
数据挖掘研究综述
2018-08-24 08:23周九常刘智明
河南图书馆学刊 2018年8期
周九常,刘智明
(郑州航空工业管理学院,河南 郑州 450046)
20世纪90年代,计算机技术和计算机网络技术开始迅速发展,数据及信息的外延也进一步扩大,由传统的纸质文献、文档数据扩增为视频、音频、图形、图像、电子档案等多种类型,不仅使信息的表现形式更加多样化,还使信息的产生速度发生了质的飞跃。以互联网为例,2013年全球互联网每天的流量达到1EB(约等于10亿GB),并且仍然在以40%的速度增长,科学家预计2020年全球的信息量将超过40ZB[1]。互联网技术的出现使人们的信息交互和合作变得更加容易,并使信息量呈指数式增长[2]。
海量的数据信息为人们提供便利的同时,也带来了一定的负面影响,如信息过载、信息距离、“信息孤岛”等,过多无用的信息导致有效的信息难以被发现、被提炼,这就是约翰·内斯波特称之为“信息丰富而知识匮乏”的困境。因此,只有对海量的数据进行分析,并提炼隐藏在其中的有效信息及知识资源,才能对其进行有效利用。但是,仅依靠传统的手工检索分析方法或自动化的数据库分析,难以达到让人满意的效果。由于分析对象数量巨大,传统的手工检索需要消耗大量的人力、物力才能达到既定目标,且由于信息具有时效性,因此往往导致部分分析结果是无用的;数据库分析虽然能够规避信息的时效性风险,但其难以对信息数据之间的关系内容或关联规则进行有效整理,无法根据现有的数据信息对未来的发展趋势进行分析,更难以得到深层次的知识。因此,当人们迫切需要一个新的工具改变这一局面时,数据挖掘技术便应运而生。
1 什么是数据挖掘
数据挖掘,又称数据库中的知识发现,Usama M.Fayyad等给出的定义是:从大量的数据中取得有效、新颖、潜在有用、最终可理解的知识的收集过程。数据挖掘在国际会议上被公认为“是对数据库中蕴含的未知、有潜在用途及非平凡知识的提取”。我国学者也对数据挖掘进行了研究总结,杨良斌认为“数据挖掘是从数据中汲取包含过往不被知道的有利用价值的潜在信息”;化柏林认为“数据挖掘是从大量、不完全、有噪声、模糊及随机的实际应用数据中,提取隐含在其中,但有一定用途的潜在信息和知识的过程”;汪明认为“数据挖掘是在大型数据存储中,自动发现有用信息的过程”[3-6]。总而言之,数据挖掘是一个过程,它包含了对海量数据的收集、清洗,以及通过关联规则或分类法对数据进行处理、对结果进行可视化呈现,使海量数据的内在联系能够清晰地被人们所认识。
2 基于CNKI的数据挖掘文献分析
2.1 数据来源及整理
笔者本次调查分析的文献均来源于CNKI数据库,检索时间为2017年5月29日,以2006—2016年为检索时间,时间跨度为10年,以“数据挖掘”为主题词进行检索,得到包括主题词、关键词、标题、参考文献等总计34,155条文献记录,统计后得到2006—2016年间数据挖掘领域每年的文献发表分布图(见图1)。图1显示,在2006—2016年,每年数据挖掘文献的发表数量都在2,000篇以上,由此可见,数据挖掘及数据挖掘相关领域都有较高的关注热度。从2012年起,数据挖掘相关文献的发表数量一直呈逐年上升趋势,并且在2016年首次超过了4,000篇,预计未来几年内,数据挖掘仍然会是各领域关注及应用的热点内容。
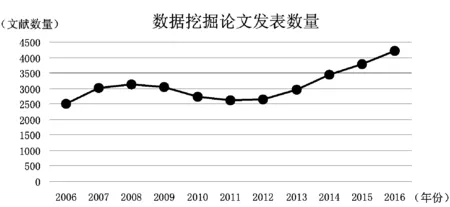
图1 2006—2016年数据挖掘论文发表数量情况图
2.2 生成图谱及其分析
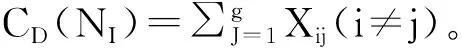

图2 2006—2016年数据挖掘关键词共现图
表1 2006—2016年数据挖掘相关文献关键词频次表
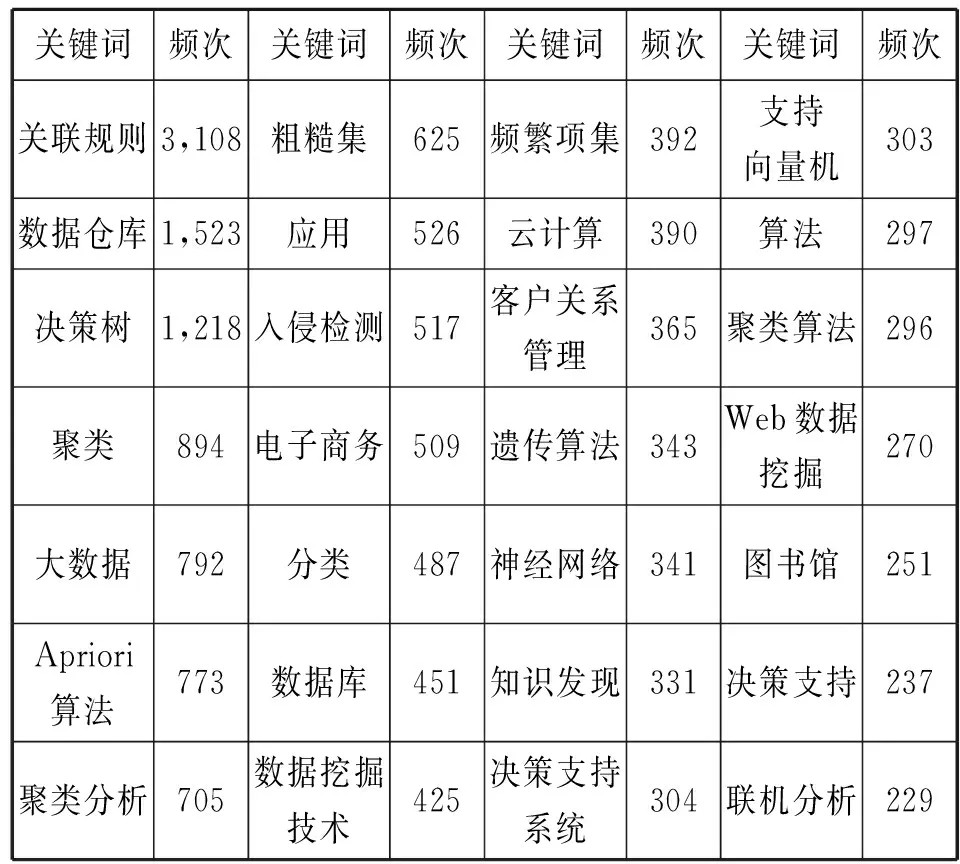
关键词频次关键词频次关键词频次关键词频次关联规则3,108粗糙集625频繁项集392支持向量机303数据仓库1,523应用526云计算390算法297决策树1,218入侵检测517客户关系管理365聚类算法296聚类894电子商务509遗传算法343Web数据挖掘270大数据792分类487神经网络341图书馆251Apriori算法773数据库451知识发现331决策支持237聚类分析705数据挖掘技术425决策支持系统304联机分析229
2.2.2 作者分布图谱。笔者通过CNKI可视化分析工具对数据挖掘文献的作者分布进行统计后发现(由于篇幅所限仅截取排名前11位作者的文献分布情况),胡学钢与杨炳儒从2006年开始发表数据挖掘的相关文献,此后几年陆续发表了大量的文献,但自2011年起文献发表数量逐年下降。唐常杰、杨洪军、范欣生与上述两位作者同期开始发表数据挖掘文献,并延续至今,发文量虽然不高但他们在长期坚持进行数据挖掘研究。吴嘉瑞与任玉兰较上述作者稍晚开始发表数据挖掘文献,且前期研究成果较少,但他们与张冰、张晓朦在近期都有大量的研究成果发布。笔者调查后发现,最近发文数量处于高峰期的张冰、吴嘉瑞和张晓朦都隶属于北京中医药大学,任玉兰和唐仕欢隶属于医学界,说明现阶段医学界十分重视对数据挖掘领域的研究(见图3)。

图3 2006—2016年数据挖掘文献作者分布图
2.2.3 机构分布图谱。不同机构在同一学科中的贡献是不同的,某些机构在不同时段对同一学科领域的关注度也不同。笔者利用CNKI可视化分析工具对30所高校在不同时期数据挖掘领域的发文数量进行了分析,由于篇幅所限仅以排名前13位的高校为例(见图4)。其中,北京科技大学和合肥工业大学自2006年开始大量发布数据挖掘的研究成果,但在高峰期过后整体呈下降趋势且持续至今;北京中医药大学则处于相反的状态,该校在2006年的发文数量较少,但其后研究成果与发文数量整体呈上升趋势;武汉大学也是在2006年开始发表数据挖掘文献的,随后几年持续有大量文献发表,特别是近年来该校文献发表数量呈大幅上升的趋势;四川大学、吉林大学、同济大学和中南大学在2006年有较多的文献与研究成果发表,之后呈平稳的发展态势;清华大学在2006年发表了大量的数据挖掘文献成果后长期呈下降趋势,但在2012年转变为上升趋势。图4显示,高校是发表数据挖掘领域文献的主力军,企业和科研院所发表的成果相对较少,这说明数据挖掘领域的研究工作一般由高校承担。机构的分布在一定程度上表明了当地对数据挖掘领域的重视程度,由图4可知,我国南方沿海地区及中原北部地区对数据挖掘领域研究的重视程度较高,而西北及西南地区对数据挖掘领域研究的重视程度相对较低。综合数据挖掘的文献数量,武汉大学在该领域的研究处于领先地位,其在2006年就已经发表了相当数量的数据挖掘文献,并且近年来其在该领域的研究热度仍然没有降低,在未来几年仍然会是该研究领域的主力军;合肥工业大学的数据挖掘文献发表数量虽然仅次于武汉大学,但这些文献大多发表在2011年以前,最近几年该校降低了对数据挖掘领域的关注度;北京中医药大学在数据挖掘领域的研究起步较晚,发文数量也相对较少,但近年来其在数据挖掘领域的研究发展迅速。

图4 2006—2016年数据挖掘领域文献机构分布图
2.3 分析结果
笔者对关键词及关键词共现图谱、作者分布图谱、机构分布图谱进行分析,从研究主题上看,数据挖掘的研究一直处于发展中,并且不满足于仅对数据挖掘方法理论的研究,而是逐步将技术应用纳入研究主题,不断将研究范围延伸到其他领域,如近年来对数据挖掘进行应用的医学领域;从作者分布看,新兴领域作者发文数量逐渐增多,理论研究领域发文数量相对减少;从机构分布看,各机构在其关注领域处于发展热点时期时,发文数量会明显上升,并且会带动整个学科领域的发展和应用。目前,虽然数据挖掘领域的文献发表大多集中在一些名校,但是新兴的应用领域机构的影响力及发展不应被忽视,未来其在该领域也可能拥有话语权。
3 数据挖掘的热点与趋势
3.1 数据挖掘的理论技术研究
进行数据挖掘理论技术研究可以使数据挖掘技术理论体系更加完善,能够囊括随时代技术发展而出现的其他类别的技术理论领域,能够对大量数据资源进行高效率及有效的分析,并得到正确的词间关系或潜在知识。因此,数据挖掘理论体系的研究和发展是十分有必要的。
3.2 数据挖掘的应用技术研究
单独存在的理论知识对用户的意义不大,只有将理论转化为应用技术才能创造出新的价值。企业和用户会出于利益和实用性等目的产生重点关注对象,如电子商务挖掘和客户关系管理等数据挖掘应用系统。因此,数据挖掘的应用技术会在企业和用户的明确需求下得到科学的发展。
3.3 大数据云计算的数据挖掘研究
大数据云计算是一种新的计算模式,是分布式处理、并行处理和网格计算、网络存储、虚拟化、负载均衡等传统计算机技术和网络技术发展融合在一起的产物[9]。大数据、云计算注重的是在对海量资源进行快速、有效的分析后,得到蕴含在资源内部的隐藏知识和相关联系,数据挖掘技术在该领域的发展过程中必须注意安全与隐私问题[10]。在数据挖掘过程中会出现专利侵权和网络泄密等问题,而敏感信息的泄密会严重影响用户体验,如何在不触及隐私及安全的前提下进一步发展数据挖掘技术和工具,是学界未来需要研究的一个重要课题。
4 结语
综上所述,数据挖掘越来越受社会各界关注,成为一个热门的研究课题,这说明数据挖掘的理论、技术及应用都具有重要的意义。目前,大数据挖掘已经涉及越来越多的领域,如近年来在医学领域的大幅应用,在未来还会涉及更多的领域。但数据挖掘并不是全能的,它只是一个分析方法和工具,还需要专业人员根据具体情况,结合相关行业的大环境以及国家的政策法规等进行综合分析后,才能得到正确及专业的数据挖掘信息。
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
速读·下旬(2021年11期)2021-10-12
大众投资指南(2021年35期)2021-02-16
北京航空航天大学学报(2020年10期)2020-11-14
大东方(2019年12期)2019-10-20
小学生学习指导(低年级)(2019年3期)2019-04-22
科学与财富(2017年22期)2017-09-10
商情(2017年1期)2017-03-22
电子技术与软件工程(2016年24期)2017-02-23
初中生世界·七年级(2017年2期)2017-01-20
