
自然场景下中文文本定位关键技术的研究
2018-07-25 11:22王晓华
计算机应用与软件 2018年7期
万 燕 王晓华 卢 达
(东华大学计算机科学与技术学院 上海 201620)
0 引 言
随着移动终端和多媒体技术的飞速发展,各种新型的应用场景中将会用到图像中的文本信息,而文字能够帮助人们更有效地理解场景图像的高层语义信息。利用计算机技术自动地提取场景图像中的文字信息是计算机视觉和模式识别领域重要的研究内容。
在现有的研究中,自然场景文本定位的方法主要可归为两类[1]。一是基于滑动窗口的方法[2-3]。该方法主要利用多尺度滑动窗口和纹理,将边缘梯度和直方图等特征相结合,然后利用机器学习等方法设计分类器来识别文字窗口和非文字窗口。该方法的时间复杂度高,计算速度也很慢。二是基于连通区域的方法[4,6-11]。该方法是把具有相似属性(颜色、亮度、笔画宽度等)的像素点聚合起来提取候选文字,然后合并候选文字,从而完成文本区域的定位。近年来,基于连通区域的文本定位方法最典型是基于MSER[5]和基于SWT[6](Stroke Width Transform)的方法。基于MSER的文本定位方法是使用MSER算法提取出候选文字区域,该方法对图像的旋转、仿射变换具有鲁棒性,并且快速、稳定。2010年,Neumann等[7]将MSER算法应用于自然场景文本定位。Ye等[8]对场景图像多通道提取MSER,然后利用纹理特征和文本之间的特征相结合对候选文本进行合并、分类,得到文本检测结果。Yin等[9]利用剪枝算法去除检测到的重复区域,然后利用单聚链算法将单个候选字符合并成文本行,并对文本行进行分类,得到最终定位结果。Epshtein 等[10]提出了基于笔画宽度变换SWT的文本检测算法,将具有相同笔画宽度的像素点聚合在一起生成连通区域,再根据文字的结构特征滤除掉非文本区域,得到检测结果。Yao[11]基于笔画宽度变换算法,并在此基础上提出多方向文本聚链的方法,最终可以定位任意方向的文本。该方法获得了良好的效果。
以上方法是针对自然场景图像的英文字符定位提出的。而汉字一般包含多个连通区域,并且汉字的结构复杂,直接使用以上算法对中文文本定位往往存在定位错误和漏检的问题。基于此,本文根据汉字的结构特点,提出一种中文文本定位算法。该方法利用形态学运算连接汉字分离的笔画,解决了一个汉字对应多个连通区域的问题;再结合汉字的结构特点,加入提取汉字的结构特征这一处理技术,提高了汉字定位的精确性;之后对SWT算法进行改进,在提取出的候选文本图像块内做笔画宽度变换,有效减少了文字笔画粘连的问题。实验结果表明,本文算法能有效提高自然场景图像中文文本定位的准确率和召回率。
1 中文文本定位算法
1.1 设计思想
本文算法主要根据汉字的结构特点提出的。其主要算法思想:首先采用基于MSER的方法提取候选文本区域,实现快速定位。对于汉字由多个连通区域构成的情况,把原图像归一化后使用形态学膨胀和闭运算来连接汉字分离的笔画,再提取汉字的结构特征并结合启发式规则过滤明显不是文字的区域,实现初步定位;然后,改进SWT算法,在初步定位提取出的候选图像块内作笔画宽度变换并加入自适应的判断方法,根据汉字的笔画特征实现汉字精确定位。
本文算法的总体流程如图1所示,主要包含三部分:文字初步定位、文字精确定位以及构建文本行。其中,文字初步定位主要是利用MSER算法、形态学运算和连通域分析得到候选的文字区域;文字精确定位通过候选文字区域的笔画宽度特征进一步确定文字区域;利用候选文字区域的颜色信息和几何位置关系构建文本行并对合并后的文本行进行验证,从而得到最终的文本区域。
1.2 候选文本区域定位
提取候选文本区域的目的就是对输入的原自然场景图像进行快速定位,将可能是文本区域提取出来,再进行下一步的过滤非文本区域,这样不仅能减少精细定位的复杂度,还能提高运算的速度。
(1) 提取MSER
MSER算法是一种图像特征区域提取算法,有较强的仿射、旋转不变性,在文字检测领域取得了良好效果。MSER算法是对一幅灰度图像做二值化处理,二值化阈值取[0, 255],在阈值的变化过程中,有些区域的面积随着阈值的上升变化很小,这种区域就叫最稳定极值区域(MSER),其严格的数学定义在文献[12]中给出。由于自然场景图像中的文本一般具有相同的颜色,并且与背景差别较大,而文字本身也是由连通区域组成,故本文采用基于MSER算法提取场景图像中的候选文字区域。
如图2所示的MSER处理效果可以看出,当图像背景与文本字符颜色差异度较明显时能取得较好的效果,但是当图像的对比度较低时存在检测不全的问题。因此,本文采用直方图均衡化技术对原图像进行预处理。

图2 MSER检测效果图
(2) 形态学运算
汉字由各个笔画构成,而各个笔画之间往往相互分离,并非构成一个完整的连通区域,这是由汉字本身的结构属性所决定的。这种现象不利于文字整体特征的提取。因此,我们把MSER检测结果通过数学形态学运算,把文字的各个笔画连接成一个完整的连通区域。
本文首先对采集到的自然场景图像进行归一化处理,归一化后得到分辨率为950×840像素的图像。然后,采用膨胀运算对图像进行形态学操作,膨胀既保留了文本区域的完整性,又避免了后续文本区域标记时笔画的丢失。最后,对膨胀后的图像采用闭运算操作填充图像内细小的空洞来连接断开的邻近区域,此时,检测出来的单个汉字已成为一个完整的连通区域。其形态学处理效果如图3所示,可见,“会”字由原来的两个连通区域已经连接成一个完整的连通区域。

图3 形态学运算效果图
(3) 基于启发式规则的候选文字区域过滤
经过MSER检测和形态学运算后,将检测到的连通区域作为候选文本区域,并基于其轮廓标记各个连通区域。由图4可以看出,标记出的MSER包含大量的非文字区域。为了缩小精确定位的范围,本文通过分析标记后的连通区域,主要使用候选连通区域的面积、高宽比、连通区域占整幅图像的比例、区域占有率等规则过滤掉一些明显不是文本的区域。比如面积太小的噪声区域、细长条状的电线杆和曲线状的物体等。经过启发式规则过滤后的效果如图5所示。

图4 连通区域标记

图5 启发式规则过滤
(4) 基于汉字特征的候选文本区域过滤
由图5可以看出,经过启发式规则过滤后的候选文本区域仍含有较多的非文本区域。众所周知,汉字有着复杂的笔画,一个汉字通常有点、横、撇、竖、竖弯钩等笔画构成,同时这些笔画相交相汇形成了很多交点,而角点是在汉字的两个笔画交汇处形成。相对于非文字区域,文本候选区域存在更多的角点。故本文选择在候选文本区域内通过提取汉字的这一特征来进一步过滤掉非文本区域。
Shi等[13]提出的角点检测算法是在图像中寻找最大特征值的角点。该算法稳定较好,对旋转和视角变化图像具有良好的检测效果,对图像中纹理较复杂的区域能够提取出更多的角点,并且角点可以作为汉字的有效特征区别于非文字区域。Shi-Tomasi算法是根据计算出的两个特征值中较小的特征值是否大于阈值来判断是否为强角点。为了更好地检测出汉字的角点,本文通过设置最小特征值为0.01,小窗口尺寸为3,权重系数为0.04来提取汉字的结构特征。然后,计算候选文本区域内检测出的角点个数和角点的外界矩形的信息来进一步过滤掉非文本区域,汉字特征提取步骤如下示。
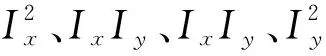
(2) 对步骤(1) 中求得的矩阵用高斯平滑滤波器滤波得到矩阵M:
(1)
式中:w(x,y)为高斯滤波器。
(3) 根据矩阵M求得行列式的两个特征值λ1、λ2。两个特征值中的最小值与初始设定的最小阈值进行比较,大于初始值的点确定为强角点。
(4) 通过设定阈值,对检测到的角点数目和角点间的距离进行约束,去除伪角点。
(5) 统计启发式规则过滤后的候选文本区域中角点的数目,把不满足式(2)的候选文本区域作为非文本区域过滤掉。
N角点>3
(2)
式中:N角点代表候选文本区域的角点数目。
(6) 计算候选文本区域角点的外接矩形的长、宽,并根据其与候选文本区域的长、宽之间的关系进一步过滤非文本区域。具体的条件如下:
w角点>0.5×w∩h角点>0.5×h
(3)
式中:w角点和h角点代表候选文本区域所有角点外接矩形的宽度和高度,h和w分别表示候选文本区域的高和宽。
通过上述流程,根据汉字特征能够有效过滤掉一些非文本区域。图6展示了汉字特征提取的二值化效果,其中大矩形框为候选文本区域,大矩形框内嵌套的小矩形框为文字角点的外接矩形。图7展示了经过汉字特征过滤之后的效果。
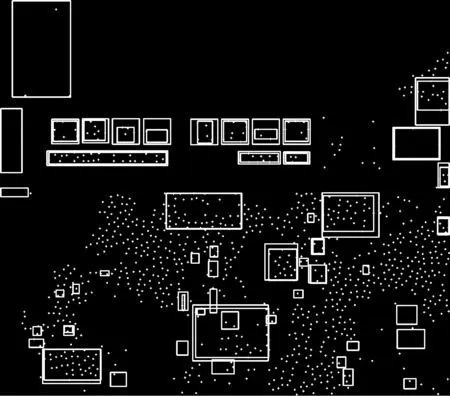
图6 文本候选区域汉字特征提取

图7 文字特征过滤效果
1.3 基于改进的SWT算法的文本精确定位
经过初步定位,一部分非文本区域能够有效地被过滤掉,但是在自然场景图像中还存在一些像树叶、杂草等非文本物体。通过分析可知,自然场景图像中的文本区域一般具有相似的笔画宽度,故本文在初步定位后的候选文本图像块内进行笔画宽度变换,并通过文字的笔画宽度的均值、方差等特征进一步过滤掉非文本区域,从而实现精确定位。
1) 笔画宽度变换 Epshtein等[10]依据邻近区域的文字通常具有大致相等的笔画宽度,提出了笔画宽度变换的概念,现已被很多学者应用于文本定位领域。笔画宽度变换SWT是一种图像局部描述算子,能很好地描述文本的特征,并且对非文字有良好的区分度。SWT算法是基于英文字符的检测提出的,其主要思想是对整个图像进行边缘检测。然后基于边缘像素点进行笔画宽度变换,即把图像中的每一个像素点的像素值转化为每个像素点的笔画宽度值,然后把具有相似笔画宽度的像素点进行聚合,进而使文本区域突出显示。
该算法在英文字符检测方面取得了突破性的进展。但是,汉字一般由多个连通区域构成,不能通过像素聚合的方法来检测汉字。另外,SWT算法主要针对暗字亮底的图像,若为亮字暗底的图像,需要执行算法两遍,故不能直接使用SWT算法。
基于以上问题,本文对SWT算法进行改进。首先,在初步定位后的候选文本图像块内进行笔画宽度变换,从而有效地避免了因汉字笔画不平行或者笔画缺失导致无法形成有效的笔画路径,同时减小了计算的时间复杂度。然后,对于亮底暗字图像或者暗底亮字图像,本文提出了一种自适应的解决方案:先计算候选文本框边缘上下各两行的平均像素亮度值,再计算文本框中间四行的平均亮度值,比较两者的大小。如果前者大于后者,则判定当前图像为亮底暗字,否则是暗底亮字。最后,通过笔画宽度变换后不是通过像素聚合,而是通过设置具有相似笔画宽度像素的像素值得到笔画宽度图像,从而根据图像块笔画宽度的均值、方差等特征进一步过滤掉非文本区域。
改进的SWT算法如下:初始条件设置图像的每一个像素点的像素值为无穷大。
(1) 判断初步定位提取出的候选图像块是亮底暗字图像还是暗底亮字图像。
(2) 对候选文本图像块进行 Canny边缘检测,取得边缘图像。
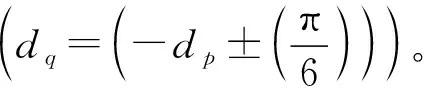
① 若无相匹配的q或者dp与dq的方向不满足要求,则废弃此路径r=p+n·dp(n≥0),需另选取一个新的边缘像素点并查找与之相匹配的像素点。
② 如果找到相匹配的像素点q,则对应于[p,q]这条路径上的每个像素点的值将被赋值为像素点p、q之间的欧氏距离‖p-q‖,即笔画宽度值,如果该点已被赋值且当前笔画宽度值比之前的小,则取较小者作为该像素的笔画宽度值。
(4) 重复上述步骤(2),算出该图像上所有没被废弃掉的路径上像素的笔画宽度值。
(5) 计算每一条路径上的所有像素的笔画宽度的中值,如果该路径上像素点的笔画宽度值超过了中值,则对该像素点赋值为该路径上笔画宽度的中值,用于矫正拐角处像素的笔画宽度值,算法结束。
图8展示了SWT算法改进前的笔画宽度图, 图9展示了改进的SWT算法提取的部分文本图像块和非文本图像块的笔画宽度图。由此可见,改进后只对候选文本区域内的图像作笔画宽度转换,有效解决了笔画粘连的问题。
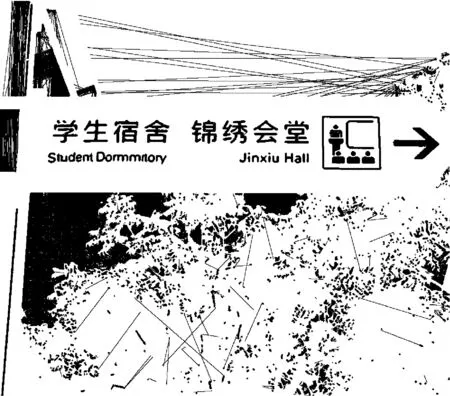
图8 原图像笔画宽度图

图9 候选图像块笔画宽度图
2) 笔画宽度特征过滤 由图9可以看出,文字区域的笔画宽度比较均匀,并且文字像素点占整个文字图像区域的比例适中,而非文字区域的笔画宽度变化较大,并且还有部分图像区域没有形成有效的笔画路径。所以,本文选取候选文本图像块笔画宽度的变化性、文字像素占空比等特征对非文字图像区域进一步过滤。
首先,计算候选文本图像块内形成有效笔画的均值、方差,根据均值与方差的关系,图像块内相邻区域笔画宽度的比值等特征过滤掉笔画宽度变化较大的非文本区域。然后,通过计算图像块内文字像素点占图像块像素点的比值,进一步过滤掉非文本物体。经过实验证明,此条规则可以过滤掉在初步定位阶段无法过滤的树叶、杂草等非文本物体,从而实现精确定位。其笔画宽度特征过滤效果如图10所示。

图10 笔画度特征过滤
1.4 文本区域合并
通过初步定位和精细定位,可以得到自然场景图像的单个文字区域。但是,其定位结果中往往还会存在个别的漏检文字和一些没有滤除的非文本区域。文字定位的结果一般要求以文本行的形式存在,但是,自然场景图像的文本不仅有水平方向,而且还有竖直方向和倾斜方向等多种形式存在。
针对以上问题,本文采用文献[9]提出的任意方向文本行构建算法并结合汉字的特点合并文本区域。因此,首先是对精细定位之后的单个文字区域依照区域相关的位置信息和几何信息两两配对,然后按照距离对配对后的区域排序。最后,用聚合算法合并文字区域。本文通过设置文字区域的高宽比、相邻区域笔画宽度均值之比、两文本区域的中心距离及区域颜色相似性等规则进行配对。
配对后,首先按照两区域中心点的距离进行从小到大排序,距离越小越优先合并成文本行。然后基于两文本对有一端相同并且方向基本一致这一规则,把两文本对合并构成文本链,并更新文本链的距离和方向。重复上述过程,直到没有文本对可以合并为止。经过上述合并,可以把字符阶段漏检的文字通过构建文本行准确定位。另外,对于在单个文字定位阶段未过滤掉的非文本区域,通过设置文本链中文字的个数进一步滤除,最终获得较准确的文本定位效果,其效果如图11所示。

图11 最终定位结果
2 实验结果及分析
由于ICDAR竞赛提供的数据集主要是针对英文字符的定位,而本文主要研究自然场景图像中文文本的定位。因此,本文自建数据库,利用智能手机采集200张不同字体、不同场景的图像,图像的像素为1 000万,包括标志牌、路标、指示牌等,其图像中的文字方向任意,文本行数任意。对每张图像中的文本区域用最小外接矩形框进行手工标定。
为了证明该算法的通用性,本文选取ICDAR2015(chanllenge2)和MSRA-TD500两个标准数据库上的部分图像进行测试,其效果如图12、图13所示。可以看出,文本区域均被正确定位,其中图13为一幅图像中存在暗底亮字和亮底暗字两种类型的文本。可以看出,本文算法对中文文本的定位具有较高的准确率,并且证明了改进的SWT算法对一幅图像中存在两种类型的中文文本定位有效、可行。

图12 倾斜文本图像定位结果

图13 两种类型文本图像定位结果
表1展示了本文的方法与其他方法在自建数据库上进行对比的实验结果。文献[14]是对MSER提取的结果,运用Adaboost分类器对连通区域分类,最后依据汉字的结构合并文本行,而本文是把汉字连接为一个完整的连通区域,根据同一行汉字的尺寸基本相似,运用任意方向文本行构建算法合并汉字。文献[15]是通过提取文字的HOG特征,然后运用SVM进行区分文本和非文本。该方法没有对文本行进行合并,故存在漏检的文字。

表1 本文方法与其他方法文本定位算法对比
总之,在定位效果方面,本文相对于其他两种方法能实现任意方向文本行定位和倾斜文本定位;在复杂度上,本文方法只是提取文字的相关特征,不需要设计分类器和对数据进行训练,故本文算法计算量小,定位速度较快。
3 结 语
本文采用基于连通区域的MSER方法和改进的SWT算法对自然场景下的中文文本进行定位。在分析汉字特点的基础上,通过提取汉字的结构特征,再结合启发式规则去掉大部分明显不是文本的区域。之后,对初步定位后的结果,根据区域笔画特征进一步过滤掉非文字区域,比对整个图像直接运用笔划宽度变换在时间和效果上有所提高。实验结果证明,该算法可提高中文文本定位的准确率和召回率,并且对字体的大小、文本的颜色有较好的鲁棒性。
猜你喜欢
计算机仿真(2021年8期)2021-11-17
——识记“己”“已”“巳”
小学生学习指导(低年级)(2020年12期)2021-01-16
学生天地(2020年14期)2020-08-25
计算机系统应用(2020年1期)2020-01-15
电子技术与软件工程(2019年9期)2019-07-12
小天使·二年级语数英综合(2018年10期)2018-10-15
电子技术与软件工程(2018年10期)2018-07-16
人生十六七(2015年5期)2015-02-28
销售与市场·管理版(2009年21期)2009-09-03
小学阅读指南·低年级版(2009年2期)2009-03-30
