在Gibbs Sampling迭代过程的收敛值,并展示在不同的收敛阈值下LDA和我们的方法需要的运行时间.我们的方法用DBSCAN降低LDA初始化时的随机性,比LDA收敛更快,实验结果见附录B. Fig.7 Performances at different iteration number Ni ter图7 各算法在不同迭代次数Ni ter的性能 Fig.8 Running time of different story assembly methods图8 不同故事组装方法的运行时间 在相同的迭代次数(1 000),我们在改变数据集(事件数)和参数(初始故事数)的情况下对比运行时间.效果最好的3个方法,即本文方法、LDA和GSDMM的运行时间如图8所示.GSDMM所需的 时间最多.我们的方法用DBSCAN的聚类结果初始化LDA,在相同的迭代次数下本文方法比LDA的运行时间略高.本文方法比LDA收敛快,在实际运行中可通过减小迭代次数缩短运行时间. 综上所述,本文方法有最优的F1值;本文方法较LDA收敛快,即实际运行过程中本文方法比LDA需要的运行时间少. 本节主要评价故事脉络生成的性能.我们基于3个组装故事(Case 1,Case 2,Case 3)对比我们的方法、Timeline[18]和 Story Forest[15]的性能. 1) Timeline.该方法基于事件的时间先后关系线性的关联事件. 2) Story Forest.该方法首先判断新事件与已发生事件是否重复,若重复则将2事件合并.该方法然后为非重复的新事件选择父节点.该方法计算新事件与已有事件的连接强度(作者自定义的函数).如果最大的连接强度小于阈值,则新事件的父亲为故事的根结点,否则新事件的父亲为连接强度最大的事件. Case 1.中国维和部队遇袭.北京时间2016年6月,联合国在巴里加奥的多层面综合稳定特派团营地被汽车炸弹袭击.中国维和部队中1人牺牲、多人受伤.同年7月,中国维和部队在南苏丹执行任务时被炮弹击中,有2人牺牲、多人受伤. Case 2.万科股权之争.中国A股市场上规模最大的并购与反并购攻防战.2015年12月17日,万科股权之争正式进入正面肉搏阶段. Case 3.2016里约奥运会.2016年里约热内卢奥运会于2016-08-05—2016-08-21在巴西里约执内卢举行. 我们基于用户体验的方式评价性能.首先,我们将12个志愿者随机平均分成6组.然后,我们将3个组装故事在3个不同方法下的结果*https://github.com/liyingrenjie/storyline2(共9个故事脉络)随机呈现给6组志愿者,并请志愿者在准确性(该脉络是否描述故事的发展过程)和理解性(该脉络是否有助于用户理解故事)2方面对3个方法排序,即针对一个结果志愿者对其进行排序,即最好为1,次好为2,最差为3.最后,我们将排序的算数平均值做为评价故事脉络生成性能的指标.准确性从微观上评价故事脉络,即故事脉络中事件间的连接是否合理.理解性从宏观上评价故事脉络,即故事脉络是否从大体上易于用户理解故事的主要内容. 基于试点用户体验的故事脉络生成的性能评价如表2和表3所示.相同算法在不同案例下的评分不一样,这说明故事脉络的评价存在主观性.我们的方法在3个案例下的准确性和理解性都有最靠前的排名.这说明,较于Timeline和Story Forest,用户倾向我们方法生成的故事脉络. Table 2 Accuracy by a Pilot User Experience Study表2 基于试点用户体验的故事脉络生成的准确性 Table 3 Comprehension by a Pilot User Experience Study表3 基于试点用户体验的故事脉络生成的理解性 附录C列出2位志愿者对不同方法的评价.从故事脉络和志愿者评论可看出,我们的方法兼顾了准确性和理解性.我们的方法既可区分故事中相对独立的分支以便于用户理解故事,又在分支内能较好体现事件的关联关系. 故事脉络生成问题在社交网络[18]和传统媒体[19-21]都有相关研究.传统媒体的内容严谨而完整,一篇新闻可完整地描述事件.社会网络的文本短小精悍,具有碎片化和语法不标准等特性.一条微博可能只包含事件的碎片化信息.基于文章可描述事件的方法[19,21]直接用于社交网络可能得不到理想的效果. 解决故事脉络生成问题的方法大致分为2类:分步法和整合法.分步法将问题形式化为多个组件,即事件检测、故事组装和故事脉络生成;整合方法则尝试构造一个统一模型来解决该问题. 1) 分步法.这里我们分别对事件检测、故事组装和故事脉络的相关工作进行回顾.①事件检测.Lee等人[22]将社交网络流建模为动态微博网络,并将网络中紧密连接的微博集合做为事件.Story Forest[15]对新闻文本流聚类,并将簇做为事件.②故事组装.Story Forest[15]依据事件与已有故事的语义距离将事件分配到特定故事.③故事脉络生成.Lee等人[22]用事件间的Jaccard系数追踪事件间的演化关系.Story Forest[15]在故事内依据自定义的函数生成故事脉络.Lee等人[22]用关键词集合表示事件,不利于用户理解事件.Lee等人[22]依据事件的微博相似度是否大于阈值判定事件的演化关系;这种方法存在2个问题:①只能连接相似度较高的事件;②会引入一些不必要的连接. 2) 整合法.CHARCOAL[23]用提出的概率图模型对新闻文章间的联系(link)建模,对故事的进展(progress),并通过新闻文章间的联系生成故事脉络.单个微博可能不包含事件的所有关键信息(例如地点和参与者),因此CHARCOAL不能直接用于社交网络.DSEM[24]和DSDM[25]用非参数化的生成模型同时提取事件的结构化表示和事件在连续时间片的演化模式.MEP[26]用基于非负矩阵分解的主题模型同时检测事件和连续时间片的事件的演化.然而,这些模型只能追踪连续变化的模式,难以对时间跨度大、不连续的故事内事件间的演化进行追踪. 在社交网络通过故事脉络对事件及事件间的演化建模具有重要意义且极具挑战.我们将故事脉络生成问题形式化为事件检测、故事组装和故事脉络生成3个连续的组件,并提出了解决框架.我们提出用包含摘要的有向无环图可视化故事的发展过程.新浪微博数据集上进行的实验表明我们的方法能有效展示故事的发展过程.社交网络存在大量的用户关系、用户行为和用户画像等信息,且用户是社交网络的主要参与者,这些信息对于故事脉络生成有重要参考价值.社交网络每天产生大量的数据,online的故事脉络生成方法便于大规模部署.如何将方法修改为online的模式并融合用户信息是下一步的研究工作.3 实验与结果
3.1 实验设置
3.2 事件检测实验结果及分析
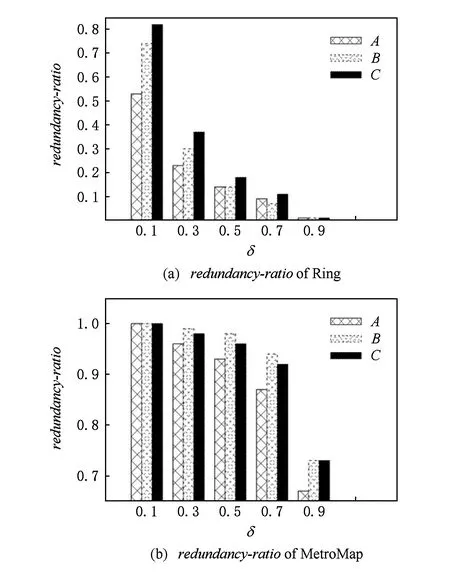
3.3 故事组装实验结果及分析

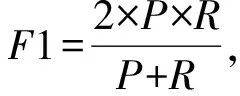


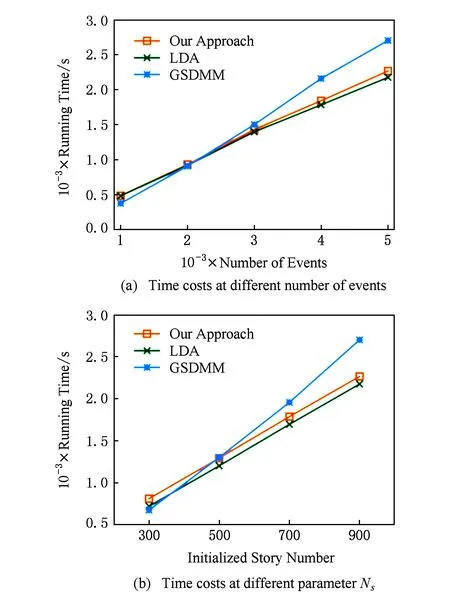
3.4 故事脉络生成实验结果及分析


4 相关工作
5 总结与展望
猜你喜欢
军事文摘(2022年14期)2022-08-26
军事文摘(2022年14期)2022-08-26
军事文摘(2022年12期)2022-07-13
少男少女·教育管理(2022年3期)2022-05-12
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机系统应用(2021年10期)2022-01-06
乐府新声(2021年1期)2021-05-21
当代陕西(2020年21期)2020-12-14
创造(2020年11期)2020-03-19
学生天地(2019年28期)2019-08-25
