
基于空间语义的地理编码在智慧城市信息系统中的应用
2018-09-13 09:34昆李明峰周醉蔡炜珩
现代测绘 2018年3期
康 昆李明峰周 醉蔡炜珩
(1.南京工业大学测绘科学与技术学院,江苏 南京211816;2.苏州市测绘院有限责任公司,江苏 苏州215006)
0 引 言
随着地理信息系统(GIS)在我国智慧城市建设中的发展和应用,城市管理部门对空间数据与非空间数据共享整合的要求日益迫切。研究表明,80%以上的城市建设信息均与地理空间位置密切相关[1]。然而,此类信息包含的空间位置大多仅为文字描述,不能直接提取具体的地理位置坐标,难以与现有智慧城市信息系统融合。通过地理编码,可有效建立城市非空间数据资源与空间数据资源的联系,为大众展示直观、便利的基于空间位置服务,搭建辅助决策应用。
地理编码时,由于中文地址表达方式与国外存在差异,不能直接使用国外地址模型,同时,国土、规划等相关行业应用中存在大量非规范中文地址业务数据,导致地址匹配困难[2]。为解决中文地址匹配问题,通常采用文本层级分词比较、模糊匹配等方法,该类方法仅基于文本比较进行地址匹配,匹配率较低。部分研究通过分析地址中存在的空间关系实现地址匹配[3],但由于一个地址元素的描述可能对应多种空间语义,地址元素提取时很难识别当前地址元素的确切空间语义,造成地址解析混乱,难以进行高质量的地址匹配。为此,本文提出基于空间语义的地理编码方法,利用空间关系约束构建地址空间语义模型,通过分层级地址树模型重构目标地址元素集合,以期解决地址元素识别歧义问题,使匹配结果更加精确。
1 基于空间语义的地理编码方法
基于空间语义的地理编码(Geocoding Based on Spatial Semantic,以下简称GBSS)主要包括地址空间语义模型构建、基于分层级地址树的地址标准化以及地址匹配,其技术流程如下所示(图1)。首先,基于分层地址模型建立标准的地址组织规则,结合地址元素空间关系约束,构建地址空间语义模型;其次,通过地名词典将地址字符串切分为地址元素集合,并根据级别对地址要素分层级;再次,针对每一层级地址要素,根据其空间语义约束生成分层级地址树,重新建立地址元素索引,达到消除错误、纠正地址缺陷等效果,形成标准化地址;最后,通过一定的地址匹配方法在参考数据库中进行搜索比对,将匹配到的空间坐标分配给对应地址。
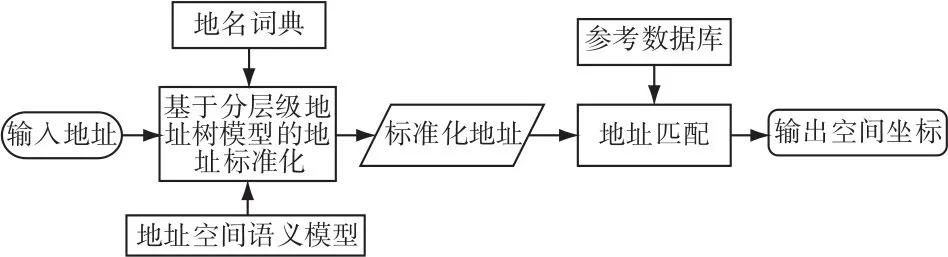
图1 基于空间语义的地理编码流程图
1.1 地址空间语义模型
地址模型解释单个地址的组织和表达方式,并定义地址元素之间的关系。地址元素指向独立的空间实体,具有一定的空间语义。
分析标准中文地址来构建地址模型。标准中文地址主要由行政要素、基本约束对象和本地点位置组成[5]。如城市地址“苏州市姑苏区五卅路第101号”,苏州市和姑苏区属于行政要素,五卅路属于基本约束对象,第101号属于本地点位置,三者构成一个完整的地址,具有这种多层地址特征的地址模型被称为分层地址模型[6]。在此基础上,结合城市地址表达方式,建立地址元素组织规则(表1)。
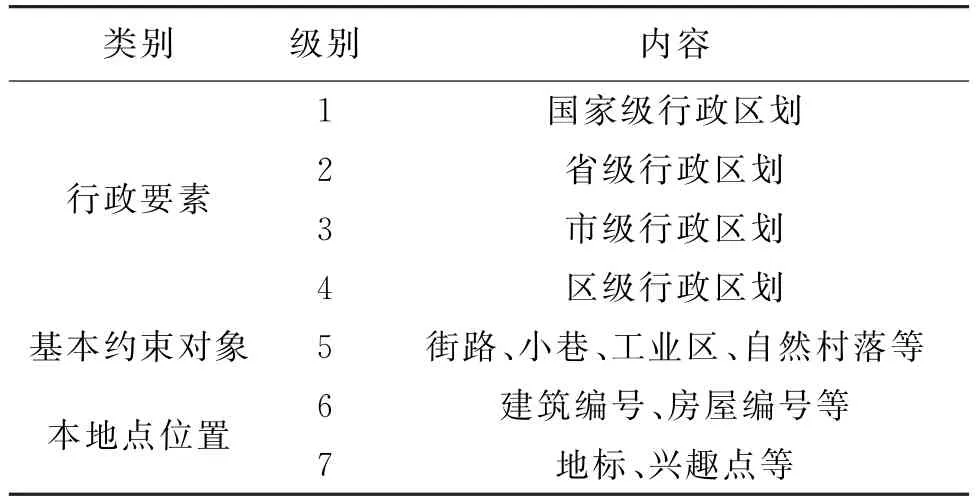
表1 地址元素组织规则
该规则从自然语言描述角度分析地址元素的层级关系,但在表达地址元素的空间关系和约束方面还有很多不足,影响地址解析和标准化的效果。地址元素间存在空间关系,如拓扑关系(包含、邻接等)、距离关系和方向关系。以下显示了具有多种空间关系的苏州某地址(图2),以此作为空间语义关系模型示例,其中“苏州市”、“姑苏区”、“五卅路”和“第101号”地址元素间存在拓扑(包含)关系。
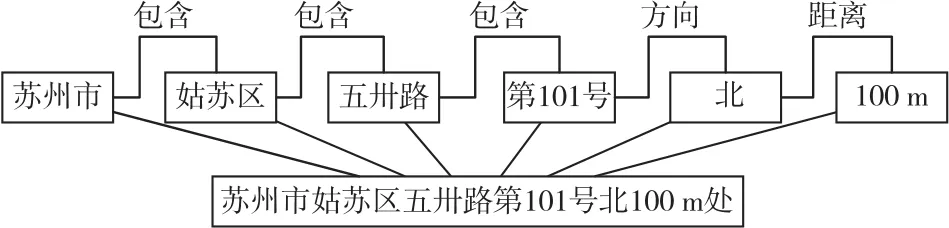
图2 空间语义关系模型示例
从类别上看,行政要素包含基本约束对象,基本约束对象包含本地点位置;从级别上看,各级行政要素存在包含关系;此外,在某些情况下,方向关系和距离关系可能同时存在于本地点位置中,如本地点位置描述“第101号北100 m”,“北”表示方向,“100 m”表示距离。本地点描述组合(“101号”、方向“北”和距离“100 m”)指向一个确切的地理位置。
通过分析表明,完整规范的中文地址普遍存在一定空间限定关系,空间范围从大到小,地址元素级别从高到低,地址的空间关系组成方式就是地址空间语义模型。
1.2 基于分层级地址树模型的地址标准化
地址标准化是地理编码最重要的过程,此过程涉及地址解析和地址规范化两个步骤。地址解析是将输入地址字符串依据地名词典切分为具有精确空间语义的地址元素;在地址规范化中,任何不规范、不完整的非标准地址字符串都将转换为标准格式,并以规范化地址重新记录。地址是地址元素的集合,并允许指向多个不同的空间实体。每个地址元素都具有一定的空间语义,地址元素空间语义是指地址元素构成地址的空间约束规则,主要包含地址元素间的空间关系。在实际操作过程中,地址分词由于地名词典不完善等原因总存在一定的分词错误率,导致同级别的地址元素可能存在多个。
在本研究中,标准化过程基于分层级地址树模型,目的是找到具有正确空间约束关系的地址元素连通路径,以期解决地址元素识别错误问题。标准化过程步骤如下。
(1)解析输入地址字符串并将其组织为地址元素集合X和空间语义集合S。
(2)创建根节点,提取出X集合中最高级别的地址元素(一经提取不再放回X集合),依次创建节点并将其连接到根节点。
(3)继续提取出X集合中级别最高的地址元素,取其中一个作为待连接地址元素,设当前地址树的叶子节点集合为Y,Yi为第i个叶子节点。
(4)将待连接地址元素依次与Yi进行空间约束关系判断操作。遍历待连接地址元素的每个空间语义,评估其与当前叶子节点是否存在一致的空间约束关系,若存在,则将该地址元素连接到当前叶子节点,而后进行与Y中下一叶子节点判断操作;若不存在,则直接进行与Y中下一叶子节点判断操作。
(5)重复步骤3-4,直至每一级别的地址元素与相关叶子节点判断操作结束。
(6)取地址树模型中层级深度最大的一个子树作为具有正确空间约束关系的地址元素连通路径,经过行政级别补全处理后即可形成标准地址。
通过以上过程,可正确地组织一个混乱、不正确描述的地址字符串,标准化后输出的地址可供后续地址匹配处理。
1.3 地址匹配
地址匹配是按照特定规则将标准化处理后的中文地址与地址参考库中各条记录逐一匹配的过程,一旦匹配成功则提取该条参考记录中的空间位置,建立空间对应关系。
地址匹配依据正向最大匹配原则,将不同级别地址要素进行处理比对。首先,尝试准确地匹配低级别(如门牌号码级别)的输入地址;若未找到匹配结果,将地址中下一较高级别(如社区,街道或区域级别)地址要素执行匹配,直至找到结果。最后,输出用于地理映射和空间分析的地理坐标。
地址匹配时,在参考数据库中找到相应的地理实体或地理坐标记录,其中地理实体需根据类型提取空间坐标。行政要素级别的地理实体为面状实体;基本约束对象级别的地理实体为线状或面状实体;本地点位置级别除兴趣点外,多为建筑物,建筑物属于面状实体。当匹配到面状实体时,计算并输出该面状实体的形心点坐标;当匹配到线状实体时,计算并输出该线状实体的中点坐标。
2 测试分析
为验证GBSS方法的有效性,从某街道办事处日常走访记录中抽取一定数量的中文地址进行实验。本实验在该街道10个社区中各抽取1 000条地址作为原始中文地址数据,数据中含有大量的非规范化中文地址。分别采用GBSS方法与模糊地址匹配方法对这些地址数据进行匹配,二者匹配的平均正确率分别为86.2%和46.5%(图3)。
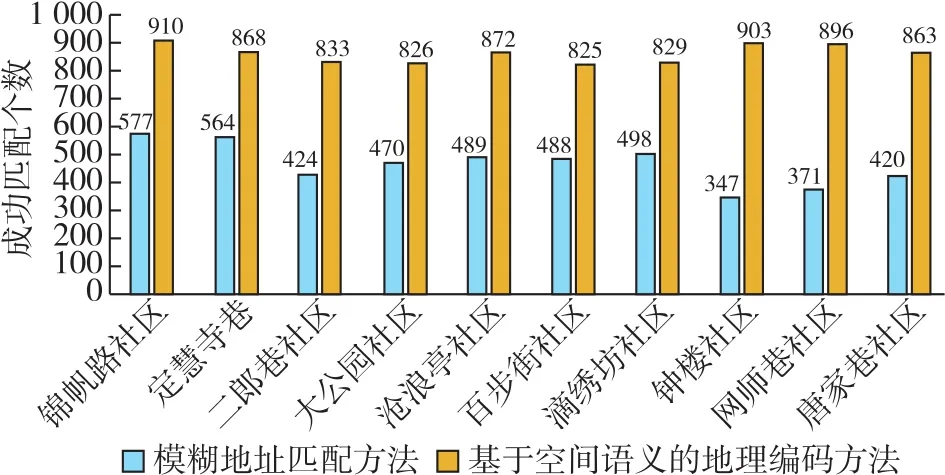
图3 两种地理编码方法实验结果
实验结果表明,本文地理编码方法的平均正确率比模糊地址匹配方法高,且匹配前后数据量基本保持一致,数据匹配效果较好。但在基于GBSS方法的地址匹配中,仍然存在部分未正确匹配的中文地址,这是由于参考地名地址库不够完善和中文地址格式不规范、信息缺失严重等原因造成的。
3 结 语
本文研究了中文地址的复杂性,解释了地址要素之间的拓扑关系,提出了一种基于空间语义的地理编码方法,可有效解析非标准中文地址,从而提高了地理编码的效率和准确性,为智慧城市地址匹配提供了一定程度的技术支持。由于非标准中文地址异常复杂,未来的改进方向将侧重于对地址别名和历史地址的正确处理以及对混乱建筑物号码描述的更好解析。
猜你喜欢
中国典型病例大全(2022年13期)2022-05-10
航天工业管理(2020年9期)2020-12-28
军事运筹与系统工程(2020年1期)2020-09-11
开放教育研究(2020年2期)2020-03-31
廉政瞭望(2019年5期)2019-06-10
小学阅读指南·低年级版(2017年1期)2017-03-13
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
长江学术(2016年4期)2016-03-11
人生十六七(2015年6期)2015-02-28
