
大数据环境下的矿产知识库构建:以钨矿为例
2018-09-20 05:24:10常力恒朱月琴汪新庆刘雨江
中国矿业 2018年9期
常力恒,朱月琴,汪新庆,张 旋,刘雨江,吴 硕
(1.中国地质大学(武汉)资源学院,湖北 武汉 430074; 2.自然资源部地质信息技术重点实验室,北京 100037; 3.中国地质调查局发展研究中心,北京 100037; 4.中国科学院大学,北京 100049;5.北京语言大学出版社,北京 100083)
1 大数据环境下地质知识库构建面临的机遇和挑战
1.1 机遇
目前,随着地质资料信息化工作的推进,形成了大量结构化、非结构化数据。地质数据中非常重要的一部分是以文献、报告等自然语言进行表示的。地质文献作为研究成果的高度总结,包含地质过程发生的时间、空间、特征要素以及与周围环境的相互作用、成因耦合等信息。因此,如何从这种泛结构化的、模糊的、定性的海量地质文献报告中快速的提取数据,并以获得的大样本数据,综合、分析、挖掘地质资料中的潜在价值,更好的服务于地质科学问题的研究是目前面临的任务和机遇。物联网、云计算、虚拟化等信息技术的发展以及多节点分布式的大数据平台建设,为海量数据的高性能计算提供了条件。机器学习、深度学习、人工智能等技术的革新为地质大数据的研究提供了方法。
2017年11月“地质云”平台发布,2018年2月《岩石学报》出版了“地质大数据”专辑,2018年4月在广州中山大学举办了“全国大数据与数学地球科学”学术研讨会,2018年5月在杭州浙江大学举办了“大数据时代——地质学的挑战与机遇”学术研讨会。应用大数据的思维方法,开展数据的相关性分析,构建地质知识库,实现问题的智能分析求解,已成为发展趋势。
1.2 挑战
尽管目前知识库构建技术已逐渐成熟,但在实际应用中依然面临巨大的困难和挑战。在地质领域中,数据类型众多,数据描述无统一规范,因此在分词的过程中会出现信息丢失。如何准确的对地质术语进行自动识别、划分,是构建知识库,进行知识计算面临的重要问题。由于地质数据具有时间跨度大、空间覆盖范围广、数据关联性强、不确定性等特点[1-2],导致对于地质实体关系高度复杂,地质现象、地质过程的形成机理及规律性无统一的认识。因此,在知识的汇聚融合中会出现知识冲突,并随时间变化会不断形成新的认识,甚至否定原有认识。如何综合不同数据源的资料,构建统一知识库也是目前面临的问题。
1.3 地质知识库构建的意义及应用
区域成矿预测是分析研究区的地层、大地构造、蚀变、岩浆岩等成矿地质条件以及物化探异常信息,进行综合评价圈定找矿靶区[3]。目前,成矿预测主要分为以数据驱动和以知识(模型)驱动为主的两类方法。数据驱动是从数据中发现规律并进行预测,知识(模型)驱动是研究成矿规律,总结找矿标志特征及找矿模型。地质数据平台的建设及数据汇聚体系形成,提供了地质条件分析的数据源。因此,如何充分利用数据,发现数据中存在的本质关联特征,从数据中提取控制成矿的关键信息,构建地质知识库,建设地质大脑,对于认识矿床的形成原因,圈定预测靶区具有重要意义。
我国钨矿资源丰富,类型多样,分布相对集中。总结不同类型钨矿的地质条件特征,构建钨矿知识库,对于研究钨矿成矿规律以及深部矿产预测具有一定的指导作用。
目前,知识库的应用主要有智能语义搜索[4]和问答系统[5-6]。而研究人员关注的更多为应用知识库如何解决目前面临的问题,如成矿谱系形成的特征分析及关键控制因素,板块运动下物质循环与致矿异常的形成机理分析。因此,综合知识库可以开展地质实体(矿床、控矿要素、岩体)空间关联性分析,理清物质相互作用过程。对于地质信息工作者可以从知识计算、智能分析推理进行研究。
2 大数据环境下知识库构建
知识库是针对某一领域问题求解的需要,将具有相互联系的知识集合经过组织、分类,并按一定的表示方式在计算机中存储,这些知识包括与领域相关的理论知识、事实数据及专家经验知识[7-10]。建立钨矿知识库的目标是探索以数据驱动的思想自动分析不同钨矿类型形成的主要控制因素,定量分析地质实体的相关性。
2.1 知识库构建现状
目前,大量的学者对知识库构建进行了研究。朱木易洁等[11]介绍了知识图谱的构建方法及构建过程;刘峤等[6]、漆桂林等[12]分析了知识库构建的主要技术;刘峤等[6]对知识库构建目前存在的问题进行了分析。另外在不同学科领域,构建了大量的知识库。何凯涛等[13]论述了数字矿床模型的概念,采用树状结构,建立不同类型铜矿床的矿床地质知识模型,采用产生式规则表示法,构建了规则知识库;邢宝荣[14]分析了储层构型要素及几何特征,采用层次分析法,构建了辫状河储层地质知识库;钟秀琴等[10]基于OWL本体与Prolog规则构建了平面几何知识库;闫洪森等[15]基于本体的思想构建了茶叶领域的知识库。Li等[16]构建了判别鱼类病症的规则知识库。另外,国内外互联网公司也推出了自己的知识库产品,如百度的知心、谷歌的Knowledge Graph、维基百科的Wikidata、微软的Probase。
2.2 要素模型
建立钨矿知识库,需要对知识类型进行分类,确定知识存储的数据模型。矿床数据模型可以分为矿床模型和找矿模型。矿床模型研究的是矿床形成原因及机理,预测要素模型反映了矿床所处的地质环境及物化遥等特性。根据《Mineral Deposits Models》一书中对矿床地质环境的描述,模型包括岩石类型、结构构造、成矿时代、沉积环境、构造、伴生矿床、矿化蚀变、矿物特征等[17]。矿床学的书籍中也对矿床研究的主要内容进行了说明和论述,内容包括大地构造环境,物质组成、物质来源及成矿过程,成矿控制因素,地层、构造、岩浆岩、围岩蚀变与矿床关系,成因机理,矿体形态特征及时空分布规律等[18]。关于找矿模型,成秋明在文献[19]中说明了找矿标志组合包括成矿有利构造环境、有利围岩条件、有利构造条件、岩浆条件、矿体结构与构造、矿石矿物、围岩蚀变、微量元素组合、磁异常、重力异常等。综合矿床模型及找矿模型建立了钨矿知识库存储的数据模型,包括大地构造环境、围岩条件(岩石类型,结构构造)、构造条件、岩浆条件(岩石组成、来源)、矿体条件(组成、结构构造)、矿石矿物、成矿时代、蚀变、元素异常组合等(表1)。

表1 知识库要素模型
2.3 钨矿知识库构建
根据全国矿产资源潜力评价钨矿数据、对钨矿文献信息提取的结果,以及要素模型对数据进行整理,建立钨矿知识库。根据《重要矿产预测类型划分方案》[20],将钨矿预测类型划分为石英脉型、矽卡岩型、斑岩型、云英岩型、陆相火山岩型、沉积变质型、层控矽卡岩型和砂矿型等8种。在对数据的整理过程中,预测类型还包括类似A-B形式的复合类型。目前共形成105条记录。由于每条记录所包含描述信息较多,下面仅以一例说明知识库存储结构及数据(表2)。

表2 钨矿知识库中数据(示例)
3 钨矿知识库实践及应用
知识库的建立是为了使计算机能够分析矿床形成条件,从而预测在不同的地质条件下矿体赋存的概率。本文以数据的分类为例说明知识库应用的一个方面。分类是根据事物的组成、性质、功用等不同表现方面,依据属性特征的差异性对事物进行划分,将某方面特征相似的事物进行归并。对于矿床则表现在构造环境、物质来源、形成过程等多个方面。正确的划分矿床类型对于认识、指导生产实践具有重要意义。
实验数据为1例从数据库中抽取并去除预测类型的钨矿记录。由于数据量占篇幅原因选择记录中的成矿岩体、赋矿地层岩性、矿物组合、蚀变4个特征属性作为数据分类的计算变量。
分类计算的核心是通过字符串的模糊匹配,分别计算测试数据的每一特征要素与数据库中匹配特征要素的相似度,累加求和所有特征要素相似度,选择每一种预测类型相似度最高的值,最后将所有预测类型对应相似度值进行综合排序,相似度最高对应的预测类型则为实验数据的分类结果。本实验基于python的fuzz.ratio字符串模糊匹配算法,对数据进行分类。其中,匹配程度最高为石英脉型,相似度为46.5%,其次相似度分别为矽卡岩型43.25%,斑岩型38.25%。具体计算结果如图1所示。
实验数据对应类型为矽卡岩型,与计算结果存在一定偏差。根据文献[21]可知广西资源县牛塘界钨矿矿石类型以矽卡岩型为主,次为石英脉型和花岗岩型,矿石品位以石英脉型较高。因此实验数据兼具矽卡岩型与石英脉型特征,与计算结果基本吻合。表3为相似度对比结果表。从表中可以看出筛选的结果数据与测试数据特征要素匹配程度非常相近。
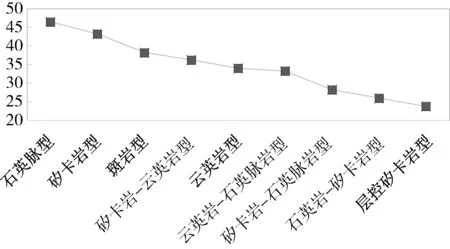
图1 分类计算结果图
表3 相似度对比结果表

数据成矿岩体赋矿地层岩性矿物组合蚀变匹配度广西资源县牛塘界钨矿(测试数据)(矽卡岩型)黑云母花岗、细-中粒黑云母花岗岩或中-细粒白云母花岗泥质粉砂岩和粉砂质泥岩主要金属矿物有白钨矿、黄铁矿、方铅矿;次要有闪锌矿、黄铜矿;脉石矿物主要有石英、石榴子石、透辉石、符山石、绿泥石、方解石。次有阳起石、透闪石、斜黝帘石、萤石、钠长石硅化、黄铁矿化、碳酸盐化、绿泥石化、碱性长石化,角岩化、矽卡岩化广东省南雄棉土窝钨矿(石英脉型)中细粒白云母花岗岩变质砂岩、板岩和石英斑岩矿物组合:金属矿物有黑钨矿、白钨矿、黄铁矿、黄铜矿、方铅矿、闪锌矿、锡石、辉铋矿、辉钼矿、毒砂等;脉石矿物主要有石英(约占90%~95%),其次为长石、绿泥石、电气石、白云母,少量方解石和石膏等硅化、电气石化、黄铁矿化、绿泥石化、绢云母化46.5%特征要素匹配度依次:46%、43%、46%、51%江西省修水香炉山钨矿(矽卡岩型)黑云母二长花岗岩含炭硅泥质灰岩和灰质泥岩、中厚层状条带状灰岩金属矿物有白钨矿、磁黄铁矿、黄铁矿、白铁矿、黄铜矿、闪锌矿、方铅矿等;主要脉石矿物有透辉石、石英、方解石、长石,其次有(绢)白云母、石榴石、透闪石、萤石等云英岩化、硅化、绿泥石化、萤石化和高岭土化43.25%特征要素匹配度依次:35%,42%、52%、44%
4 分析讨论
针对实验结果,查阅了相应矿床地质特征描述的文献资料。根据文献[21]对测试数据广西资源县牛塘界钨矿的赋矿地层岩性描述为灰黑色变质泥质粉砂岩、粉砂质绢灰黑色变质泥质粉砂岩、粉砂质绢云板岩夹大理岩或矽卡岩化大理岩。而知识库中该矿床对岩性描述缺少大理岩或矽卡岩化大理岩等关键词,直接导致计算结果存在偏差。造成这一问题的主要原因在于数据来源的准确性,另一个原因在于字符串匹配算法对于所有词进行同等匹配,即不能识别关键词,未对敏感词赋予较高权重,进而增加结果的准确性。本文仅对第一种原因进行了实验,利用修改后的数据重新计算匹配度,结果见图2。对比图1,图2中包含矽卡岩的预测类型的数据匹配程度更高,结果更为准确。
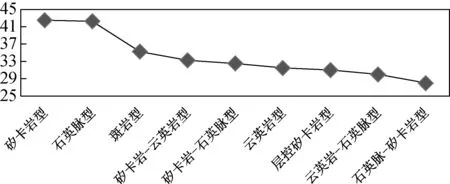
图2 修正测试数据后计算结果图
5 结 语
从多源海量的数据中挖掘知识,分析数据之间的相关性,构建地质知识库对于计算机自动推理、智能分析、辅助决策具有重要意义。因此本文以矿床模型、成矿预测理论为指导,构建了要素模型,结合潜力评价数据和文献资料构建了钨矿知识库。在应用实践方面,以数据分类为例,进行了文本的相似度计算,实验结果表明数据源的质量对结果划分具有重要影响。在数据准确,描述完整的情况下,匹配算法可以很好的识别矿产预测类型。对于另一个问题,计算机自动识别和区分不同要素变量、不同词汇的重要性程度,如何融合地质专家认识对不同信息赋予不同权重进行矿产分类,是下一步工作的研究方向。
猜你喜欢
大众投资指南(2021年23期)2021-12-06 05:46:58
矿产勘查(2020年6期)2020-12-25 02:41:46
制造技术与机床(2019年6期)2019-06-25 10:17:46
中国交通信息化(2016年9期)2016-06-06 07:42:23
岩矿测试(2015年3期)2015-12-21 03:57:04
图书馆研究(2015年5期)2015-12-07 04:05:48
Acta Geochimica(2015年4期)2015-10-25 02:03:16
河北遥感(2014年3期)2014-07-10 13:16:47
吉林地质(2014年3期)2014-03-11 16:47:21
金属矿山(2013年11期)2013-03-11 16:55:03
