
基于知识图谱的可视化技术研究
2018-08-08 06:28秦锦玉翟洁陈程赵维杰蔡婷婷武海霞
电子设计工程 2018年14期
秦锦玉,翟洁,陈程,赵维杰,蔡婷婷,武海霞
(华东理工大学信息科学与工程学院,上海200237)
众所周知,中医是中国古代医者同大量未知疾病斗争所得的经验,经历持久的医学实践逐步形成和发展医学理论体系。其中,中医药的研究和发展是中医理论必不可少且相当重要的一部分。但由于国外对中医药学的无人问津,国内知识图谱的发展还不够面面俱到,导致中医药的知识网络相对零散,更多的以文字作为载体的呈现形式,以静态的图形来表述关联性,缺乏一定的交互性,也致使了大多数非相关人员很难接触和了解这门学科,甚至从事者也难以在大量的文献和文字资源中高效的获取所需求的知识。
针对以上问题,设计了关于中医药知识图谱的可视化系统,对中药数据采集后进行清理和分类,提供一个所想即所得的方式,以“图”的方式提供一种引导性学习,将大量的中医药知识之间的关联以简单的图谱形式展示,可视化效果好。
1 可视化的流程
中医药知识图谱的可视化流程如下所述:
1)层析结构设计
对展示的数据内容进行层次结构分析,确定上下位关系、数据模型和图模型。
2)节点生成
对主页面、分类页和详情页根据其节点特点,设计不同的节点生成算法,获得相应的节点和连线信息。
3)html页面生成
节点和连线准备好之后,需要将其转换为图形。本文设计了html页面生成算法,将节点和连线信息写入html页中。
4)力导引布局
以上步骤生成的知识图谱整体平衡,但存在很多交叉点,很不美观。我们可以利用KK算法来优化节点布局,减少交叉点的数量。流程图如图1所示。

图1 中医药知识图谱的可视化流程图
2 技术实现
2.1 层次结构设计
领域内的层次结构直观反应了领域内知识的上下位关系,为实现中药知识图谱可视化,首先要建立中药层次结构图。
在中药领域中,存在着很多上下位关系。本文中,采用药性、药味、归经等等作为中药知识的下层知识。药性、药味、归经又有各自包含的子概念,形成了具体的上下位关系,即是层次结构。
另外,考虑到有多处的一对多及多对一关系,数据模型选择不完全连接网状结构,因包含关系的单向性,图模型选择有向图。
综上,图谱设计规则为:上位元素作为起始节点,下位元素作为终止节点。
2.2 节点生成算法分析
生成知识图谱节点,便是将数据图形化,因而数据的提取、合并就成了重中之重。文中,设计了适合这个中医药知识图谱各种特性的节点及连线生成算法。
2.2.1 主页面及分类页节点生成算法
为形成清晰美观而又实用的主页面及分类页,采用排序算法及随机数生成算法,将点击率较高和另一些随机的中药节点呈现出来,总数不多于20。图2为主页图和分类节点图的生成流程。

图2 主页图和分类节点图的生成流程
具体思想是:
1)实例化自定义类Edges,其中包括属性source(起点),target(终点),weight(线段粗细)。
2)使用sql语句搜索得到所有具备当前属性的节点,并以主表中的点击率字段从高到低排列。
3)判断所有节点数是否大于20,若不大于则全部添加进节点列表,并添加所有连线。
4)若节点数大于20,先添加点击率最高的10个节点进节点列表,并在剩余节点中调用随机函数生成10个节点
5)随机函数原理则是生成10个0到n-10的节点(n为所有节点总数),得到随机数后+10则是所需节点的下标。
6)添加所有连线,起点均是中间属性节点,而终点则是节点列表中的节点,遍历添加即可。
2.2.2 详细页节点生成算法
详细页的节点需要二次查重,节点省略,还需要对连线进行合理分配起点终点。具体流程如下:
1)使用sql语句搜索得到当前中药所有分类总数,并将当前中药作为0号节点添加至节点列表。
2)记录所有分类节点数量parentNodes。
3)对每个分类节点再进行一次搜索,使用sql语句找到当前分类的中药,当搜索结果数量小于5时,全部添加,大于等于5时,添加点击率最高的4个节点,再添加一个“…”节点,表示有其他未添加的节点。
4)当添加节点时,某些子节点会和父节点具有多个相同分类,相同节点不应多次添加,即需要查重。则每次添加节点时必须对已有的节点列表进行遍历检查是否存在,若存在则只添加新的连线,而连线的起点则设置为遍历过程中,搜到重复节点的下标。
5)当节点和连线列表填充完毕后,再次记录节点列表的总节点数,目的是得到所有的子节点数量记作childNodes,在之后的知识图谱生成过程中,parentNodes和childNodes将作为重要参数。
详细页节点生成算法流程如图3所示。
详情页的节点生成比主页面和分类页更复杂,分类页的生成图的重点在于判断总节点数后对于节点的选择,而详情页则是在节点获取时的判断数量,是否添加,起点和终点的节点下标,以及分别记录节点数量。
2.3 html页组成算法分析
通过节点生成算法准备好节点和线后,需要将这些节点和线数据转换成图形。这要由D3.js这一类库完成,脚本语言需要嵌套在html页中展示,作为WPF设计界面,又可以通过浏览器控件访问html页。具体流程如下:
1)以流的方式读入html模板页,模板页为html语言编写,其中所需要的json格式数据源以及其他需要通过后台传入的参数,用字符串代替。
2)将用节点生成算法获取的节点和连线列表用string拼写成 json 格式{key:value,key:value,key,value…}。
3)替换json数据源,替换重要参数parentNodes。
4)流的方式写成html文件,并以当前药名/分类名命名。
之后,需要对其中的部分参数进行修改来达到系统最美观的程度,同时增加部分事件来体现交互性,而KK算法已经由D3.js中的force方法实现,调用force方法后,修改参数的值,会得到不同的界面效果。
2.4 力导引布局
据图4可以看出,单单的平衡可以采用圆面的布局方式,尽可能的使节点出现在某半径的圆周上。整体图形很平衡,但明显会有大量的交叉线在内部产生。极大的影响了图的可阅读性和美观程度。
力导引布局的方法可以产生相当优美的网络布局,并充分展现网络的整体结构及其自同构特征。该方法最早由Eades在1984年提出。其基本思想是将网络看成一个顶点为钢环,边为弹簧的物理系统,系统被赋予某个初始状态以后,弹簧弹力(引力和斥力)的作用会导致钢环移动,这种运动直到系统总能量减少到最小值停止。
Kamada和Kawai改进了Eades的弹簧模型,提出KK算法。
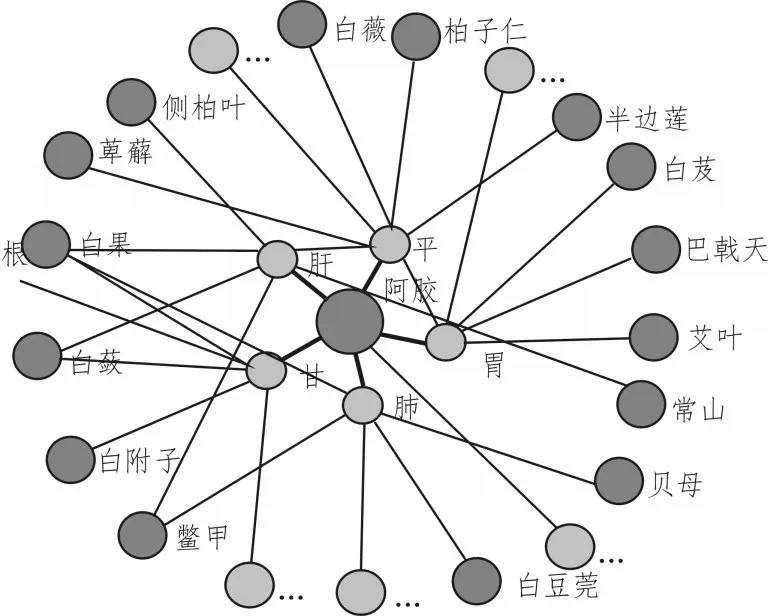
图4 未使用力导引布局的图
2.4.1 KK算法
D3.js中的force方法提供了KK算法的基本实现,由虎克(Hooke)定律,单个弹簧的能量E为:

其中:k是弹簧的弹力常数,x是从未拉伸的长度起的位移。KK算法中的能量写作:

其中:pv是节点v的位置向量,kuv是弹力常数,luv是节点v和节点u之间理想的弹簧长度。假定在式(2)中,为了使所有的弹力模型只计算一次,那么必须使所有的节点以有序对的形式出现。模型的力基于kuv和luv值的选择。弹簧未拉伸的长度定义为:

其中:L是单个边的理想长度。d(u,v)是节点v和节点u之间在图中对应的距离长度,和节点之间相隔的边有关,即从节点u到节点v所经过的边数。对L可用两种方法定义。一种方法是:

其中:W和H是显示区域的宽和高,|V|是图中节点的个数,本质则是通过最终面积来确定节点之间的最佳长度。另一种方法是:

式中:Lo是显示显示区域的一条边的边长,diam(G)是图G的直径(即相距最长距离节点对之间边数)

这种方法称为用图的直径定义理想边长。对于不同的应用,可以用其他方法定义L。弹力常数kuv定义为:

其中:K是一个任意的常数。显然用(3)和(7)代入到(2)中,得:

2.4.2 KK算法使用
算法本身由脚本文件直接生成,即组成html页时可以直接将节点和连线生成,但若要根据实际情况更优化的显示图谱,仍需要对参数进行修改和调试,其中linkDistance即为KK算法中luv,charge则是KK算法中的kuv。
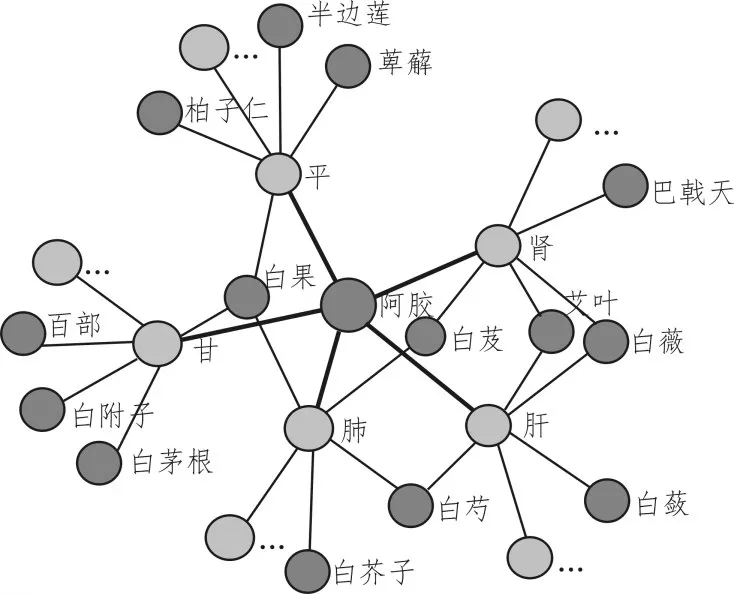
图5 l=600,k=-800

图6 l=1 000,k=-800

图7 l=600,k=-1 200
通过图5,6,7 3张图的比较,不难发现,kuv对于图最终的布局影响并不大,主要体现在了图生成过程中的速度,以及个边不相邻节点之间的距离,图7中个别节点的距离比图5中的距离大。而luv对最终图的影响比较大,如图6,当luv=1 000时,明显可以看到节点连线的夹角变大,整体图的效果比luv=600时显得松散。这和节点的数量本身有关,因此根据实际需要,节点总数量,子节点数量的各方面因素决定此处选择luv=600,kuv=-800。
3 结果演示
基于以上技术的分析,本文通过visual studio建立了一个wpf项目。在系统搜索栏中搜索某种中药名,窗体左侧便呈现以该中药为中心节点的知识图谱。通过知识图谱,可以清楚了解该中药的性、味、归经情况,还可以找到与该中药有相似处甚至可替换的其他中药。从效果图图8中可以看出,利用KK算法调整后的图整体布局平衡,交叉点少。
4 结束语
本文研究了中医药知识图谱可视化的相关技术,主要包括层析结构设计、节点生成、html页面生成和力导引布局4个部分,以此为基础,最终将网络上、书本上零散抽象的中医药知识进行整合、分类,并实现了一个高交互性的可视化系统。该系统为用户提供全面、及时、可靠的知识服务,也为中医药知识图谱的进一步发展提供了一些参考。

图8 结果展示
猜你喜欢
保健医苑(2022年1期)2022-08-30
快乐语文(2021年27期)2021-11-24
快乐语文(2021年11期)2021-07-20
小学生学习指导(中年级)(2021年4期)2021-04-27
快乐语文(2020年36期)2021-01-14
课堂内外(初中版)(2020年5期)2020-06-19
快乐语文(2019年12期)2019-06-12
中学生数理化·中考版(2015年10期)2015-09-10
华东师范大学学报(自然科学版)(2014年3期)2014-03-11
网络安全技术与应用(2011年3期)2011-03-14
