
基于GPU的H.264并行解码优化
2018-07-27 05:16:14,,
计算机测量与控制 2018年7期
, ,
(1.电子科技大学 航空航天学院,成都 611731; 2.国家新闻出版广电总局五四二台,北京 100866)
0 引言
2003年,ITU(International Telecommunication Union)与ISO (International Organization for Standardization)组成的JVT(Joint Video Team)制定了H.264/AVC标准。其中,为了在保证其图像质量的同时尽可能降低码率,H.264/AVC标准采用了的许多新创的编解码技术,如改进的去块效应滤波器、块的多种划分方式、像素运动估计(帧间预测)以及根据块划分的多模式帧内预测等;但是,H.264解码时的计算复杂度是MP4的2.2~4.1倍,并且H.264各个对应部分的计算量比H.263均高出了1.2~2.1倍。
在H.264/AVC标准中,多模式帧内预测与去块效应滤波器两种技术是保证码率与图像质量的关键。在多模式帧内预测技术中,率失真优化是帧内预测的本质;为了更好的协调码率与失真,H.264/AVC标准对所有预测模式进行计算,选择率失真代价最小的模式作为最优解。其中,文献[1]提出了9种不同处理顺序;采用多级流水线方式,改变预测块顺序,使不相关的块可以并行执行,实现帧内预测模块的并行执行,但是并没有达到最好的效果;为了提高并行效率,文献[2]在其基础上改变了预测模式,这虽然减少了处理时间,但是所对应的影响则是很大程度上降低了图像质量。
而对于H.264/AVC标准中的滤波器,其主要的作用,是去除了编码过程中所产生的方块效应。其中,对于去块滤波器的并行实现,文献[3]直接提出了一种基于CUDA的并行实现方法,文献[4-5]提出了通过局部减少分支条件来提高滤波器效率。上述两种算法在一定程度上提高了效率,但在流程上并没有进行足够的改进,且在执行顺序上没有很好的突破。
本文主要研究H.264/AVC标准中的帧内预测与滤波器模块的并行算法,在文献[2]基础上对帧内预测模块进行优化处理,对滤波器模块提出新的Bs值并行求取算法,另外在文献[3]的所提出的奇偶边界执行算法的基础上提出一种新的滤波执行并行算法。
1 GPU解码框架
FFmpeg(Fast Forward Mpeg)使用的H.264解码器,主要通过对帧一级的图像解码来实现多线程并行工作:
1)从网络抽象层(Network Abstraction Layer (NAL))获取码流数据,将其放入解码和重排序模块进行解析,可得一系列量化系数X,继续将获得的数据进行反量化与反变换处理,得残差数据D。
2)从NAL获取的码流,通过解析能得出帧内预测模式与帧间预测模式中所需要的MV等信息,将此信息作为帧内预测或帧间运动补偿参考数据进行帧内/帧间预测。
3)由残差数据与预测数据相结合得到重建的图像数据,因为图像中存在块效应,所以需要通过滤波器进行滤波,形成真正的解码帧,此解码帧也作为之后解码用的参考帧。
本文仅对帧内预测与滤波器做并行化处理,因此其框架如图1所示。

图1 解码框架图
在H.264/AVC标准中,当图像中各个宏块经过反量化与反变换之后,所形成的图像根据规则被分为I帧与P帧,I帧是指在编码过程中,预测所采用的是帧内预测,P帧是指在编码过程中,预测所采用的是帧间预测(运动估计)。而在本文的框架中,主要对I帧进行讨论。
GPU中处理的主要包括两个部分,其中,“处理部分1”为帧内预测部分;“处理部分2”为滤波器部分。具体处理流程如图2所示。

图2 运行流程图
如图2所示,当前帧为I帧的时候才通过CUDA调用GPU进行帧内预测解码,否则当前帧为P帧,调用CPU进行帧间预测(运动估计)解码。当帧内预测与帧间预测都执行完成后,将两个模块的数据统一传到滤波器模块,调用GPU进行滤波模块的处理。
2 帧内预测并行算法优化
在H.264/AVC标准中,帧内预测主要包括四种方式:PCM预测方式、4×4亮度块的帧内预测方式、16×16亮度块的帧内预测方式、8×8色度块的帧内预测方式。
本文主要研究四种模式中的4×4亮度块的帧内预测方式,其传统处理顺序如图3所示。由图3可见,此方式以一个16×16亮度块为单位,其中MB0、MB1、MB2、MB3、MB4为16×16亮度块,每个16×16像素的宏块有16个4×4像素的子宏块,单个16×16亮度块内4×4像素子宏块的处理顺序如图中字母顺序所标示。

图3 16×16亮度宏块图
16×16像素的宏块MB4中子宏块的帧内预测所依赖的全部子宏块分别为:块1的j、k、o、p子块;块3的g、m、n、p子块;块0的p子块;块2的j子块。以块4的16个4×4子宏块中,需要其他16×16块做支持的子块为例:a子块的预测需要块0标记为p子块,块1标记为j、k子块,块3标记为g的子块;g子块的预测需要块4标记为f子块,块1标记为p子块,块2标记为j的子块;j子块的预测需要块3标记为p子块,块4中标记为d、i的子块。而对于16×16宏块的执行的顺序为0~4,每一个16×16宏块中的4×4子块的执行顺序则是为a~p。
若直接将传统的帧内预测解码顺序在GPU上实现,那么传统模式所采用的固定顺序会导致GPU的运行效率极低。为了解决该问题,文献[1]中提到了9种更改的处理顺序,文献[2]在其基础上从中选择一种处理顺序并在其基础上提出一种流水线解码方案,该方案的并行处理顺序如图4,其中数字为并行处理顺序,数字相同的则是可以被并行处理的子块。
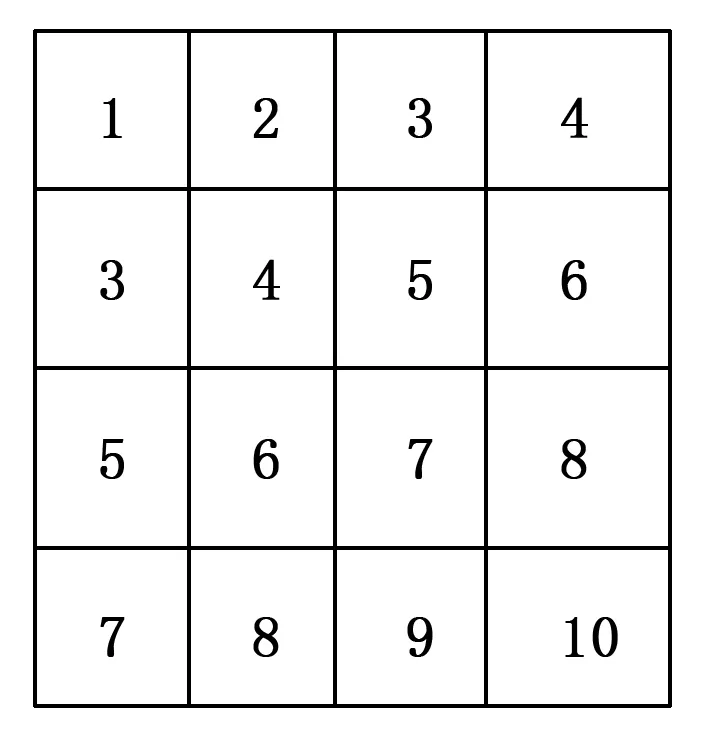
图4 文献[2]中4×4块处理顺序图
该方案在原先基础上将4×4块的处理顺序进行了较好的并行化处理,对一个16×16的宏块,总计需要10个计算单个子块的时间;本文在文献[1-2]基础上,提出了一种以4×4亮度块为最小单位、去除模式3与模式7的并行优化方案,如图5,图中数字仍为并行处理顺序,数字相同的是可以被并行处理的子块;每行的间隔从2减少为1。

图5 本文4×4块处理顺序图
如图5所示,本文算法的并行粒度进一步提高,使得每行的宏块都能流水线的进行并行处理,对于一帧内的16×16块中属于同一行的4×4块进行顺序处理,对一个16×16宏块,总计仅需要7个计算单个子块的时间。
假定一帧图像的宽为W、高为H;对于所处理的块,其基础单位为 4×4像素块。使用本文所提出的执行顺序,每一帧I帧至少需要GPU对其进行M次运算;而N是该执行顺序所能达到最大理论并行粒度。M、N计算方式如式(1)~(2):
M=(H/1-4)+W/4
(1)
N=min(W/4,2×(H/4))
(2)
每次运算所能同时进行的宏块数量由list[i]表示。list[i]计算方式如式(3),其上限即为N:

(3)
因为编码阶段仍然会将模式3和模式7作为预测模式,若在解码阶段直接去除模式3与模式7会使得最终的图像质量受到影响。因此,为了保证最终图像质量,本文在进行帧内预测并行处理的同时,选择添加一个分支的方式,此分支可以在基本不影响并行粒度的同时,保证模式3和模式7的正常解码,其处理流程如图6。

图6 处理顺序分支流程图
如图6所示,该分支主要作用是为了防止模式3和模式7的出现,等待前一个线程的宏块处理,使得当前模块所需要的左上模块得以被处理完成。
3 滤波器并行算法优化
3.1 滤波原理
1)在H.264/AVC标准中,图像边界分为虚假边界、真实边界,根据式(4)~(6)辨别图像边界伟哪种边界。其中,通过查QP表得出α和β的值。真实边界是指所求值不满足以下条件;虚假边界是值满足以下条件;滤波器将对存在虚假边界的宏块进行滤波。
|p0-q0|<α
(4)
|p1-q0|<β
(5)
|q1-q0|<β
(6)
2)滤波强度Bs值是根据图7所描述规则来求取。在滤波的过程中,分别会对图像进行水平滤波、垂直滤波,因此要分别求取水平边界与垂直边界的Bs值。
Bs值的求取规则如图7所示:
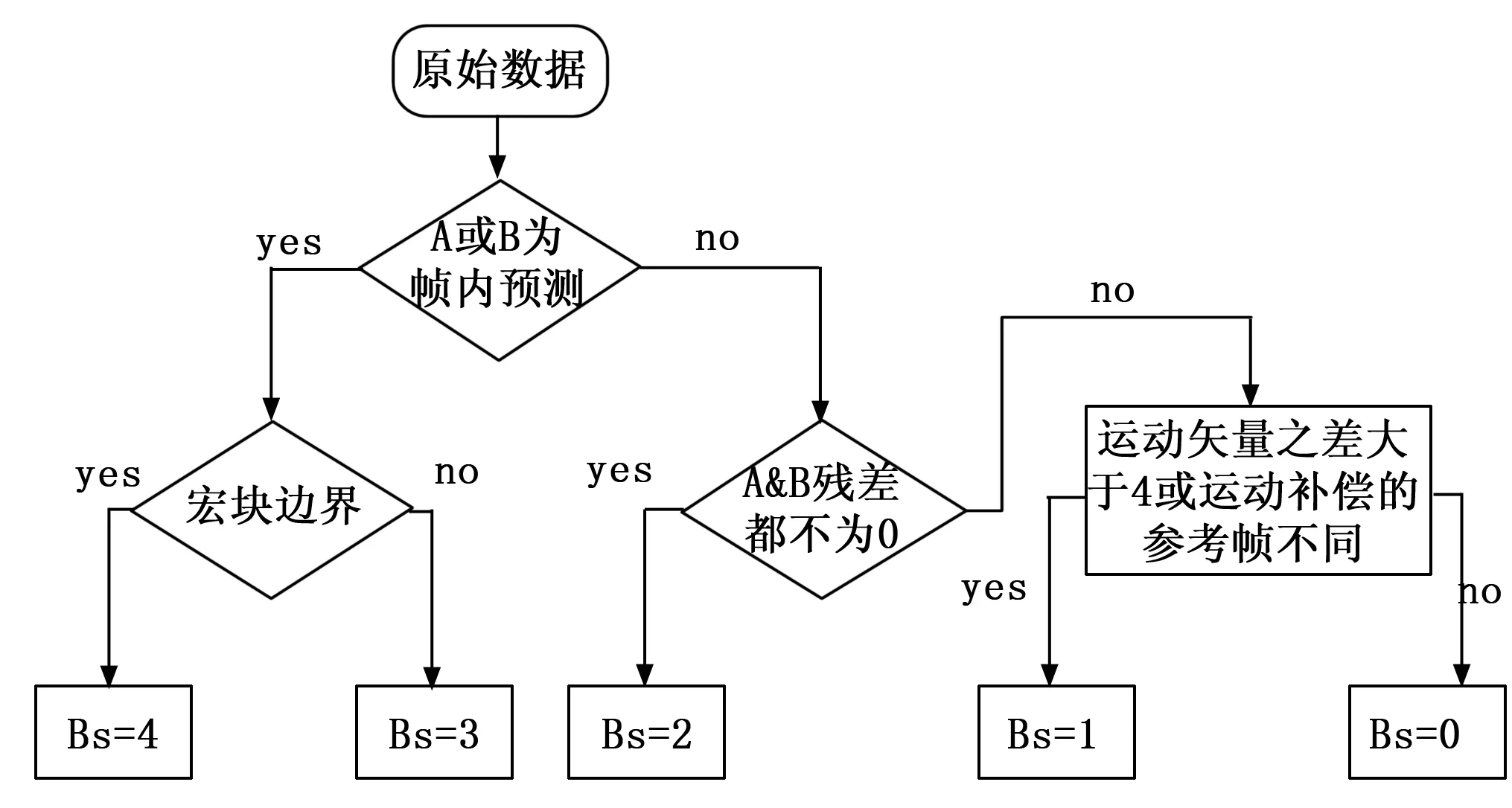
图7 Bs值确定规则图
3)虚假边界进行滤波操作,其中Bs值越大,滤波越强。
3.2 滤波强度Bs值求取的并行实现
3.2.1 Bs值的并行求取
滤波强度Bs值求取的过程是以16×16块为计算单位,一帧图像的边数为(W/H×H/16)×8=W×H/32条,共有W×H/32×16=W×H/2个边界点。这些边界点求取所需的值已经在之前的过程中获得,因此没有相关性,可以并行求取。
在滤波强度Bs值的求取过程中,总计需要的参数为:熵解码所解出的CBP值、运动矢量MV、编码过程中的整数变换矩阵系数、反变换后所得残差数据、帧内预测模式等;在熵解码中,CBP值与整数变换矩阵系数已经被转换为CBP_BLK值。
本文将这些参数存放在全局存储器中,不需要额外调用CPU相GPU传递这些参数;另外需要额外处理的参数为CBP_BLK数组,将其传入到GPU内的纹理存储器中,以便于减少读写访问;同时给GPU分配一定大小的空间用以存放各个边界点的滤波强度Bs值,以便于滤波执行时的直接调用。
在GPU中的每个block所处理的最小单位为16×16像素块,即1个block需对128个边界点进行处理;本文为每个点分配一一对应的thread进行计算,以保证读写的效率与精准度。线程调度方式为:
grid(W/16,H/16),block(16,4,2)
即将一帧分为W/16×H/16个block,每个block负责16×4×2个thread。
3.2.2 优化的并行求取算法
对于同一个4×4像素块中的运动矢量MV、帧内预测模式、反变换后所得残差数据以及CBP_BLK等参数是一样的,因此根据同样参数所计算出的Bs值也应该相同。基于该情况,本文对进一步优化Bs值求取算法,其所需的存储空间与时间都为原来的1/4,计算效率为原来的4倍。优化后的线程调度为:
grid(W/16,H/16),block(4,4,2)
即将一帧分为W/16×H/16个block,每个block负责4×4×2个thread。算法执行时,仅需要对同一个4×4像素块的多个边界点进行一次计算,所计算出的Bs值就是该宏块所有全部边界点的滤波强度Bs值。
3.3 环路滤波执行的并行优化
对于传统的滤波执行如图8所示,滤波首先对从水平方向对各个垂直边界进行滤波,执行的顺序从1~4;然后从垂直方向对各个水平边界执行滤波,执行顺序为5~8。

图8 传统滤波执行顺序图
从H.264/AVC标准中的滤波原理所知,块与块间的滤波是没有关联性的,其所需要的像素点都已经在之前的过程中被计算出,官方所给出的H.264/AVC标准给出顺序是为了提高数据访问的精确性,以便于串行操作;受文献[3]中对并行滤波执行的启发,彻底的打破原先的执行顺序,本文提出一种优化环路滤波并行算法。
该算法在奇偶边界并行滤波算法基础上进一步的提高并行粒度:首先从水平角度执行,对一个16×16块的全部垂直边界同时进行滤波;然后从垂直角度执行,对一个16×16块的全部水平边界同时进行滤波。因为是先水平后垂直的执行顺序,并不会对存储器的读写造成访问冲突。
在本文提出的并行滤波算法中,以16×16块为单位进行滤波,1个block对应处理一个16×16块;由于从水平角度到垂直角度的滤波顺序是串行的,所以每次滤波过程仅并行的处理4条边界,对于一个16×16块的每条执行边界有16个像素点,为得到更好的并行粒度,为每个边界一一对应的分配thread。其thread与边界点所对应的关系如图9。
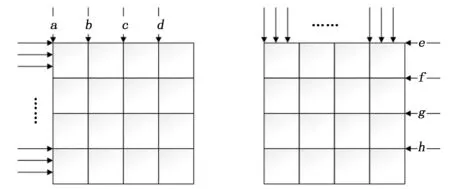
图9 边界滤波中线程和边界点对应关系图
以图9为例,边界a、b、c、d子边界的滤波所分配的64个线程进行处理,当完整的一轮滤波执行完后,再由同样的64个线程对边界e、f、g、h子边界滤波进行处理。这样能保证各个边界点之间为线性的一对一存储访问,从而提高读写的精准度。
在GPU上的内核函数线程调度如下:
for(i=0;i<2;i++){
filter<<
}
在本文算法执行前,所需要的参数已经经Bs求取模块处理完成并存放在了GPU的本地存储器中,因此没有额外的参数传递时间损耗。当执行完全部滤波后,调用GPU将最终所计算出的图像传回CPU中。由于本文提出的算法完全打破了原有的执行顺序,因此,最终的图像结果可能会与串行解码所得的图像结果有略微不同。
4 仿真实验
实验的运行环境采用的GPU是 NVIDIA GeForce GTX 950显卡,CPU的型号为Inter®CoreTMi5-4590处理器,操作系统是 windows 10,编译环境为 CUDA8.1。
实验中,选取了四种不同尺寸的H.264视频码流,分别为Foreman_QCIF序列(176*144)、Mobile_625SD序列(720*576)、Parkrun_720P序列(1280*720)、Tortoise_1080P序列(1920*1280)。在实验过程中取每个序列200帧亮度帧进行50次实验,计算平均每帧耗时。
4.1 帧内预测并行算法的并行优化实现
本文算法、文献[2]中算法以及FFmpeg算法对比如图10所示。
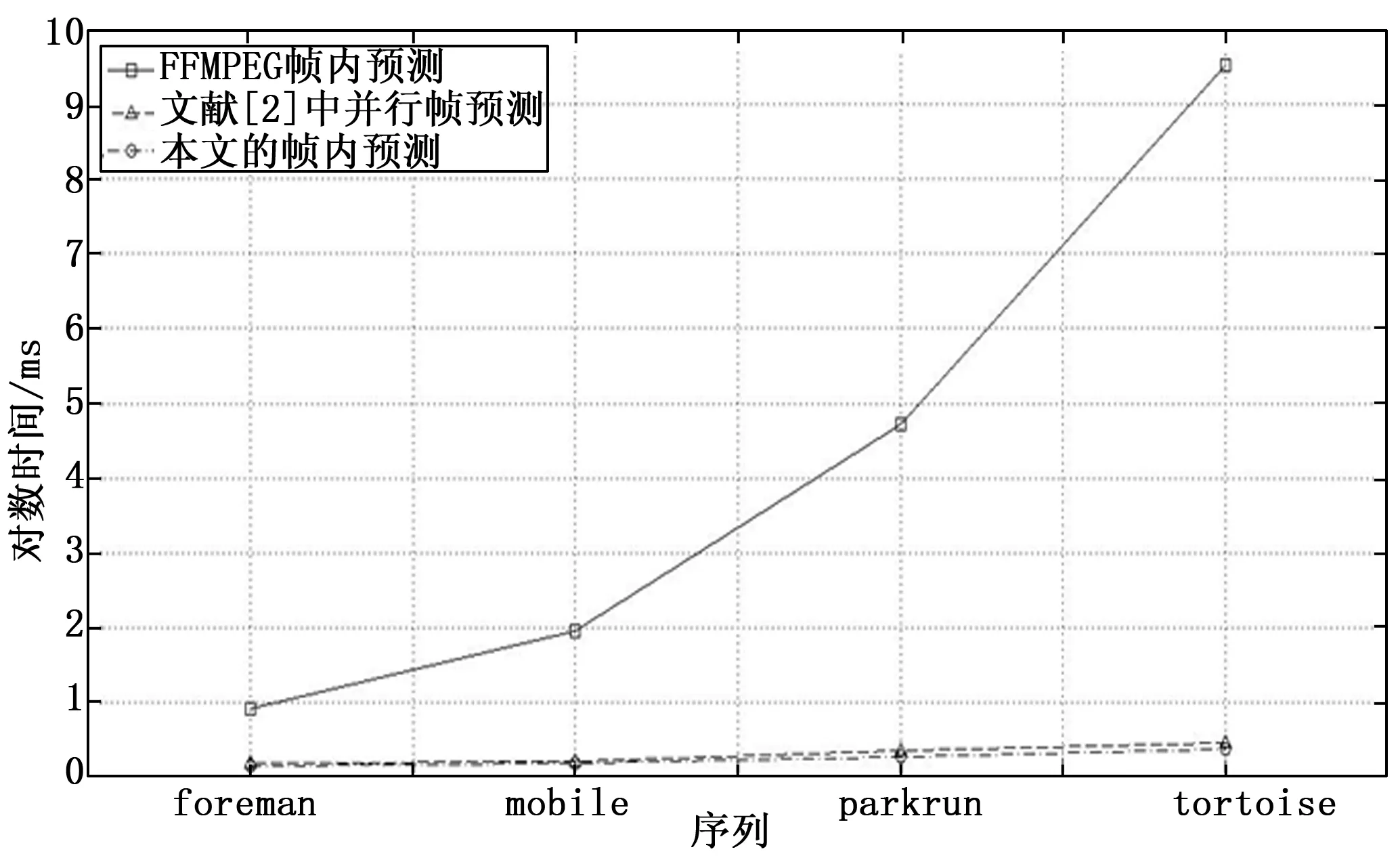
图10 帧内预测解码对比图
由图10可知在四种序列下,序列的像素点越多,并行加速效果越明显。其中本文所提出的帧内预测与文献[2]中并行帧内预测相比有1.2~1.4倍的加速效果,这是因为在编码中去掉了模式3和模式7,使得并行架构更紧凑合理;且因加入了分支判断,对图像质量没有影响。
4.2 滤波强度Bs值求取
本文算法、文献[4]中算法以及FFmpeg算法对比如图11所示。
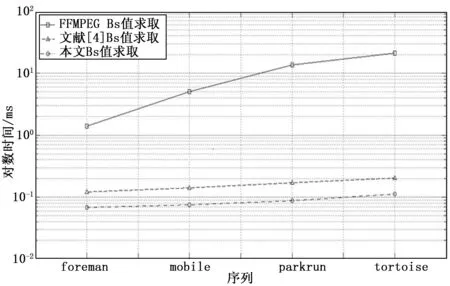
图11 滤波强度Bs值求取对比图
由图11可知,随着被处理图像尺寸的增加,加速效果也随之提高。本文所提出的对滤波强度Bs值并行求取算法的优化表现出了明显的效果。虽然原并行算法的加速比已经很明显,本文算法比文献[4]中并行算法也有1.8~2倍的明显加速比。
4.3 滤波执行
本文算法、文献[5]中算法以及FFmpeg算法对比如图12所示。
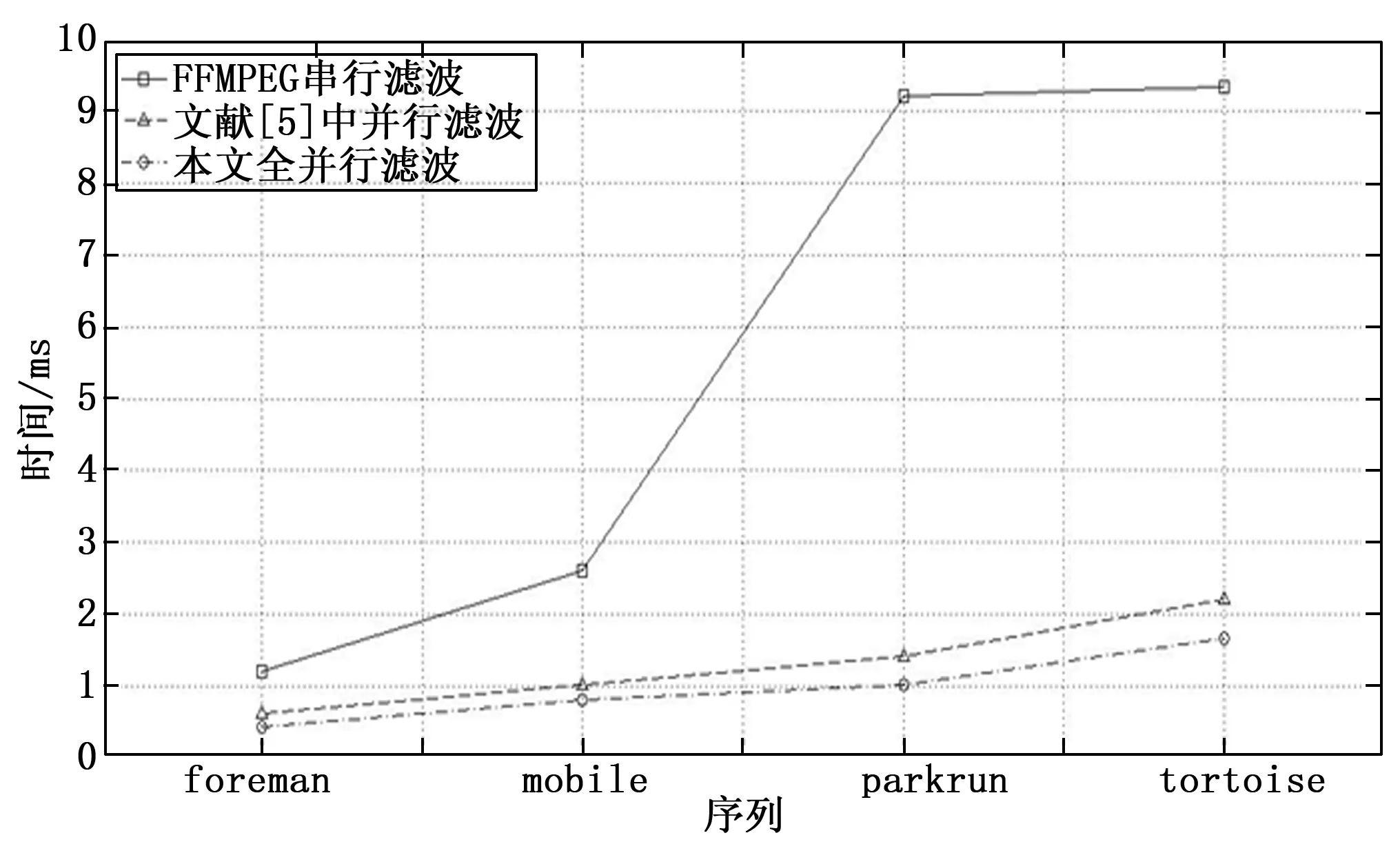
图12 滤波执行对比图
由图12可知,本文所提出的对全并行滤波执行算法有很明显加速的效果,虽然原并行算法的加速比已经很明显,但是经过优化后的算法比文献[5]中并行算法也有1.2~1.5倍的明显加速比。对比1280×720的parkrun序列,1920×1280的tortoise序列,可以看出尺寸更小的parkrun序列的加速比反而比尺寸更大的tortoise序列更高,这是因为parkrun序列中的运动过程更多;具体原因是在CPU串行执行时候,所有的边界处理时间之和才是环路滤波所消耗的运算时间,对运动越剧烈的图像序列,所需要的边界点数规模更大。
为了对最终图像质量进行比较分析,本文采用两种评价标准PSNR与SSIM,对形成的图像进行比较分析。
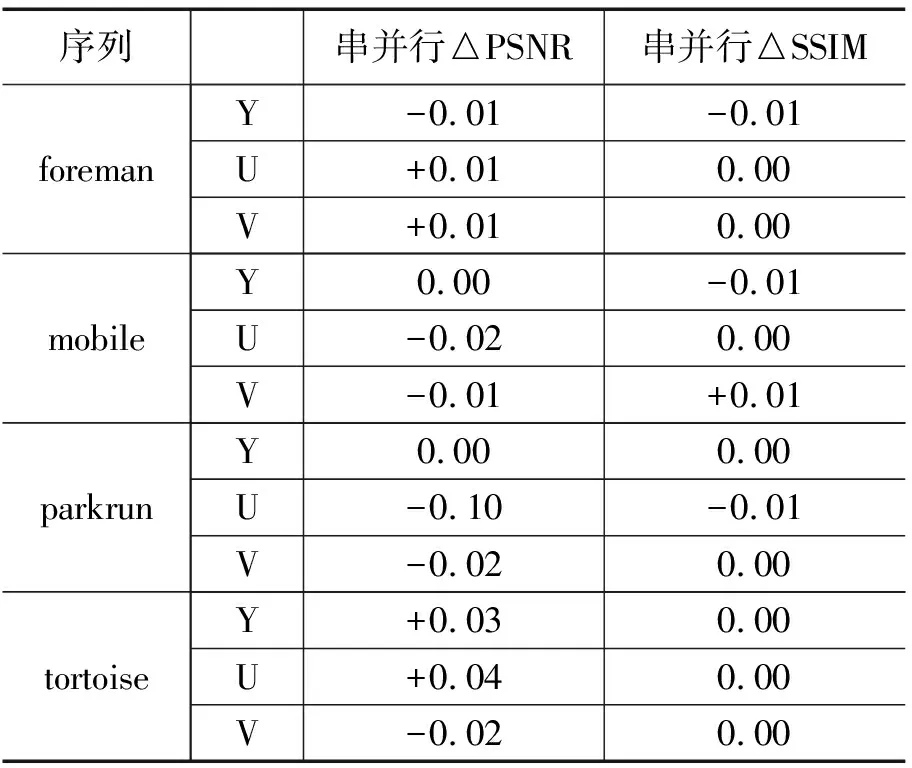
表1 串并行成像效果对比
由表1可知,PSNR、SSIM两种标准中,四种不同尺寸的序列中,仅存在十分微小的差异;所以本文提出的并行滤波算法在有很大加速比的同时,也不会对成像效果有很大影响。
5 结束语
本文基于GPU分别提出了一种的帧内预测并行算法与一种滤波器并行算法;帧内预测算法主要对文献[1,2]算法进行了优化,实验中优化后的算法是原算法加速比的1.2~1.4倍,加速效果明显;本文将滤波器分为两个部分,对于Bs值求取是在文献[4]基础上做出了优化,对滤波执行在文献[3]基础上提出一种全并行算法,使得滤波器加速优势更明显。通过实验可以看出GPU非常适合进行视频解码处理。
猜你喜欢
电脑知识与技术(2024年12期)2024-06-16 05:03:12
电脑知识与技术(2024年10期)2024-06-01 05:59:06
科技创新导报(2021年31期)2021-05-10 14:55:00
现代计算机(2021年36期)2021-03-14 00:50:40
计算机应用(2018年12期)2019-01-07 12:16:36
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01 04:06:43
电子设计工程(2015年24期)2015-08-26 06:39:42
电子设计工程(2014年18期)2014-02-27 12:00:14
郑州大学学报(理学版)(2013年3期)2013-03-11 20:30:36
杭州电子科技大学学报(自然科学版)(2011年5期)2011-09-04 06:09:24
