
基于改进卷积神经网络的机动车图像分类算法
2018-07-25 11:22陈一民丁友东
计算机应用与软件 2018年7期
王 茜 陈一民 丁友东
1(上海大学计算机工程与科学学院 上海 200072) 2(上海市公安局刑事侦查总队科技信息科 上海 200083)
0 引 言
由于机动车公共管理和事件查控的需求,我们往往需要在海量视频监控图像中快速获得相应分类属性的目标车辆或车辆集。车型属性相对于机动车的颜色、品牌、用途、大小等属性而言,分类更加明确而精细,对我们的价值也更大,但针对其进行图像分类任务也面临更多挑战。以往各类方法或需要过多预处理操作,或识别率低,且多数仅基于小型数据集。自基于神经网络的深度学习问世以来,基于大规模图像数据的应用开始成为可能,如何基于有效CNN网络,对基于监控图像的海量机动车图像进行高精度的属性分类,是公安需要解决的实际问题。
近几年业内熟知的Alex CNN[1]、GoogleNet V1[2]、VGGnet[3]、ResNet[4]等CNN网络,伴随着网络层级不断增加,算法往往需要大量训练时间和计算量消耗,网络层级增加导致参数变大的弊端也越来越凸显。学者们开始把目光从原有通过致力于增加网络深度以提升识别准确率的研究方向,转入到增加网络广度、减少网络参数和提高收敛速度的研究中。2015年起,Googlenet在原有算法97中推出了V2版本[5],提出了更加有效提高学习率的批泛化层BN(Batch Normalization)取代原有成效不高的网络的局部反应归一化层LRN(Local Response Normalization)。2015年底,Googlenet再次提出了V3版本[6],全面提出了inception单元的概念,对于减少网络参数和提升网络广度做出了较大贡献。
在解决一直困扰大家的不均衡样本导致的识别偏差的问题上,难负样本挖掘[7]HNM(Hard negative mining)是重要的通用性减轻样本不均衡性的方法。文献[7]就将该方法应用于花卉问题,以期配合样本增加解决花卉种类过多而样本过少的问题;文献[8]提到了方法对计算资源的消耗较大,并提出了减少挖掘算法次数的选择性Hard negative mining方法,同时通过高斯分布函数计算正确和错误预测的正样本。
在防止过拟合和缩减网络大小的进展中,每一个神经元拥有相同的概率被丢弃和保留的dropout方法被提出和广泛应用[9]。但部分学者提出了用不同决定性和随机性影响因子替代原有随机dropout参数的方法,以通过对复合数据集中不同部分集合的局部参数调整,实现对识别效果的整体优化[9-10]。
本文基于前述方法,采用了节省网络层级和时间消耗的CNN网络。我们将该网络辅以优化后的dropout参数以加快收敛算法,通过改进的Hard negative mining方法减少异类样本分布不均衡性带来的不利影响。
1 基于改进深度学习神经网络的车型识别算法
1.1 数据集构建
我们采用了真实城市道路中6个路口共计42 个多角度高清摄像头,抓拍过往车辆图片。经过6个月的时间,我们去除了同车型中样本数少于100的极小类车型图片和遮挡、模糊图片,整理出车辆图片共计100万张,即使这样,同一车型下最多样本数达到了73 714张,最少样本数仅为100张,数据集仍呈现了极度不均衡性。我们按80%和20%的比例将其分为训练集和测试集。
1.2 车型属性分类算法
本文基于深度神经网络的车辆属性分类算法示意如图1所示。

图1 基于深度神经网络的车辆车型属性分类算法示意图
算法详细实施过程如下:
① 数据输入(Input):
我们将共计T类车型的P张训练图片集统一归一化为3 200×160的RGB图像,并将其表述为:
{xp|xp∈}(1≤p≤P)
(1)
② 神经网络(CNN)训练:
图2所示为我们采用的神经网络模型。除输入层外,中间经过了共计三个卷积层Conv(Convolution)、一个池化层(pool)、六个Inception单元,两个全连接层(Full connecting)。
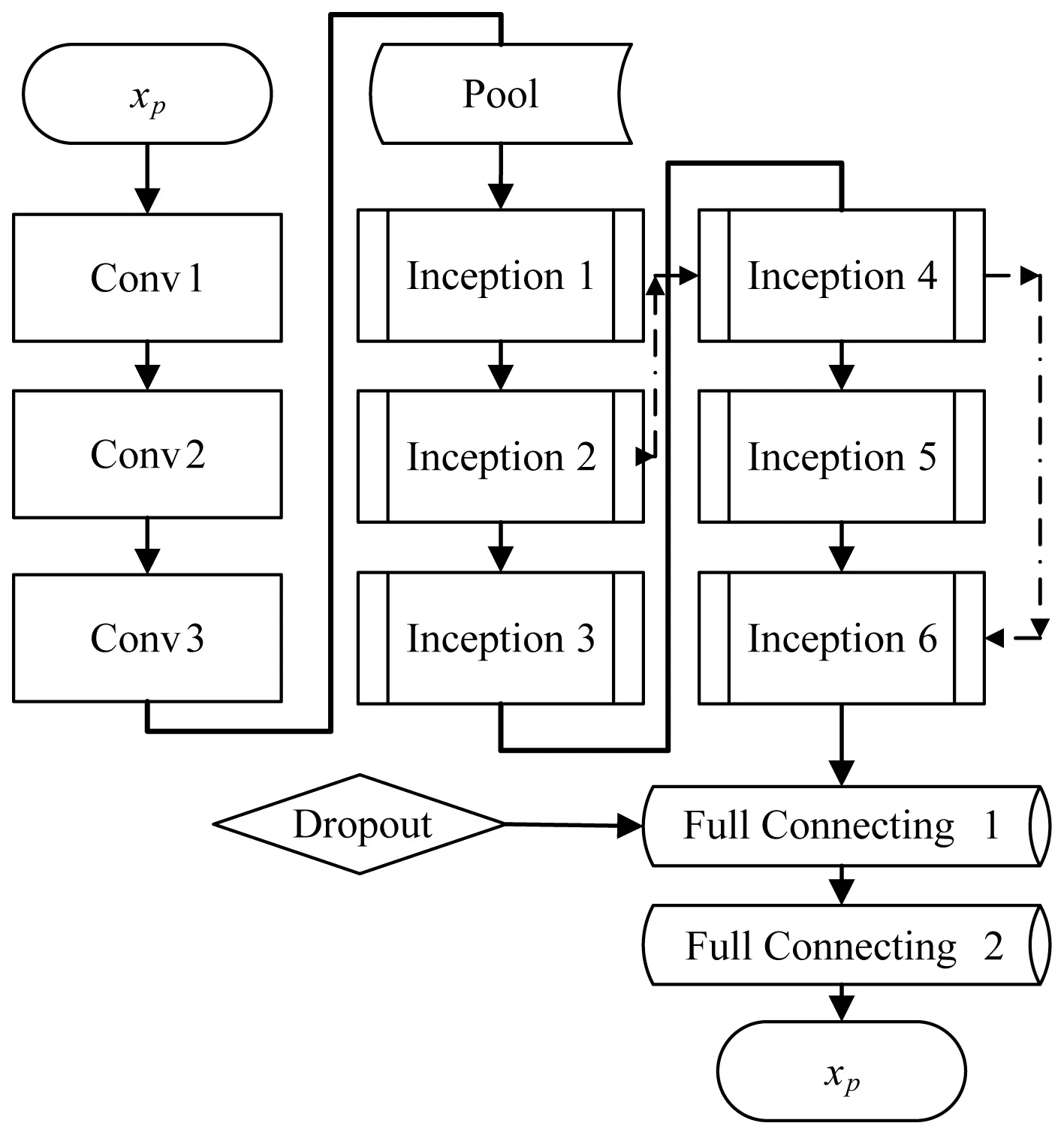
图2 算法卷积神经网络部分结构图
卷积层(Conv1-3):通过卷积,获取图像的多个特征。每个卷积后面均跟随一个修正线性单元ReLU(Rectified Linear Units)和BN层。参数设置上patch size均为3,stride为2,channel为32,pad为2。Conv1-Conv3参数共计928+9 280+18 624=28 832个。
最大池化层(pool):采用最大池化层降低特征图(feature map)一半的大小,stride为2(非重叠),patch size设为2。
Inception1-Inception6单元:为减少参数和加速收敛,将原有5×5卷积改为两个3×3,增加了网络的非线性。inception单元内部参照googlenet V3中的设计[6],但单元数较之原算法减少一半。值得一提的是,我们将Inception2到Inception4和Inception4到Inception6单元之间,设计了两条跳转直连的网络通路,目的是为了避免多次Inception传输后导致的特征损失(图2中虚线表示)。
全连接层(1-2):将Inception单元最后获得的“分布式特征表示”,映射到样本标记空间,下述的dropout就在全连接层1展开,具体见③,全连接层1生成大小为512的输出,全连接层2将1输出大小再次减半,最终获得大小为H=256的输出层记为{yp,n},为CNN后生成的全连接特征值。可得:
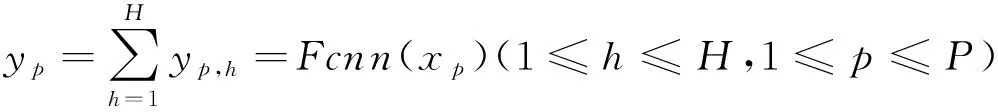
(2)
式中:Fcnn(·)为xp经过多重神经网络后生成yp的H个特征值的函数表示。
③ 分类:
直接根据欧式距离生成样本间的距离函数,任意两张图片p1和p2间距离为:
(3)
我们将生成距离用Softmax分类,尽可能让类间距离最小,类内距离最大,即下式最小:
(4)
式中:φ(·)为用Softmax回归函数生成的预测概率和真实概率的交叉熵。最终完成车辆属性分类,生成车型类别为1到T的集合结果。
④ 难负样本挖掘:
{x(i,t)|xi,t∈} 1≤t≤T1≤i≤It
(5)
即xi,t为第t车型类别下的第i张图片。
我们首先将本次CNN网络迭代次数记为r,并假设在第r次迭代完成之前,C图片已被神经网络判别为tc车型分类的positive数据集中,这时网络的输出层可表述为:
tc(r-1)∪HNeg(r-1)
(6)
即被分为相对于tc完全分类的true positive和hard negitive两部分的数据集。所有的图片可以在多次不同的迭代中分类到各自的true positive集中去,如图片B被正确分类为tc,我们这里不做继续讨论。但设在第r次迭代中获得的正样本集为tc(r)中存在正确正分类Truetc(r)和错误正分类Falsetc(r),即:
tc(r)=Truetc(r)∪Falsetc(r)
(7)
我们将错误正分类并入原HNeg(r-1),正确正分类并入原tc(r-1),即:
HNeg(r)=HNeg(r-1)∪Falsetc(r)
(8)
tc(r)=tc(r-1)∪Truetc(r)
(9)
为考虑在类别t下正样本过多情况下tc(r)不断增长所引发的数据不均衡加剧的情况,不同于文献[8]的处理方式,我们引入了质心和距离函数δ(t,r,i),当时,即It(r)为第r次迭代在类别t下正样本数与该迭代时的总样本数P(r)的比值等于π(t,r)倍的总样本均衡分类值时,开始筛选tc(r)集合中的样本。π(t,r)可写为:
(10)
筛选时,我们保留该集合下最边界的样本,即找出距离质心最近的样本的予以丢弃,以停止该分类下样本数增长。距离函数定义为:
(11)
我们将丢弃操作记为Throw():
(12)
即在达到π(t,r)条件时,执行Throw()操作。其中findmin(δ(t,r,i))为找出距离质心最小距离的样本。根据我们车辆数据的不均衡度,我们将π(t,r)设为4,即保留正样本数不超过样本均衡分类值的4倍。值得注意的是,为了避免样本差别大导致的质心偏移,我们建议该方法应用于不均衡性程度高且样本量足够大的数据集中。所得结果将不断更新入网络输入层,随着迭代次数的增加,增强各类别边界的易混淆类别的数据易分性。
⑤ 基于神经元重要性分值的dropout实施:
我们把dropout的操作实施在全连接层1上,未沿用以往随机减去神经元的做法,而是参考了文献[10]的方法后,采用了简单计算的基于分值的dropout方法。给每个神经元m在网络中所起到的重要性进行打分,分值记为Score(m),设:
Score(m)=φ(Fcnn(xp))-φ(Fcnn-m(xp))
(13)
式中:Fcnn-m(·)表示将神经元m置为无效时的神经网络,即我们把m无效时和有效时,两者的回归概率差值作为该神经元的重要性的分值函数。判定是否丢弃该神经元的判定函数为:
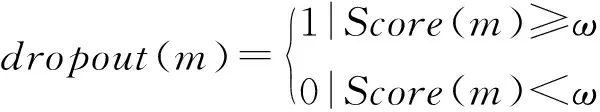
(14)
式中:ω为重要性分值的临界阈值。我们把ω置为0,即当神经元m有作用时予以保留(即dropout(m)=0),无作用或为负作用时丢弃(即dropout(m)=1)。该方法既减少了随机dropout带来的盲目性,又可以根据ω值得设置,保留神经网络中发挥作用或作用最大的神经元,在缩减网络大小和去除无效网络结构的同时,实现了提升网络识别效果的双重作用。
2 实验结果与分析
2.1 神经网络训练效果
本文神经网络模型训练过程如图3(a)所示,为便于比较性能,我们在图3(b)中同时展示了Googlenet V3算法的训练情况。在两者同样进行共计20.083 33小时的241 000次迭代过程中,本文算法在耗时15.92小时的191 000次迭代中达到收敛,此时识别率(accuracy)为91.69%,距离最终最高正确率91.96%仅0.27个百分点;较之图3(b)中Googlenet V3中在耗时18.33小时的第220 000次迭代达到收敛,具有训练时耗少、收敛速度快的特点。究其原因,本文在难负样本挖掘和基于神经元重要性分值的dropout步骤,起到了提升算法识别率和效率的作用。
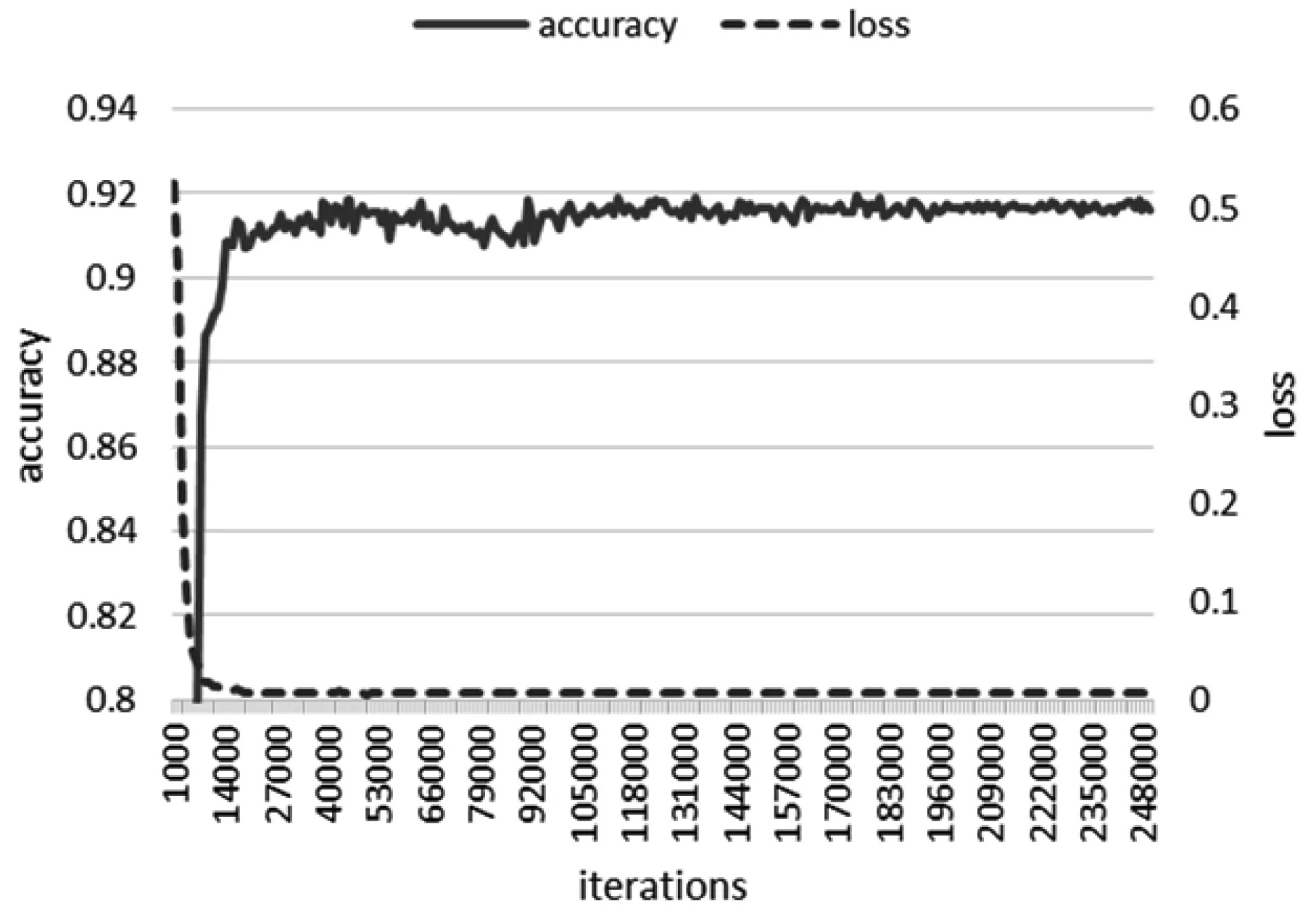
(a)
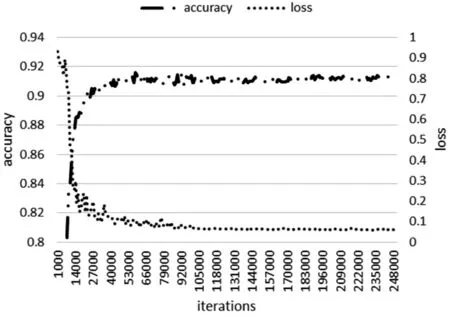
(b) 图3 本文神经网络算法与Googlenet V3训练过程比较
2.2 各神经网络算法比较实验
我们接着对本文神经网络与业界熟知的神经网络进行了识别率的比较,结果如表1所示。我们看到,本文算法在前1(top1)和前5(top5)置信度上获得了91.96%和96.42%的识别率,较之Lenet CNN、Alex CNN、Googlenet V197,在top1上都有较大的提升;在与较本文算法层级更多的Googlenet V3算法的识别率比较上,本文算法在top1上略高于V3算法0.74个百分点,证明了算法在图像分类上的优越性。
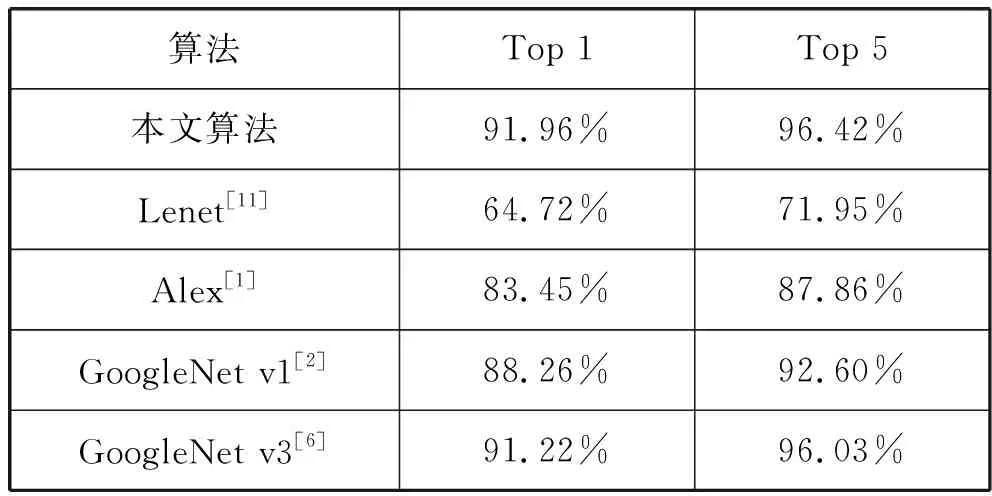
表1 各主流神经网络算法与本文算法的识别正确率比较
3 结 语
本文利用一种识别率、收敛速度、训练耗时均优于googlenet V3的改进的CNN神经网络算法,实现了基于大规模机动车图像库的车型属性分类。我们在该CNN网络的基础上,提出了通过难负样本挖掘和基于神经元中重要性分值的dropout方法,缓解了样本不均衡性问题带来的不利影响,进一步提升了神经网络的特征提取能力,显著减少了神经网络的算法消耗,提升了算法的训练速度。下一步我们拟进一步增加样本,及将该算法应用在车辆其他属性分类实践中,实现车辆全属性的分类。
猜你喜欢
电子科技大学学报(2022年4期)2022-07-15
湖南林业科技(2021年3期)2021-12-02
甘蔗糖业(2021年4期)2021-09-26
电子产品世界(2021年8期)2021-01-16
土壤(2020年2期)2020-06-15
中国计算机报(2019年49期)2019-02-07
中国新闻周刊(2017年36期)2017-10-21
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
