
基于AGD的恶意域名检测
2018-08-03 00:18:50臧小东龚俭胡晓艳
通信学报 2018年7期
臧小东,龚俭,胡晓艳
基于AGD的恶意域名检测
臧小东1,2,3,龚俭1,2,3,胡晓艳1,2,3
(1. 东南大学网络空间安全学院,江苏 南京 211189;2. 东南大学江苏省计算机网络重点实验室,江苏 南京 211189;3. 东南大学教育部计算机网络和信息集成重点实验室,江苏 南京 211189)
提出了一种聚类和分类算法相结合的恶意域名检测思路,首先通过聚类关联,辨识出同一域名生成算法(DGA, domain generation algorithm)或其变体生成的域名,然后分别提取每一个聚类集合中算法生成域名(AGD, algorithmically generated domain)的TTL、解析IP分布、归属、whois的更新、完整性及域名的活动历史特征等,利用SVM分类器过滤出其中的恶意域名。实验表明,该算法在不需要客户端查询记录信息的情况下即可实现准确率为 98.4%、假阳性为0.9%的恶意域名检测。
网络安全监测;域名生成算法;命令与控制服务器;算法生成域名
1 引言
作为互联网的重要基础设施,DNS承载着域名与IP的双重映射,电子邮件、网站服务、微博等多种应用都与之相关。与此同时,各种恶意活动也随之诞生,如僵尸网络[1]、垃圾邮件、钓鱼网站等利用DNS解析域名获取回连服务器的IP地址,隐藏和躲避僵尸代理背后的命令与控制(C&C, command and control)服务器,然后回连该服务器,接收指令和回传窃取的信息。由此可见,域名对僵尸网络等恶意活动的构建和发动攻击起着重要的作用。因此,有效检测和识别出这些恶意活动使用的域名,对发现和防范其传播具有重要意义。
早期的恶意代码通常在程序中预置IP地址作为其C&C的地址,这种现象经常导致单点故障问题。随后攻击者采用IP-Flux技术频繁切换IP地址躲避拦截,但该技术使用的域名固定,难逃域名黑名单的封堵。为了进一步提高逃逸和生存能力,最近攻击者采用域名生成算法生成域名,该算法使用一个特定参数(日期、时间、知名网站的内容)作为种子初始化一个随机算法,生成大量域名,并选择部分进行注册,如Conficker-A/B/C僵尸、Kraken botnet等[2]。本文将不同DGA生成的域名统称为AGD。为了有效区分这些AGD,研究人员开始逆向分析恶意代码[3-4],记录和封堵当前和后续生成的域名,但是当攻击者采用加密、周期性更新代码等混淆技术时,这种方法费时费力。
近年来,研究人员致力于通过分析DNS的活动行为进行恶意服务检测,算法的关键在于挖掘出合法活动区别于恶意活动的特征。相关研究存在2种思路:1) 围绕本地缓存名字服务器获取的下层DNS 流量开展,这种思路认为同一恶意代码感染的僵尸主机具有相似的访问模式,研究人员分别从解析成功和解析失败的域名出发,分析客户端用户对域名的查询行为[5-10]并进行辨识;2) 分析上层DNS流量,借用下层类似模型分析DNS活动,测量缓存名字服务器中的IP地址集的相似性、空间分布等特征[11-13]。研究发现,上述研究成果多集中在恶意域名的检测方面,而对生成的AGD属于哪一种DGA的研究较少;另外发现,上述算法各有所长且有着不同的适用范围,如文献[7]提出的Pleiades系统对具有Fast-Flux特性的域名具有较低的识别率;而文献[11]提出的Kopis仅识别某个特定顶级域的恶意域名;尽管文献[14]对生成的AGD属于哪一种DGA进行了研究,但该算法没有区分AGD中的恶意域名,实测过程中发现该算法存在较多误报。
为了弥补上述研究中存在的不足,并考虑到相关检测信息收集的难度和成本,本文提出了一种新的检测思路。具体地,通过对流经中国教育科研网江苏省网边界的上层DNS解析流量的实际观察,本文发现同一DGA生成的大量域名映射到相同的IP集合,本文认为攻击者拥有一个相对稳定的IP集合,映射到这些IP集合上的域名有可能是一种DGA生成的,为此,本文将解析到相同IP集合的域名聚类,这些IP很有可能是恶意代码的C&C服务器。另外发现,不同DGA生成的域名在字面组成上具有可区分性,根据这种现象,本文提取域名的字面特征,将字面特征相近的域名聚类。然后对2种聚类集合进行关联性分析,进一步过滤掉噪声,使每一个聚类集合中的域名更贴近同一DGA或其变体生成的域名。然后针对每一个聚类集合,挖掘出域名解析IP的使用位置、归属特征、whois特征、TTL及域名活动历时等特征,并在此基础上利用SVM算法过滤掉合法的域名。
本文的贡献如下所示。
1) 通过聚类关联有效识别同一DGA或其变体生成的域名。尽管使用聚类算法对域名分簇已十分常见,但将不同聚类算法关联起来,通过计算2种不同聚类算法输出结果的Jaccard index得分来识别同一DGA或其变体生成的域名在现有文献中暂未发现。与文献[14]相比,本文算法在识别同一DGA生成的域名方面较全面、准确,还可以区分出其中的恶意域名。
2) 提出了新的恶意域名检测测度,如域名解析IP使用位置、归属、whois的完整性及逆向IP查询得到的二级域名数。实验表明,利用本文提出的测度结合TTL、域名解析IP的分布及域名活动的历史信息等旧的测度可以有效地辨识出DGA生成的恶意域名及Fast-Flux[15-17]域名,并有着较高的检测精度。与文献[6]相比,本文算法不需要客户端的IP地址参与,不会因DNS缓存机制屏蔽用户的查询行为导致检测率低。
2 相关工作
越来越多的攻击者利用DNS 这种互联网的重要基础设施作为纽带从事非法活动,如新型僵尸网络等利用DNS服务隐藏其命令与控制服务器,提高生存性,其行为可分为感染阶段、C&C服务器招募阶段、攻击阶段及维护阶段,如图1所示。由此可见,识别出这些恶意代码使用的域名,可以实现事前检测和拦截恶意服务。近年来,研究人员通过分析 DNS 的活动行为检测恶意服务。由于在实际监测过程中观察到 DNS 流量的覆盖范围不同,本文将DNS 的解析流量分为上层流量和下层流量,如图 2 所示。其中,下层流量指实际所有DNS解析流量(包括访问缓存的流量),上层流量指访问DNS服务器的DNS解析流量。
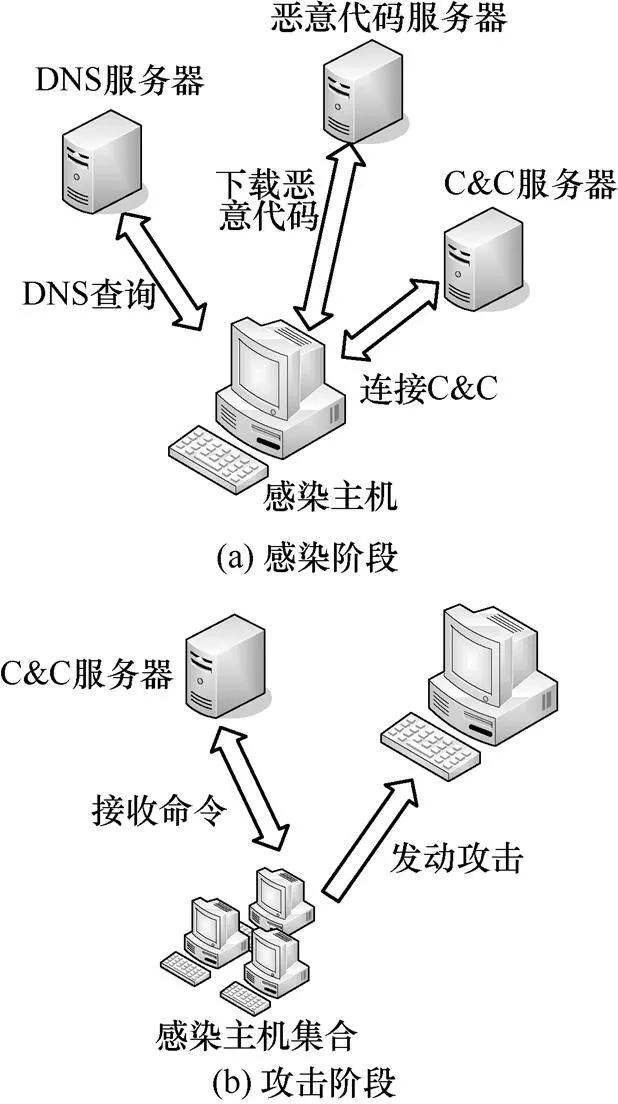
图1 僵尸网络
由于在接入网边界采集的DNS解析流量中不包含访问本地缓存的DNS解析流量,因此从接入网边界观察到的是上层DNS解析流量。研究思路分为2种,一种是围绕本地缓存名字服务器获取的下层DNS流量开展[5-10],分析查询失败的域名,从中识别出AGD。而文献[10]能从正确解析的域名出发提出动态的域名打分系统Notos,该系统使用被动DNS的查询数据、网络及域名的zone特征,通过计算域名的得分情况来确定该域名的合法性。

图2 DNS流量层次分类
另一种思路围绕上层DNS流量开展,借用下层DNS活动中的类似模型辨识出其中的恶意域名[11-13]。相关研究工作较少,代表性的方法有文献[11]提出的Kopis检测系统,该系统通过分析顶级域名服务器和权威服务器的数据以及全球域名的查询和响应行为特征进行识别,但是该系统仅可识别某个特定顶级域的域名。由于从顶级域名服务器处观察到的本地缓存名字服务器数量庞大且地域分布广泛,因此会降低从本地缓存名字服务器视角观察IP地址集相似性及空间分布特征的上层DNS流量检测算法的准确率。文献[12]基于域名的依赖性和使用位置区分域名的恶意性,实测过程中发现存在大量误报。近年来,深度学习越来越受研究人员的关注,它通过组合低层特征形成更加抽象的高层表示属性类别或特征用来发现数据的分布。文献[18]提出一种基于域名历史数据的异常域名检测算法,能够有效识别出具有一定生存时间的可疑域名,且该方法在历史数据足够多的情况下比较高效。文献[19-20]提出了用模糊模式识别技术来识别被管理网络中的僵尸,该技术通过DNS检测和TCP检测等步骤识别恶意域名和IP,但它使用的简易成员函数导致误报率高、实用性差。
分析发现,已有工作主要集中在恶意域名检测方面,而对生成的AGD属于哪种DGA研究较少。尽管文献[14]对这一方面进行了研究,实测发现该算法误报多且没有区分AGD的恶意性。另外,本文的研究对象是上层DNS流量经过基于词素算法[21]得到的AGD,而文献[14]中研究对象涉及的域名包括正常域名和DGA生成的域名。由于DNS缓存机制的存在,它会屏蔽终端用户查询相关域名的IP,即上层DNS流量无法看到终端用户信息,从而导致从终端用户角度出发分析客户端访问模式的相似性算法失效。本文算法不需要客户端查询记录,可以有效区分域名的恶意性并具有较高的检测精度。考虑到本文训练数据仅1万条而测试数据有100万条,相比之下训练样本较少,而SVM具有在训练过程中不需要太多的训练样本,即可实现较高精度的分类且能够处理高维的特征向量特点。鉴于其在本文的适用性,本文利用它过滤掉正常域名,并将其与C4.5、NN等分类算法对比,发现SVM算法具有较高的准确率。
3 方法介绍
本文的目标是辨识出攻击者利用域名生成算法生成的恶意域名。为了达到这个目标,本文首先辨识出同一DGA或其变体生成的域名聚类,然后针对每一个聚类集合,提取能够有效区分域名恶意性的特征,过滤掉正常的域名集合。
域名和域。一个域名由多个标签(点)拆分的字符串组成。最右部分为一个域名的顶级域名(TLD, top-level domain),然后是其二级域(2LD, second-level domain),依次类推。例如www. baidu.com,顶级域为com,二级域为baidu,三级域为www,而baidu.com为二级域名,其中,顶级域的标签不止一个,如.co.uk。
3.1 同一DGA生成的域名聚类
3.1.1 基于二分图的聚类
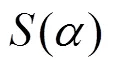

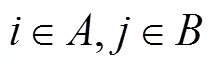
算法1 谱聚类算法对域名聚类

3.1.2 基于域名字面特征的聚类
本文通过分析流经中国教育科研网江苏省网边界的上层DNS解析流量发现,不同DGA生成的域名在字面上要么由随机英文字符组成,要么由全数字和数字、英文字符混合组成,甚至一些高级恶意代码使用的DGA可以生成一系列可读的域名(类似于英文单词)。本文分别统计了域名的-元特征、字符熵值、数字特征及有意义字符所占百分比,利用-means算法对这些域名进行聚类。
-元组特征。为了区分域名的可读性,本文分别提取每个域名对应2LD和3LD的两元、三元特征。针对每一域名的2LD和3LD,本文分别统计其两元、三元出现次数的平均值方差及中位数,平均值计算方法参考式(2),-元组提取详见算法2。

算法2-元统计值计算
输入 域名、、规范化后的英文字典
输出 域名中-元字符的统计次数
1) 提取域名的字符串,并插入容器
2) 构建字典树
3) 遍历字典树,统计在字典数出现的次数
4)+ =
5) return
熵值特征。为了进一步区分域名中字符的分布情况,本文计算每个域名2LD和3LD中所含字符熵的变化情况。不同DGA生成的域名所包含字符的熵值变化范围往往不一致,本文可以利用这个测度进行区分,如式(3)所示。
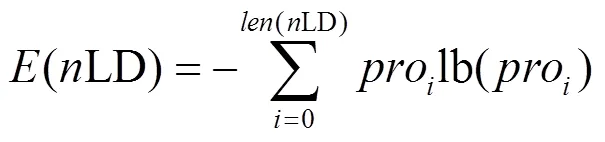
数字特征。同一DGA生成的域名具有较高的相似性,基于这个特点本文分别提取域名的长度特征、2LD和3LD的长度、域名中级域中的取值及域名2LD和3LD域中数字字符所占的百分比特征。




图3 AGD占测试数据集的比率
3.2 恶意域名识别
域名的TTL特征。DNS响应分组中包含TTL,记录了域名服务器将域名的解析信息保留在缓存中的最长时间。正常域名的值一般为1~5天[23],恶意域名为了提高其逃逸能力往往设置较短的值。统计分析样本数据中的正常域名和恶意域名的值发现,正常域名中大约30%的域名值大于1天,60%以上的域名值大于1 200 s;而恶意域名的值较小,通常小于500 s,大概占45%左右,而小于1 000 s的恶意域名更是占总量的70%以上。另外,正常网络服务为了减少开销,使用Round-Robin DNS和内容分发网络(CDN, content delivery network)实现负载均衡,其值也比较低,如阿里云盾的Challenge Collapsar/DDoS攻击防御方法使用DGA生成的域名为CDN使用。由于单一通过分析值区分域名的恶意性会产生较高的误报率和漏报率,因此需要与其他测度结合分析。本文分别提取域名的平均值、标准方差、的变化次数及变化范围的百分比作为区分测度。
域名的whois特征。whois是当前域名系统中不可或缺的一项信息服务,通过它可以知道域名的解析IP、注册人等相关信息。本文利用virustotal提供的API查询每个域名对应二级域名的whois信息,基于以往专家对域名的分析,正常域名的生命周期往往较长,且在这段时间内该域名提供的服务几乎都可以被访问,相比之下,botmaster使用随机算法或使用Flux技术注册的域名生命周期短,便于频繁切换和更新,可以提高其生存性和隐蔽性。另外,正常域名为了提高知名度,在注册时拥有较完整的注册信息,而恶意域名为了掩人耳目,注册信息随机且不完整。表1统计了virustotal官网域名whois的主要信息项及含义。本文提取域名的注册时间、到期时间、更新时间信息,并分析了whois信息的完整度,分别统计了正常域名和恶意域名的whois信息的完整度。统计发现,域名的whois信息项大概有50多条,其中93.28%正常域名whois信息项有30条左右,仔细分析发现Registrant的多数信息真实存在,而90%以上的恶意域名的whois信息小于20条且提供的注册信息可读性差。然后统计了域名注册时间的变化情况,发现87%以上的正常域名注册时间比较长,大概在5年以上,其中,60%还未更新;而90%的恶意域名注册时间短,低于3年且65%以上都已经到期,已经更新。同时还发现,正常域名伴随着生存时间的增长,域名更新次数较多,而大多数恶意域名的whois信息更新次数较少,因此可以有效区分。

表1 样本域名whois的主要信息项及含义
解析IP特征。为了逃避检测,攻击者采用多种逃逸技术,如Fast-Flux,确保其C&C控制器的存活性。此外,CDN也将其域名映射到多个IP上以实现负载均衡,但是CDN背后拥有的服务器通常是高性能的专用服务器,其IP长期稳定活跃,而Fast-Flux 感染的主机通常是普通用户且无法对其直接控制,这些IP短期活跃且不断更新。另外,CDN为了提高服务质量,减少用户访问时间,采用就近原则提供服务,其IP集合分布广且均匀,而Fast-Flux则不是这样,其IP分布比较发散。基于上述特点,本文分析正常域名和恶意域名的解析IP的使用位置、归属信息。研究发现,恶意域名的解析IP分布比正常域名发散,本文查询实验室的IP活动库获取其解析IP所在城市数、归属地数。根据IP所在城市数、归属地数,计算解析IP的使用位置及归属地熵值。熵值越大,位置越发散,越接近恶意域名。尽管Fast-Flux网络通过频繁切换IP逃避检测,但域名固定仍然难以避免单点失效,DGA通过生产大量域名,定位其C&C服务器,恰好弥补上述不足。反而言之,Fast-Flux网络的IP会映射到多个域名上,统计分析所有解析IP地址到域名的映射,其中,CDN中,每个解析IP反向映射到的二级域名数目超过39个的只有17.3%,而Fast-Flux网络中占42.5%;CDN中,每个解析IP地址反向映射的二级域名数目超过10个的仅有15.3%,而Fast-Flux网络却有45.4%[12]。由此看出,CDN中域名的解析IP地址到二级域名的映射数较少。本文还提取了逆向IP查询得到的IP到域名映射的数量作为一个测度,来区分CDN域名和Fast-Flux域名。
域名活动历史特征。本文采用基于网络的特征和基于IP黑名单的证据特征刻画域名的活动历史,其中,基于网络的特征描述分配给域名注册者的网络资源情况。研究发现,不法分子经常滥用其域名及IP资源,这些域名或IP通常表现为具有较短的生存时间和较高的切换频率,而正常用户的网络特征相对稳定。本文分别统计域名对应解析IP所属的BGP前缀和自制系统(AS, autonomous system)数,即BGP(D)、BGP(2LD)、BGP(3LD)、AS(D)、AS(2LD)、AS(3LD)数及这些BGP前缀归属的国家数。正常域名对应的BGP前缀、AS值较小,而诸如Fast-Flux等恶意域名由于常进行频繁的切换导致BGP前缀、AS值较大。另外,域名资源相对于IPv4地址资源比较便宜,不法分子通常重用已知的恶意网络资源,如IP地址、BGP前缀及AS等资源。本文分别统计域名对应解析IP地址A(D)、BGP(A(D))和AS(A(D))在Spamhaus Block List[24]上的数目,来刻画待检测域名与已知恶意域名或IP的关联程度,数目越多,关联度越高,越接近恶意域名。
待提取到所有特征后,构建特征向量,使用机器学习算法过滤掉不符合要求的域名。为了实现较好的性能而不至于过拟合,本文采用5折交叉验证方法对训练数据进行训练,本文的训练数据包括Alex前1万的域名及文献[7-11]提供的恶意域名,然后分别比较C4.5决策树、NN 、Bayesian Network和SVM等分类算法的测试结果,实验发现SVM算法具有较高的精度。
4 性能评估
本文所有实验均在一台两路Intel Xeon服务器上执行,每一路上具有一个Intel(R) Xeon(R) CPU E5-2650的处理器,每个处理器包含八核,主频2.00 GHz,内存为128 GB。算法的实现采用C++和Python语言,本文在Python中使用了NumPy包,并利用scikit-learn机器学习库构建机器学习模型。

4.1 系统概述
本节为恶意域名检测系统提供了一个全面概况,主要包括预处理、聚类模块及分类模块3个部分,如图4所示。

图4 AGD恶意域名检测系统概况
实测数据集。从2017年2月12日—26日在中国教育科研网江苏省网边界采集到的能够正确解析的DNS交互分组,大约100万的不同域名集合。本文的恶意域名检测算法是基于域名本身所呈现的特性进行的。恶意域名本身的活动是一种特殊应用,这种应用无论在教育网还是商业网所呈现的流量特征是一样的。流量特征的不同和用户行为有关,而用户行为和网络中的应用是相关的[25]。不同的网络应用,呈现的流量特征也不尽相同,所以说本文的算法和结论可以用于大规模商用网络。
训练数据集。正常域名集,本文选取Alex网站连续三次排名前1万的域名集合(每月观测一次,从而保证其排名的稳定性),但由于Alex 网站只提供二级域名,为了获取完整的域名,本文从实测域名集获取与上述域名具有相同“二级域名标签”的域名构成合法样本集。恶意域名集合,本文选取僵尸网络、钓鱼网站、垃圾邮件和恶意软件等恶意域名,针对这些域名中没有三级域名标签的域名,本文采用与正常域名集相同做法构成恶意样本集。
预处理模块。提取DNS响应分组,剔除DNS查询不成功的域名,然后利用域名、IP及不合法域名后缀黑名单对实测数据进行过滤,过滤掉已知恶意的域名。
聚类模块。分别将映射到相同解析IP地址集合的域名聚类和域名字面特征相近的域名聚类,分析2种聚类聚合的Jaccard index得分,识别同一DGA或其变体生成的域名。
分类模块。提取域名的TTL、whois更新、完整性特征、解析IP分布、归属等特征,利用SVM算法过滤掉正常域名。
4.2 聚类灵敏度及算法精度评估


图6 不同特征组合下准确率
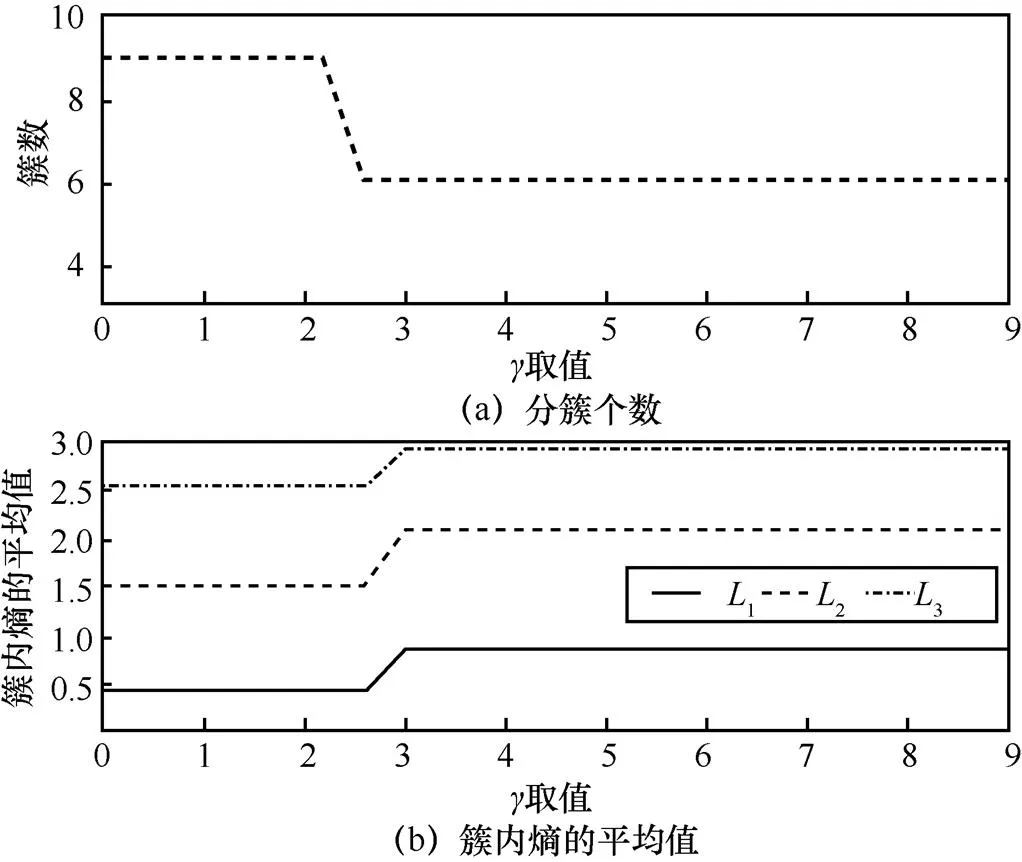
图5 聚类灵敏度参数取值分析
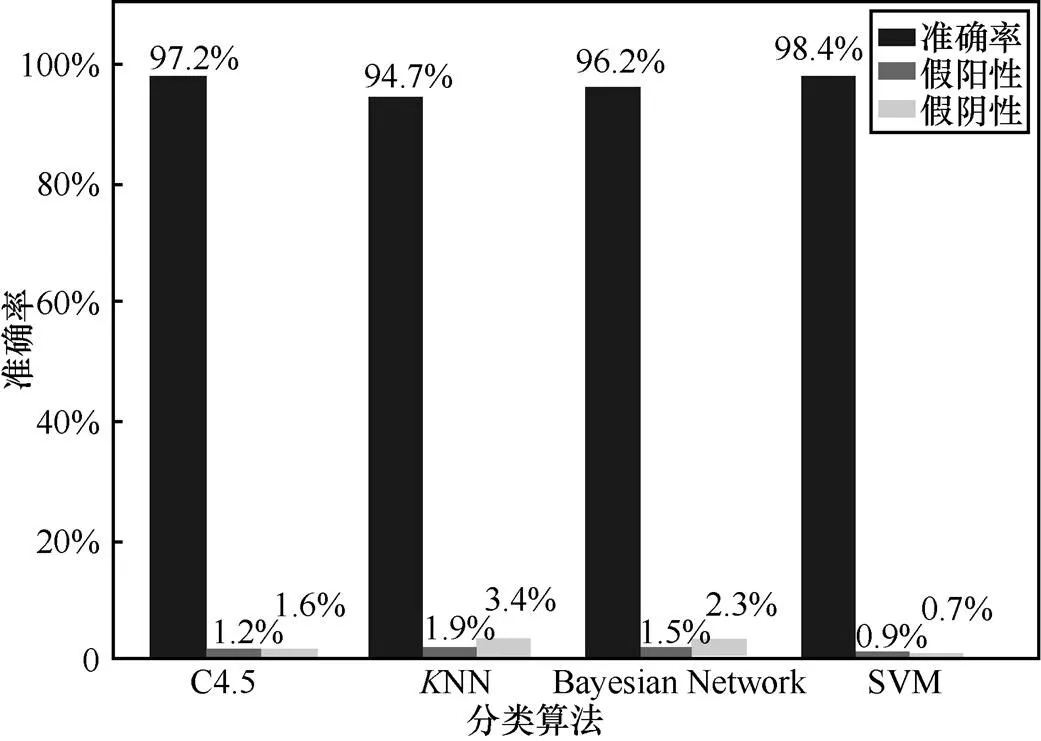
图7 不同分类算法的准确率
4.3 监控窗口与准确率的关系
为了有效区分恶意域名,本文统计监控时间与准确率的关系。一般而言,监控窗口越长,信息越全,准确率越高,相反准确率降低。但是当窗口足够大时,数据量庞大,就会影响系统性能。为此本文考虑准确率与性能的权衡,重复上述实验,选择合适的监控窗口。本文在保持数据集不变的情况下,设定监控窗口为(3, 5, 8, 10, 13, 15)天,从准确率、假阳性和假阴性3个方面评估算法的检测精度。实验发现,算法的准确率随着观测窗口的长度增加而增大,但幅度不大。相应地,假阳性和假阴性有所减小,如图8所示。

图8 准确率与监控窗口的关系
当观测时间长度从3天增加到8天后,检测准确率从 94.6%上升到97.8%,假阳性从 2.5%下降到 1.2%,假阴性也从2.9%下降到1.0%。当窗口继续增大时,准确率有所下降。进一步实验,本文设置第8天作为初始窗口,此时的准确率等同于窗口等于3的结果。本文观察一周的准确率变化情况,发现在第15天的准确率达到98.4%,所以在实测过程中设定观测窗口为7天。
4.4 实测分析
完成训练后,利用本文提取的测度对实测数据进行检测发现,5 142个可疑二级域名标签,进一步分析发现,其中507个二级域名所辖子域名出现于域名黑名单中。然后通过McAfee Site Advisor交叉验证剩余域名发现,4 375个域名为恶意域名,剩余260个域名中121个域名无法正常访问,107个域名对应于合法域名为误报。实测分析算法准确率可达到97.84%,误报率为0.88%,召回率为77.5%,值为86.5%,符合的训练结果。针对这些恶意域名本文进一步分析其对应的三级标签及解析IP,研究发现3 678个为DGA域名,709个存在Fast-Flux特性,剩余的域名部分为Spam和成人网站作为媒介进行恶意企图。
4.5 对比分析
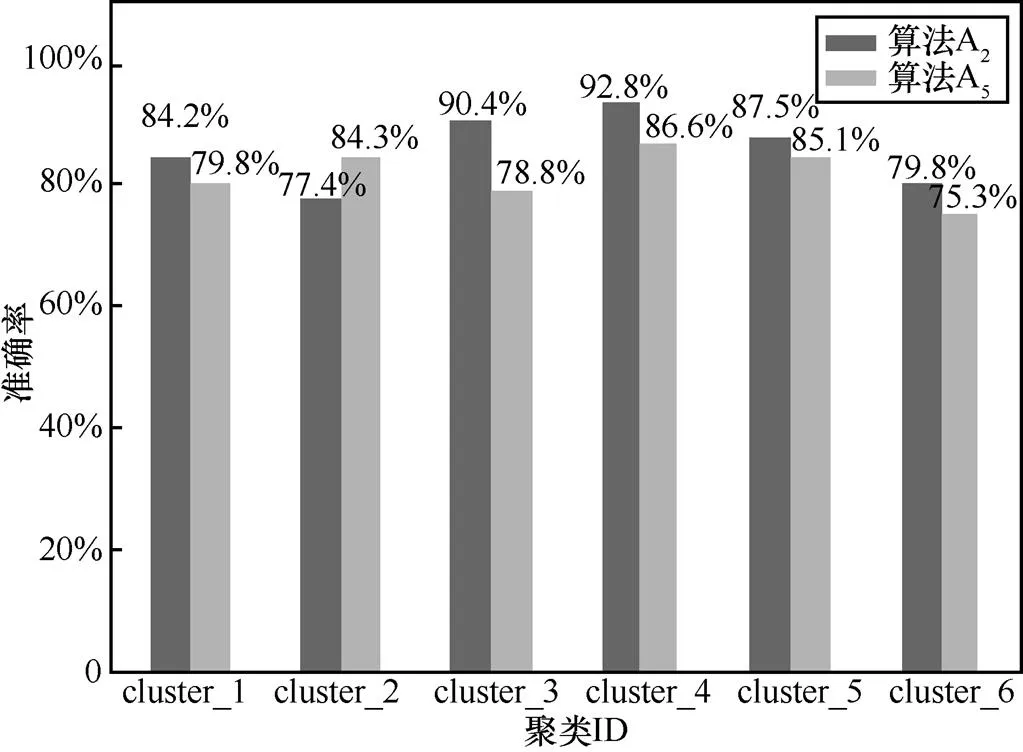
图9 AGD识别准确率
实验发现,本文算法准确率较高,漏报率相对较低,优于文献[14]。然后将本文算法(A2)分别与算法(A3)[12]、算法(A1)[23]和算法(A4)[11]进行比较,分析在恶意域名检测方面的准确率和性能。实验发现本文算法与其他算法相比,准确率、假阳性、假阴性、召回率、值指标明显优于其他算法,这充分说明本文聚类和分类相结合的算法在分析AGD的恶意性方面更加有效,如图11所示。
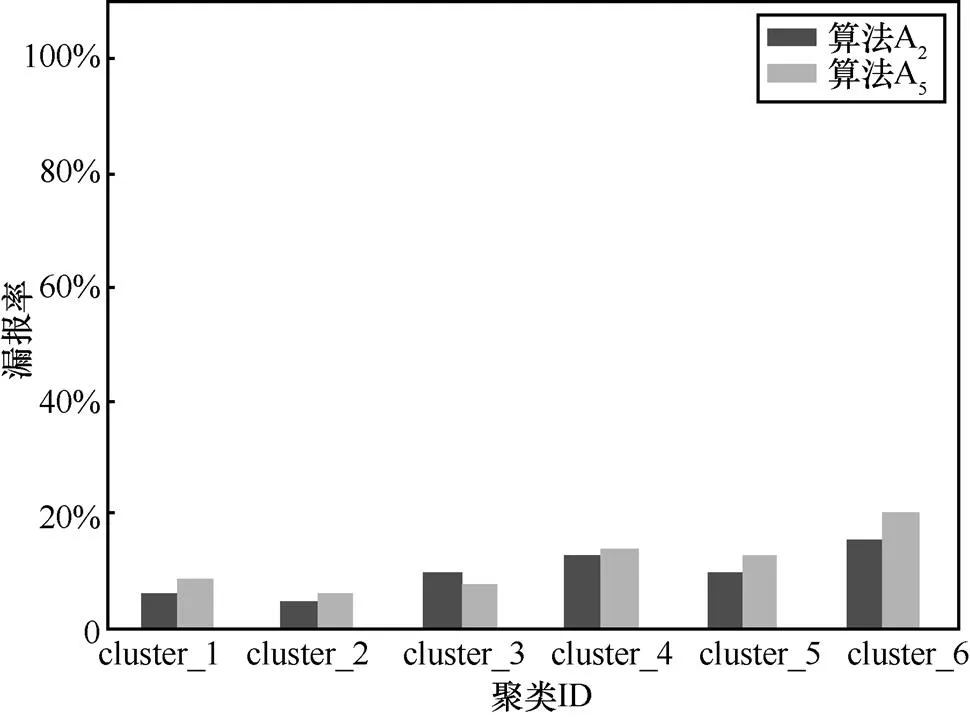
图10 AGD识别漏报率
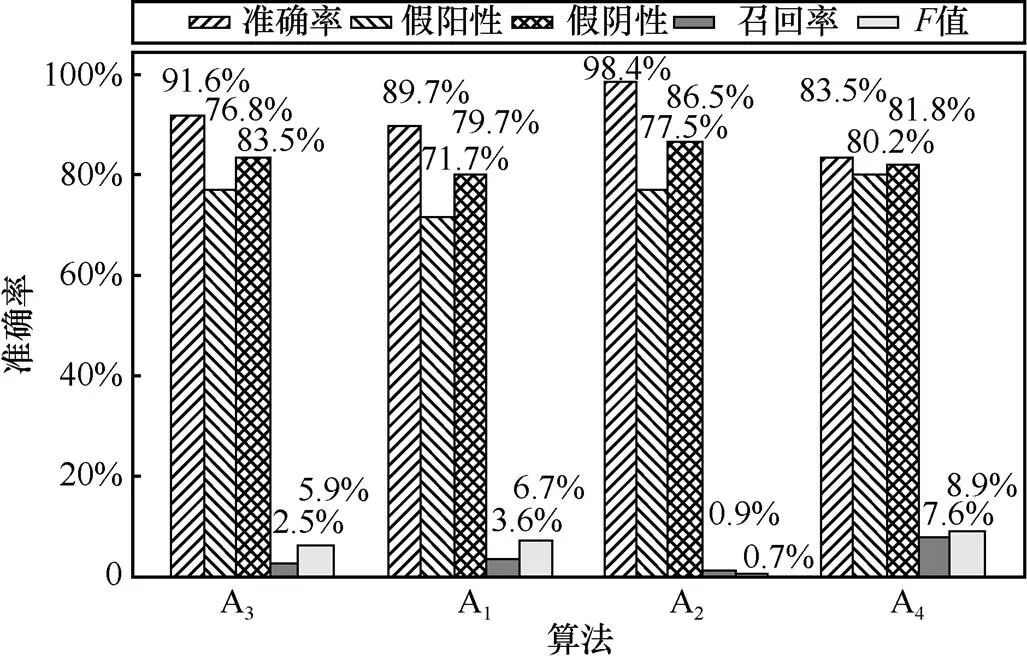
图11 不同检测算法准确率
最后,本文分析了上述算法的系统开销。本文主要通过virustotal官网API获取whois信息,为了避免网络爬虫,virustotal官网对其API的API-key进行了限制,一定程度上影响了系统性能。为了减少运算开销,本文在实验过程中将获取的whois信息存入MySQL数据库,重新执行本文算法。与其他算法相比,本文算法性能开销略微较大,但相差不大,另外,本文算法具有较高的检测精度,这充分说明,尽管本文算法不能完全取代其他检测算法,但一定程度上可以作为其他算法的补充,在运算开销几乎和其他算法差不多的情况下,可以准确地进行恶意域名辨识。不同检测算法的开销评估如表2所示。
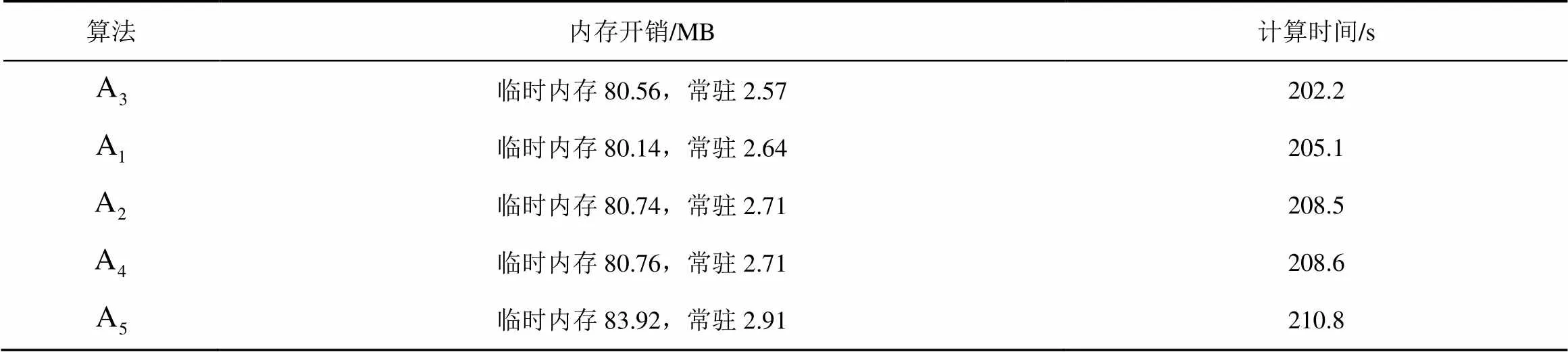
表2 不同检测算法的开销评估
5 结束语
作为互联网的重要基础设施,DNS在提供便利的同时,日益被攻击者利用来从事一些非法活动。本文设计了一种新的恶意域名检测方法,首先,定义不同的相似度标准,分别对域名聚类,利用Jaccard index分析不同聚类集合的关联性,辨识出同一DGA或其变体生成的域名,这是本文工作的一个特色,也是与其他工作的不同之处。其次,提取一些新的检测测度,并充分与其他特征相结合,对每一个聚类集合中的域名进行分类,过滤正常域名。实验发现,在不需要分析客户端IP对域名的查询记录及用户规模的情况下,本文算法便可有效区分出AGD中的恶意域名。与现有工作相比,本文算法在检测精度和检测效率方面有了很大提升。本文下一步的工作考虑设计实时性的恶意域名检测算法及恶意代码意图分析以实现秒级的响应。
[1] 江健, 诸葛建伟, 段海新, 等. 僵尸网络机理与防御技术[J].软件学报, 2012, 23(1): 82-96.
JIANG J, ZHUGE J W, DUAN H X, et al. Research on botnet mechanisms and defenses[J]. Journal of Software, 2012, 23(1): 82-96.
[2] YADAV S, REDDY A, REDDY A, et al. Detecting algorithmically generated malicious domain names[C]//The 10th ACM SIGCOMM Conference on Internet Measurement. 2010: 48-61.
[3] STONE G B, COVA M, CAVALLARO L. Your botnet is mybotnet: analysis of a botnet takeover[C]//ACM Conference on Computerand Communications Security (CCS).2009:635-647.
[4] DANIEL P, KHALED Y, MICHAEL K, et al. A comprehensive measurement study of domain generating mal-ware[C]//The 25th USENIX Security Symposium. 2016: 263-278.
[5] WANG T S , LIN H T , CHENG W T, et al. DBod: clustering and detecting dga-based botnets using DNS traffic analysis[J]. Computers & Security, 2017, 64:1-15.
[6] BILGE L , KIRDA E , KRUEGEL C , et al. Exposure: finding malicious domains using passive DNS analysis[C]//NDSS. 2011:1-17.
[7] ANTONAKAKIS M, PERDISCI R, NADJI Y. From throw-away traffic to bots: detecting the rise of DGA-Basedmalware[C]//Usenix Conference on Security Symposium.2012:24-40.
[8] SHARIFNYA R, ABADI M. DFBotKiller: domain-flux botnet detection based on the history of group activities and failures in DNS traffic[J]. Digital Investigation,2015,12(12):15-26.
[9] KHEIR N, TRAN F, CARON P, et al. Mentor: positive DNS reputation to skim-off benign domains in botnet c&c blacklists[C]//IFIP International Information Security Conference.2014:1-14.
[10] MANOS A, ROBERTO P, DAVID D, et al. Building a dynamic reputation system for DNS[C]//The 19th USENIX Security Symposium (USENIX Security’10). 2010:273-290.
[11] ANTONAKAKIS M, PERDISCI R, LEE W, et al. Kopis: detecting malware domains at the upper DNS hierarchy[C]//Usenix Conference on Security. 2011.
[12] 张维维, 龚俭, 刘尚东, 等. 面向主干网的 DNS 流量监测研究[J]. 软件学报, 2017, 28(9): 2370-2387.
ZHANG W W, GONG J, LIU S D, et al. DNS surveillance on backbone[J]. Journal of Software ,2017,28(9):2370-2387.
[13] THOMAS M, MOHAISEN A. Kindred domains: detecting and clustering botnet domains using DNS traffic[C]//Companion Publication of the International Conference on World Wide Web Companion. 2014:707-712.
[14] STEFANO S, FEDERICO M, LORENZO C, et al. Phoenix: DGA-based botnet tracking and intelligence[C]//International Conference on Detection of Intrusions& Malware.2014: 192-211.
[15] CELIK Z B, OKTUG S. Detection of fast-flux networks using various DNS feature sets[J]. Computers&Communications,2013:868-873.
[16] HUANG S Y, MAO C H, LEE H M. Fast-flux service network detection based on spatial snapshot mechanism for delay-free detection[C]//5th International Symposium on ACM Symposium on Information, Computer and Communications Security .2010: 101-111.
[17] ALMOMANI A. Fast-flux hunter: a system for filtering online fast-flux botnet[J]. Neural Computing& Applications, 2016: 1-11.
[18] 袁福祥, 刘粉林, 芦斌, 等. 基于历史数据的异常域名检测算法[J].通信学报, 2016, 37(10): 172-180.
YUAN F X, LIU F L, LU B, et al. Anomaly domains detection algorithm based on historical data[J]. Journal on Communications, 2016, 37(10): 172-180.
[19] WANGA K C, HUANGB C Y, LIN S J, et al. Fuzzy pattern-based filtering algorithm for botnet detection[J]. Computer Networks, 2011, 55(15): 3275-3286.
[20] WANG K, HUANG C Y, LIN S J, et al. A fuzzy pattern-based filtering algorithm for botnet detection[J]. Computer Networks the International Journal of Computer & Telecommunications Networking, 2011,55(15): 3275-3286.
[21] 张维维, 龚俭, 刘茜, 等. 基于词素特征的轻量级域名检测算法[J].软件学报,2016,27(9):2348-2364.
ZHANG W W, GONG J, LIU Q, et al. A Lightweight domain name detection algorithm based on morpheme features[J]. Journal of Software, 2016,27(9):2348-2364.
[22] LIN H T , LIN Y Y, CHIANG J W . Genetic-based real-time fast-flux service networks detection[J]. Computer Networks, 2013,57(2): 501-513.
[23] BILGE L, SEN S, BALZAROTTI D. Exposure: a passive DNS analysis service to detect and report malicious domains[J]. ACM Transactions on Information and System Security (TISSEC),2014,16(4):14-41.
[24] SHI Y, CHEN G, LI J T. Malicious domain name detection based on extreme machine learning[J]. Neural Process Letters,2017: 1-11.
[25] LI B D, SPRINGER J, BEBIS G, et al. A survey of network flow applications[J]. Journal of Network and Computer Applications, 2013, 36(2): 567-581.
Detecting malicious domain names based on AGD
ZANG Xiaodong1,2,3, GONG Jian1,2,3, HU Xiaoyan1,2,3
1. School of Cyber Science and Engineering, Southeast University, Nanjing 211189, China 2. Jiangsu Provincial Key Laboratory of Computer Network Technology, Southeast University, Nanjing 211189, China 3. Key Laboratory of Computer Network and Information Integration of Ministry of Education, Southeast University, Nanjing 211189, China
A new malicious domain name detection algorithm was proposed. More specifically, the domain names in a cluster belonging to a DGA (domain generation algorithm) or its variants was identified firstly by using cluster correlation. Then, these AGD (algorithmically generated domain) names’ TTL, the distribution and attribution of their resolved IP addresses, their whois features and their historical information were extracted and further applied SVM algorithm to identify the malicious domain names. Experimental results demonstrate that it achieves an accuracy rate of 98.4% and the false positive of 0.9% without any client query records.
network security monitoring, domain generation algorithm, command and control server, algorithmically generated domain
TP393
A
10.11959/j.issn.1000−436x.2018116
The National Natural Science Foundation of China (No.61602114)
2017−10−09;
2018−06−21
国家自然科学基金资助项目(No.61602114)
臧小东(1985−),男,山东济宁人,东南大学博士生,主要研究方向为网络安全、网络管理。

龚俭(1957−),男,上海人,博士,东南大学教授、博士生导师,主要研究方向为网络安全、网络管理。
胡晓艳(1985−),女,江西金溪人,博士, 东南大学讲师,主要研究方向为网络体系结构、网络安全。

猜你喜欢
中学生数理化·高一版(2021年4期)2021-07-19 09:00:56
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
语文世界(小学版)(2018年3期)2018-03-22 17:50:54
计算机与网络(2018年10期)2018-02-15 09:06:37
商周刊(2017年12期)2017-06-22 12:02:01
摄影之友(影像视觉)(2016年2期)2016-08-16 06:43:16
中国知识产权(2015年9期)2015-05-30 10:48:04
