
基于词义消歧的短文本情感分类方法研究
2018-08-01 01:09:56金保华周兵王睿殷长魁
现代计算机 2018年20期
金保华,周兵,王睿,殷长魁
(郑州轻工业学院,郑州 410002)
0 引言
随着互联网的发展和普及,其影响已经深入到了人们的日常生活,对人们的生活方式也产生了巨大的影响。网络空间已经成为人们获取知识和信息的重要渠道,同时,也是人们表达自己的情感观点的集散地和社会事件舆论信息的放大器。例如:微博,跟帖评论等。如何对这些承载着情感信息的网络文本进行情感分类,有利于了解和掌握社会事件舆情的动态。
面对这些数据量如此庞大的文本信息,以人工的方式对它们识别分类,这显然是不现实的,因此就需要一种智能的方法代替人工来处理这种事情。文本信息的情感分类研究是一项新的研究领域,它包含人工智能、计算机语言学、机器学习、信息挖掘等学科内容。近年来,关于文本情感信息分类的研究已经取得了长足的进步。
1 相关研究
基于文本的情感倾向分析是一个多学科相互交叉的研究工作,它包含人工智能、数据挖掘、信息检索等多个领域和学科。自21世纪初,Pang[1]提出了有关文本情感倾向分析的概念后,不少的学者都对此问题进行了卓有成效的研究。Hinton[2]于2006年提出了深度学习的方法,随后,深度学习方法在计算机语音与图像识别领域得到了广泛运用,并且取得了不错的研究效果,于是越来越多的学者和研究人员,在借鉴了该方法在其他领域的成功经验,将其应用于文本情感倾向分析判断的研究中。
目前为止,常用的文本情感分析方法是基于机器学习的情感分类分析方法,该类分析方法又可以分为支持向量机(SVM)、最大熵(ME)、朴素贝叶斯分类器(NB)、k-最邻近(kNN)等方法。虽然以上方法可以有效地促进情感倾向分析的准确率,但是这些方法在对文本进行分析之前,需要对文本预处理,例如,对文本信息的预处理、分词、特征提取等步骤和过程,这些过程对文本情感倾向分析的准确率,起着至关重要的作用。由于需要对文本信息进行过多的人工预处理,而且还忽略了词义之的关系,费时费力。因此选用一种减少人工预处理的方法,对现在不断飞速扩展的互联网文本信息的处理,就显得尤关必要了。
词义消歧是自然语言处理中一项重要的工作,同一个的词汇在不同的语境之下含义不同的现象在自然语言的语境中普遍存在,所以消除词汇之间的歧义,在文本情感倾向分析中,有着至关重要的作用。为了获取文本内容向下文相关联的文本特征信息,Graves[3]提出一种BLSTM模型,该模型采用双向的LSTM(长短时记忆网络)对文本信息和特征进行双向识别。Zhou[4]介绍了带注意力机制的BLSTM模型,该模型能够在没有太多干预的情况下依靠自己来获取文本特征信息。在2014年,学者Kim[5]提出了一个新的文本情感分类模型,它利用卷积神经网络模型(CNN),对提取到的文本数据特征进行处理操作,该模型中运用两个大小不同的过滤器,作为一个分布式的文本特征提取器,被应用于文本情感分类模型中。
本文采用了一种基于卷积神经网络和词义消歧的结构模型,大大减少了以人工的方式对文本进行预处理,利用有关数据集对模型进行一定量的训练后,再进行文本情感倾向的分析。实验结果表明,该方法模型在减少人工预处理的工作之后,仍然能取得良好的结果。
2 卷积神经网络与词义消歧模型
2.1 词向量
为了实现计算机能够有效地识别和处理现实生活中的文字文本信息,就需要找到一种计算机能够识别的合适的对文本内容信息结构化表示的方法,向量空间模型(Vector Space Model,VSM)是现在最常用的文本表示方法,它是在20世纪60年代末,由哈佛大学的Gerard Salton[6]首先提出的,该表示方法模型最早被应用于Smart信息检索系统上。在这个模型中,每一个文本都被映射成多维向量中的一个点,以向量的形式给出。将这些向量集合在在一起,于是就形成一个文本的向量空间。
例如,对于给定的文本 D,其中包含单词集W(w1,w2,…,wm),提取到文本的特征集 K(k1,k2,…,kn),m是文本中的单词个数,n是表示提取到的文本特征个数。第 j个单词提取到的 i个文本特征表示为对文本信息做词向量化处理:

其中,rw是词 w向量的向量表示,Wword∈Rl×||m表示文本的词向量矩阵。
两个文本向量在它们的空间上的距离称之为它们的相似度。文档 d1和文档 d2向量在空间上的夹角余弦值称之为文档在该空间上的相似度,其向量余弦值定义为:
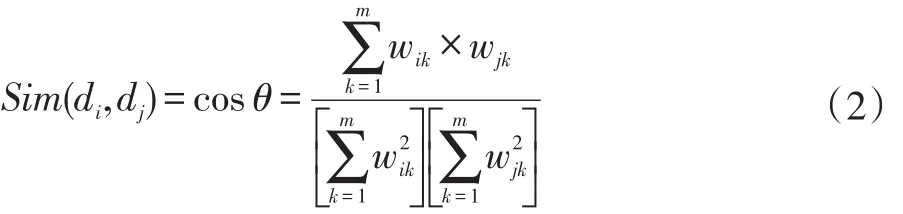
文档向量之间的向量余弦值越高,则表示两个文档之间的相关度越高。
2.2 词义消歧
在人类自然语言的语境中,一个词汇往往含有一个甚至多个语义,如果将这个词汇在一定的语境中独立出来,这个词汇就会产生语义歧义。确定一个词汇的哪个语义在哪个语境中被使用,是词义消歧研究的目的。
关于词义消歧的研究在机器翻译、信息检索、文本分析、知识挖掘等研究方向都具有十分重要的意义。现有的词义消歧方法主要可以分为两类:一、基于词典的方法,二、基于语料库的方法。基于词典的方法利用词典资源中词汇和语义之间的对应关系进行词义消歧,基于语料库的方法从提供的语料库中学习自然语言的语言规则,以此来实现语义消岐。
本文选取一种基于知网的语义消歧算法[7],作为本文的研究工具。该算法利用利用语义联系强度来进行语义消歧。
例如一个词汇 W,它对应的语义集为R={r1,r2,…,rn},其中n≥1。设 Wi是 W 的一个常用的关联词,它们在一起组成一个特定意义的短语,此时与 Wi关联在一起时,W 对应的语义为 ri(ri∈R,0<i<n),此时Wi就与 W的语义 ri之间有个关联度,于是就可以建立起一个词汇与词汇语义之间的联系强度网。
2.3 结合词义消歧的卷积神经网络分类模型
文本针对现有的文本情感分类模型,在对词向量进行训练的时候,往往忽略词汇在不同语境的词义歧义问题,特在模型中引入词义消歧的概念,在词向量训练的同时,对词向量结合上下文关系进行词义消歧,然后得到消歧后的文档特征作为卷积神经网文本情感分类模型的底层输入数据。其模型示意图如图1所示:

图1 词义消歧的卷积神经网络分类模型示意图
在向量空间模型中,自然语言信息被转化成由字、词组和短语等元素组成的结构化向量,这些元素中,有些更能够代表文本的内容,并且对该文本类区别于其他文本的辨识贡献度越高,这样的元素可以被称作文本的“特征项”。
输入层:该模型中,文本特征信息利用训练好的词向量来表示,然后结合文本中的上下文信息,对当前词汇进行语义消歧,利用词义消歧后的词来表示当前文本的特征表示[8],词汇在某时刻 t语义消歧后的特征表示为 xt,则有:

则此时的文档特征矩阵表示为:

卷积层:利用不同大小窗口的过滤器与输入层相连起来,假使其中一个过滤器窗口大小为 h,与它相对应的卷积过滤器为 v∈Rhk,如果该卷积过滤器对输入数据样本中大小为 h的词向量上,于是对原来的输入样本处理操作,产生一个新的特征向量,生成新特征的公式如下所示:

其中,函数 f是一个非线性函数,b∈R是函数f的偏置项元素,并且 b和 v均为该卷积神经网络模型中的重要参数。此卷积过滤器作用于输入样本中所有可能的窗口大小为 h的相邻此向量{w1:h,w2:h,…,wn-h+1:n}上,然后生成一个特征向量:

其中向量 c∈Rn-h+1。
池化层:池化层对数据特征向量 c进行池化操作。池化操作对数据特征向量 c取最大值c̑=max{c}操作,得到的这个最大值 c̑就是数据特征向量 c对应卷积过滤器的特征。卷积神经网络模型中池化层的设计思想是利用池化操作,获得的特征向量的最大值就是与卷积滤波器中相对应起来的最重要特征。
3 实验及结果分析
3.1 实验数据
本文采用现有的数据测试集COAE2014任务4评测语料数据集对模型进行测试,该数据集中共含有40000条测试数据,其中官方公布了5000条评论的极性。利用数据测试集中提供的40000条测试数据来训练词向量。
其中数据集中的数据评论样例如表1所示:
3.2 模型参数
卷积神经网络中模型有许多重要的参数,这些参数对模型分类效率和准确率都有十分重要的影响,例如:卷积核大小、学习速率等。本文选取Filter与Hidden_unit两个参数作为训练参数,Filter为模型卷积层中过滤器滑动窗口的大小;Hidden_unit决定了模型中卷积过滤器的数目[9]。
3.3 实验结果与分析
本文的实验对参数 Filter,给出(2,3,4)、(4,5,6)、(6,7,8)三个备选项,对参数Hidden_unit给出50和100两个备选项,然后对参数相互组合,然后给出每种参数组合模型的分类效果,如表2所示:

表1 评论数据例子

表2 不同参数组合模型的准确率对照表
从实验结果中,我们可以看出本文提到的方法,略好于传统的卷积神经网络文本分类模型的结果。且对实验参数做出调整,发现,当参数Filter为(4,5,6)且参数Hidden_unit为100时,文本分类的准确率最高。因为微博文本的长度一般在140字左右,文本句子的特征维度一般不会太高,经过卷积神经网络模型的池化操作后,选取到的文本句子的主要特征在100左右,Fliter的宽度决定了词向量的长度,词向量的长度过长,不但增加了算法的复杂度,而且还不利于特征的提取。
4 结语
本文在传统的卷积神经网络文本情感分类模型的基础上,引入了词义消歧的概念,在对文本训练的过程中对词汇进行词义消歧,得到消歧后的文本特征向量,更能体现文本的原始语义特征,并以此作为输入数据,利用卷积神经网络进行分类,得到了比单一的卷积神经网络模型更好的分类效果,这说明词义消歧对文本特征的提取是有意义的,而且对分本的分类效果也有一定的提高。
猜你喜欢
计算机与数字工程(2021年12期)2022-01-15 06:24:02
哈尔滨工程大学学报(2020年8期)2020-11-13 01:53:32
西夏研究(2020年1期)2020-04-01 11:54:26
开放教育研究(2020年2期)2020-03-31 01:54:14
新高考(英语进阶)(2018年3期)2018-05-14 07:38:00
电脑与电信(2018年12期)2018-03-23 02:37:20
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
语言与翻译(2014年3期)2014-07-12 10:31:59
中文信息学报(2012年4期)2012-06-29 06:29:14
