
中文图片验证码识别方法的研究
2018-08-28 02:46:20杨航,蔡浩
汕头大学学报(自然科学版) 2018年3期
杨 航,蔡 浩
(汕头大学工学院,广东 汕头 515063)
0 前言
验证码测试是一种为了区分人类和机器的测试.一般是人类可以测试通过,但是机器不能测试通过的,这样就达到了图灵测试的目的.因而,验证码测试被广泛应用于网络安全中,例如:账号注册,账号登陆等.最开始提到有关“机器图灵测试”的问题出现在Moni Naor[1]的一篇论文中.而第一个自动图灵测试系统是由Altavista[2]开发的,是为了阻止机器人自动识别注册网页.而最近两年基于人工智能的分类算法是学术上研究的热点,在这种前提和背景下,本文研究了基于OCR的中文验证码识别方法、模板匹配法、基于卷积神经网络的分类算法以及相关改进方法在中文验证码识别上的表现,来探究这几种方法在识别精度,样本需求量,识别时长上的表现,并着重对基于卷积神经网络的方法进行了改进,最后对三者的适用性做了简单的总结.
1 研究目的简述
目前利用已有中文字符OCR对中文字符的识别成功率不到10%(从文献[3]中可以知道),文章新加了两种方法对中文图片验证码进行了识别研究.对比研究这三种验证码识别技术,结合验证码的特点,进而探究这类验证码中存在的安全隐患,从而构建更加安全的防护机制.只有深入了解机器识别验证码的机制,我们才能组合出更不利于机器识别的验证模式,从而使验证码这种机制更加安全.
2 研究方法
字符型验证码的识别可分为基于分割的识别和不基于分割的识别.不基于分割的方法有,尹龙等[4]用到一种基于密集尺度不变特征变换(DENSE SIFT)和随机抽样一致性算法(RANSAC)的识别方法,该方法的普适性较好,但算法设计较为复杂.基于分割的方法,一般分割之后再用机器学习的方法进行分类,殷光等[5]采用基于SVM分类器的识别方法,王璐[6]采用了分割后基于卷积神经网络的方法,张亮等[7]采用了LSTM型RNN的方法,都取得了不错的识别效果.当然这些方法都是针对阿拉伯数字和英文字母,和中文比较起来,中文具有字型更复杂,符号数量更多的特点.目前还没有文献介绍用卷积神经网络识别中文字符验证码的.本文提出了基于点矩阵的模板匹配法和基于卷积神经网络的识别方法对该问题进行实验研究.基于点矩阵的模板匹配法是比较寻找所要识别图片与事先建好字库中图片相似度最大的图片,这里的相似度可以采用点矩阵重合率和点矩阵余弦相似度,最后判定相似度最大的字符值为所要识别字符的值.基于卷积神经网络的方法则采用了现在在图像分类问题上处理比较常用的方法,先进行人工标记样本图片,然后将图片分为训练集和测试集,再建立神经网络模型,让模型在训练集上训练,不断调整模型参数,最后让训练好的模型在测试集上测试得到模型表现结果.本文选用一类代表性比较强的中文验证码作为实验对象,验证码中字符有平移,旋转,并且有大量的噪点和干扰线.本文是基于先分割再识别的思路去研究中文验证码识别问题的,选用了基于OCR的识别方法和基于卷积神经网络的识别方法,以及基于点矩阵的模板匹配法,并对所研究方法进行改进和实验对比.
3 实例分析
3.1 图片预处理
下面介绍的是实验的具体操作步骤,首先介绍两种方法的公共部分,即图片的预处理部分,分为图片的灰度化,图片的二值化,图片去噪,图片切块,图片的人工分类标记.
样本选用的是某个具有一定代表性的公开网站,我们提前下载好一批验证码图片,这里的样本图片如图1所示.

图1 原始未处理图
可以看出图片中的汉字的位置变化很大,噪点和干扰线较多,字符之间存在不同程度的粘连.
3.1.1 灰度化与二值化
灰度化是去掉图片中与字符无关的色彩信息,简化计算,更有利于识别图片中的字符.这是适用于字符类验证码识别的预处理.具体可采用平均值法或者参考文献[8]中的自适应算法.为了之后的问题处理方便,要把图像二值化成黑白图像,即去掉中间的灰度.在处理像素点时,用0表示白色像素,用1表示黑色像素.二值化图像的方法有很多,有固定阈值二值化法和自适应阈值二值化法.自适应阈值二值化需要统计整幅图像像素特征,自动计算出阈值,然后根据该阈值进行二值化.确定好阈值后,二者的后续操作是一样的.如果用threshold表示阈值,则伪代码如下(其中color表示当前像素点的像素值):
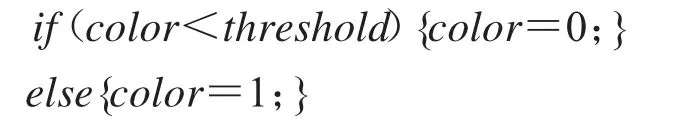
3.1.2 去噪
一般采用中值滤波或均值滤波的方法去除图像中的噪音,本文图片分类对去噪能力依赖性不大,故采用相邻点数的阈值去噪方法,具体步骤:设定阈值,统计相邻点为黑色的数值,如果统计的黑色点个数小于阈值,则判定该点为噪点,去除该点,否则保留.算法的伪代码如下(其中threshold为设定的阈值,number表示统计相邻点为黑色的数值):

3.1.3 切块
这里为了获得更好的切块效果也可以用文献[9]中提出的基于结构特征点的字符切割方法,切割准确度要比投影分析方法、连通域提取方法、传统滴水方法、骨架形态分析方法等要好.
3.1.4 分类贴标签及预处理效果
经过以上几个步骤操作之后,最后的效果图如图2,可以看到获得的预处理效果还是相当不错的,虽然字体有些歪斜,噪声也并不是完全清楚干净,但是肉眼可以明显辨认出图2中字符所代表的中文字,这就有了后续识别的基础.

图2 预处理后效果图
3.2 识别方法
3.2.1 相似度模板匹配方法
3.2.1.1 人工建立模板库 对每个字符随机挑选出50-100张切割好的图片作为特定字符的模板库,每个模板库中模板的数量保持一致.原因有两点,一个是为了程序编写方便,一个是为了匹配时不会产生计算偏倚,即不会偏重匹配成功某个模板较多的字符.
3.2.1.2 图片模板库转文本模板库压缩存储 可以利用将图片信息转化为文本信息来完成压缩存储,这样就可以减少计算机打开图片解码图片等步骤,而且可以减小模板库的存储空间,使用起来更便利.
3.2.1.3 效果展示 最后统计图片中总的点数,统计重合点数,则最后的相似率计算可以用重合点数比上总过的点数,pic对应的识别标签值.最后的效果展示图如图3所示.

图3 识别效果展示图
3.2.1.4 其他注意事项及技巧 可以看到图1原始未处理图中,字符是有旋转的,有粘连,并且有噪点和干扰线,对于特定的一类验证码我们需要人为的建立一类对应的模板库,这样的识别才会更精准.可以看到初始图片集中,是有成语类的验证码的,而计算类验证码字符是只有十三个的,所以如果能区分成语类和计算类,然后再进行识别的话,所需要的模板字符就变少了.因为计算类的图片中,会出现“等于”字样,我们可以建立一个“于”字库,用于对比切割之后原始图片中的最后一个字符来确定当前验证码的类别,这个技巧可以发散,对于特定一类验证码,利用其本身的特点来验证可以事半功倍.如果一类验证码中没有明显区分这种类别时,则需要建立更多字符的模板库.
3.2.1.5 模板匹配法优缺点 简单总结一下,模板匹配法操作简单,容易实现,所需样本少,但是其识别精度还不够高,当识别字符较多时,需要建立更多字符的模板库,匹配计算量会变得很大,识别时间会很长.
3.2.2 基于卷积神经网络的识别
原始的模型参考LeNet-5[10]的结构搭建卷积神经网络,本文采用的网络结构一共有6层,第一层和第三层是卷积层,卷积核均为5×5的,第二层和第四层是池化层,但是第二层步长设置为2,而第四层设置的是1,第五层和第六层为全连接层,连接数为512,输入和输出在模型的两端,输入为25×25的图片,颜色通道数为3,最后的输出为13类中的一类,模型示意图如图4所示:

图4 卷积网络模型示意图
3.2.3 基于卷积神经网络识别方法的改进
改进1:加入图片增强技术.文献[11]中进行图片编码处理时,对图像进行了大小调整、裁剪、翻转等处理,这样训练出的神经网络模型实用性更好.类似的,我们可以将这种思想运用到中文验证码识别问题中.对于该问题验证码获取成本较高,并且网站经常禁止访问,所以不可能获得太大数量的原始样本.为了获得更多有效的样本,对切割好的图片,可以采用人工制造噪点干扰线,图片适当旋转平移等方式,来增强图片的表示,并获得更多有效的样本.
改进 2:模型改进.在模型中引入 ReLU激活层[12]、Dropout层[13]以及 Batch Normalization层[14].ReLU激活层是一个非线性的激活层,可以更好的模拟神经网络的作用,实践证明其表现是优于Sigmoid线性激活层的.在池化层的后面添加Dropout层来防止过拟合,其主要工作原理是按照一定的概率将神经网络单元从网络中丢弃.文献[14]对Dropout层的作用有详细的解释.引入Batch Normalization的目的是,让训练的过程更快,精准度更高.基本原理是在每次SGD时,通过mini-batch来对相应的activation做规范操作,使得输出信号各个维度的均值为0,方差为1.最后使用了scale and shift操作,保证了模型的容纳能力.
改进3:用模板匹配法粗分字符集.我们可以先建立极小数量的字符模板库,然后利用建好的模板库,对未处理的收集样本进行切割粗分,减少人工操作,当然最后需要人工检查是否分割正确,这样可以大大降低人工干预和工作量.
4 结果分析
4.1 实验平台及数据量描述
4.1.1 硬件描述
处理器:Intel(R)Core(TM)i7-6700HQ CPU@2.60GHZ 2.60GHZ
内存(RAM):8.00GB
系统类型:64位操作系统(WIN10),基于x64的处理器
4.1.2 软件描述
编程语言为python(3.5.2版),安装包主要有numpy(1.13.3版),Pillow(4.2.1版),Keras(2.0.8版),tensorflow(1.4.0版),pyocr(0.4.7版).算法的实现主要是基于google的tensorflow深度学习开源框架.
4.1.3 实验数据量描述
实验分类字符为13类,3种方法的数据量是不同的,这主要受限于当前方法本身,中文模板匹配法总的图片数据1 300张,每一类100张;未改进的卷积神经网络方法总的数据量为26 000张,每一类2 000张;改进的卷积神经网络方法总的数据量为3 900张,每一类300张.3种方法最后测试的数据图片量为1 000张.
4.2 3种方法结果对比
我们设定几个指标来比较衡量这些方法.设定指标如下:
识别精度:即识别正确率(在测试集上的).
样本需求量:方法对样本数量多少的依赖.
识别时长:识别程序开发好后,识别一张图片所用时间.
这些方法的指标对比见表1.

表1 3种方法对比结果
经过实践证明,基于OCR的方法对于此类中文验证码的识别基本无效.通过表1可以看出,从开发周期和样本需求量上看,相较于模板匹配法,基于卷积神经网络的方法需要更多的样本和时间去开发.但是识别效果提升明显,尤其是改进之后的卷积神经网络方法,不仅样本需求量更小,识别精度也有很大提高,优于文献[3-7]中的实验结果.从普适性上分析,改进后的卷积神经网络方法更适用于图像分类问题.
5 研究结论
经过上面的实验,可以得出如下结论:
模板匹配法简单可行,开发周期短,所需样本数量非常少,但正确率较低,字符较多时,比较的计算时间会很长.相对的,基于卷积神经网络的方法则需要更多的样本和开发训练时间,以及模型调整时间,但是模型的准确性很高,而且识别所需时间更短,速度很快.二者各有所长,模板匹配简单易行,而卷积神经网络分类准确率高.经过改进之后的卷积神经网络方法则表现出了更好的普适性和更优越的性能.
中文图片验证码问题的研究能给防止机器识别的研究启示,例如可以研究如何改变验证码生成策略和验证策略来提高验证码的安全性.再一个衍生的研究课题是,如何利用现有的卷积神经网络,以及深度学习网络来提升OCR中文识别技术.
6 小结
通过实验对比研究了文中提到的几种方法在中文验证码识别上的表现,并进行相应的改进与提升.最后改进的卷积神经网络获得了99.8%的识别精度,并且对样本的依赖性降低,模型更适用于中文字符的识别.现实生活中我们经常会遇到类似的图像分类问题,而且很多时候无法在短时间里得到一个很好的模型,我们可以先从简单的模型出发,后期再对模型进行调整和优化.对于图片分类问题,卷积神经网络表现出的优越性很明显,并且相当适用,是处理这类问题一个不错的选择.
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
制造技术与机床(2019年9期)2019-09-10 07:36:54
电子制作(2019年11期)2019-07-04 00:34:38
西南交通大学学报(2018年6期)2018-12-18 02:22:28
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
河北遥感(2017年2期)2017-08-07 14:49:00
