
文本情感分析的深度学习方法
2018-08-15 08:02:34邢长征
计算机应用与软件 2018年8期
邢长征 李 珊
(辽宁工程技术大学电子与信息工程学院 辽宁 葫芦岛 125105)
0 引 言
如今是一个信息爆炸的时代,如何利用这些海量的、庞杂的数据已慢慢成为了当下研究的热点内容[1]。随着近些年研究的深入和计算机硬件设备的改善,基于神经网络的模型越来越受到欢迎[1],深度学习在人工智能方面的处理能力也初步提升,越来越受到人们的重视。深度学习是机器学习的一个分支,深度学习的概念最早由多伦多大学的G.E.Hinton等在2006年提出,指基于样本数据通过一定的训练方法得到包括多个层级的深度网络结构的机器学习过程[2]。
情感分析,也称为观点挖掘,指的是分析说话者在传达信息时所隐含的情感状态、态度、意见进行判断或者评估[3]。关于文本,整句的情感倾向性一般比较明确,其中正向情感表示褒义类:赞扬、喜悦、歌颂等;负向情感表示贬义类:贬斥、悲哀、嫉妒等[4-5]。在文本情感分析的发展过程中,人们使用了朴素贝叶斯算法、最大熵、决策树、支持向量机(SVM)等算法。这些方法都归属于浅层学习,函数模型和计算方法都不复杂,实现相对简单,导致这些算法在有限的样本和计算单元下无法表达复杂的函数,泛化能力较弱。浅层学习依靠人工经验抽取样本特征,网络学习后获得的是没有层次结构的单层特征,而深度学习通过对原始信号进行逐层特征变换,将样本在原空间的特征表示变换到新的特征空间,自动学习得到层次化的特征表示[4,6]。近些年人们对于文本情感分析的研究逐渐从浅层的学习过渡到用深度模型进行训练,并且,深度学习在情感分析方面逐渐成为了主流的方法。
1 相关研究
近几年国内外关于情感分析问题的研究越来越多,人们从机器学习的方法不断地向着深度学习方法进行探索。崔志刚[7]使用改进的SVM进行实验,属于浅层学习方法。刘艳梅[3]基于SVM/RNN构建分类器对微博数据进行情感分析。李阳辉等[8]采用降噪自编码器对文本进行无标记特征学习并进行情感分类。Santos等[9]使用了卷积神经网络(CNN)进行实验,实验验证CNN在处理文本信息时有着不错的效果。Li等[10]采用LSTM进行情感分析,实验证明,LSTM相较于RNN在分析长语句情感分析方面表现得更好。梁军等[11]使用一种基于极性转移和LSTM递归网络相结合对LSTM进行改善。王欢欢[12]运用情感词典和LSTM结合的方法提高准确率。王雪娇[13]使用CNN与GRU相结合的新模型来改善CNN。Hassan等[14]提出将CNN与LSTM相结合的新的深度学习模型,将LSTM作为池化层的替代。Li等[15]提出基于CNN和双向LSTM RNN的电影情感分析方法进行情感分析。
卷积神经网络(CNN)和循环神经网络(RNN)都可以解决文本的情感分析问题[16-18]。CNN在处理图像和计算机视觉方面表现出很好的效果[19-20],它善于提取特征。而RNN在处理手写文字识别和文本处理等方面表现出了它的优越性[21],近些年,LSTM在情感分析的任务上得到了广泛的应用,并且表现出了较好的效果。
2 相关技术
2.1 长短时记忆网络(LSTM)
在自然语言处理方面,循环神经网络在捕捉任意长度序列的信息[22]有类似的记忆功能。传统的循环神经网络在输入数据过长时,因为非线性变换,在尾部的梯度进行反向传播时不能将梯度传给句子的起始位置,经过训练会出现一个不可忽视的问题:梯度弥散,梯度弥散是一个需要解决的问题。针对这个问题人们提出了一个基于循环神经网络的新的网络模型——LSTM,LSTM可以理解为升级版的循环神经网络。长短时记忆网络解决了循环神经网络中存在的梯度弥散的问题[10,23],LSTM提出了一个叫作记忆单元的新结构。LSTM由四个部分组成:输入门、输出门、遗忘门和记忆单元。LSTM的网络具体结构如图1所示。
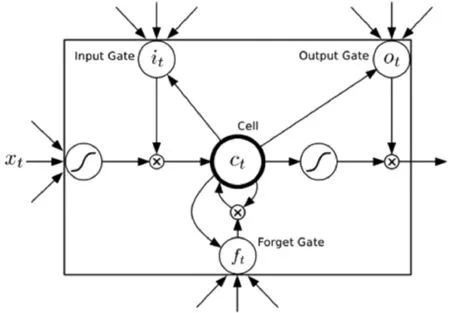
图1 LSTM结构
下面就几个公式介绍一下LSTM具体的工作流程:
第一步:新输入xt前状态ht-1决定C哪些信息可以舍弃ft与Ct-1运算,对部分信息进行去除:
ft=δ(Wf·[ht-1,xt])+bf
(1)
it=δ(Wi·[ht-1,xt]+bi)
(2)
(3)
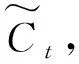
(4)
第四步:根据控制参数Ct产生此刻的新的LSTM输出:
Ot=δ(WO[ht-1,xt]+bO)
(5)
ht=Ot×tanh(Ct)
(6)
2.2 GRU
GRU是长短时记忆网络的一个重要变种[24],它从两个方面做出了改变,首先是遗忘门和输入门的结合(不是独立,不是互补),将其合成了一个单一的更新门。其次,控制参数Ct与输出ht结合,直接产生带有长短记忆能力的输出。而且GRU同样还混合了细胞状态和隐藏状态,和其他一些改动。GRU与LSTM效果类似,GRU比标准LSTM简单[23],GRU所使用的参数要少于LSTM中使用的个数。具体结构如图2所示。

图2 GRU结构
下面就几个公式介绍一下GRU具体的工作流程:
第一步:新输入xt前状态ht-1和权重Wz对zt进行更新:
zt=δ(Wz·[ht-1,xt])
(7)
第二步:新输入xt前状态ht-1和权重Wr计算rt,从新得到的内容中抽取信息:
rt=δ(Wr·[ht-1,xt])
(8)
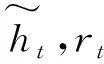
(9)
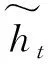
(10)
GRU计算的过程中不需要C,GRU将C合并到了ht中,在GRU中ht做不断的更新,更新的方式是遗忘多少就添加多少。
3 实 验
本实验利用GRU进行堆叠设计神经网络模型,提出一种新的模型——MultiGRU。期望通过多层的GRU的堆叠,不断提取语句的相关信息,防止文本信息的缺失和捕获语句间的长期依赖关系。
3.1 实验平台及数据集
3.1.1 实验平台
实验的首要条件为对实验环境的设置和实验平台的搭建。本实验依托的硬件和软件的平台为:
(1) 硬件:Win7系统、内存4 GB。
(2) 软件和依赖的库:Python3.5、tensorflow、keras等。
3.1.2 数据集
IMDB数据集为电影评论数据集,见表1。本数据集含有来自IMDB的50 000条影评,被标记为正面、负面两种评价。该数据集中的评论数据被分为训练集和测试集。其中正负样本数均衡。

表1 数据集
3.2 实验分析
3.2.1 模型构建
首先分析预先处理好的IMDB的数据:训练集每条评论中的字长不相同,有的评论很长,有2 494个字符,这样的异常值需要排除,文本计算得出平均每个评论的字长为238.714个字符。根据平均字长可以设定最多输入的文本长度为400个字符,这样也便于数据降维,一些字长比较短,不足400个字符的文本用空格填充,超过400个字符的文本截取400个字符,即maxword为400。使用keras提供的Embedding层作为模型的第一层,词向量的维度为64,每个训练段落为maxword×64矩阵,作为数据的输入,填入输入层。本实验利用GRU神经网络进行深度模型的构建,所提出的网络结构MultiGRU选取三层GRU的堆叠,三层 GRU的输出维度分别设定为128、64、32,从而构建起基本的网络模型。实验在GRU的层级之间添加了Dropout层,为了减少训练过程中出现的过拟合,在Dropout层中设置随机失活值为0.2。之后我们将引入一个全连接层作为输出层,该层使用的非线性激活函数为sigmoid,预测0,1变量的概率。MultiGRU通过每层GRU来不断捕捉语句间的信息,减少信息的丢失和依赖关系的消失。
模型基本搭建完成后,通过交叉熵来测试模型,把交叉熵作为目标函数,交叉熵越小说明匹配的越准确,模型精度越高。本次实验使用RMSprop Optimizer来进行优化,该优化函数适用于循环神经网络,在模型训练中使用的梯度下降方法中,合理动态地选择学习率。将数据灌入模型,使用IMDB中的测试集作为验证数据,批次大小设置为100,迭代轮次设为5轮。
3.2.2 MultiGRU参数选择
超参数可以有很多不同的组合,需要花费时间不断学习调整验证。在进行参数选择的对比实验过程中发现:首先,在模型层数选择的实验中,模型的层数分别设定为一层、两层、三层和四层,测定MultiGRU有几层GRU时效果较好,经过实验发现当模型的层数大于三层时的准确率并没有随着GRU层数的增加而有所提升,反而实验的时间耗费的更长,故最终模型选择的层数为三层时较好(如图3所示)。其次,在Dropout的参数选择实验中分别选取0.1、0.2和0.5三个参数进行对比实验,经实验可知,在该模型中,当Dropout参数为0.2时准确率更好(如图4所示)。
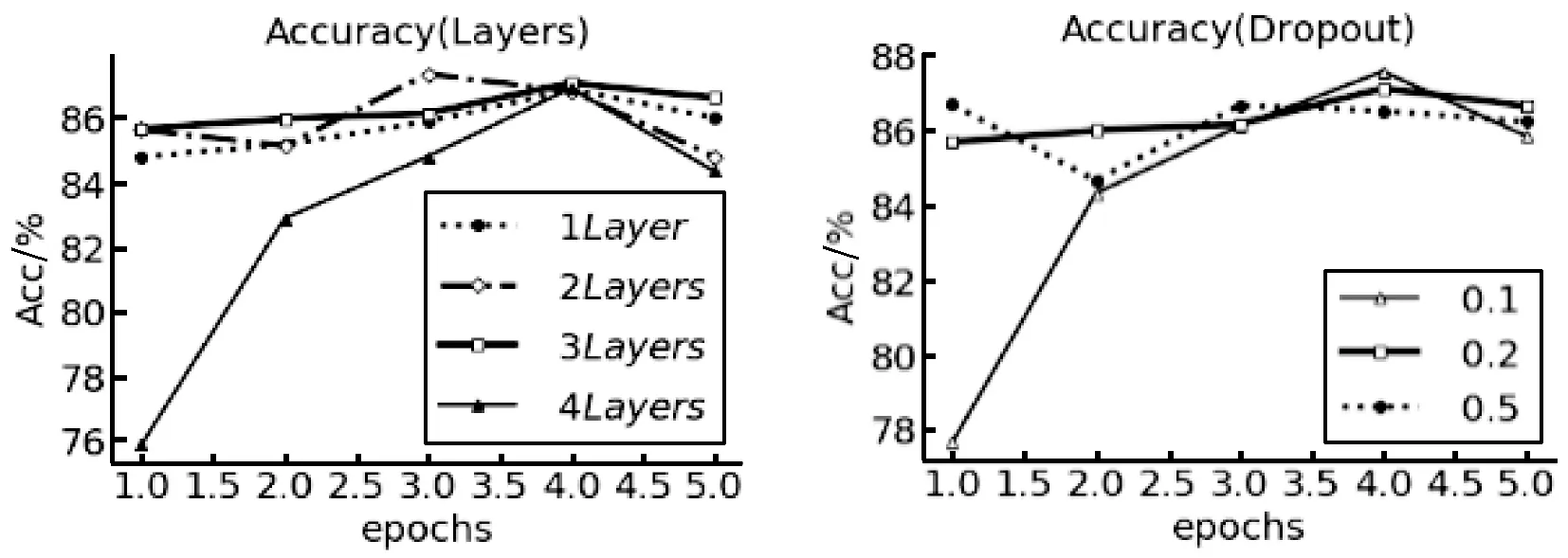
图3 层数实验 图4 Dropout参数实验
进一步测试MultiGRU构建时所选取的相关参数对模型的影响,实验分别测试层数为1到4层时不同的Dropout参数下的MultiGRU模型的性能,评价指标分别为准确率和MSE(最小错误率)[13],准确率越高、MSE越小代表模型越好。实验结果如表2所示,可以看出,在MultiGRU的相关参数:层数为3层,Dropout 设定为0.2时,准确率较高且MSE值最小,模型的性能最好。
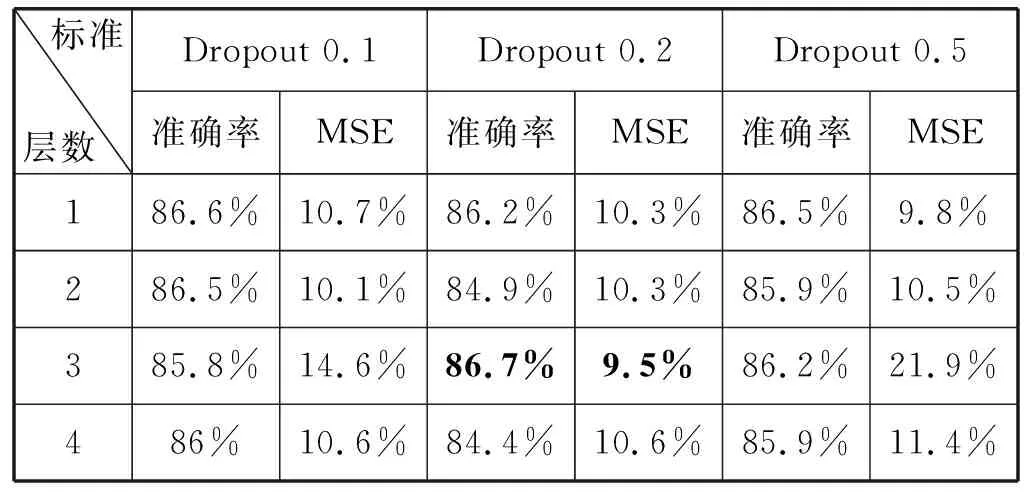
表2 MultiGRU参数选择实验
3.2.3 对比实验
1) 与LSTM的实验对比 LSTM在处理文本情感的分析上有着较好的效果,是目前处理情感分析问题时使用的热点方法[14]。本次实验通过GRU层的堆叠来不断训练构建的MultiGRU模型,对比实验中将模型中所有的GRU层全部替换成LSTM层,其他条件不变,迭代5轮后的对比结果:
(1) 在损失方面对比:设定的评价指标分别为交叉熵和MSE,实验结果如表3所示,MultiGRU的交叉熵和MSE都较小一些,说明MultiGRU模型匹配的比较准确,模型精度较高,鲁棒性更好一些。
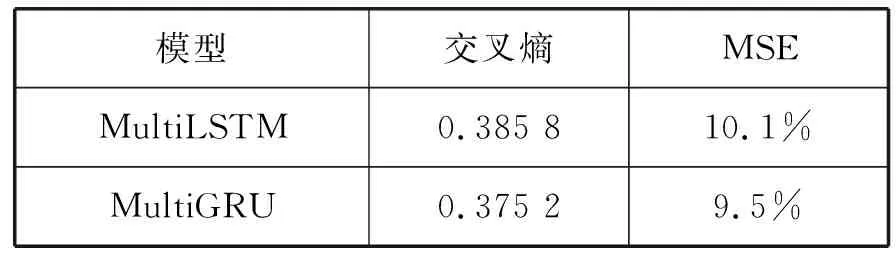
表3 两种模型的损失对比
(2) 在准确率等方面:设定的评价指标分别为准确率、召回率和F1值,实验结果如表4所示,综合这些评价指标可以看出MultiGRU模型的性能更好一些。
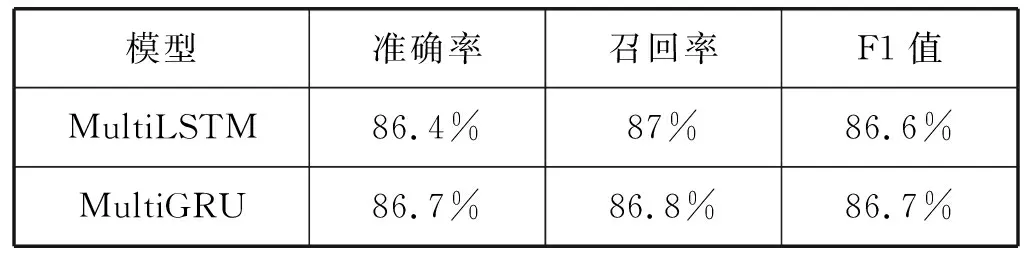
表4 两种模型的评价指标对比
(3) 在训练所花费的时间上:MultiGRU所使用的时间短于MultiLSTM训练所花费的时间,说明使用MultiGRU模型进行实验的速度要快于采用MultiLSTM模型的速度。如图5所示。
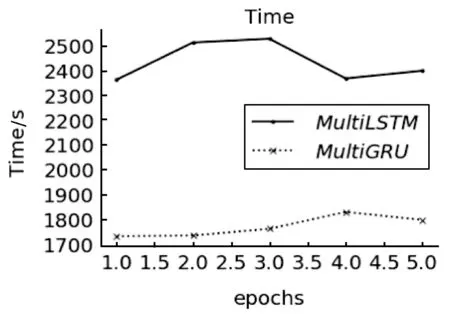
图5 时间
综上,从损失、准确率、召回率、F1值和时间对MultiGRU模型进行了评估,可以看出,MultiGRU模型在综合以上评价指标上表现得更好一些。
2) 与MLP(全连接神经网络)、CNN的实验对比 本次实验除了与LSTM进行实验对比之外,还选用了谢梁等[25]提出的两种神经网络模型进行实验,分别为全连接神经网络(MLP)模型和CNN模型,MLP与CNN同样可以应用于情感分析的任务上。实验从损失和准确率两个方面进行实验结果的对比和分析。
首先,在三种模型的损失对比实验中,设定的评价指标分别为交叉熵和MSE,实验结果如表5所示。MLP模型和CNN模型的交叉熵和MSE还是较大的,MultiGRU在该方面的值相较于其他两个模型更小,说明MultiGRU模型匹配的更准确,模型精度更高,鲁棒性更好一些。

表5 三种模型的损失对比
其次,在三种模型的准确率等相关评价指标上的对比实验中,实验结果如表6所示。综合这些评价指标可以看出,MultiGRU模型的性能更好一些。
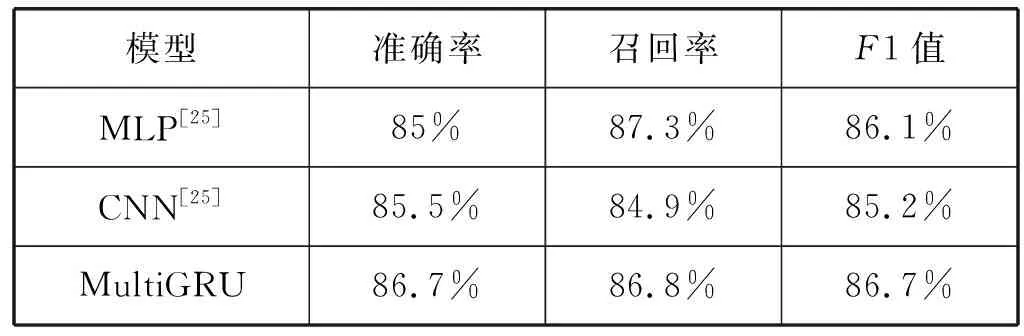
表6 三种模型的评价指标对比
综上,实验采用了其他两种神经网络模型对MultiGRU模型进行了评估,可以看出,在相关评价指标的测定下,MultiGRU模型性能较于其他两个模型都表现得更好。
4 结 语
随着世界的不断发展和信息量的日益增加,情感分析问题得到了越来越多人的重视,在科研和实际的生活中有着广泛的应用。本文对涉及到的相关知识做了简略的介绍,并提出了一个新的模型以减少信息丢失。实验证明,该技术方案对于处理文本数据的情感分析具有可行性。深度学习领域中也正有许多的新的结构被提出,可能这些新兴的结构在未来处理情感分析的问题上能够得到更好的结果,下一步的工作将研究更加适合情感分析的深度学习方法。
猜你喜欢
东北水利水电(2022年6期)2022-06-28 06:04:36
康复(2022年31期)2022-03-23 20:39:56
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:50
中国交通信息化(2018年5期)2018-08-21 03:37:40
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
