
基于规则的多语种音译软件设计①
2018-09-17 08:49梁建飞王军元
计算机系统应用 2018年9期
梁建飞,王军元,刘 敏
(61243部队,新疆 830006)
音译通常用于命名实体的翻译,如地名、人名等,是指利用源语言及目标语言发音规则的异同将源语言形式翻译成目标语言形式[1].由于音译从读音角度处理翻译问题,在处理未登录词翻译问题上有着良好的效果[2],因此在很多跨语言任务如机器翻译[3]、双语地图[4]中有着广泛的应用,其中双语地图对音译的要求非常高,必须遵循严格的音译规则才能得到可供使用的双语注记[4].
目前有大量音译规则可供使用,如联合国地名标准化会议要求:世界各国的地名,要实行单一罗马化拼写,即以罗马语为官方语言的国家,应提供标准的地名拼写形式;使用非罗马语的国家,要制定出非罗马字母转写为罗马字母的转写规则,经联合国标准化会议通过在国际上推广使用.在此基础上,我国国家质量技术监督局最新发布了《外国地名汉字译写导则》,包括英语、法语、德语、俄语、西班牙语、阿拉伯语、葡萄牙语、蒙古语共八种.除此之外,中国地名委员会制定了50个语种的音译规则表,这些规则表依据原语种字母罗马化后的不同发音所对应的国际音标,分为元音字母和辅音字母,由元音字母和辅音字母单独发音或组合发音进行译写.
针对音译的研究一般分为音译等价对挖掘的研究和音译模型构建的研究两大类,前者是指从平行或可比较语料库中挖掘双语音译等价对,构建一个更大更新的音译词典,后者是指使用平行双语语料库进行训练,根据其本身信息及上下文信息自动建立一个音译模型.
根据音译的方式不同,音译方法可分为基于发音的方法和基于字形的方法[5].前者如文献[6],利用源语言发音规则将源语言转换为发音中间体,然后根据目标语言的发音规则将中间体转换为目标语言;后者如文献[7],直接由源语言不经过任何中间体转换为目标语言,这类方法信息丢失最少,音译效果最优.文献[8]综合上述两种方法的优点,提出将音节和字形特征相融合的方法.
根据音节划分的粒度,音译方法可分为以音素为粒度的方法和以字母为粒度的方法.如Knight和Graeh[6]在日英人名音译中,提出以英文音素为粒度,通过发音相似性寻求转换的方法,而Knight[9]和Sherif[10]提出以字母为单位,不考虑发音过程,直接进行翻译.
除上述方法外,文献[11]使用音节相似度模型进行人名翻译;文献[12]通过人工定义规则的方法进行翻译,将英文字母划分为元音字母和辅音字母,切分时则遵循元音字母和辅音字母配对的原则;文献[13]将音节切分问题转换为序列标注问题,把机器学习和统计机器翻译模型用于音译.
现有的研究音译效果还不够理想,主要原因在于音节划分规则不够完善,音节划分错误较多,因此无法满足双语地图对注记的要求.本文提出一种音节划分方法,能够有效避免音节划分错误,从而获得比较理想的音译结果;设计了基于规则的多语种音译软件,利用现有的规则表资源,获得了大量高质量的音译成果.
1 音译流程设计
音译的第一步是选择合适的音译规则表(不同的音译规则表对应不同的通用名词库、专有名词库和特殊规则表),然后查询通用名词库和专有名词库,如果输入的单词出现在这两个库中,直接输出该单词对应的翻译结果,否则进入单词音译模块.由于规则表无法覆盖所有音译规则,因此需要根据特殊规则表对输入的单词进行预处理,然后经过单词拆分、拆分结果优化、单词重组和规则表查询等环节就可得到音译结果.详细流程如图1所示.
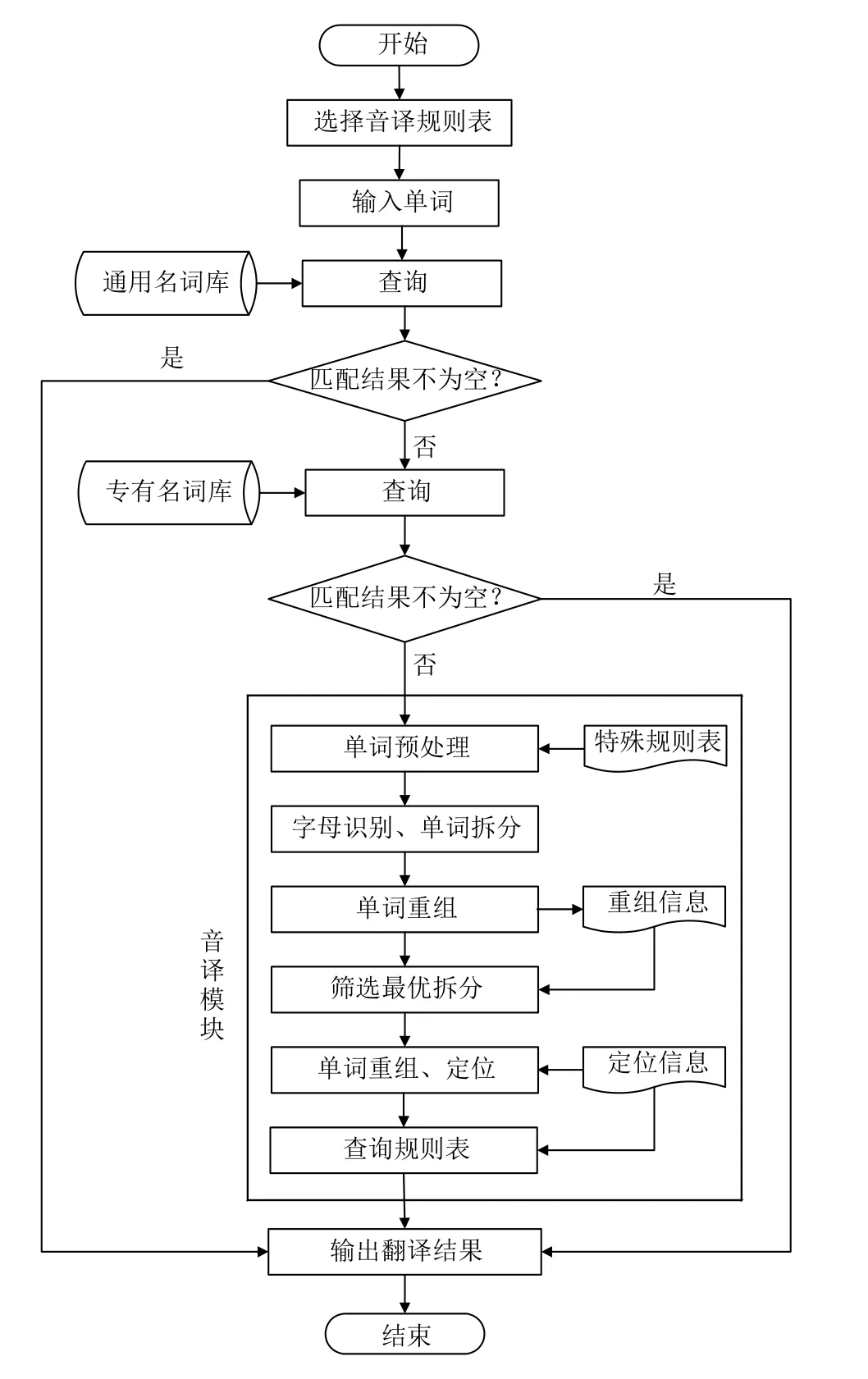
图1 音译流程图
图1中通用名词库、专有名词库、规则表和特殊规则表应按软件要求的格式对数据进行组织.就某个具体领域而言,通用名词的数量是非常有限的,如地图制图领域,涉及到的通用名词如“山”、“河”、“村”、“湖”等.专有名词库的数据源可以是相关语言的双语资源,如人名资源、地名资源等,也可以是经过审核认可的音译成果.规则表和特殊规则表的设计应以权威部门发布的成果为依据,在使用过程中可适当进行修改和完善.基于上述的设计,利用软件能快速获得高质量的音译成果,避免了人工查找规则费时费力、容易出错的可能性.
2 基于规则的音译算法
2.1 单词预处理
单词预处理是依据特殊规则表对源语言单词进行处理,以便新单词利用规则表中的规则获得可信的音译结果.通过对大量数据进行分析总结,制定特殊规则表(以罗马语-汉语为例)格式如表1所示.
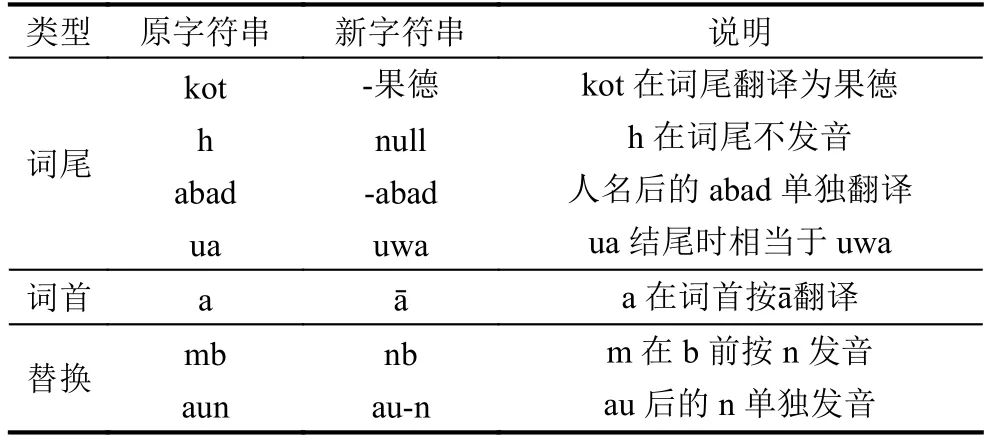
表1 特殊规则表
表1中的例子包含罗马化的普什图语和印地语的部分特殊规则,从中可以看出按替换位置划分,特殊规则可以分为词首、词尾和替换三类,分别表示用新字符串替换单词中词首、词尾和任意位置的原字符串,其中“-”为单词分隔符,“null”表示空字符串.单词预处理的过程比较简单,输入的单词与特殊规则表逐行进行匹配,如果相应的位置上出现原字符串,则用新字符串替换并记录对应的说明信息,用于在最终成果中输出.
2.2 单词拆分
单词拆分的第一步是字母识别,即单词与所有元音字母和辅音字母进行匹配,每个字母的匹配结果用四个参数表示:字母、位置、长度、类型.以罗马语单词“taisar”为例,字母识别的结果为:t 0 1 f;a 1 1 y;i 2 1 y;ai 1 2 y;s 3 1 f;a 4 1 y;r 5 1 f,其中每行的第一列表示单词中的字母,第二列表示该字母在单词中的索引位置,第三列表示字母的长度,第四列表示字母的类型,“f”为辅音字母,“y”为元音字母.根据字母识别结果对单词进行拆分,就是从位置为0的字母开始,搜索位置等于前一个字母位置和长度之和的字母,从而得到一个连续的、不重叠的字母序列,详细算法用伪码表示如算法1.

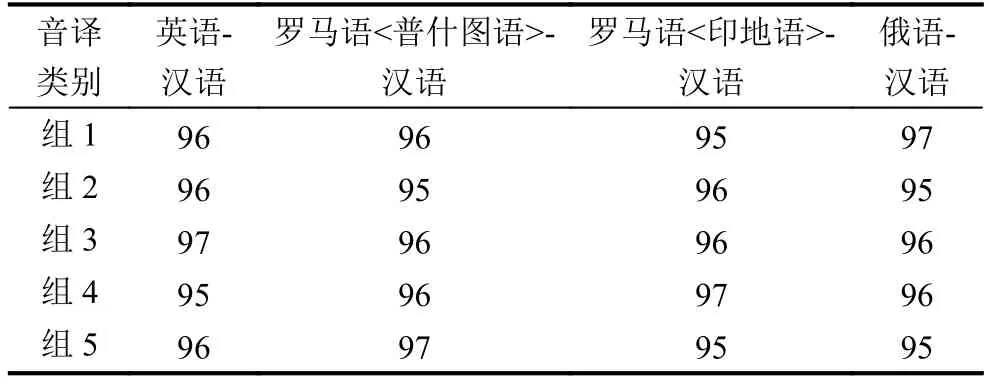
算法1.单词拆分算法1.Hashtable chash;//存储单词拆分结果的哈希表2.Hashtable thash ←(“”,0);//存储过程数据的哈希表3.begin while(End(thash,wlen)!=true)//判断是否结束循环4.chash.clear();//清空哈希表5.begin foreach(object obj in thash)//遍历哈希表6.int s ← obj.value;//搜索位置赋值7.begin for(int r ← 0;r 上述算法中,函数End(thash,wlen)用于判断循环是否结束,其中参数wlen表示待翻译单词的字符串长度,循环结束的条件是哈希表thash中各项的value值均等于wlen.以单词“taisar”为例,单词拆分的结果包含两项:t|a!i!s|a!r|和t|ai!s|a!r|.接下来对这两个拆分结果分别进行字母编组并筛选出最优拆分方案. 单词重组的目的是实现字母编组,方法是用字符“!”对单词拆分结果进行分割,对不同类型的分割结果分别进行处理,原则是尽可能多的出现“辅音字母+元音字母”组合,尽可能少的出现单个元音字母或单个辅音字母组合,详细算法用伪码表示如算法2. 算法2.单词重组算法1.string itext;//单词重组结果2.int gps ← 0;//组合数3.int fys ← 0;//辅音元音组合数4.string[] strs ← split(ctext,”!”);//用字符“!”分割 ctext 5.begin foreach(string str in strs)6.int c ← count(str);//计算 str中字符”|”的个数7.begin switch(c)8.begin case 0:9.itext ←itext+”|”+str+space;//space 表示空格10.gps ← gps+1;11.break; 12.end case 13.begin case 1:14.itext ←itext+str+space;15.gps ← gps+1;16.begin if(!EndWith(str,”|”))//判断 str是否以字符”|”结尾17.fys ← fys+1;18.end if 19.break;20.end case 21.begin default:22.begin if(EndWith(str,”|”))23.string[] ss ← split(str,”|”);24.begin foreach(string s in ss)25.itext ← itext+s+”|”+space;26.gps ← gps+1;27.end foreach 28.end if 29.begin else 30.string[] ss ← split(str,”|”);31.begin for(int i←0;i 上述算法中,针对不同类型的拆分结果分别进行了处理,结果包含重组字符串以及对应的组合数和辅音元音组合数两个参数,用于筛选单词的最佳音节划分.对字符串t|a!i!s|a!r|和t|ai!s|a!r|进行单词重组,得到的重组字符串分别是“t|a |i s|a r|”和“t|ai s|a r|”,对应的组合数分别是4和3,辅音元音组合数均为2. 排除极少数有歧义的情况,对于多个拆分结果,只有一个是正确的,即最佳音节划分.通过对大量音译成果进行分析发现,最佳音节划分具备两个特点:a.组合数最小;b.辅音元音组合数最大,这也符合自然语言的发音规则.因此,单词taisar的最优拆分方案是t|ai!s|a!r|,对应的重组结果即音节划分结果是“t|ai s|a r|”.采用这种策略不仅能获得正确的结果,还能保证结果的唯一性. 根据重组结果确定音译结果,其核心是确定每个组合中辅音字母和元音字母在规则表中的列号和行号,从而定位目标语言项,详细算法用伪码表示如算法3. 算法3.规则表定位算法1.int[][] parrs;//规则表定位结果2.int pf,py;//辅音、元音字母索引位置3.string[] strs ← split(itext,space);//用空格符分割itext 4.begin foreach(string str in strs)5.begin if(EndWith(str,”|”)||StartWith(str,”|”))6.begin if(EndWith(str,”|”)7.int len ← length(str);8.string subf ← str.substring(0,len–1);//去掉 str中最后一个字符”|”9.pf ← pos(subf,flist);//在辅音字母列表flist中定位字母subf 10.parrs ←(pf,1);//将定位信息追加到数组中11.end if 12.begin else 13.string suby← str.substring(1);//去掉 str中第一个字符”|”14.py ← pos(suby,ylist);//在元音字母列表ylist中定位字母suby 15.parrs ←(1,py);16.end else 17.end if 18.begin else 19.int idx ← index(str,”|”);//返回字符”|”在 str中的索引位置20.string subf ← str.substring(0,idx);21.string suby ← str.substring(idx+1);22.pf ← pos(subf,flist);23.py ← pos(suby,ylist);24.parrs ←(pf,py);25.end else 26.end foreach 上述算法中,辅音字母列表和元音字母列表中前两位存储空字符串,辅音字母或元音字母从第三位开始存储,单独辅音字母组合或单独元音字母组合对应规则表的行号或列号为1.根据二维数组parrs中存储的值,可以很方便地在规则表中查找到对应的音译结果.如字符串“t|ai s|a r|”中各个组合对应的定位值分别为(4,7)、(5,2)和(13,1),对应的音译结果分别为“泰”、“萨”和“尔”,因此罗马语单词 taisar的音译结果为“泰萨尔”. 本文提出的算法是在Win7操作系统上用C#语言编程实现的,软件使用到的通用名词库、专有名词库、特殊规则表和音译规则表均独立于软件本身,使用者可根据实际情况单独进行编辑,以满足不同语种音译的需要. 对英语地名单词、罗马化的普什图语地名单词、罗马化的印地语地名单词和俄语地名单词进行实验,分别随机抽取3000个单词,分为5组,每组600个单词,人工检查音译结果并统计正确率,实验结果如表2所示. 表2 正确率统计结果(单位:%) 从实验结果可以看出,音译正确率可达91%以上,通过对音译结果错误的单词进行分析发现,导致错误的原因是:1)个别特殊规则未加入到特殊规则表中;2)未设置好特殊规则的优先级;3)少量单词的最佳音节划分结果不唯一.在接下来的实验中,本文将“连续两个辅音字母按一个辅音字母发音”这一规则加入到特殊规则表中并在单词预处理阶段优先使用,实验结果如表3所示. 表3 本文方法的正确率统计结果(单位:%) 从实验结果可以看出,完善规则表可有效提高音译正确率.现有的音译规则研究成果是音译的重要基础,随着任务的不断拓展和深入,需要不断完善和充实音译规则表,确保音译成果正确可靠.最佳音节划分结果不唯一的单词数量很少,但需人工干预以确定正确的音译结果. 实验结果表明,本文提出的算法能有效解决多语种音译问题,在实际使用中只要设计好通用名词库、专有名词库、规则表和特殊规则表就能获得良好的音译效果.由于本文提出的算法较好地解决了音节划分问题,有效避免了音节划分错误,因此进一步提高了音译正确率,可以满足双语地图、机器翻译对双语资源的需要.2.3 单词重组


2.4 规则表定位

3 实验结果与评价
3.1 算法实现
3.2 实验结果与分析

4 结论与展望
猜你喜欢
现代英语(2021年9期)2021-10-17考试与评价·八年级版(2021年4期)2021-08-14考试与评价·七年级版(2021年1期)2021-08-14汉字汉语研究(2020年3期)2020-12-14考试与评价·八年级版(2020年3期)2020-11-02考试与评价·八年级版(2020年6期)2020-11-02考试与评价·七年级版(2020年1期)2020-10-23英语世界(2018年5期)2018-11-28老年世界(2017年2期)2017-03-16北京大学学报(自然科学版)(2016年1期)2016-10-12
