
网络诈骗案件热度分析与时空预警模型研究
2018-09-10 05:07:43赵四方周学广张志刚
计算机与网络 2018年20期
赵四方 周学广 张志刚
摘要:以门户网站获取的公开新闻文本为数据源,利用词频统计和正则表达式方法,计算了时间热度的月环比增长率,构建了热度时间和空间模型。利用双索引字典方法和均值聚类算法得到了时空分布模块与预警模块,并且构建了上述工作的可视化模型。结果显示,网络诈骗案件呈低速增长、由外内迁的趋势,研究成果丰富了相关领域的分析方法,可为相关部门决策提供一定的科学依据。
关键词:网络诈骗;文本分析;均值聚类;可视化
中图分类号:TP393文献标志码:A文章编号:1008-1739(2018)20-58-4
Analysis and Study on Hot Degree and Spatio-temporal Early-warning Models of Internet Fraud
ZHAO Sifang1, ZHOU Xueguang2, ZHANG Zhigang2(1. Unit 92785, PLA,,Suizhong Liaoning 125200, China;2. Navy University of Engineering, Wuhan Hubei 430033, China)
0引言
根据CNNIC发布的《第40次中国互联网络发展状况统计报告》中数据显示,截止2017年6月,中国网民规模达7.51亿,其中使用手机网上支付结算进行线下购物的网民比例达到61.6%[1]。在网络线下支付等行为越来越普遍时,随之而来的网络诈骗案件也频繁发生。尽管各地公安机关一直持续不断打击,但网络诈骗社会危害性的复制性、聚焦性和扩散性[2]的特点使得网络诈骗案件容易“死而复生”。随着文本内容分析、大数据、机器学习和深度学习技术的成熟,社会上出现了一些有深度的技术层面的监管措施,包括从用户行为特征、扫描统计方法和涉案人群智能分析[3]等。
本文以中文网页中关于网络诈骗的新闻文本为数据源,构建网络诈骗热度分析的时间和空间模型,运用可視化技术直观展示近年来我国网络诈骗案件热度分析和时空分析的变化趋势。
1内容分析方法在网络文本中的应用
传播学家伯纳德·雷尔森定义内容分析为:“一种对具有明确特征的传播内容进行的客观、系统和定量的描述的研究技术”。[2]研究目标主要为趋势分析、现状分析、比较分析和意向分析,其与数学和计算机学科结合,形成了对文本信息使用统计、分类和挖掘等方法,以获得更深层次的技术。
本文研究过程中主要使用文本内容分析正则表达式和词频统计技术。
①正则表达式可以用于从文中抽取特定的目标信息内容和数据。原理是用一串具有特定意义的字符作为正则运算符来表示某种匹配规则,其主要应用方向是Web信息内容抽取,最基本的3种功能是匹配、替换和提取。本文中正则表达式主要使用了单模式匹配方法和双模式匹配的贪心算法,单模式匹配方法是从文本中抽取对应模式内容,贪心算法是利用正则表达式组成逻辑结构实现对全部内容的匹配,方法是用.*?”表示匹配前文全部内容0或1次。
Pattern1+.*?+Pattern2,
式中,Pattern1表示正则表达式起始端;Pattern2表示正则表达式结束端;+表示连接正则表达式内容。
②词频统计是文本分析中的基本步骤,通过对关键词语的统计实现对文本主题内容的抽取、分类和信息过滤等。目前词频统计规律的提出、验证及应用等方面已有大量参考资料,本文使用基本的词频统计方法统计关键词[4]的出现次数,通过分析后得出相应结论。
2数据挖掘方法在分析和聚类中的应用
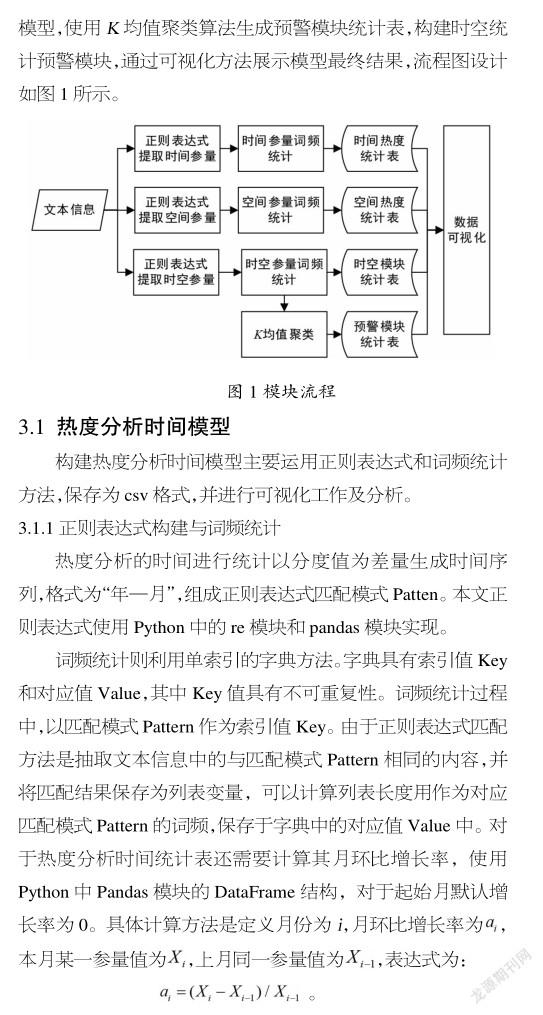
3.1.2模型算法
模型算法包括了热度分析时间统计表算法和月环比增长率统计表算法,分别称之为算法1与算法2。算法1前声明时间序列列表date,列表中各个元素为匹配模式Pattern;声明字典变量为dict_time。
算法1:输入:文本数据wenebn.txt;输出:热度分析时间统计表hot_time.csv。步骤:①for i in range(0,len(date),1);②key = re.findall(匹配模式=date[i],匹配内容=wenben.txt,换行处理re.S);③dict_time [i] = len (key);④文本指针归0;⑤df = pandas.DataFrame(dict_time);⑥df.to_csv(hot_time.csv保存路径)。
算法2:输入:算法1变量df;输出:月环比增长率统计表rate.csv。步骤:①df[增长率]=0;②for i in range(1,len(df.index),1);③df.ix[i,增长率] = float(df.ix[i,对应时间统计的词频数值number])/float(df.ix[i-1,对应时间统计的词频数值number])-1;④df.to_csv(rate.csv保存路径)。
3.2热度分析空间模型
构建热度分析空间模型与热度分析时间模型算法需要将相同省份名称和词频频率汇总为热度分析空间统计表,保存为Excel格式,并进行可视化工作及分析。
3.2.1正则表达式构建和词频匹配
针对热度分析的空间统计,可以以我国省份名称作为正则表达式的匹配模式Pattern,正则表达式匹配前声明字典变量,字典的索引值Key为省份名称,字典对应值Value为词频频率。
3.2.2模型算法
热度分析空间统计算法成为算法3。算法3前声明省份名称列表province,列表中各个元素为匹配模式Pattern;声明字典变量dict_province。
算法3:输入:文本数据wenebn.txt;输出:热度分析时间统计表hot_space.csv。步骤:①for i in range(0,len(province),1);②key = re.findall(匹配模式=province[i],匹配内容=wenben. txt,换行处理);③dict_province[i] = len(key);④文本指针归0;⑤df = pandas.DataFrame(dict_province);⑥df.to_csv(hot_space. csv保存路径)。
3.3时空统计预警模型
3.3.1时空统计模块
时空统计模型使用了双索引字典技术,分别为外层字典与内层字典。具体方法与热度分析时间和空间模型相同,正则表达式由“时间参量+.*?+空间参量”的匹配模式构成,最终得到时空统计表,其包含了时间、省份和词频,并通过软件进行数据可视化展示。
3.3.2预警模块
预警模块以时空统计表为基础,使用均值聚类法对月环比增长率进行聚类。具体方法是首先判断月环比增长率取值,对大于0的月环比增长率进行均值聚类,定义值为4,得到4类聚类结果,而月环比增长率小于0的情况单独归为一类,总计得到5层分类结果。
3.3.3时空统计模块算法
时空统计模块算法称为算法4。算法4使用算法1声明的时间序列列表date和算法3前声明的省份名称列表provicne。声明字典变量dict1。
算法4:输入:文本数据wenben.txt;输出:时空统计表time_space.csv。
步骤:①for i in range(0,len(date),1);②定义字典dict2;③for k in range(0,len(province),1);④key = re.findall(匹配模式=date[i]+.*?+province[k],匹配内容=wenben.txt,换行处理);⑤dict2[province[k]] = len(key);⑥文本指针归0;⑦dict1[date[i]] = dict2;⑧df = pandas.DataFrame(dict1);⑨df[rate]=0;⑩for i in range(1,len(df.index),1);
4实验与分析
4.1实验环境与数据准备
(1)实验环境
实验是在JetBrains Pycharm Community Edition 2017.2上用Python2.7语言实现。数据可视化软件为Excel2016,数据源为各个模型的统计结果表。
(2)数据准备
本文数据来自人民网社会模块,在此以网络诈骗为关键字检索相关新闻,获得了由2012年7月07日~2017年5月26日的全部文本新闻报道共计995篇。
4.2热度分析时间结果
热度分析的时间模型对2012年7月~2017年5月的时间进行了匹配和统计,经过算法处理后得到热度分析的时间统计表,实验结果如表1所示。
根据得到热度分析的时间统计表得到月环比增长率表,表明网络诈骗存在“死灰复燃”的特征,结果如表2所示。
4.3热度分析空间结果
热度分析空间统计模型对2012年6月~2017年5月间的我国31个省级行政区和港澳台地区的名称进行了匹配和统计,经过算法处理后得到了热度分析的空间统计表。网络诈骗热点省份由高至低的前10名省份统计结果由表1所示。
4.4时空统计预警模块实验及结果
由于热度分析的时间和空间模型剥离了时空相关性,其热度分析时间统计表和热度分析空间统计表不能作为时空统计的数据源,所以时空统计预警模块对文本重新进行了正则表达式匹配和词频统计。4.4.1时空统计模块
时空统计模块通过双索引技术,利用时空相关性特点,通过算法处理后得到了时空统计表,从图1可发现我国在2012年末~2014年1月和2015年3月~2016年1月是我国网络诈骗的一个高发期,其中北京、上海和广东一直是关注网络诈骗案件的热点地区,结果如图2所示。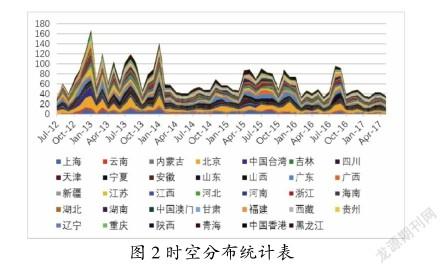
4.4.2預警模块
预警模块以时空统计图为基础,经多次实验,均值聚类方法迭代次数分析在21~24次之间。通过动态图发现我国网络诈骗主要在沿海区域和经济发达区域,东南沿海区域长时间处于预警状态。
5结束语
网络诈骗是国内的热点与重点事件,空间模型在数据深度的提取上仅达到省、直辖市与自治区级别,仍具有地理深度上钻取数据的价值和广阔的发展前景。除此之外,未参考地域特征、人口文化素质和经济收入等相关因素,因而本文的模型在构建的方法上可以更加多样化,其反应的结果也将更加丰富。
参考文献
[1]中国互联网信息中心.中国互联网络发展状况统计报告[R].北京:中国互联网信息中心,2017.
[2]朱少强,邱均平.文献计量与内容分析—文献群中隐含信息的挖掘[J].图书情报工作,2005,49(6):19-23.
[3]王占宏.基于扫描统计方法的上海犯罪时空热点分析[D].上海:华东师范大学,2013.
[4] Steven B,Ewan K,Edward L. Natural Language Processing with Python [M]. Sebastopol:OReilly Media,2009.
[5]程洁.数据挖掘技术在情报学领域的应用研究现状分析[J].现代情报,2005(10):14-15.
[6]孙吉贵,刘杰,赵连宇.聚类算法研究[J].软件学报,2008(1): 48-61.
[7]曾接贤,王军婷,符祥.K均值聚类分割的多特征图像检索方法[J].计算机工程与应用,2013,49(2):226-230.
[8]周志华.机器学习[M].北京:清华大学出版社,2016.
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
海洋信息技术与应用(2020年1期)2020-06-11 12:43:56
传媒评论(2019年4期)2019-07-13 05:49:14
科教导刊·电子版(2017年5期)2017-04-01 16:43:32
商业经济(2016年11期)2016-12-20 19:44:02
戏剧之家(2016年22期)2016-11-30 16:49:57
青年文学家(2016年30期)2016-11-22 18:50:01
考试周刊(2016年45期)2016-06-24 13:48:11
中国市场(2016年2期)2016-01-16 17:20:17
