
尖叫声识别装置的研制
2018-07-26 08:52张旭东陈立江
复旦学报(自然科学版) 2018年3期
毛 峡,张旭东,陈立江
(北京航空航天大学 电子信息工程学院,北京 100191)
尖叫声识别在现代智能监控系统的研究中具有重大意义,它能为保护居民生命安全,减少犯罪率提供有力保障.现代主要的监控系统多为视频监控系统.视频监控系统极容易受到光线环境的影响,很难在夜晚发挥应有的作用.监控的及时性很大程度上取决于监控人员,在监控人员高度疲劳或者注意力不集中的情况下,视频监控中的危险细节很容易被遗漏.此外,视频监控存在着不可避免的盲区问题,一个传统的视频监控系统无法捕捉在视线盲区内的任何信息.而音频监控能够有效地克服视频监控中存在的各种先天问题,具有较高的鲁棒性.在发生突发事件时,惊慌失措的人群往往使得视频信息变得晦涩、杂乱以及不稳定,与之相反,此时音频信息往往更值得信赖[1].此外,音频识别系统还可以辅助视频自动监控系统,使得监控系统更好地理解监控环境中发生的异常事件,从而做出更加及时与准确的反映[2].
目前,国内外学者针对尖叫声识别进行了研究.在文献[3]中,作者使用梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient, MFCC)、短时能量、短时过零率作为特征,使用隐马尔可夫模型(Hidden Markov Model, HMM)来检测电影中尖叫声片段,达到的平均准确率高于97%.在文献[4]中,作者训练了支持向量机(Support Vector Machine, SVM)以及一个高斯混合模型(Gaussian Mixture Model, GMM),对尖叫、哭喊、玻璃碎裂声等声音进行分类,系统所达到的性能是检测概率96.5%,虚警概率23%.在文献[5]中,作者借鉴深度学习(Deep Learning, DP)的方法,利用深度波尔兹曼机对尖叫声进行检测;在文献[6-7]中,作者提出的系统能够区分讲话、哭喊以及像玻璃破碎和水洒出来之类的事件.在文献[8]中,作者使用两个串联的SVM分类器: 第一个分类器使用多组一对一分类器对环境噪声进行排除;第二个分类器使用一个一对多的分类器进行危险信号识别.该方法在20dB的信噪比(Signal Noise Ratio, SNR)下达到的检测概率为93.16%,虚警概率4.76%;0dB下达到的检测概率为84.13%,虚警概率为4.13%.文献[9]使用深度神经网络(Deep Neural Network, DNN)从环境噪声中识别出枪声及尖叫声,准确度为93.8%.文献[10]使用混合时间轨迹方法对地铁站内的异常音频事件进行检测,在20dB的信噪比下F值达到了92.03.
为了解决目前国内外研究在尖叫声识别领域中存在的问题,本文对几种不同的尖叫声识别算法进行了改进,并对改进后的算法进行了系统地比较,然后讨论了尖叫声识别算法在硬件上的具体实现细节.
1 尖叫声识别
1.1 尖叫声特征
考虑到尖叫声所特有的声音特质(声谱往往在尖叫声起始和结束时变化明显),本文除采用传统特征如梅尔频率倒谱系数(MFCC)[11]、频谱特征[12-13],还使用了梅尔频率倒谱系数变化率作为一种改进特征:
(1)
式中:c(n)代表当前帧的第n阶MFCC;cprevious代表前一帧的第n阶MFCC;cvariance代表了MFCC相对变化率.式(1)的分子部分反映了MFCC变化值的平方和,分母部分则表示相对变化的概念.图1,图2展示了两种不同音频的MFCC变化率cvariance随样本帧序号i的变化规律.对比图1与图2可知,尖叫声样本MFCC变化率在整个发生过程中取值较小(大部分取值在0.15以下)且中间部分变化平稳;相反,对话声样本MFCC变化率在发声过程中取值较大(大部分取值在0.15以上,且部分取值达到0.5以上)且变化剧烈.

图1 尖叫声样本MFCC变化率Fig.1 MFCC variance of a scream sample

图2 说话声样本MFCC变化率Fig.2 MFCC variance of a conversation sample
1.2 尖叫声识别算法
1.2.1 基于改进HMM与矢量量化的识别算法
使用传统的基于HMM与矢量量化的方法进行识别时,往往选取其中HMM输出的对数概率最大者的类别号作为测试样本类别号,即:
(2)
式中:Pi代表样本属于i类的概率.此算法实验效果较差,这是因为这分类器过于“严格”.因此本文对HMM的识别方法做了一些改进.
首先,算法将对数概率ln(Pi)进行降序排序,得到一个按元素大小排列的向量:
(3)
设定两个阈值(R,dT).识别算法可描述为,判定测试样本为尖叫声(类别号为1),当且仅当下列两个条件满足:
(4)
式中:N为该样本所对应序列长度.这可简单描述为: 样本为尖叫声的对数概率的值lnP1要排在所有类别对数概率降序排列后的前R位,且其隐含的帧平均概率要大于等于dT.之所以强调帧平均概率,是因为满足相同概率分布的序列,长度越长,则它出现概率的期望将越低.传统识别方法对应的阈值为(1,+∞),为改进算法的一个特例.
1.2.2 基于SVM与静态特征的识别算法(SVM-S)
因为SVM并没有上下文相关的结构,所以在使用SVM对音频信号进行分类时,可以采用取所有帧特征的统计值作为新特征的方法.该统计特征通常称作静态特征.统计特征通常选取均值、均方差、顺序统计量、差分的均值和方差等.本文中选取均值和方差作为统计特征,即:
(5)
1.2.3 基于SVM与码字直方图的识别算法(SVM-H)
SVM方法存在着无法反映音频信号时间结构的问题.因此,本节将采用直方图技术来分析音频信号码字的组成成分,并以此作为特征向量,使用SVM对其进行分类.
矢量量化将特征向量序列映射到正整数序列:
因此直方图向量可表示为:
(6)
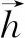

(7)
图3和图4分别展示了尖叫声集合和对话集合上的直方图向量的平均值.从图中可以看出,尖叫声的码字出现的较为单一,而对话相对分布比较广泛.

图3 尖叫声样本码字直方图Fig.3 Code words histogram of a scream sample
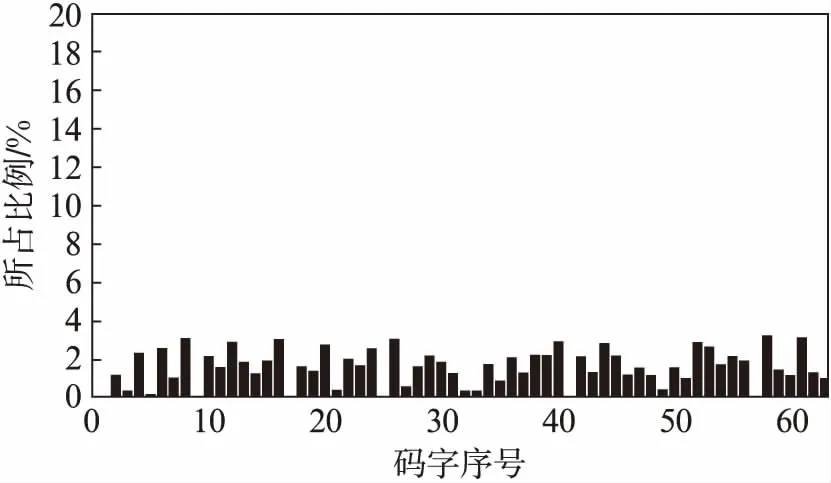
图4 说话声样本码字直方图Fig.4 Code words histogram of a conversation sample
2 尖叫声识别算法验证与分析
2.1 实验数据
本文使用部分MIVIA实验室[14-15]的音频数据(使用Axis T83全方向麦克风获取)以及部分电影音频剪辑作为数据源,总共583条音频,其中包含了尖叫声、动物声音、咳嗽、笑声、音乐、对话6类声音.所有音频的采样率为32kHz,分辨率为16bit,绝大部分时长在0~3s之间.在算法训练和调优中,使用408条作为训练集合,60条作为未开发集合,115条作为测试集合.
本文使用一部电影的音频作为噪声源来模拟真实情况下的噪声,其中包含了对话、音乐等不同种类的声音,本文称待添加噪声的测试样本为目标样本.首先本文从电影音频中剪辑若干个有声片段;在需要添加噪声时,程序将随机选择一段剪辑,并随机选择剪辑中与目标样本等长的一段声音作为环境噪声;如果该剪辑长度小于目标样本的长度,将剪辑复制并添加到剪辑尾部来进行长度扩展.之后以固定20dB的信噪比向环境噪声中添加高斯白噪声.最后将这段环境噪声以指定的信噪比(0,20,40dB)加入到测试样本中.
2.2 特征选择与验证
图5,图6给出了4种特征集合在不同信噪比环境下的ROC(Receiver Operating Characteristic)曲线,其中蓝色、红色、黄色、紫色分别代表以“MFCC+频谱特征+MFCC变化率”、“MFCC+MFCC变化率”、“MFCC+频谱特征”、“频谱特征”作为特征集合时的ROC曲线.图中,纵坐标为检测概率(Detection Rate, DR),横坐标为虚警概率(False Alarm Rate, FAR).一般来说,曲线越靠近左上方,分类器性能越好.
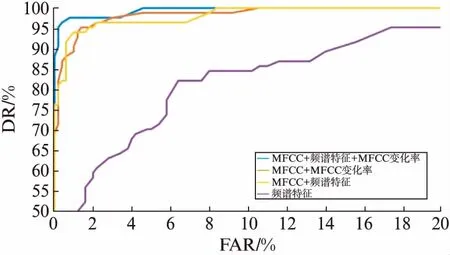
图5 SNR为20dB时不同特征集合的ROC曲线Fig.5 ROC for different feature sets in 20dB SNR
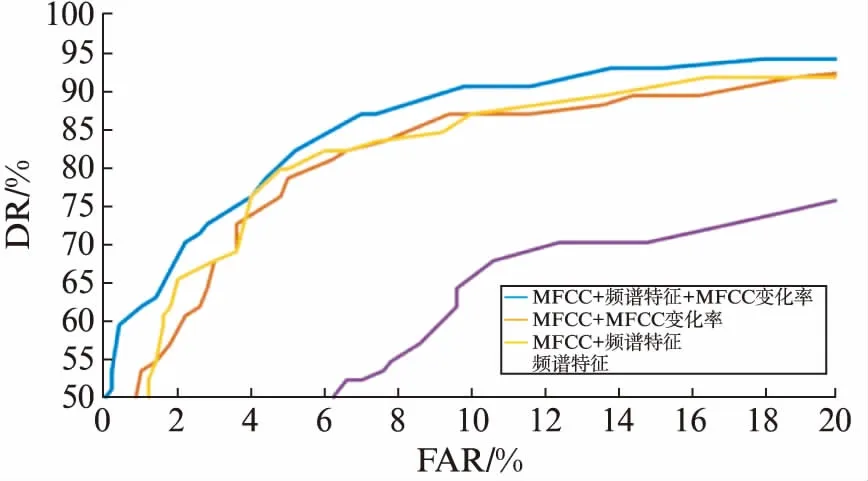
图6 SNR为0dB时不同特征集合的ROC曲线Fig.6 ROC for different feature sets in 0dB SNR
从图5,图6可以看出当信噪比为20dB时,ROC曲线仍处于图中的右上方,因此,这些特征对噪声并不敏感.只有当信噪比很低时,例如0dB,ROC曲线才会明显地向右下方移动,说明算法对噪声的抗干扰能力较强.
另一方面,当算法使用“MFCC+频谱特征+MFCC变化率”作为特征时效果最好,而“MFCC+MFCC变化率”和“MFCC+频谱特征”效果差别不大.MFCC变化率只利用到了MFCC,没有其他更多的运算.但是计算频谱特征需要更多的计算,并且它包含3个单独的特征分量.
鉴于“MFCC+频谱特征+MFCC变化率”的ROC曲线总是分布在其他特征的ROC曲线的左上方,最终算法选取“MFCC+频谱特征+MFCC变化率”作为特征.
2.3 算法评估
图7,图8给出了3种尖叫声识别算法在不同信噪比下的ROC曲线.在信噪比为20dB时,分类器的识别性能相差不大,但是在较低的信噪比环境中(SNR为0dB),使用矢量量化后的特征的分类器性能会大大下降.因此,本文选择SVM-S算法来实现尖叫声识别系统.
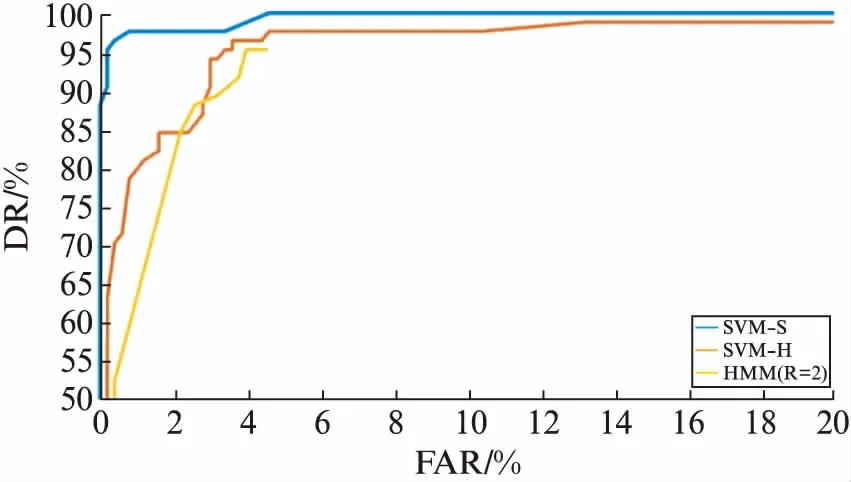
图7 SNR为20dB时3种算法的ROC曲线Fig.7 ROC for three algorithms in 20dB SNR

图8 SNR为0dB时3种算法的ROC曲线Fig.8 ROC for three algorithms in 0dB SNR
3 尖叫声识别算法在ARM9上的实现
3.1 系统框架
整个尖叫声识别系统分为硬件和软件两部分,鉴于它们各自不同的特点,本节将从硬件和软件两部分来介绍整个系统框架.图9展示了整个系统硬件的模块图.首先麦克风将空气中的振动信号转变为电信号;然后,UDA1341TS对原始的电信号进行放大、滤波;之后,该芯片将通过模数转换将模拟信号转变为PCM数据;这些数据将在DMA控制器的协调下通过IIS接口,存储到RAM中;待需要时,这些数据将被送到CPU中进行运算,从而识别;最后,CPU将输出识别信号.在本文中,识别信号通过LED周期性地的亮灭来表示.

图9 系统硬件模块Fig.9 Hardware modules in the designed system
图10展示了系统软件流程图.首先系统上电后完成必要的寄存器初始化工作;然后,主程序将请求DMA(图10中虚线代表请求DMA,DMA工作不需要CPU参与,一旦DMA完成工作,将一帧信号送入内存,CPU将会进入中断处理程序),通过IIS接口获取音频数据并将其存入内存中.主程序通过识别标志监视DMA中断处理程序的进程;在DMA中断处理中,程序将检查每一帧的能量,并根据能量来决定状态机的状态变化,标定音频信号的起始点和终止点;一旦能量条件满足,中断处理程序将通过激活识别标志来通知主程序进行识别;当音频信号结束后,将暂时停止DMA请求;主程序发现识别标志被激活后,将对音频数据进行特征提取和识别,并输出识别信号;最后,主程序将重新请求DMA,进入到下一个流程循环.
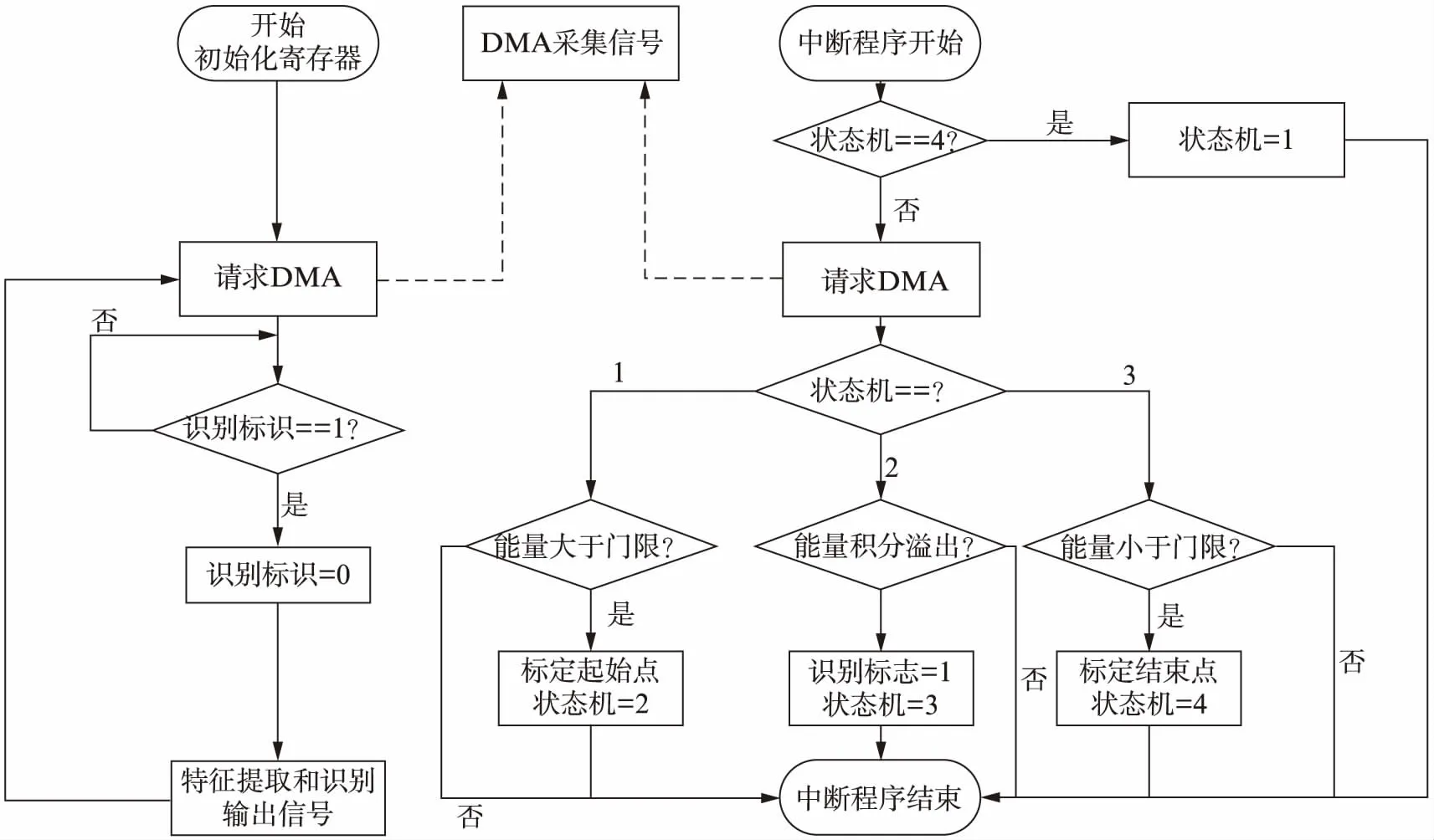
图10 系统软件流程Fig.10 Programming flowchart for the designed system
3.2 音频传输模块
在ARM9尖叫声识别系统中,音频传输是协调音频采集与音频识别的关键.音频传输采用IIS总线接口,它参与了图9中DMAC控制器协调下的音频传输过程.整个接口模块如图11所示,模数转化后的串行数据首先经过移位寄存器,在通道发生器和状态机的控制下进入一个FIFO中,FIFO的状态可以通过一个寄存器组和状态机进行查询和控制,DMAC利用该寄存器组完成从FIFO中读取数据,并将其存入RAM的工作.
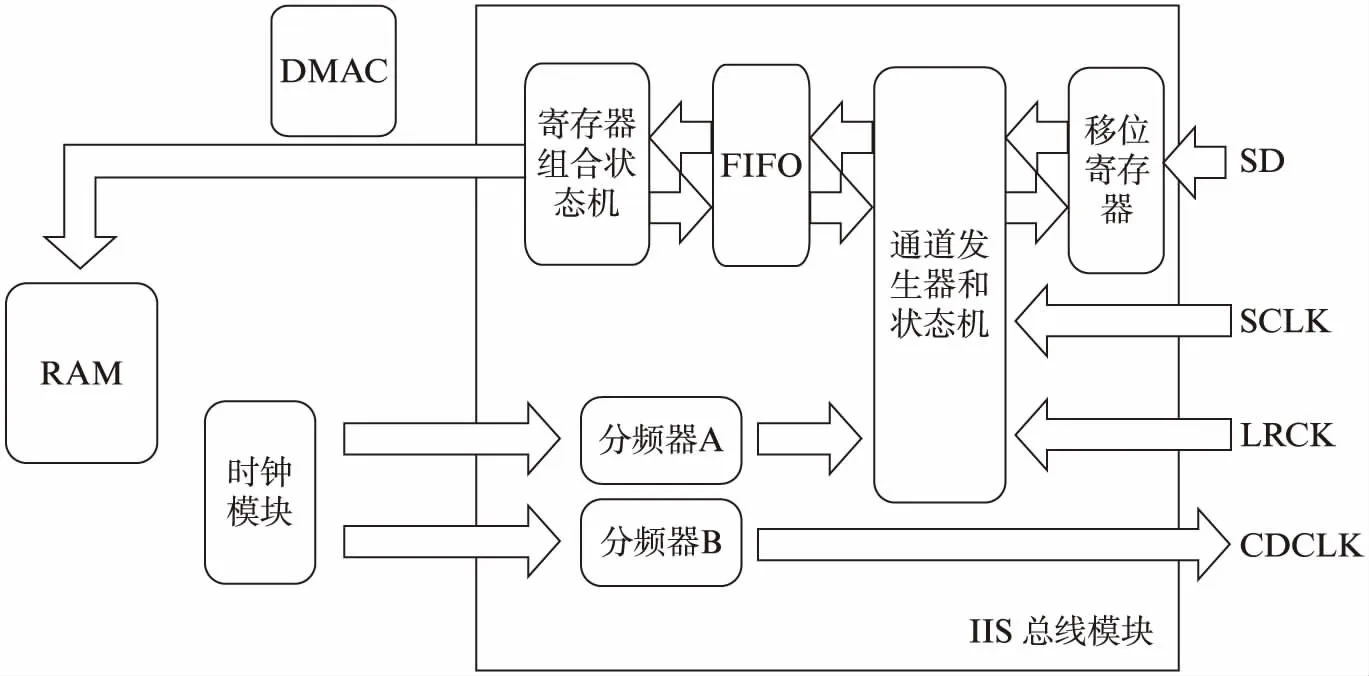
图11 IIS接口模块图Fig.11 IIS interface module
在整个任务的软件编程中,通过对寄存器组和状态机写入控制字来对IIS模块进行控制.首先需要对两个分频器进行配置,使其能正确产生使得IIS以及UDA1341TS工作的时钟.分频比必须准确,否则可能会导致音频采样率不准.之后选择IIS的发送接收模式为DMA.当请求DMA时,DMA控制器将自动从IIS模块取音频数据,不需要CPU干预.
3.3 系统性能测试
本文最终在测试集合中选取115条音频(测试集中所有样本)进行硬件测试,系统采用的特征为“MFCC+MFCC变化率+频谱特征”,采用的算法为SVM-S.音频在实验室环境下使用电脑进行播放.结果如表1,其中每一列代表实际尖叫声或非尖叫声的样本数量,每一行代表预测得出的尖叫声或非尖叫声样本数量.例如表中数据第一行第一列代表了实际为尖叫声,在预测中也被判断为尖叫声的样本数量.系统的检测概率为96%,虚警概率为3.4%.并且在测试中,系统的应答时间均小于2s.因此,该系统基本满足尖叫声识别系统的要求.

表1 系统测试结果
在系统测试过程中发现,在被误识别为非尖叫声的尖叫声样本中,尖叫者发出了多次连续尖叫且幅度变化剧烈,与其他样本具有明显区别.另外,经过电脑外放与ARM9重新采集后的音频与原始音频之间存在差异,影响了计算得到的特征值.以上原因导致了系统对一部分样本进行了错误的识别,作者将在后续研究中针对系统中的不足进行改进.
4 结 语
本文提出用MFCC变化率作为尖叫声特征,以此改进了尖叫声识别系统的检测概率和虚警概率并对HMM的传统判别方式进行了改进,使得其可以通过阈值(R,dT)对HMM的ROC曲线进行调整,进而避免了检测概率过小的问题.在此基础上,本文使用IIS和DMA实现了基于ARM9的尖叫声识别系统.
猜你喜欢
湖南电力(2021年4期)2021-11-05
初中生世界·九年级(2020年9期)2020-09-21
中国诗歌(2018年5期)2018-11-14
金山(2017年12期)2018-01-08
计算机应用(2017年4期)2017-06-27
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
初中生学习·低(2016年6期)2016-05-14
电测与仪表(2016年14期)2016-04-11
电测与仪表(2015年20期)2015-04-09
