
基于IRIV算法优选大豆叶片高光谱特征波长变量估测SPAD值
2018-08-22 03:18朱亚星
农业工程学报 2018年16期
于 雷,章 涛,朱亚星,周 勇,夏 天,聂 艳
(1. 华中师范大学地理过程分析与模拟湖北省重点实验室,武汉 430079;2. 华中师范大学城市与环境科学学院,武汉 430079;3. 华中师范大学可持续发展研究中心,武汉 430079)
0 引 言
叶绿素是植物营养胁迫、光合能力和衰老进程各阶段的良好指示剂[1]。监测大豆叶片的叶绿素状况,对大豆生长诊断与施肥调控等具有重要意义[2]。SPAD(soil and plant analyzer development)值是叶绿素的相对含量,与叶绿素含量具有良好的相关性,可准确表征叶绿素含量[3]。目前,普遍采用便携式叶绿素仪单点测定植物叶片SPAD值,不仅需要反复接触叶片,而且不适于大范围叶绿素信息获取[4]。高光谱遥感技术具有高效率、非接触、不破坏、无污染等特点,为获取植物叶片 SPAD值提供了一种新方法。然而,叶片近红外光谱的吸收峰严重重叠,导致光谱中存在冗余信息,影响了高光谱估测叶绿素含量模型的精度[5]。因此,分析叶绿素的光谱特征,揭示叶绿素的高光谱响应规律,确定叶绿素的敏感波长变量,对提升叶绿素高光谱估测模型的运行效率、简化模型结构和增强模型稳定性具有重要意义。
变量筛选方法是从高光谱波段信息中挖掘隐藏信息,提取与估测目标相关的特征波长变量方法的总称[6],主要具有3个优点:1)消除无信息和干扰信息变量提高模型预测能力;2)挑选信息变量增强模型可解释性;3)降低数据维度提升模型运行速度[7]。常见的变量筛选方法可分为 2类,一类是以变量数理统计特征为基础,主要包括无信息变量消除法(uninformative variables elimination,UVE)、竞争适应重加权采样法(competitive adaptive reweighted sampling,CARS)、连续投影算法(successive projections algorithm,SPA)等。UVE方法可以滤除高光谱中的无效信息变量,但保留变量数依然较多[8];CARS和SPA方法分别可以剔除冗余信息变量及消除共线性信息变量,然而筛选结果中可能存在较低信噪比的变量[9-10]。另一类是基于优化算法搜索最优变量,主要有逐步选择、前向选择、反向消除、遗传算法(genetic algorithm,GA)等,此类方法可全局搜索有效信息变量,但运算过程耗时长,模型参数复杂且难以彻底搜索所有可能的变量组合[11]。上述方法均较好地实现了高光谱特征波长变量的筛选,然而未对筛选结果进行细化分析和归类,未考虑变量之间的联合效应,易忽视与叶绿素关系较弱的信息[12]。迭代保留信息变量算法(iteratively retains informative variables,IRIV)[12],假设所有变量被采样的几率相同,不将变量当作独立的个体,充分考虑波长变量间的联合效应,根据变量重要性将其划分为强信息波长变量(strongly informative variable)、弱信息波长变量(weakly informative variable)、无信息波长变量(uninformative variable)和干扰信息波长变量(interfering variable)等4类[13],经过迭代分析运算,排除无效及干扰信息变量,从强信息波长变量和弱信息波长变量中提取特征波长变量。IRIV算法可尝试用于研究叶片光谱弱信息变量在揭示叶绿素高光谱响应规律及构建叶绿素估测模型中的作用。
因此,本研究以江汉平原大豆叶片为研究对象,分析叶片光谱特征,采用IRIV算法筛选光谱特征波长变量,建立大豆叶片 SPAD值估测模型。研究方法可为叶绿素动态监测提供技术支撑,研究结果可为研发叶绿素高光谱传感器提供理论依据。
1 材料与方法
1.1 叶片样品采集与分析
本研究选取湖北省潜江市竹根滩镇(112°52¢~112°59¢E,30°25¢~30°34¢N)作为试验区,其位于江汉平原腹地,地势平坦;属于亚热带季风性湿润气候,四季分明,雨量充沛;耕地地力优越,主要种植大豆、棉花和花生等旱生作物;该试验区为优质高蛋白大豆标准化生产示范基地,大豆种植类型主要为鄂豆系列,采用配方施肥,栽培技术相对统一。在试验区范围内,选取 80块种植大豆的田块作为样点,相邻样点的东西间距不小于200 m,南北间距不小于1 000 m,每个样点均为面积不低于1 hm2的连片耕地。由于试验区范围大,样点距离较长,试验环境变化及光谱仪频繁校正会影响光谱数据的稳定性和精确性[14],因此本研究在试验环境稳定的室内进行光谱采集。试验时间处于大豆鼓粒期,每个样点采集 6片具有代表性且生长健康的叶片,立即装入自封袋排除空气放入冰盒暂存,在2 h内转移至4 ℃冰箱中冷藏保存,充分保证室内测定光谱时叶片的新鲜度。
采用日本KONICA MINOLTA公司生产的SPAD 502叶绿素仪测定SPAD值,其原理是夹紧叶片测量叶片在2个波长(650、940 nm)的吸收率反演叶绿素的相对含量,直接显示SPAD值。每个样点测定6片叶片,6片叶片SPAD值的平均值作为该样点的SPAD值;最终获得80个样点的SPAD值。
1.2 叶片样本集的划分
采用浓度梯度法划分样本集[15],将80个样点作为总体样本集(whole set);根据各样点的SPAD值由小到大排序,依次每隔 2个样本取一个作为验证集(validation set),共计26个样本;其余54个样本作为建模集(calibration set)。每个数据集SPAD值的描述性统计见表1。
1.3 叶片光谱数据的测定及预处理
本研究采用美国Analytical Spectral Devices公司生产的ASD HandHeld 2型地物光谱仪测定叶片高光谱数据,波谱范围为350~1 075 nm,采样间隔为1.5 nm,重采样输出间隔为1 nm。光谱测量在暗室内进行,光源为能够提供平行光线的 50 W 卤素灯,其到叶片表面距离为30 cm,光源入射角度为30°;光钎探头视场角为25°,探头到叶片表面距离为10 cm;将每个样点6片叶片平铺在黑色吸光布上,叶片平铺面积约为 80 cm2,使其完全覆盖光谱视场范围。每次采集光谱前,用白板(反射率近似 100%)对光谱仪进行优化和标定。每个样本保存 10条光谱曲线,对其进行算术平均后得到该样本的叶片原始光谱。每条光谱去除噪声较大的边缘波段(350~399 nm,1 001~1 075 nm),保留400~1 000 nm。采用Savitzky-Golay平滑对全部光谱数据进行预处理,降低因试验环境和仪器本身而产生的噪音。
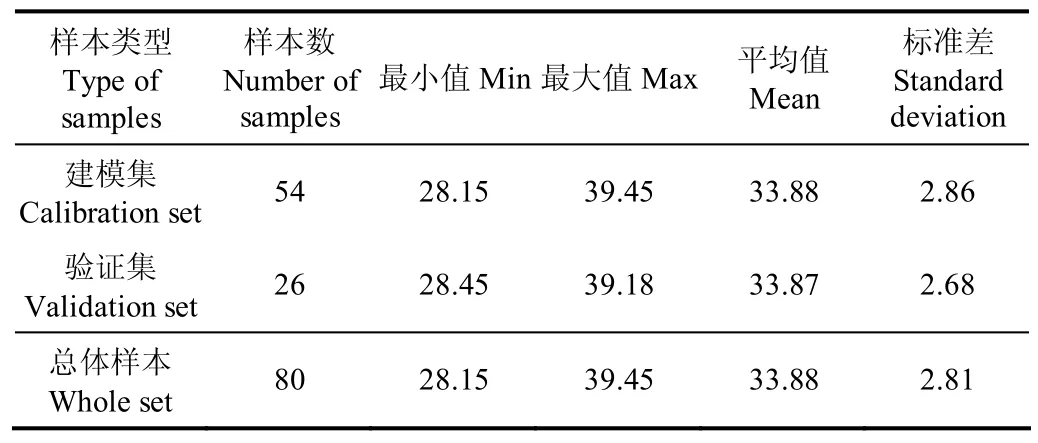
表1 各数据集SPAD值的描述性统计Table 1 Statistical characteristics of SPAD value
1.4 IRIV波长变量筛选算法
IRIV算法利用变量的随机组合并充分考虑变量间的相互作用,在二进制矩阵重排过滤器的基础上,将所有变量生成随机组合的二进制矩阵(行为变量的随机组合,列为变量数),基于矩阵每一行(即变量的随机组合)分别建立偏最小二乘模型,利用交叉验证均方根误差(RMSECV)评估不同随机变量组合模型效果。基于模型集群分析方法,逐个波长变量计算包含和不包含该变量时的 RMSECV平均值,得到两者之差 DMEAN(difference of mean values)和非参数检验方法曼-惠特尼U检验的P值,确定该变量的重要性(表2)[12],每一次迭代后都会产生不同的DMEAN和P值,均保留强信息波长变量和弱信息波长变量,经多次迭代循环直至消除无信息波长变量和干扰信息波长变量,最后进行反向消除获得最优特征波长变量[16]。本文定义分布于可见光波段的波长变量为“可见光变量”,分布于近红外波段的波长变量为“近红外变量”。
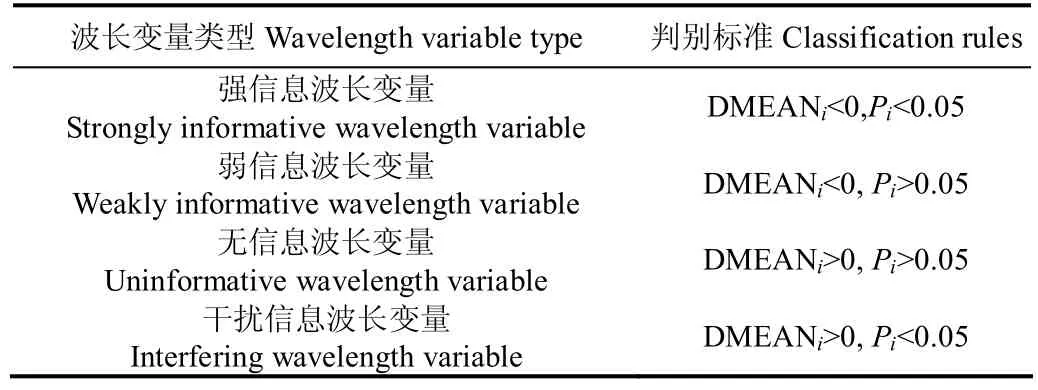
表2 变量分类规则[12]Table 2 Variable classification rules
1.5 模型构建与检验
本文分别采用线性和非线性建模方法,定量描述叶片SPAD值与特征波长变量之间关系,建立SPAD估测模型。其中,线性建模方法为偏最小二乘法(partial least squares regression,PLSR),其借鉴了多元线性回归分析、典型相关分析和主成分分析的思想,在提取主成分减少光谱维数的同时考虑了目标变量的作用,可以较好地解决样本数量小于波长数量的问题,以及自变量之间存在多重相关性的问题[17];非线性建模方法为支持向量机(support vector machine,SVM),其能较好地解决自变量与因变量之间的非线性复杂关系,将非线性不可分的问题在高维空间(超平面)中转化为线性可分,具体处理过程可概括为升维和线性化[18]。本文采用 RBF核函数[19],利用网格参数寻优确定SVM建模的最佳惩罚参数C和核参数g。
利用3个参数即决定系数(R2)、均方根误差(RMSE)、相对分析误差(RPD)检验SPAD估测模型性能。其中,R2值越接近于1,表明模型的稳定性及拟合度越高;RMSE值越接近于 0,表明模型预测能力越强;RPD值是计算样本标准差与均方根误差比值得到,若 RPD<1.4,模型对样本无法实施预测,1.4≤RPD<1.8,模型可对样本进行粗略评估,1.8≤RPD<2.0,模型可对样本进行较好的评估,RPD≥2,模型可对样本进行极好的预测[20]。
2 结果与分析
2.1 叶片光谱特征分析
将建模集样本的 SPAD值由高至低排序,选取四分位样本,分析其原始光谱反射率曲线(图1)。结果表明,4个样本的反射率曲线整体形态具有较高的相似性,可见光波段范围内,500~600 nm为高反射区,在550 nm附近出现一个波峰,400~500与600~700 nm为2个低反射区,从700到760 nm反射率呈陡增趋势;近红外波段范围内,760~1 000 nm为强反射区,曲线接近水平。另外,4个样本的反射率曲线在局部存在反射率相差低于0.1的微弱差异,在高反射区(500~600 nm),随SPAD值升高,反射率呈现逐渐降低单调变化的规律;在强反射区(760~1 000 nm),随SPAD值升高,反射率未出现单调变化的规律。
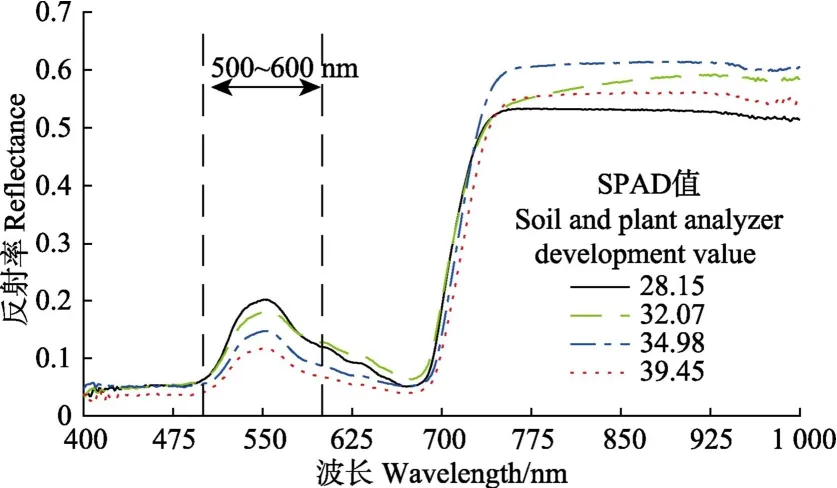
图1 大豆叶片原始光谱反射率Fig. 1 Spectral reflectance curve of soybean leaves
2.2 叶片SPAD值与光谱反射率相关性分析
逐个计算叶片 SPAD值与各波长变量的相关系数,得到全波段的相关系数曲线(图 2)。结果表明,可见光波段 SPAD与光谱变量为负相关,相关系数曲线在 550和710 nm附近出现2个明显的低谷,谷底对应的相关系数分别为-0.70和-0.53;近红外波段SPAD与光谱变量为正相关,从760到1 000 nm相关系数平稳上升,相关系数最大值约为0.2。通过P=0.01显著性检验,得到500~650 nm、690~730 nm波段为极显著负相关。
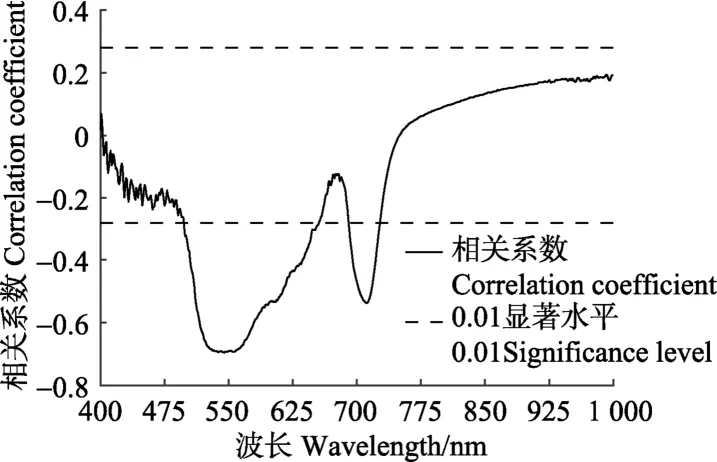
图2 SPAD值与波长相关系数Fig.2 SPAD value and wavelength correlation coefficients
2.3 波长变量之间相关性分析
全波段的波长变量两两之间的相关性分析表明(图3),可见光波段与近红外波段相对独立,2个波段之间的变量相关性较弱,2波段内部的变量相关性较强;可见光波段内部,在500 nm附近的波长变量与其他波长变量具有较高的相关性;近红外波段内部,800 nm之后的变量之间的相关系数绝对值(R)均高于 0.8,说明波长变量之间相关程度高,存在较严重的相互干扰,近红外部分的光谱数据存在较大冗余。
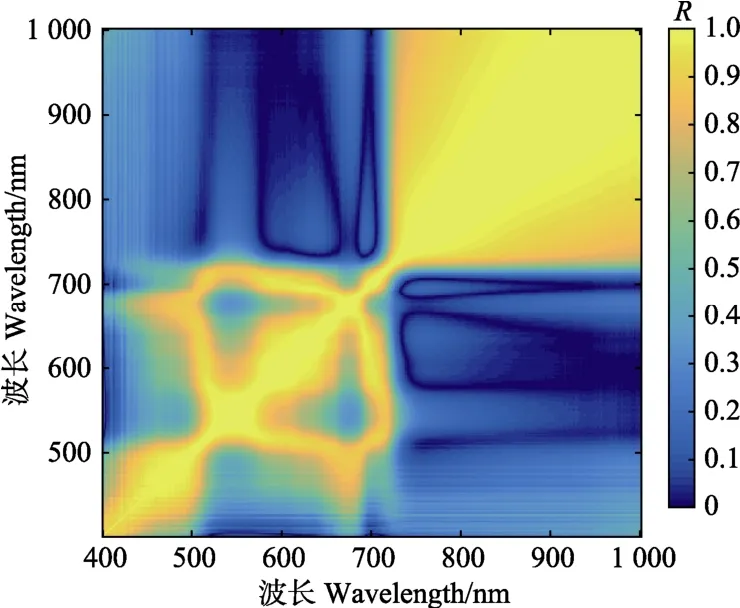
图3 波长变量二维相关系数Fig. 3 Two-dimensional correlation coefficient of wavelength variable
2.4 采用IRIV算法筛选光谱特征波长变量结果
本文确定IRIV算法的交叉验证次数为5,最大主成分数为10[12]。随着迭代次数的增加,保留变量数随之降低,下降趋势逐渐平缓(图4a)。在本研究中迭代次数为5次,之后为反向消除。限于篇幅,仅展示第5次迭代所保留的16个波长变量的DMEAN和P值(图4b),结合表2的规则,可划分变量类型。
IRIV算法经过数轮迭代分析后,从全部601个光谱波长变量中筛选出强信息波长变量 6个和弱信息波长变量10个。其中,强信息波长变量全部为可见光变量,分别是540、541、544、545、568、569 nm;弱信息波长变量包括7个可见光变量(542、549、550、556、557、558、559 nm),3个近红外变量(813、814、815 nm)。通过反向消除从强信息波长变量和弱信息波长变量中筛选了 9个(包含5个强信息波长变量和4个弱信息波长变量)与 SPAD值相关的最优特征波长变量,其中,可见光变量 8 个:540、541、544、545、549、550、556、568 nm;近红外变量1个:814 nm。
经IRIV筛选出的波长中(540,541 nm)、(544,545 nm)、(549,550 nm)两两之间邻近,通过P=0.01显著性检验,存在极显著相关性(相关系数均大于 0.9)。因此,尝试去除相邻的与SPAD相关系数低的波长(541、544、549 nm),保留6个波长(记为IRIV-C):540、545、550、556、568、814 nm。
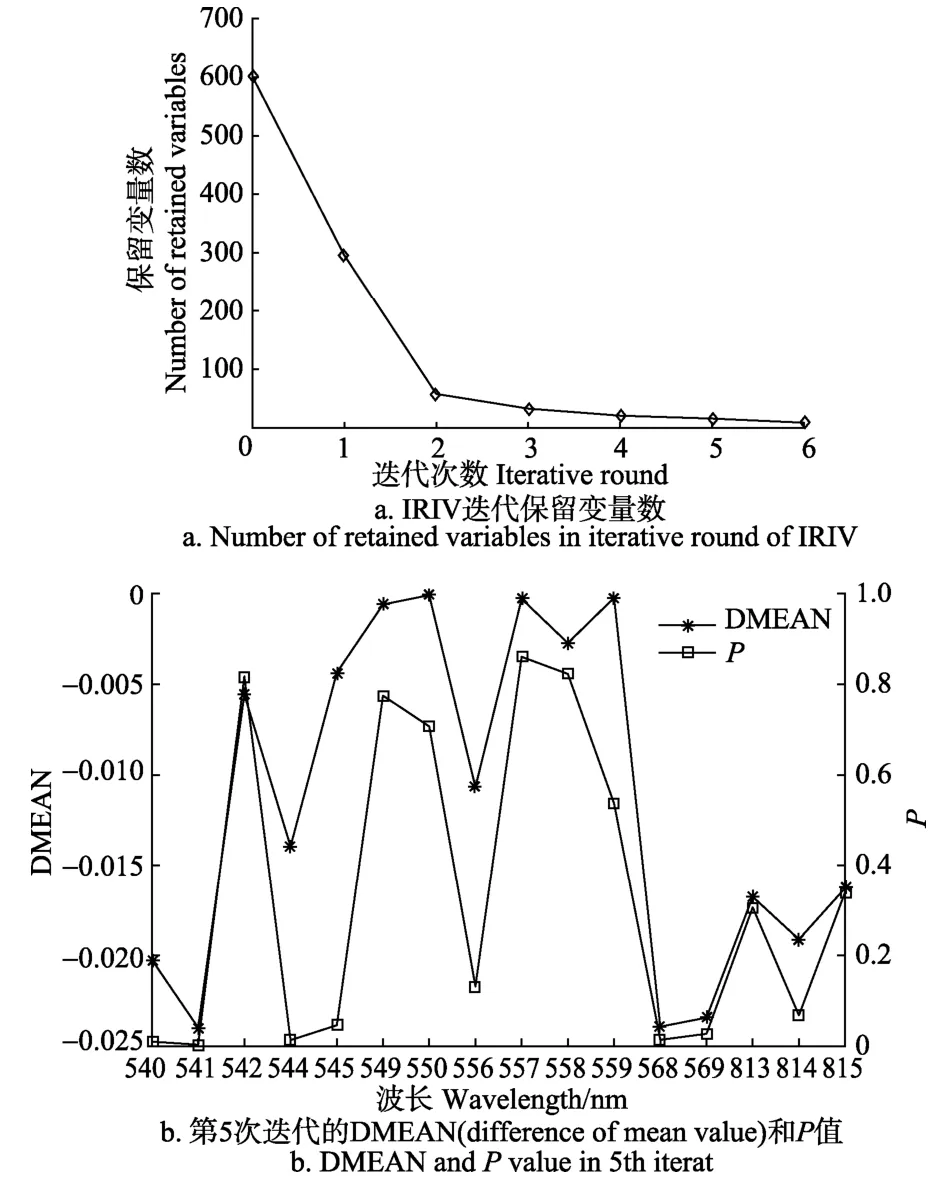
图4 IRIV迭代过程及波长类型判定参数值Fig.4 IRIV iterative process and wavelength type decision parameter values
2.5 模型建立与比较
对比SPAD线性和非线性估测模型结果(表3),基于非线性SVM模型的拟合效果整体上要优于线性PLSR模型,IRIV-SVM 模型效果最好,其建模集和验证集R2分别达到0.80、0.73,RPD达到1.82,表明IRIV-SVM模型可以较好地估测SPAD值,SPAD值与反射率之间的关系更趋于非线性关系。
基于不同自变量的模型效果存在差异,全波段变量(full spectral variables,FULL)模型估测效果整体要优于强信息波长变量(strongly informative variables,SV)模型,表明仅利用SV会损失模型精度,模型估测效果不佳。经IRIV方法筛选后的特征波长变量建立的模型估测效果优于未筛选的FULL模型和SV模型,表明IRIV具有较强筛选能力,加入弱信息波长变量对于提升模型精度有明显效果;易被忽视的弱信息波长变量中存在叶绿素相关信息,对于估测模型精度提升有重要的作用。IRIV-C模型估测效果整体优于FULL与SV模型,与IRIV模型效果相当,表明在IRIV基础上去除自相关性较高的波段,在保持模型精度的同时有利于进一步减少冗余。
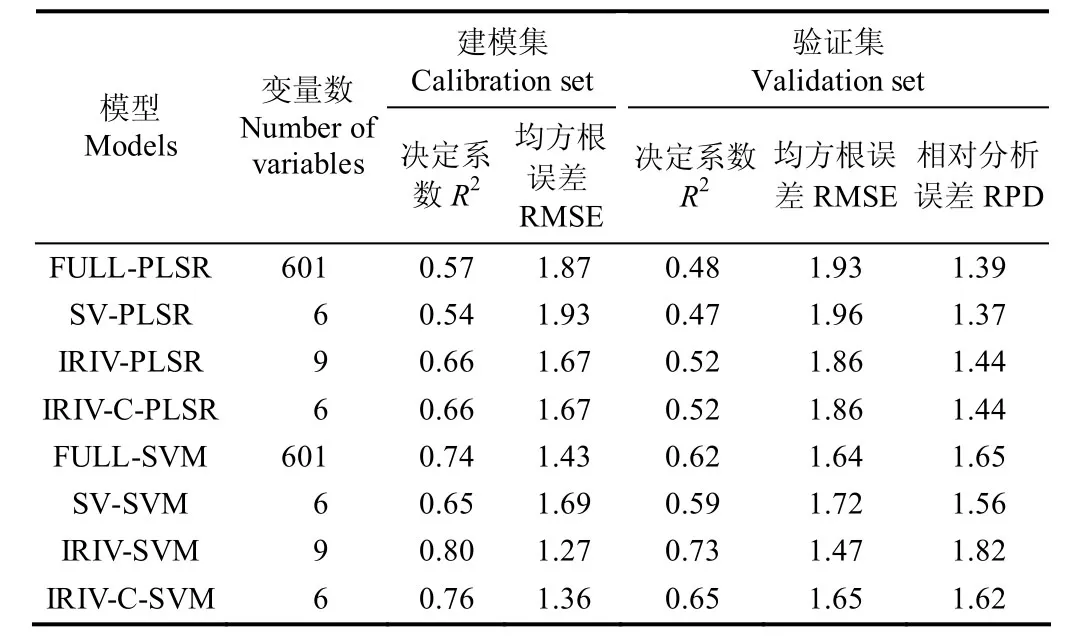
表3 SPAD值估测模型的建模集和验证集结果Table 3 Calibration and validation results of estimation models for SPAD value
由全波段变量和特征波长变量模型验证集1∶1线图(图5)可以看出,相比全波段模型,基于IRIV的特征波长模型的实测值和估测值均匀分布在1∶1线附近,模型精度更高,可以更精确地估测SPAD值。由此表明,IRIV变量筛选方法可以准确提取被掩盖的叶绿素特征波段,有效降低建模的波长变量数,简化模型结构;与常规建模方法相比,估测能力有较大提升。
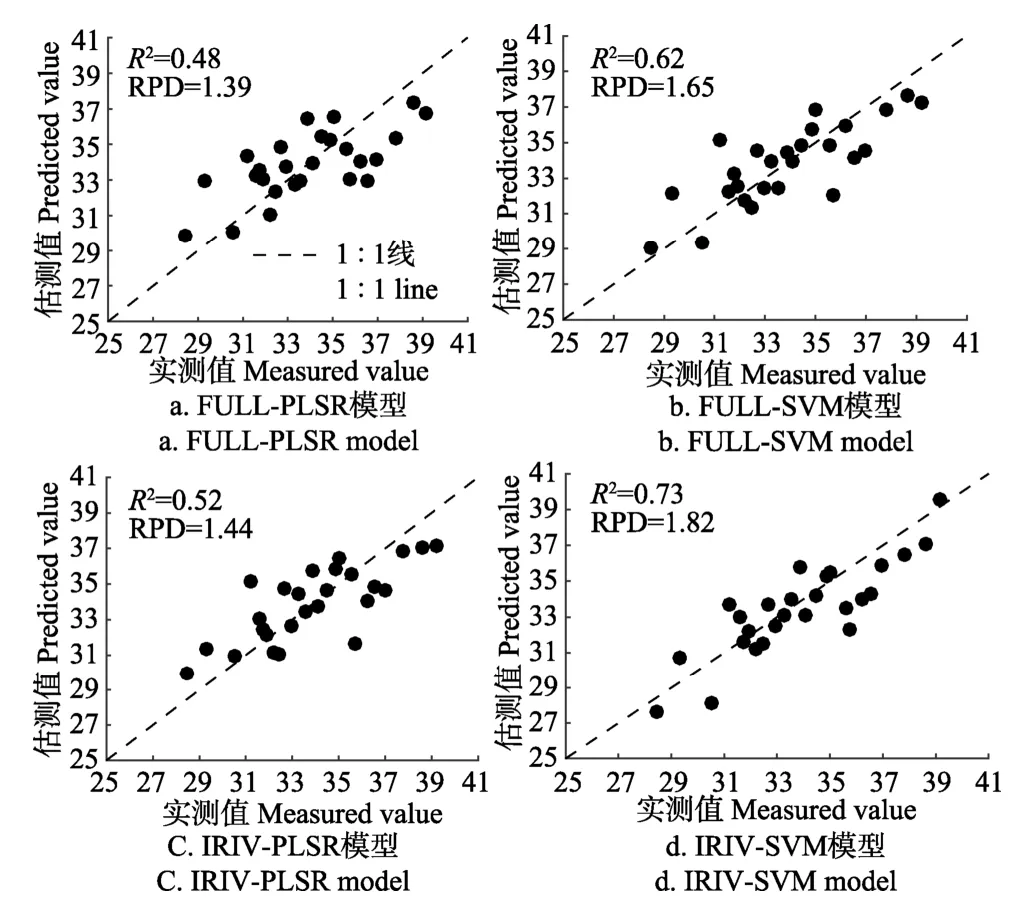
图5 SPAD实测值与估测值比较Fig.5 Comparation of measured and predictive value SPAD
3 讨 论
本研究表明叶片光谱在可见光处吸光强烈,反射率整体较低且波动剧烈,与叶绿素呈显著负相关关系;而在近红外区域反射率较高且平稳,与叶绿素相关性较弱,这与王晓星等[21]研究结果一致。在可见光波段,反射率主要受叶片色素影响,绿光波段是强反射区,而蓝、红光波段的光辐射被叶片中的叶绿素全部吸收而形成 2个低反射区域。受细胞结构及叶片含水率的影响,在近红外波段叶绿素与光谱反射率相关性程度较低[22],其光谱反射率高则由于叶肉内的海绵组织结构内有很大反射表面的空腔,且细胞内的叶绿素呈水溶胶状态,具有强烈的红外反射[21]。基于上述叶片光谱机理,SPAD 502叶绿素仪利用650 nm(强吸收区)、940 nm(强反射区)2个波长测定SPAD值,可准确表征叶绿素含量[3]。为实现大范围叶绿素监测,挖掘叶绿素特征波长信息,学者们利用高光谱技术估测植物叶片 SPAD值,刘京等[22]建立了苹果叶片SPAD值高光谱估测模型,建模集和预测集R2分别为0.74、0.89;殷紫等[23]基于高光谱技术对不同生育期油菜叶片建立SPAD值反演模型,预测模型R2最高为0.70;杨荣超等[4]基于高光谱对甜菜SPAD值进行估测,其模型R2为0.57。前人研究表明高光谱可以较好地估测SPAD,有利于将来大范围监测,但估测精度存在明显差异,需要解决测试环境、仪器、波长变量自相关等因素影响,以进一步提高估测精度。
近红外光谱波段间存在严重自相关性(图 3),导致近红外波长变量与 SPAD值的相关性较弱,而传统的基于光谱特征参数估测叶绿素未充分考虑这一特性,忽略了近红外波段信息[24-26]。王福民等[27]基于水稻光谱研究发现,可见光波段与近红外波段存在大量冗余信息,经信息提取,特征波长在可见光与近红外波段均有分布。王强等[28]基于全波段组合指数构建叶绿素密度估测模型,结果表明近红外波长1 055 nm与可见光波长684 nm的比值归一化指数效果最佳。由此说明,在近红外波段存在与叶绿素相关的有用波长变量。采用变量筛选方法可以最大限度地提取因受外部因素影响而相关性较弱的叶绿素特征波段,有效地压缩波长变量数并简化模型结构[29],本研究表明,通过加入弱信息波长变量可提升模型预测精度。然而,UVE、CARS等变量筛选方法易忽视弱信息波长变量的作用,IRIV方法注重波长变量间的联合效应,考虑弱信息波长变量作用[13],经过数轮迭代分析,筛选出包含叶绿素信息的特征波长变量。Yun等[12,16]先后比较了IRIV、CARS、UVE、GA等多种变量筛选方法,结果表明IRIV算法表现最优,可有效滤除大部分冗余及共线性信息变量。
在本研究中,经IRIV方法筛选出的特征波长变量集中在540~560 nm,由图2可知,该波段波长与SPAD值具有极强的相关性。刘燕德等[11]基于高光谱的GA和SPA算法对赣南脐橙叶片SPAD值定量反演,GA和SPA挑选的敏感波长分别集中在 550~720 nm、520~800 nm,2种算法挑选范围基本吻合,都是叶绿素信息区域波段,含有叶绿素吸收峰。然而,所筛选的波长两两邻近存在较高的相关性,IRIV方法无法完全消除数据间的自相关性,尝试基于波长与 SPAD值相关系数,去除相邻的较低相关系数波长。结果表明该方法在保持模型精度的基础上有利于进一步减少冗余,简化模型结构。
本研究通过筛选特征波长变量结合线性和非线性模型估测大豆叶绿素含量,取得了较好的估测结果。但如何改进筛选方法以降低特征波长变量的自相关性,如何将本研究应用于大豆全生育期及其他种类作物以进一步提升模型鲁棒性,今后需要着重探讨研究。
4 结 论
本研究利用室内大豆叶片光谱数据,基于IRIV算法筛选大豆叶片的光谱特征波长变量,建立估测能力较高的 SPAD值估测模型,为利用高光谱估测植物生理参数提供了一种新的方法和途径。主要结论如下:
1)大豆叶片SPAD值在可见光波段与光谱波长变量相关性较强,尤其在500~650 nm、690~730 nm波段与光谱波长变量为极显著负相关,在近红外波段与光谱波长变量为不显著正相关(P>0.01);
2)大豆叶片可见光波长变量与近红外波长变量之间相关性较弱,而 2波段内部变量相关性较高,尤其近红外波段变量共线问题突出;
3)基于IRIV算法确定了9个大豆叶绿素的特征波长变量,其中,在可见光波段筛选 5个强信息变量和 3个弱信息变量,在近红外波段筛选弱信息变量1个;
4)SVM模型估测效果要优于PLSR模型,PLSR模型验证集R2最高为0.52,SVM模型验证集R2均高于0.59,SPAD值与反射率之间趋于非线性关系;
5)IRIV算法可以有效地确定大豆叶片SPAD值的特征波长变量,基于IRIV特征波长变量模型估测能力优于基于全波段模型和强信息波长变量模型,其中IRIV-SVM表现最优,验证集R2为0.73,RPD为1.82,说明IRIV变量筛选方法的有效性及弱信息变量的重要性。
[1]Merzlyak M, Gitelson A, Chivkunova O, et al. Nondestructive optical detection of pigment changes during leaf senescence and fruit ripening[J]. Physiologia Plantarum,1999, 106(1): 135-141.
[2]杨杰,田永超,姚霞,等. 水稻上部叶片叶绿素含量的高光谱估算模型[J]. 生态学报,2009,29(12):6561-6571.Yang Jie, Tian Yongchao, Yao Xia, et al. Hyperspectral estimation model for chlorophyll concentrations in top leaves of rice[J]. Acta Ecologica Sinica, 2009, 29(12): 6561-6571.(in Chinese with English abstract)
[3]程志庆,张劲松,孟平,等. 杨树叶片叶绿素含量高光谱估算模型研究[J]. 农业机械学报,2015,46(8):264-271.Cheng Zhiqing, Zhang Jingsong, Meng Ping, et al.Hyperspectral estimation model of chlorophyll content in poplar leaves[J]. Transactions of the Chinese Society for Agricultural Machinery, 2015, 46(8): 264-271. (in Chinese with English abstract)
[4]杨荣超,田海清,李斐,等. 基于冠层高光谱的甜菜不同生育时期SPAD值估测研究[J]. 干旱区资源与环境,2017,31(7):50-54.Yang Rongchao, Tian Haiqing, Li Fei, et al. Research on the SPAD values at different growth stages of sugar beet based on canopy hyperspectrum[J]. Journal of Arid Land Resources and Environment, 2017, 31(7): 50-54. (in Chinese with English abstract)
[5]Vohland M, Ludwig M, Thiele-Bruhn S, et al. Determination of soil properties with visible to near- and mid-infrared spectroscopy: Effects of spectral variable selection[J].Geoderma, 2014, s 223–225(1): 88-96.
[6]Zou Xiaobo, Zhao Jiewen, Povey M. J, et al. Variables selection methods in near-infrared spectroscopy[J]. Analytica Chimica Acta, 2010, 667(1/2): 14.
[7]Guyon, Isabelle, Elisseeff, et al. An introduction to variable and feature selection[J]. Journal of Machine Learning Research, 2003, 3(6): 1157-1182.
[8]朱亚星,于雷,洪永胜,等. 土壤有机质高光谱特征与波长变量优选方法[J]. 中国农业科学,2017,50(22):4325-4337.Zhu Yaxing, Yu Lei, Hong Yongsheng, et al. Hyperspectral features and wavelength variables selection methods of soil organic matter[J]. Scientia Agricultura Sinica, 2017, 50(22):4325-4337. (in Chinese with English abstract)
[9]Sun Ye, Wang Yihang, Xiao Hui, et al. Hyperspectral imaging detection of decayed honey peaches based on their chlorophyll content [J]. Food Chemistry, 2017, 235: 194.
[10]Xu Shengxiang, Zhao Yongcun, Wang Meiyan, et al.Determination of rice root density from Vis–NIR spectroscopy by support vector machine regression and spectral variable selection techniques[J]. Catena, 2017, 157:12-23.
[11]刘燕德,张光伟,蔡丽君. 基于高光谱的GA和SPA算法对赣南脐橙叶绿素定量分析[J]. 光谱学与光谱分析,2012,32(12):3377-3380.Liu Yande, Zhang Guangwei, Cai Lijun. Analysis of chlorophyll in gannan navel orange with algorithm of ga and spa based on hyperspectral[J]. Spectroscopy and Spectral Analysis, 2012, 32(12): 3377-3380. (in Chinese with English abstract)
[12]Yun Yonghuan, Wang Weiting, Tan Minli, et al. A strategy that iteratively retains informative variables for selecting optimal variable subset in multivariate calibration[J].Analytica Chimica Acta, 2014, 807(1): 36.
[13]Díaz-Uriarte R, Andrés S A D. Gene selection and classification of microarray data using random forest. [J].Bmc Bioinformatics, 2006, 7(1): 3.
[14]Terra F S, Demattê J A M, Rossel R A V. Spectral libraries for quantitative analyses of tropical Brazilian soils:Comparing vis–NIR and mid-IR reflectance data[J].Geoderma, 2015, s 255–256: 81-93.
[15]刘伟,赵众,袁洪福,等. 光谱多元分析校正集和验证集样本分布优选方法研究[J]. 光谱学与光谱分析,2014(4):947-951.Liu Wei, Zhao Zhong, Yuan Hongfu, et al. An optimal selection method of samples of calibration set and validation set for spectral multivariate analysis[J]. 2014(4): 947-951.(in Chinese with English abstract)
[16]张航,刘国海,江辉,等. 基于近红外光谱技术的乙醇固态发酵过程参数定量检测[J]. 激光与光电子学进展,2017(2):314-320.Zhang Hang, Liu Guohai, Jiang Hui, et al. Quantitative detection of ethanol solid-state fermentation process parameters based on nearinfrared spectroscopy [J]. Laser &Optoelectronics Progress, 2017(2): 314-320. (in Chinese with English abstract)
[17]彭小婷,高文秀,王俊杰. 基于包络线去除和偏最小二乘的土壤参数光谱反演[J]. 武汉大学学报(信息科学版),2014,39(7):862-866.Peng Xiaoting, Gao Wenxiu, Wang Junjie. Inversion of soil parameters from hyperspectra based on continuum removal and partial least squares regression[J]. Geomatics and Information Science of Wuhan University, 2014, 39(7):862-866. (in Chinese with English abstract)
[18]史舟. 土壤地面高光谱遥感原理与方法[M]. 北京:科学出版社,2014.
[19]奉国和. SVM分类核函数及参数选择比较[J]. 计算机工程与应用,2011,47(3):123-124.Feng Guohe. Parameter optimizing for support vector machines classification[J]. Computer Engineering and Applications, 2011, 47(3): 123-124. (in Chinese with English abstract)
[20]Rossel R A V, Mcglynn R N, Mcbratney A B. Determining the composition of mineral-organic mixes using UV–vis–NIR diffuse reflectance spectroscopy[J]. Geoderma, 2006,137(1/2): 70-82.
[21]王晓星,常庆瑞,刘梦云,等. 冬小麦冠层水平叶绿素含量的高光谱估测[J]. 西北农林科技大学学报(自然科学版),2016,44(2):48-54.Wang Xiaoxing, Chang Qingrui, Liu Mengyun, et al.Hyper-spectral estimation of chlorophyll content in canopy of winter wheat[J]. Journal of Northwest A & F University(Natural Science Edition), 2016, 44(2): 48-54. (in Chinese with English abstract)
[22]刘京,常庆瑞,刘淼,等. 基于SVR算法的苹果叶片叶绿素含量高光谱反演[J]. 农业机械学报, 2016,47(8):260-265.Liu Jing, Chang Qingrui, Liu Miao, et al. Chlorophyll content inversion with hyperspectral technology for apple leaves based on support vector regression algorithm[J]. Transactions of the Chinese Society for Agricultural Machinery, 2016,47(8): 260-265. (in Chinese with English abstract)
[23]殷紫,常庆瑞,刘淼,等. 基于光谱指数的不同生育期油菜叶片 SPAD估测[J]. 西北农林科技大学学报(自然科学版),2017(5):66-72.Yin Zi, Chang Qingrui, Liu Miao, et al. Estimation of rape leaf SPAD in different periods based on spectral indices[J].2017(5): 66-72. (in Chinese with English abstract)
[24]徐道青,刘小玲,王维,等. 淹水胁迫下棉花叶片高光谱特征及叶绿素含量估算模型[J]. 应用生态学报,2017,28(10):3289-3296.Xu Daoqing, Liu Xiaoling, Wang Wei, et al. Hyper-spectral characteristics and estimation model of leaf chlorophyll content in cotton under waterlogging stress[J]. Chinese Journal of Applied Ecology, 2017, 28(10): 3289-3296. (in Chinese with English abstract)
[25]刘文雅,潘洁. 基于神经网络的马尾松叶绿素含量高光谱估算模型[J]. 应用生态学报,2017,28(4):1128-1136.Liu Wenya, Pan Jie. A hyperspectral assessment model for leaf chlorophyll content of Pinus massoniana based on neural network[J]. Chinese Journal of Applied Ecology, 2017, 28(4):1128-1136. (in Chinese with English abstract)
[26]冯伟,王晓宇,宋晓,等. 白粉病胁迫下小麦冠层叶绿素密度的高光谱估测[J]. 农业工程学报,2013,29(13):114-123.Feng Wei, Wang Xiaoyu, Song Xiao, et al. Hyperspectral estimation of canopy chlorophyll density in winter wheat under stress of powdery mildew[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2013, 29(13): 114-123. (in Chinese with English abstract)
[27]王福民,黄敬峰,徐俊锋,等. 基于光谱波段自相关的水稻信息提取波段选择[J]. 光谱学与光谱分析,2008,28(5):1098-1101.Wang Fumin, Huang Jingfeng, Xu Junfeng, et al. Wavebands selection for rice information extraction based on spectral bands inter-correlation [J]. Spectroscopy and Spectral Analysis, 2008, 28(5): 1098-1101. (in Chinese with English abstract)
[28]王强,易秋香,包安明,等. 基于高光谱反射率的棉花冠层叶绿素密度估算[J]. 农业工程学报, 2012,28(15):125-132.Wang Qiang, Yi Qiuxiang, Bao Anming, et al. Estimating chlorophyll density of cotton canopy by hyperspectral reflectance [J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2012,28(15): 125-132. (in Chinese with English abstract)
[29]于雷,洪永胜,周勇,等. 高光谱估算土壤有机质含量的波长变量筛选方法[J]. 农业工程学报,2016,32(13):95-102.Yu Lei, Hong Yongsheng, Zhou Yong, et al. Wavelength variable selection methods for estimation of soil organic matter content using hyperspectral technique[J]. Transactions of the Chinese Society of Agricultural Engineering(Transactions of the CSAE), 2016, 32(13): 95-102. (in Chinese with English abstract)
猜你喜欢
冶金能源(2022年5期)2022-10-14
——缺陷度的算法研究
条码与信息系统(2022年3期)2022-07-05
汽车电器(2022年6期)2022-07-02
航天返回与遥感(2022年2期)2022-05-12
阅读(科学探秘)(2021年8期)2021-09-01
照明工程学报(2020年1期)2020-06-16
汽车文摘(2018年2期)2018-11-27
电子制作(2018年2期)2018-04-18
制导与引信(2017年3期)2017-11-02
电子制作(2017年8期)2017-06-05
