
基于不完全信息随机博弈与Q-learning的防御决策方法
2018-09-12 02:18张红旗杨峻楠张传富
通信学报 2018年8期
张红旗,杨峻楠,张传富
基于不完全信息随机博弈与Q-learning的防御决策方法
张红旗1,2,杨峻楠1,2,张传富1,2
(1. 信息工程大学三院,河南 郑州 450001;2. 河南省信息安全重点实验室,河南 郑州 450001)
针对现有随机博弈大多以完全信息假设为前提,且与网络攻防实际不符的问题,将防御者对攻击者收益的不确定性转化为对攻击者类型的不确定性,构建不完全信息随机博弈模型。针对网络状态转移概率难以确定,导致无法确定求解均衡所需参数的问题,将Q-learning引入随机博弈中,使防御者在攻防对抗中通过学习得到的相关参数求解贝叶斯纳什均衡。在此基础上,设计了能够在线学习的防御决策算法。仿真实验验证了所提方法的有效性。
网络攻防;随机博弈;Q-learning;贝叶斯纳什均衡;防御决策
1 引言
近年来,信息安全事件日趋频繁,给网络安全带来了巨大的损失[1]。由于资源和能力的限制,防御者无法保证绝对的安全,因此亟需一种能够对攻防行为进行分析和防御策略选取的技术,使防御者在风险与投入之间达成一种均衡。博弈论与网络攻防所具有的目标对立性、关系非合作性和策略依存性高度契合[2],通过建立网络攻防的博弈模型及对模型的均衡求解来研究攻击行为和指导防御决策逐渐成为一个研究热点[3]。
针对网络防御决策问题,本文首先对网络攻防进行分析。将攻防对抗进行离散化处理,整个过程看作一系列时间片,每个时间片都包含且只包含一个网络状态。网络攻防过程可以用图1(a)进行描述。每个时间片中攻防双方检测当前网络状态,依据状态选择执行攻防动作。网络系统在攻防双方的联合行为作用下由一个状态转移到另一个状态。时间片中的网络状态转移关系如图1(b)所示,网络状态之间的转移不仅受到攻防动作的影响,还受到网络中其他一些复杂因素的影响,这导致网络状态的转移存在随机性。由于网络攻防的非合作性,攻防双方无法完全掌握对手信息,且只能通过检测网络来了解对手的行动,这会比动作的执行时间至少延迟一个时间片,并导致每个时间片中双方不知道对手当前时间片的行动,因此每个时间片是一个不完全信息静态博弈。但从整个攻防过程来看,当前时间片的攻防动作会影响后续时间片的网络状态,进而影响攻防双方的决策,这又是一个动态变化的过程。
本文采用不完全信息静态博弈与马尔可夫决策结合的随机博弈[4]来对网络攻防进行建模分析,其博弈系统在参与人的联合行动下由一个状态转移到另一个状态,符合上述分析的网络攻防对抗过程。
目前,国内外基于随机博弈的网络安全研究已取得一定进展,但是应用在网络安全领域的随机博弈模型大部分基于完全信息假设。文献[5]将攻击者的特权状态作为网络状态,构建完全信息随机博弈模型。文献[6]通过完全信息随机博弈分析攻击者与防御者之间的策略交互,利用纳什均衡指导防御决策。文献[7]提出一种完全信息随机博弈分析方法,保护电网免受协调攻击。文献[8]将随机博弈应用于物联网中用于平衡网络性能与安全水平,其所提方法比其实验中的基准方法更有效。由于网络攻防的竞争关系,掌握对方博弈信息非常困难,上述文献中的完全信息假设不能满足实际需求。因此部分学者开始采用更符合实际的不完全信息随机博弈进行研究。文献[9]针对移动目标防御决策问题,构建不完全信息随机博弈模型,并通过对比分析说明了此模型比其之前建立的完全信息随机博弈模型[10]实用性更高。但是,上述成果均未讨论随机博弈现有收益函数在网络攻防中的适用问题。首先,上述文献的收益函数都以已知转移模型为前提,但在实际中防御者往往无法确定网络状态转移概率,导致无法利用上述文献模型中的收益函数求解均衡。另外,网络具有动态性,其状态转移概率也会不定期变化,但上述文献没有提出相应的解决方案而是假设状态转移概率为定值。以上2点使上述文献的模型实用性较低。

图1 网络攻防
为解决上述问题,借鉴强化学习思想,在不完全信息随机博弈中引入Q-learning[11]算法。据统计,阿里云在2017年仅每天就要遭受16亿次左右的攻击,对于不同攻击者,可能每个攻防场景只会出现一次,但对于以阿里云为代表的防御者来说,其每天都要面对大量相同的攻防场景。通过引入Q-learning算法并将其由一个参与者扩展为可用于博弈的2个参与者,使防御者在大量相同的攻防场景中以增量求和的方式对收益进行在线学习和更新,不需要确定转移概率,就可以求解相应场景的贝叶斯纳什均衡,从而进行防御决策。
目前,Q-learning在攻防领域已得到广泛应用。文献[12]提出一种基于Q-learning的LDoS攻击实时防御机制,该方法具有较好的实时性和灵敏性。文献[13]将Q-learning嵌入软件中,提供一种安全机制,该方法能够较快学会阻止恶意行为。文献[14]基于Q-learning设计了一种有效的智能电网脆弱性分析方法。上述研究取得了一定进展,但其将攻击者作为环境的一部分固定到系统中,不能体现攻防的对抗特点,也无法较好地满足网络攻防的策略依存性。
2 不完全信息随机博弈模型
实际的网络攻防对抗是一个复杂的过程,针对防御策略选取问题,对其进行一些必要的假设和简化。
对参与博弈的攻防双方做出如下假设。
1) 攻防双方都是理性的,追求最大的收益。
2) 防御者对攻击者收益函数的不确定性视为对攻击者类型的不确定性,且防御者对攻击者类型的概率分布有一个判断[11]。
对每个时间片中博弈所需的“信息”和“行动顺序”这2个基本要素做进一步假设。设当前博弈处于时间片中,则在中攻击者类型为其私有信息,双方的共同知识为:①时间片中的状态和对应状态攻防双方可采取的动作;②攻击者在采取的动作,在+1会被防御者观察到,防御者在采取的动作,在+1会被攻击者观察到;③防御者对攻击者类型分布的概率判断。行动顺序:在每个时间片,攻防双方是同时行动的。这里的“同时”是一个信息概念,非时间概念,即尽管从时间概念上攻防双方的选择可能不在同一时刻,但只要攻防双方在行动时不知道对手的选择就认为是同时行动。

常用变量及其含义如表1所示。

表1 主要符号及其含义
在上述基础上构建博弈模型。



采用海萨尼转换[15]来处理不完全信息博弈,引入虚拟参与人“自然”按照相应概率选择转移的状态和攻击者类型,使攻防双方对状态转移的不完全信息和防御者对攻击收益的不完全信息转换成对“自然”行动的不完美信息。在此基础上,依据博弈模型构建一个时间片的攻防博弈树,如图2所示。其中,N为虚拟参与人“自然”,A为攻击者,D为防御者。博弈由上一个时间片转移到当前时间片后,“自然”N按照转移概率先选择当前时间片的网络状态,再按防御者对攻击者类型分布的概率判断选择攻击者的类型,攻击者A和防御者D都能观察N对状态的选择,但只有攻击者能观察到N对攻击者类型的选择。A和D观察后依据策略选择自己的动作并获得回报。当前时间片的博弈结束后,博弈转移到下一个时间片。
3 Q-learning与贝叶斯纳什均衡求解
贝叶斯纳什均衡是攻防双方的最优策略,双方无法再通过单方面改变自己的策略来提高收益。本节主要对随机博弈在网络攻防中求解均衡存在的问题进行研究。
3.1 网络攻防中的均衡求解参数问题





3.2 基于Q-learning的均衡求解参数确定方法

Q-learning是一种被广泛应用的典型免模型强化学习算法,能够求解马尔可夫决策的最大回报和最优策略问题。虽然Q-learning和随机博弈的基础理论都是马尔可夫决策,但是Q-learning中只有一个参与人,其决策只受环境的影响,每个状态下参与人最大收益的动作是固定的,而随机博弈中有2个参与人,其决策不仅受环境的影响,还要依赖于对手的决策,每个状态下对手采取不同策略,自己的最大收益策略也不同,将Q-learning应用在随机博弈中还需要对其进行改进。






图3 防御者学习机制
Q-learning中的环境采用本文II-SGM中的博弈状态进行建模,参与者的行为采用II-SGM中的攻防动作集合来定义。


4 网络防御策略选取
本节首先对将贝叶斯纳什均衡作为攻防策略的合理性以及均衡的存在性进行分析,然后提出结合II-SGM与改进Q-learning的防御策略选取算法并从理论上对算法的收敛性进行分析。
4.1 贝叶斯纳什均衡策略分析
网络攻防具有策略依存性:①防御者在考虑策略时,会对攻击者做出预测并根据预测结果选择收益最高的策略;②攻击者会预测到防御者对自己的预测进而调整自己的策略;③作为理性的防御者,还应该进一步考虑到攻击者会因预测到自己对攻击者的预测而做出调整,此时防御者会进一步优化防御策略;④作为理性的攻击者,也应该考虑到防御者会因预测到自己对防御者的预测而重新调整策略。这是一个螺旋上升的过程,最终攻防双方的最优策略会达到一种稳定状态,此时双方的策略都是对方策略的最优响应,没有人有积极性再去偏离这个结果。根据第3节贝叶斯纳什均衡的定义,均衡中每一个参与人的策略,都是在其他参与人策略下使自己获得最高收益的策略,是针对其他人做出的最优响应,所以贝叶斯纳什均衡是攻防对抗稳定状态的最优策略,防御者选择均衡作为防御策略可以获得最高的期望收益,是合理的。

4.2 防御策略选取算法
算法1 自适应防御策略选取算法
begin

9)repeat:


//对贝叶斯纳什均衡进行更新
end
4.3 算法分析
4.3.1 收敛性分析

在满足上述假设的基础上对算法的收敛性进行分析。

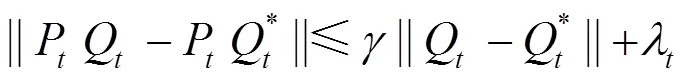
下面,对本文算法是否满足上述3个条件进行分析。
本文算法算子为

条件1)
由于本算法满足假设2,因此条件1)成立。
条件2)

在上述基础上证明如下引理。


联立式(10)和式(12)可知,欲证引理1,只需证明


即可。
当为攻击者时,分2种情况进行证明。


由式(14)和式(15)可知,式(13)成立。

条件3)


由式(16)可知,本文算法满足条件3)。
综上可知,本文算法满足3个条件,所以本文算法收敛。
4.3.2 复杂性分析
5 仿真实验与分析
5.1 仿真实验场景
采用图4所示的典型网络信息系统场景进行仿真实验。Web服务器和堡垒主机部署在非隔离区(DMZ, demilitarized zone),内网由文件服务器和数据库服务器组成。防火墙的安全策略为外部用户仅允许访问Web服务器的FTP、HTTP服务和堡垒主机上的SMTP服务,其他网络节点和端口均进行阻断。所有的攻击均来自外网。参考NVD数据库给出目标网络脆弱性信息,如表2所示。参考美国麻省理工大学的攻防行为数据库[20]给出防御动作,如表3所示。

图4 仿真网络信息系统场景

表2 网络脆弱性信息

表3 防御动作描述
5.2 构建仿真场景的攻防随机博弈模型

表4 网络状态

图5 网络状态转移关系
攻击者类型分布的先验概率为




接下来,在防御者不知道转移概率的前提下,对本文算法的有效性进行测试,仿真实验使用Python2.7实现了本文的防御策略选取算法。
5.3 测试与结果分析
5.3.1 收敛性测试与分析
1)不同参数设置对算法收敛性的影响

表5 实验参数设置


图6 不同参数设置下状态s4的防御策略变化
从图6可以看到,3组参数设置都能够收敛,通过与已知转移概率计算的贝叶斯纳什均衡结果对比可以发现,3组参数设置都能够收敛到正确的贝叶斯纳什均衡,即

不同参数设置的收敛速度不同,设置1在防御200次左右达到贝叶斯纳什均衡,而设置2和设置3在防御350~400次左右达才达到收敛,且设置1在学习过程中的振荡幅度也明显小于设置2和设置3,由此可知,设置1比设置2和设置3更适用于本场景。
2) 不同攻击策略对算法收敛性的影响

图7 不同攻击策略下状态s4的防御策略变化
从图7可以看到,当面对理性攻击者时,本文方法能够在200次左右的学习后快速收敛到贝叶斯纳什均衡策略;当面对非理性攻击者时,防御者仍能够在与攻击者对抗中进行学习,虽然学习过程中振荡幅度比情况1稍大且收敛速度比情况1稍慢,但在400次左右的学习后也能够达到收敛。综上可知,攻击者的策略会对本文方法的学习速度和振荡程度有一定影响,但不会影响最终的学习结果,这说明算法在实际的复杂环境中也能进行有效的防御决策。
5.3.2 适应性测试与分析


算法第16)步中状态s=的防御策略变化如图8所示。
从图8可以看到,初始状态下算法进行了第一次学习并达到收敛,当网络状态转移概率发生变化后,算法能够及时做出反应,进行第二次学习并再次达到收敛。第一次收敛经历了200次左右的学习,而第二次收敛只经历了100次左右的学习,这是因为初始状态只引入了较少的先验知识,所以需要较长的学习过程,而第二次由于网络的动态变化一般比较平稳,通常不会突然发生剧烈改变,由此转移概率的变化幅度较小,利用前一阶段的学习成果相当于引入了较多的先验知识,因此收敛速度较快。综上可知,算法能够在网络动态变化时及时做出调整,适应新的环境。
5.3.3 对比测试与分析
从图9可以看到,本文方法在经过200次左右的学习后收敛到了客观的均衡策略;文献[5-6,9]的方法由于初始计算时无法得到准确的转移概率导致其结果与客观的均衡存在误差,其中,文献[5-6]又由于以完全信息假设为前提,导致误差比文献[9]要稍大一些;单纯的Q-learning方法由于只能选择纯策略,而客观均衡是一个混合策略,导致其防御策略一直在振荡。

图9 不同方法在状态s4的防御策略变化
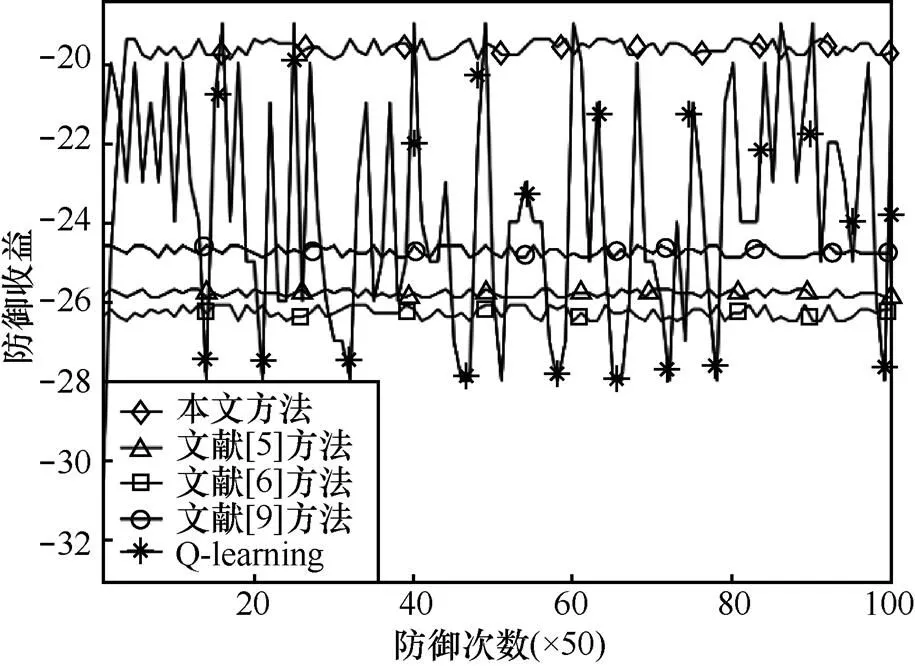
图10 不同方法在状态s4的防御收益变化
从图10可以看到,本文方法在初始阶段收益稍低于其他方法,但是当收敛到均衡策略以后,本文方法收益明显高于其他4种方法,这表明本文方法的防御策略在此场景要优于其他方法。
6 相关工作对比分析
本文方法与一些典型方法的研究对比结果如表6所示。文献[5-6,8-9]的理论基础为随机博弈,文献[12,14]的理论基础为Q-learning,本文方法则是随机博弈与Q-learning的结合。与文献[5-6,8]相比,本文方法以不完全信息假设为前提,更符合攻防实际;与文献[5-6,8-9]相比,本文方法不需要已知转移模型,且能够适用于转移概率动态变化的情况;与文献[12,14]相比,本文方法能够充分考虑网络攻防的策略依存性。

表6 本文方法与典型方法的评估比较
将本文方法扩展至实际网络,其攻防对抗仍然符合随机博弈过程,防御决策原理仍然正确,但是需要针对具体网络的环境做一些调整。如果实际网络规模较小,则本文方案可直接使用;如果网络规模较大,一些网络的攻防策略集和攻击者类型数量会增加,导致博弈求解难度加大,还有一些网络采用表存储值时可能会消耗过多内存,同时收敛速度也会降低。文献[21]对第一类情况进行了总结与分析,给出了相应的解决方案。如遇到第一类情况,可参考文献[21]中的方法对博弈求解方式进行调整。如遇到第二类情况,可利用神经网络或深度学习等函数拟合的方式存储值。需要注意的是,并不是本文现有的博弈求解方式和以表存储值的方式存在问题,而是实际中不同网络对算法有不同的需求,本文现有的博弈求解方式和以表存储值的方式更适用于规模较小的网络,而文献[21]中提供的求解方式和神经网络(深度学习)存储值的方式则更适用于大规模网络。两者各有优势,由于这不是本文的研究重点,因此没有对其进行深入讨论。
7 结束语
[1] HU H, ZHANG H, LIU Y, et al. Quantitative method for network security situation based on attack prediction[J]. Security & Communication Networks, 2017(4): 1-19.
[2] HU H, LIU Y, ZHANG H, et al. Optimal network defense strategy selection based on incomplete information evolutionary game[J]. IEEE Access, 2018, PP(99): 1.
[3] FALLAH M. A puzzle-based defense strategy against flooding attacks using game theory[J]. IEEE Transactions on Dependable & Secure Computing, 2010, 7(1): 5-19.
[4] FILAR J, VRIEZE K. Competitive Markov decision processes[J]. Springer Berlin, 1996, 36(4): 343-358.
[5] 姜伟, 方滨兴, 田志宏, 等. 基于攻防随机博弈模型的防御策略选取研究[J]. 计算机研究与发展, 2010, 47(10): 1714-1723.
JIANG W, FANG B X, TIAN Z H, et al. Research on defense strategies selection based on attack-defense stochastic game model[J]. Journal of Computer Research and Development, 2010, 47(10): 1714-1723.
[6] LYE K W, WING J M. Game strategies in network security[J]. International Journal of Information Security, 2005, 4(1-2): 71-86.
[7] WEI L, SARWAT A, SAAD W, et al. Stochastic games for power grid protection against coordinated cyber-physical attacks[J]. IEEE Transactions on Smart Grid, 2016, PP(99): 1.
[8] ARFAOUI A, LETAIFA A B, KRIBECHE A, et al. A stochastic game for adaptive security in constrained wireless body area networks[C]//Consumer Communications & NETWORKING Conference. 2018: 1-7.
[9] LEI C, ZHANG H Q, WAN L M, et al. Incomplete information Markov game theoretic approach to strategy generation for moving target defense[J]. Computer Communications, 2018, 116: 184-199.
[10] LEI C, MA D H, ZHANG H Q. Optimal strategy selection for moving target defense based on Markov game[J]. IEEE Access, 2017, PP(99): 1.
[11] WATKINS C J C H, DAYAN P. Technical note: Q-learning[J]. Machine Learning, 1992, 8(3-4): 279-292.
[12] 刘陶, 何炎祥, 熊琦. 一种基于Q学习的LDoS攻击实时防御机制及其CPN实现[J]. 计算机研究与发展, 2011, 48(3): 432-439.
LIU T, HE Y X, XIONG Q. A Q-learning based real-time mitigating mechanism against LDoS attack and its modeling and simulation with CPN[J]. Journal of Computer Research and Development, 2011, 48(3): 432-439.
[13] RANDRIANSOLO A S, PYEATT L D. Q-learning: from computer network security to software security[C]//International Conference on Machine Learning and Applications. 2015: 257-262.
[14] YAN J, HE H, ZHONG X, et al. Q-learning-based vulnerability analysis of smart grid against sequential topology attacks[J]. IEEE Transactions on Information Forensics & Security, 2017, 12(1): 200-210.
[15] HARSANYI J C, SELTEN R. A general theory of equilibrium selection in games[M]. Boston: MIT Press, 1988.
[16] CORMEN T H, LEISERSON C E, RIVEST R L, et al. Introduction to algorithms[M]. Boston: MIT Press, 2009.
[17] 张恒巍, 李涛. 基于多阶段攻防信号博弈的最优主动防御[J]. 电子学报, 2017, 45(2): 431-439.
ZHANG H W, LI T. Optimal active defense based on multi-stage attack-defense signaling game[J]. Acta Electronica Sinica, 2017, 45(2): 431-439.
[18] HUNG S M, GIVIGI S N. A Q-learning approach to flocking with UAVs in a stochastic environment[J]. IEEE Transactions on Cybernetics, 2016, 47(1): 186-197.
[19] SZEPESVARI C, LITTMAN M. A unified analysis of value-function-based reinforcement-learning algorithms[J]. Neural Computation, 1999, 11(8): 2017-2059.
[20] GORDON L, LOEB M, LUCYSHYN W, et al. 2015 CSI/FBI computer crime and security survey[C]//The 2014 Computer Security Institute. 2015: 48-64.
[21] 王震, 袁勇, 安波, 等. 安全博弈论研究综述[J]. 指挥与控制学报, 2015, 1(2): 121-149.
WANG Z, YUAN Y, AN B, et al. An overview of security games[J]. Journal of Command and Control, 2015, 1(2): 121-149.
Defense decision-making method based on incomplete information stochastic game and Q-learning
ZHANG Hongqi1,2, YANG Junnan1,2, ZHANG Chuanfu1,2
1. The Third Institute, Information Engineering University, Zhengzhou 450001, China 2. Henan Province Key Laboratory of Information Security, Zhengzhou 450001, China
Most of the existing stochastic games are based on the assumption of complete information, which are not consistent with the fact of network attack and defense. Aiming at this problem, the uncertainty of the attacker’s revenue was transformed to the uncertainty of the attacker type, and then a stochastic game model with incomplete information was constructed. The probability of network state transition is difficult to determine, which makes it impossible to determine the parameter needed to solve the equilibrium. Aiming at this problem, the Q-learning was introduced into stochastic game, which allowed defender to get the relevant parameter by learning in network attack and defense and to solve Bayesian Nash equilibrium. Based on the above, a defense decision algorithm that could learn online was designed. The simulation experiment proves the effectiveness of the proposed method.
network attack and defense, stochastic game, Q-learning, Bayesian Nash equilibrium, defense strategy
TP393.08
A
10.11959/j.issn.1000−436x.2018145
张红旗(1962−),男,河北遵化人,博士,信息工程大学教授、博士生导师,主要研究方向为网络安全、风险评估、等级保护和信息安全管理等。

杨峻楠(1993−),男,河北藁城人,信息工程大学硕士生,主要研究方向为网络信息安全、博弈论和强化学习等。
张传富(1973−),男,山东莱芜人,博士后,信息工程大学副教授,主要研究方向为计算机建模与仿真技术等。

2018−04−03;
2018−07−10
杨峻楠,624519905@qq.com
国家高技术研究发展计划(“863”计划)基金资助项目(No.2014AA7116082, No.2015AA7116040)
The National High Technology Research and Development Program of China (863 Program) (No.2014AA7116082,No.2015AA7116040)
猜你喜欢
锦绣·中旬刊(2021年3期)2021-07-14
法律方法(2021年4期)2021-03-16
锦绣·中旬刊(2021年8期)2021-03-15
中国生物医学工程学报(2019年6期)2019-07-16
爱你·心灵读本(2018年6期)2018-09-10
爱你(2018年16期)2018-06-21
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
指挥与控制学报(2015年4期)2015-11-01
意林·作文素材(2015年14期)2015-08-26
郑州大学学报(理学版)(2014年2期)2014-03-01
