
卷积神经网络在异常声音识别中的研究
2018-08-20 06:16吴小培
信号处理 2018年3期
胡 涛 张 超 程 炳 吴小培
(安徽大学计算智能与信号处理教育部重点实验室,安徽合肥 230039)
1 引言
近年来,伴随着社会经济的快速增长以及信号处理的不断发展,监控系统被广泛的应用在日常生活中,同时社会对监控系统的性能和要求也在不断地提高。过去常见的视频监控系统已经显露出局限性和诸多缺点,因此音频监控逐渐受到人们的关注。通过音频监控系统辅助传统的基于视频图像的监控系统,能够发挥更好的监控效果,提高检测到危险事件的成功率。由于声音信号的采集过程相对简单、存储需求较小,因此系统的计算复杂度相对较低,运行效率能够得到有效的提高,同时也尊重了他人的隐私权,适用于私密性高的环境。
音频事件检测是音频监控的核心和关键。音频事件检测包括音频事件定位和音频事件识别两大部分[1-2]。异常声音识别是音频事件识别领域的一个重点研究方向,实际上就是识别生活中的异常声音,例如枪声、警报声等。随着异常声音识别技术的不断发展,已经能够在监控场合下从声音信号的角度上有效检测出是否发生异常事件,从而改善了仅依赖视频监控所存在的缺陷,因此引起了公共安全领域极大的兴趣。传统的声音识别算法一般有动态时间规整技术(Dynamic Time Warping, DTW)、支持向量机(Support Vector Machine, SVM)、高斯混合模型(Gaussian Mixture Model, GMM)以及隐马尔可夫模型(Hidden Markov Model, HMM)[3]等,它们都在各种不同的实验环境下得到了应用。如Francesco Aurino等人提出基于1-SVM分类器对多种突发的异常声音(如枪声、玻璃破碎声和尖叫声)进行识别[4]。G.Valenzise等人提出了一个应用在公共广场上基于音频的监控系统,该系统采用两个平行的高斯混合模型分别从噪声环境中识别出枪声和尖叫声,使识别性能获得了大幅度提升[5]。但是这些识别模型都只是一种符号化系统,降低了建模的能力,因此在实际环境中对不同质量的声音信号的识别性能将会大幅下降。近年来,声音识别技术逐渐发展为信号处理领域研究的热点,Xia X等人提出了一种利用随机森林模型进行分类的方法,该方法显著提高了声音事件检测的准确性[6]。针对叠加音频片段的特征空间极为复杂的问题,Mesaros A等人提出基于非监督学习的非负矩阵分解的方法对重叠音频事件进行检测,在识别率上相对于基线系统提高了10%[7]。在音频特征参数的研究方面,Dennis J等人提出了一种基于子带能量分布的音频事件图像特征,它由光谱图的视觉感知所激发,为声音分类提供一种鲁棒性更强的特征,与传统的声音特征相比,该特征在抗噪能力方面有了很大提高[8]。随着机器学习的兴起,人们对神经网络在声音识别中的应用开始了更深入的研究。人工神经网络(Artificial Neural Networks, ANNs)是一种对人类神经系统处理复杂信息的机制进行抽象的数学模型,它在声音信号处理过程中,能够实现复杂的逻辑操作和高度的非线性关系,与包含大量复杂信息的声音信号的时变性和非平稳特性相适应,在解决声音识别问题的过程中表现出良好的性能[9]。在1986年,Rumelhant和Mcllelland在多层神经网络模型的基础上,提出了多层神经网络权值修正的反向传播学习算法(Back Propagation, BP),解决了多层神经网络的学习问题,具有良好的泛化能力,它强有力地推动了神经网络的发展[10]。目前,人工神经网络模型已经成功运用在语音分析[11]、语音压缩[12]和语音识别[13]等声音信号处理的相关领域。此外,随着神经网络的研究不断发展和延伸,多种神经网络形式相继被提出,并且普遍应用在不同领域。卷积神经网络(Convolutional Neural Networks, CNNs)是近些年发展起来并相当具有实用价值的一种高性能、高效率的模型,特别是在模式分类领域[14-15]。2012年,Abdel-Hamid O等人将卷积神经网络应用在语音识别过程中,识别性能在之前的基础上获得了显著提高[16]。2015年,Zhang H在卷积神经网络的声音事件识别过程中使用了基于频谱的图像特征,在有噪声干扰下表现出优异的性能[17]。
本文对基于卷积神经网络的异常声音识别进行研究,与几种常见的识别模型,如高斯混合模型、BP神经网络进行比较,分析了卷积神经网络抗噪识别性能和异常声音识别的适用性问题,从多方面验证了卷积神经网络在异常声音识别中的优势。重点在于分析声音信号特征维度对卷积神经网络识别性能和噪声鲁棒性的影响。
2 卷积神经网络
卷积神经网络可以视为标准神经网络的一种变形,其特别之处在于由一对或多对卷积层和采样层代替全连接的隐含层。除此之外,卷积神经网络的顶层会添加一个或多个全连接层,目的是在到达输出层之前,将所有频带的特征连接起来整合成一维的特征信息,更加有利于直接分类。输出层则根据输入的特征信息,计算出各个状态的后验概率,最终达到识别的目的。卷积网络模型结构如图1所示。
卷积层选用一组卷积核遍历整个输入特征图,对其局部区域进行相关性信息的提取。卷积核的选取需要权衡特征的局部相关性和所包含的细节信息量,它直接影响了特征提取的质量[18]。采样层通过指定的窗口大小使用某种采样方法对卷积层特征图中的不同区域进行聚合,进一步减少了网络中的参数。一对连续的卷积层和采样层的运算流程如图2[15]所示。
由图2可知,假设J是输入特征图,它通过和I个卷积核进行卷积操作,与卷积层中卷积特征图Ki(i=1,…,I)相互映射。通过公式(1)计算得出卷积层的输出:
(1)
公式(1)中Ki表示输入特征图J和第i个卷积核Wi进行卷积操作之后的卷积特征图,卷积核Wi是权重矩阵,ai是网络偏置,非线性的激活函数σ通常选择sigmoid函数或者反正切函数。
从图2能够看出采样特征图是对卷积特征图中信息的提炼,目的是减少卷积特征图的参数数量,从而降低运算的复杂度。采样方法一般选用最大值采样或均值采样。在声音识别领域中,通常认定最大值采样方法的性能优于均值采样方法。最大值采样方法的计算公式如下:
(2)
式中R是采样大小,o是采样位移,它决定相邻采样窗口的重叠程度。采样大小和采样位移对提供给更高的网络层的特征信息量具有一定的影响。均值采样方法的计算公式如下:
(3)
式中ρ是缩放因子,能够通过学习得到。在声音识别过程中,通常将R=o作为前提条件,这样能够保证任何采样窗口之间没有重叠部分,并且特征图被采样窗口完全覆盖。
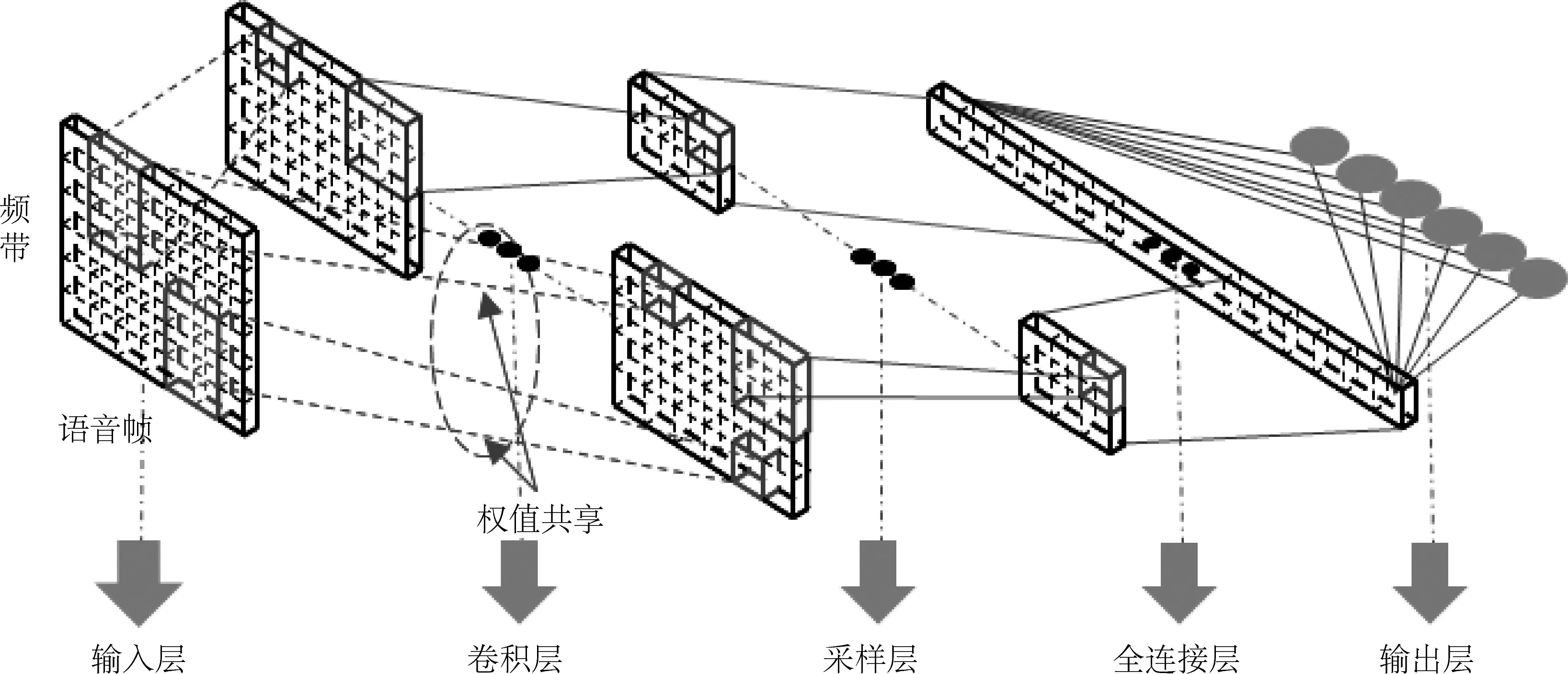
图1 卷积神经网络模型结构图

图2 卷积神经网络中一对连续的卷积层和采样层的运算流程,从输入层或者采样层到卷积层的计算基于公式(1),从卷积层到采样层的计算基于公式(2)和公式(3)
3 本文方法
3.1 声音信号的排列方式
选用卷积神经网络作为异常声音识别模型,需要将提取的异常声音特征排列组合成一系列的特征图作为卷积神经网络的输入。传统的卷积神经网络的输入特征图都被排列成二维结构,例如卷积神经网络应用在图像处理中,将图像的特征通常按照像素在图像中所对应的位置排列成二维矩阵作为一个输入特征图。但是将卷积神经网络应用在异常声音识别中,需要提取的是声音信号的特征。和二维图像相比,声音信号是一维的,因此适用于卷积神经网络的声音特征图的排列组合可以有多种形式[19],目前常见的应用在卷积神经网络中的声音信号特征图是按照在时间和频域两个维度上排列的二维特征图。本文将分析研究声音信号的特征采用不同方式进行排列对卷积神经网络识别性能的影响。如图3所示,分别采用两种不同方式排列声音信号的特征,最后组合成二维特征图和一维特征图。图3(a)中排列方式是传统的二维排布方式,将一段声音信号分帧加窗,每一帧提取36个频带的特征参数,时间规整为20帧,二维特征图中每一帧的特征向量构成一列,依次按照时间先后顺序排列,最后组成36×20的二维特征图。图3(b)中将声音信号的特征信息排列成一维特征图,同样将一段声音信号分帧加窗,每一帧提取36个频带的特征参数,时间规整为20帧,按照时间先后顺序,把后面一帧的特征参数连接在相邻的前一帧特征参数后面,这样依次将所有帧的特征串联在一起,构成该段声音信号的长时特征,最后组成720×1的一维特征图。
3.2 适用于一维特征的卷积神经网络
传统的卷积神经网络的输入特征图均为二维排布,而适用于一维声音特征的卷积神经网络与其不同之处在于网络中卷积核以及卷积特征图和采样特征图都是一维结构。图4中展示了两种大小为4的卷积核对二维特征图和一维特征图进行卷积操作的过程。图4(a)所示是一个2×2的卷积核对二维特征图进行卷积运算的过程,2×2的卷积核从特征图左上端开始卷积,每次操作完成后,依次向右或者向下移动一列或者一行再开始卷积操作,直至遍历整个特征图,最后得到一个二维的卷积特征图;图4(b)所示是一个4×1的卷积核对一维特征图进行卷积运算的过程,4×1的卷积核从特征图最顶端开始卷积,每次操作完成后,依次向下端移动一行再开始卷积操作,直至遍历整个特征图,产生一维的卷积特征图。
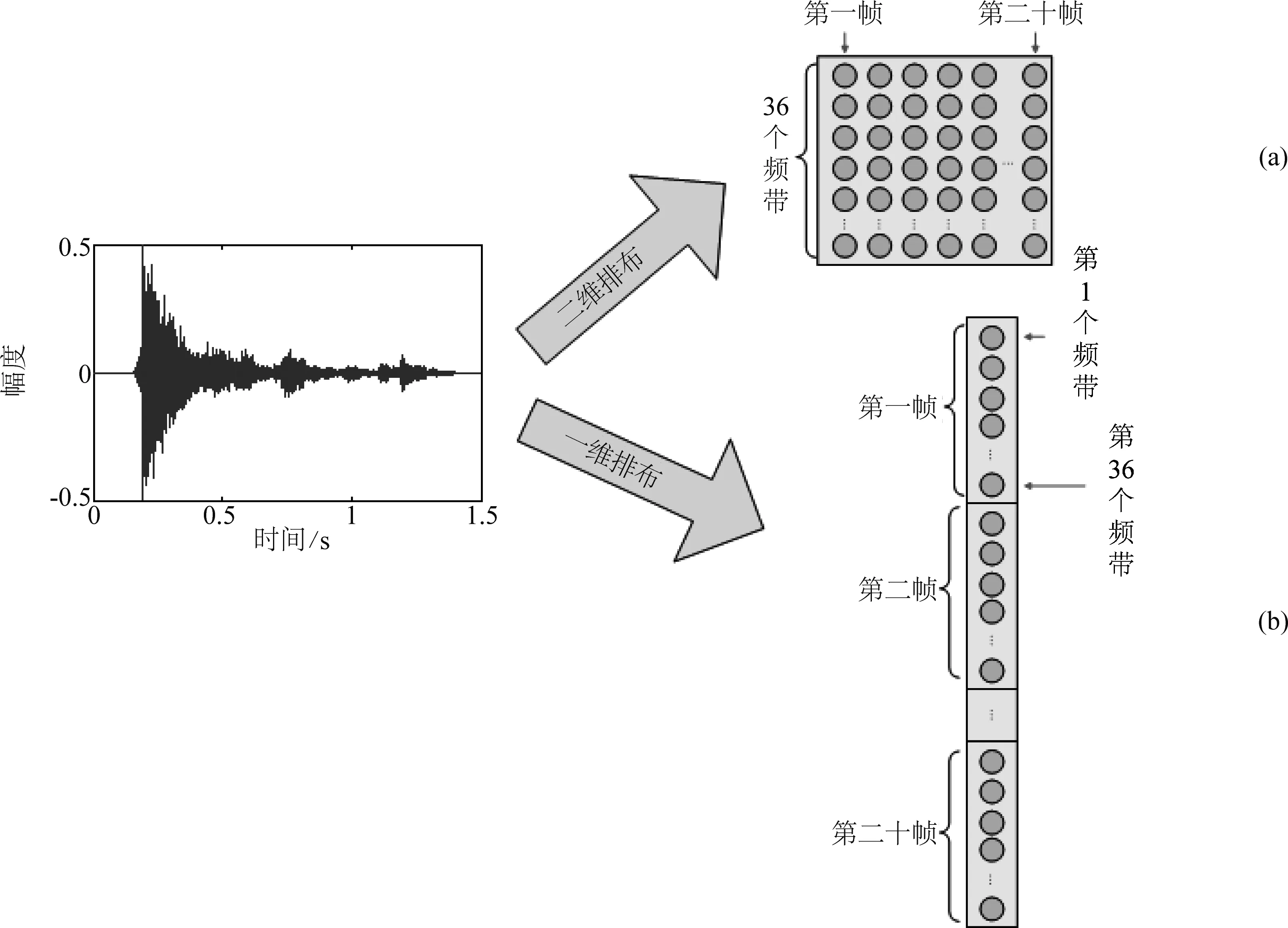
图3 两种不同的声音信号特征排列方式组成的卷积神经网络输入特征图
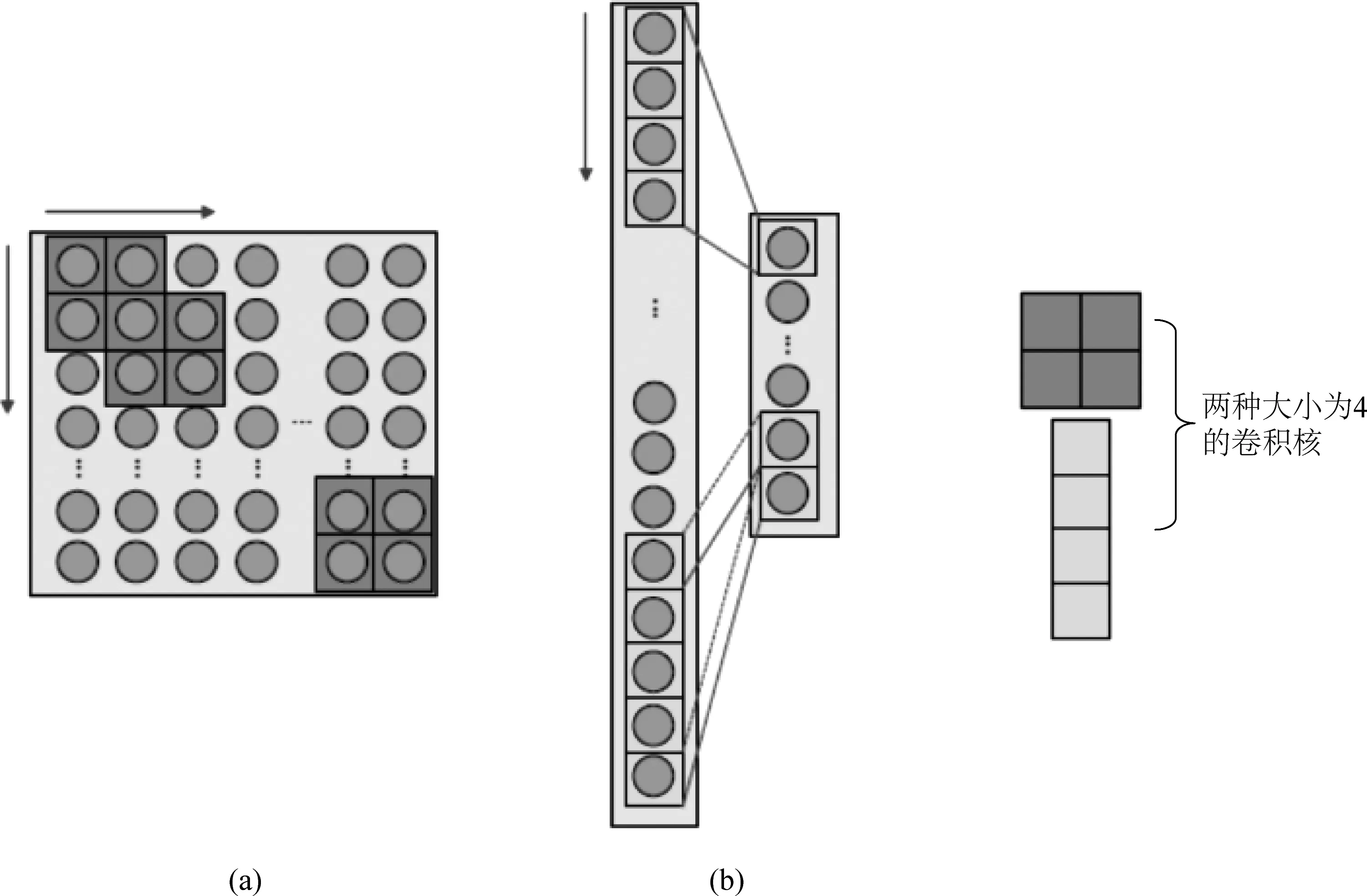
图4 两种大小相同的卷积核分别对二维特征图和一维特征图进行卷积操作,红色指针表示卷积核移动的方向
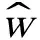
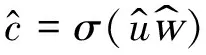
(4)
采样层只需要对一维卷积特征图进行下采样,同样获得采样特征图是一维的。由于特征图都是一维的,全连接层不需要将特征图从二维拉伸成一维的,只需要将所有特征图简单连接在一起。整个网络结构更加简单明了。
3.3 数据增强
卷积神经网络是一种包含大量权值参数的模型,需要依赖庞大的训练数据以得到良好的性能。由于带标签的异常声音样本极为稀缺,这在一定程度上限制了卷积神经网络研究的进展,也阻碍了卷积神经网络性能的提升。数据增强技术的目的就是为了改善训练数据资源匮乏的现状,实质上是通过对已有的训练样本进行适当的转换产生新的数据,其核心是保证样本标签转换前后的实际含义一致。将数据增强之后的训练样本用于卷积神经网络的训练,能够使网络对这些类型的变形保持高度不变性,因此能够更好的推广在各类具体的应用场景中[20-21]。
接下来介绍本文应用的几种转换方式:(1)提高或者降低原始声音样本的音调;(2)压缩或者扩张原始声音样本的时间轴;(3)针对真实条件下声音的空间感,对原始声音样本添加混响效果;(4)随机选取同一类型的两个声音样本进行混合。对于每种转化方式,重点均在于保持前后样本标签的一致性,增强的幅度则取决于已有的训练数据量以及研究任务的规模。数据增强之后的训练样本不仅能很大程度上减小过拟合的可能,还能够使卷积神经网络充分发挥自身的优势。
4 实验结果及分析
4.1 实验数据采集
实验共采集6种异常声音,分别是爆炸声、玻璃破碎声、枪声、警报声、开关门声和哭声。异常声音库中包含五种不同信噪比(0 dB、5 dB、10 dB、15 dB和无噪声)的子库,各个子库中每种异常声音有1500个样本,总共包含了9000个样本,其中带噪样本是通过加入babble噪声进行仿真获取的,加噪公式如下:
f(t)=h1*s(t)+h2*n(t)
(5)
式中f(t)表示带噪声音信号,s(t)表示纯净声音信号,n(t)表示babble噪声,h1,h2为混合矩阵,由信噪比大小决定,*为线性卷积。
样本采样频率为11025 Hz,比特率为8 bit;训练集包含五种不同信噪比(无噪声、0 dB、5 dB、10 dB和15 dB)子训练集,分别从五种不同信噪比的子库中随机抽取70%的异常声音样本组成,每个子训练集包含6300个样本。测试集包含五种不同信噪比(无噪声、0 dB、5 dB、10 dB和15 dB)子测试集,分别从五种不同信噪比子库中剩余部分随机抽取50%的异常声音样本组成,每个子测试集包含1350个样本。验证集也包含五种不同信噪比(无噪声、0 dB、5 dB、10 dB和15 dB)子验证集,分别由五种不同信噪比的子库中最后剩余的样本组成,每个子验证集包含1350个样本。为了比较和验证识别模型的抗噪识别性能,先选择无噪声的子训练集对模型进行训练,再使用不同信噪比的测试集进行测试。每组实验共做10次,统计每次实验的识别率,然后求取平均识别率,最后对识别性能进行研究分析。实验的具体流程如图5所示。
4.2 特征参数提取及排列
实验选用的语音特征是传统的MEL频率倒谱系数(MFCC),MEL标度体现了人耳频率的非线性特征。MFCC基于人耳听觉系统与人脑处理外界声音过程原理进行分析,因而具有很好的鲁棒性,尤其当加入MFCC一阶差分系数(△MFCC),MFCC二阶差分系数(△△MFCC)后能够更好的反映人耳对声音动态特性的灵敏程度。在特征参数提取阶段,选用帧长为256个采样点,帧移为128个采样点以及汉明窗进行分帧加窗操作,每一帧提取36维MFCC特征参数,其中包括MFCC系数、△MFCC和△△MFCC。神经网络模型输入层和输出层的大小和维度都是固定的,但由于声音信号具有很大的随机性,每个异常声音样本的时间长度不统一,所以每个样本的帧数不尽相同。如果采用压缩或者扩张时间轴的方法保证每个样本的时长相同,难以有效精准对正。因此本文采用动态时间规整的方法将所有的异常声音样本规整成相同的帧数以保证每个异常声音样本的特征参数可以排列成相同尺寸的特征图输入到卷积神经网络中。
本文为了比较一维特征图和二维特征图对卷积神经网络异常声音识别性能的影响,将所有异常声音样本的特征分别规整到20帧、30帧和40帧,然后按照图3中两种排列方式组合成二维特征图和一维特征图,排列完成后二维特征图分别为36×20、36×30、36×40三种二维矩阵,一维特征图分别为720×1、1080×1、1440×1三种一维向量。
4.3 实验参数设置
实验采用卷积神经网络对异常声音进行识别。网络模型的结构简化为1层卷积层、1层采样层和1层全连接层,其中卷积层的卷积核数目为10,以及采样层的采样方法选用最大值采样。网络采用标准的反向传播算法进行学习,使用交叉熵作为代价函数,输出层采用softmax分类器。
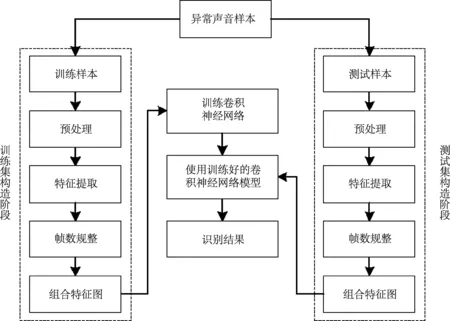
图5 基于卷积神经网络的异常声音识别流程图
4.4 实验结果与分析
4.4.1卷积神经网络和高斯混合模型(GMM)识别性能对比
高斯混合模型是一种传统声音识别模型,它可以将一类事物通过多个高斯概率密度公式加权和的形式进行描述,能够较好的描述声音信号这种时变、非平稳信号,并表现出不错的识别性能。n阶高斯混合模型的异常声音识别技术实质上是使用了n个单高斯分布的线性组合为每一类异常声音进行建模。本节将卷积神经网络和高斯混合模型从异常声音识别性能以及抗噪能力这两方面进行比较。实验选用这两种识别模型分别对五种不同信噪比(0 dB、5 dB、10 dB、15 dB和无噪声)条件下的异常声音进行识别,结果如表1所示。
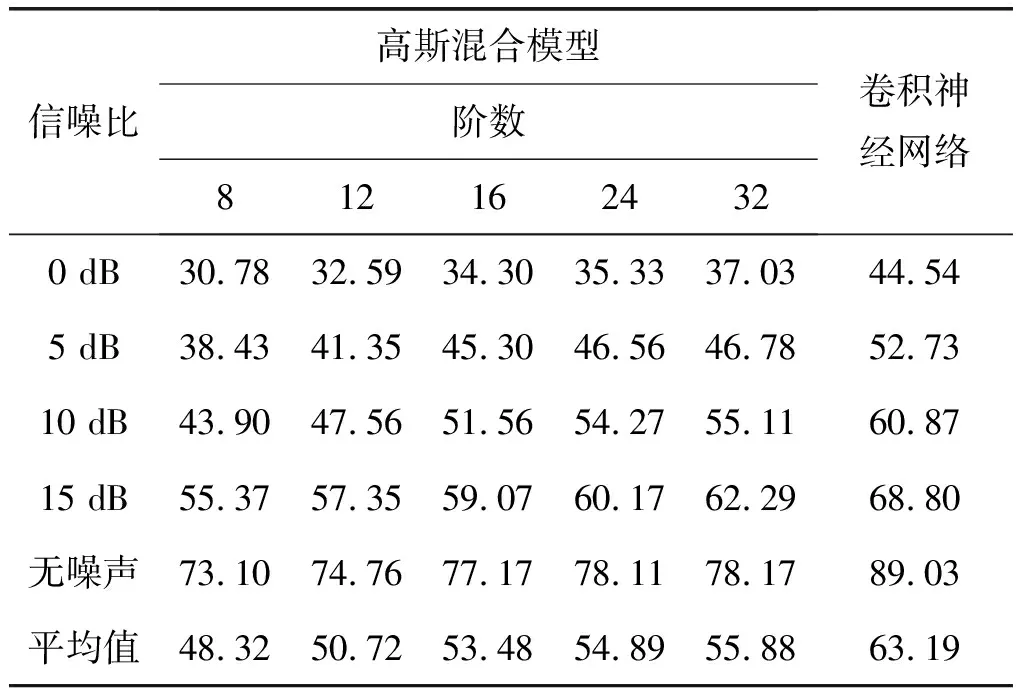
表1 不同信噪比下高斯混合模型和卷积神经网络的识别结果
表1中给出五种阶数的高斯混合模型的识别结果,随着阶数的增加,高斯混合模型的识别性能不断提升,当阶数超过16之后,逐渐趋于平稳。在每种信噪比下,卷积神经网络的识别结果都优于高斯混合模型,当阶数为32时,高斯混合模型的平均识别率为55.88%,而卷积神经网络的平均识别率能达到63.19%,相对提升了13.08%,由此可以分析出卷积神经网络能够对声音信号的局部进行观察,提炼出相关性信息,并且在采样层的特征聚合过程中(尤其是采取最大值采样方法时)将频带上的位移差异最小化,进而大大降低频带位移对识别结果造成的影响。而高斯混合模型对声音信号的处理是全局性的,尤其当噪声干扰造成声音信号被掩蔽的情况下,无法区分出频带上细微的位移[16],导致建模能力有限。通过对比看出,卷积神经网络的异常声音识别能力和对噪声的鲁棒性明显优于高斯混合模型。
4.4.2卷积神经网络和BP神经网络识别性能对比
BP神经网络是一种典型的多层前向神经网络,含有多个隐含层,并且相邻层的神经元全连接,同层之间的神经元不连接,它通过误差反向传播算法对有标签的数据进行学习。BP神经网络具有强大的非线性映射能力,因此被普遍应用在声音识别领域中,并且表现出不错的识别性能[22]。与卷积神经网络的输入特征图(矩阵)不同,BP神经网络的输入层输入的必须是特征向量。本节将在识别性能和抗噪能力方面对卷积神经网络和BP神经网络这两种识别模型进行比较,所采用的BP神经网络结构简化为一层输入层、一个隐含层和一个输出层。
实验在保证卷积神经网络和BP神经网络中权值参数数量相同的前提下,分别对三种不同规整帧数下的异常声音进行识别,比较两者的识别性能,实验结果如图6所示。
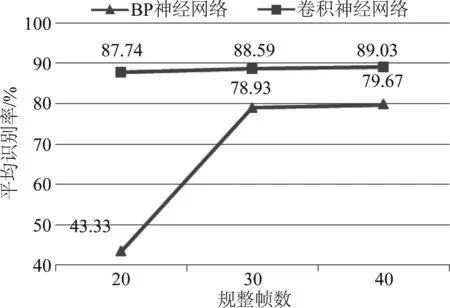
图6 三种规整帧数条件下,BP神经网络和卷积神经网络识别性能对比
由图6可看出当规整帧数为20时,卷积神经网络的平均识别率比BP神经网络明显提高了44.41%,识别性能远远高于BP神经网络。这是因为BP神经网络的全连接结构需要大量的权值参数,若保证其与卷积神经网络的权值参数数量相同,会使其隐含层中神经元个数过少。当规整帧数逐渐提高到30帧和40帧时,随着BP神经网络隐含层的神经元个数不断增加,其识别性能得到显著提高,但是卷积神经网络的平均识别率相比于BP神经网络仍然高出了9.66%和9.36%。实验结果表明,一方面,BP神经网络的隐含层中神经元个数过少时,会对其识别性能产生巨大的影响;另一方面,即使BP神经网络的隐含层包含足够数量的神经元,卷积神经网络的识别性能仍明显优于BP神经网络。
卷积神经网络和BP神经网络都采用误差反向传播算法进行学习。这种学习方式是根据网络的实际输出和目标输出计算误差,再依据误差从后往前逐层对网络中权值参数进行修正。随着学习的次数不断增多,网络中的误差越来越小,直至误差收敛,网络才真正的完成训练。但是有时候网络训练迭代的次数过多,拟合了训练数据中包含的噪声或者无意义的特征,造成训练数据误差越来越小,而测试数据误差越来越大,导致网络的泛化能力变弱。于是在训练集以外提供验证集,在每次迭代后对网络进行验证,防止网络出现过拟合现象。当连续3次迭代验证集的误差不再减小时,将会对网络停止训练。本节将通过卷积神经网络和BP神经网络的误差收敛以及validation checks进行比较分析,进一步说明卷积神经网络在异常声音识别中的优势。
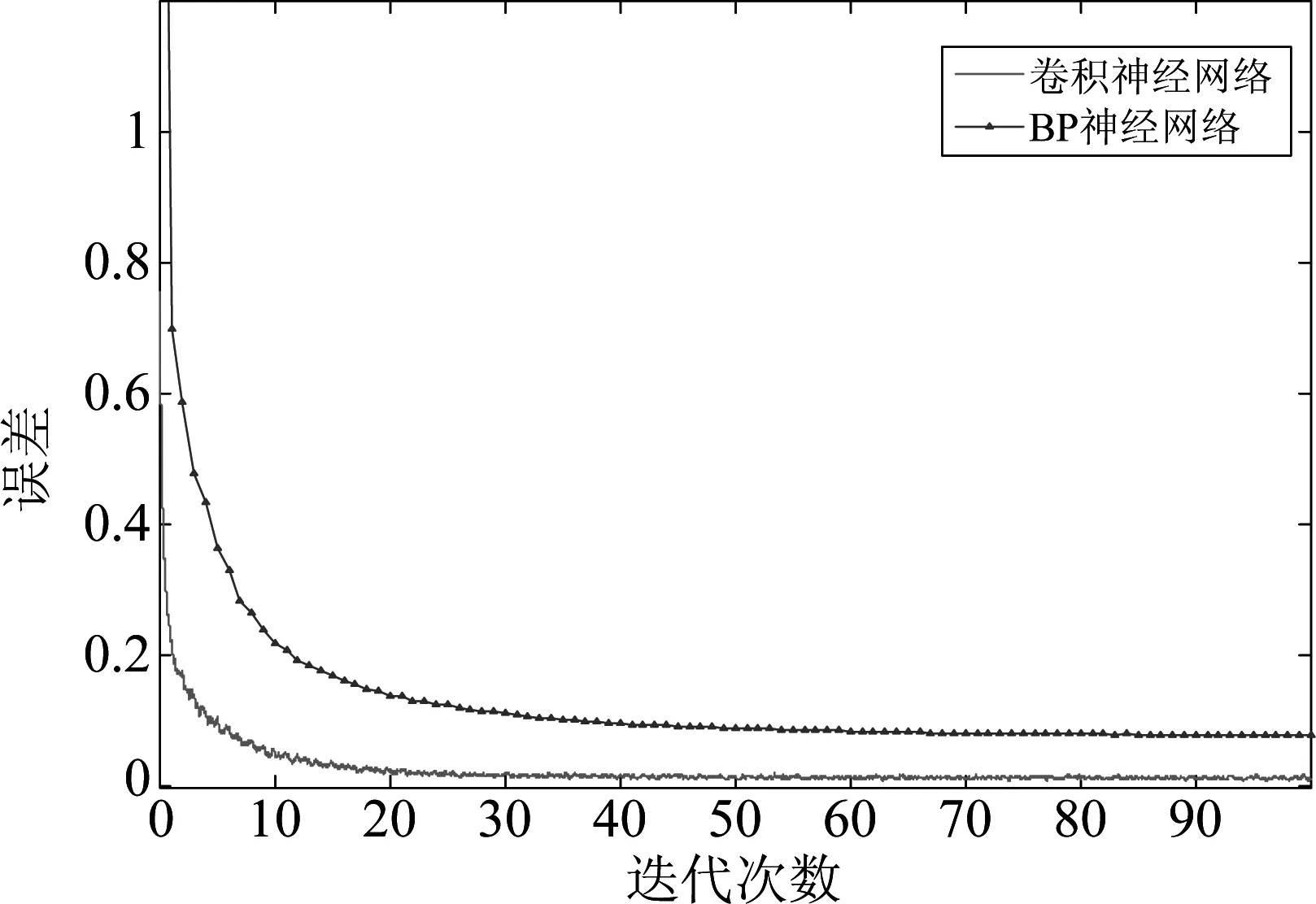
图7 卷积神经网络和BP神经网络误差收敛曲线
从图7中的误差收敛曲线可知,卷积神经网络在训练初期的误差明显小于BP神经网络,收敛速度比BP神经网络更快,并且收敛后的误差比BP神经网络收敛后的误差更小。从图8可以看出卷积神经网络在第40次迭代时,测试集的误差就已经连续3次不再减小,网络训练完成;BP神经网络则在第92次迭代时,测试集的误差才连续3次不再减小,网络训练完成。因此,通过对网络的学习速率、训练迭代次数以及最终收敛后的网络误差等方面进行比较,可以判断卷积神经网络在异常声音识别方面比BP神经网络明显更好。
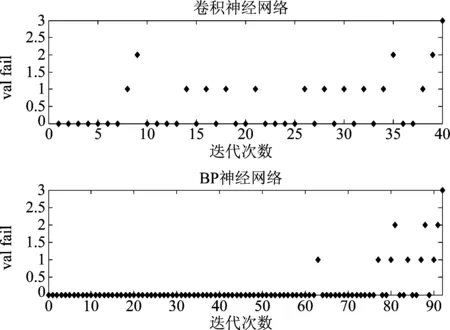
图8 卷积神经网络和BP神经网络的验证过程
本节选用四种不同信噪比(0 dB、5 dB、10 dB和15 dB)的异常声音对卷积神经网络和BP神经网络的噪声鲁棒性进行比较,实验结果如图9所示。
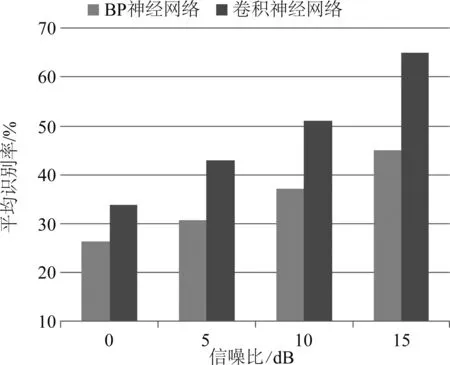
图9 不同信噪比下卷积神经网络和BP神经网络的平均识别结果
通过图9能够清晰看出,在四种不同信噪比条件下,卷积神经网络的平均识别率都明显高于BP神经网络。这是因为卷积神经网络利用卷积核的局部感知能力能够从频带上较为纯净的部分过滤出性能良好的特征,每个频带上只有少量被用来训练的特征受到了噪声的干扰,这种处理方式比BP神经网络直接在底层简单地处理所有的输入特征更好,使卷积神经网络对噪声具有良好的鲁棒性并且减少了过拟合的可能。通过实验结果比较可以看到,卷积神经网络比BP神经网络具有更好的泛化能力,在噪声环境下具有更强的鲁棒性。
4.4.3卷积神经网络中声音信号的特征维度对识别性能影响的比较
为了验证和比较声音信号的一维特征和二维特征对卷积神经网络异常声音识别性能的影响。本节将从6类异常声音提取出来的特征分别按照图3中两种声音信号的特征排布方式进行组合,最后得到卷积神经网络的二维输入特征图和一维输入特征图。
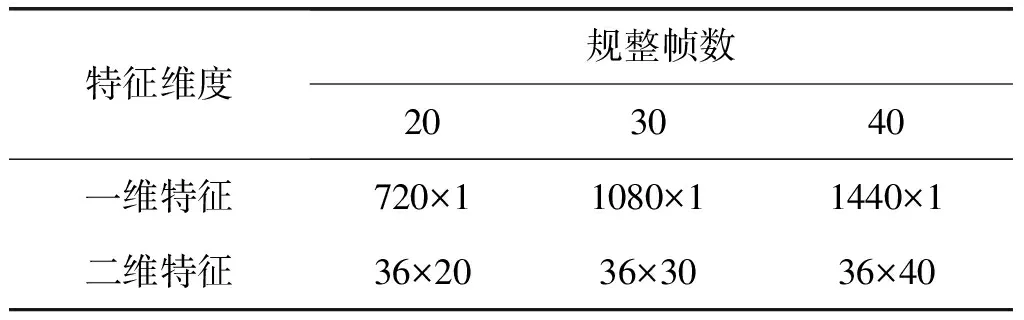
表2 三种规整帧数下一维特征和二维特征的排布形式
实验将异常声音的特征分别规整到20帧、30帧以及40帧,一维特征和二维特征排布形式如表2所示。本节在一维特征上选用卷积核大小为20、30和40的一维卷积核,在二维特征上选用了性能较好的大小为20(4×5)、30(5×6)和40(5×8)的二维卷积核进行实验,无噪声条件下的识别结果如表3所示。
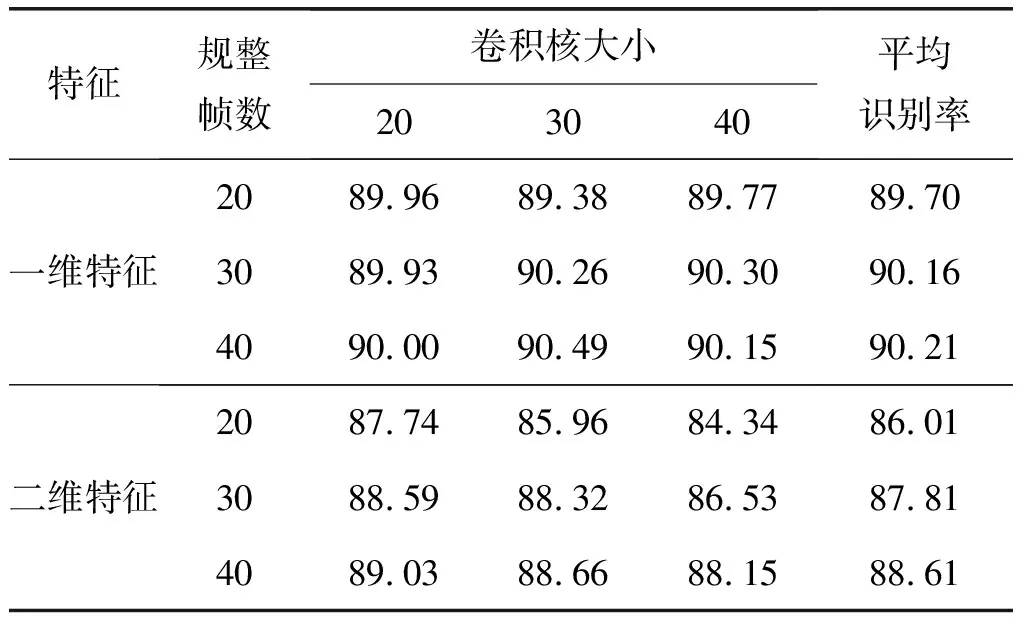
表3 无噪声条件下一维特征和二维特征识别结果
由表3可知,当规整帧数大小分别为20、30、40时,一维特征在3种卷积核大小下的平均识别率分别比二维特征提升了3.69%、2.35%、1.60%,实验说明在通过卷积层进行卷积操作后,一维特征比二维特征能够更多的保留声音信号的非平稳特性和频带上的局部相关性信息,有益于识别过程中的后续处理,进一步提升了卷积神经网络的识别性能。因此,在无噪声干扰条件下,一维特征的识别结果都好于二维特征。
对噪声的鲁棒性是衡量卷积神经网络识别性能是否优良的重要标准,本节还将四种不同信噪比(0 dB、5 dB、10 dB和15 dB)条件下的异常声音特征规整到40帧,然后分别排列成二维特征和一维特征进行识别,一维特征和二维特征上选用的卷积核大小都是20,实验结果如图10所示。
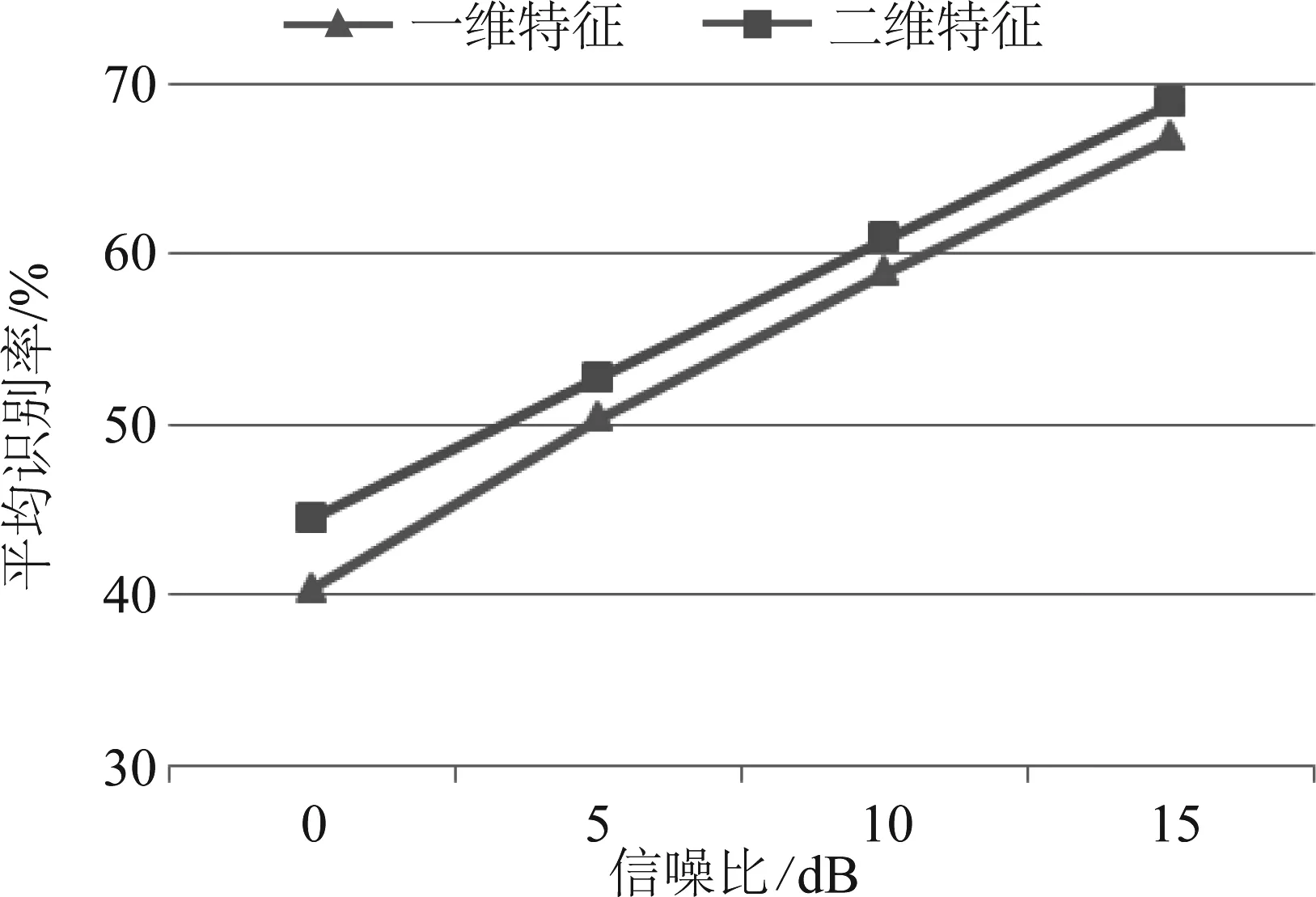
图10 不同信噪比下,一维特征和二维特征的识别结果
根据图10可知当信噪比分别为0 dB、5 dB、10 dB和15 dB时,二维特征的识别结果比一维特征分别提升了4.15%、2.35%、0.41%和0.47%。这是因为babble噪声主要分布在中低频率区域,采用二维特征的排布形式能够使卷积核同时沿着时间和频域两个维度对多个频带进行局部相关性信息的提取,有利于卷积神经网络区分出异常声音和噪声,所以二维特征比一维特征对噪声具有更好的鲁棒性。结合实验结果可以得出,使用二维特征进行训练的卷积神经网络的抗噪性能优于一维特征训练的网络。
通过特征训练网络模型是为了降低实际输出和目标输出之间的误差,在训练阶段选取不同类型的特征,能够直接影响网络的训练迭代次数、误差收敛速度以及最终收敛的结果。本节通过实验对五种不同信噪比的异常声音的一维特征和二维特征的误差收敛曲线进行比较,结果如图11所示。
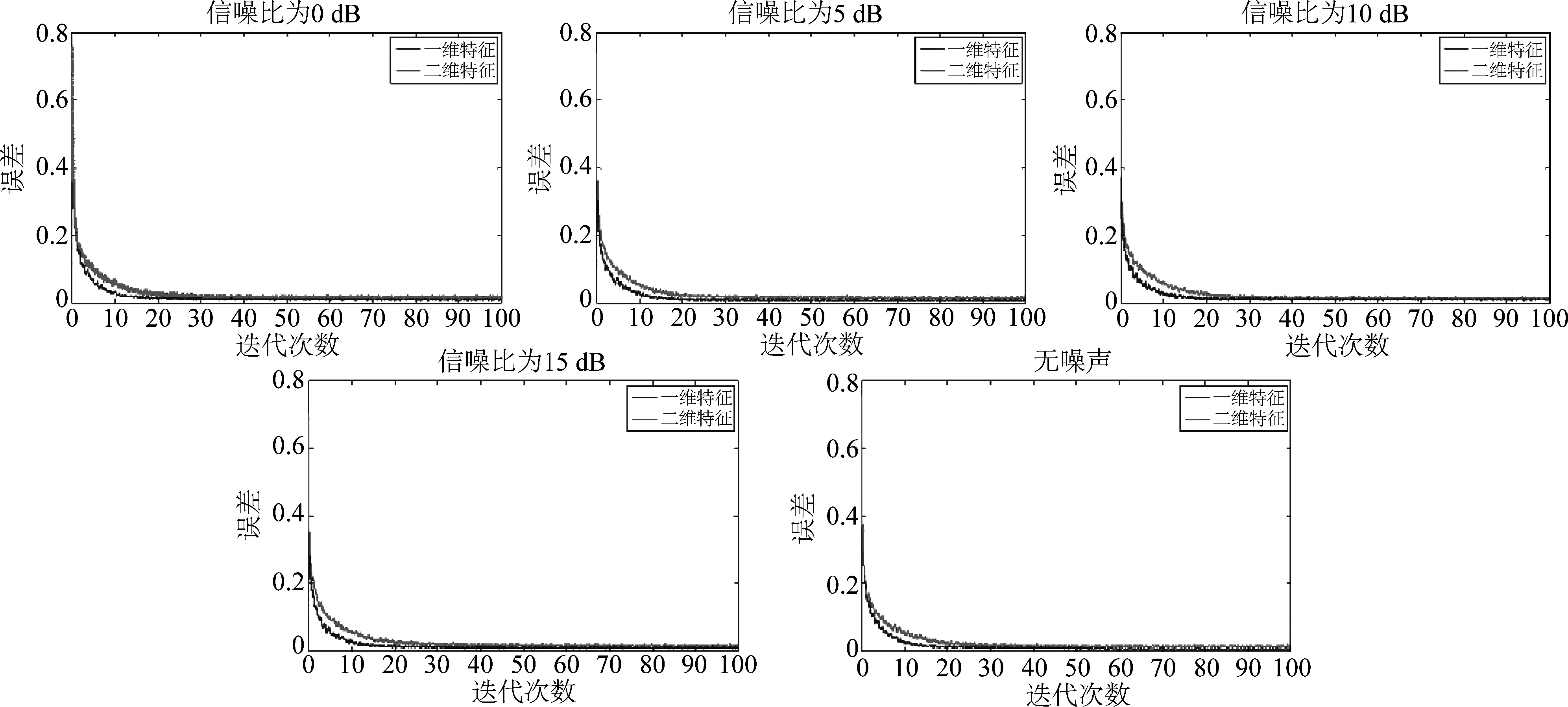
图11 不同信噪比下,一维特征和二维特征的误差收敛曲线
根据图11的实验结果,可以清楚看出,在五种信噪比条件下,一维特征和二维特征收敛后的误差大小相近,但一维特征的误差收敛速度均快于二维特征。这说明一维特征既能够降低卷积神经网络的运算复杂度,也可以很好的保留声音信号频带间的局部相关性信息,有利于提升卷积神经网络的学习速率。这一结论表明相较于传统的二维特征,声音信号的一维特征也能够有效的应用在卷积神经网络中。
5 结论
本文对基于卷积神经网络的异常声音识别进行了研究,将卷积神经网络分别与高斯混合模型、BP神经网络进行比较,从抗噪性、误差收敛速度等多方面对比分析了这三种识别模型实际性能的差异。实验结果说明,卷积神经网络在异常声音识别性能和对噪声的鲁棒性上均有着较大的优势。同时,针对声音信号特征的维度对卷积神经网络异常声音识别性能的影响进行了讨论,所得结论是在误差收敛速度方面,一维特征优于二维特征;在识别性能方面,噪声干扰强度大的环境下,二维特征性能好于一维特征,但是噪声干扰强度小的环境下,一维特征性能好于二维特征。我们认为,根据实际环境的信噪比条件来选取声音信号特征的维度,能够得到更好的识别效果。
需要说明的是,声音信号的特征排布方式并不局限于本文所述的两种方式,还有很多依据声音信号的特性将其特征按照不同形式进行组合的方法。找到更适合声音信号的特征排布方式以提升卷积神经网络的识别性能值得今后进一步研究。
[1] Stowell D, Giannoulis D, Benetos E, et al. Detection and classification of acoustic scenes and events[J]. IEEE Transactions on Multimedia, 2015, 17(10): 1733-1746.
[2] Zhuang X, Zhou X, Hasegawa-Johnson M A, et al. Real-world acoustic event detection[J]. Pattern Recognition Letters, 2010, 31(12): 1543-1551.
[3] Schröder J, Anemüller J, Goetze S. Performance comparison of GMM, HMM and DNN based approaches for acoustic event detection within Task 3 of the DCASE 2016 challenge[C]∥Proc. Workshop Detect. Classification Acoust. Scenes Events, 2016: 80- 84.
[4] Aurino F, Folla M, Gargiulo F, et al. One-class svm based approach for detecting anomalous audio events[C]∥Intelligent Networking and Collaborative Systems (INCoS), 2014 International Conference on. IEEE, 2014: 145-151.
[5] Valenzise G, Gerosa L, Tagliasacchi M, et al. Scream and gunshot detection and localization for audio-surveillance systems[C]∥Advanced Video and Signal Based Surveillance, 2007. AVSS 2007. IEEE Conference on. IEEE, 2007: 21-26.
[6] Xia X, Togneri R, Sohel F, et al. RANDOM FOREST CLASSIFICATION BASED ACOUSTIC EVENT DETECTION[C]∥IEEE International Conference on Multimedia and Expo. IEEE, 2017.
[7] Mesaros A, Heittola T, Dikmen O, et al. Sound event detection in real life recordings using coupled matrix factorization of spectral representations and class activity annotations[C]∥IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 2015:151-155.
[8] Dennis J, Tran H D, Chng E S. Image Feature Representation of the Subband Power Distribution for Robust Sound Event Classification[J]. IEEE Transactions on Audio Speech & Language Processing, 2013, 21(2):367-377.
[9] Kons Z, Toledo-Ronen O. Audio event classification using deep neural networks[C]∥INTERSPEECH, 2013:1482-1486.
[10] Cai H, Liu L, Cao Q. A novel BP algorithm based on self-adaptive parameters and performance analysis[C]∥Innovative Computing, Information and Control, 2006. ICICIC'06. First International Conference on. IEEE, 2006, 2: 383-387.
[11] Tuckova J, Sramka M. Emotional speech analysis using artificial neural networks[C]∥Computer Science and Information Technology (IMCSIT), Proceedings of the 2010 International Multiconference on. IEEE, 2010: 141-147.
[12] Srinonchat J. Enhancement Artificial Neural Networks for Low-Bit Rate Speech Compression system[C]∥Communications and Information Technologies, 2006. ISCIT'06. International Symposium on. IEEE, 2006: 118-121.
[13] Gupta S, Bhurchandi K M, Keskar A G. An efficient noise-robust automatic speech recognition system using artificial neural networks[C]∥Communication and Signal Processing (ICCSP), 2016 International Conference on. IEEE, 2016: 1873-1877.
[15] Piczak K J. Environmental sound classification with convolutional neural networks[C]∥Machine Learning for Signal Processing (MLSP), 2015 IEEE 25th International Workshop on. IEEE, 2015: 1- 6.
[16] Abdel-Hamid O, Mohamed A, Jiang H, et al. Applying convolutional neural networks concepts to hybrid NN-HMM model for speech recognition[C]∥Acoustics, Speech and Signal Processing (ICASSP), 2012 IEEE International Conference on. IEEE, 2012: 4277- 4280.
[17] Zhang H, Mcloughlin I, Song Y. Robust sound event recognition using convolutional neural networks[C]∥IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 2015:559-563.
[18] 张晴晴, 刘勇, 潘接林,等. 基于卷积神经网络的连续语音识别[J]. 工程科学学报, 2015,37(9):1212-1217.
Zhang Qingqing, Liu Yong, Pan Jielin, et al. Continuous speech recognition by convolutional neural networks[J].Chinese Journal of Engineering, 2015, 37(9): 1212-1217.(in Chinese)
[19] Abdel-Hamid O, Mohamed A R, Jiang H, et al. Convolutional Neural Networks for Speech Recognition[J]. IEEE/ACM Transactions on Audio Speech & Language Processing, 2014, 22(10):1533-1545.
[20] Schlüter J, Grill T. Exploring Data Augmentation for Improved Singing Voice Detection with Neural Networks[C]∥ISMIR, 2015: 121-126.
[21] McFee B, Humphrey E J, Bello J P. A Software Framework for Musical Data Augmentation[C]∥ISMIR, 2015: 248-254.
[22] Rajput N, Verma S K. Back propagation feed forward neural network approach for speech recognition[C]∥Reliability, Infocom Technologies and Optimization (ICRITO)(Trends and Future Directions), 2014 3rd International Conference on. IEEE, 2014: 1- 6.
猜你喜欢
现代仪器与医疗(2022年1期)2022-04-19
北京航空航天大学学报(2021年9期)2021-11-02
数学年刊A辑(中文版)(2020年3期)2020-10-27
电子制作(2019年13期)2020-01-14
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
雷达学报(2017年3期)2018-01-19
中学生数理化·八年级物理人教版(2017年9期)2017-12-20
雷达与对抗(2015年3期)2015-12-09
