
基于流计算的电力调度网络流量监测平台①
2018-07-18 06:06李喜旺周心圆
计算机系统应用 2018年7期
吴 奔, 李喜旺, 周心圆
1(中国科学院 沈阳计算技术研究所, 沈阳 110168)
2(中国科学院大学, 北京 100049)
3(吉林大学, 长春 130012)
1 引言
电力调度网是电网调度自动化、信息化的基础,是确保电网安全、稳定、经济运行的重要手段, 是电力系统的重要基础设施, 传统的电力调度网安全监测,主要是依靠工程师对网络设备进行排查或依靠网管对管理信息库及参数的分析进行定位.
随着电力系统信息化进程的加快, 持续推动了实时监测系统、现场移动检修系统、测控一体化系统、智能变电站和电力信息管理系统的扩建和应用, 使电力行业正逐渐步入到由复杂及异构数据源广泛存在和驱动的电力大数据时代. 电力学术领域开始利用云计算技术解决智能电网海量数据, 但还是无法达到很好的实时处理能力. 想要真正实现海量实时监测, 需要研究其他大数据处理技术, 例如利用内存计算, 大数据流计算等技术, 如目前主流的大数据流计算框架Hadoop、Storm、Spark等[1–3], 采用流计算对产生的数据流进行实时处理, 并将数据在内存数据库中缓存, 通过内存计算的方式加速数据的处理速度[4], 提高分析处理的性能.
2 流计算处理技术及系统设计
2.1 流计算技术介绍及计算框架的选择
相较于传统的数据处理方式, 流计算的技术特点主要体现在流入系统的数据流是实时的, 流计算能够对流入的数据进行实时处理, 并将数据在内存数据库中缓存, 通过内存计算的方式加速数据的处理速度, 提高分析处理的性能. 流数据处理的一般过程如图1所示.
图1 流计算处理一般过程
目前著名的开源数据流计算框架有Hadoop平台的 MapReduce 计算框架, Apache Storm 计算框架和Apache Spark计算框架, 他们是目前最常见的处理海量数据的开源框架.
Hadoop是磁盘级计算, 而Storm和Spark是内存级计算, 磁盘访问延迟约为内存访问的75 000倍, 因此Storm和Spark更快. 对于Storm和Spark这两个高性能并行计算引擎的最大区别在于实时性: Spark是准实时, 先收集一段时间再处理, 实时计算延迟是秒级;而Storm是纯实时, 实时计算延迟是毫秒级. 但Spark拥有更高的吞吐量, Spark还有一个特别的地方是,Spark 的软件栈允许将一些 library (Spark SQL, MLlib,GrapnX)与数据流相结合[5], 提供便捷的一体化编程模型. Spark的各个组件如图2所示.
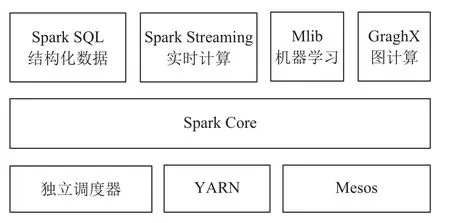
图2 Spark 软件栈
Spark计算框架解决了大数据处理遇到的批处理,实时流处理和交互式查询等难题, 结合Spark高度抽象的 RDD (Resilient Distribute Dataset, 弹性分布式数据集)概念[6], 针对多种不同的数据处理场合, 基于Spark的编程模式将被同一成相同的处理方式, Spark统一了技术栈, 降低了研发成本. 另外 Spark 拥有更清晰, 等级更高的API.
2.2 流计算网络监测模型介绍
为满足对电力调度数据网实时监测分析的实时性和高吞吐量的要求, 基于流计算的大数据实时处理分析基础平台以电力调度网络的大量实时监测数据为处理对象, 主要包括: 数据接入模块, 训练模块, 实时计算模块, 分布式存储及可视化模块. 分布式存储使用内存数据库和分布式文件数据库, 完成对实时推送数据进行存储, 实现实时分析结果存储, 以及离线处理功能.流计算网络监测模型图, 如图3所示.
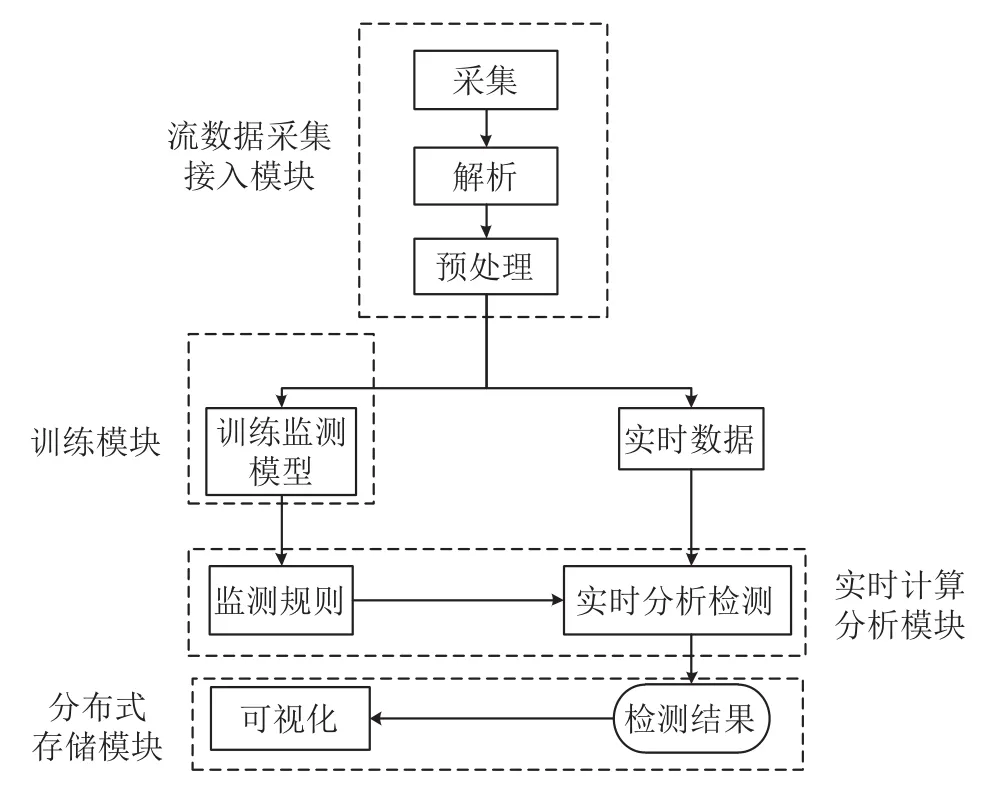
图3 网络监测模型图
2.3 系统的整体架构及工作流程
基于流数据的实时处理分析基础平台以电力调度网的大量实时监测数据为处理对象, 主要包括数据源接入, 实时流计算, 以及分布式存储展示三个基本过程.其中考虑到调度数据网中产生的实时监测数据的源头很多, 而且数据源只有接入实时处理系统后, 才可以进行流计算处理, 这里数据源是通过自适应采集获取的特定类型的数据. 结合数据流处理流向, 实时流计算系统框架图如图4所示.
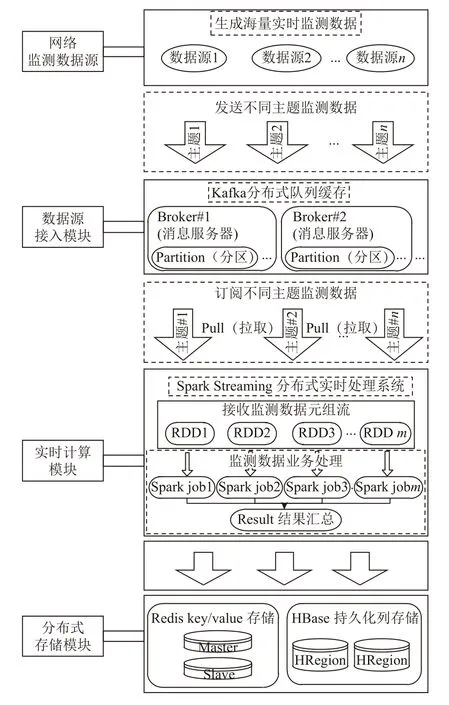
图4 流计算实时处理系统整体架构图
2.3.1 数据接入模块
使用分布式消息队列系统Kafka作为系统的数据接入模块[7], 发挥其发布订阅消息传递机制及海量消息缓存特性, 为实时监测数据的连续流计算提供数据保障. 由于数据流的生成方式采用的是Kafka分布式消息队列, 因此数据在进行整合发送时, 还需要根据发送数据的类型, 将数据添加话题字段, 同一Topic内部的消息按照一定的key和算法被分区到不同的服务器上.本系统可以包含多种数据源, 如调度网设备运行状态信息, 调度网网络流量特征等, 发布信息时流数据产生系统作为Kafka消息数据的生产者将数据流分发给Kafka消息主题, 流计算系统 Spark Streaming实时消费并计算数据. Kafka分布式集群架构如图5所示.
2.3.2 实时流计算模块
系统平台的实时流计算模块主要是基于Spark Streaming的分布式流计算框架构成, 它将流式计算分解成一系列短小的批处理作业[8], 将Kafka中每一个话题的连续数据源定义为一个数据流DStream, 而DStream为每个时间段所对应的RDD的集合, 每一段数据都转化成Spark中的RDD弹性分布式数据集.Dstream数据流的定义如图6所示.
然后将 Spark Streaming中对 DStream的Transformation操作变为针对Spark中对RDD的Transformation操作[9], 将RDD经过操作变成中间结果保存在内存中. 整个流式计算根据业务的需求可以对中间的结果进行叠加, 或者存储到外部设备. Spark Streaming的运行流程如图7所示.
2.3.3 分布式存储模块
为提高数据分析处理和数据监测预警的实时性,对于数据的存储模块则选用内存数据库实现, 这里使用分布式内存数据库Redis将实时处理分析的结果进行数据key/value存储. 由于内存数据库存储容量限制,对于访问频率较低, 数据量较大, 用以进行定期离线分析的数据,则需要借助分布式文件数据库HBase对其进行存储, 确保数据存储的可靠性, 高并发, 及扩展能力.
3 电力调度网络实时监测应用实现
3.1 网络流量异常监测
网络流量异常监测是网络安全防护至关重要的方法, 由于网络攻击具有突发性, 要求我们能够及时发现可疑网络流量, 从而采取网络防护措施. 网络流量异常监测主要实现方法[10], 首先获取正常通讯下的网络数据和攻击下的异常网络数据, 将采集到的网络数据作为带标签的训练样本[11], 可以结合Spark软件栈中的MLib机器学习函数库应用于流数据分析中[12], 通过聚类算法对训练样本进行聚类, 建立网络流量分类模型.结合流处理框架Spark Streaming, 程序加载分类模型对新增的流量数据数据进行分类, 对大规模网络流量准实时监测[13,14].

图5 Kafka 分布式集群架构图

图6 Dstream 的定义

图7 Spark Streaming 运行流程图
3.2 异常监测的实现
对于网络流量的特征向量, 采用基于机器学习的流量异常监测方法最常用的是聚类算法对数据集样本进行训练[15]. 对于如K-means等传统的划分聚类方法仅能发现球状簇, 它们很难发现任意形状的簇, 无法避免地将噪声或离群点包含进簇中. 为了发现任意形状的簇, 可以把簇看做数据空间中被稀疏区域分开的稠密区域, 即基于密度实现聚类. 对于对象o的密度则可以用靠近o的对象数度量. DBSCAN (Density Based Spatial Clustering of Application with Noise, 具有噪声应用的基于密度的空间聚类)则是基于密度聚类算法的典型代表[7]. 该算法指定参数ε来表示每个对象的邻域半径, 对象o的ε邻域则是以o为中心、以ε为半径的空间. 邻域的大小由参数ε确定, 因此邻域的密度可以简单地用邻域内的对象数度量. DBSCAN通过另一参数MinPts, 即指定稠密区域的密度阈值, 来衡量邻域是否稠密. DBSCAN算法在发现簇的过程如下文.
(1) 首先将给定数据集D中的所有对象都标记为“unvisited”.
(2) DBSCAN随机地选择一个未访问的对象p, 标记 p 为“visited”, 并检查 p 的ε-邻域是否至少包含MinPts个对象. 如果不是, 则p被标记为噪声点.
(3) 否则为 p创建一个新的簇 C, 并且把 p的ε-邻域中的所有对象都放到候选集合N中. DBSCAN迭代地把N中不属于其他簇的对象添加到C中.
在此过程中, 对于N中标记为“unvisited”的对象,DBSCAN 把它标记为“visited”, 并且检查它的ε-邻域.如果的ε-邻域至少有MinPts个对象, 则的ε-邻域中的对象都被添加到N中. DBSCAN继续添加对象到C,直到C不能再扩展, 即直到N为空. 此时, 簇C完全生成, 于是被输出. 为了寻找下一个簇, DBSCAN 从剩下的对象中随机地选择一个未访问的对象. 聚类过程继续, 直到所有对象都被访问.
4 实验与结果分析
4.1 实验环境
系统实验环境所使用的Spark集群搭建在基于Hadoop的基于分布式的安装, 集群有3个节点, 其中将一个节点配置为Master, 其他2个配置为Slave, 每个节点的配置都是内存8 GB, 并搭载Centos操作系统, 相关软件版本如表1所示.

表1 集群的软件配置
4.2 实验结果与分析
本论文使用的数据为从电力调度数据网通过自适应采集及预处理过的网络流量数据, 每个网络连接的统计信息, 数据集的大小约为708 M, 包含490万个连接. 数据集中每个连接信息包括发送的字节数, 登录次数, TCP 错误数等. 数据集包含 38 个特征, 下面是其中的一个连接的样例:
2, tcp, http, SF, 1684, 363, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 1, 1, 0.00, 0.00, 0.00, 0.00, 1.00, 0.00,0.00, 104, 66, 0.63, 0.03, 0.01, 0.00, 0.00, 0.00, 0.00,0.00, normal.
数据集中每个连接的信息包括发送的字节数, 登陆次数, TCP 错误数等. 以上代表一个 TCP 连接, 他访问http服务, 发送了1684字节的数据, 收到数据363字节, 用户登录成功等. 许多特征值取值为0或1, 比如第15列的su_attemted,它们代表某种行为出现与否.最后的字段表示类别标号, 大多数为normal.
在建立监测模型时, 由于每个特征的属性值, 和阈值不同, 我们需要将数据集进行数据归一化(数据标准化)处理, 数据归一化的标准采用的是z-score归一化方法, z-score方法是基于数据集的均值和标准差σ计算归一化后的结果, 计算方式如公式(1)所示:

实验首先经过Kafka客户端读取数据集特征数据通过创建话题的方式生产主题, 发送给Spark Streaming消费, 这里使用Direct方式读取并计算分析, 将特征数据以DBSCAN聚类学习算法进行聚类, 使用Spark-Mlib中的DbscanModel的变体StreamingDbsan[16].StreamingDbscan模型可以根据增量对簇进行更新. 我们分别就网络流量异常监测的准确性和平台计算的实时性进行测试. 准确率通过合并各个SparkStreaming输出数据来计算. 计算每个类簇所含的主要攻击种类个数与数据总数的比值.
某个类簇的准确率p的计算公式如公式(2)所示:

其中,m为类簇中数量占第一位的数据总数, 即主要攻击的类型个数,w为类簇的数据总数.
数据的总准确率P的计算公式如公式(3)所示:

其中,M为所有类簇中数量占第一位的数量总数,W为所有类簇的所有数据的总和.
表2是经过SparkStreaming结合Dbscan数据聚类分析的得出的结果.

表2 流量数据聚类检测结果
从表2可以看出, 经过聚类分析将数据分为19类,通过公式(3)可以得出总的准确率P为97.48%. 准确率较高.
实验分别在云计算和流计算处理平台, 分别以每100万条数据, 5个测试等级对应时间出来开销, 分别测试并对最终获得结果, 从图8所示的实验结果可知,与云计算方式的系统架构对比, 使用流计算的系统框架具备了分布式流处理的高吞吐的性能, 能够满足海量数据实时处理分析的性能需求.
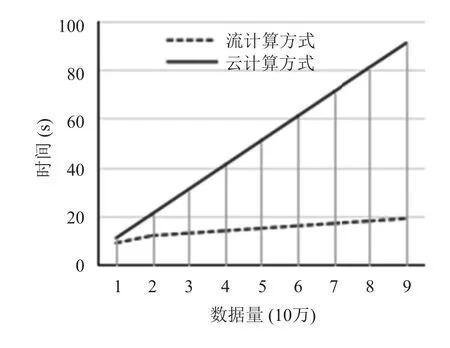
图8 云计算方式与流计算方式吞吐量对比
5 结语
本文提出了基于流计算的处理方式, 针对电网调度数据网海量数据监测分析, 构建实时监测分析平台,兼具高吞吐量高实时性及容错性和可扩展性的优势,该系统基于电网调度数据网流量数据实现了流量异常的监测, 结合流计算技术实现了海量实时数据的计算分析处理及存储的需求, 同时为电力调度网的自动化运维等其他需求提供有效可靠的借鉴思路. 但本文只是对已知的网络攻击进行分析, 还需加强未知类型攻击的算法模型创建, 系统仍然需要更加深入的改进.
猜你喜欢
航空学报(2022年7期)2022-09-05
农业工程学报(2022年7期)2022-07-09
舰船科学技术(2022年10期)2022-06-17
计算机应用与软件(2022年2期)2022-02-19
逻辑学研究(2021年3期)2021-09-29
汽车维修与保养(2020年10期)2021-01-22
沈阳工业大学学报(2020年6期)2020-12-29
汽车维修与保养(2020年11期)2020-06-09
计算机技术与发展(2020年5期)2020-05-22
微型电脑应用(2019年8期)2019-08-22
