
基于集成学习的口令强度评估模型
2018-07-25 07:41宋创创
计算机应用 2018年5期
宋创创,方 勇, 黄 诚*,刘 亮
(1.四川大学电子信息学院,成都610065; 2.四川大学 网络空间安全学院,成都610207)
(*通信作者电子邮箱opcodesec@gmail.com)
0 引言
在应用系统的认证方面,口令(Password)的安全性直接关系到整个应用系统的安全以及用户隐私的保护。随着互联网服务的发展(如邮件、电子商务、社交网络等),越来越多网络服务需要口令的保护;然而人类的记忆能力有限[1],这导致用户不可避免地使用不同程度的弱口令,或者在不同的应用系统中使用同一个口令,从而给应用系统带来严重的安全隐患(如社会工程学攻击、猜测攻击[2-3]等),所以,在用户注册时,评估用户输入的口令安全性并及时反馈给用户,提醒其注意口令的强弱,具有重要的意义。
口令安全性研究的难点在于,口令是人产生的,与人的行为直接相关,而每个人行为因内在或者外在的环境而千差万别,所以口令之间具有很大的差异。在口令评估方面,基于对猜测攻击方法和用户脆弱口令行为的深入理解,常用的方法是使用通用口令列表来评估用户输入的口令,如:以用户输入口令是否在通用口令列表里来判断口令是否可接受。这种方法具有很大的局限性,其准确程度取决于黑名单口令列表的大小,并且影响用户体验。目前,根据美国国家标准技术研究所 (National Institute of Standards and Technology,NIST)的建议[4]而衍生的启发式口令强度估计也颇受欢迎,它是基于大小写字母、数字和特殊字符 (Lower and Uppercase letters,Digits and Symbol,LUDS)数量来计算信息熵的,信息熵越大,口令强度就越强;然而,文献[5-6]中表明基于信息熵的口令强度评估方法,只能提供一个粗略的评估结果。
鉴于以上口令强度评估技术的缺陷,近年来,使用统计学来研究口令安全问题逐渐兴起,其中有基于马尔可夫模型[7],也有基于概率上下文无关文法(Probabilistic Context-Free Grammar,PCFG)[8]的。这两种方法在复杂口令强度评估上具有很好的效果,如今也都投入到了应用当中,然而对于非常简单的弱口令,它们的评估效果就有很大不足;相反地,基于启发式的评估方法和黑名单口令集合比基于概率的方法更为有效,基于概率的方法更适合评估比较复杂的口令。
基于上述研究,本文提出了基于机器学习中的集成学习方法,将多个模型作为子模型进行集成学习训练。在这个过程中,集成学习模型将扩展各个子模型在口令评估上的适用范围,强化各个子模型评估方法的优点,弱化它们的不足,达到合理评估的口令强度的效果。
本文的主要工作包括:
1)提出了基于集成学习的口令评估模型。其中的基学习器包括基于通用口令集的评估模型、启发式口令评估模型、基于马尔可夫链的评估模型以及基于概率上下文无关文法的评估模型等4类评估模型。
2)提出了基学习器自带判定器策略和基学习器间的偏弱项相对投票的结合策略,基学习器自带判定器策略有效避免了由于维度不同而对评估结果产生影响的问题,偏弱项相对投票结合策略有效强化各个基学习器的优势,弱化其缺陷。
3)选择9个网络上泄露的真实口令集合作为模型的实验数据,设计有效的评估实验。实验结果表明,本模型在口令强度评估方面要比单独子模型的表现要好,也证明了本模型的适用性。
1 整体构架
针对各个不同的口令强度评估方法存在的优势和不足,本文提出了基于集成学习的口令评估模型,整体架构如图1所示。其中,基学习器包括:基于黑名单口令集的评估学习器、基于启发式评估学习器、基于马尔可夫链的评估学习器、基于PCFG学习器等,每个基学习器之间相互独立。

图1 模型整体构架Fig.1 Architecture of model
输入口令会同时进入各个基学习器中进行评估,输出各自的评估分数S。之后,将S输入到各自的判定器中,经过各自判定器判定,输出口令判定结果Lables,其中结果集Lables包括:弱(weak)、中(middle)、强(strong)三个标签。根据各个基学习器的判定结果,采用Bagging的偏弱项相对投票的组合方法得出最终的评估结果。
2 模型结构解析
文中提出的模型由4个基学习器组成,分别采用不同的评估方法来评估同一个口令的强度,之后通过集成学习得出最终的评估结果。
2.1 基于黑名单口令集的口令评估基学习器
该基学习器采用基于黑名单口令集的口令评估方法,针对常见的弱口令的评估,该方法是非常有效的,它也是抵抗常规猜测攻击最有效方法之一。
方法中使用通用的弱口令集合为参考集,如:网络上的通用口令TOP 1000000。待测口令:Password分别与参考集合中的口令比较,如果待测口令存在于参考集合中,则判定该口令强度为弱,否则为强。
本文对该方法进行了改良,采用了待测口令与参考集合中的口令计算文本相似度。对于相似度算法,本文采用Levenshtien相似度算法,计算长度为Lp的待测口令与参考口令集合中每个口令(长度为Lc)的编辑距离(Damerau-Levenshtein distance,DL)为DL,则相似度为Sc计算方法如下:

对于判定器,模型采用不同来源的口令集合(参见第3章实验部分)进行子模型参数训练,在不同标记的数据训练集合下通过训练得出判定阈值,如在1/2 tianya口令集合作为训练集,1/2 tianya口令集合作为测试集中,得出阈值相似度 Sc∈[0.8,1]判定为弱口令,Sc∈ (0.5,0.8) 判定为中等强度,Sc∈[0,0.5]则判定待测口令为强密码。例如:参考集合为 top_1000000[9],检测如下口令,其结果见表1。

表1 Levenshtien相似度评估Tab.1 Levenshtien similarity evaluation
2.2 基于启发式口令评估基学习器
该基学习器采用启发式口令评估方法,虽然这种方法只能提供一个较粗略的评估结果,然而它在常规口令的评估上仍然有很多的应用,如:一些在线的密码评估计[10-11]以及一些顶尖的技术公司[12]。这种方法是基于由口令经验衍生的专家规则来评估的,其中口令经验认为口令构成越复杂其脆弱性就越低,抵抗猜测攻击就越强。如专家规则有:口令长度越长,口令中包含不同类别的字符种类越多,口令鲁棒性就越强。虽然这种专家规则在某些特别的口令评估上产生不合逻辑的结果,但是在一定程度上对某些口令评估比较有效,尤其是在抵抗猜测攻击时。
本文结合美国国家标准技术研究所的建议与实际口令评估训练提出合理的专家规则,其中除了大小写字母、数字、特殊字符数量和口令长度外,还考虑了连续的大小写字母数字的数量,中间字符中包含的字符类别,以及重复字符和键盘序列等。其评估分数SN计算方法如下:

其中:A表示口令总长度,Uch表示大写字母数量,Lch表示小写字母数量,Nch表示数字数量,Sch表示特殊字符数量,Mid表示口令序列中间(非开始和结尾)包含数字和特殊字符数量,R表示符合以上5个条目的数量,OL表示口令中仅包含小写字母时口令长度,ON表示口令中进包含数字时口令长度,RCS表示重复字符(大小写敏感)数量,CU表示连续大写字母数量,CL表示连续小写字母数量,CN连续数字数量,KS表示键盘序列数量,DS表示数字顺序的数量,SS表示键盘中特殊字符顺序的特殊字符数量。该方法依赖专家规则的可靠性。本文认为单纯只有小写字母或者大写字幕以及数字的口令皆判定为弱。
对于判定器,模型采用不同来源的口令集合(参见第3章实验部分)进行子模型参数训练,在不同数据训练集合下制定不同判定阈值,如在1/2 tianya口令集合作为训练集,1/2 tianya口令集合作为测试集中,得出判定阈值:当评估分数SN∈[0,50]口令判定为弱口令,SN∈(50,70)口令强度为中,SN∈[70,100]则判定为强口令。部分评估结果如表2所示。

表2 启发式口令评估Tab.2 Heuristic-based password evaluation
2.3 基于马尔可夫链口令评估基学习器
该基学习器采用于马尔可夫链口令评估方法。由于口令是人产生的,所以人从口令空间选择一个口令就产生了这个口令对应的概率,使用这个概率来描述人选择产生的口令的强度看起来是比较合理的。文献[13]首次将马尔可夫链模型引入到口令猜测上来,其核心思想是:用户构造口令是从前往后依次进行的,所以,它是根据口令字符前后之间的关系来计算口令的概率的。
2.3.1 构建n-gram的口令概率矩阵
口令字符前后之间有一定的依赖关系,n-gram的马尔可夫模型以(n-1)个前缀字符(称之为先验序列)来确定下一个字符的概率。
构建n-gram的口令转移矩阵,只需要对于每一个n元字符元组,通过式(3)计算得到其条件概率。条件概率等于该n元组出现的频数除以所有以n-1元组为先验序列的n元组的频次之和。

其中,U为口令字符空间集合,本文中选择可显示字符数量96,即口令字符空间集合 U={a,b,…,z} ∪ {A,B,…,Z} ∪{0,1,…,9}∪{S}。其中S为可打印的特殊字符集合。较大的字符集会导致转移概率矩阵的稀疏性,然而包含所有可打印的字符能完整地保留口令内在的规律。
2.3.2 口令强度评估
使用口令出现的概率来描述口令强度是基于马尔可夫评估模型的核心算法。对于n阶马尔可夫模型来说,长度为m的口令 pwd=(c1,c2,…,cm)被选中的概率为:

例如:在4阶马尔可夫模型中,口令song123其出现的概率为:

所以,使用概率描述口令强度定义为:m

本文使用真实口令数据集来训练模型参数,为了消除数据集中过拟合(Overfitting)问题,模型采用了Laplace平滑技术[14],即:在训练完毕之后对于每个字符串的频数都加0.01再去计算字符串的概率,公式如下:

其中Σ为口令字符空间的字符数量,本文使用可显示字符集,加上一个结尾符,共96个。
2.3.3 判定器
模型采用不同来源的口令集合(参见第3章实验部分)进行子模型参数训练。对准确率和计算代价进行折中考虑,本文选择了4阶马尔可夫模型作为评估模型。在不同数据训练集合下制定不同判定阈值,如在1/2 tianya口令集合作为训练集,1/2 tianya口令集合作为测试集中,得出当评估强度SM∈[0,140]口令判定为弱,SM∈(140,200)判定口令为中等强度,SM≥200则判定为强。案例测试如下:

表3 基于4阶马尔可夫模型评估Tab.3 4-Markov-based password evaluation
2.4 基于概率上下文无关文法口令评估基学习器
本基学习器采用基于概率上下文无关文法口令评估方法。观察大量的实际的口令,会发现口令存在分段式结构的特点,例如:song123,可以看成两段,字母段song和数字段123。考虑到口令的结构特点,文献[8]提出了基于概率上下文无关文法的漫步口令猜测算法。该算法先将口令按照字母L、数字D、特殊字符S三个类别进行分段操作,口令的每个分段是相互独立的。例如:“song12!@#”被切分为 L4:song,D2:12,S3:!@#,L4D2S3被称为口令的结构。
2.4.1 概率上下文无关文法评估算法
该评估算法主要分为训练和评估两个阶段,在训练阶段统计训练集中口令的结构特征的频率表Σ1和字符段的频率表Σ2。整个过程如图2所示。
在评估阶段,根据上面获得的结构频率表Σ1和字符段频率表Σ2计算口令出现的概率,计算方法如下:

则口令强度SP的计算方法如下:

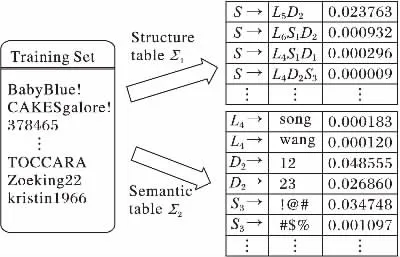
图2 PCFG算法的训练过程Fig.2 Train process of PCFG algorithm
2.4.2 判定器
本文使用不同来源的口令训练集对PCFG子模型进行训练,在不同数据训练集合下制定不同判定阈值,如在1/2 tianya口令集合作为训练集,1/2 tianya口令集合作为测试集中,得出SP∈[0,150]为弱口令,SP∈(150,200)为中等强度,SP≥200为强口令。测试案例及结果如表4所示。

表4 基于PCFG模型评估Tab.4 PCFG-based password evaluation
2.5 集成学习的Bagging方法
Bagging是并行式集成学习的著名代表。它是基于自助采样法(bootstrap sampling)在给定包含m个样本的数据集中,先随机取出一个样本放到采样集中,再把该样本放回到初始数据集,使得下次采用仍有可能被选中,经过m次随机采样,得到含有m个样本的采样集。初始训练集中约有63.2%的样本在采样集合中出现。
本文用4个含m个样本的采样集分别训练4个子模型,再将4个子模型进行结合。在结合策略方面,本文对相对多数投票法进行了改进,使投票结果偏向于弱项,投票部分规则如表5所示,当出现票数相当的两个选项时,选择低强度作为输出,即:偏弱项投票。

表5 偏弱项投票法部分规则Tab.5 Partial rules of tendency voting
3 实验及结果分析
3.1 实验数据集
本文训练测试所用到的口令数据集为国内外知名网站泄露的用户真实口令集(在文献[15]中使用),口令集合包括:Tianya表示天涯论坛网站的口令集;CSDN表示CSDN网站的口令集;Dodonew表示网站嘟嘟牛网站的口令集合;Zhen'ai表示珍爱网网站口令集;Sina Weibo表示新浪微博口令集;Rockyou表示国外网站Rockyou的口令集;Battlefield表示国外Battlefield网站口令集;Yahoo表示雅虎邮箱口令集;Phpbb表示国外网站Phpbb口令集。实验对象为长度(length)大于6的单列口令,不包含其他信息。使用的口令集合描述如表6。
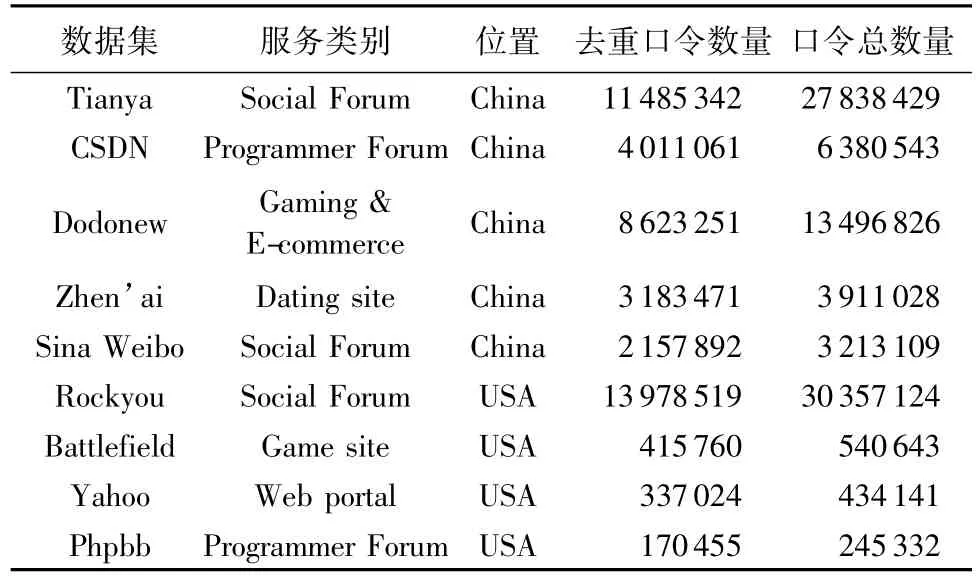
表6 实验口令集描述Tab.6 Detail of experiments password sets
这些网站泄露的口令集涵盖了境内外多个服务包括社交论坛、游戏、约会交友以及电子商务邮箱等,保证本文中模型得到综合的训练和评估。
从表7中可以看出在不同的口令集之间的共有情况。其中第一列表示数据集对比并用其首字母大写表示,如T&S表示Tianya和Sina Weibo之间的共享比例,其他数据集类似。可以看出,对于口令集合的Top 10000之间的口令共有程度,所属国家相同的口令集合比所属国家不同的口令集合的要高。

表7 部分口令集合之间共享比例Tab.7 Password sharing proportion between password sets
表8统计了各个口令集合中4种字符类别LUDS所占比例,可以看出每个网站的口令集,约有99.9%的口令包含两种或两种以上的字符类别,约有一半的口令包含三种类别的字符。
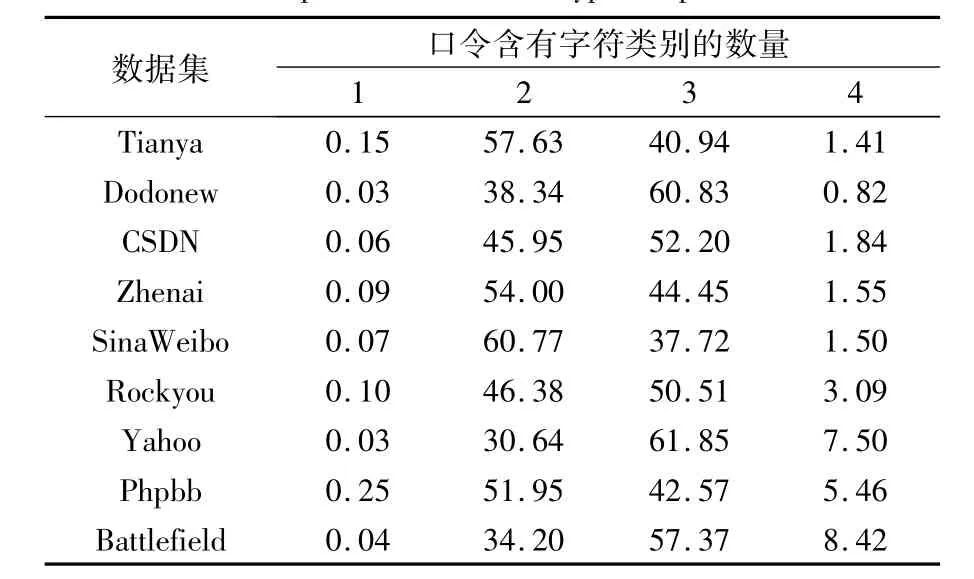
表8 口令字符类别(LUDS)所占集合比例 %Tab.8 Proportion of character types in password sets %
表9对口令集合中的口令长度(length>6)进行了统计。从表中可看出各口令长度子口令集在总口令集中所占比例。口令长度大多集中在7~15位,9位口令最多。
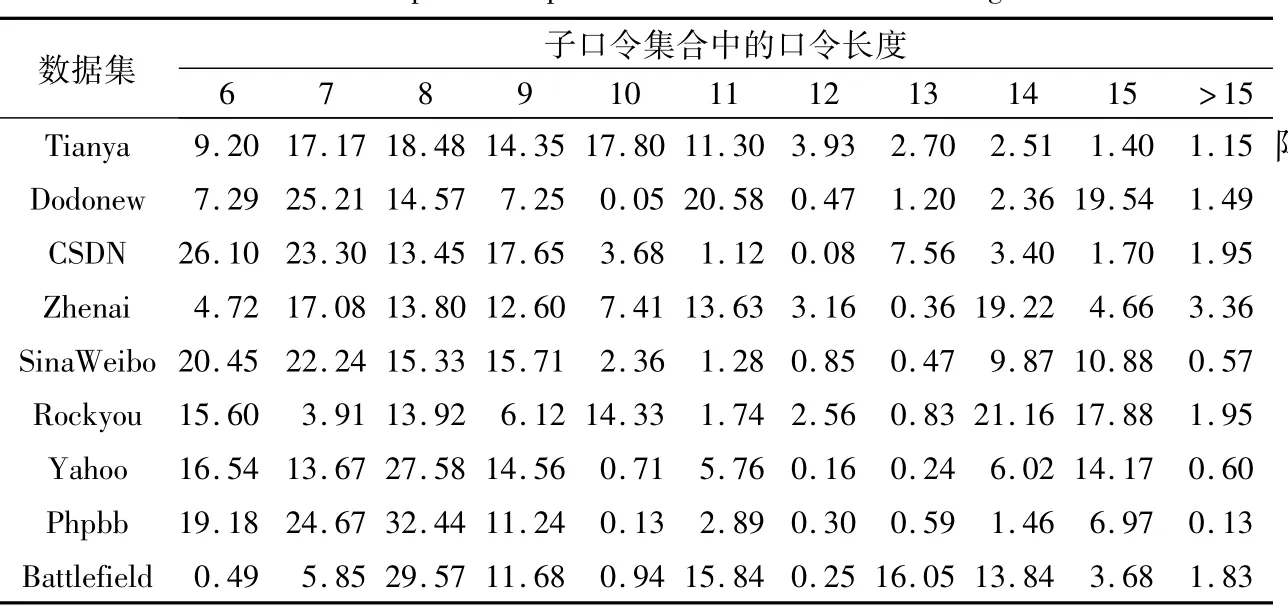
表9 口令集合中各口令长度所占比例 %Tab.9 Proportion of password subset with different length %
3.2 实验步骤
1)针对训练样本数据集,依据Bagging的自助采样方法进行数据采集,每个进行有放回的随机采样,选用每个网站口令的1/2作为训练集合,1/2作为测试集合。每个数据集得到4个采样集。
2)选用采样得到的训练集分别对2.1节~2.4节介绍的模型以及本文提出的模型进行训练,得到各自模型参数。
3)从每个测试样本集中随机取出1000个口令进行人工标记。将标记的样本分别通过2.1节~2.4节介绍的模型和文中提出模型进行评估,得到评估结果。分析实验评估结果,得出结论。
3.3 实验结果分析
为了方便描述实验结果,本文随机从测试集合中抽出两个测试集用来作实验结果描述。选择在1/2 CSDN和1/2 Rockyou口令集合作为训练集下,随机从对应测试集合中取出1000个口令进行人工标记,其标记结果如表10所示。

表10 1/2 CSDN&1/2 Rockyou口令测试集随机取1000口令标记结果Tab.10 Labeling result of random 1000 passwords from 1/2 CSDN&1/2 Rockyou testing sets
为了评价模型的优劣程度,本文将各个基模型与集成学习模型分别在相应的训练集合下评估对应的标记的测试集的口令,计算其对应的标记口令的评估结果的混淆矩阵。
在1/2 CSDN训练集合下各个基模型的评估混淆矩阵如下:基于攻击的评估模型的混淆矩阵:

基于马尔可夫(Markov)链评估模型的混淆矩阵:

基于概率上下文无关文法模型的混淆矩阵:

在1/2 Rockyou训练集合下各个基模型的评估混淆矩阵如下:
基于攻击的评估模型的混淆矩阵:

基于集成学习模型的混淆矩阵:
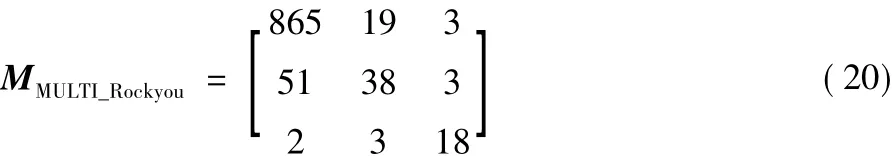
从混淆矩阵中可以初步看出在评估标记的测试集合时,各个评估模型的优劣性。
为了更直接评价各个模型的性能,本文将计算不同模型在不同的训练集下的评估的准确率(Accuracy,Ac)、精确率(Precision,Pr)、召回率(Recall,Re)、以及综合评价指标 F1值(F1-measure,F1),通过这些指标来衡量本文中模型的优劣程度。如表11所示,各个模型的指标对比,可以看出本模型在不同的训练集合下,口令强度评估的各个性能指标要比传统的评估模型的表现更好,这也证明了本模型的适用性。

表11 各个模型之间性能对比Tab.11 Performance comparison between models
4 结语
本文提出了一个高通用性高准确性的口令强度评估模型。它综合利用以往口令研究领域的评估方法,有效弱化每个评估方法的弱项,强化利用其优点,利用集成学习方法,采用偏弱项相对投票法评估口令强度。基于实际网站口令集合的口令评估实验证明,基于集成学习的口令评估模型具有高度的适用性。下一步的研究是结合更多的口令评估模型,采用更高级的结合策略。
猜你喜欢
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
计算技术与自动化(2019年3期)2019-11-05
电脑爱好者(2019年8期)2019-10-30
动漫界·幼教365(小班)(2019年10期)2019-10-28
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
科技创新导报(2019年31期)2019-04-07
儿童故事画报(2019年3期)2019-04-01
