
结合区域生长及主成分分析的机载LiDAR建筑物点云提取
2018-07-26 00:21王竞雪洪绍轩
信号处理 2018年9期
王竞雪 洪绍轩
(1. 辽宁工程技术大学测绘与地理科学学院,辽宁阜新 123000;2. 西南交通大学地球科学与环境工程学院,四川成都 610031)
1 引言
机载激光雷达技术(Light Laser Detection and Ranging,简称LiDAR)作为一种主动式遥感技术,可以快速、准确地获取地表及建筑物等人工地物的高密度三维点云数据,为三维数字城市建模提供关键基础数据。而从原始机载LiDAR点云数据中提取建筑物点云是基于LiDAR数据建筑物三维建模的关键[1-3]。
目前,从机载LiDAR点云中提取建筑物的算法可归为三类:第一类是基于栅格影像的建筑物点云提取。该方法将点云数据转化成距离影像,在此基础上利用图像的纹理信息进行建筑物点云的提取。刘修国等提出一种对比度特征辅助的点云数据建筑物快速提取算法[4]。徐文学等提出一种多标记点过程的LiDAR点云建筑物提取算法[5]。张皓等提出一种基于灰度共生矩阵(Gray Level Co-occurrence Matrix,简称GLCM)的LiDAR点云建筑物自动提取算法[6]。该类方法以数字图像处理技术为基础,原理相对简单,但初始点云栅格化过程中点云空缺处的栅格需要进行插值计算,该过程会影响原始LiDAR点云数据的基本特征与初始结构,不利于后续建筑物提取;第二类是融合多源遥感数据进行建筑物点云提取。Gao等提出一种基于航空影像与机载 LiDAR 数据融合的地物分类方法[7]。Mohammad等提出一种结合多光谱图像的激光雷达数据建筑物自动检测算法[8]。该类方法可以简化建筑物点云提取算法,但是需要将LiDAR点云数据与影像进行精确的配准与融合,而且对于影像分辨率要求较高;第三类是基于地形地物空间特征的相似性对点云进行聚类或分割提取建筑物。Wang等提出一种基于八叉树分裂、合并的机载LiDAR数据共面点聚类自动分割算法[9]。汪禹芹提出一种基于TIN点云分割算法[10]。罗胜等提出一种基于区域生长的多层结构建筑物激光点提取算法[11]。Pang等提出基于三角形的区域生长算法[12]。上述采用聚类分析法提取建筑物激光脚点,需要进行庞大的距离矩阵计算,且算法复杂,运算效率低。同时该类算法依赖于种子点的选取精度。
上述大部分算法都是基于滤波之后的非地面点云进行建筑物激光脚点提取,这种方法受滤波结果的影响,如果滤波精度不高,将直接影响后续建筑物点云提取精度。针对这一问题,何曼芸等直接利用原始点云数据进行建筑物提取,提出一种综合不规则三角网和区域生长的建筑物提取算法[13]。该方法对单一建筑物能得到较好的提取结果,但由于区域生长后的后处理工作不完善,导致与树木邻近的建筑物存在错分现象,特别当二者高度相当时错分现象尤为严重,同时该方法对于地形以及房屋类型没有达到良好的自适应性。鉴于此,本文提出一种结合区域生长及特征分析的机载LiDAR点云建筑物提取算法。该方法在文献[13]基础上,对区域生长后得到的点云数据,进一步采用主成分分析法对其进行检核,并根据面积阈值法剔除小区域噪声,有效的提高了建筑物点云的提取精度。
2 原理
本文算法整体流程如图1所示。该算法首先对粗差剔除后的机载LiDAR离散点云构建TIN三角网,利用建筑物边缘点与地面点构成三角形的特征,提取建筑物边缘激光脚点,并利用邻域特征对建筑物边缘激光脚点进行优化;然后将优化后的建筑物边缘点作为种子点进行局部区域生长得到建筑物点云;最后通过主成分分析法过滤掉非建筑物点云,同时利用连通性分析原理对全部建筑物点云进行单体化分割,同时剔除小面积区域,得到最终的建筑物激光脚点数据。

图1 建筑物点云提取算法流程图Fig.1 Flowchart of building point clouds extraction algorithm
2.1 基于Delaunay三角网的建筑物边缘点提取
本文对粗差剔除后的机载LiDAR点云构建不规则TIN三角网,利用三角网中建筑物边缘点所在的三角形有其自身的特点,如图2所示,该三角形中有两条边长近似相等且明显大于第三条边长,同时该三角形所在平面近似为铅垂面。因此本文根据上述两方面特点提取建筑物边缘三角形及边缘点,具体步骤如下:
Step1 对原始点云构建Delaunay三角网;
Step2 对三角网中任一三角形,计算三角面的法向量n1及三边的边长l1、l2、l3,假定l1≤l2≤l3;
Step3 计算法向量n1与铅垂线夹角的余弦值cosα;
Step4 将余弦值和边长同时满足如下条件的三角形确认为边缘点所在的三角形,cosα Step5 计算边缘三角形重心点坐标,三角形中Z坐标值大于重心点Z坐标值的顶点为建筑物边缘激光脚点; Step6 对三角网中每个三角形重复Step2~Step5,依次判断其是否为边缘点所在三角形,并提取建筑物边缘点。 图2 边缘三角形Fig.2 Boundary triangle 对上述提取到的建筑物边缘激光脚点,进一步采用优化算法去除孤立的建筑物边缘点。以目标点为球心,一定长度为半径的设定球体作为目标点的三维邻域范围,确定该邻域内包含建筑物边缘点的数目,将数目小于阈值n(区间范围:4~6个)的目标点去除。最终得到优化后的建筑物边缘激光脚点如图4所示,原始点云如图3所示。 图3 原始点云Fig.3 Original point clouds 图4 建筑物边缘点提取Fig.4 Building boundary points extraction 区域生长算法过程主要包括种子点选取、制定生长准则、设定终止条件三方面内容[14-16]。该算法依赖种子点选取的精度,因此种子点选取是关键。本文以基于Delaunay三角网提取到的建筑物边缘点作为种子点,采用区域生长算法从粗差剔除后的LiDAR点云数据中提取建筑物点云。具体过程如下: (3)终止条件:判断i是否等于l?否,令i=i+1,重复上述步骤(2),进行区域生长;是,迭代终止。得到初始建筑物激光脚点如图6所示。 图5 局部区域搜寻示意图Fig.5 Local area search schematic 图6 区域生长提取建筑物点云Fig.6 Building point clouds extraction by region growing 由于植被的干扰,经过边缘点区域生长后得到的建筑物激光脚点可能会包含一些非建筑物点云,尤其当建筑物邻域内存在与其高度相近的树木的情况下。因此本文进一步利用主成分分析算法[17]对提取结果进行检核,去除噪声点。 (1) 式中: (2) (3) 实验中,为了结果的可靠性,需要确保当前点邻域集合M内离散点的数目大于一定的阈值TM=8。因此当邻域内点的数目小于TM时,判定点Pi为植被点或者建筑物噪声点。当邻域内所有点都在一个平面上,λ1为0,但是由于点云离散性特点,当λ1值较小时就认为其邻域M内的离散点满足空间平面。设定点Pi的表面曲率为: (4) f越小,则点Pi及其邻域点越有可能在同一平面上,因此给定经验阈值Tf=0.3。若f 图7 主成分分析后建筑物点云Fig.7 Building point clouds after principal component analysis 本文进一步采用栅格连通性对全部建筑物点云进行单体化分割,同时剔除小面积区域。该过程首先将提取到的建筑物点云进行栅格化处理,将其投影到二维虚拟格网里;然后基于格网八邻域连通性对建筑物点云进行区域分割,得到若干个各自独立的小区域;最后设定面积阈值TS为参考数据最小建筑物面积,认为分割结果中小于面积阈值的区域为噪声区域,将其去除,最终得到单体化的建筑物激光脚点,如图8所示。 图8 最终建筑物点云Fig.8 Final building point clouds 为了验证本文算法的有效性,实验选用ISPRS官网提供的三组测区数据:Samp12、CSite2、CSite3。其中Samp12测区包含有建筑物、植被、道路、电力线等混合地物,城市区域较为密集,而且还有部分是山地,地形起伏较明显。区域范围大约为53300 m2,原始点云数目共52119个。CSite2测区数据采用末回波数据,对原始CSite2测区数据进行裁剪,得到裁剪区域如图9(b)所示,包含有大量的形状不规则的建筑物,植被区域较多,地势较为平坦。裁剪区域范围大约为44544 m2,点云数目共40009个。CSite3测区同样采用末回波数据,其建筑物较为密集,屋顶形状较异常,高低不平,植被较多且有很多与建筑物紧邻,地形较平坦。区域范围大约为200368 m2,共包含188514个离散激光脚点。测试数据中分别包含平顶型、人字型、山型等多种屋顶类型的建筑物。三组测区原始点云渲染图分别如图9所示。后续为了进行结果检核,在TerraScan软件中人工目视判读选取的建筑物脚点,并将其作为标准参考数据,如图10所示。 采用本文提出的结合区域生长及主成分分析的机载LiDAR点云建筑物提取算法对上述三组数据进行测试实验。同时为了验证本文算法的有效性,还分别采用文献[13]提出的综合不规则三角网与区域生长的建筑物点云提取算法和文献[18]中基于形态学的建筑物点云提取算法对上述三组测试数据进行建筑物点云提取实验,并与本文算法提取结果进行对比分析,验证本文算法的有效性。三种方法建筑物点云提取结果分别如图11~13所示,图中不同颜色信息代表分割的单体建筑物。 图9 三组测区原始点云Fig.9 The original point clouds of three test data 图10 参考数据结果Fig.10 Reference data results 图11 数据Samp12不同算法建筑物提取结果Fig.11 Data Samp12 extraction results by different algorithms 图12 数据CSite2不同算法建筑物提取结果Fig.12 Data CSite2 extraction results by different algorithms 图13 数据CSite3不同算法建筑物提取结果Fig.13 Data CSite3 extraction results by different algorithms 图11为不同算法对Samp12数据进行建筑物提取的结果,从中可以看出,三种算法都可以提取出建筑物的基本轮廓。但是从标记1可以看出文献[13]算法将某些非建筑物点云错误的提取出来;而从标记2、标记3可以看出,文献[18]算法存在部分建筑物提取不完整,对于高程比较低的建筑物会有遗漏现象。而本文算法对于山坡上的建筑物可以完整地提取出来,且植被与建筑物紧邻处也可以很好地区分。 图12为不同算法对CSite2数据进行建筑物提取的结果。从标记1和标记2可以看出文献[13]算法提取的建筑物不完整,文献[18]形态学算法相对完整,但是建筑物拐角点处没有成直角;标记3是圆柱形建筑物,高程比较矮而且墙壁较窄,文献[13]算法没有将其提取出来;标记4中部分建筑物与植被紧邻,而且植被点高程与建筑物顶面高程接近,文献[13]算法可以大致分离出建筑物与植被,但是少数植被点云被错误的提取出来,而文献[18]算法对此难以区分。对于上述两种算法出现的问题,本文算法都可以很好的解决。 图13为不同算法对CSite3数据进行建筑物提取的结果。从标记1中可以看出文献[18]算法对于植被与建筑物紧邻区域难以将二者分离出来,文献[13]算法也存在过提取现象;标记2和标记3充分说明了文献[18]算法对于复杂建筑物屋顶面提取的效果不理想,存在严重的提取漏洞;从标记4和标记5得知,文献[13]算法会将部分非建筑物点云错误的提取出来;与上述两种算法相比,本文算法总体提取效果较好。 通过上述三组测试数据不同算法实验结果对比分析可以看出来,与文献[13]、文献[18]算法相比,本文算法对于建筑物与植被紧邻的区域,可以更好的将二者区分。同时该算法对于不同地形有更好的自适应性,提取的建筑物比较完整,轮廓清晰。后续通过对建筑物点群单体化分割,便于后期建筑物三维重建。图14~16为截取的不同屋顶类型建筑物本文算法的提取结果图,从中可以看出,本文算法对不同类型的建筑物具有较好的鲁棒性。 为了进一步验证本文算法的可靠性,借鉴文献[19]中滤波的评价方法,本文同时采用定量评价的方法对建筑物提取结果进行精度评定。以人工目视判读选取的建筑物脚点作为基准数据。分别从第Ⅰ类误差、第Ⅱ类误差、总误差以及Kappa系数四个方面对提取结果进行定量评价。 图14 山型屋顶建筑物提取结果Fig.14 Extraction results of mountain roof buildings 图15 平顶型屋顶建筑物提取结果Fig.15 Extraction results of flat roof buildings 图16 人字型屋顶建筑物提取结果Fig.16 Extraction results of herringbone roof buildings ①第Ⅰ类误差定义为建筑物点误分为非建筑物点的误差,计算公式如下: (5) 式中,b为建筑物点误分为非建筑物点的数目,e为参考数据中的建筑物点数目。 ②第Ⅱ类误差定义为非建筑物点误分为建筑物点的误差,计算公式如下: (6) 式中,c为非建筑物点误分为建筑物点的数目,f为参考数据中的非建筑物点数目。 ③总误差计算公式如下: (7) ④Kappa系数计算公式如下: Kappa系数= (8) 式中,a为分类正确的建筑物点总数目,d为分类正确的非建筑物点总数目,g表示本文算法提取的建筑物点总数,g表示本文算法提取的非建筑物点总数。 对上述三种算法建筑物提取结果进行统计,分别如表1、表2、表3所示,其中涵盖了正确提取建筑物以及非建筑物点数量、将参考数据中的建筑物误分类为非建筑物、将参考数据中的非建筑物误分类为建筑物等内容。表4是对表1、表2、表3统计结果做的定量精度评价,从表中可以看出,文献[18]算法精度差距比较大,主要是因为形态学算法提取建筑物的局限性,主要适用于地形平坦的小区域,而且建筑物与植被高程差别明显。表中Ⅰ类误差比较大,说明该算法对于建筑物漏提取现象比较严重,主要因为数据集地形起伏明显,建筑物高程相差比较大,这样在生成DSM深度图像以及二值化处理之后,与植被高程相当的建筑物被当成植被过滤掉,导致漏提取现象;总误差以及Kappa系数比较差,是因为Ⅰ类误差比较大所导致,也说明了文献[18]算法还没有达到普适性。但是Ⅱ类误差控制的比较好,表明对于植被的过滤效果比较好。本文算法的Ⅰ类误差维持在0.84%~4.90%,说明对于建筑物点云提取的完整性很高,其中对于CSite3数据,文献[13]算法的Ⅰ类误差比本文算法略好,是因为本文算法在连通性分析单体建筑物分割之后,设定的面积阈值稍大,将个别面积较小的建筑物过滤掉。本文算法的Ⅱ类误差在0.06%~1.67%范围,充分说明本文算法对于区域生长之后的后处理效果很好,可以将非建筑物点过滤掉,降低误分率。Ⅰ类误差和Ⅱ类误差比较低,致使总误差也比较理想。Kappa系数控制在96%左右,表明本文算法建筑物提取结果与参考数据结果的高度一致性,各类建筑物提取的鲁棒性比较好,同时对于非建筑物的分离也比较准确,通过比较充分论证本文算法的可行性。 表1 文献[13]算法建筑物提取结果精度评价 表2 文献[18]算法建筑物提取结果精度评价 表3 本文算法建筑物提取结果精度评价 表4 三种算法精度对比 本文提出一种结合边缘点区域生长及主成分分析的机载LiDAR点云建筑物提取算法,该方法利用Delaunay三角网提取的建筑物边缘点作为种子点进行区域生长,然后结合主成分分析及单体化分割对提取到的建筑物点云进行后处理,得到可靠的提取结果。该算法具备以下特点:①改变了原有先滤波后提取的建筑物点云提取方式,无需滤波处理,直接对原始机载LiDAR点云处理,提高处理效率;②优化了种子点的选取方式,增加了种子点的可靠性;③局部区域生长方式增加了对地形以及不同房屋类型的自适应性,同时也解决了现有算法中植被与建筑物紧邻而导致建筑物提取精度低的问题;④将主成分分析方法引入到点云数据处理中,极大的提高了建筑物提取的准确性;⑤最终实现建筑物点云单体分割。通过不同算法对不同测区点云数据进行建筑物提取,验证了本文算法的可靠性与适用性。后续将对屋顶面的精确分割以及边界线的规则化做进一步的研究,为建筑物的三维重建作准备。


2.2 基于边缘点区域生长的建筑物点云提取


2.3 主成分分析去除噪声点


2.4 建筑物单体化分割及小面积区域剔除

3 实验与分析
3.1 实验数据
3.2 不同算法建筑物提取结果对比分析





3.3 不同算法精度评价



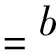


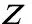




4 结论
猜你喜欢
铁道建筑技术(2021年4期)2021-07-21黑龙江水利科技(2020年8期)2021-01-21哈尔滨轴承(2020年2期)2020-11-06今日中国·法文版(2020年7期)2020-07-04小学生学习指导(低年级)(2019年9期)2019-09-25中国特种设备安全(2019年1期)2019-03-13通信产业报(2016年44期)2017-03-13山东青年(2016年2期)2016-02-28小天使·二年级语数英综合(2015年12期)2015-12-04雕塑(1999年2期)1999-06-28
