
声音-图像的跨模态处理方法综述
2018-08-02 06:15:50郑婉蓉谢凌云
中国传媒大学学报(自然科学版) 2018年4期
郑婉蓉,谢凌云
(中国传媒大学 传播声学研究所,北京100024)
1 引言
传统的声音信号(无论是乐音还是语音)处理中,一般都是获取一维的波形数据,进行与声音有关的特征分析或数字信号处理。同样地,在图像信号处理中,所采用的特征和方法也是直接和二维图像相关的。这两种视听觉模态的输入信息,一直以来都是在各自的领域进行独立的研究。近年来,视听交互和融合的心理感知现象在视听觉的信号分析领域得到越来越多的重视,研究人员的分析视角也逐渐地从一维声音信号和二维图像信号的独立分开处理转向创造性的跨模态处理。声音(图像)的信号处理方法,被运用到另一模态的图像(声音),从而试图从一个模态上挖掘有用的信息后再应用到另一个模态上。其中最重要的中介就是语谱图。
语谱图将声音的频谱随时间变化的信息展现在一个二维平面图上,其中横轴是时间,纵轴是频率,某一点处颜色的深浅代表了对应时刻和频率的信号能量大小,也被称为声谱图(spectrogram)。它虽然反映了声音信号的特征,但是却和二维图像具有相同的属性。以它为中介,可以完成图像到声音和声音到图像的双向转换,达到跨模态处理的目的。
本文接下来一方面介绍了从语谱图的角度进行声音分类的研究内容及进展情况,包括用于音乐流派分类图像特征类型及其分类的精确度,对普通声音事件分类的方法及其结果。另一方面对图像到声音的相互转换及关系等相关工作进行了介绍,包括通过修改声音来改变图像或者通过图像处理来改变声音等。同时提出了基于语谱图的图像处理重建语音,以达到语音增强目的的处理方法。
2 基于语谱图像的声音信号分类研究
信息时代早期以来,数字音乐已成为消费类型最多的媒体之一,对于音乐数据的自动分析相应的越来越重要。音乐流派是人类为确定音乐风格而创建的分类标签,是提高音乐检索的一个重要描述信息。传统音乐流派分类的方法大多都以音乐信号为基础,近几年来,相当一部分关于音乐的自动流派分类工作大部是基于内容的,即从数字音频信号中提取有代表性的短时音频特征,较为频繁使用的特征中有音色、节拍、音高等,再利用模式识别以及分类算法处理特征达到音乐流派分类的目的。例如Tzanetakis[1]根据声音的音色、节奏、韵律、MFCC系数等特征对10个音乐流派进行分类,达到了61%的分类识别率。国内外有相当一部分研究如Kosina、Grimaldi都做了类似的工作。2011年Costa[2]提出了一种新的音乐流派分类方法。
Costa提出的音乐流派分类方法是将声音信号的时频表示转换为纹理图像,提取图像特征来构建新的音乐流派分类系统。具体是将音频信号转换为语谱图,然后从视觉表示中提取特征,对图像特征向量进行训练分类,从而达到音乐流派分类的目的。音乐信号可能包括类似的乐器和类似的节奏模式,使得语谱图图像中有相似区域。通过对图像进行分区,提取出局部特征信息,获得每种音乐流派的突出特点再进行分类。
接着,Costa又利用灰度共生矩阵(Gray-Level Co-occurrence Matrix,GLCM)来对音乐信号进行分类训练,GLCM是特定空间(包括距离和角度)中两个灰度出现的联合概率分布,得到的结果与Lopes[3]的结果相比,分类正确率提高了7个百分点。
2012年,Costa[4]从语谱图提取了图像特征:灰度共生矩阵和局部二值模式(Local Binary Patterns,LBP)。LBP是用来描述图像局部纹理特征的算子,它反映的内容是每个像素点与其周围像素点的对比信息,或者说差异。结果表明用LBP训练的SVM分类器能够实现80%的识别率,优于用GLCM训练。具体见表1。
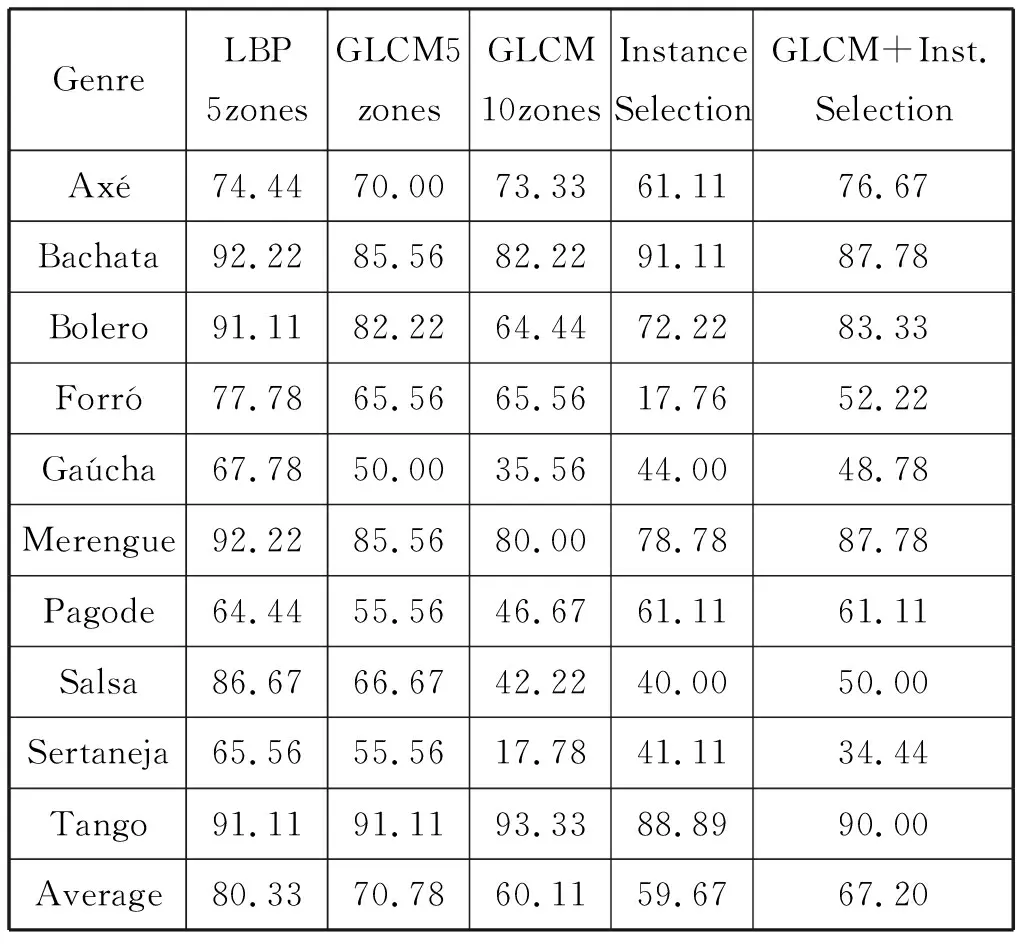
表1 流派分类的结果对比
2013年Costa[5]进一步利用Gabor滤波器和LPQ(Local Phase Quantization,局部相位量化)描述符来表示图像纹理特征,得到新的音乐流派分类识别率。Gabor函数是一个用于边缘提取的线性滤波器。Gabor滤波器的频率和方向表达同人类视觉系统类似。用LPQ训练的SVM分类器达到高于80%的识别率。结果参见表2和表3。
实验的过程方法都是类似的,数据集使用的是LATIN MUSIC DATABASE(LMD),图像取自歌曲前中后三个片段的语谱图,分别采用全局和局部两种特征进行训练分类,训练分类使用了三重交叉验证。
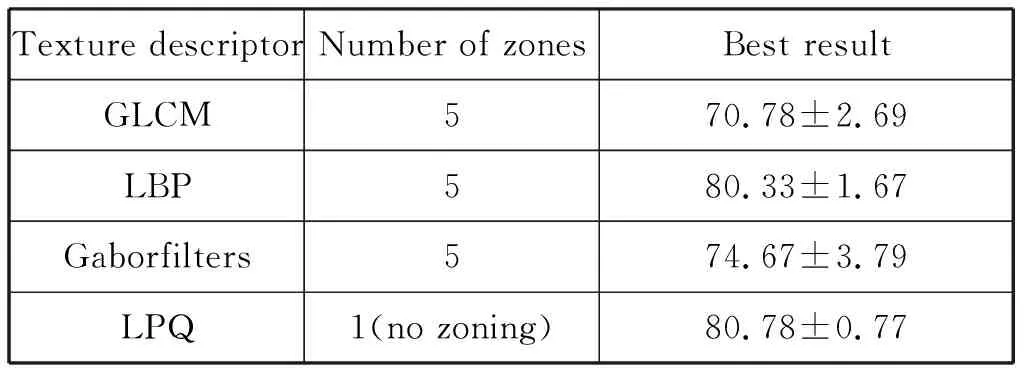
表2 不同图像特征的结果对比
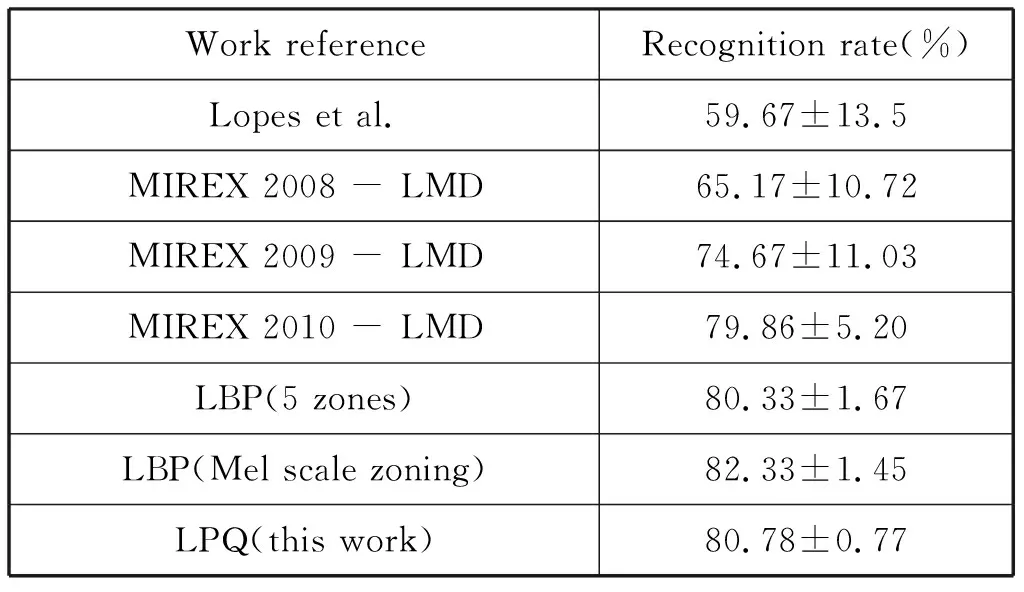
表3 不同图像特征的结果与传统方法及比赛结果对比
由结果可以看出,提出的基于语谱图图像特征的方法表现出了良好的分类效果,特别是LBP和LPQ,存在的不足是使用的特征向量维数过多,造成计算时的冗杂,例如LBP的特征向量唯独为59。因此在优化识别率的基础上,算法效率也需要加强。
声音事件通常具有更独特的时间频率表示,能量集中在少量的频谱分量上。这使得它们更适合于基于它们的视觉特征进行分类,因此可以从图像处理的相关领域中得到启发。2014年,Dennis[6]介绍了最近6种根据语谱图进行声音事件分类的方法,包括一个基于帧的直方图特征(Histogram of Oriented Gradients,HOG),三个全局特征语谱图图像特征(Spectrogram Image Feature,SIF)、子带功率分布图像特征(Subband Power Distribution Image Feature,SPD-IF)、声谱缝模式(Spectrographic Seam Patterns,SSP),两个局部特征包括时频有序BOVW(Ordered Spectro-Temporal Bag-of-Visual-Words)和尺度不变特征变换BOVW(SIFT BOVW)。Dennis分析了这6种方法在对50种不同环境声音中的表现的性能,声音数据来自RWCP(Real Word Computing Partnershi),所选择的声音事件涵盖了广泛,包括木制,金属和瓷器撞击,摩擦声以及其他声音如铃声,电话和哨声等。使用了NOISEX’92中的语噪、工厂噪声、飞机驾驶舱噪声作为环境噪声。表4给出在不同方法在声音事件分类任务中的效果比较。
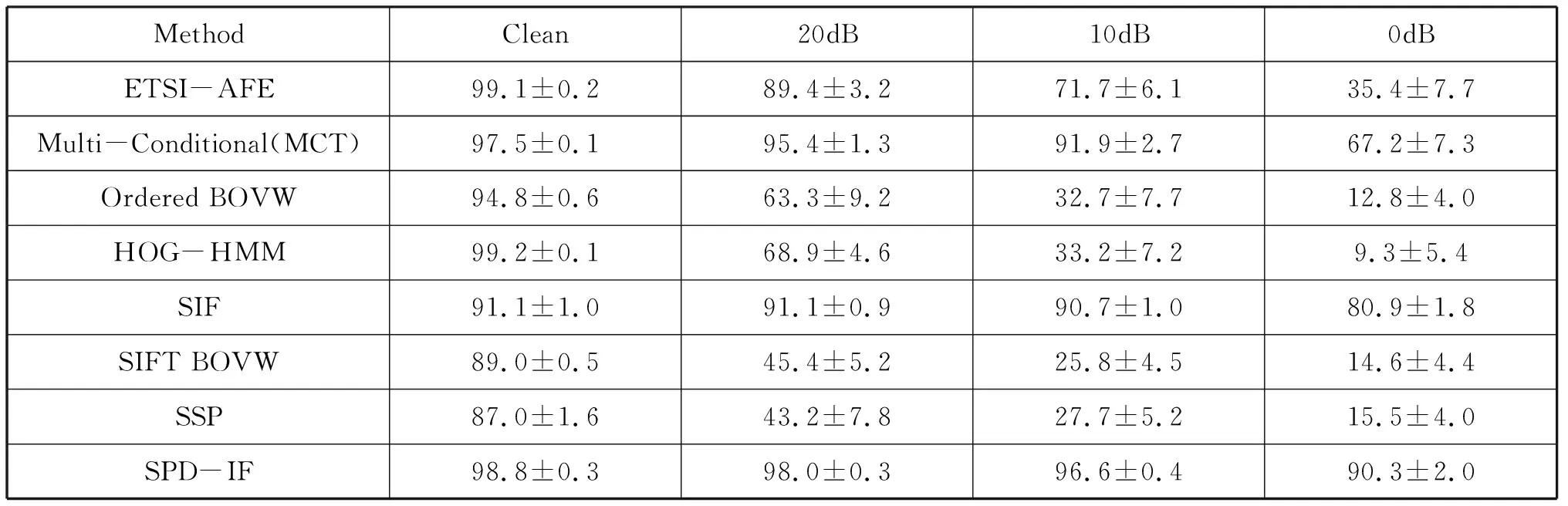
表4 不同声音分类方法结果对比
其中ETSI Advanced Front End(AFE)和Multi-Conditional Training(MCT)是基于帧的MFCC-HMM系统,两个分类系统都使用基于39维的基于帧的MFCC特征,后六个方法是基于语谱图图像处理方法的。使用有序BOVW方法的性能明显优于无序SIFT BOVW技术。整体性能表现最好的方法是SPD-IF,SPD-IF方法是通过频谱图的子带分布捕获时间信息,与SIF相比,信号和噪声信息在SPD表现中更容易分离。SPD方法没有精确捕获声音中时间信息的排序,但它可以为特征提取提供一个鲁棒和区分性的基础,优于现有MCT技术。总的来看将语谱图信息结合到特征中对于声音事件分类是有益的。
3 图像与声音的相互转换
3.1 从图像到声音
Kawamura[7]在2016年发表在《applied acoustics》上的文章里讨论了关于“图像-声音-图像”的变换方法。他把一般图像视为某个声音的语谱图进行处理,将任意的图像进行IFFT变换得到一个一维的声音数据,对该声音数据进行相应的音频信号处理,如延时、滤波、改变相位等技术来修改声音,再将一维的声音数据进行FFT,得到产生相应改变的语谱图图像,具体过程如图1。

图1 图像-声音-图像的转换
图像经过IFFT后得到声音,对声音进行的基本运算,包括乘、延迟、叠加等。结果发现乘法算子可以改变信号幅度,由此改变图像的明亮度。信号乘的系数越大,重建图像亮度越高。时域延迟会使图像右移,特定情况图像会减损。声音叠加时,相位对结果影响很大,当且仅当两信号相位相同时,信号相加得到的频谱(图像)也是相加的,否则图像会产生失真。作者还对声音进行了常见的音频信号处理,经过不同类型的滤波器(高通、低通、带宽)后恢复的图像有相应不同的遮挡效果,经过FIR或IIR滤波器后恢复的图像有延迟重叠效果,陷波滤波器可以产生宽度和位置可变的黑线条。脉冲声经过图像重建产生竖直线;正弦信号则显示水平线,这与傅里叶变换结果一致。
以上的研究把图像与声音信号处理之间关联起来,采用声音信号处理的方法来改变图像。实际应用上也可以借此利用通感,让盲人经过训练后,通过声音来感受图像的变化。这种思维角度值得进一步研究。
3.2 从声音到图像
基于以上研究,我们提出了一种新的基于谱图的语音增强方法。其主要思想是将带噪语音声音经过STFT之后得到语谱图数据,将语谱图转换成灰度图像后,对其进行图像处理后再进行逆短时傅里叶变换得到重建的声音。实验中采用的方法均基于灰度变换(Gray-Scale Transform,GST)。GST是对图像像素直接进行处理,可以根据实际需要来扩展或者压缩灰度,起到图像增强的作用。实验主要采用了两种灰度变换方法,一种是gamma变换,一种是对比度拉伸。
实验语料采用IEEE语料库中的10个句子,每个句子7~12个单词。噪声类型选择了3种,分别为白噪声、speech-shaped noise和babble噪声。所有信号设置采样率16kHz,16位深度。噪声和语音设置了3种信噪比:-5dB,0dB,5dB。图像处理方法使用了gamma变换和对比图拉伸两种,并使用维纳滤波、谱减以及最小均方误差估计三种传统增强方法作为对照。
经过图像处理方法重建的语音以及经过传统方法增强语音不同方法处理后得到的语音后,分别对处理后的语音进行信噪比(SNR)、分段信噪比(SEG-SNR)以及主观语音质量评估(PESQ)的计算,并对结果进行分析,其中PESQ的结果见图2。

图2 不同语音增强方法下的PESQ
PESQ是 ITU-T P.862建议书提供的客观MOS值评价方法。如图2所示,在PESQ的表现上,图像处理方法的去噪效果明显好于传统方法。传统去噪方法信噪比越低,对PESQ提升的效果越差,而图像处理方法对PESQ的提升则相对稳定。
SNR是语音信号的整体信噪比,从长时信噪比的提高的结果上来看,通过图像处理方法重建的声音虽然相对于原始加噪语音有所提升,但相比于传统方法没有表现出明显的优势,在SNR为5dB的情况下表现稍差,其他情况与传统方法的效果近似。SEG-SNR是对信号的每一帧进行计算得出的平均信噪比值。图像处理方法在这个参数的表现上相对传统方法没有优势。
由于不同的窗口大小得到的语谱图具有不同的时间分辨率和频率分辨率,考虑的到这种特性可能会影响GST方法的结果,在实验中用分别使用了6种大小的窗长64/128/256/512/1024/2048进行了测试,发现窗口大小对增强语音质量没有显著影响。
这种声音到图像的映射方法,连接了图像信号处理方法和声音数据。在这种情况下,时间的维度在声音处理中消失,被引入到图像处理中,形成了图像二维矩阵的一个维度。从一个新的角度去处理问题,得到了意想不到的效果,这对声音的处理有了新的启发。
4 结论
利用语谱图的图像特征对音乐流派或声音事件进行分类具有良好的效果;通过修改声音可以达到改变图像特征的目的;实验证明了从图像角度来处理数据可以达到语音去噪效果。这种声音-图像跨模态的处理思想,连接了图像处理技术和声音处理技术。从声音被识别为图像或图像被识别为声音的全新视角来看待视听觉信号处理,这种新的方法会为数字信号处理中的跨模态研究提供新的思路,也能够帮助视听交互心理感知研究的量化建模。
猜你喜欢
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
小型微型计算机系统(2019年9期)2019-09-09 03:38:42
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
电子制作(2018年18期)2018-11-14 01:48:20
吉林大学学报(信息科学版)(2018年3期)2018-06-13 10:36:38
中国公共安全(2017年8期)2017-10-13 08:12:21
中国公共安全(2017年8期)2017-10-13 08:12:20
东北师大学报(自然科学版)(2017年2期)2017-06-13 10:43:55
