
基于数据增强技术的神经机器翻译
2018-08-17 07:10蔡子龙杨明明熊德意
中文信息学报 2018年7期
蔡子龙,杨明明,熊德意
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
神经机器翻译是Sutskever等人[1]在2014年提出的一种基于编码器—解码器模型的机器翻译方法。和传统基于短语的统计机器翻译[2]不同,神经机器翻译没有特征工程、隐藏结构设计等方面的困扰,而是简单地通过训练一个单一、大型的神经网络对输入句子产生合适的翻译。该方法刚被提出来的时候,效果还不如统计机器翻译。2015年,Bahdanau等人[3]在此工作的基础上通过引入注意力机制使得神经机器翻译在多种语言对上的评测结果超过统计机器翻译,神经机器翻译因此得到了广泛的关注。
神经机器翻译本质上是训练一个大型的神经网络,该网络由上万个神经元构成。为了能够充分地学习到网络的权重值,神经机器翻译需要大量的平行句对作为训练数据,往往平行句对越多,训练效果越好。然而,对于资源贫乏语种来说,获得充足的训练语料是十分困难的。
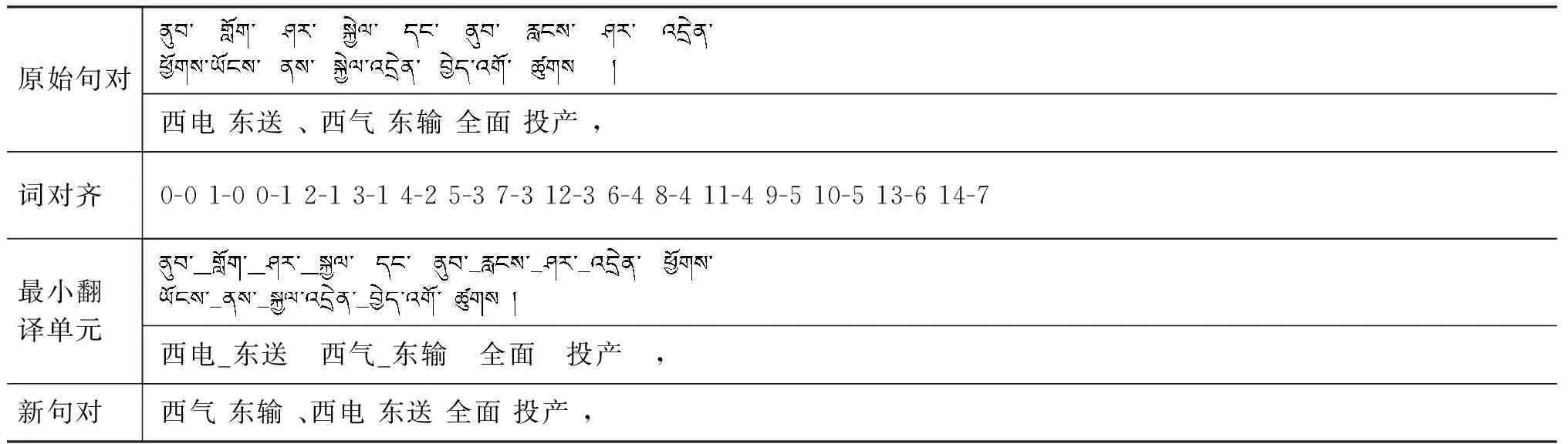
为了解决神经机器翻译在资源贫乏语种上因为训练数据太少而导致的泛化能力不足问题,本文提出了一个简单有效的方法: 数据增强技术。该方法首先对句子进行分块,然后找到句子中最相似的两个模块,通过对调它们的位置形成新的句子。利用数据增强技术,不但可以将训练语料扩充一倍,而且也会使句子的结构变得多样化。本文在藏汉语种上进行了实验,较于基准系统,获得了4个BLEU值[4]的提高。实验表明,本文提出的数据增强方法可以显著提高神经机器翻译对于资源贫乏语种的泛化能力。
本文其他部分的组织如下: 第一节和第二节分别介绍了神经机器翻译的背景知识和在资源贫乏语种上研究的相关工作;第三节详细说明如何对训练语料进行数据增强;第四节对实验结果进行分析;最后,对本文的工作进行了总结,并对下一步工作进行了展望。
1 背景知识
本节主要介绍基于注意力机制的神经机器翻译。如图1所示,神经机器翻译分为两个部分,一个是编码器,另一个是解码器。编码器采用双向循环的神经网络,对源句子x=x1,x2,…,xTx进行编码,得到该句子的隐藏层h=h1,h2,…,hTx。解码器使用注意力机制,从左往右逐单词地生成目标端句子y=y1,y2,…,yTy。
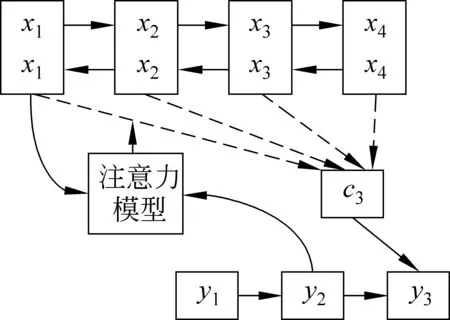
图1 基于注意力机制的神经机器翻译模型
在训练阶段,神经机器翻译计算一个平行句对
(1)
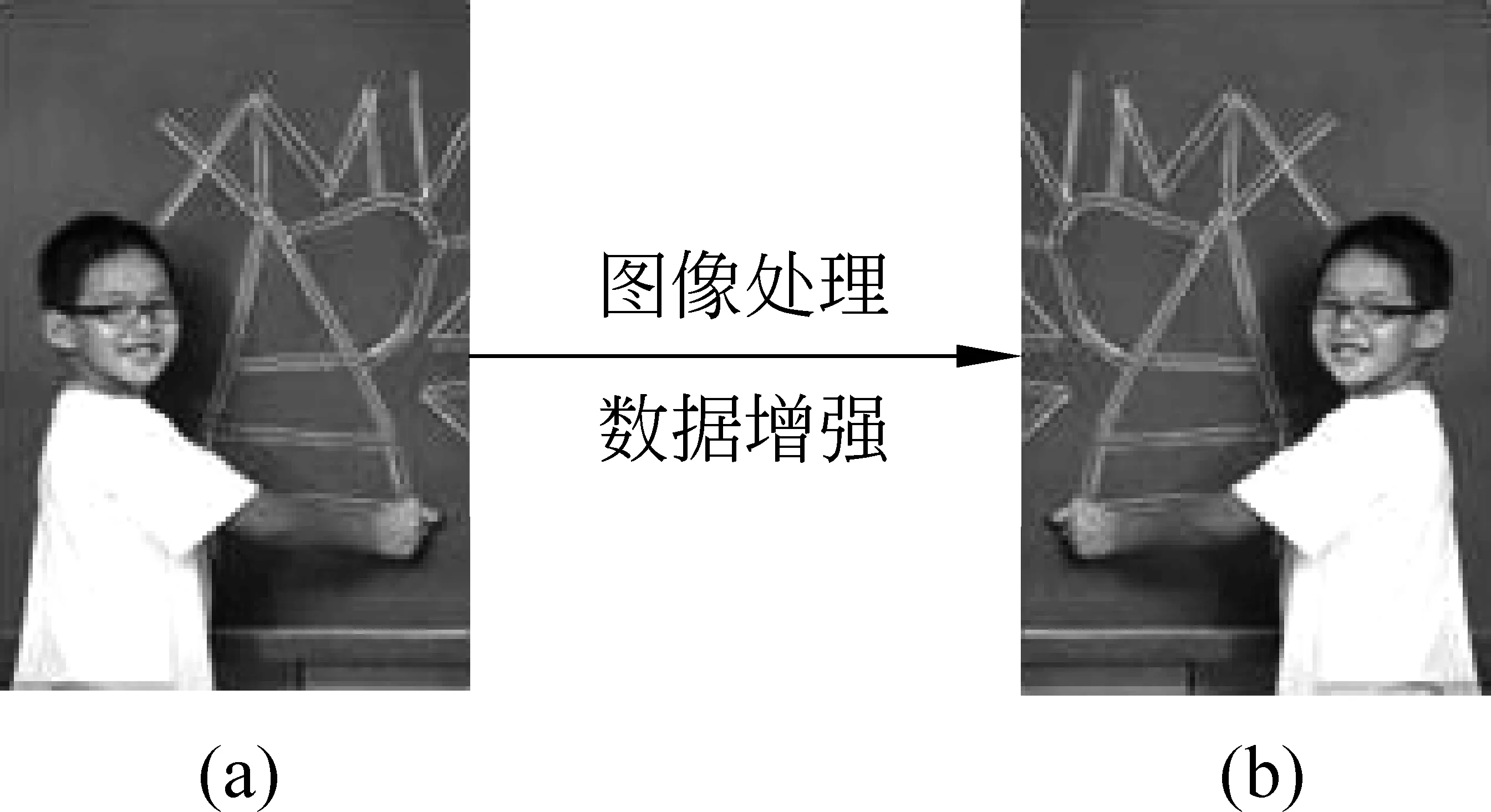
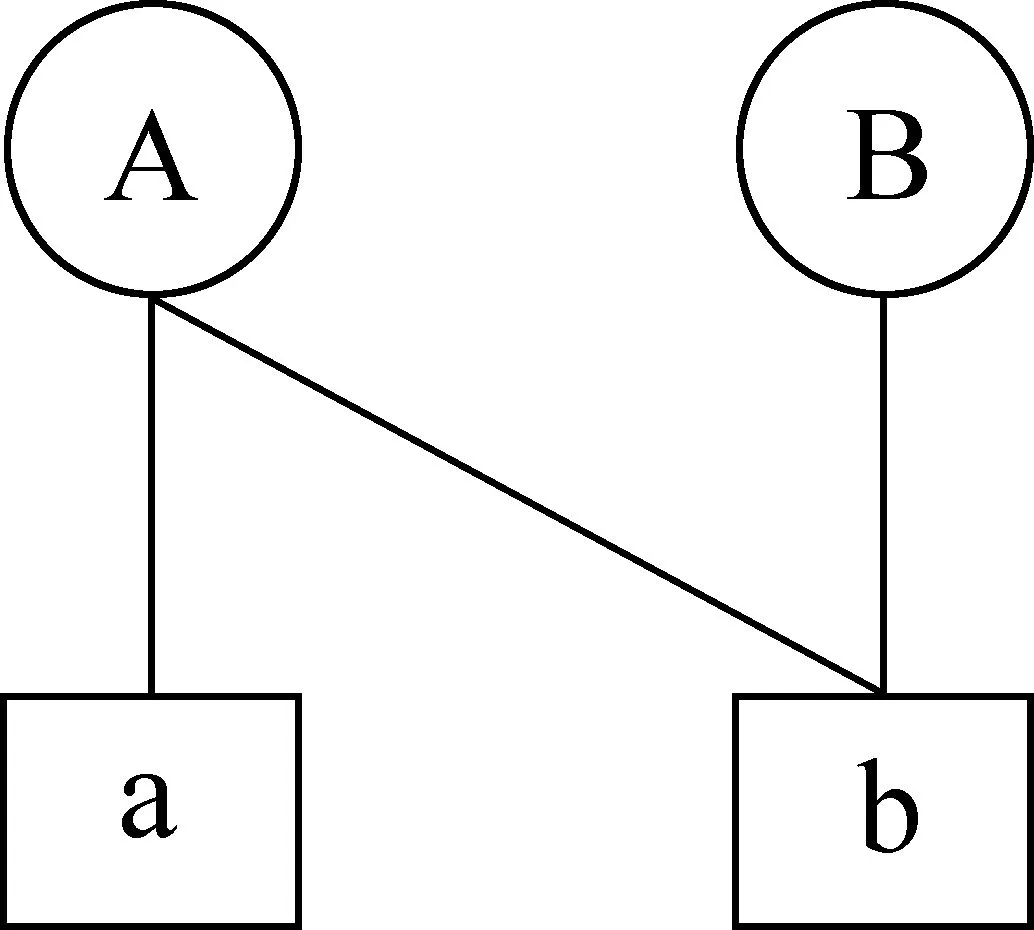
其中yi是解码器第i时刻生成的目标端单词,y p(yi|y (2) 其中f(·)是非线性函数,si是解码器第i时刻的隐藏状态,如式(3)所示。 si=g(si-1,yi-1,ci) (3) 其中,g(·)是非线性函数。ci是源端句子的内容向量,它是源端隐藏层h的线性和,权重ai,j代表解码器解码第i个单词时,对源端第j个单词所对应的隐藏向量的关注度。计算方式如式(4)所示。 (4) 基于注意力机制的神经机器翻译使用最大似然函数训练整个模型的参数,如式(5)所示。 (5) 其中,θ指的是模型的参数,N指的是语料中的平行句对数。 (6) 本节主要介绍神经机器翻译在资源贫乏语言对上研究的相关情况。2016年,Zoph等人[6]最先提出: 在资源贫乏语言对上,神经机器翻译的效果不如统计机器翻译,他们在四组资源贫乏语言对上进行了实验,分别用神经机器翻译和统计机器翻译进行训练,结果发现统计机器翻译在这四组语言对上的评测结果均优于神经机器翻译。 国内外很多研究者对此问题提出了各自的解决方法。这些方法大致可以分为两类,一类是通过补充训练数据,使得神经机器翻译模型得到较为充分的训练;另一类是将文字的语法、语义信息和神经机器翻译模型相融合,从而提高神经机器翻译的性能。 本文主要关注的是第一类解决方法,即通过增加训练数据,改善神经机器翻译在资源贫乏语言对上翻译性能不佳的情况。增加训练数据,并不是去挖掘真实的平行句对,而是通过技术手段,构造伪平行句对。 Sennrich[7]是第一个提出利用单语语料来构造伪平行句对的研究者。他认为,对于资源缺乏的语言对来说,单语语料的获取往往相对容易,充分地利用单语语料来增强神经机器翻译是十分必要的。在收集到单语语料之后,可以用现有的翻译工具或者在小规模语料上训练好的神经机器翻译模型对单语语料进行翻译,从而获得伪平行句对,之后将伪平行句对和真实的平行句对放到一块进行模型训练。 和Sennrich的思路不同,Fadaee[8]提出了一种新的增加语料的方法。该方法首先在规模较大的单语语料上训练出语言模型,然后用语言模型找到句子中可以被低频词替换的高频词的位置。通过这种简单的单词替换,增加了训练语料中低频词出现的次数,从而增强神经机器翻译对低频词的理解能力。 本文在Sennrich和Fadaee等人工作的基础上,提出了自己的数据增强技术,即将句子中最相似的模块进行位置上的对调,以此形成新的语料。与Sennrich提出的方法相比较: 不同点在于我们利用真实的平行句对而非单语语料进行伪语料的构造,相同点在于构造的伪语料都存在错误。与Fadaee提出的方法相比较: 不同点在于我们改变的是语料中句子的结构信息而非语料中的词频信息,相同点在于都是对原语料进行扩充。 本文中,我们把神经机器翻译当作一个“黑盒子”,不进行任何修改,而是利用数据增强技术提高神经机器翻译对于资源贫乏语种的泛化能力。本节从三个方面对数据增强技术进行详细的说明。第一,分析数据增强技术在神经机器翻译上面临的难点;第二,提出解决这些难点的方法;第三,介绍数据增强技术具体实现的细节。 虽然数据增强在图像处理任务中已经成为一个标准的技术用于提高神经网络的泛化能力,但是由于语言的特殊性,我们并不能简单地将该技术拓展到机器翻译任务上来。 图2是数据增强技术在图像分类任务中的一个典型应用。新图像(b)由原图像(a)翻转180度所得,因为是简单的旋转变化,所以图像(b)的内容、标签与图像(a)完全一致。把图像(b)放入训练数据,可以增强图像训练的鲁棒性[9]。 图2 数据增强技术在图像处理任务中的应用 自然语言处理与图像处理方式大有不同。自然语言有着严格的语法约束,如表1第一个例子所示,简单地将一句话从右往左地倒着读既破坏了语法规则,句子本身也失去了语义信息。第二个例子,原句子本身就是一个十分简单的主谓宾结构,将“我”和“篮球”进行对调,虽然新句子没有破坏语法规则,但是在语义上存在错误。第三个例子,“西电东送”和“西气东输”是对等的两个实体,将它们对调形成的新句子在语义和语法上均保持正确。 根据上面的分析,我们不难发现,如果原句子的长度较短,本身结构简单,那么无论对这个句子进行怎样的变化,新句子都会存在语法或者语义上的错误。对于这类存在一定错误的新句子,我们并不会丢弃,而是将它作为噪声来增强神经机器翻译的泛化能力。 而对于表1中第三个例子,我们应尽可能地将句子中最相似的模块进行调换。因此,数据增强技术在神经机器翻译上的难点如下: ①如何获得句子的模块; ②如何计算模块之间的相似度? 表1 自然语言变化的示例 获得句子的模块是指如何对一个句子进行切分。句子可以分为三个层级,其中单词是构成句子的最小单位,单词组成短语,短语的再上一级是最小翻译单元。以单词为单位对句子进行切分会存在一对多的问题。例如,图3是词对齐中常见的的一对多问题,源端A单词分别和目标端a,b对齐,将a和b的位置进行对调,那么源端A的位置并不能唯一地确定下来。 图3 词对齐中的一对多问题 因此,本文以最小翻译单元为单位对句子进行切分,理由如下: ①最小翻译单元在句子的结构中处于最上层,除了涵盖单词和短语的信息外,它还具有一些句子级别的信息; ②最小翻译单元具有闭包性,单元与单元之间不存在词对齐关系,这个性质避免了词对齐中的一对多问题。 计算句子模块之间的相似度分两步: 第一步,获得模块的向量表示;第二步,对模块进行余弦相似度计算。这里句子模块指的是最小翻译单元,最小翻译单元由句子中连续的若干个单词构成,因此有两种方式获得它的向量表示: 第一种,以单词为单位,用Word2Vec对原语料进行训练,获得单词的向量表示。然后将构成最小翻译单元的单词向量相加作为其对应的向量表示。第二种,把最小翻译单元当做一个整体,用Word2Vec直接获得它所对应的向量表示,得到最小翻译单元mtu1和mtu2的向量表示之后,如式(7)所示,用向量夹角的余弦值来描述它们的相似度,余弦值越大,最小翻译单元就越相似。 (7) 本节通过一个例子,具体说明实现数据增强技术的四个步骤。如表2所示,首先获取平行语料,然后利用moses对平行语料进行训练,获得词对齐信息。接着利用pbmt工具得到句子的最小翻译单元。最后通过调换原句子最相似的两个模块得到新的平行句对。 对于第四个步骤,我们要分情况进行讨论。第一种情况是3.2节中提到的,最小翻译单元向量的表征方式分为直接和间接两种。第二种情况是原句对中源端最相似的模块不一定和目标端最相似的模块相互对齐。 表2 数据增强技术的四个步骤 对于第一种情况,我们做两组对比实验。第一组,以单词为单位,用Word2Vec对语料进行词向量训练,然后用单词向量的和对最小翻译单元进行向量表征,我们把通过这种方式得到的向量称为最小翻译单元的间接向量(I-MTU)。第二组,我们把最小翻译单元当做一个单词,用Word2Vec进行训练,获得的词向量,我们称为最小翻译单元的直接向量(D-MTU)。 对于第二种情况,我们分三种方式产生新句对。如表3所示,xi,yi是源端和目标端相互对齐的最小翻译单元对,(xi,yi)表示源端第i个和第j个最小翻译单元的相似度(sim)。 第一种方式是以源端为基准产生新句对(source-based generate, SBG)。该方法首先找到源端最相似的最小翻译单元x1和x2,并对调它们的位置,然后根据对齐信息,找到目标端对应的最小翻译单元y1和y2,并对调它们的位置。 第二种方式是以目标端为基准产生新句对(target-based generate,TBG),与SBG类似,这里不再赘述。 第三种方式是将源端和目标端相结合产生新句对(combination-based generate, CBG)。CBG综合考虑源端和目标端sim值排在前k个的最小翻译单元对,两者取交集,若该交集非空,则取交集里相似度最高的作为两端最相似的最小翻译单元。若该交集为空,则比较源端和目标端最大的sim值,当源端sim值高于目标端的时候,我们采用SBG产生新句对;否则,我们采用TBG产生新句对。实验中我们把k值设置为3。 表3 各种新句对产生方式 表3中,Source-MTU指的是句子源端的最小翻译单元,Traget-MTU指的是句子目标端的最小翻译单元,Rank of Source-MTU 指的是将源端的最小翻译单元对按照余弦值从大到小进行排序,Rank of Traget-MTU 指的是将目标端的最小翻译单元对按照余弦值从大到小进行排序。 为了验证本文提出的数据增强技术,我们分别在藏汉、汉英这两个语言对上进行实验。其中, 藏汉语料是2011年全国机器翻译研讨会提供的10万平行句对,测试集为650句。中英语料是本实验组收集整理的,共100万平行句对,测试集为nist06。 本文用Word2Vec获得最小翻译单元的向量表征。Word2Vec包含两种训练模型,本文用的是skip gram模型[10],其中词向量的维度设置成30,训练窗口大小设置为5。 本文用的神经网络机器翻译系统是本课题组基于Bahdanau等人的工作开发出来的,用“RNNSearch”表示。其中,对训练语料的句子长度限制在80以下,源端和目标端的词向量维度设置为620,隐藏层维度设置为1 000,单词表大小设置为3万,采用ADADELTA[11]方法对参数进行更新,训练中batch的大小设置为80,Dropout[12]设置为0.5。 本文还将基于数据增强技术的神经机器翻译与统计机器翻译作对比,实验采用爱丁堡等大学联合开发的Moses[13]作为统计机器翻译的基准系统,Moses采用默认配置,实验以BLEU-4作为评测标准。 本文针对最小翻译单元的向量表征提出了两种方法,分别是I-MTU和D-MTU。其中,I-MTU是一种间接获取短语向量表征的方式,D-MTU把短语作为一个整体,其向量表示由Word2Vec训练得到,是一种直接获取短语向量表征的方式。从图4中我们可以看出,在三种不同生成句子的策略下,D-MTU的结果都要比I-MTU好,这表明,虽然Word2Vec训练的词向量具有良好的语义信息,但是简单地用词向量的和对短语进行表征,还是存在一定问题。 图4 藏汉六组实验结果 本文用三种不同的方式产生新的句对,分别是SBG、TBG和CBG。图4的实验结果表明,在藏汉翻译上,TBG对翻译性能的提升是最显著的。 为了说明SBG、CBG和TBG三种方法间的差异,我们对产生的新语料进行了统计,结果如表4所示。SBG和TBG产生的新语料中有近60%的句子是不同的,CBG和TBG产生的新语料中有近40%的句子是不同的,这表明翻译源端和目标端语种的不同,对找出相似的最小翻译单元是有影响的。对于藏汉翻译来说,以汉语为基准产生新句对要比以藏语为基准产生新句对的方法好。在其他语言的翻译任务中,我们并不能事先知道SBG和TBG哪种方法更好,而训练神经机器翻译往往需要大量的时间和资源,这时采用折中的方法CBG是一个不错的选择。 表4 SBG、CBG与TBG不相同句子数所占的百分比 注: SU是差集的缩写。 为了验证本文提出的数据增强技术,我们做了以下几组实验进行对比分析。 从表5中,我们可以看出,在藏汉这种小语料上,神经机器翻译的基准系统比统计机器翻译系统低了3个点,这验证了Zoph等人提出的在资源稀缺的语言对上,神经机器翻译要弱于统计机器翻译。通过使用数据增强技术,神经机器翻译系统的性能得到大幅提升,BLEU值提高了4个点,甚至比统计机器翻译的结果还要高1个点,这验证了我们提出的数据增强技术的有效性。 为了进一步分析数据增强技术在不同程度的资源贫乏场景下的效果,如表6所示,我们以汉英作为我们的训练语言对,分别在语料规模为10万(极度贫乏)、30万(十分贫乏)、50万(中度贫乏)、70万(轻微贫乏)、100万(不贫乏)上做实验,实验结果表明,当语言对处于极度贫乏时,本文提出的数据增强技术可以有效地提升神经机器翻译的性能,当语言对不是很贫乏时,本文提出的方法也是正向反馈的,也能提高大概1个多点的BLEU值。 表6 不同程度的资源贫乏场景下的效果对比 如表6最后两行所示,我们对比了Sennrich提出的用伪语料加强神经翻译训练的方法。实验中,我们用谷歌翻译工具对随机抽取的与Baseline不相同的英文句子进行中文翻译,从实验结果上来看,这种伪语料技术的效果要比本文提出的数据增强技术要好,但是考虑到谷歌公司可能会把我们的联合国语料放到它自己的模型上进行训练,因此伪语料技术实际上未必能比我们提出的数据增强技术高4个BLEU值。我们也将本文提出的数据增强技术和伪语料技术相结合,实验结果表明两种方法联合使用可以进一步提升资源贫乏语言对的翻译质量。 表7是我们从测试集中挑选的句子,用于说明数据增强技术对神经机器翻译系统的帮助。对比参考译文,Moses生成的译文丢失了动词“提高”;基准系统RNNSearch生成的译文丢失了名词“企业”,且不通顺;RNNSearch+TDA基本翻译正确,而且通过调换“要”的位置,相比于参考译文,也显得更加通顺。 表7 译文示例 本文针对神经机器翻译在资源贫乏语种上面临的训练语料不足问题,提出了数据增强方法。该方法首先对句子进行分块,然后调换最相似的两个模块得到新的句子,最后将新的句子加入到语料中,对翻译模型进行训练。本文在藏汉、汉英语种上的实验结果表明,数据增强技术既能有效提高神经机器翻译对于资源贫乏语种的泛化能力,也能对语料较丰富的语种起到提升翻译质量的作用。当然,该方法也有自己的缺点,通过这种方法产生的新句子往往存在语义或者语法上的错误,这种错误对神经机器翻译产生的影响有待研究。在未来的工作中,我们会考虑将句法知识引入数据增强技术,以此改善生成的句子。
2 相关工作
3 数据增强技术
3.1 难点分析

3.2 解决方法
3.3 具体实现

4 实验结果与分析
4.1 实验设置
4.2 最小翻译单元的向量表征
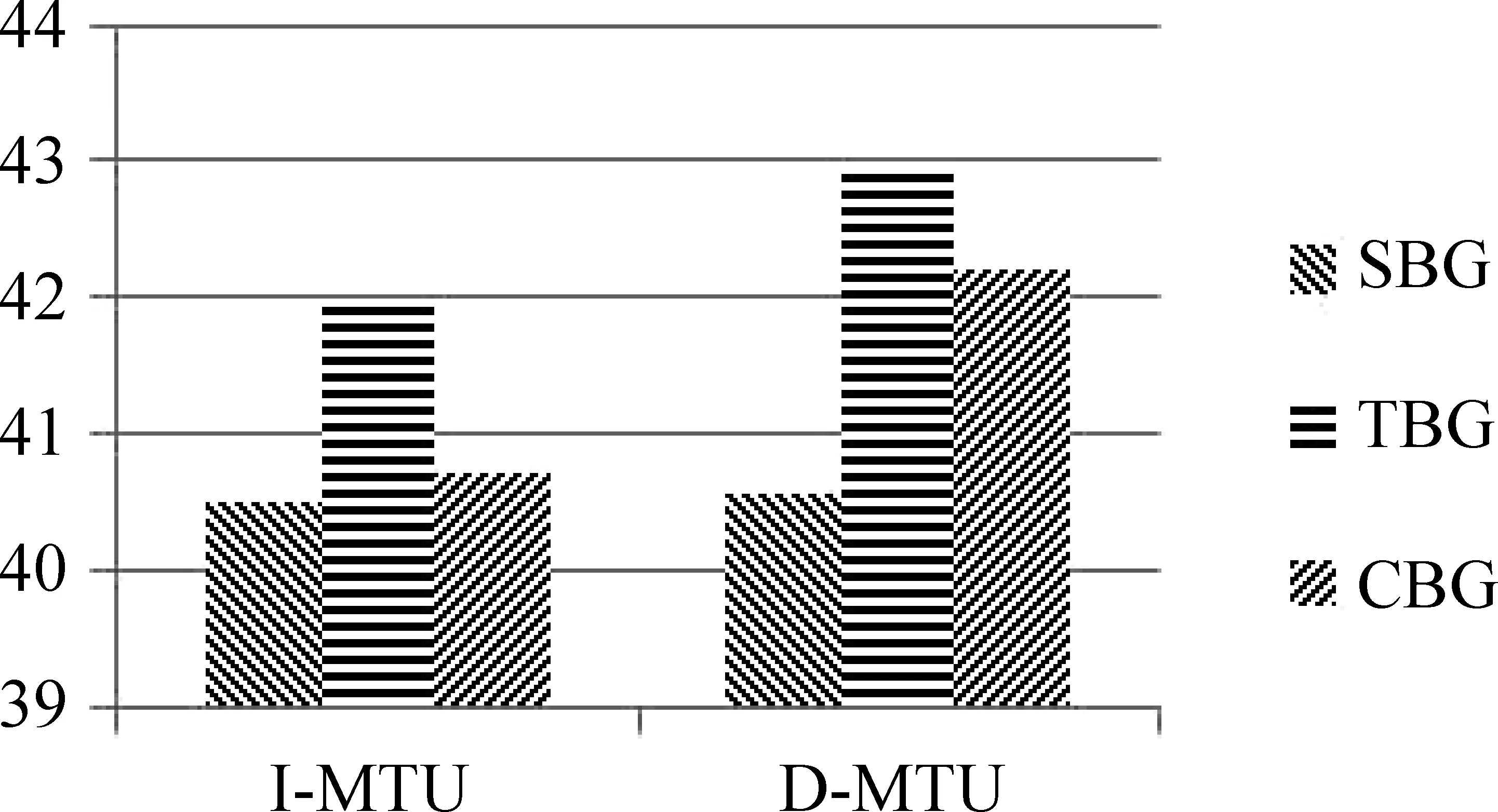
4.3 生成句子的策略选择

4.4 数据增强技术的验证

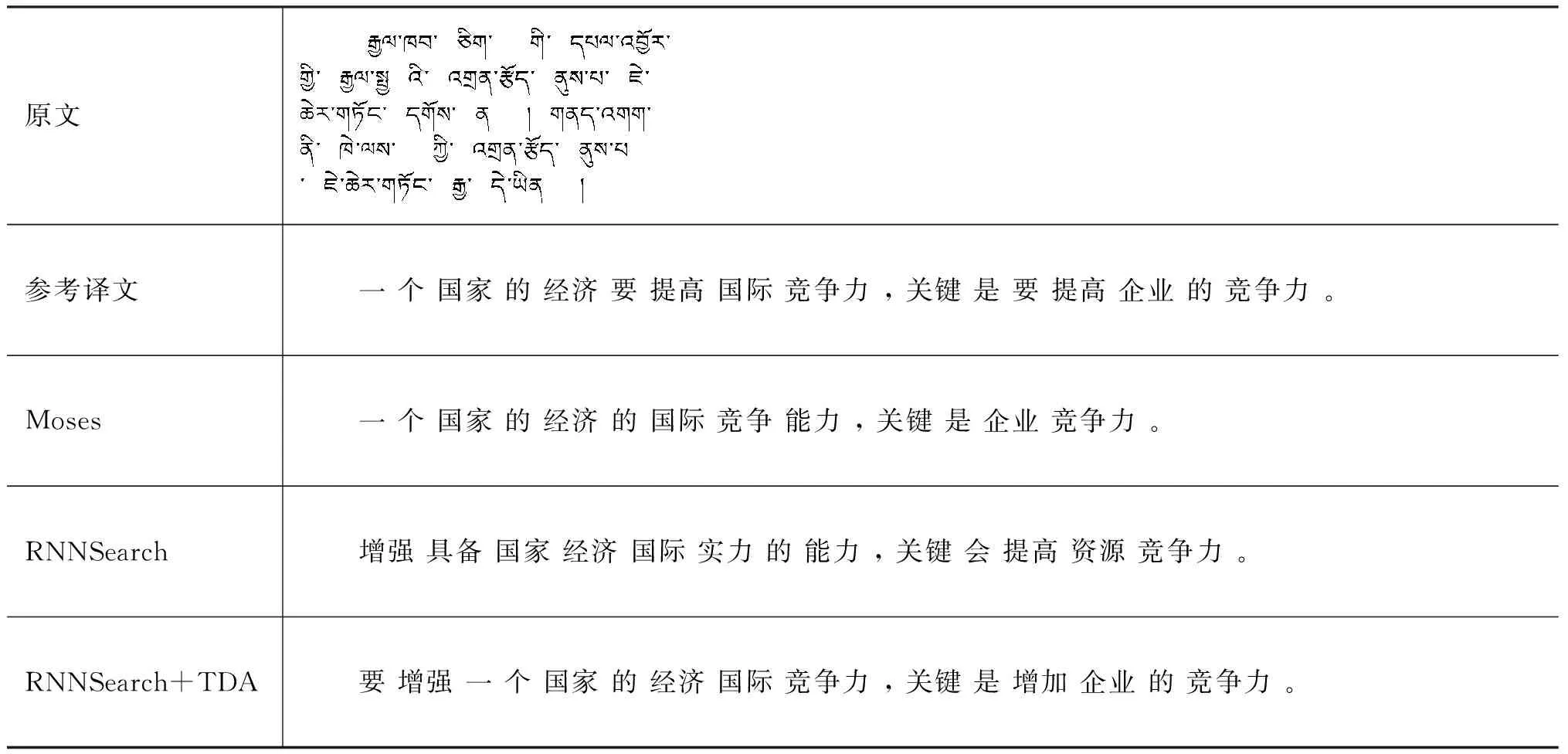
4.5 示例分析
5 总结
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28通信技术(2021年12期)2022-01-25中学生数理化(高中版.高考数学)(2021年1期)2021-03-19阅读(快乐英语高年级)(2020年8期)2020-01-08智慧少年·故事叮当(2018年11期)2018-05-14高中生学习·高三版(2016年9期)2016-05-14新高考·高二数学(2015年11期)2015-12-23小学生时代·大嘴英语(2014年9期)2014-11-04民族古籍研究(2014年0期)2014-10-27外语教学理论与实践(2014年2期)2014-06-21
