
基于大数据平台和并行随机森林算法的能耗预测模型优化
2018-08-25 02:54肖祥武文雯白全生胡卫东李志金刘克勤
综合智慧能源 2018年7期
肖祥武,文雯,白全生,胡卫东,李志金,刘克勤
(湖南大唐先一科技有限公司,长沙 410007)
0 引言
2015年12月2日,国务院常务会议决定全面实施燃煤电厂超低排放和节能改造目标,截至2020年,要求所有现役电厂平均煤耗低于310 g/(kW·h),对火电厂节能降耗、降本增效提出了更高的要求。
随着计算机、互联网、物联网等现代技术的快速发展,电力企业数据库每天存储大量的数据积累形成电力大数据,这些数据具有数量大、数据类型多、处理速度快、数据价值高4大特征[1]。从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中提取隐含在其中的规律和规则,进行有用信息和知识的挖掘[2],是电力大数据应用面临的最关键问题,因此,将电力大数据应用于火电节能降耗工作面临着巨大的机遇与挑战[3]。机器学习是开展电力大数据分析极其重要的手段,机器学习通过计算手段利用经验来改善系统自身性能,是计算机从数据中产生“模型”的算法[4]。
基于大数据的火电能耗预测属于回归预测范畴,在数学学科领域中,灰色理论、强化学习、模糊理论、时间序列、人工神经网络、决策树和支持向量机等均是常用模型。文献[5]研究了并行随机森林回归算法对短期电力负荷的预测,同时比较了并行随机森林回归算法与传统单机模板的支持向量机算法,指出了决策树回归算法在负荷预测上的优越性能,最后得出随机森林回归算法精确度更高的结论。文献[6]研究了将随机森林算法应用到判别分析、有无数据分析、回归分析3个应用场景,得出随机森林算法具有较强的鲁棒性和高精确度的结论。文献[7]研究比较了决策树与随机森林算法在不同数据样本量条件下的算法效率与精度,得出随机森林算法更优的结论。由此可见,随机森林算法具有对属性交互作用、离群点、缺失值不敏感的强鲁棒性特点,同时对数据不易产生过拟合。
鉴于传统算法模型在处理大数据量和高纬度数据时,不能满足预测精度与效率的要求,本文提出基于Spark架构,利用已构建大数据分析平台,开展基于分布式随机森林回归算法的火电供电煤耗预测模型优化的研究,实现能耗精准计算。
1 大数据分析平台
1.1 大数据分析平台组成
本文介绍的X-DT大数据平台主要由主题分析管理、组件管理、作业管理、运行监控4大功能组成。硬件部分由4台型号为Dell poweredge R730的服务器构成,搭配24核处理器,内存容量为256 GB,硬盘存储容量为8×2TB。其中网页Web应用部署在单一的云主机之上,安装基础的Linux操作系统、Java运行环境和Tomcat服务。
1.2 大数据分析平台的性能
X-DT大数据分析平台具有大数据采集、数据存储、文件处理、数据清洗、数据预处理、建模分析、模型参数优化、模型评估等功能,采用Spark的集群并行分布式设计。与传统的MapReduce相比,Spark技术存在较大不同[8],符合本研究大数据分析工作的要求。Spark与MapReduce的对比见表1(表中:HDFS为Hadoop分布式文件系统;RDD为弹性分布式数据集)。

表1 Spark与MapReduce对比
Spark是一种基于内存运算的分布式集群框架,在集群中,一台任务调度服务器作主节点(driver),若干台服务器作从节点(worker)。主节点负责向从节点分配任务,并将计算结果数据存于内存中,返回给主节点。Spark核心的RDD贯穿于Spark所有计算任务中,具有多次访问数据集的交互式数据分析机制,特别适用于机器学习中的大量迭代运算。
X-DT大数据分析平台集成了Hadoop,Spark,Hbase,拥有Hadoop分布式文件系统的存储功能、Spark并行计算分析功能和Hbase大数据仓库快速记录读写功能。平台设计开发采用Java和Scala语言,实现了Spark中数据处理和分析算法的快速调用和组合,使建模快速便捷。在分析平台中,分析模块由Spark提交任务到Yarn,Yarn再对任务进行资源分配、任务调度、任务运行状况查询。在分析过程中,产生的运行日志数据存储到Hbase数据仓库,运算的结果数据保存到HDFS[8]。
2 随机森林回归算法原理
随机森林(Random Forest,RF)算法[9]性能优异,但很少被用于煤耗计算的研究工作中。X-DT大数据分析平台内置的随机森林算法是决策树的集成算法,能分析出若干个特征变量对目标变量的作用。在构建决策树时,随机森林会根据设置随机生成指定数量的决策树,然后对每个决策树的预测值取均值作为算法输出结果[9],泛化能力强的决策树是随机森林算法的基础。一棵树包含一个根节点、若干个内节点和叶节点。根节点包含样本集全集,从根节点到每个叶节点对应了一个判定测试序列,叶节点对应决策结果[10]。随机森林回归算法流程如图1所示。
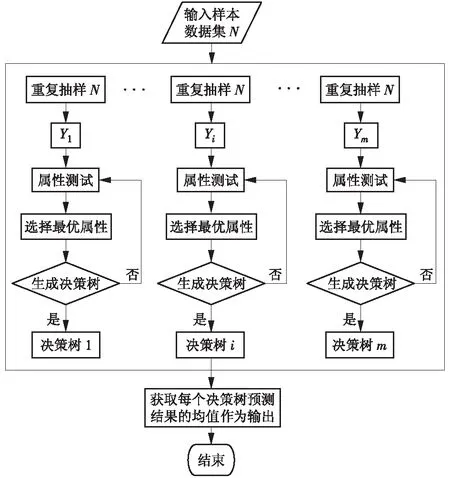
图1 随机森林流程
随机森林算法具有如下特点:(1)随机重复抽取训练决策树数据集;(2)决策树的生长策略中,随机选择节点分裂属性。算法具备的这2个优异特性,使得预测不易出现过拟合。
大数据分析平台采用Spark中实现的并行随机森林回归算法进行能耗预测,主要涉及的参数有决策树数量、决策树深度、最大分裂数等。在评估回归模型预测精度的统计量时,本文选取平均绝对误差(MAE)和均方根误差(RMSE)来描述,具体计算公式为
(1)
(2)

3 大数据平台能耗预测模型的建立
利用大数据分析平台采集某电厂2016年9月1日至2017年8月31日为期一年的运行数据,步长为1 min。通过分析发电机组煤耗计算过程,本文选取表2所示的38个参数为供电煤耗随机森林预测模型的输入量,供电煤耗为输出变量。
采用平台内置的数据预处理方法,通过开停机处理、剔除异常数据、填补空值,局部异常数据检测与处理,工况判稳,工况划分等步骤,对采集数据进行清洗,选取稳定工况下的健康数据样本进行分析。具体流程如图2所示。
4 预测模型调优
针对该电厂#3机组一年的运行数据,本文设计通过预处理后的样本数据预测供电煤耗,并比较不同数据量、不同模型参数对算法的预测效果和算法效率的影响,选出较佳的预测模型。
(1)决策树数量(NumTrees)。在研究决策树数量对模型性能和可解释性影响之前,数据集(10 000条)和其他参数(深度10、分裂策略all、最大分裂数50等)保持一致。在训练随机森林时,当构建的决策树的数量较小时,随机森林回归误差比较大,性能也比较差。但设置的树越多,算法的复杂度就也高,时间花费也越多。当森林达到一定规模时,模型的可解释性减弱。根据试验给出的MAE和RMSE,从表3和图3可见,随着决策树数量的增加,MAE和RMSE的走势有一定的相似性,决策树数量较小时MAE和RMSE有上升的趋势,当决策树数量达到200~300时,MAE和RMSE达到一个较小的值,再往后又逐渐上升,证明决策树数量在这个范围可以得到较好的预测精度。

表2 预测模型输入变量

图2 能耗回归预测流程
(2)决策树的深度(TreeDeepth)。在研究决策树深度对模型的影响时,试验设定数据集(10 000条)和其他参数(决策树数量250、分裂策略all等)保持一致。树的深度增加了算法的复杂程度,同时也提高了算法的精度,算法的运行时间也将增加。从表4纵向分析得出,随着深度的增加,MAE逐渐降低。其趋势如图4所示。
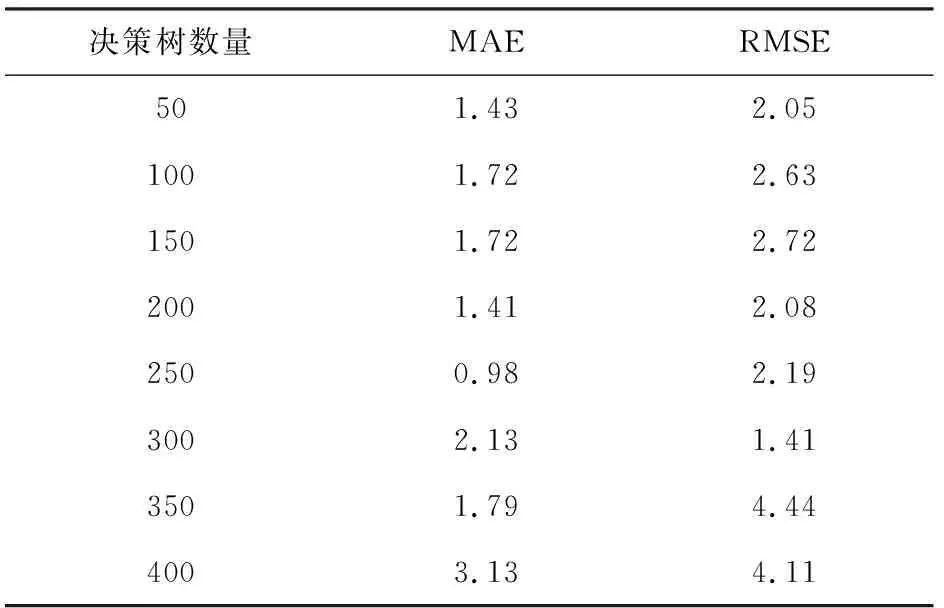
表3 不同决策树数量的MAE,RMSE
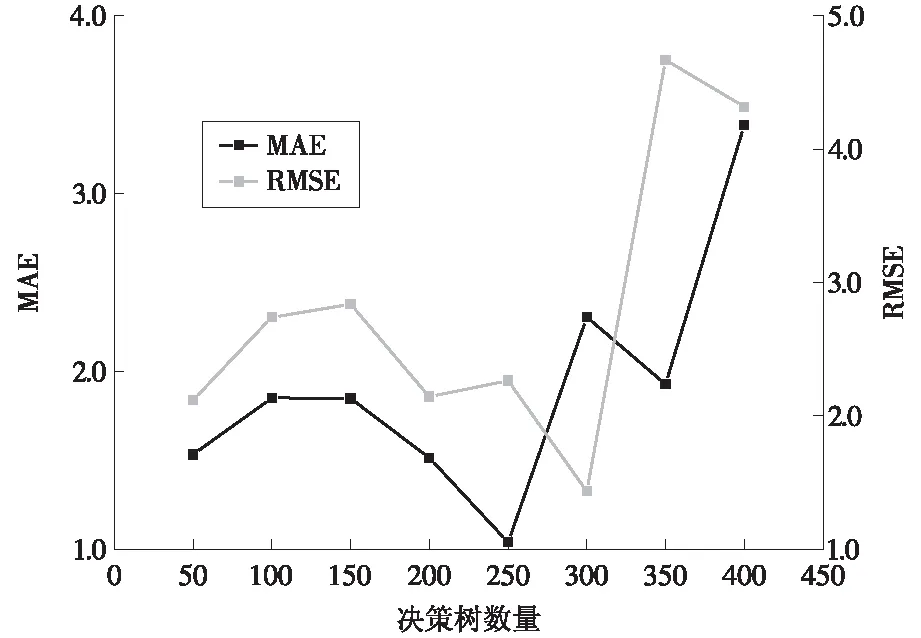
图3 不同决策树数量的MAE,RSME对比

表4 不同决策树深度和最大分裂数的MAE值
(3)最大分裂数(maxBins)。在研究决策树最大分裂数对模型的影响时,试验设定数据集(10 000条)和其他参数(决策树数量250、分裂策略all等)保持一致。最大分裂数表示连续特征离散化的最大数量,在做节点分裂时,影响特征分裂的方式。最大分裂数的增大,会不断增加算法的复杂度和运行时长。根据表4横向分析可得出,随着最大分裂数的增大,当决策树的深度小于30时,MAE不断增加,当深度达到30时,MAE基本持平,其趋势如图4所示。
(4)数据样本量。在研究数据样本量对模型的影响时,试验设定决策树数量250、决策树深度30、分裂策略all、最大分裂数50均保持一致。从表5可以看出,随着样本量的增加,训练时间不断增加,呈现幂指数增长趋势,故可根据实际业务需求及模型计算时间合理确定数据样本量。

图4 不同决策树深度和最大分裂数的MAE值对比

表5 数据量与训练时间的关系
(5)模型优化结果对比。由以上分析可知,在对该机组一年的数据样本进行清洗预处理后,将采集的机组发电负荷、环境温度作为边界条件,通过k-means聚类成10个不同运行工况。从每个工况中随机选取70%的数据样本,剩下30%的数据作为预测精度评估,具体优化模型参数设定如下:决策树数量250、决策树深度30、最大分裂数50,其余参数按默认值设定。另外设计4个比较模型,每个模型改变一个参数,其余保持一致。不同的参数分别设置为:决策树数量400、决策树数量50、决策树深度5、最大分裂数200。模型评估的输出结果见表6。从图5可以看出,优化模型的MAE曲线中参数1(250/30/50)最符合优化预测的目的,即当决策树数量为250、决策树深度为30、最大分裂数为50时,预测模型MAE最小,此时性能达到最优。

表6 优化模型的MAE,RMSE值对比
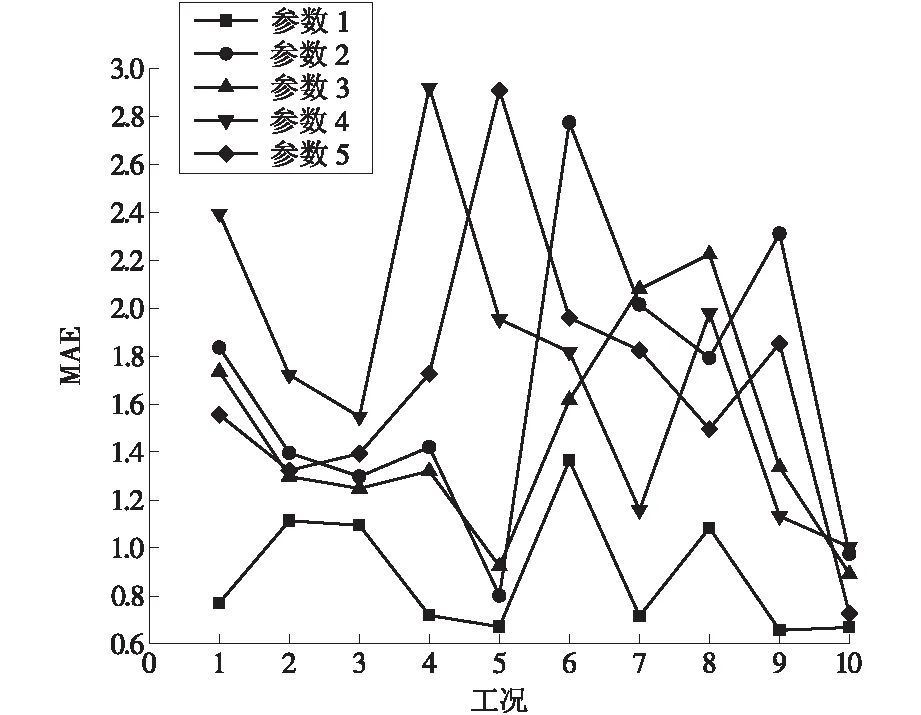
图5 MAE比较
5 结论
本文通过研究基于Spark的随机森林回归算法,利用大数据分析平台,建立了火电能耗预测模型,重点对该预测模型进行优化处理研究,得到了最佳决策森林能耗预测模型,得到了如下结论。
(1)决策树数量的最佳设定范围为200~300,决策树数量大于300时,既增加了模型训练的时间成本和模型复杂度,又影响了模型的精度。
(2)决策树的最佳深度为30,随着深度的增加,模型复杂度增强,预测的精度也不断增强,在条件允许下,可以尽量增大此参数。
(3)最大分裂数参数设定在50,随着最大分裂数的增大,预测精度有所降低,时间复杂度也增大,此参数取值不宜过大。
(4)通过比较,本随机森林预测模型的最优化模型参数为:决策树数量250,决策树深度30,最大分裂数50,其余参数选默认值。本研究成果可应用于火电机组能耗分析与诊断中,实现供电煤耗的精准预测与软测量。
猜你喜欢
快乐学习报·教育周刊(2022年16期)2022-05-01
数学小灵通(1-2年级)(2021年10期)2021-11-05
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
福建基础教育研究(2019年6期)2019-05-28
小学生学习指导(低年级)(2019年3期)2019-04-22
电子制作(2018年16期)2018-09-26
电子制作(2017年24期)2017-02-02
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
小猕猴智力画刊(2016年6期)2016-05-14
郑州大学学报(医学版)(2015年1期)2015-02-27
