
基于科技知识组织体系的标引框架研究与应用
2018-08-22 01:39刘春江胡正银
图书馆理论与实践 2018年7期
刘春江,胡正银,方 曙,钱 力
(1.中国科学院成都文献情报中心;2.中国科学院大学;3.中国科学院文献情报中心)
1 概述
在大数据环境与数据密集型科学研究新范式下,科技文献知识组织方式向基于概念单元或知识单元的知识组织方向发展。[1,2]为了满足多层次、细粒度知识组织和知识关联的需求,需要采用自动或半自动方式对科技文献进行主题标引。从方法上看,文献的自动标引一般都会综合运用统计学、语言学或机器学习等多种抽取方法,但会以某种具体方法为主,如,Frank[3]等主要采用了基于机器学习的抽取方法,使用了怀卡托大学开发的关键词抽取工具(Keyword Extraction Algorithm,KEA),[4]利用训练文档集建立抽取模型;Hulth[5]主要采用了基于语言学的抽取方法,使用了爱丁堡大学开发的开源工具LT-TTT2,[6]利用文本中的语言学特征抽取术语;Plas[7]等主要采用了基于词典的抽取方法,利用了WordNet[8]词典中词汇的基本语义关系(如IS-A和PART-OF等)及其一词多义解释等特点。虽然这些文献自动标引的方法能够实现一定精度的术语与概念的自动抽取,但是无法更进一步实现术语的规范化与概念的关联化,也就不能达到对文献进行知识组织的最终目的。
科技知识组织体系(Scientific&TechnologicalKnowl edgeOrganization Systems,STKOS)是“十二五”国家科技支撑计划“面向外文科技文献信息的知识组织体系建设与应用示范”项目的核心成果,是一套基于常用自然科学领域词表的超级词表。STKOS术语发布与共享服务平台[9]提供了一系列标准化、集成化的开放查询和推理接口,使第三方应用可以灵活地将STKOS检索、查询和推理功能嵌入到自己的服务中。[10,11]本文提出了基于STKOS的标引框架,实现了STKOS与标引流程的深度嵌入,可以高效地对科技文献蕴含的知识单元进行自动化抽取、主题标引与语义关联。
2 基于STKOS的标引框架
基于STKOS的标引框架由接口层、数据层和业务层组成,主要思路如下:① 从文本中自动抽取出一定数量且能够表征文献主题的关键词,形成术语集;② 在STKOS超级词表中检索与这些术语相匹配的优选词,实现术语到概念的映射,形成概念集;③ 根据STKOS,建立概念的语义关联(见图1)。

图1 基于STKOS的标引框架
接口层主要实现了对STKOS的Webservice开放查询和推理接口的调用。数据层包含各种非结构化文档,如论文、专利、专著、标准等,主要是通过对文档载体(如PDF和WORD)进行文本的自动提取。
业务层主要展示了STKOS的应用环节。由于机器学习算法比较成熟,流程清晰,有大量的开源框架可供系统集成,本文使用了基于机器学习的术语抽取方法。具体的流程是:首先确定文本所属领域,从STKOS中导出领域词表,结合训练集,构建领域标引模型,然后使用模型对文本进行自动标引,之后调用STKOS进行术语规范,通过人工的审核校验,最后基于STKOS对文献的概念集建立语义关联,完成标引流程。
3 STKOS在标引框架中的具体应用
3.1 术语抽取
本研究选择KEA来抽取术语,KEA基于JAVA语言实现,提供基于简单知识组织系统(SimpleKnowledge OrganizaticnSystem,SKOS)词表的自动关键词抽取。
从标引框架可以看出,构建面向领域的标引模型非常重要。具体来说,建立模型分三步完成。
(1)从STKOS中导出相关范畴的领域词表。笔者实现了STKOS查询与推理引擎的浏览服务接口(Browser Service)和关联推理服务接口 (RelatedSearch Service)。针对浏览服务接口,主要实现了在STKOS超级词表中下位范畴类的获取和范畴下概念的获取;针对关联推理服务接口,主要实现了在STKOS超级词表中上下位和相关概念的获取(见表1)。

表1 STKOS接口中被使用的方法和功能
领域词表的载体采用了SKOS词表,以“人工智能”范畴为例,由于SKOS词表是建立在RDF之上,因此在表头先要定义文件的RDF属性,然后建立该RDF文件的概念表属性,这里可以定义为:
获取“人工智能”范畴category1;
while(category1有下位范畴)
获取下位范畴category2;
获取category2下的概念列表concepts;
for each概念列表concepts中的概念concept do
if RDF中没有该概念concept,Then定义新的skos:Concept属性,加入skos:preflabel中;
if concept有上位概念,Then加入skos:broader中;
if concept有下位概念,Then加入skos:narrower中;
if concept有相关概念,Then加入skos:related中;
end for
end while
(2)构建训练集。任意选择一定数量的文献,针对每篇文献,将文本内容放到“txt”为后缀的文件中,由领域专家从领域词表中选择数量不等的概念作为标引词,将标引词放到“key”为后缀的文件中,两个文件的文件名必须一致。
(3)建立模型。基于领域词表和训练集构建标引模型,模型建立的步骤如下:① 在任意文件夹下新建模型根目录,如“AI”;② 在“AI”下面针对抽取文本的语种建立目录,如,“en”表示抽取文本的语种是英语,同时建立词表目录“vocabulary”;③ 在“en”下面建立训练集目录,如“train”;④ 把训练集(包含多个txt和key文件组)放到训练集目录下面;把前面生成的领域词表放到词表目录下面;⑤ 在程序中设置相关参数,包括词表位置、格式和编码等,然后执行程序,会在“en”目录下生成模型文件“model”。
标引模型和领域词表建立完成后,就可以基于该模型文件和SKOS词表,利用KEA对输入文档集进行术语的自动抽取,针对每篇文档形成术语集。
3.2 术语规范
在术语集里面,术语有可能不在领域词表的概念之中,因此需要利用STKOS进行概念规范,概念规范由术语规范和审核校验两个环节组成。在术语规范过程中,笔者实现了STKOS查询与推理引擎的关联推理服务接口(RelatedSearch Service),利用了获得规范词方法 getStandardWord(List

图2 术语规范流程图
3.3 审核校验
由于可能存在概念明显错误或者数量过少等问题,需要审核人员对文献的自动分析结果进行人工校验。审核人员首先判断文献的概念集是否需要新增或者删除,如果需要新增,那么就在输入接口中填入术语,利用获得规范词方法getStandardWord(List
3.4 语义关联
语义关联主要基于STKOS建立概念与范畴之间的关系以及概念本身的上位、下位和相关关系。本研究主要实现了在STKOS超级词表中上位范畴类和概念所属范畴的获取以及在STKOS超级词表中上下位和相关概念的获取(见表2)。
文献概念的语义关联载体也采用通用的SKOS词表格式,以“人工智能”领域下的文献为例,定义SKOS词表属性的算法如下所示,最终生成的SKOS词表见图4。

图3 审核校验流程图
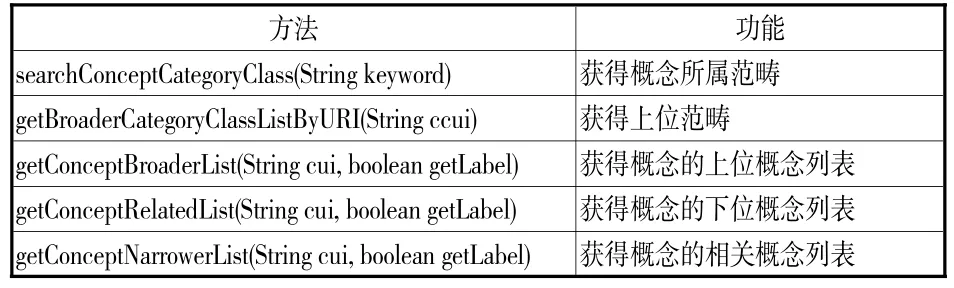
表2 STKOS接口中被使用的方法和功能

图4 文献概念的语义关联简单知识组织体系词表图
foreach概念列表concepts中的概念conceptdo
if RDF中没有该概念concept,Then定义新的skos:Concept属性,加入skos:preflabel中;
ifconcept有上位概念,then加入skos:broader中;
if concept有下位概念,then加入skos:narrower中;ifconcept有相关概念,then加入skos:related中;foreach该概念的范畴列表categories中的概念category do
if category在“人工智能”领域词表里面,then加入skos:category中;
end for end for
4 标引框架的应用示范
笔者已在中科院成都文献情报中心重要会议开放资源采集与服务系统(以下简称采集服务系统)[11]上进行集成和整合,通过应用本标引框架,使得标引人员可以获得效果较好的推荐信息,快速完成对文献和会议的准确标引。具体来说,在文献主题词规范环节,标引人员可在主题词列表中对术语规范后的主题词进行校验(修改或者删除),还可调用接口查询STKOS获取到新的规范主题词,并增加到主题词列表中;校验完成后,标引人员保存主题词列表即可完成对单篇文献标引结果的审核。在学科分类界面图中,系统除了可以根据文献主题词调用接口列出推荐的学科分类列表,还可以调用接口列出STKOS的学科树,标引人员选择正确的会议所属学科分类进行保存即可完成对单个会议标引结果的审核。
5 结语
STKOS作为面向计算机应用开发的具有一定规模的超级科技词表,涉及的科技领域范围广、科技术语和科技概念数量多。因此,如何利用STKOS有效地服务于外文科技文献的信息揭示、知识组织和知识发现成为当务之急。本研究针对标引环节可能会遇到的四个应用点,包括领域词表导出、术语规范、审核校验和语义关联等,在STKOS查询与推理引擎中找出了需要使用的接口方法,形成了一套标引框架,为国内基于STKOS的应用工作提供示范。
猜你喜欢
计算机与现代化(2022年5期)2022-06-06
南京中医药大学学报(2022年5期)2022-05-18
英语世界(2021年13期)2021-01-12
实用医药杂志(2021年4期)2021-01-11
中国医学计算机成像杂志(2020年6期)2020-03-14
资源信息与工程(2019年2期)2019-05-09
山西青年(2019年14期)2019-01-15
中国骨与关节杂志(2016年12期)2016-01-23
对联(2011年20期)2011-09-19
