
考虑用户特征的主题情感联合模型
2018-07-25 07:41许银洁孙春华刘业政
计算机应用 2018年5期
许银洁,孙春华,刘业政
(合肥工业大学管理学院,合肥230009)(*通信作者电子邮箱ahcrocky@163.com)
0 引言
随着互联网的发展,越来越多的用户倾向于在网络上发表评论,这些评论为消费者的购买决策和商家的市场监控与策略调整提供了依据。如何对数量庞大、内容复杂的在线评论进行分析,挖掘其中的用户观点已经成为研究热点问题。主题情感联合(Joint Sentiment/Topic,JST)模型是一种无监督学习方法,能够同时提取文本中的主题和情感信息[1-2]。已有的主题情感联合模型主要是对文本内容进行建模,很少考虑用户特征。过去的研究发现,由于用户的个体异质性,不考虑用户特征将会导致情感分析结果出现偏差,即研究的外部有效性问题[3]。本文提出了考虑用户特征的主题情感联合(Joint-User Sentiment/Topic,JUST)模型,能够在文本数据中快速识别目标用户对于特定话题的情感,对于商家和消费者而言,具有重要的现实意义。
1 相关工作
传统的情感分析方法主要有两大类:基于知识的和基于机器学习的方法[4]。基于知识的情感分析方法需要借助情感字典标注文档中每个词的情感倾向,并结合一些句法规则对文档中的情感词进行加权求和,得到文档的总体情感倾向。例如,Zhang等[5]提出了一种基于规则的两阶段方法:首先依据词汇情感倾向得到句子情感倾向,然后聚合句子情感倾向得到文档情感倾向。基于知识的情感分析方法通常需要针对特定领域构建情感字典,在如今信息爆炸的时代,网络流行语层出不穷,领域情感词典难于实时更新,基于知识的方法在实时、动态地分析用户的情感倾向方面略显不足。而机器学习方法将情感分析任务视为分类问题,首先在标注正负情感的语料集上训练出分类模型,然后基于分类模型对新的语料进行情感分类。例如,Su等[6]将Word2vec方法与支持向量机(Support Vector Machine,SVM)分类器结合,分类准确率高达90%以上。Ramadhani等[7]比较了加入不同平滑方法的Naive Bayes情感分类器,结果表明,使用Laplace平滑方法的情感分类器效果最好,F1值达到0.7234。机器学习方法准确率较高,但是通常需要人工进行情感标注以得到训练集。此外,机器学习方法通常是将整条语料信息划分为正负两类,难以在细粒度的水平上分析用户情感。以汽车评论为例,“时尚、动感、运动的外观让人眼前一亮,不到10万块的价格,有这样的设计外观相当不错了,最不满意的就是内饰了,塑料感太强了,基本装饰性的东西都没有”中,用户对汽车外观持正向情感,对内饰持负向情感,如果对整条评论进行情感分类,则分类结果的应用价值不大。
主题模型可以自动识别文本中隐含的主题,且无需对语料进行人工标注[8-9],这在一定程度上弥补了传统情感分析方法的不足,因此被广泛应用于情感分析系统。起初,研究者们将主题发现和情感分类作为两个独立的任务,首先应用主题模型提取特征词,然后在文档中寻找特征词对应的形容词作为情感词[10]。但是,情感通常是依赖主题而存在的,将主题和情感割裂建模,会造成信息损失[2]。主题情感联合模型则进一步考虑了主题和情感之间的依赖关系问题,实现了对主题和情感的同步分析[1-2]。例如,Mei等[1]提出了概率主题情感混合(Topic-Sentiment Mixture,TSM)模型,该模型可用于识别文本中的潜在话题、子话题以及相应的情感;Lin等[2]提出了JST模型,不需要任何情感标签信息,实现了主题和情感同时建模;Hai等[11]提出了有监督的联合模型(Supervised Joint Aspect and Sentiment Model,SJASM),可以在同一框架下发现主题层面的情感和文档层面的情感;Zhang等[12]提出了JABST(Joint Aspect-Based Sentiment Topic)模型,模型中区分了全局主题情感词和特定主题情感词。后来的研究者对主题情感联合模型进行了改进,但大多还是对文本内容本身进行建模,较少关注和文本内容相关的用户特征信息。
已有研究表明,用户的个体特征影响其情感表达的方式[3,13],忽略用户特征可能导致情感分析结果出现偏差,包括人口统计因素导致的偏差以及事件导致的偏差等[3]。TSMMF(Topic Sentiment Model based on Multi-feature Fusion)模型[14]虽然考虑了表情符与微博用户性格情绪特征因素,但是在模型中没有对用户人口统计因素和事件特征进行解释。本文提出了一种考虑用户特征的主题情感联合模型,将用户年龄、性别等人口统计特征以及评论时间、购车目的等事件特征加入了主题情感联合模型。与其他考虑用户特征的主题模型[14-17]相比,本研究的不同之处在于:将用户人口统计特征和行为事件特征直接加入了模型,而不是生成用户特征。此外,对不同用户特征的组合效果进行了比较,与生成用户特征的模型相比,本文提出的模型具有更强的可拓展性。
2 模型介绍
2.1 JST 模型
JST模型[2]由Lin等提出,该模型在隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)模型的框架下加入情感层,采用完全无监督的方式同时建模主题和情感。最终生成文档-情感分布,文档、情感-主题分布和情感、主题-词分布。JST模型可以对无情感标注的文本信息建模,方便灵活地适应不同领域的数据,但是无法对包含额外信息的文本建模。
2.2 DMR 模型
DMR(Dirichlet-Multinomial Regression)模型[18]由 Mimno等提出,该模型是在LDA主题模型[8]的基础上加入线性先验,适用于对包含额外信息的文本进行建模。在DMR模型中,先根据文档的额外信息特征确定文档-主题分布的超参数,然后从文档-主题分布中抽取出一个主题,再从主题-词分布中抽取出一个词,最终得到带有额外信息特征的文本-主题分布和主题-词分布。与建模文档作者信息的AT(Author-Topic)模型[17]和建模文档时间信息的TOT(Topics Over Time)模型[19]相比,DMR模型具有良好的实验效果并且降低了模型的复杂性[18]。
2.3 JUST 模型
2.3.1 模型描述
本文借鉴了 DMR[18]和 JST[2]两种模型的主要思想,提出了考虑用户特征的主题情感联合模型,即JUST模型。本文之所以选择将DMR模型与JST模型相结合,在此基础上建立新模型,主要原因是:DMR模型直接将用户特征信息的影响加在文档-主题分布的超参数上,可以灵活地对加入用户特征信息的文本语料进行建模。而JST模型在真正意义上实现了主题情感的同时建模,而不是将主题和情感割裂分别建模。本文提出的JUST模型将用户特征的影响加到情感分布的超参数上,同时考虑用户特征、主题和情感三方面的影响,实现加入用户特征信息的主题情感联合建模(图1),模型中的变量含义见表1。
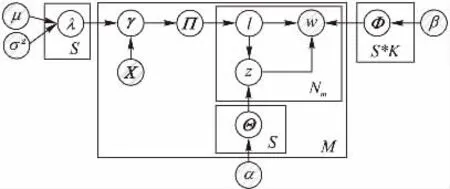
图1 JUST模型Fig.1 Joint-User Sentiment/Topic model

表1 JUST模型变量含义Tab.1 Meaning of JUST model’s variables
在JUST模型中,先根据文档的用户信息特征确定文档-情感分布的超参数γ,然后从文档-情感分布中抽取出一个情感,从文档、情感-主题分布中抽取出一个主题,从情感、主题-词分布中抽取出一个词,最终得到带有用户信息特征的文本-情感分布,文档、情感-主题分布和情感、主题-词分布。
给定用户特征矩阵X,算法过程如下:
1)对每个情感l,主题z:
情感l的参数向量λl~N(0,σ2I)
情感l主题z的词分布Φlz~Dir(β)
2)对每一篇文档m:
文档-情感分布Πm~Dir(γm)
文档、情感-主题分布Θml~Dir(α)
对每个单词i:
1)选择情感li~Mul(Πm)
2)选择主题zi~Mul(Θml)
3)选择单词wi~Mul(Φlz)
JUST模型中有4个固定参数:先验参数中的方差σ2,文档、情感 -主题分布的先验参数α,主题、情感 -词分布的先验参数β和主题数T。
2.3.2 模型求解
JUST模型(图1)的联合概率如式(1)所示:
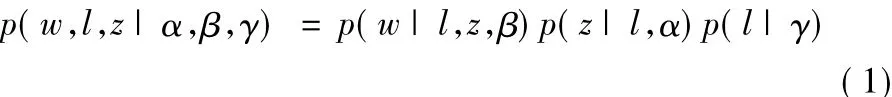
采用吉布斯采样近似计算,在文档m中,单词t属于情感l和主题z的概率更新规则如式(2)所示:

其中:Nl,z,w表示单词 w 属于情感 l且属于主题 z的次数,Nl,z表示所有单词中属于情感l且属于主题z的总次数,Nm,l,z表示在文档m中,属于情感l且属于主题z的单词出现次数,Nm,l表示在文档m中,属于情感l的单词出现次数,Nm表示文档m的总单词数,下标-t表示排除当前词t,xm表示文档m的用户特征向量,λl表示情感l的参数向量。
每次采样后,Φ、Θ、Π的更新公式如式(3)~(5)所示:

图1中文档情感的似然概率如式(6)所示,其中k表示第k维的特征:

根据式(6),对某个给定的情感l和特征k,参数λlk的对数偏导如式(7)所示:

模型具体求解:首先根据高斯分布,得到不同情感的向量参数λl的初始值,固定参数λl,根据γml=exp(xmTλl)计算出每篇文档中不同情感的先验参数γ,先验参数γ固定后,根据式(2)更新单词的情感和主题,然后固定单词的情感和主题,采用优化方法L-BFGS[20]优化参数λl,最后再将优化后的参数λl代入吉布斯采样更新规则求解单词的主题和情感,不断迭代,直到最终文档-情感分布,文档、情感-主题分布和情感、主题-词分布达到稳定。
3 实验与分析
将汽车之家的用户口碑数据作为实验数据集,比较加入不同用户特征的JUST模型、JST模型和TSMMF模型在文本情感分类上的准确性,实验流程如图2所示。

图2 实验流程Fig.2 Experiment process
3.1 实验数据
本文的实验数据是来自汽车之家的口碑数据。选择其中用户评论字数在200字以上,评论所对应的用户数据没有缺失,且用户年龄处于国家允许的驾驶机动车年龄范围内的数据。最终得到13 252条评论,其中正负情感的评论各6 626条。用户数据包括用户的年龄、性别、评论时间、评分数据、购车目的。
用户特征离散化 年龄分为以下5个区间:18~30岁、31~40岁、41~50岁、51~60岁、61~70岁;用户评论时间分为以下5个区间:2012年、2013年、2014年、2015年、2016年;用户购车目的分为以下10类:商务接送、越野、跑长途、泡妞、赛车、上下班、接送小孩、自驾游、购物、拉货;用户对汽车性能的评分数据为1~5星的5个等级。
数据分词 采用Jieba分词包进行分词,将搜狗词库中的汽车品牌型号作为用户字典加入程序以提高分词效果,对照停用词表删去停用词,得到处理后的用户评论数据。
评论语料TF-IDF处理 如果直接使用词频数进行模型训练,则所有的主题中前5个词都是“满意”“感觉”“油耗”“比较”“空间”,无法区分主题,因此,本文在进行模型训练之前,先计算出每个词的TF-IDF值,再进行模型训练。
情感字典构建 本文以Hownet情感词库和NTUSD中文情感极性字典中的情感词为种子词,使用Word2vec方法对情感词进行扩展。Word2vec是一种神经网络方法,可以依据上下文获得单词的向量表示形式,并计算单词之间的相似性。本文的具体做法是,将分词后的评论放入Word2vec模型进行训练,得到每个单词的向量表示,然后将评论中的单词与初始情感字典中的情感词相匹配,匹配成功后计算该单词最相似的词,并加入情感字典。需要说明的是,扩充后的情感词不仅仅是形容词,也可能是名词、动词等包含情感的词汇(见表2)。情感字典构建完成后,在JUST模型中初始化单词的情感。

表2 初始情感字典Tab.2 Initial emotion dictionary
最终用户特征实验数据形式如表3所示,使用0-1向量表示,属于特征子分量的标记为1,不属于的标记为0,默认特征值始终为1。

表3 实验数据Tab.3 Experiment data
3.2 实验设置
在本文的实验语料中,用户主要对汽车的空间、动力、操控、油耗、舒适性、外观、内饰、性价比、4S店服务、是否满足购车目的等进行评价。根据实验语料的特点,本文将主题数设置为20,其中10个正向情感主题,10个负向情感主题。参考JST模型[2]的做法,主题分布的超参数α值为50/主题数,词分布的超参数β值为0.01。参考DMR模型[18]的做法,σ2在默认特征值上取值为10,其他特征取值为0.5,根据经验设置,模型的迭代次数设为1000。在JUST模型中,迭代250次后开始优化参数λ,之后每50次迭代后优化更新参数λ。本文实验判断标准采用文档情感分类的准确率和召回率[21]。
3.3 实验结果分析
为了检验本文提出的JUST模型的有效性,本文以JST模型和TSMMF模型为基准模型,分别计算了 JUST、JST和TSMMF模型在情感分类上的准确率和召回率,实验结果如表4所示。
从表4可以看出,与JST和TSMMF模型相比,JUST模型有较好的情感分类效果。在单个用户特征中,加入用户年龄的JUST模型的情感分类效果较好。年龄一定程度上反映了用户的社会阶层和收入水平,不同年龄的用户在价值观、消费能力、生活形态和消费形态上会呈现很高的异质性。反映在实验数据中,不同年龄的用户关注主题和情感表达上有很大差异,JUST模型可以学习到这种差异性,更有效地生成模型。在多个用户特征的组合中,用户年龄、用户评分和购车目的的特征组合效果较好。用户评分直接反映了用户的情感,而购车目的反映了用户的关注主题,JUST模型学习到了对应的评论差异性,当这种差异性达到某种饱和状态,模型的优化效果达到峰值,再加入其他特征也不会有太大的提升,而且在本文的实验数据中,不同性别用户的评论和不同时间之间的评论,其差异性并不大。

表4 三种模型在文本情感分类上的准确率和召回率Tab.4 Accuracy and recall rate of three models in text sentiment classification
4 模型应用
本模型可识别不同用户群体的更细粒度的情感倾向,帮助商家实时掌握目标客户的消费需求,及时作出策略调整,在激烈的市场竞争中占据有利地位。本文在汽车之家的用户数据上,分别比较了不同性别的用户、不同年龄的用户、不同评论时间的用户、不同评分的用户和不同购车目的的用户之间的主题情感表达差异。
将用户性别数据加入JUST模型,计算不同性别的用户对于各个主题的情感概率。由图3可以看出,男性和女性用户基本类似,都对汽车发动机噪音(负向主题2)持负向情感,对汽车油耗(正向主题8)持正向情感。在个别主题上,男性和女性有微弱差异,例如,男性用户较为关注汽车的中控、离合(正向主题6),并对其持正面情感,而女性用户较为关注汽车的气味、头枕(负向主题0),并对其持负面情感。相应主题见表5。

图3 加入用户性别的JUST模型结果Fig.3 Results of JUST model with user’s gender

表5 加入用户性别的JUST模型的部分主题Tab.5 Part topics of JUST model with user’s gender
将用户年龄数据加入JUST模型,计算不同年龄用户对于各个主题的情感概率。如图4所示,五个年龄段的用户都对汽车的起步、换挡(正向主题0)持正向情感,对汽车的后排、隔音(负向主题4)持负向情感。61~70岁年龄段的用户较为关注汽车的轮胎、减震(正向主题9),并对其持正向情感;51~60岁年龄段的用户较为关注汽车的座椅(负向主题2),并对其持负向情感;41~50岁年龄段的用户较为关注汽车的厂家、服务(负向主题7),并对其持负向情感。相应主题见表6。

图4 加入用户年龄的JUST模型结果Fig.4 Results of JUST model with user’s age

表6 加入用户年龄的JUST模型的部分主题Tab.6 Part topics of JUST model with user’s age
将用户评论时间数据加入JUST模型,计算不同评论时间的用户对各个主题的情感概率。如图5所示,各时间段上没有太大差异。可以认为,汽车口碑在一定时间内是比较稳定的。例如,不同评论时间的用户都对汽车的座椅持正向情感(正向主题3),对汽车的异响(负向主题0)、起步噪音(负向主题2)持负向情感。2012年的评论较为关注汽车的胎噪、味道(负向主题6),并对其持负向情感,相应的主题见表7。
将用户评分数据加入JUST模型,计算不同评分的用户对各个主题的情感概率。如图6所示,5星评分基本对应正向情感的主题,而1~4星评分基本对应负向情感的主题。用户打5星主要因为汽车的轮胎、中控、离合器(正向主题7),用户打1~4星主要是因为发动机、噪音(负向主题5)、汽车的胎噪、车漆(负向主题7),相应的主题见表8。

图5 加入用户评论时间的JUST模型结果Fig.5 Results of JUST model with user’s comment time

表7 加入用户评论时间的JUST模型的部分主题Tab.7 Part topics of JUST model with user’s comment time

图6 加入用户评分的JUST模型结果Fig.6 Results of JUST model with user’s rating

表8 加入用户评分的JUST模型的部分主题Tab.8 Part topics of JUST model with user’s rating
将用户购车目的数据加入JUST模型,计算不同购车目的的用户对各个主题的情感概率。如图7所示,所有购车目的用户对汽车的后排空间、轮胎(正向主题3),音乐、USB(正向主题9)和油耗(正向主题6)持正向情感,都对汽车的异响、顿挫感(负向主题2)持负向情感。以商务接送为目的的用户的较为关注汽车的细节(正向主题7),并持正面情感,以赛车为目的的用户较为关注汽车的排气管,并持负向情感(负向主题5);以购物为目的的用户较为关注汽车的储物空间,并持负面情感(负向主题0)。相应的主题见表9。

图7 加入用户购车目的的JUST模型结果Fig.7 Results of JUST model with user’s purpose of buying car

表9 加入用户购车目的的JUST模型的部分主题Tab.9 Part topics of JUST model with user’s purpose of buying car
5 结语
针
对现有主题情感联合模型(JST)忽略用户特征所导致的偏差问题,提出了考虑用户特征的主题情感联合模型(JUST)。在主题情感联合建模过程中,加入用户人口统计特征和行为事件特征,实验结果表明,JUST模型的情感分类效果优于JST模型。同一个隐性社区中的用户通常享有共同的兴趣爱好,促使用户在网上产生追评、点赞等交互行为,导致用户的关注主题和情感受到所在隐性社区的影响,后续研究将在JUST模型的基础上,加入隐性社区层,用于解释用户所在隐性社区群体对用户关注主题和情感表达的影响,期望进一步提升模型的情感分类效果,同时也能应用于社区发现领域。
猜你喜欢
客联(2022年3期)2022-05-31
成都信息工程大学学报(2021年5期)2021-12-30
中国新闻周刊(2021年26期)2021-07-27
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
初中生世界·九年级(2020年2期)2020-04-10
阅读(快乐英语高年级)(2020年8期)2020-01-08
电子制作(2018年17期)2018-09-28
智慧少年·故事叮当(2018年11期)2018-05-14
电脑爱好者(2017年7期)2017-05-06
