
Horspool扩展算法在方块苗文模式匹配中的应用*
2018-09-12 09:28莫礼平刘笔余唐澳斌莫春望
吉首大学学报(自然科学版) 2018年4期
曾 磊,莫礼平,刘笔余,唐澳斌,莫春望,尹 娟
(吉首大学信息科学与工程学院,湖南 吉首 416000)
模式匹配用于解决从目标文本中查找给定模式串的问题,目前广泛应用于信息检索、模式识别、事件检测、生物计算等领域.假设待处理文本为T[0:n-1](长度为n的目标文本),给定子串为P[0:m-1](长度为m的模式),那么从T中找出与P相同的所有子串的问题就是模式匹配问题[1-2].模式匹配可以分为单模式匹配和多模式匹配.单模式匹配是从文本T中查找一个模式P,多模式匹配则是从文本T中一次性查找多个模式串P1,P2…,Pq.英文字符串的单模式匹配是最常见的字符串匹配问题,可用线性或亚线性的KMP,BM和Horspool算法等高效的模式匹配算法来解决.KMP算法[3]是一种消除了朴素模式匹配算法中的回溯问题的前缀匹配算法,该算法属于稳定算法,即使在最坏情况下也能保持线性查找过程,其时间复杂度为O(n+m)[3-4].BM算法[5]是一种后缀匹配算法,采用从右向左比较字符和从左向右“跳跃式”移动模式串的方法,同时应用2种启发式规则(坏字符规则和好后缀规则)计算移动量,并从中选择最大值来决定模式串向右跳跃的距离[5].该算法又属于贪心算法,其时间复杂度在平均、最坏和最优3种情况下分别为O(n),O(m×n)和O(n/m).在实际应用中,其性能优于KMP算法3~5倍[6].BM算法被提出以后,中外学者针对此算法进行了优化,提出了许多基于BM的改进算法[7-13],Horspool算法便是其中最有效的算法之一.Horspool算法以BM算法为基础,但仅利用BM算法的坏字符规则来计算模式串的移动量,固定将匹配窗口的最后1个字符作为坏字符.笔者以Horspool算法为基础,对Horspool算法所处理的字符单位进行扩展,设计了一种适用于方块苗文信息检索的字符串模式匹配算法.
1 Horspool算法
1.1 算法原理

图1 Horspool算法原理Fig. 1 Schematic Diagram of Principle of Horspool Algorithm
为描述方便,将待处理文本T中用于与模式串P进行匹配的文本子串(匹配窗口)记为T[i],…,T[i+m-1](i为子串的起始位置,0≤i≤n-m),T[i+j]和P[j]分别表示文本串和模式串中的当前处理字符(0≤j≤m-1).Horspool算法的基本思想是取匹配窗口的最后一个字符T[i+m-1]为坏字符,将其与模式串的最后一个字符P[m-1]进行比较.如果匹配,就继续从右向左对T和P中的字符逐个进行比较,直到完全相等或者在某个字符处不匹配为止;如果不匹配,就以T[i+m-1]为坏字符,找到坏字符在P中出现的最后位置k(-1≤k≤m-2),将P右移,使T[i+m-1]和P[k]对齐后进行再次匹配.
为了实现模式串的移动,须事先记录各个字符在P中出现的最后位置k及其到P[m-1]的距离.该距离记为Shift[P[k]],表示以T[i+m-1]为坏字符时P的移动量,
Shift[P[k]]=m-1-k-1≤k≤m-2.
当k=-1时,表示当前字符不出现在模式串中,模式串的移动量为m.Horspool算法原理如图1所示.
1.2 算法分析
Horspool算法同BM算法一样,在平均、最坏和最优3种情况下时间复杂度分别为O(n),O(m×n)和O(n/m).因为Horspool算法仅使用坏字符规则来计算模式串的移动量,避免了BM算法使用好字符规则来计算模式串移动量和选择移动量最大值的工作,所以在实际应用中Horspool算法的效率要高于BM算法[10].
1.3 算法示例
假设当前待处理匹配串T为“abcbcsdLinac-codcbcac”,模式串P为“cbcac”,匹配串长度为21,模式串长度为5.表1给出了T中各个字符在P中出现的最后位置,以及根据Horspool算法得到的P的移动量Shift.
Horspool算法应用于英文字符串匹配的过程如图2所示.图2a可知,匹配窗口在位置3处出现不匹配,坏字符“c”对应Shift为2,故将模式串向右移动2个位置.由图2b可知,匹配窗口在位置4处出现不匹配,坏字符“d”对应Shift为5,故将模式串向右移动5个位置.由图2c可知,匹配窗口在位置2处出现不匹配,坏字符“c”对应Shift为2,故将模式串向右移动2个位置.由图2d可知,匹配窗口在位置3处出现不匹配,坏字符“c”对应Shift为2,故将模式串向右移动2个位置.由图2e可知,匹配窗口在位置4处出现不匹配,坏字符“d”对应Shift为5,故将模式串向右移动5个位置.由图2f可知,主串匹配窗口和模式串完全相等,模式串查找成功.
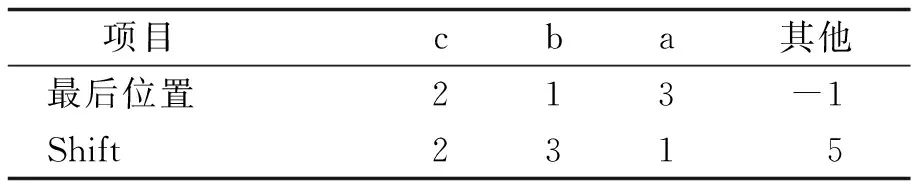
表1 T 中各英文字符在P 中出现的最后位置及P 的移动量
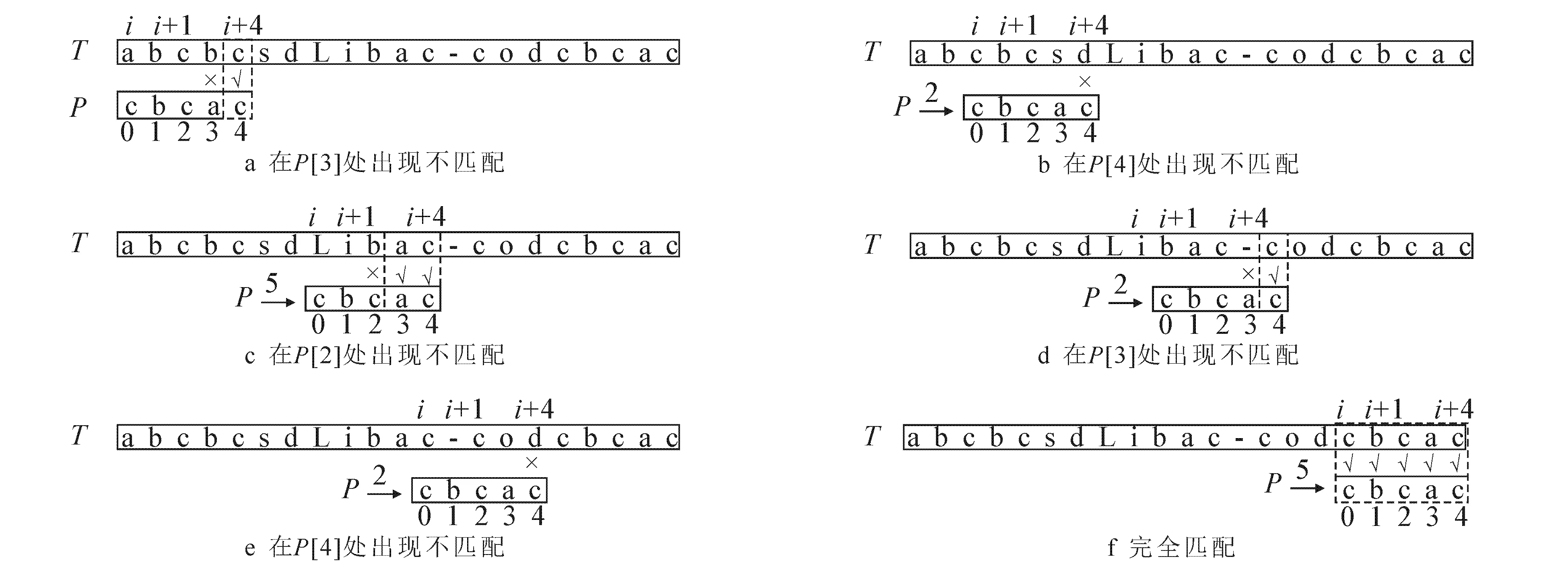
图2 英文字符串匹配过程示例Fig. 2 Example of English String Matching Process
2 方块苗文及其字符串查找的特点
方块苗文是一种仿汉字结构的方块文字,几乎全是合体字.它以假借汉字为主,创造性地运用了形声、会意、假借、象形等手段进行造字,直接取一些易认和易记的汉字、汉字部首和极个别无音无义的纯粹符号(如“~”“X”)作为义符、声符或形符构件,采用一字一音节的方法来标记1个语素或词.[14-16]根据构字方式,方块苗文的1个字就代表1个语素或词.实际应用中,方块苗文的词以单字词和双字词为主,有少量的3~5字词,5字词及以上的极少出现.此外,据已收集的资料可知,方块苗文通常出现在以汉字为主体的苗文歌本和剧本中,并与汉字混合出现.方块苗文字符串匹配主要是从苗汉混合文本中查找一个有意义的方块苗文字符串.相对于英文单词,方块苗文字符串重复出现在苗汉混合文本中的概率非常低,因此模式匹配时,匹配窗口中的字符串子串包含方块苗文且这些苗文正好出现在模式串中的概率很低,匹配失败的次数远远多于匹配成功的次数.一般将某种语言包含的所有文字的集合称为该语言的字母表,1个文字就是1个字符.如果将收集到的所有方块苗文组成的集合视为字母表,那么每个方块苗文都是1个字符.目前已收集到的方块苗文超过1 000个,相对于英文26个字母而言,方块苗文是大字母表环境.大字母表环境中,字母表中字符的重复度远比英文单词中字母的重复度低,有利于产生更大的模式串移动距离.Horspool算法适用于大字母表环境,显然,将Horspool算法用于解决方块苗文的字符串查找问题是合适的.
3 适用于方块苗文模式匹配的Horspool扩展算法
3.1 扩展算法的基本原理
根据方块苗文字符串查找的特点可知,将Horspool算法应用于方块苗文字符串匹配能够产生较大的模式串移动距离,从而有效提高匹配速度.然而,方块苗文采用Unicode格式进行编码,同汉字一样,1个方块苗字由2个字节组成.若把方块苗文按单字节处理,则因字母表最大为256而导致文本中的重复度大大提高,单字节匹配成功的概率加大.此时采用Horspool优化算法不但没有优势,而且可能出现假匹配情况.因此,将Horspool算法应用于方块苗文字符串匹配时,需要对算法进行调整.
笔者使用最简单的方法对算法进行调整,即直接将模式匹配中的字符概念扩展到字,把苗文的2个字节作为一个整体进行处理,只有2个字节完全相等时才视作1个苗字匹配.因此,根据方块苗文字符串匹配的实际需要,在编程实现Horspool算法时,可直接将模式串P和文本串T的类型定义由char*改为word*,并将字符的比较和移动都改为以字为单位.计算机对char和word类型数据的处理时间相同,故Horspool扩展算法的时间复杂度保持不变.
3.2 扩展算法应用于方块苗文字符串模式匹配的示例
假设当前待处理的方块苗文文本T和方块苗文模式串P分别为

表2给出了T中各个字符在P中出现的最后位置以及根据Horspool扩展算法得到的P的移动量Shift.

表2 T 中各方块苗文字符在P 中出现的最后位置及P 的移动量
Horspool扩展算法应用于方块苗文字符串匹配的过程如图3所示.由图3a可知,匹配窗口在P[1]处出现不匹配,坏字符T[i+5]对应Shift为4,故将P右移4个位置;由图3b可知,匹配窗口在P[5]处出现不匹配,坏字符T[i+5]对应Shift为1,故将P右移1个位置;由图3c可知,匹配窗口在P[3]处出现不匹配,坏字符T[i+5]对应Shift为4,故将P右移4个位置;由图3d可知,匹配窗口在P[5]处出现不匹配,坏字符T[i+5]对应Shift为2,故将P右动2个位置;由图3e可知,主串匹配窗口和模式串完全相等,模式串查找成功.
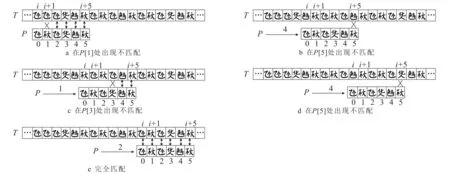
图3 方块苗文字符串匹配过程示例Fig. 3 Example of a Square Hmong Characters String Matching Process
4 方块苗文模式串匹配实验
为了测试算法的性能,选用3段长度分别为8 728,34 079,147 380字的苗汉混合文本作为测试文本T1,T2和T3,针对文本中出现的单字词、双字词、3字词、4字词和5字词这5种情况进行方块苗文字符串的模式匹配实验.实验中选择单字、双字及多字词模式串的原则为模式串在已收集到的苗汉混合真实文本中均具有一定的出现频率.
在Intel(R) Core(TM) i5-3470 CPU @ 3.20 GHz,4G内存,Win7操作系统条件下进行实验,用C++编程实现算法.针对5种情况分别取10个模式串,进行1 500次实验,实验结果列于表3.表3中TextNo,PatternLen,PatternNum,AvgOccurNum,AvgSucMatNum,AvgCompNum,AvgShiftNum和AvgTime,分别表示测试文本编号、模式串长度(对应方块苗文的词类型)、模式串测试个数、模式串出现次数的平均值、模式串成功匹配次数的平均值、模式串字符比较次数的平均值、模式串移动次数的平均值和模式串匹配所耗费时间的平均值.

表3 方块苗文模式串匹配实验结果
根据表3中的实验结果,结合测试文本T1,T2和T3的文本长度之比,对不同长度模式串进行匹配的正确率及所耗费时间进行比较,结果列于表4.表4中CompTextNo,TextLengthRate,AccuracyRate,TimeRate和AvgTimeRate,分别表示对比文本编号、文本长度比率、匹配正确率、匹配所耗费时间比率和匹配所耗费平均时间比率.
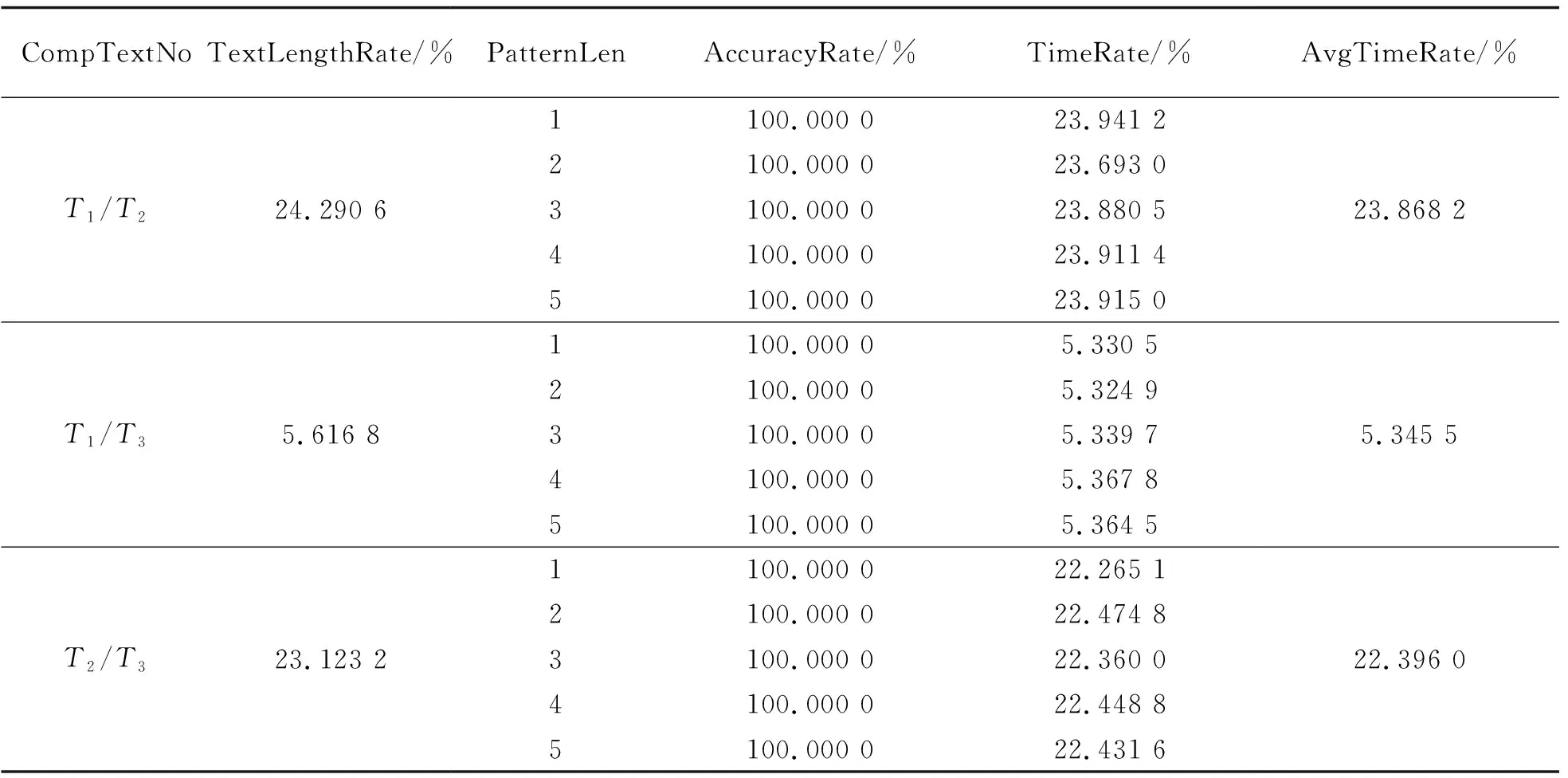
表4 不同长度模式串匹配的正确率及所耗费时间
由表4可知:对3个测试文本中出现的5种长度模式串进行方块苗文字符串模式匹配,Horspool扩展算法均保证了100%的正确匹配率;对应于T1/T2,T1/T3,T2/T3的文本长度之比24.290 6%,5.616 8%和23.123 2%,5种长度模式串所耗费的匹配时间的平均值之比为23.868 2%,5.345 5%和22.396 0%.此结果表明,不同长度字词的模式串,匹配所耗费的时间与测试文本长度均呈线性关系,且耗费时间的降低率快于测试文本长度的增长率.从上述实验数据还可以看出,即使是在10万字以上的苗汉混合文本中进行单字词、双字词和多字词的方块苗文字符串模式匹配,Horspool扩展算法的性能也能得到较好的发挥.
5 结语
当今信息时代,随着计算机及网络技术的不断发展,人们对文本检索效率提出了更高的要求.方块苗文字符串匹配算法是实现方块苗文信息快速检索的关键.结合方块苗文信息的查找特点和存储格式提出高效率的方块苗文字符串匹配算法,对方块苗文的信息化具有很好的理论意义和现实价值.笔者提出的Horspool扩展算法具有思想简单、容易实现的特点.方块苗文字符串的匹配实验数据表明,Horspool扩展算法能够成功应用于方块苗文字符串的模式匹配.下一步拟以该算法为基础,将其与DFA和Petri网建模技术相结合,研究方块苗文多模式匹配算法及其优化技术,以解决苗汉混合文本中方块苗文的并行检索问题.
猜你喜欢
小学生学习指导(低年级)(2022年9期)2022-10-08
数学小灵通·3-4年级(2021年5期)2021-07-16
无线互联科技(2020年11期)2020-12-01
科普童话·学霸日记(2020年4期)2020-05-06
电子制作(2019年13期)2020-01-14
移动信息(2018年1期)2018-12-28
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
科教导刊·电子版(2016年30期)2016-12-26
中国信息技术教育(2015年21期)2015-09-10
山东工业技术(2015年21期)2015-07-27
